Rails API
Une formation interne @Capsens
Tour de table
6. Tests
7. Ressources complexes
8. Déploiements
9. Versionning
10. Mobile
1. Présentation d'une API simple
2. Authentification
3. Rôles & permissions
4. Documentation
5. Process de communication Back/Front
Programme
Présentation d'une API simple
- render au format json
- pagination
Controler
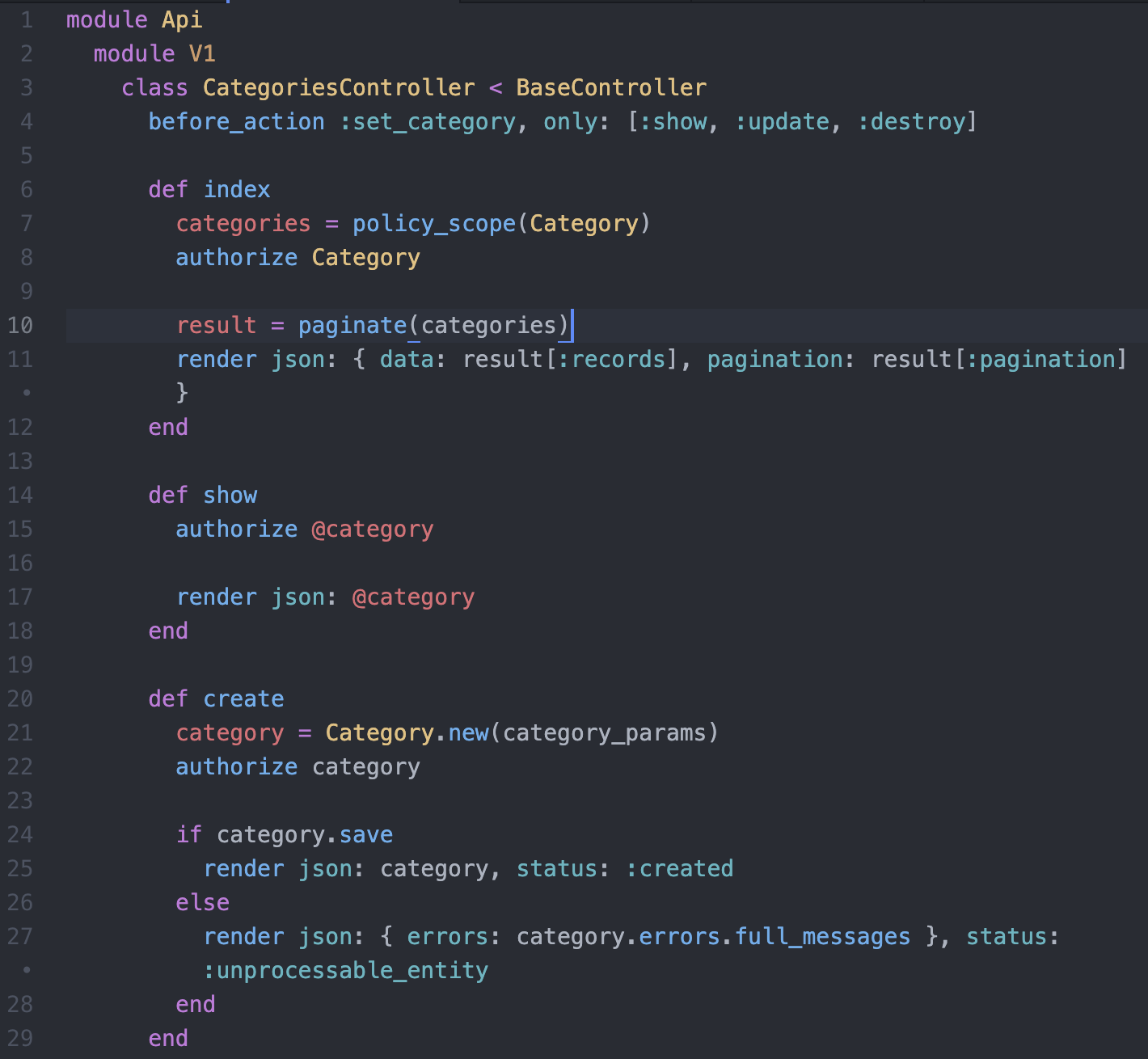
- hérite de ActionController::API
- gestion d'erreur "standard"
Application Controler
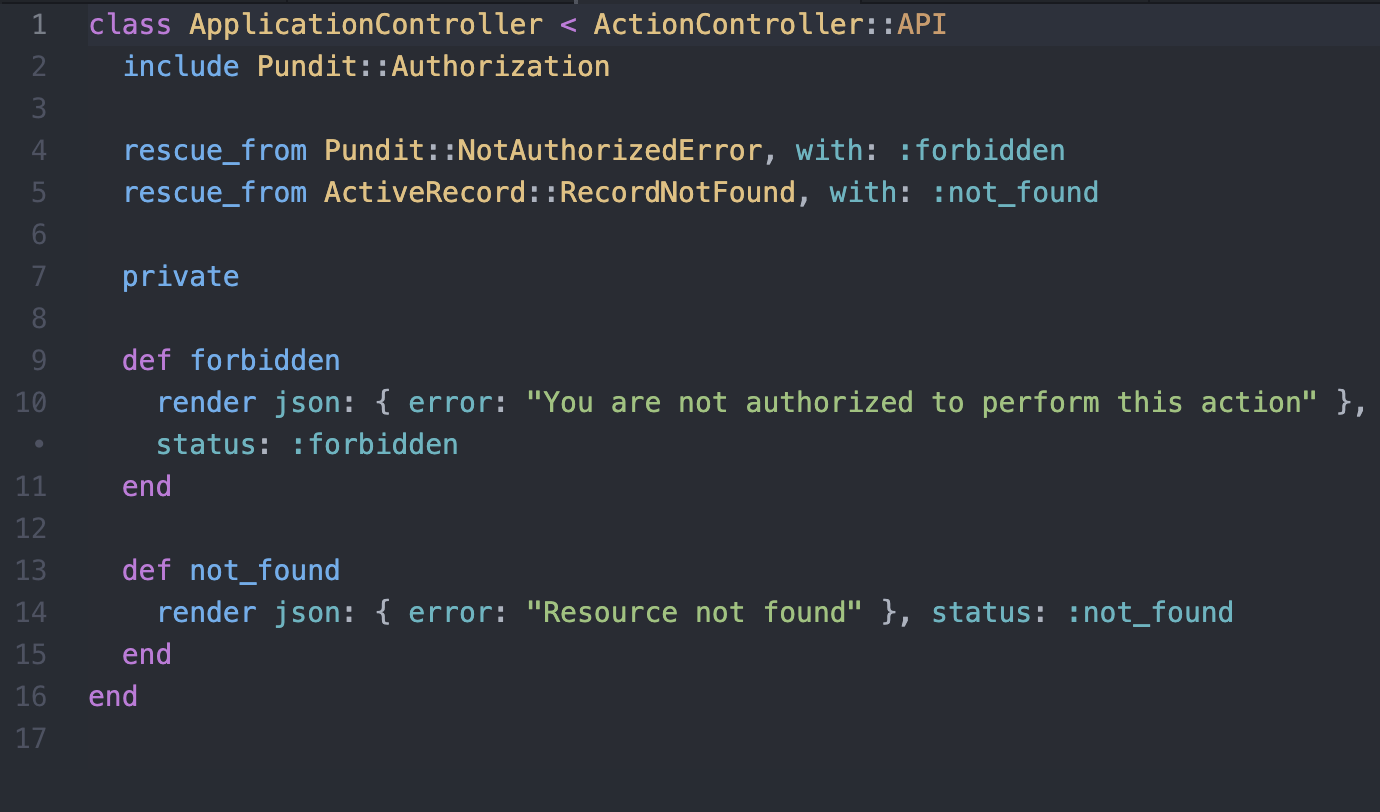
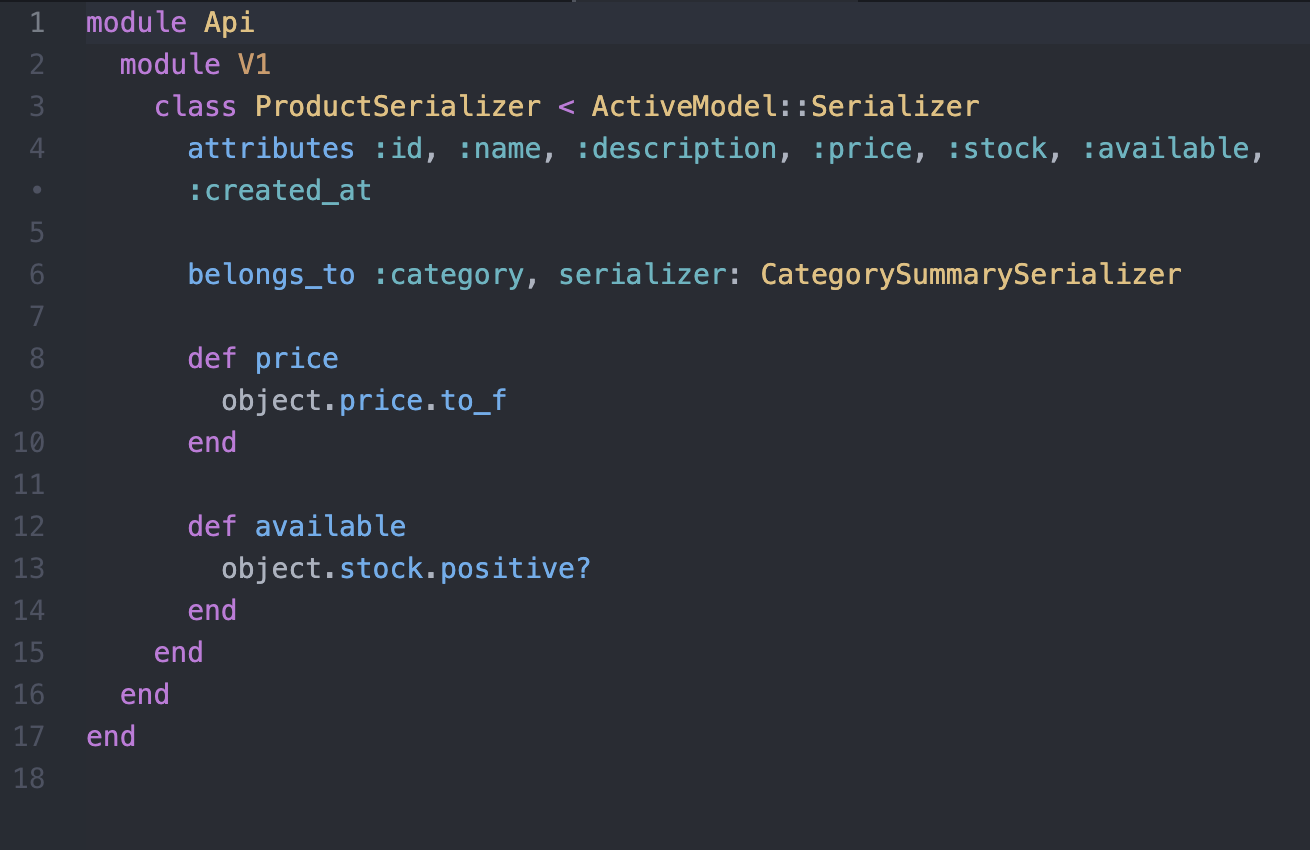
- Possibilité d'avoir plusieurs serializer par ressource
- attention aux "has_many" qui font des n+1 et ignorent la pagination
Serializer
4. Creer la base de donnees : rails db:create db:migrate db:seed
