Tense
"A man who dares to waste one hour of time has not discovered the value of life."
Charles Darwin
Virtual-Time Execution
Tense
Virtual-Time Execution
Develop software with performance in mind and identify optimisation opportunities with the highest impact.
void execute_query() {
// todo
}
// your growing code-base
void main() {
parse_request();
prepare_query();
lock();
execute_query();
unlock();
prepare_response();
send_response();
}Timing models of missing functionality can drive virtual time
int tense_move(const struct timespec * delta);
int tense_move_ns(unsigned long long delta_ns);
// todo: new cache policy will make this 50% faster
void execute_query() {
...
}
// your large codebase
void main() {
parse_request();
prepare_query();
lock();
execute_query();
unlock();
prepare_response();
send_response();
}Time-scaling affects functional behaviour
int tense_scale_percent(int percent);
int tense_scale_clear(void);The completion of off-CPU tasks respects the passage of virtual time
int tense_sleep(const struct timespec * sleep);
int tense_sleep_ns(unsigned long long sleep_ns);And, of course, you can check the time
int tense_time(struct timespec * now);What makes this hard?
Time-scaling is dynamic
Interesting applications run more than two threads on more than two cores
Tense architecture
Dynamic linking tricks
libtense
tense file in debugfs
tense.ko
Patches to the Linux kernel
Multitasking 101
Multitasking is the ability to execute a task without waiting for the current one to finish
Multitasking 101 (in Linux)
Processes are tasks. Threads are tasks, too.
Tasks are the leaves of a hierarchy of scheduling queues.
The hierarchy is weighted based on process priorities or group CPU shares.
Execution time from the tasks is summed up the hierarchy.
TLDR: A bit more complex than round-robin.
Multitasking 101 (in Linux)
The real execution time is in fact scaled by the weight of the entity it belongs to. This value is called "virtual runtime".
