HANDLING DJANGO IN A HIGHLY CONCURRENT & SCALE ENVIRONMENT
@Tarun_Garg2
What is this talk about 🤷🏽♀️



Theme #1
Django Admin Pagination
Django Admin Pagination

Django Admin
Django Admin Pagination
# {project}/orders/models.py
from django.db import models
class Order(models.Model):
order_reference_id = models.CharField(max_length=50)
# {project}/users/admin.py
from django.contrib import admin
from .models import Order
admin.site.register(Order)

Django Admin Pagination

Django Admin Pagination
-- Count the total number of records - 2.43 seconds
SELECT COUNT(*) AS "__count"
FROM "orders_order"
-- Get first page of orders - 2ms
SELECT "orders_order"."id",
"orders_order"."reference_id"
FROM "orders_order"
ORDER BY "orders_order"."id" DESC
LIMIT 100# django/core/paginator.py
@cached_property
def count(self):
try:
return self.object_list.count()
except (AttributeError, TypeError):
return len(self.object_list)Django Admin Pagination
# common/paginator.py
from django.core.paginator import Paginator
class DumbPaginator(Paginator):
"""
Paginator that does not count the rows
in the table.
"""
@cached_property
def count(self):
return 9999999999

Attempt #1 - Dumb paginator
Django Admin Pagination
-- Get first page of orders - 2ms
SELECT "orders_order"."id",