5. Lancer le serveur : rails s
6. Verifier que l'API repond : GET http://localhost:3000/api/v1/products
Setup d'un environnement local de test
1. Telecharger et installer Postman (https://postman.com/downloads)
2. Télécharger l'API démo https://github.com/petrachi/ecommerce_api
3. Installer les dependances : bundle install
Exercice
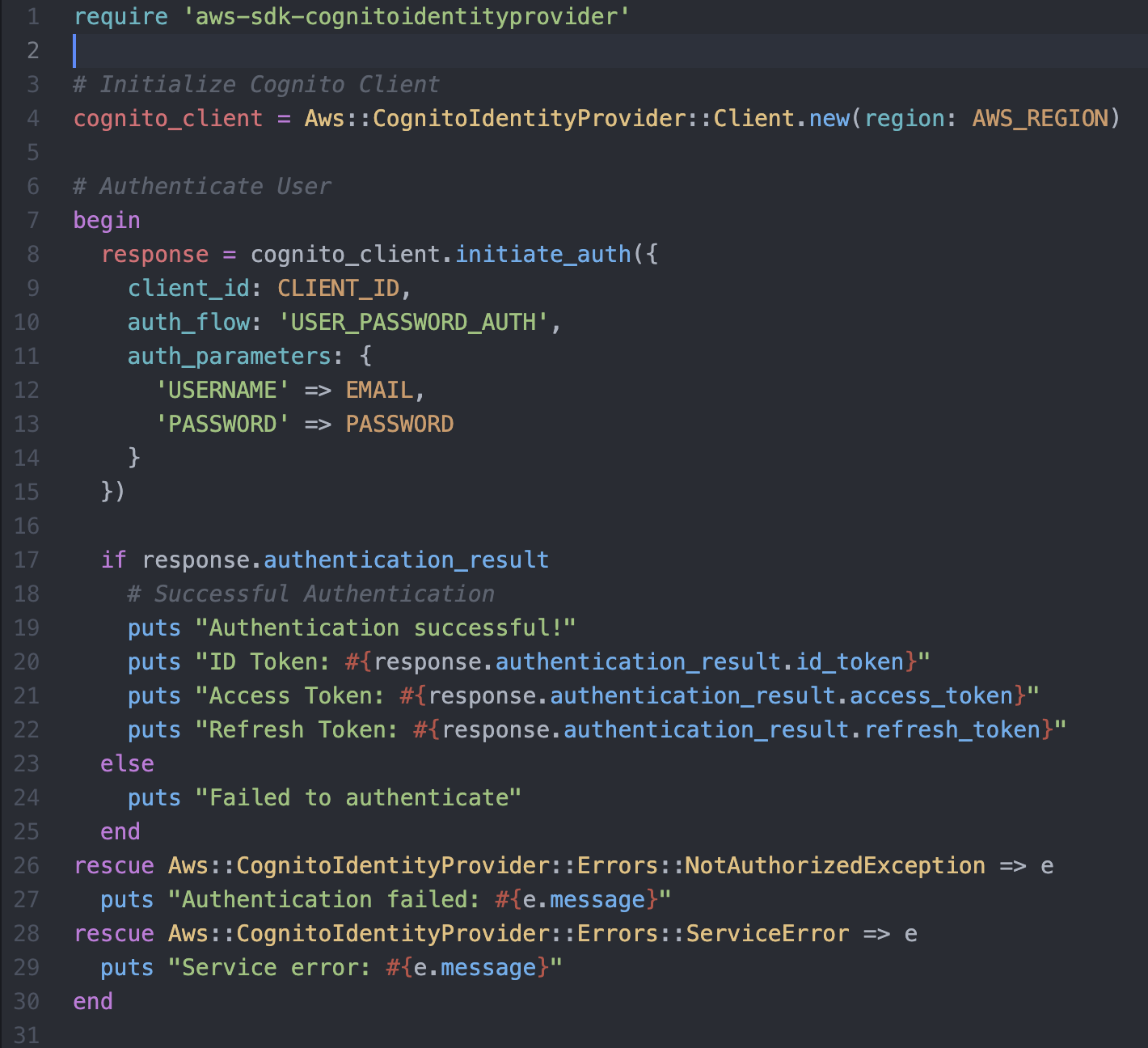
Authentification
JWT vérifié par un tiers
- Délégation des contraintes de sécurité au tiers
- Facilement scalable et partageable entre plusieurs services
Access Manager
JSON Web Token
- Simple à implémenter
- Mécanique d'expiration
- Le contenu du token est variable (on peut y mettre un user, des permissions, etc)
JWT
Token dans le header
- Très simple à implémenter