The next task to run is picked by traversing the hierarchy of scheduling entities and choosing the one with the lowest virtual runtime at each level.
There is a separate hierarchy for each CPU.
Tasks can migrate between hierarchies.
TLDR: A lot more complex than round-robin.
Multitasking 101 (in Linux)
Completely Fair Scheduler
gcc
gcc
gcc
Multitasking 101 (in Linux)
Threads are tasks, too
gcc
gcc
gcc
inbox
editor
send
Multitasking 101 (in Linux)
Virtual runtimes
gcc (15)
gcc (14)
gcc (9)
mail (8)
inbox (5)
editor (3)
send (0)
\[\Sigma \tau_i\]
next task to run
Multitasking 101 (in Linux)
Virtual runtimes
gcc (15)
gcc (14)
gcc (9)
mail (10)
inbox (5)
editor (3)
send (2)
\[\Sigma \tau_i\]
next task to run
Multitasking 101 (in Linux)
Scheduling entities
gcc (15)
gcc (14)
gcc (9)
mail (10)
inbox (5)
editor (3)
send (2)
\[\Sigma \tau_i\]
tencho (38)
tony (10)
\[\Sigma \tau_i\]
\[\Sigma \tau_i\]
Multitasking 101 (in Linux)
Weights (nice levels)
gcc (15)
gcc (14)
gcc (9)
mail (10)
inbox (5)
editor (3)
send (2)
\[w_{mail}^{-1}\Sigma \tau_i\]
tencho (3)
tony (10)
\[w_{tencho}^{-1}\Sigma \tau_i\]
\[w_{tony}^{-1} \Sigma \tau_i\]
Approaches to time dilation
Priority (above) vs. Virtual runtime (below)
Approaches to time dilation
Priority (above) vs. Virtual runtime (below)