"orders_order"."reference_id"
FROM "orders_order"
ORDER BY "orders_order"."id" DESC
LIMIT 100Pros
Cons
• No more count queries & hence
blazing fast admin.
• UX is kinda compromised because if even we have <1m rows it will show all the pages.
• Dumb & fast to implement.
• Dumb & we should be able to do better.
Django Admin Pagination
Attempt #2 - Best effort basis
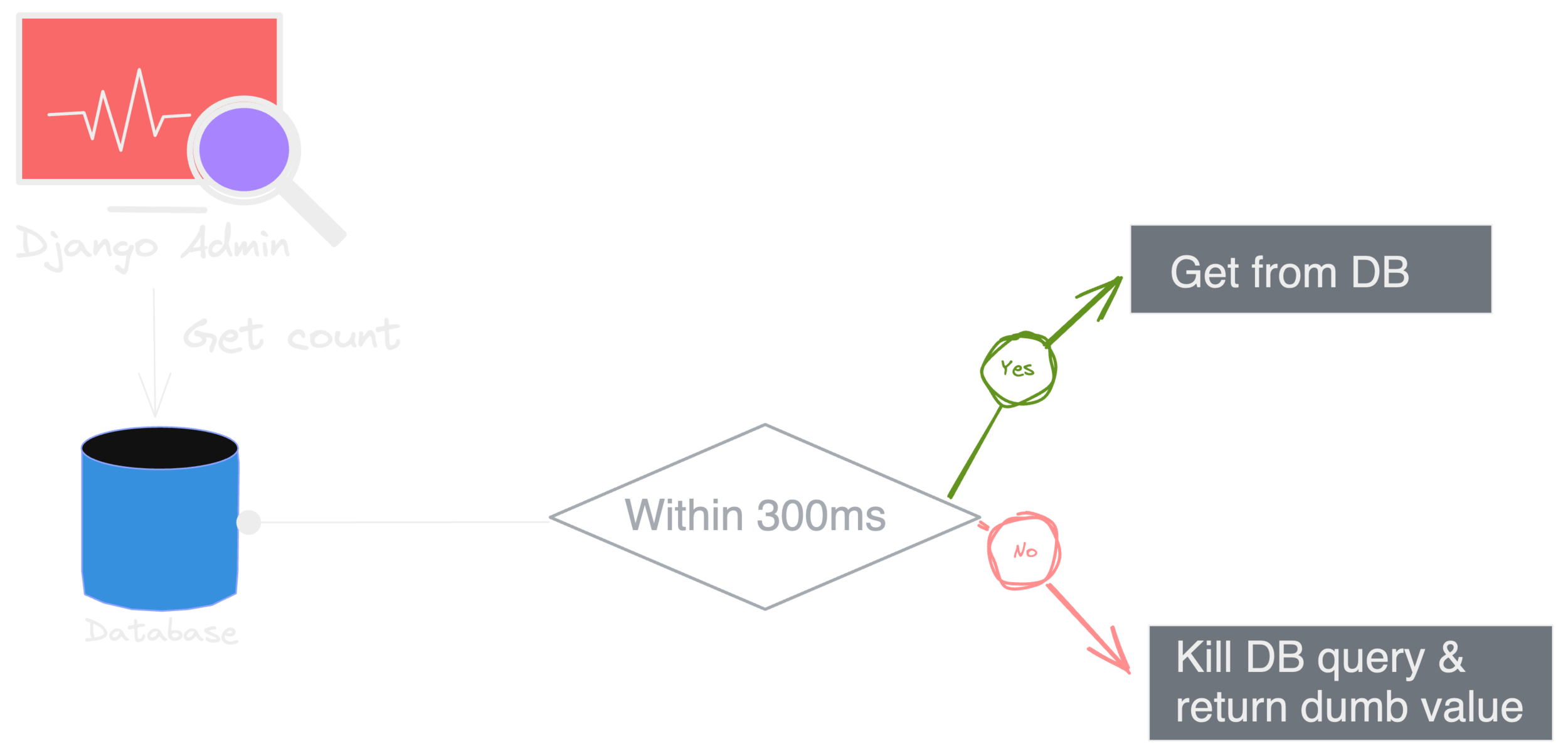
Django Admin Pagination
@cached_property
def count(self):
"""
Paginator that enforces a timeout on the count operation.
If the operations times out, a dummy value is returned
"""
with transaction.atomic(), connection.cursor() as cursor:
# Prevent statement_timeout from affecting other trxn
cursor.execute('SET LOCAL statement_timeout TO 300;')
try:
return super().count
except OperationalError:
return 99999999
Attempt #2 - Best effort basis
This is much better but the worst case time will still be ~300 ms & we've not removed dumbness entirely.
Django Admin Pagination
Attempt #3 - Best effort with approximation
* Postgres only
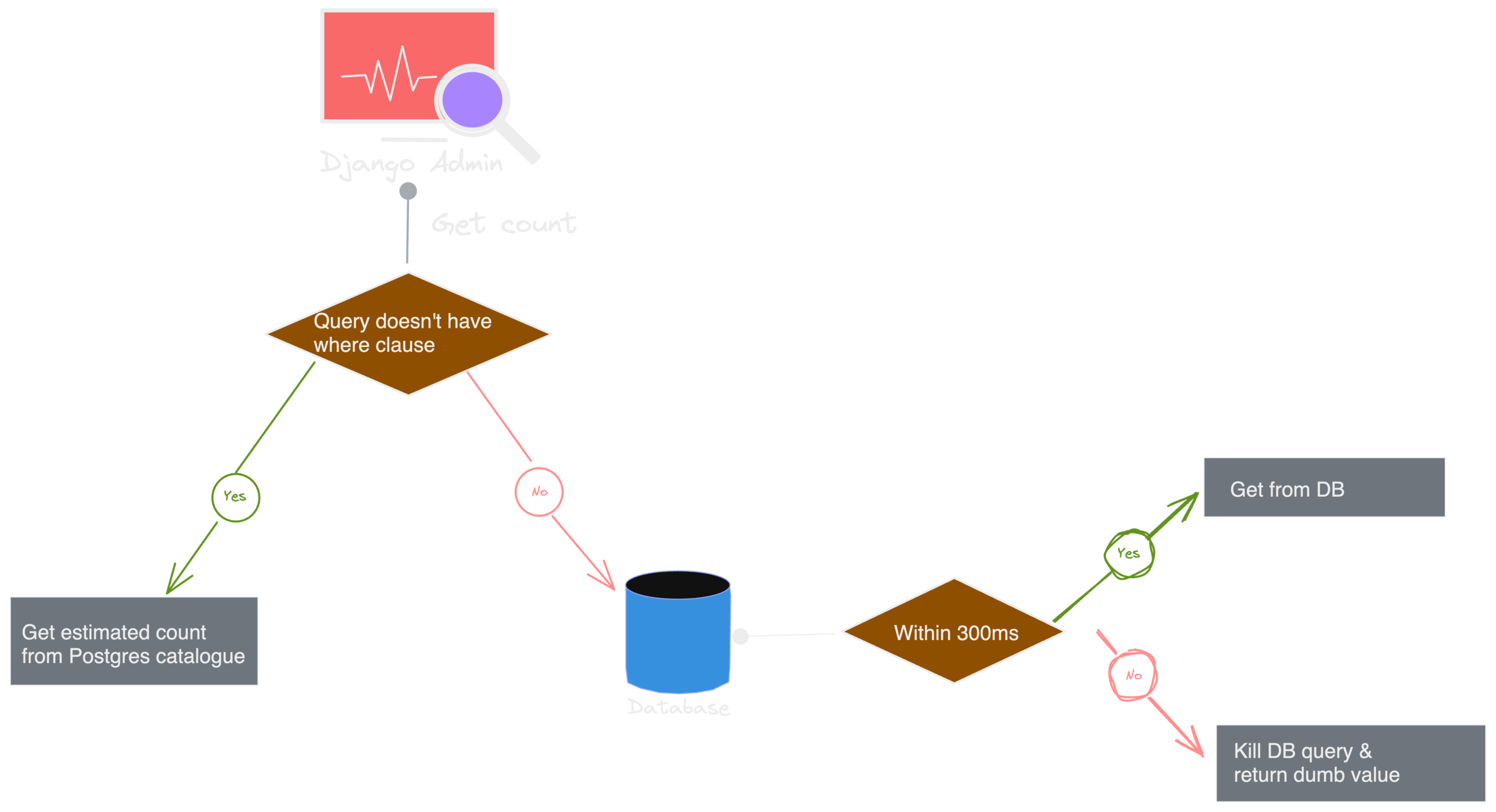
Django Admin Pagination
Attempt #3 - Best effort with approximation
* Postgres only
@cached_property
def count(self):
query = self.object_list.query
if not query.where and not is_env_local():