- La clé doit rester secrète
- Peut convenir pour des communication entre deux services interne
Header

Header
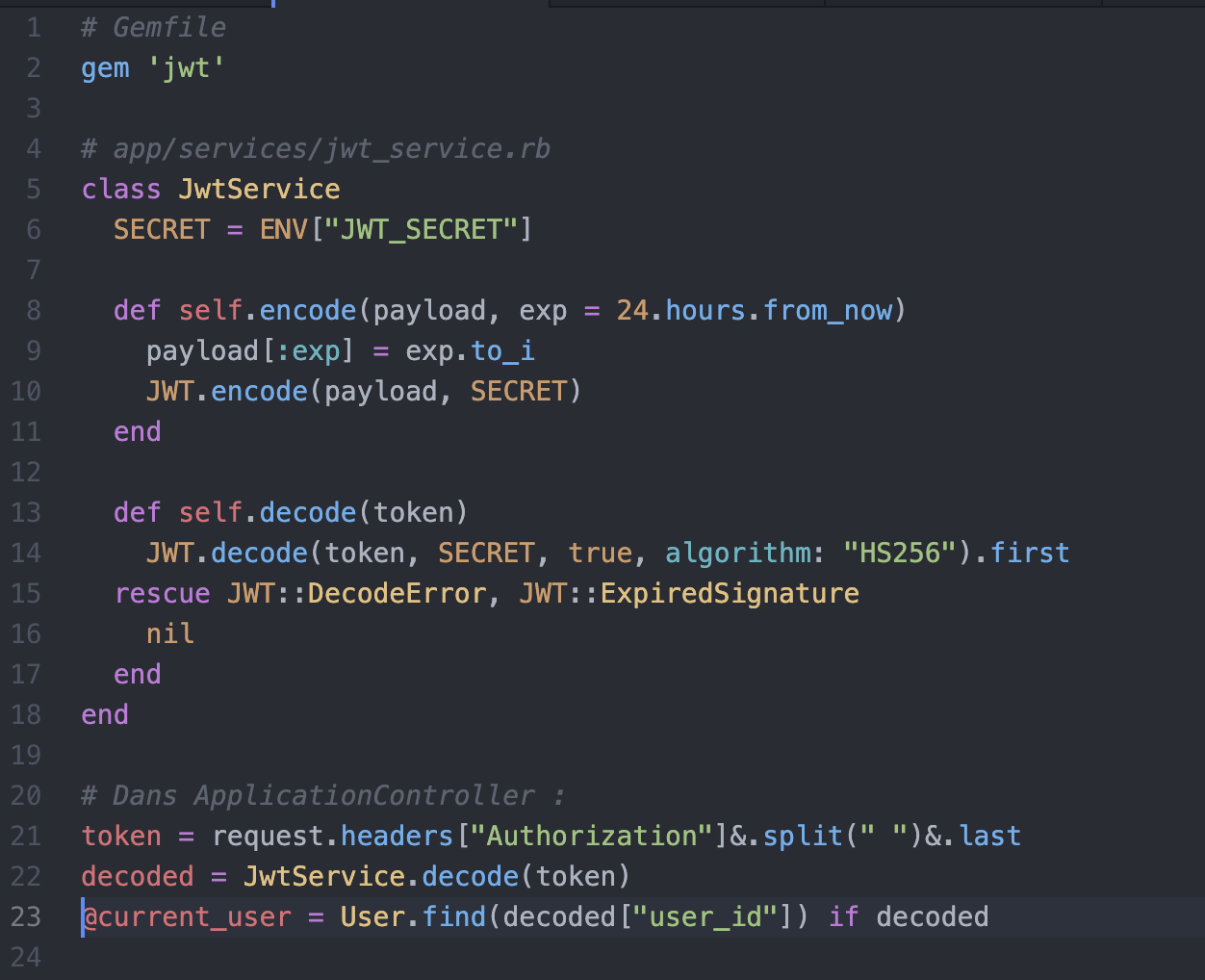
JWT
Access Manager
4. Automatiser le processus avec les variables postman
1. Se connecter via postman http://localhost:3000/api/v1/login
2. Récupérer le token de connexion
3. Récupérer la liste des produits en s'authentifiant http://localhost:3000/api/v1/products
Exercice
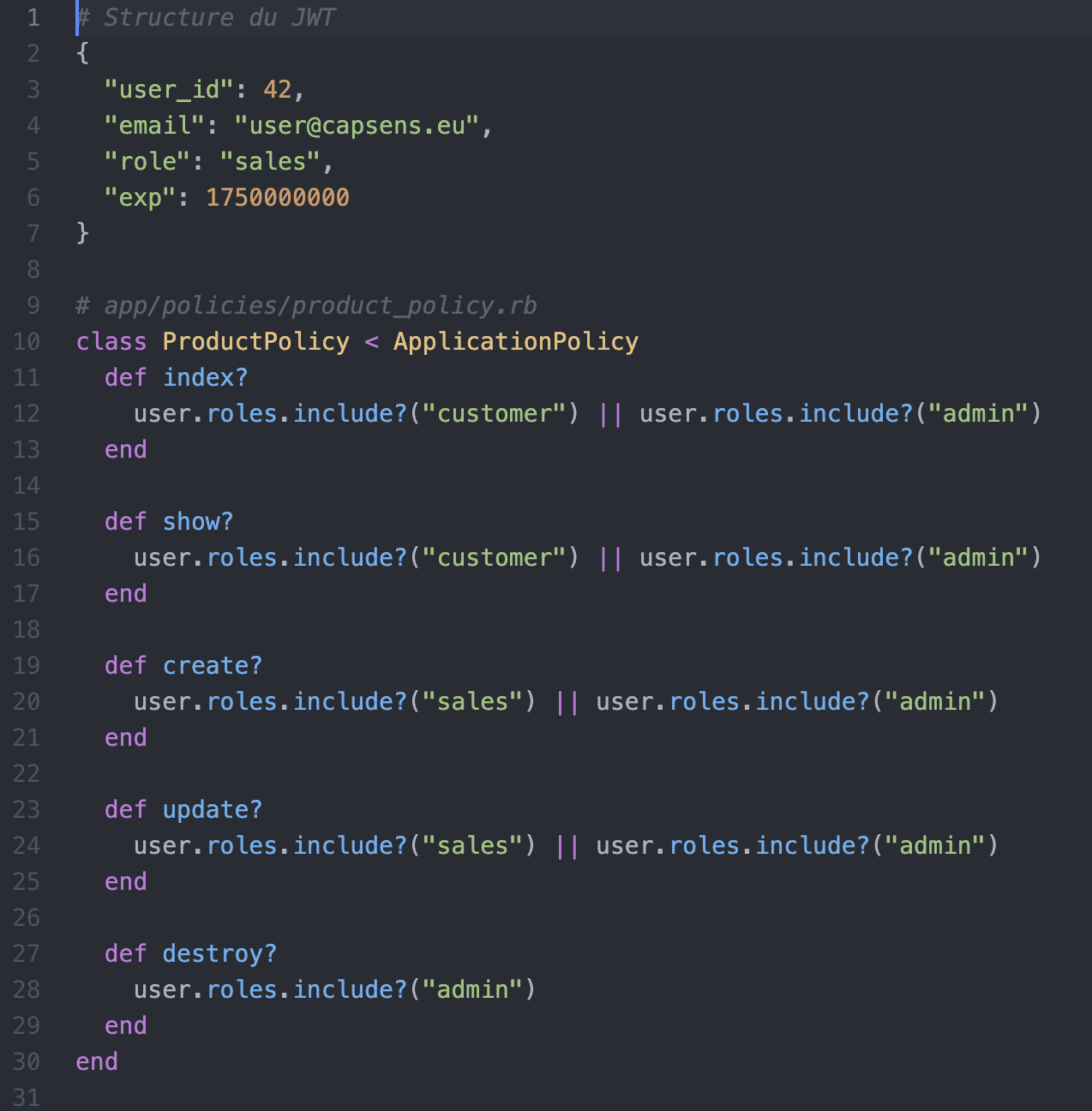
Rôles & permissions
- Le token de connection inclut les permissions de l'utilisateur, le back ne fait que le lire
- Permet de partager la ségregation des permissions à travers plusieurs services
Permissions dans le JWT
- Le token de connexion inclut le rôle de l'utilisateur connecté