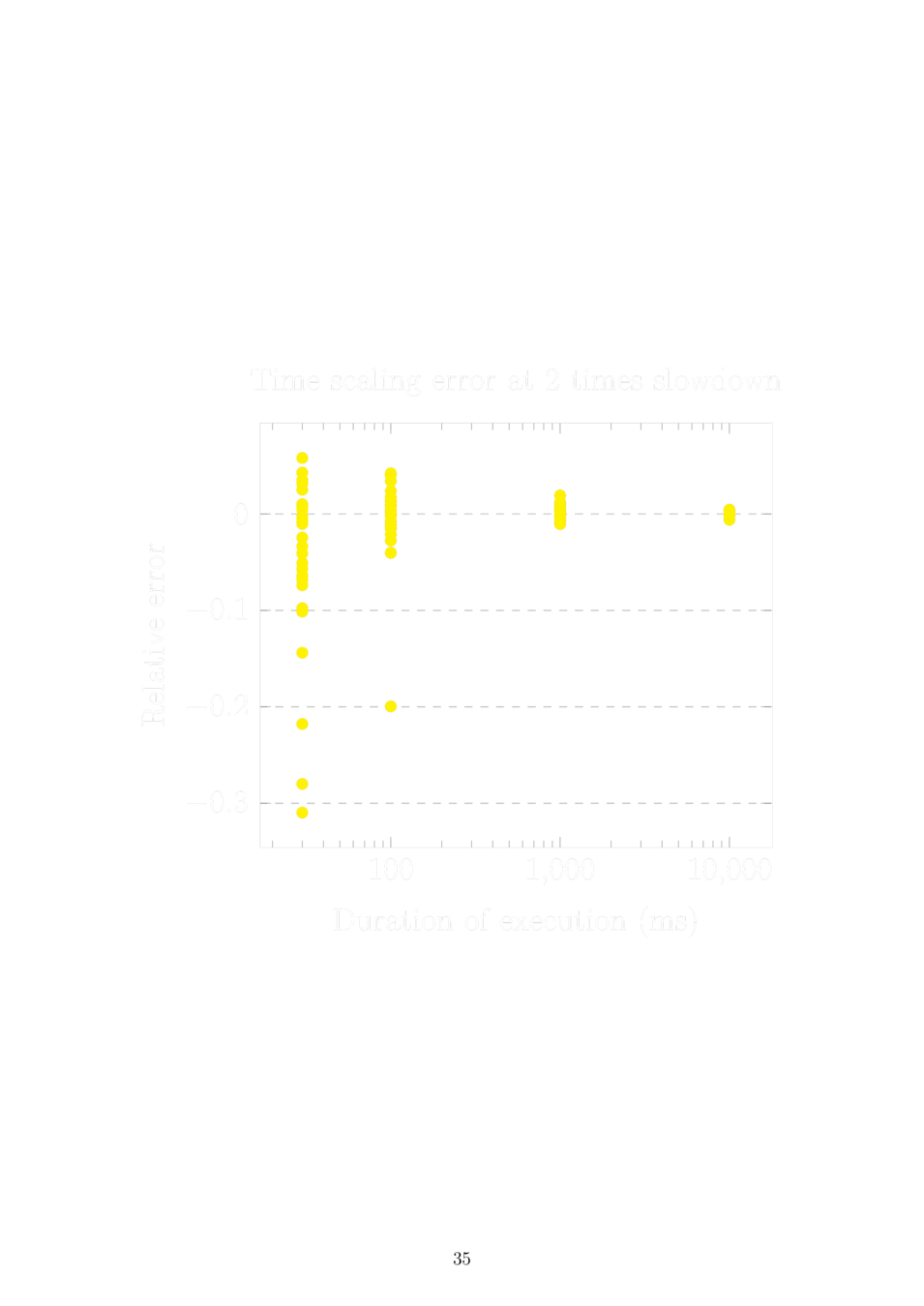
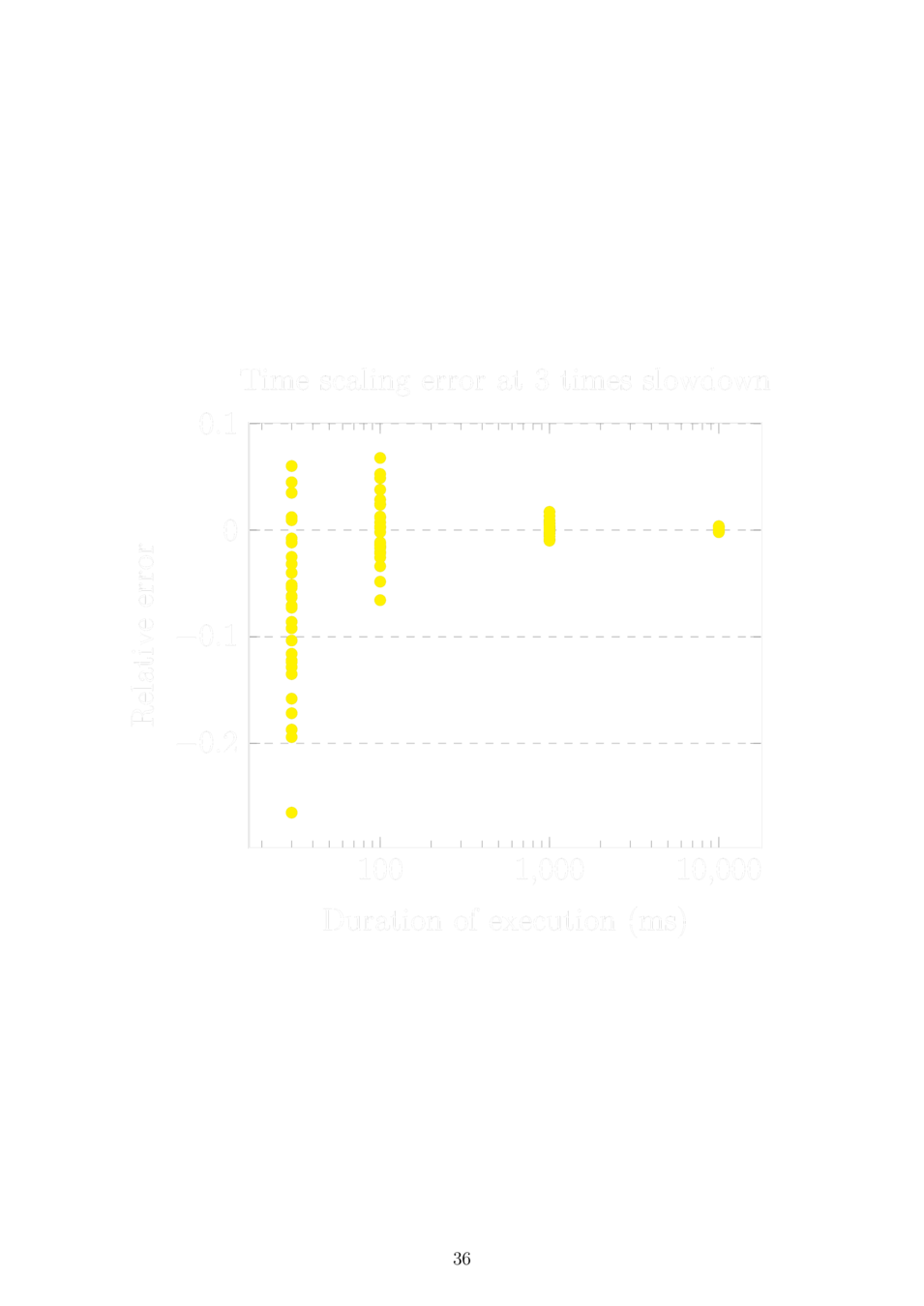
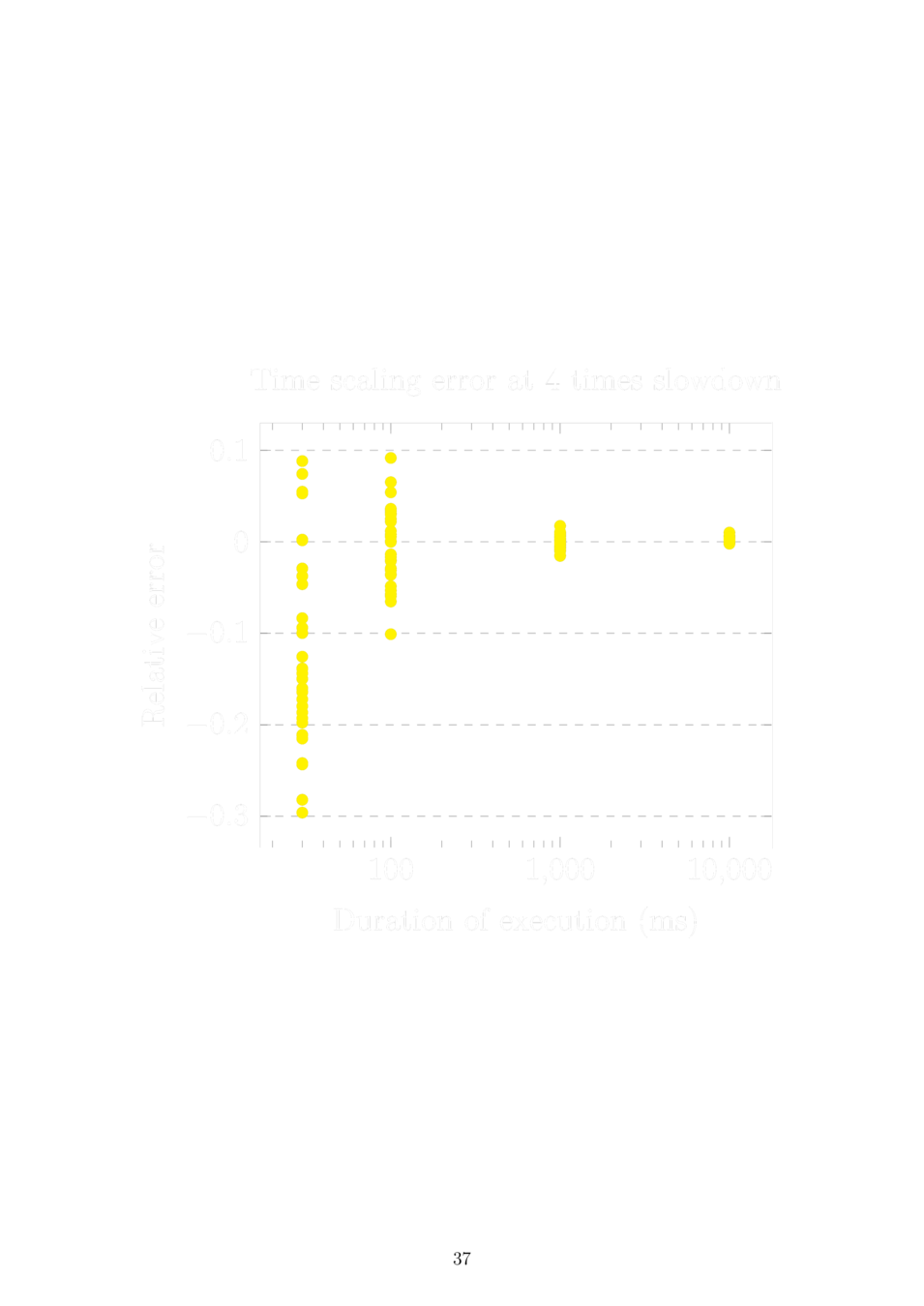
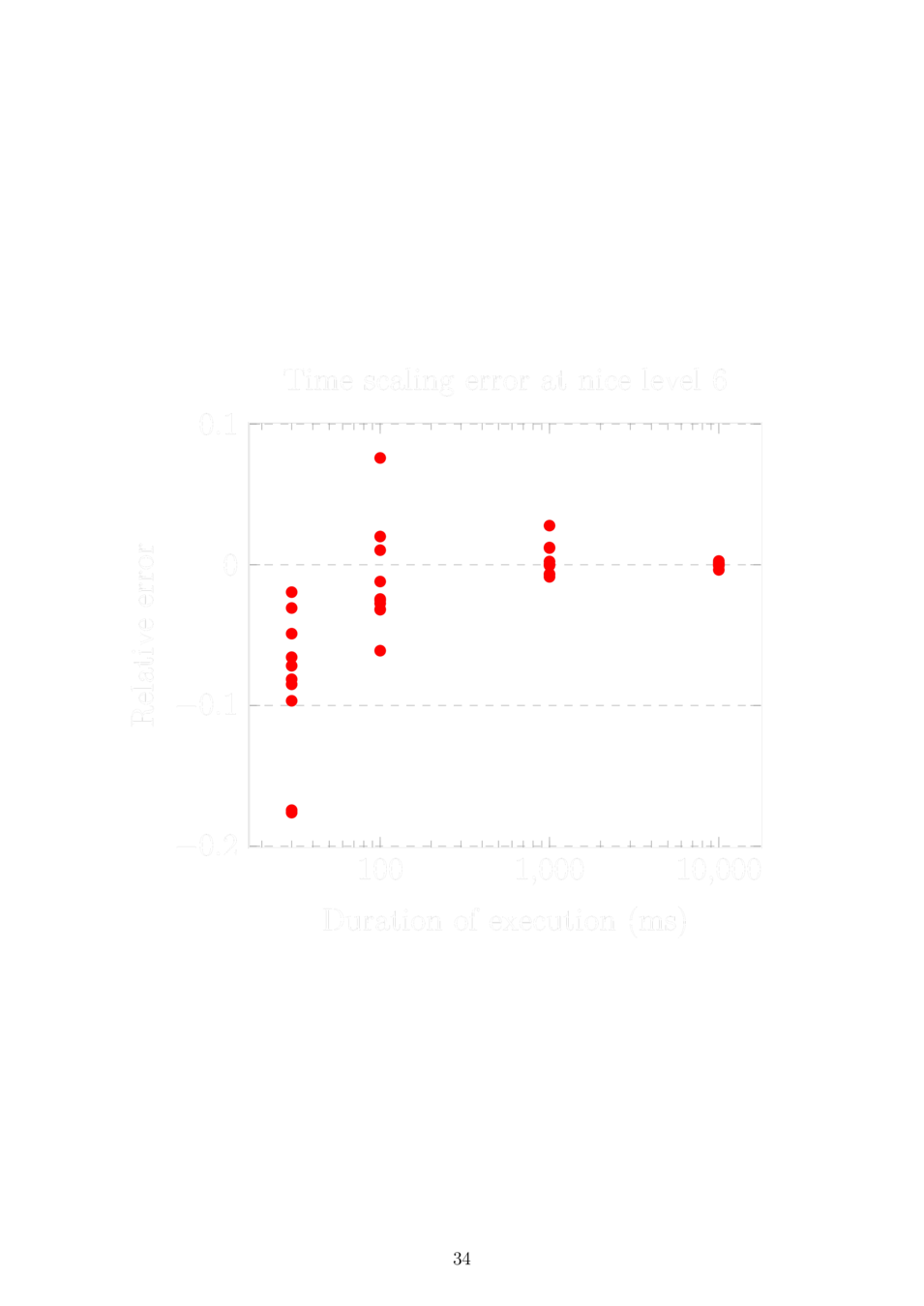
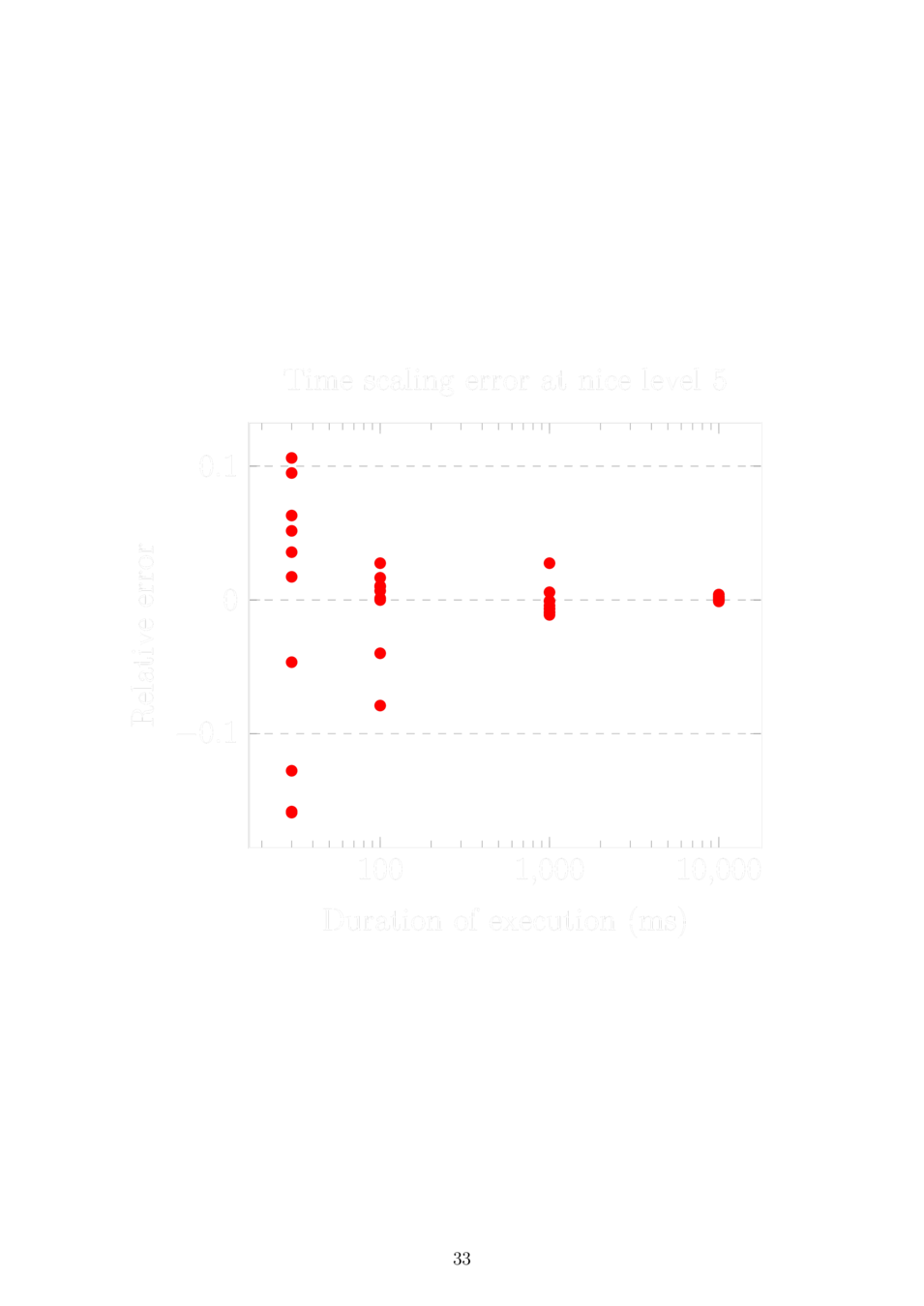
Sleeping in virtual time
Static time dilation and two processes:
The problem is solved by scaling the sleep duration by the time dilation of the other process before setting the wake-up timer.
Dynamic time dilation and N processes:
Sleep until now < wake-up time < now + virtual tick, then set a timer as above assuming the next process to run is the only other process and it won't change its time dilation. If the assumption is violated, restart the timer.