cursor = connection.cursor()
cursor.execute(
"SELECT reltuples FROM pg_class WHERE relname = %s",
[query.model._meta.db_table],
)
return int(cursor.fetchone()[0])
with transaction.atomic(), connection.cursor() as cursor:
# Prevent statement_timeout from affecting other trxn
cursor.execute('SET LOCAL statement_timeout TO 300;')
try:
return super().count
except OperationalError:
return 99999999Django Admin Pagination
Attempt #3 - Best effort with approximation
-- Get from pg catalogue - 2ms
SELECT reltuples FROM pg_class WHERE relname = "orders_order"
-- Get first page of orders - 2ms
SELECT "orders_order"."id",
"orders_order"."reference_id"
FROM "orders_order"
ORDER BY "orders_order"."id" DESC
LIMIT 100Pros
Cons
• Good tradeoff between accuracy & latency.
• Does not work when we have filters applied(where clause).
• Might not be suitable for a) smaller tables & b) where analyse is run with lesser frequency.
• The probability of reaching to dumb value is reduced.
• Still dumb value problem.
Django Admin Pagination
Attempt #4 - Solving for 'where' clause from #3 * Postgres only
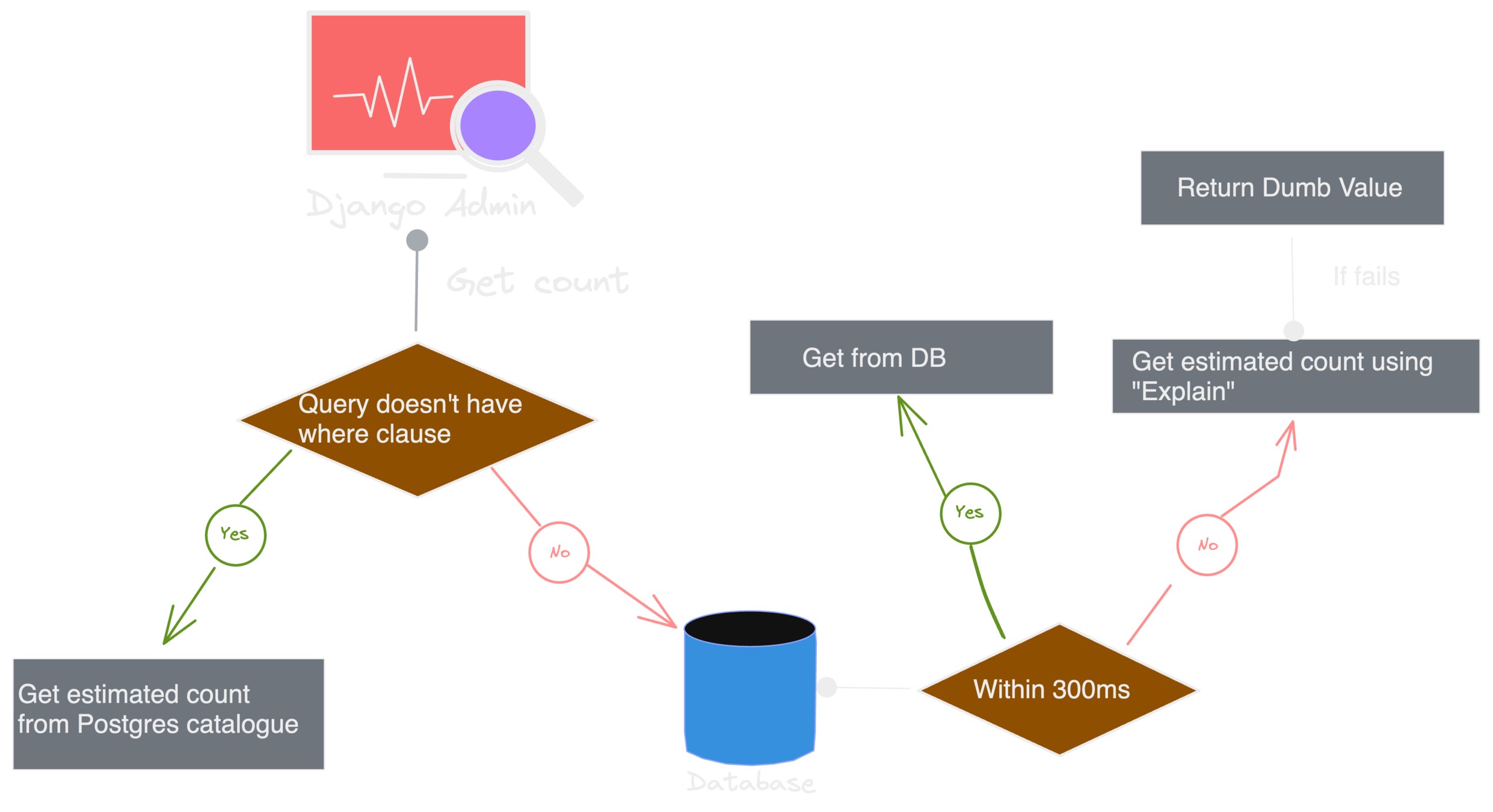
Django Admin Pagination
Attempt #4 - Solving for 'where' clause from #3 * Postgres only
@cached_property
def count(self):