- Le front peut utiliser le rôle pour obtenir différentes informations à différents endroits de l'application
- Le back peut customizer les réponses en fonction du rôle souhaité
Rôles dans le JWT
- Toutes les permissions sont gérés au regard de l'utilisateur connecté
- Les permissions peuvent être ultra-précises
Interne à l'application

Interne à l'application
Roles dans le JWT
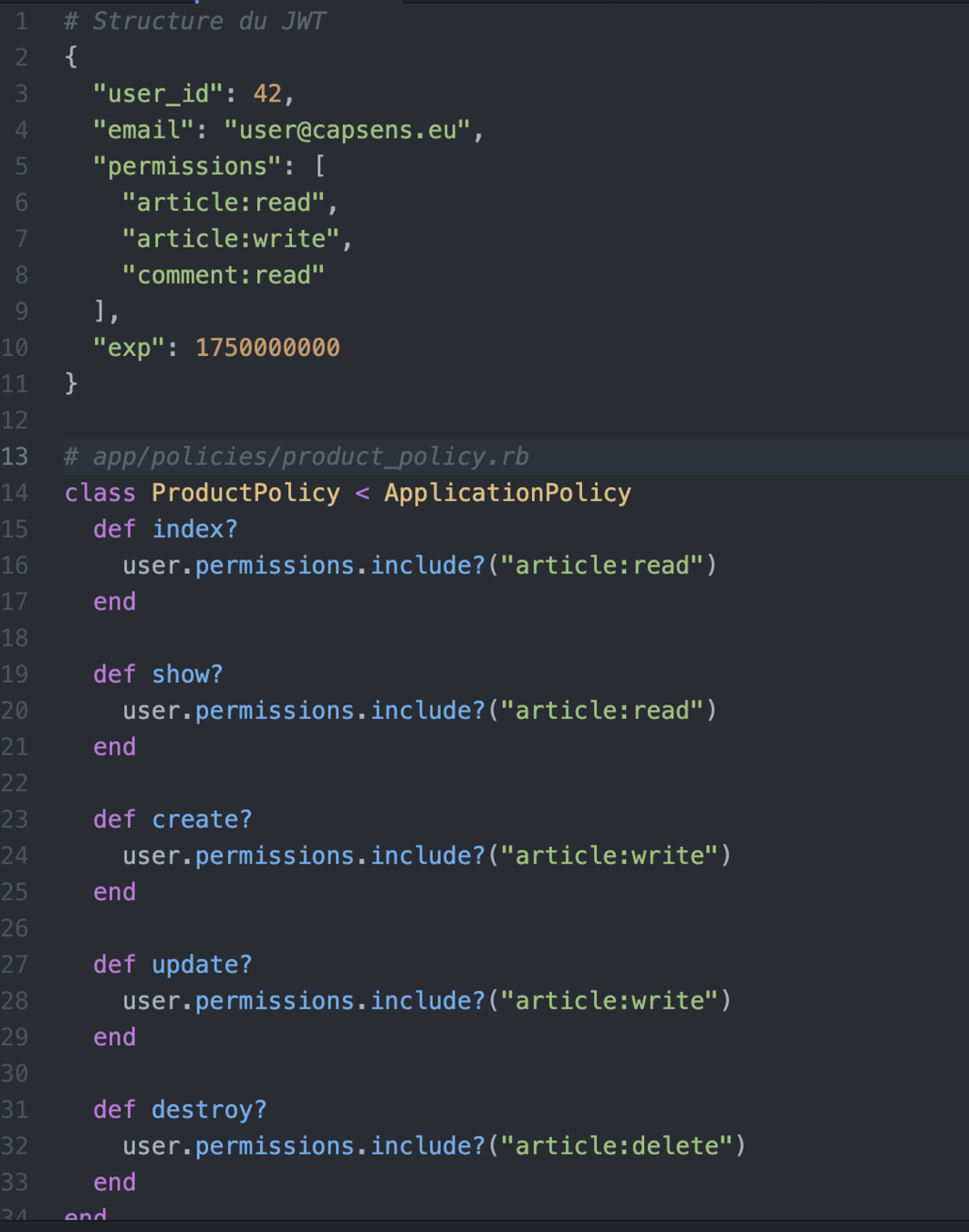
Permissions dans le JWT
Documentation
- On écrit la doc à priori ou à posteriori ?
- On concentre les efforts sur la précision du typage du schema de donnée ?
- Ou sur des exemples d'usages ?
- On écrit la doc via des outils automatiques, ou à la main ?
Quelle doc
Mes collégues dev back ?
Mes collégues dev front ?
Des devs front externes ?
Quelle cible ?