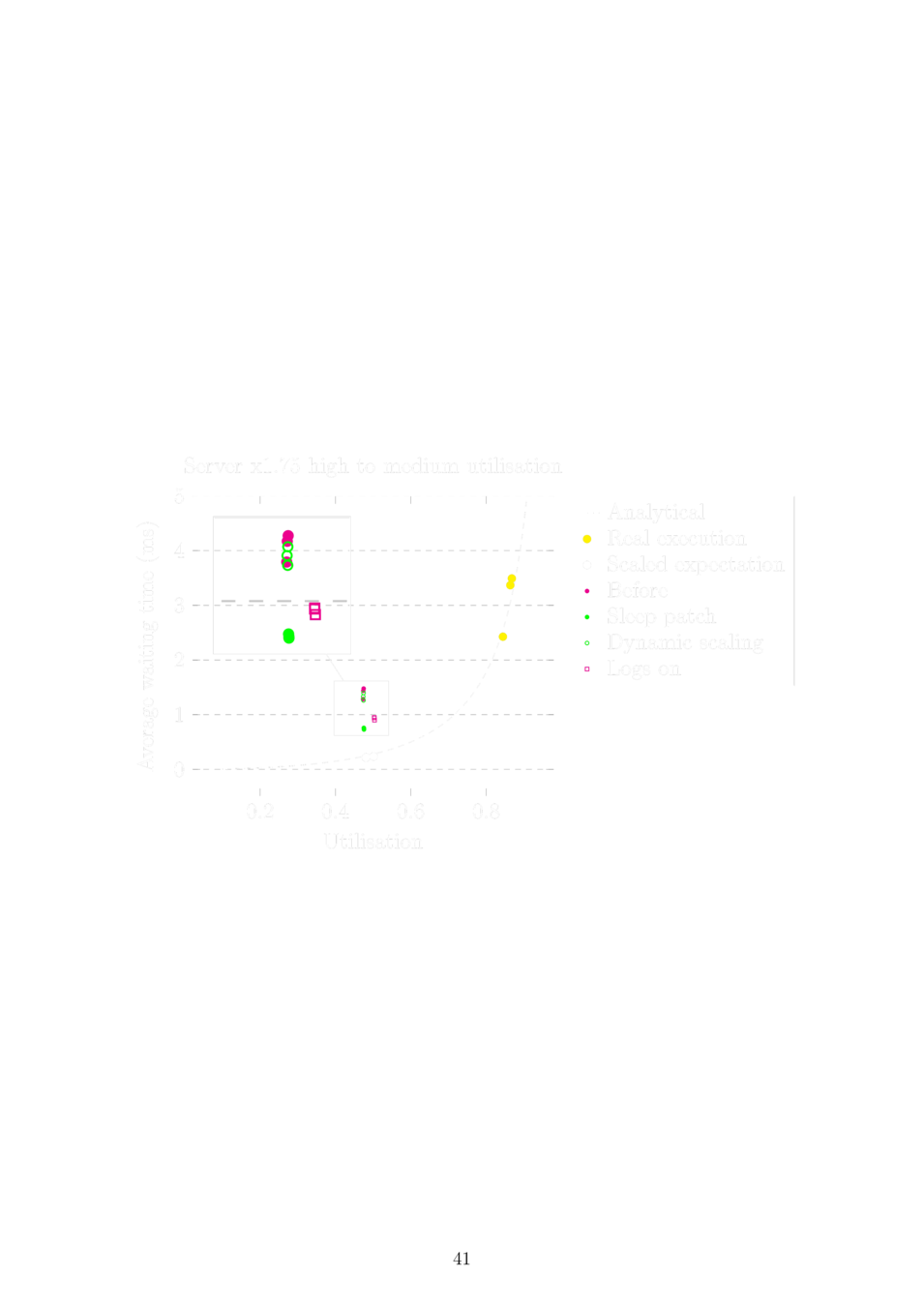
Sleeping in virtual time
Experimental setup
Producer thread
Consumer thread
Analytical mean waiting time (Pollaczek-Khintchine formula): \[E(W)=\frac{\rho\mu}{2(1-\rho)}\left(1+\frac{\sigma^2}{\mu^2}\right)\]
repeat 10 000 times
sleep(exp_sample(r));
push_job();repeat 10 000 times
fetch_job(); // busy-wait
service_job();Sleeping in virtual time
SMP algorithm
We need to synchronise multiple timelines on multi-core.
This is quite a dramatic change to the uniprocessor algorithm.
There are some tricky details - catch-up time, deadlocks, migrations.
The PARSEC benchmark
The goal is to evaluate Tense with a large application.
We can accurately predict the relative speed-up, but the absolute execution time is overestimated by 10% in both cases.
tense_scale_percent(120);
r = compress(chunk->compressed_data.ptr,
&n, chunk->uncompressed_data.ptr,
chunk->uncompressed_data.n);
tense_clear();What's next
Avoid running a custom kernel.
Fix known bugs in the SMP algorithm and discover new ones.
Improve user-space features.