
La codifica dei testi
BIBLIOGRAFIA
Susan Hockey - The History of Humanities Computing, Companion di Digital HUmanities
Digital Scholarly Editing: Theories and Practices
https://www.openbookpublishers.com/product/483/digital-scholarly-editing--theories-and-practices
BIBLIOGRAFIA
Elena Pierazzo, La codifica dei testi letterari, Carocci, 2005 (1 Capitolo)L'umanista digitale, il capitolo di Teresa Numerico.F. Ciotti. 2015. Sul distant reading: una visione critica. Semicerchio, LIII(2)T. Underwood. 2017. A Genealogy of Distant Reading. Digital Humanities Quarterly 11(2). Web: http://www.digitalhumanities.org/dhq/vol/11/2/000317/000317.htm
BIBLIOGRAFIA
Gino Roncaglia, La quarta rivoluzione. Sei lezioni sul futuro del libro
Alessandro Gazoia, Come finisce il libro Contro la falsa democrazia dell'editoria digitale

Le informazioni incorporate in un testo sono denominate, dall'inglese, alternativamente "codifica" (encoding), "marcatura" (markup), o, con un brutto calco, "taggatura" (tagging).
Introduzione
Senza una marcatura semantica o strutturale, si possono effettuare solo ricerche molto semplici sui testi
Introduzione
Che cos'è la codifica?
La codifica informatica di un testo è la rappresentazione di un testo su un supporto digitale in un formato comprensibile da un elaboratore elettronico.
Tale definizione sottende però una serie di questioni teoriche (ma anche pratiche!). Innanzitutto il cincetto di rappresentazione del testo (a che livello?da quale punto di vista?), e in secondo luogo il problema della comprensione, vale a dire un sitema di comunicazione condiviso dall'uomo e dalla macchina.
Schema della comunicazione di Jakobson
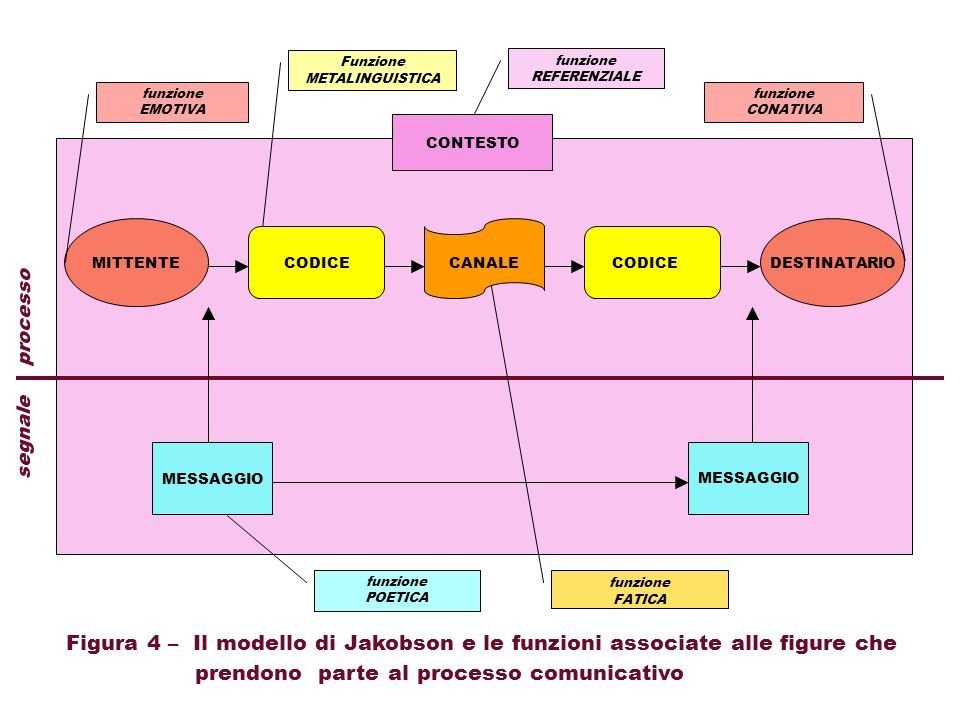
Che cos'è la codifica?
In ambito letterario la differenza esistente fra il codice dell'Autore e quello del Lettore ha portato Cesare Segre a definire qualsiasi testo un diasistema, cioè il "risultato del compromesso tra il sistema del testo e il sistema del copista"
Che cos'è la codifica?
La codifica gioca un ruolo importante per la rappresentazione e modellizzazione del documento in quanto, ogni volta che un atto di comunicazione ne viene attuato, si opera una selezione e una organizzazione dell'informazione da trasmettere.
Che cos'è la codifica?
Analizzare significa innanzittutto scomporre, selezionare.
La codifica, quindi, è un mezzo per rendere esplicita un'interpretazione del testo (G. Gigliozzi, 1997)
Che cos'è la codifica?
La codifica di un testo, quindi, può essere definita come una rappresentazione di un testo su un supporto digitale, in funzione di un determinato punto di vista, secondo un codice condiviso in modo sostanziale dall'uomo e dall'elaboratore elettronico cui tale codifica è destinata.
