Debut as conference speaker


@Tarun_Garg2
Looking beyond B-Tree Index for performance optimizations

@Tarun_Garg2
Problem Statement

@Tarun_Garg2
Problem Statement
- The entries in the table are growing like a million in a day.
- Now, we need to find out the people born in certain states over a period of time.
Assumptions :-
SELECT * FROM population WHERE
State_of_birth IN ("Karnataka")
AND dob BETWEEN "2019-06-01" AND "2019-12-31"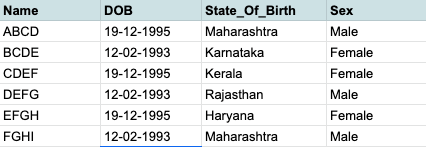

@Tarun_Garg2
Text
Why is this taking eternity to load?

@Tarun_Garg2

@Tarun_Garg2
Explain Analyze to rescue
Seq Scan on population (cost=0.00..1155.56 rows=43501 width=8)
(actual time=0.019..54.654 rows=43495 loops=1)
Filter: (state_of_birth="Karnataka"::TEXT) AND ..filters..
Planning Time: 0.103 ms
Execution Time: 54.654 ms
EXPLAIN ANALYZE SELECT * FROM population WHERE
State_of_birth IN ("Karnataka")
AND dob BETWEEN "2019-06-01" AND "2019-12-31"
The query planner was doing a sequence scan over a million records

@Tarun_Garg2
In our case,
How to avoid the sequence scan?
Indexing FTW!

@Tarun_Garg2
We also created an index with -
CREATE INDEX idx_name ON population (..columns..)
Result...?
The query planner was still doing sequence scan
@Tarun_Garg2
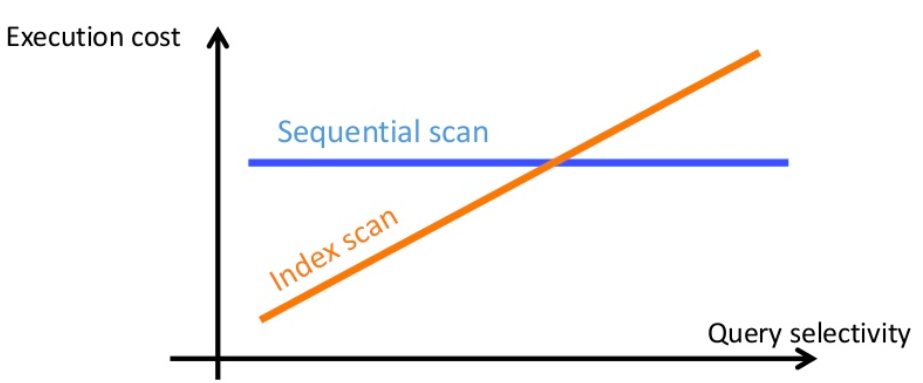
Planner: Sequence Scan or Index Scan
@Tarun_Garg2

C = seq_page_cost, random_page_cost, etc.
-
The default value of random_page_cost is 4, while the default value of seq_page_cost is 1
-
We can change these values per table and index basis usage statistics
- If your DB can fit in the RAM/Cache OR using SSD, then we can make random_page_cost~=seq_page_cost
Text