Outil semi-automatique
S'intégre aux scénarios de tests
Gem rswag-specs

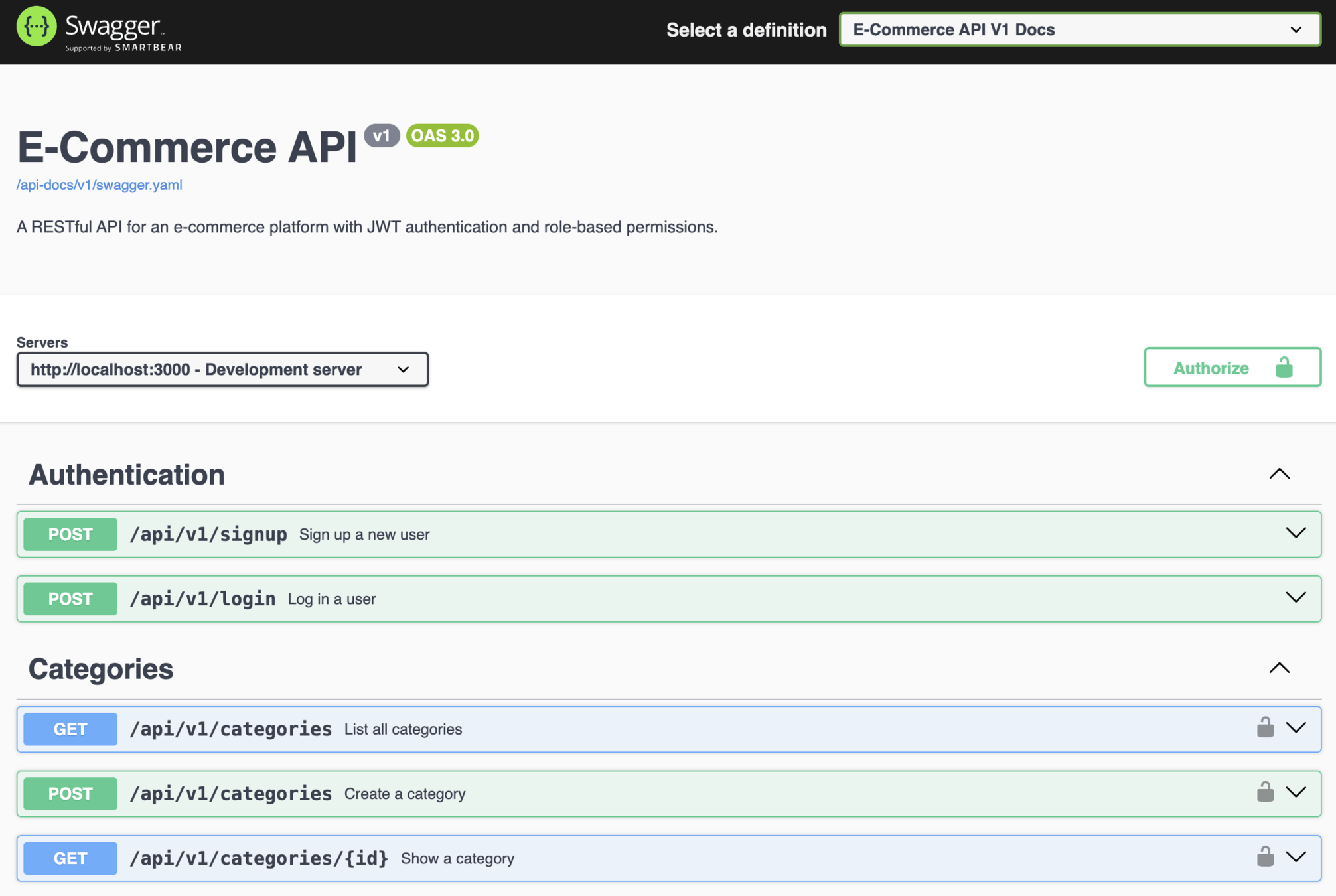
Permet d'exposer une UI interactive à partir des swagger générés
Gem rswag-ui
4. Copier le token via le boutton "Authorize"
5. Récupérer la liste des produits qui coûtent moins que 500
1. Aller sur http://localhost:3000/api-docs/index.html
2. Essayer de récupérer la liste des produits qui coûtent moins que 500
3. Se connecter via l'action "login"
Exercice
Process de communication Back/Front
Contexte :
Une équipe Front et une équipe Back
Problématique :
Comment on fait pour travailler en même temps sur le même feature ?
Partage d'expérience
Solution en 3 étape :
- Les deux équipe font une conception technique commune de la feature
- Il faut surtout réfléchir à la structure de donné
- De quoi a besoin le front comme information ?
- Comment le Back va organiser ça dans son schéma de DB ?
- Tous les endpoints nécessaires sont écrits dans le ticket
- Le schéma de donnée est écrit
- Les noms sont définitifs
- Ce qui est écrit dans le ticket fait loi
- Le front et le back peuvent travailler en même temps
- Le front utilise des mocks le temps que le back ait fini
- Le back écrit la documentation définitive à posteriori grâce à des outils automatiques
1. Réflexion sur l'intégration de ces contraintes chez Capsens
2. Écriture des guidelines de workflow de développement d'API
Exercice
Tests
Avec une API, les tests d'intégration sont des tests end-to-end
Je vous renvoie à cet article pour plus d'informations
https://www.rubybiscuit.fr/p/ecrire-des-tests-qui-evitent-les
Quels tests écrire ?
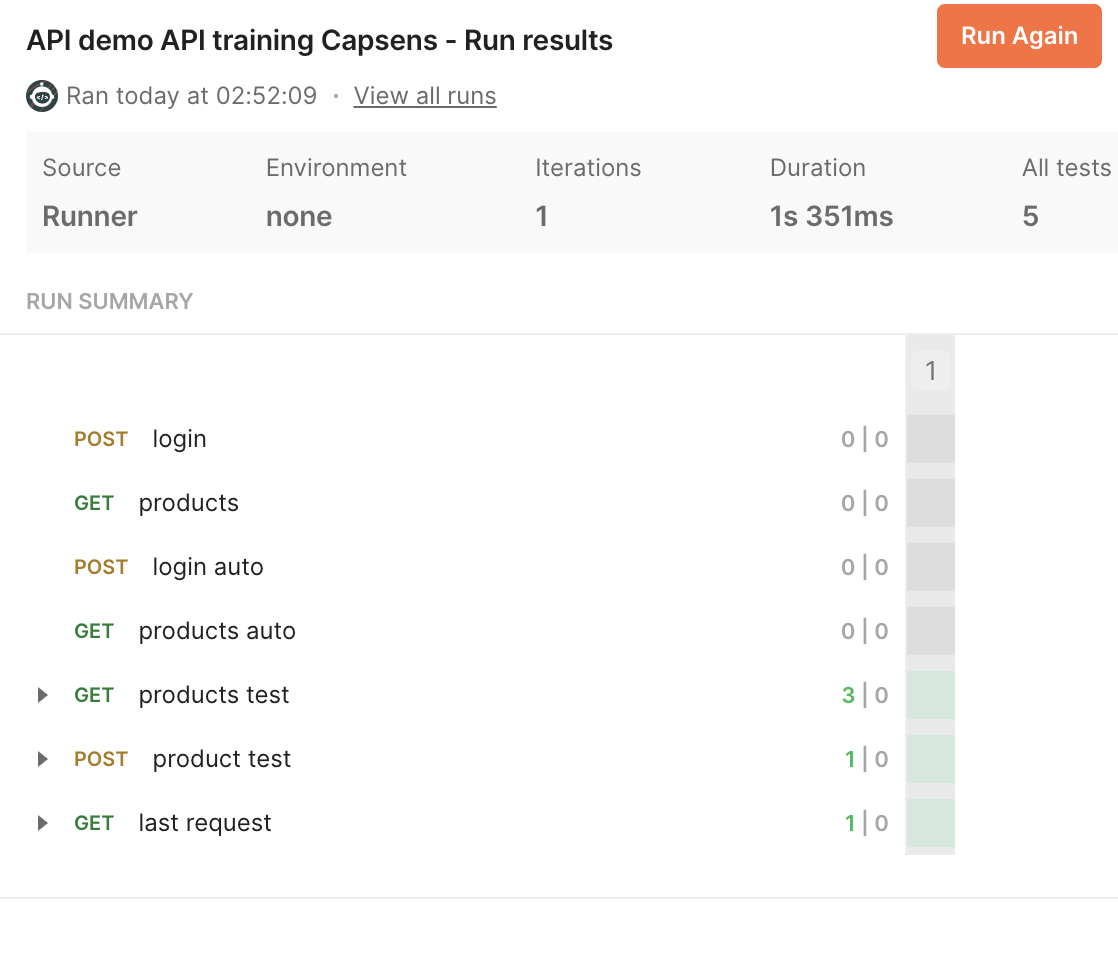
Postman permet également de créer des scénarios de tests
Peu d'avantages comparé à des tests intégrés à Rails
Alternative Postman