XML: sintesi principi fondamentali
- XML adotta un paradigma di codifica dichiarativo e descrittivo
- XML descrive un documento come una struttura ad albero
- XML introduce il concetto di “tipo di documento” e di “sintassi del documento”
- XML si basa su ISO 10646 /UNICODE
Il concetto di modello
Prima della codifica di un qualsiasi documento è necessario studiarne la natura, le caratteristiche e le possibili funzionalità
In questa fase perciò scegliamo non solo come ma che cosa vogliamo rappresentare/codificare
Dal punto di vista della codifica informatica, questo processo analitico coincide con la creazione di un modello del documento fonte
Il concetto di tipo di documento
Un’applicazione XML si basa su un determinato tipo di documento
Un tipo di documento descrive le caratteristiche di una classe di documenti strutturalmente omogenei
Il tipo di documento è il fondamento della sintassi e della semantica di una applicazione XML
Aspetti di sintassi generale
I nomi di elementi, attributi e entità sono sensibili alla differenza tra maiuscolo e minuscolo
Il mark-up è separato dal contenuto testuale mediante caratteri speciali:
< > &
Tali caratteri speciali non possono comparire come contenuto testuale e devono essere eventualmente sostituiti mediante i riferimenti a entità
< > &
Aspetti di sintassi generale
Gli elementi da inserire sono:
- Elemento radice
- Elementi figli
- Attributi
Aspetti di sintassi generale
I quattro errori comuni
Spesso codificando in XML si può cadere in questi errori:
1. Omettere i tag di chiusura: ogni tag va aperto e chiuso
<p>Oggi c'è il sole (sbagliato)
<p>Oggi c'è il sole</p> (esatto)
Aspetti di sintassi generale
I quattro errori comuni
Spesso codificando in XML si può cadere in questi errori:
2. Dimenticare che XML è sensibile alle maiuscole e minuscole:
<PersName>Daniele</persname> (sbagliato)
<PersName>Daniele</PersName> (esatto)
Aspetti di sintassi generale
I quattro errori comuni
Spesso codificando in XML si può cadere in questi errori:
3. Inserire gli spazi nel nome dell‘elemento:
<Pers Name> (sbagliato)
<PersName> (esatto)
Aspetti di sintassi generale
I quattro errori comuni
Spesso codificando in XML si può cadere in questi errori:
4. Dimenticare le virgolette per i valori degli attributi:
<note place=foot> (sbagliato)
<note place="foot"> (esatto)
La Text Encoding Initiative
TEI è un progetto internazionale che ha visto coinvolte le maggiori organizzazioni internazionali dedicate all'Informatica Umanistica
TEI: macrostruttura
Tutti i testi conformi alla TEI contengono:
una testata TEI <teiHeader>, da considerarsi il frontespizio del documento elettronico;
una trascrizione del testo vero e proprio marcata con l'elemento <text>.
XML / TEI - Aspetti importanti
XML /TEI
Output
Pagine HTML
Epub
Linguaggi di trasformazione
XML / TEI - Aspetti importanti
2. XML /TEI
Output
Pagine HTML
Epub
Linguaggi di trasformazione
1. SCHEMA
3. xslt
output
XML - Aspetti importanti
TEI
TeiHeader
Text
TEI - Macrostruttura
Tutti i testi conformi alla TEI contengono:
una testata TEI <teiHeader>, da considerarsi il frontespizio del documento elettronico;
una trascrizione del testo vero e proprio marcata con l'elemento <text>.
La macrostruttura del testo
Come già detto ogni testo unitario deve iniziare con l'elemento obbligatorio <text>. Esso è composto a sua volta da tre elementi di livello inferiore:
<front>: contiene tutti i materiali di tipo avantestuale, che introducono il testo nelle edizioni a stampa, dalla pagina del titolo, al frontespizio, ad introduzioni, dediche, prefazioni, etc.;
<body>: contiene il testo vero e proprio, il suo corpo;
<back>: contiene tutti i materiali peritestuali che possono essere rinvenuti nelle pagine finali di un testo stampato, postfazioni, glossari, indici, etc.
La macrostruttura del testo
<text>
<front>
[materiali peritestuali iniziali]
</front>
<body>
[testo]
</body>
<text><TeiHeader>
L’intestazione elettronica TEI contiene informazioni analoghe a quelle contenute nel titolo della pagina di un testo stampato:
documentazione della responsabilità editoriale, dati bibliografici, metodologie adottate per la codifica, etc…
<TeiHeader>
Una corretta documentazione del testo elettronico dovrebbe prevedere le seguenti informazioni:
individuazione del testo elettronico attraverso le sue determinazioni bibliografiche: titolo, autore, luogo e data di edizione, ecc.;
certificazione della responsabilità del testo, anche quando la codifica ha avuto diversi responsabili;
indicazione della fonte;
documentazione accurata delle metodologie di rappresentazione dei vari fenomeni testuali, delle scelte teoriche che permettano di interpretare correttamente i simboli usati nella codifica del testo, delle eventuali modifiche o correzioni introdotte rispetto alla fonte.
Elementi
- I componenti strutturali di un documento sono denominati elementi (element)
- Ogni nodo dell’albero del tipo di documento è un (tipo di) elemento
- Ogni (tipo di) elemento è dotato di un nome (detto identificatore generico) che lo identifica
Elementi
Esiste un (e uno solo) elemento, detto elemento radice (corrispondente al nodo radice dell’albero), che non è contenuto da nessun altro e che contiene direttamente o indirettamente tutti gli altri
Ogni elemento, escluso l’elemento radice, deve essere contenuto da un solo elemento (elemento padre) e può contenere altri sotto-elementi (elementi figli) e/o stringhe di caratteri
Esiste un sottoinsieme di elementi che non contengono altri elementi e che possono essere vuoti contenere esclusivamente stringhe di caratteri
Struttura XML / TEI
Un documento XML deve essere ben formato
SCHEMA XML
Documento XML