Block Range Index

BRIN Index
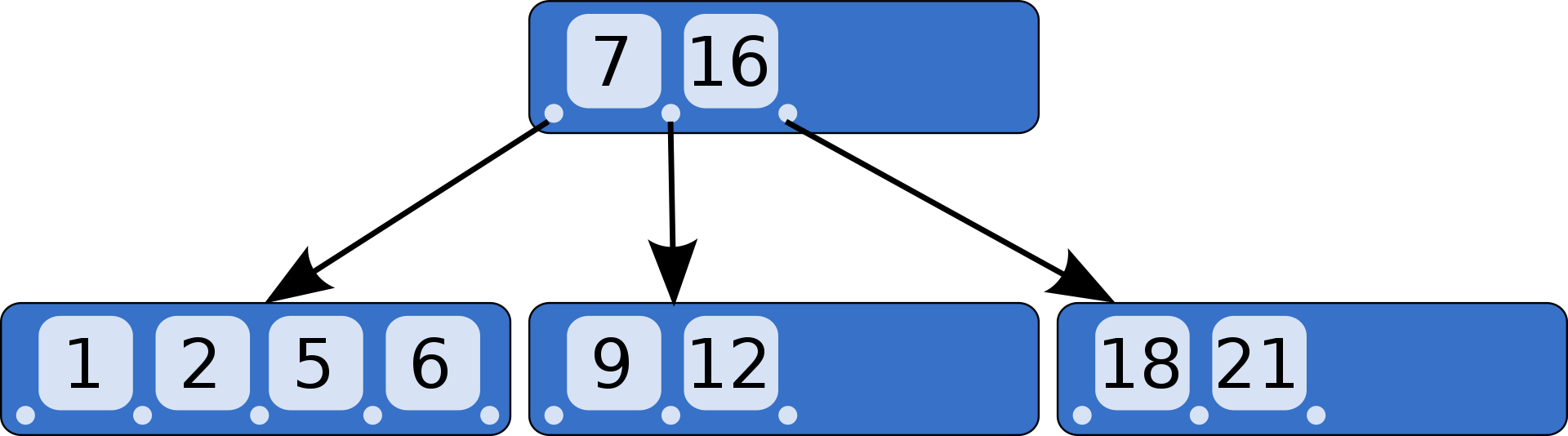
B-Tree Index
Pages = [1,2]
Pages = [3]
Pages = [4]
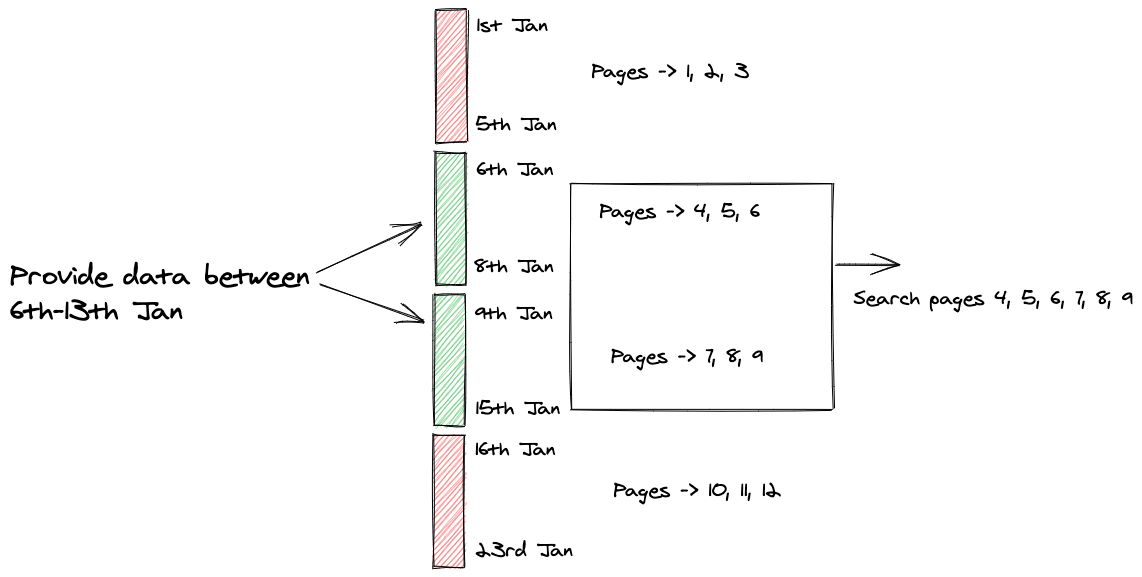
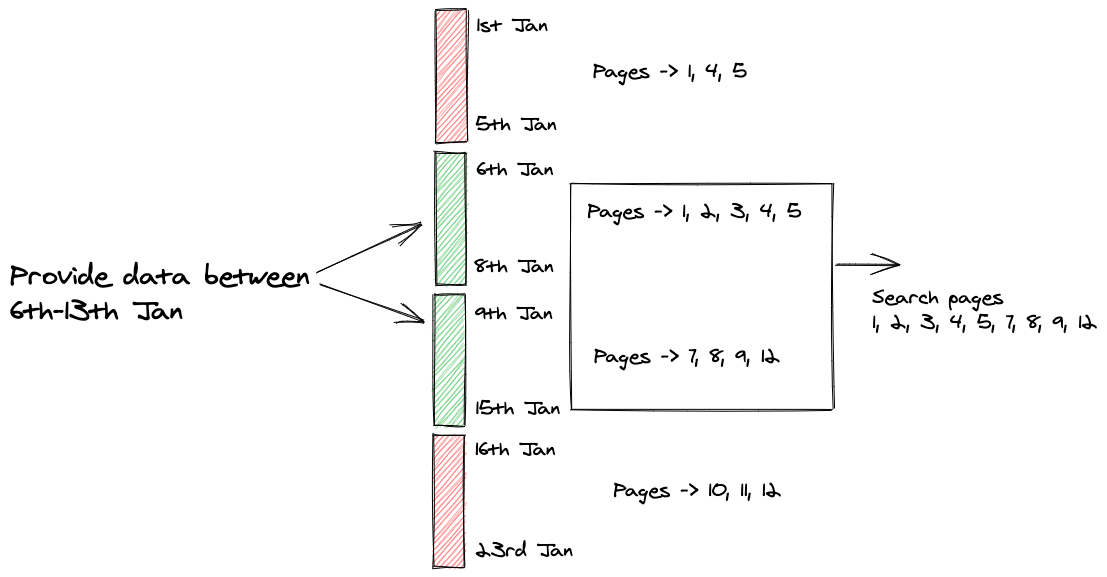
Brin Index
Search over BRIN index is like Index Search + Sequential Search
Text
They're preferred when there is a strong correlation between data being stored in disk and column values e.g. sequence number, timestamp, etc.
Brin Index
@Tarun_Garg2
Brin Index
Due to the way they're stored they occupy significantly lower space than usual indexes
With all this, we wanted to give BRIN indexing a try:-
CREATE INDEX idx_name ON population USING BRIN(dob)
Result...?
We had a takeaway here that BRIN succeeds when search target is narrow set of values
No Success

