Mario meets reinforcement learning
Cristian Vargas
- Lead developer at Swapps
- Electronic engineer
- PythonCali and Calidev organizer
- https://github.com/cdvv7788
- @cdvv7788
About Me

What is Reinforcement Learning?

Agent
Environment

State and Action

Reward

Taken from: http://pngimg.com/download/36890
Repeat until it works...or you give up trying

OpenAI Gym

Mario Library for Gym
Basic program
import gym
from gym import wrappers
from random_agent import RandomAgent
from nes_py.wrappers import BinarySpaceToDiscreteSpaceEnv
import gym_super_mario_bros
from gym_super_mario_bros.actions import SIMPLE_MOVEMENT
agent = RandomAgent()
env = gym_super_mario_bros.make('SuperMarioBros-1-1-v0')
env = BinarySpaceToDiscreteSpaceEnv(env, SIMPLE_MOVEMENT)
env = gym.wrappers.Monitor(env, agent.get_recording_folder(),
video_callable=lambda episode_id: episode_id % 2 == 0,
force=True)
done = True
episode = 1
while True:
if done:
print('Restarting env. Attempt # {}'.format(episode))
state = env.reset()
episode += 1
state, reward, done, info = agent.run(env)
env.close()Random Agent
Duuuhhh
class RandomAgent(Agent):
"""
Randomly executes an action from the action space.
Has no memory nor intelligence at all.
"""
def get_recording_folder(self):
return './random'
def run(self, env):
state, reward, done, info = env.step(env.action_space.sample())
return state, reward, done, infRandom Agent
Oops?
Q-Learning

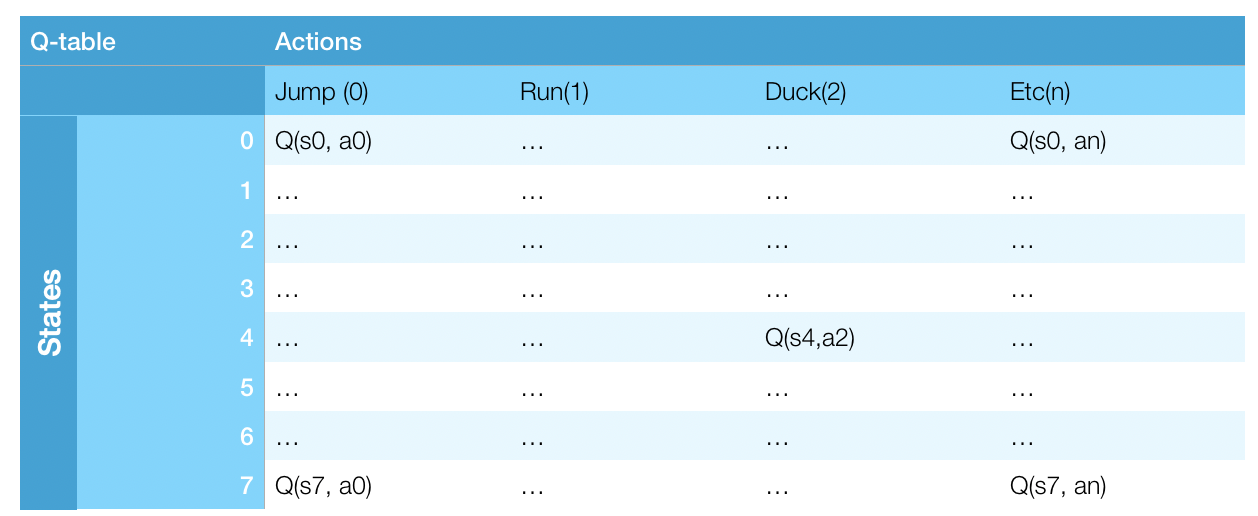
Q-Learning
Is this applicable to the Mario game?
Possible number of states, assuming we feed a single image at once, resized to 84x84 and changed to grayscale:
84*84*4*256 = 7'225,344
Q-Learning
Preprocessing steps
I followed the approach proposed in the original deepmind paper and based earlier work on a toptal post.
The approach is:
- Scale to 84x84
- Take only every 4th frame (frameskip)
- Take 4 of these frames to create an input of 84x84x4
Q-Learning
Preprocessing steps
Deep Q-Learning
In short terms, we approximate the q-table using neural networks
Challenge: Input data is highly correlated, breaking the assumption for gradient descent that the input must be independent and identically distributed random variables( i.i.d)
Deep Q-Learning
- Easy to overfit
- Stuck into local minimum
- Quickly forgets previous experiences
In general terms, using neural networks with reinforcement learning is an unstable process
Deep Q-Learning
Network Architecture
class NeuralNetwork(nn.Module):
def __init__(self, number_of_actions):
super(NeuralNetwork, self).__init__()
self.conv1 = nn.Conv2d(4, 32, 8, 4)
self.relu1 = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(32, 64, 4, 2)
self.relu2 = nn.ReLU(inplace=True)
self.conv3 = nn.Conv2d(64, 64, 3, 1)
self.relu3 = nn.ReLU(inplace=True)
self.fc1 = nn.Linear(3136, 512)
self.relu4 = nn.ReLU(inplace=True)
self.fc2 = nn.Linear(512, self.number_of_actions)Deep Q-Learning
Experience Replay
- We save every new step in a buffer of defined length.
- We train the neural network using random samples of defined length taken from the memory.
- We discard the oldest entries in the memory when it is full.
Experience Replay
Double Deep Q (DDQN)
DQN suffers of overconfidence on its estimations. This means that it can propagate noisy estimation values across the entire Q-table.
This affects the stability of the algorithm.
Double Deep Q (DDQN)
A proposed solution named Double Learning attacks this problem.
Keep 2 different tables. Take the action from table #1, and the value for the proposed action from the table #2.
Double Deep Q (DDQN)
Double Deep Q
EPOCH 0
Double Deep Q
EPOCH 10000
Double Deep Q
EPOCH 16000
Next Steps
- Prioritized Experience Replay
- Epsilon alternative algorithms
- Asynchronous advantage actor critic (A3C)
- A lot more approaches, like IMPALA