4. PATCH /products/:id -> modifier le titre
5. GET /products/:id -> verifier la modification
6. DELETE /products/:id -> supprimer le produit
7. GET /products/:id -> verifier la supression
Écrire dans postman un scénario de test CRUD classique
1. POST /auth/login -> sauvegarder le token de connexion
2. POST /products -> creee un produit et sauvegarder l'id
3. GET /products/:id -> verifier la creation et un champ du produit
Exercice
Ressources complexes
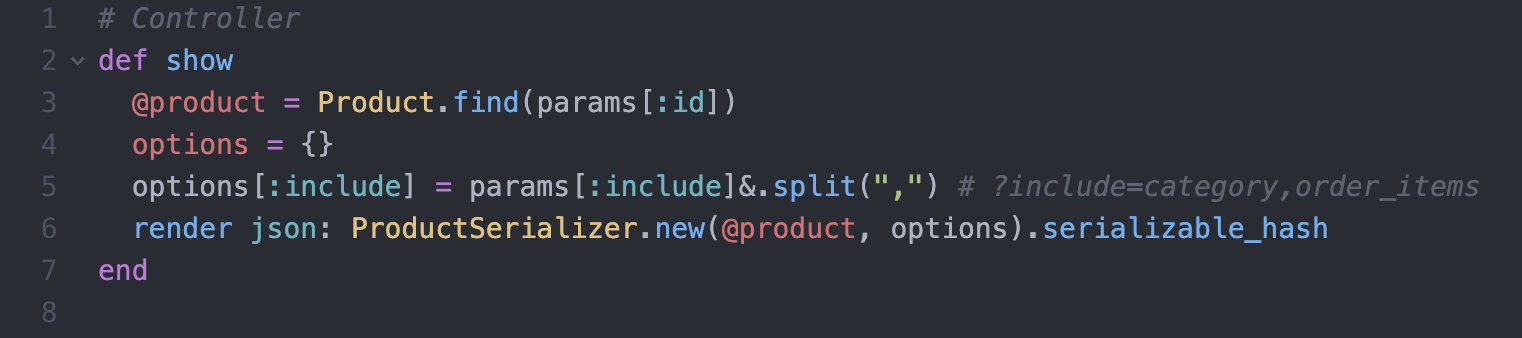
L'application propose un endpoint différent pour chaque besoin, même sur la même ressource
- Le code de chaque endpoint est indépendant du reste du code de l'API
- Le code des endpoints qui utilisent la même ressource risque d'être dupliqué, et de se désynchroniser avec le temps
- Le front est totalement dépendant du back pour personaliser ses appels
Endpoint dédié
L'application propose des endpoints "tous les mêmes", mais qui possédent de grandes capacités de personalisation
- Le code de chaque endpoint est simple
- Le code "coeur" de l'API est complexe et risque d'être difficile à maintenir
- Le front est autonome pour personaliser ses appels
Endpoint générique
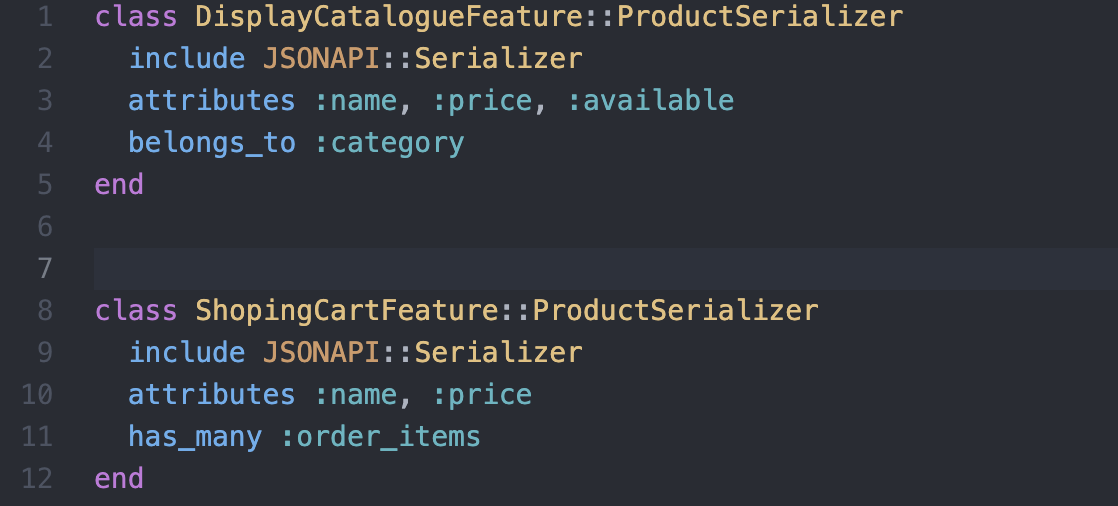
Exemple où les associations sont gérées de façon génériques.
Endpoint générique
Exemple de deux serializers differents où les associations sont incluses ou non en fonction des besoins de la feature
Endpoint dédié
Déploiements
1. Toujours déployer le Back avant le Front
2. Toujours tester la rétro-compatibilité avant de déployer
Points d'atttention
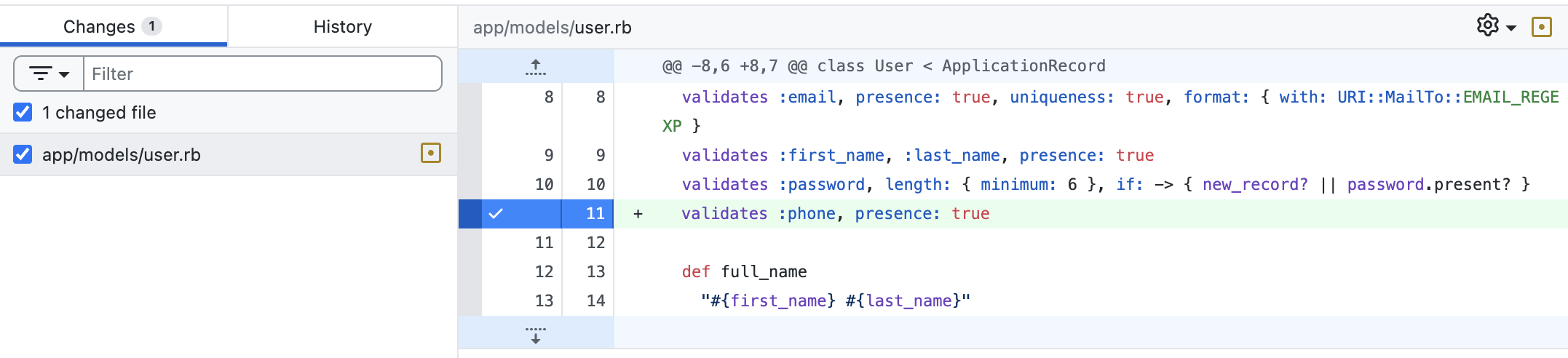
QCM #1
Je valide cette PR ?
Je demande des changements ?
QCM #1
Je valide cette PR ?
Je demande des changements !
Il faut mettre une valeur par défaut sinon tu casse la rétro-compatibilité.
