Codebase Analysis
Challenge Day 2017
Sandy Suh, Ezra Skolnik, Suzi Curran, Morgan Packard
What we did:
- Investigated the feasibility of doing static analysis of our codebase to inform our work
- Parsed git logs from the PHP repo to look at author counts, commit counts, and reverts on a file-by-file basis
- Explored correlating errors thrown in production to files and file metadata
- Mocked the sort of results we could expect to see from an investment in this type of analysis
What we learned:
- We have a treasure trove of data in Gitlab!
- Kibana's accessibility, lifespan, and formatting demand more investment
- Let the data do the driving: we are better served by looking at as many variables as possible and letting the numbers provide us with conclusions, rather than fishing for anything in particular
- While we need to be careful about our controls, there appear to be strong correlations in file metadata, ex:
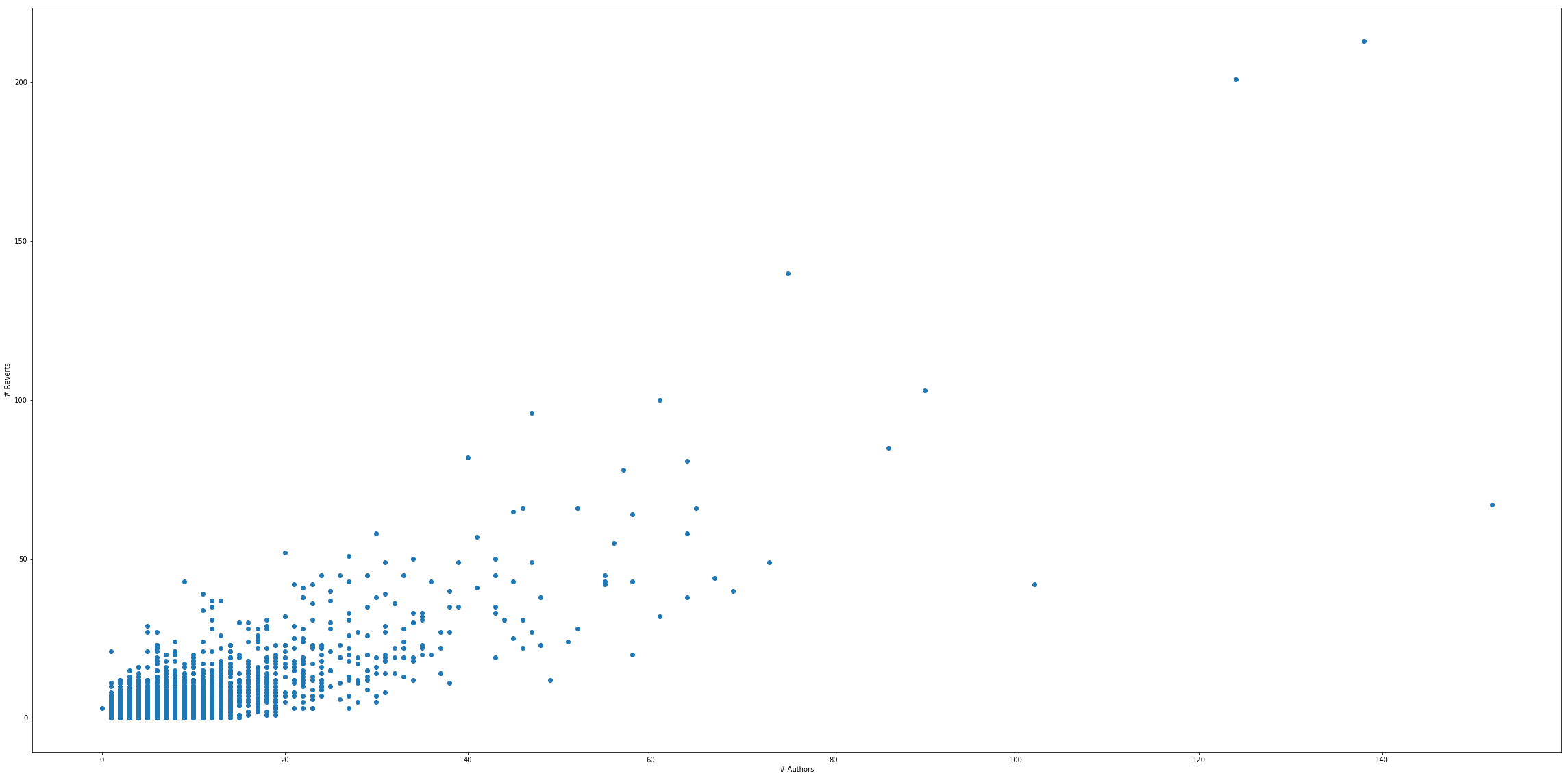
When regressing on both author count and commit count, a higher author count predicts fewer reverts
Example A: Authors to Reverts
# of Reverts
# of Authors
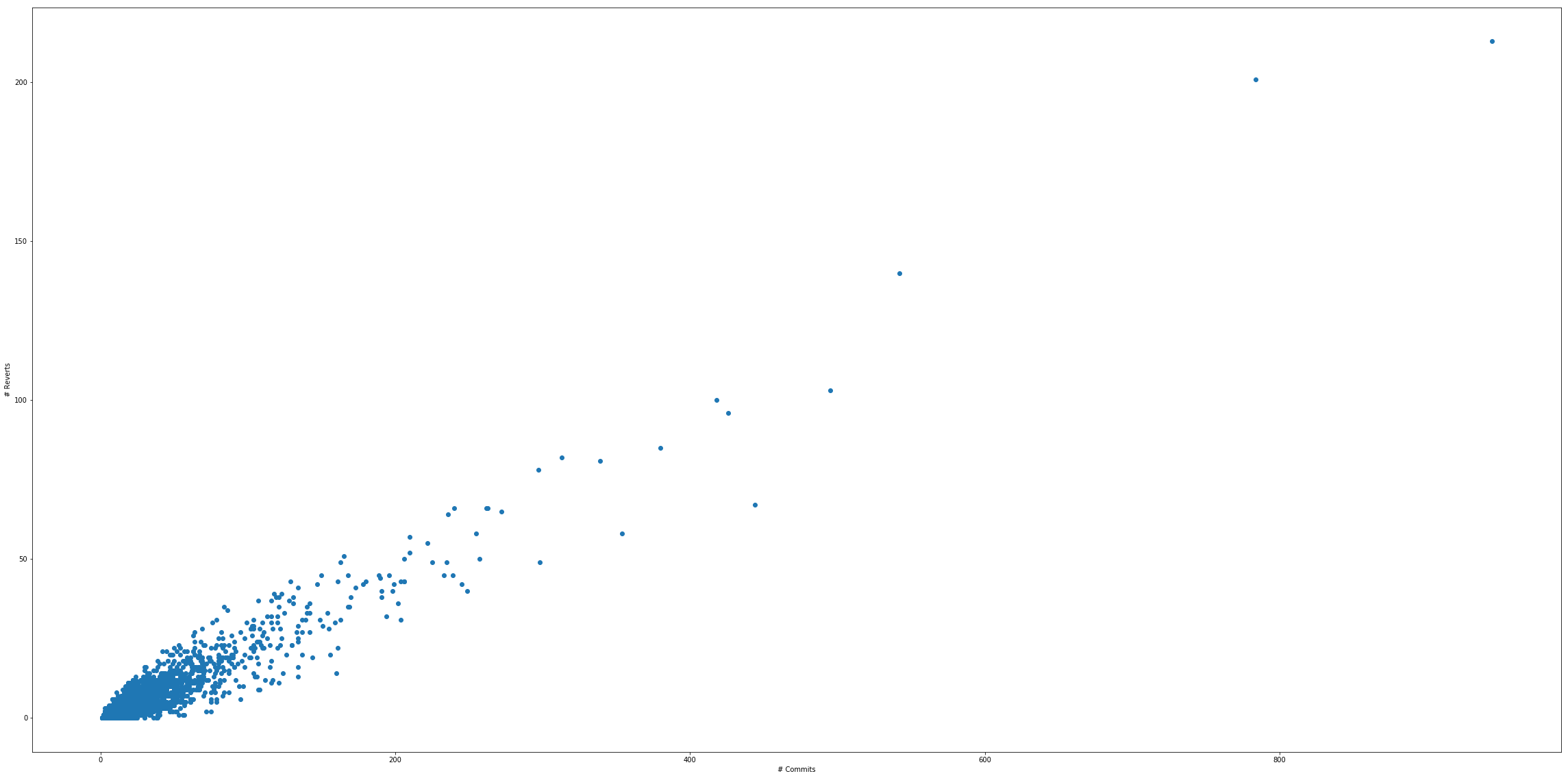
Example B: Commits to Reverts
# of Reverts
# of Commits
Kibana log batch exporter job:
https://git.csnzoo.com/mpackard/git-repo-analysis
Git repo analysis work:
https://git.csnzoo.com/wayfair/php/commits/challenge_day_17
Special Thanks To:
- Clover Bobker, for assistance with the Elasticsearch client
- The Challenge Day planning team, for their hard work