@Tarun_Garg2
But this exercise seeded the idea that the BRIN index is like a virtual partitioning where partitions are sequentially scanned

Partition 1
Partition 4

@Tarun_Garg2
Materialized views
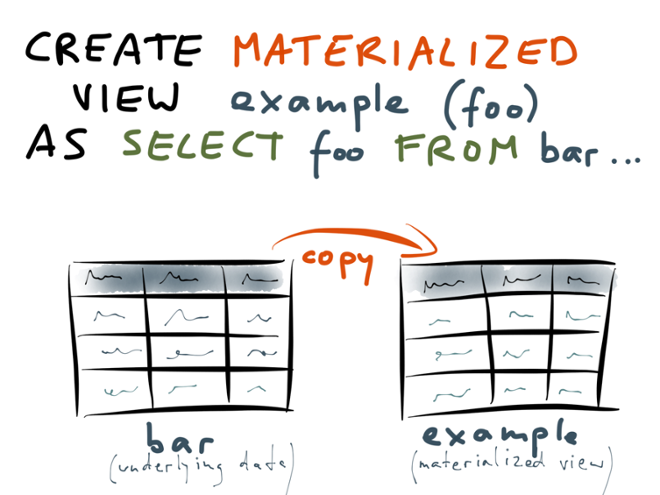
- Similar to Database views, but results are persisted in the table in the disk vs querying being routed on the main table always
- Since they are like tables, they can be indexed, etc
- Ideal for capturing frequently used joins and aggregations, etc
- In order to update materialized views with new data in the original table, you'll need to manually refresh the view, so they're not real-time
Materialized Views
@Tarun_Garg2
As with BRIN Indexing, this also seeded an idea that maybe if we can have smaller tables with indexes that would do it!
Partitioning FTW!
The main idea is that you take a massive table(parent) and split that into multiple smaller tables called partitions or child and this enables quick query execution by pruning un-necessary partitions and parallel processing
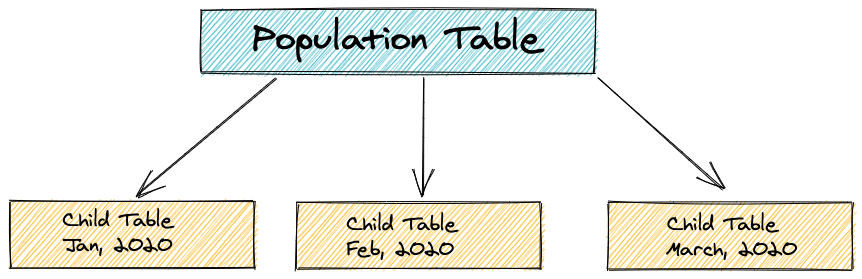
Inheritance Partition
CREATE TABLE child_table_january