query = self.object_list.query
if not query.where and not is_env_local():
cursor = connection.cursor()
cursor.execute(
"SELECT reltuples FROM pg_class WHERE relname = %s",
[query.model._meta.db_table],
)
return int(cursor.fetchone()[0])
with transaction.atomic(), connection.cursor() as cursor:
# Prevent statement_timeout from affecting other trxn
cursor.execute('SET LOCAL statement_timeout TO 300;')
try:
return super().count
except OperationalError:
try:
with connection.cursor() as cursor:
cursor.execute("EXPLAIN(FORMAT JSON) {}".format(query))
return cursor.fetchone()[0][0]["Plan"]["Plan Rows"]
except Exception:
return 99999999Django Admin Pagination
Attempt #4 - Solving for 'where' clause from #3 * Postgres only
-- Get from pg catalogue -- OR run some approximation queries..
-- Get first page of orders - 2ms
SELECT "orders_order"."id",
"orders_order"."reference_id"
FROM "orders_order"
ORDER BY "orders_order"."id" DESC
LIMIT 100Pros
Cons
• Better tradeoff between accuracy & latency.
• Might not be suitable for tables where analyze is run with lesser frequency.
• The probability of reaching to dumb value is reduced the most.
• Getting count of rows using "Explain" is probabilistic & depends upon MCV list in pg.
Django Admin Pagination
Attempt #n