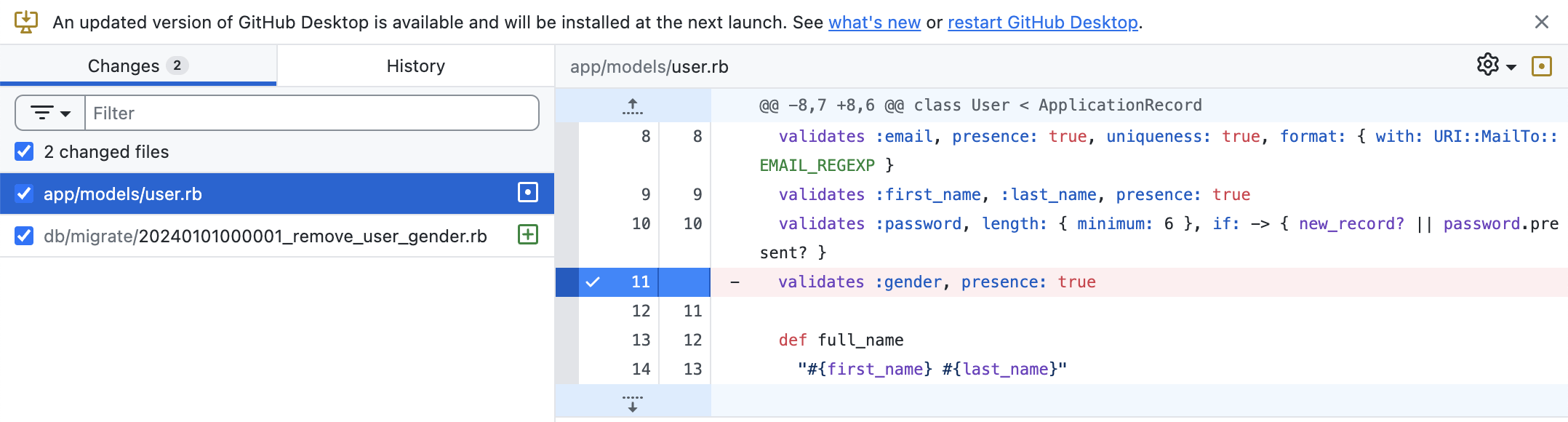
QCM #2
Je valide cette PR ?
Je demande des changements ?
QCM #2
Je valide cette PR ?
Je demande des changements !
Il faut supprimer cette colonne en deux deploy, sinon tu casse la retro compatibilité.
Met ta migration dans un autre deploy.
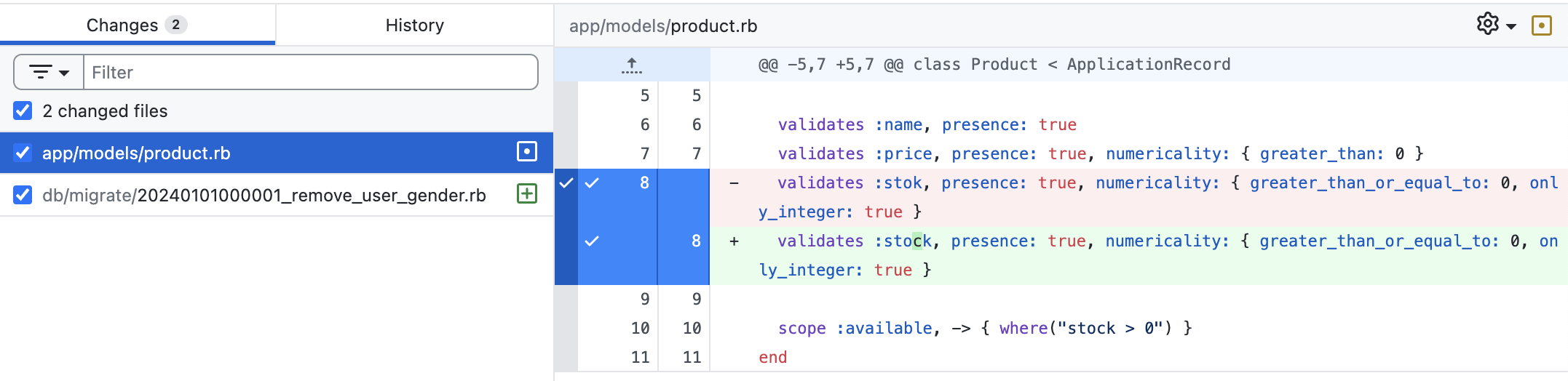
QCM #3
Je valide cette PR ?
Je demande des changements ?

QCM #3
Je valide cette PR ?
Je demande des changements !
Tu ne peux pas renommer de colonne c'est interdit. Tu dois créer la nouvelle colonne et dupliquer les données existantes. Et supprimer l'ancienne dans un second deploy
rename_product_stock.rb
rename_product_stock.rb

QCM #4
Je valide cette PR ?
Je demande des changements ?

QCM #4
Je valide cette PR ?
Je demande des changements !
Tu ne peux pas renommer la colonne dans le serializer non plus, c'est la même logique que pour la migration
QCM #5
Je valide cette PR ?
Je demande des changements ?
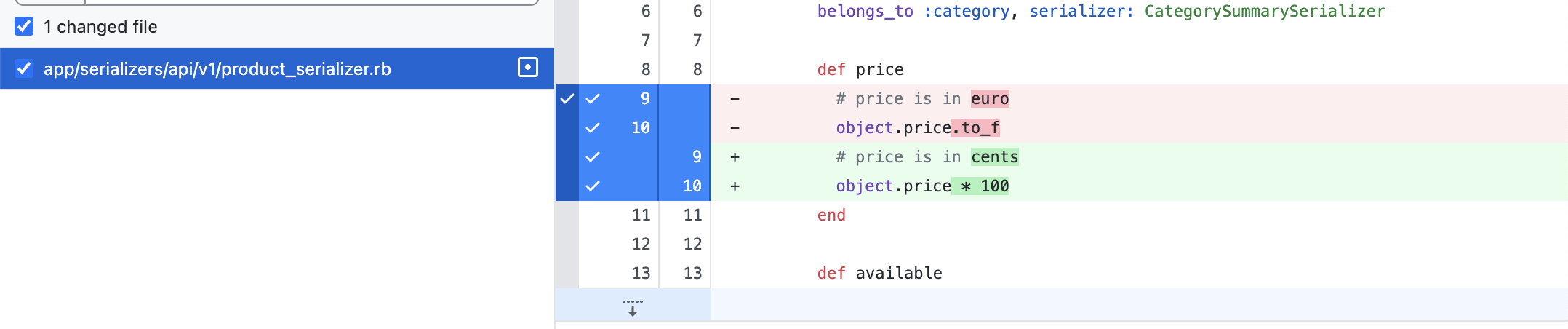
QCM #5
Je valide cette PR ?
Je demande des changements !
Tu ne peux pas modifier le format d'un champs dans le serializer sans casser la rétrocompatibilité
QCM #6
Je valide cette PR ?
Je demande des changements ?