INHERITS (parent_table)CHECK
(dob>='2020-01-01' and dob<='2020-01-31')1. Create child table inheriting parent table
2. Add non-overlapping checks for each child table
CREATE TRIGGER trigger_name BEFORE INSERT ON population
FOR EACH ROW EXECUTE PROCEDURE
name_of_procedure();4. Add triggers to insert into desired partitions
CREATE INDEX idx_partition_1
ON child_table_january using btree(dob)3. Add indexes to key columns
Inheritance based Partitioning
We have to use rules and triggers in order to route an insert(and update) to the parent table to the appropriate child table 😑
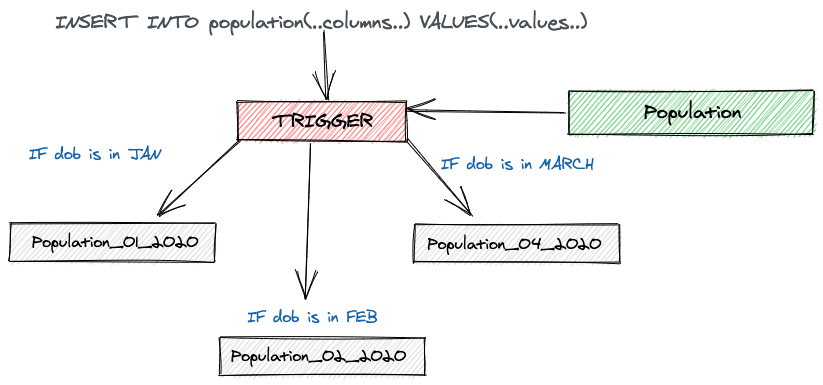
Inheritance based Partitioning
When querying the parent table, the query references all the rows from the parent as well as the child 😐
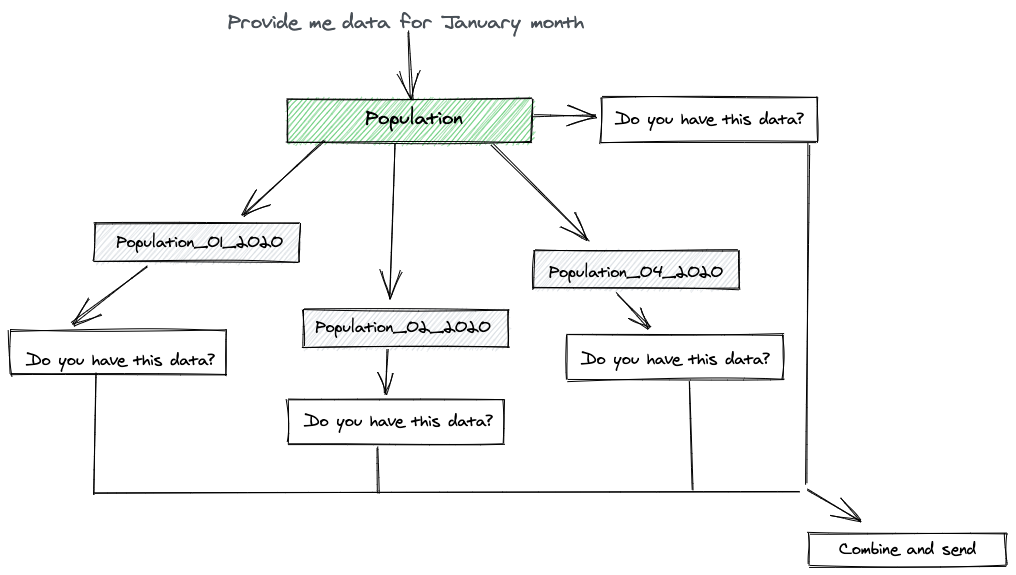
Inheritance based Partitioning
constraint_exclusion parameter needs to be enabled for query optimizations to work 😐
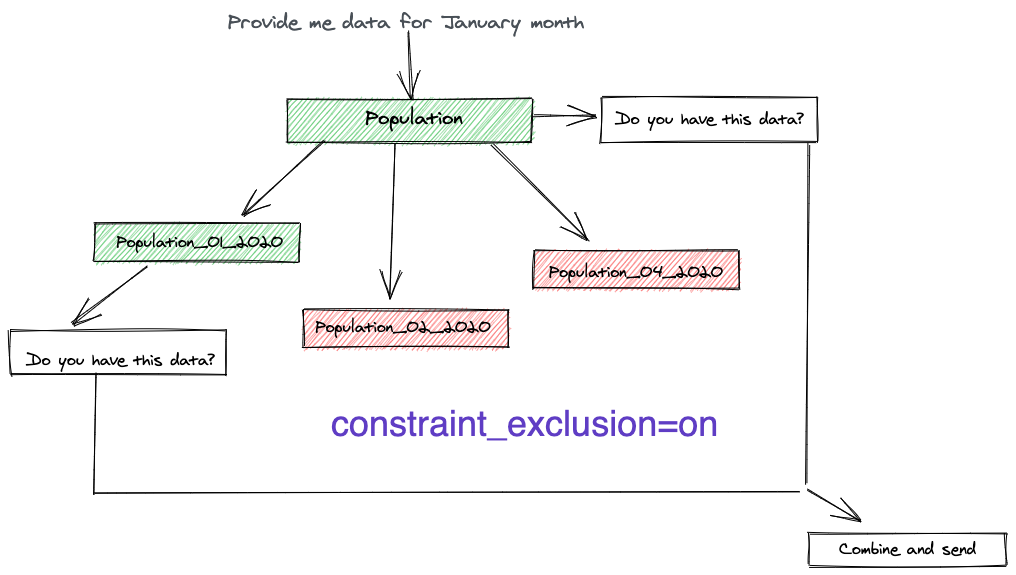
Inheritance based Partitioning
-
Child table can have more columns and indexes than parent table 😃
- Inheritance based partitioning was the only way before Postgres v10