Theme #2
Django Admin Text Search
Story Time
Django Admin Text Search


Story Time
Django Admin Text Search
class OrderAdmin(model.Admin):
search_fields = (
"reference_id",
)

Story Time
Django Admin Text Search
class OrderAdmin(model.Admin):
search_fields = (
"reference_id", "user__username"
)

Story Time
Django Admin Text Search
class OrderAdmin(model.Admin):
search_fields = (
"reference_id", "user__username", "user__first_name", "user__last_name"
)

Story Time
Django Admin Text Search
class OrderAdmin(model.Admin):
search_fields = (
"reference_id", "user__username", "user__first_name", "user__last_name",
"paymenr__reference_id"
)
Django Admin Text Search


Select * from orders_order WHERE
UPPER(reference_id::text) LIKE UPPER(<search_term>)
OR UPPER(payment.reference_id::text) LIKE UPPER(<search_term>)
OR UPPER(user.email::text) LIKE UPPER(<search_term>)
...and so onDjango Admin Text Search
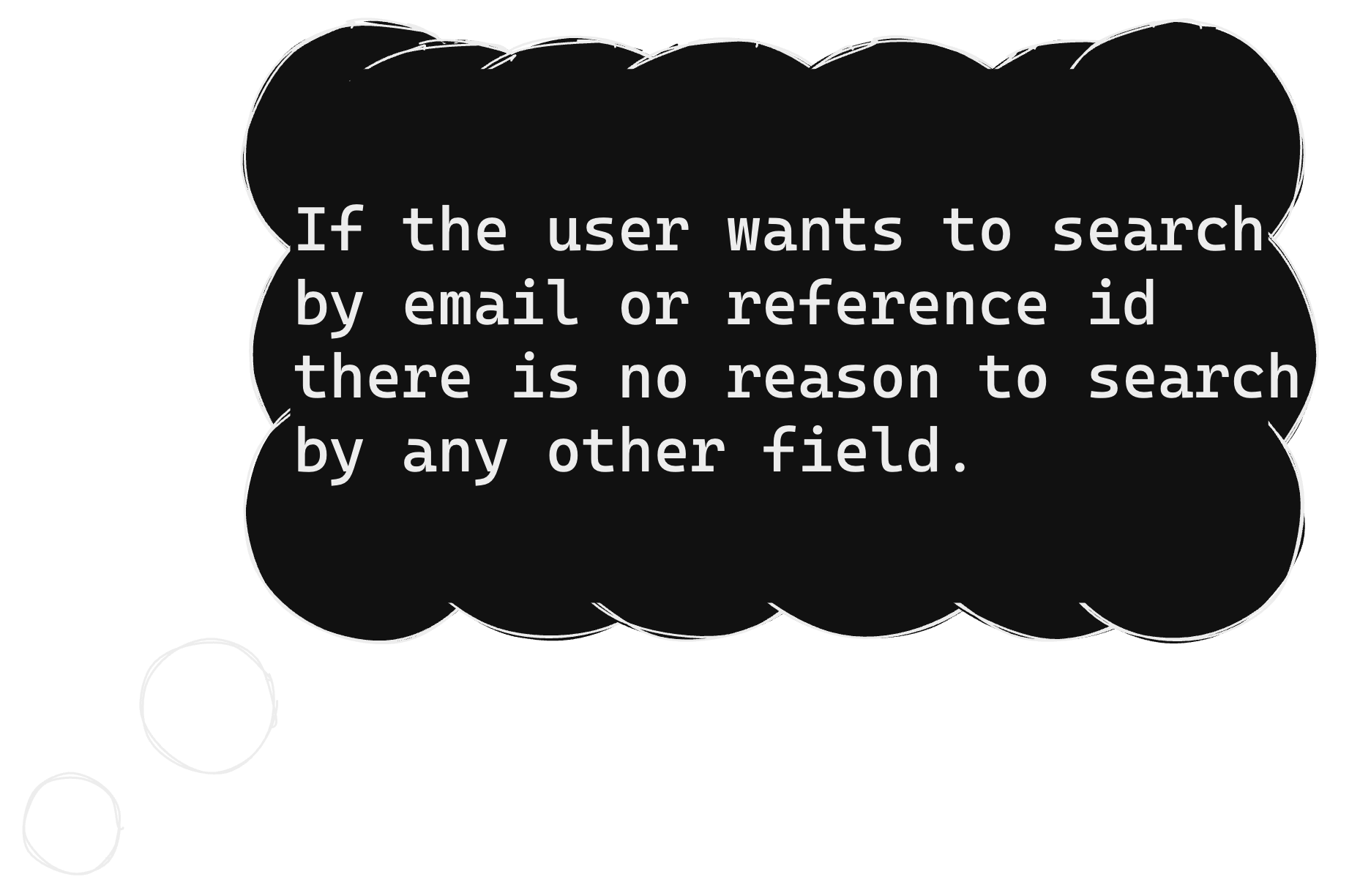