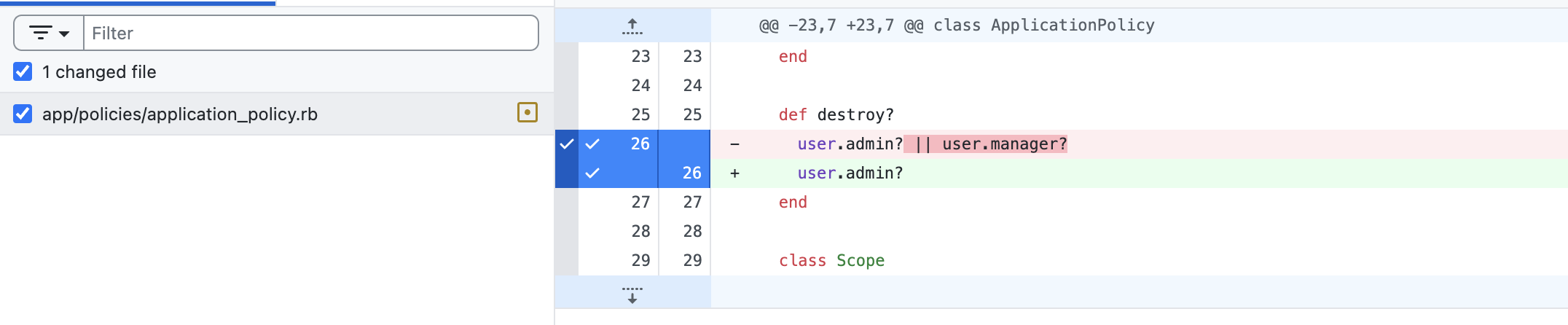
QCM #6
Je valide cette PR !
Je demande des changements ?
Je suppose que tu sais que tu casse la rétro-compatibilité ici, mais vu que c'est pour corriger une faille de sécurité c'est OK
QCM #7
Je valide cette PR ?
Je demande des changements ?
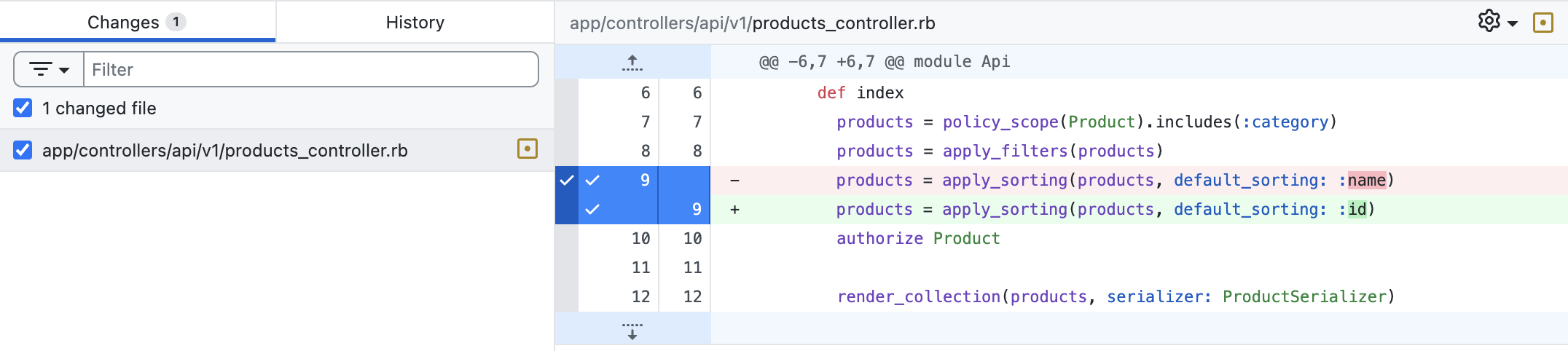
QCM #7
Je valide cette PR ?
Je demande des changements ?
Ça dépends !
On a bien la confirmation que le front a modifié ses requêtes pour explicitement passer le param de sorting sur le nom là où ils en avaient besoin ?
QCM #8
Je valide cette PR ?
Je demande des changements ?
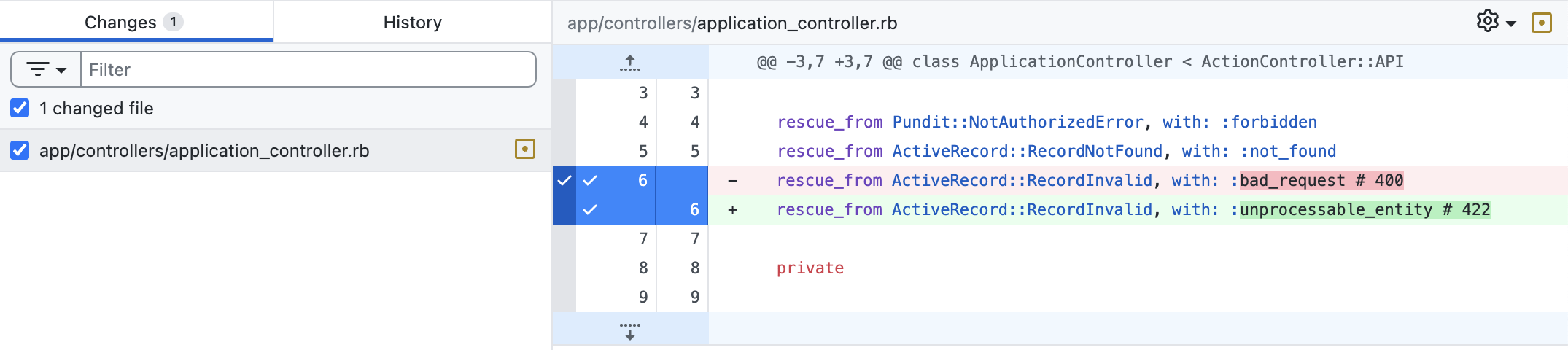
QCM #8
Je valide cette PR ?
Je demande des changements ?
Ça dépends !
On a bien la confirmation que le front interceptent aussi bien les erreurs 422 que les 400 ?
Versionning
Vous mettez votre code d'API dans un dossier "v1", "v2", etc
Vous utilisez le code pertinent en fonction de l'url, ou d'un header, ou d'un param
La pratique
Vous devez faire évoluer votre API par gros changements
Un petit changement ne suffit pas à justifier la duplication de toute la base de code liée à l'API
Dans un contexte d'amélioration continue, il est probable que vous ayez une v1 pour toujours
Intégrer une mécanique de feature flag / déprecation warnings est peut-être plus approprié
Inconvénients
Vous pouvez avoir plusieurs versions de l'API qui fonctionnent en même temps
C'est bien plus pratique pour permettre aux clients de l'API pour se mettre à jour
Ce qui est probablement nécessaire si vous faites une API qui est consommée par des clients externes, avec qui vous avez peu de communication
Avantages
Sur chaque réponse de l'API Back, vous ajoutez un champ "deprecation", qui est habituellement vide
Si une feature évolue, vous activez ce flag "deprecated" sur l'ancien comportement
Le front met en place un mécanisme, dans ses tests automatiques qui renvoie une alerte si le flag "deprecated" est rempli
Deprecation Warning
1. Le front envoi sur chaque requête son "numéro de version front"
2. En fonction, le back va répondre avec le nouveau comportement ou l'ancien comportement
Feature Flag
Mobile
3. Coupures réseau
Il faut anticiper et mettre en place des mécanismes de récupération en cas de coupure réseau
Il faut aussi prévoir que les requêtes n'arriveron pas nécessairement dans le bon ordre
2. Les appstores doivent valider les nouvelles version des applications
Vous n'avez pas entièrement le contrôle sur le moment de déploiement de la nouvelle version
Difficile aussi de faire un hotfix sur le front en cas de bug
1. Les utilisateurs contrôlent la mise à jour de leur application (front).
Il faut donc assurer la rétro compatibilité sur de longues périodes
Partage d'expérience : environ 10% des utilisateurs avaient une version datant de +6mois
Quelques challenges spécifiques
5. Prévoir du stockage local côté front
Et donc, peut-être, considérer un envoi des données basé sur un diff (à la git)
4. Attention à la consomation de Data et de batterie
Il faut privilégier les approches qui demandent le moins de requêtes possibles
Ainsi que des requêtes les plus légéres possibles (dans les deux sens)