- Index & constraints created on parent does not get automatically created on child
Declarative Partitioning
@Tarun_Garg2
CREATE TABLE partitioned_population (columns)
PARTITION BY <METHOD RANGE|LIST|HASH>
(key_column)CREATE TABLE child_partition_january
PARTITION OF partitioned_population
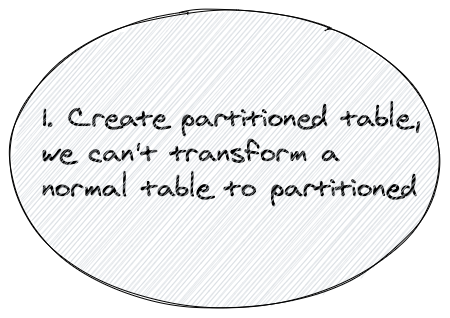
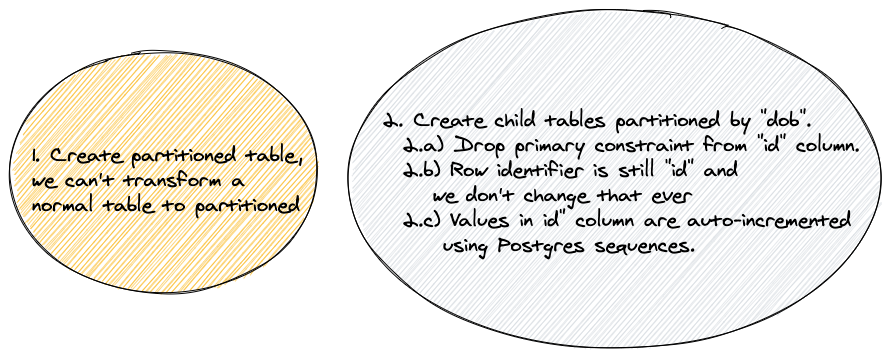
FOR VALUES FROM X TO Y1. Create parent partition table(you can't turn regular table into partitioned table)
2. Create child partitioned tables
Ways of doing partitioning in postgres
1. List Based Partitioning
CREATE TABLE population_partitioned(...)
PARTITION BY LIST(state_of_birth)Useful for cases when you have selected distinct values and you want to partition by those e.g. state_of_birth, payment_status, etc.
Ways of doing partitioning in postgres
Useful for cases when you distribute the rows by a range of values e.g. date of birth, day/month/year, etc.
2. Range Based Partitioning
CREATE TABLE population_partitioned(...)
PARTITION BY RANGE(dob)Ways of doing partitioning in postgres