Django Admin Text Search

Django Admin Text Search
class ReferenceIDFilter(InputFilter):
parameter_name = 'reference_id'
title = _('Order Reference ID')
def queryset(self, request, queryset):
if self.value() is not None:
uid = self.value()
return queryset.filter(reference_id__icontains=uid)
Theme #3
Caching Django Models 👀
Caching Django Models 👀
Cache SET - cache.set(key, django_model_object)

Cache GET - cache.get(key)

Caching Django Models 👀
class Order(models.Model):
reference_id = models.CharField(max_length=15)
cache.set(f"Order:{given_pk}", Order.objects.get(pk=given_pk))cache.get(f"Order:{given_pk}")
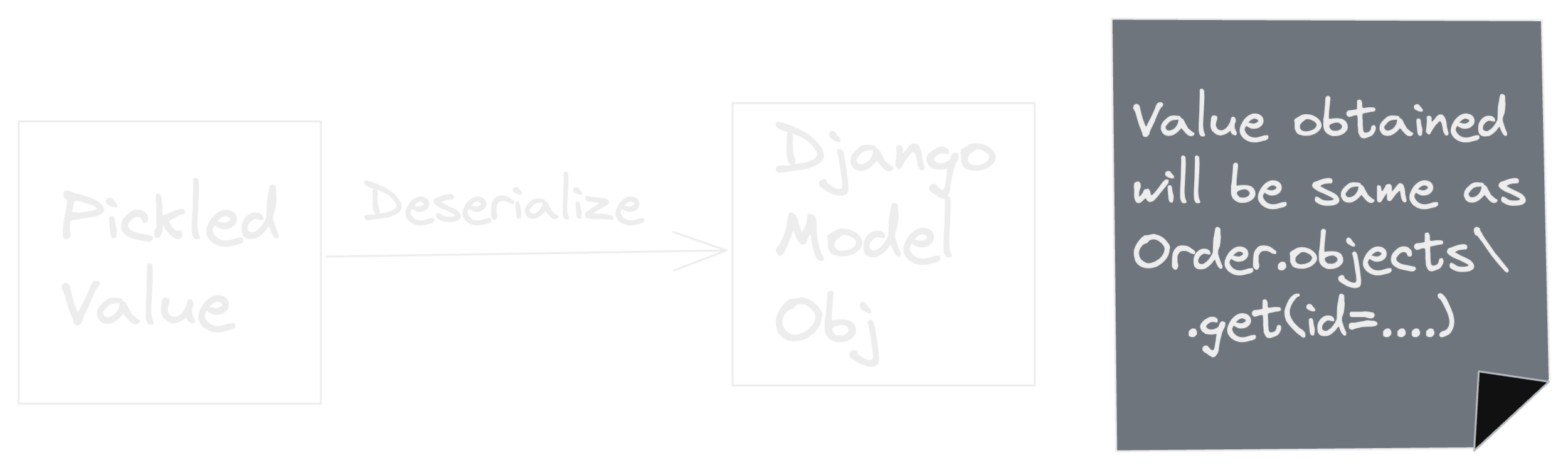

Caching Django Models 👀
class Order(models.Model):
reference_id = models.CharField(max_length=15)
order_amount = models.IntegerField()cache.get(f"Order:{given_pk}")
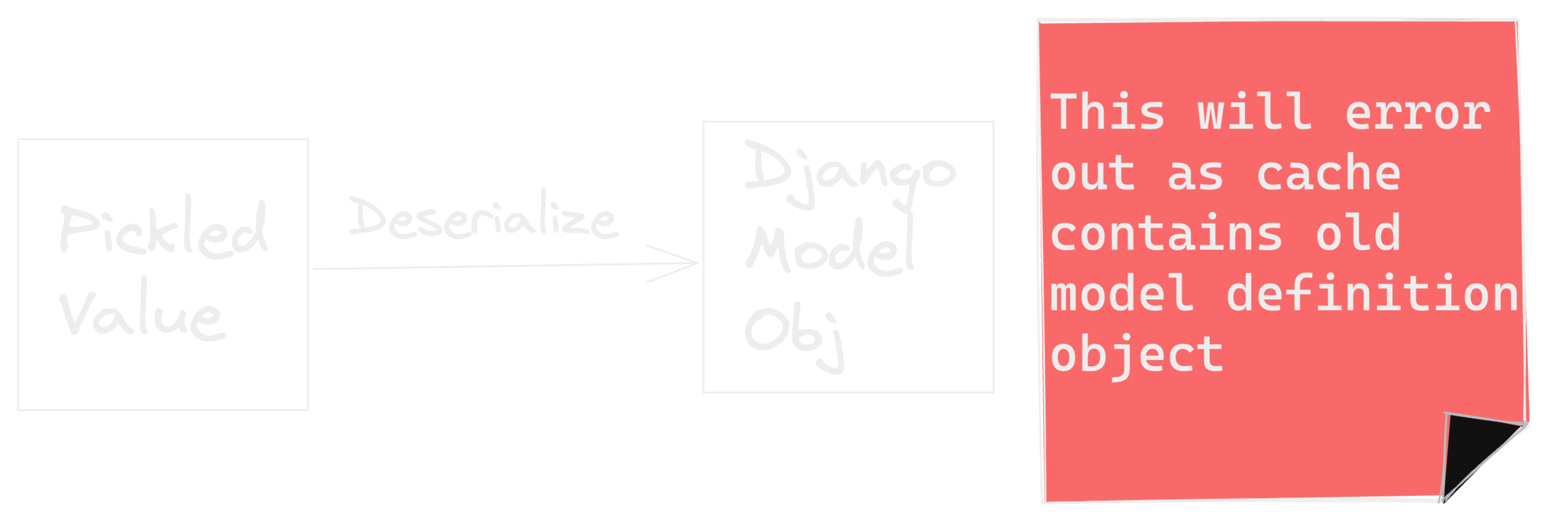

Caching Django Models 👀

Set low enough TTL for cache keys

Delete all keys for changed model
Change key structure whenever model definition is updated