Useful for cases when you want to distribute the rows based on hash value OR when you're not sure how many partitions I want to create so you just go by a number and use modulo to divide rows in those paritiong e.g. values for which modulo of something is 0,1,2 and so on.
3. Hash value Partitioning(in v11)
CREATE TABLE population_partitioned(...)
PARTITION BY HASH(user_id)Declarative based Partitioning
New inserts are automatically routed to partitioned tables basis partition key
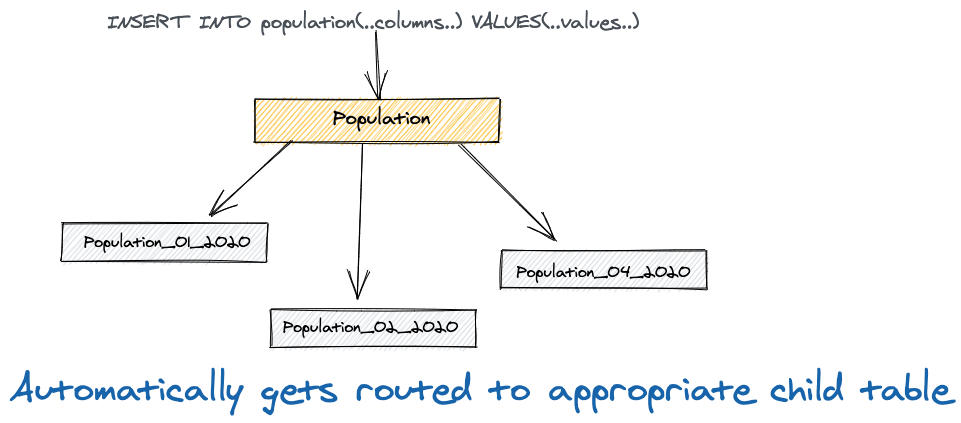
Declarative based Partitioning
Updates are also automatically routed to partitioned tables basis partition key(added in pg11)
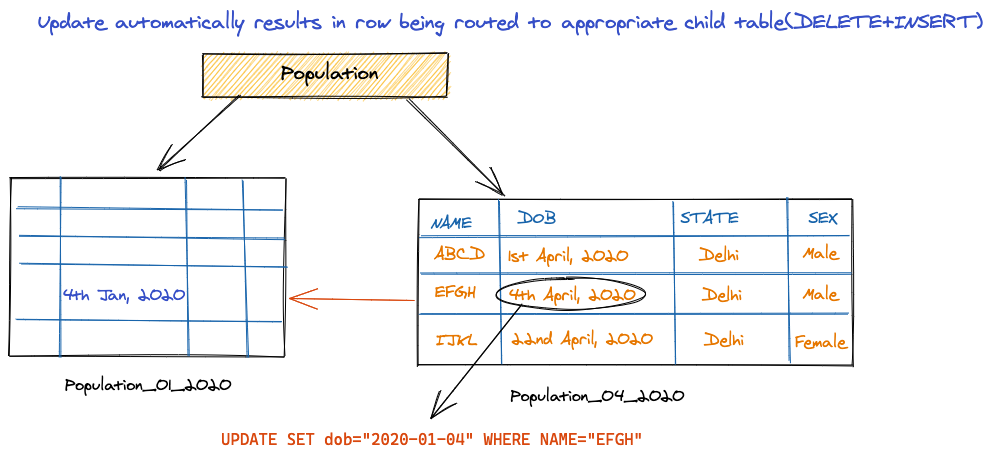
Declarative based Partitioning
There is a default partition to catch unrelated data that does not fall under defined partition buckets(added in pg11)
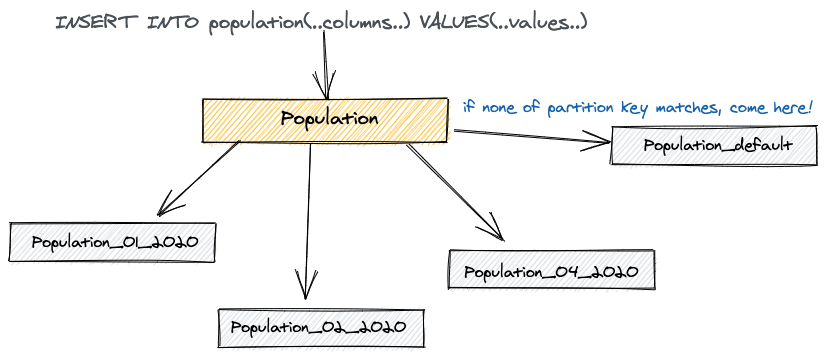
Declarative based Partitioning
Improved query support, in this case parent does not contain any data and partition exclusion is done on run time(vs constrained exclusion)
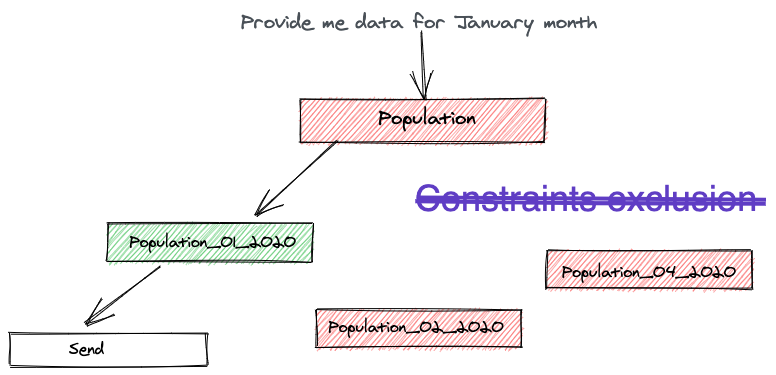
Declarative based Partitioning
Index created on parent gets automatically routed to child table
(added in pg11)
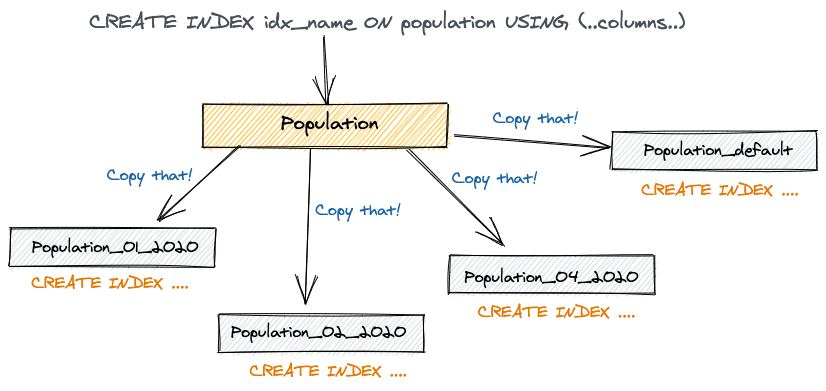
Declarative based Partitioning
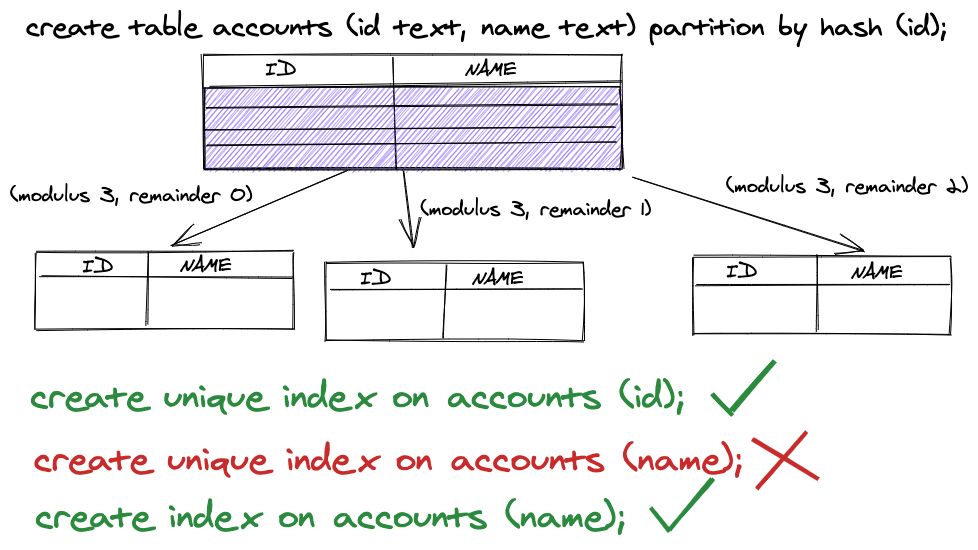
You're allowed to have a primary key and unique keys in parent table provided they're part of partition keys also :)
Declarative based Partitioning
-
Partitions are not allowed to have their own columns 😑
-
Support for the foreign key is very limited, you can add any foreign key to parent it'll automatically get routed to the child(outgoing) but the same is not true when the parent gets referenced.
-
Unique constraints are enforced on per partition level vs global level
- Major improvements are coming in Postgres 12 wrt declarative partitioning so watch out 👀(performance+data integrity-related)
-- works, and this foreign key gets added to all partitions
alter table population add foreign key (branch_id) references branches (id);
-- doesn't work, yet!
create table sensus (aid text references population, delta int);Declarative based Partitioning
With all this knowledge and things, we implemented declarative based parititioning
Declarative based Partitioning
Declarative based Partitioning