Caching Django Models 👀
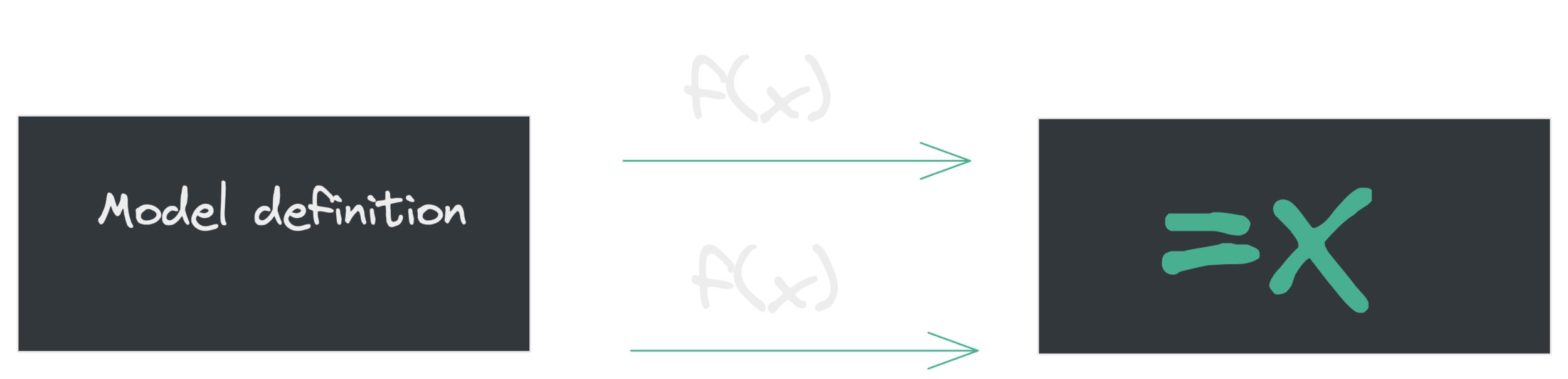


Caching Django Models 👀
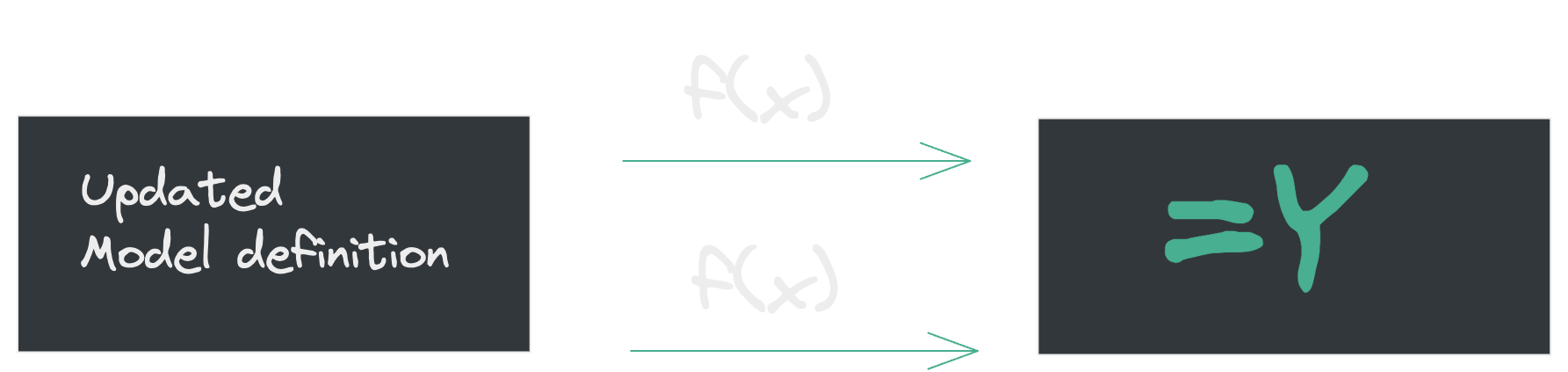

Theme #4
Case of .save() in Django 👀
Case of .save() in Django 👀
How does .save() work?
class Record(models.Model):
# id will be created automatically
name = models.CharField(max_length=255)
created_at = models.DateTimeField(auto_now_add=True)
is_deleted = models.BooleanField(default=False)
>>> record = Record.objects.get(id=1)
>>> record.name = "new record name"
>>> record.save()UPDATE "record"
SET "name" = 'new record name',
"created_at" = NOW(),
"is_deleted" = FALSE
WHERE "id" = 1
Case of .save() in Django 👀
In the case of 2 different updates done concurrently on the same object, the last write wins.
Case of .save() in Django 👀
Take lock on DB row when updating
Take distributed lock using Redis
Django update_fields to rescue
Case of .save() in Django 👀
>>> record = Record.objects.get(id=1)
>>> record.name = "new record name"
>>> record.save(update_fields=["name"])UPDATE "record"
SET "name" = 'new record name'
WHERE "id" = 1
Case of .save() in Django 👀
• The other 2 solutions also have their place but those are not the "best" for our problem.
• There are 3rd party libraries to do the job
automatically for you.
• You can create linters to check if the usage of .save() has update_fields in it.
Special Mentions
- My colleagues & ex-colleagues at SquadStack
-
CitusData blog post around "Faster PostgreSQL Counting"
-
Haki Benita's blog posts about Django & Django Admin optimizations
-
Doordash blog posts about Django scaling issue
-
Excalidraw for all the beautiful graphics
- Django community & volunteers
🙏🏻 Open to
feedback or questions!

@Tarun_Garg2

tarungarg546