Result...?
A big sequence scans got split into multiple small-small index scans that are happening parallelly and by themselves

Append (cost=0.56..1164264.69 rows=25154 width=1180) (actual time=1046.912..1669.778 rows=25487 loops=1)
-> Index Scan using paritition_9_2019_idx on population_9_2019 (cost=0.56..260693.47 rows=181 width=1016) (actual time=465.840..465.840 rows=0 loops=1)
Index Cond: ((dob >= '2019-09-01 00:00:00+00'::timestamp with time zone) AND (dob <= '2020-02-01 00:00:00+00'::timestamp with time zone) AND (state = 'Karnataka'::text))
-> Index Scan using paritition_10_2019_idx on partition_10_2019 (cost=0.56..236484.18 rows=157 width=1050) (actual time=412.491..412.491 rows=0 loops=1)
Index Cond: ((dob >= '2019-09-01 00:00:00+00'::timestamp with time zone) AND (dob <= '2020-02-01 00:00:00+00'::timestamp with time zone) AND (state_of_birth = 'Karnataka'::text))
-> Index Scan using partition_11_2019 on partition_11_2019 (cost=0.56..205569.95 rows=123 width=1215) (actual time=168.577..229.683 rows=24 loops=1)
Index Cond: ((dob >= '2019-09-01 00:00:00+00'::timestamp with time zone) AND (dob <= '2020-02-01 00:00:00+00'::timestamp with time zone) AND (state_of_birth = 'Karnataka'::text))
-> Index Scan using partition_12_2019 on partition_12_2019 (cost=0.56..213123.07 rows=3179 width=1211) (actual time=6.936..253.228 rows=5294 loops=1)
Index Cond: ((dob >= '2019-09-01 00:00:00+00'::timestamp with time zone) AND (dob <= '2020-02-01 00:00:00+00'::timestamp with time zone) AND (state_of_birth = 'Karnataka'::text))
-> Index Scan using partition_1_2020 on partition_1_2020 (cost=0.56..248259.67 rows=21513 width=1176) (actual time=0.027..298.852 rows=20169 loops=1)
Index Cond: ((dob >= '2019-09-01 00:00:00+00'::timestamp with time zone) AND (dob <= '2020-02-01 00:00:00+00'::timestamp with time zone) AND (state_of_birth = 'Karnataka'::text))
-> Index Scan using partition_2_2020 on partition_2_2020 (cost=0.55..8.57 rows=1 width=1197) (actual time=0.013..0.013 rows=0 loops=1)
Index Cond: ((dob >= '2019-09-01 00:00:00+00'::timestamp with time zone) AND (dob <= '2020-02-01 00:00:00+00'::timestamp with time zone) AND (state_of_birth = 'Karnataka'::text))
Planning Time: 1.315 ms
Execution Time: 1674.708 msWord of caution
- B-Tree Indexing is still great, long live index. You should look for alternatives only when you're fetching a large number of tuples from DB.
- Indexing comes in various forms be it partial index, composite indexing, full-text indexing, etc. and more often than not any combination of indexing technique coupled with the change in application logic and caching should suffice
- We used RDS to test out everything, so we did not have the luxury to install many extensions like pg_bench or pg_partman to unleash advanced feature sets
- All other things being presented in this talks are our personal experiences, observations, and readings they might not fit true for your scenario so always test everything being said
Open to feedback or any questions!
@Tarun_Garg2
PS:- We're also hiring, send out your resumes at build@squadvoice.co