Edizione scientifica digitale in pratica



// Codifica di livello 0 o di basso livello. Riguarda la rappresentazione binaria
della sequenza ordinata dei caratteri (la codifica dei caratteri, UnicodeUTF8)
// Codifica di alto livello. Arricchisce il testo codificato al livello zero con infor-
mazioni di tipo strutturale:
e.g. l’organizzazione del testo in elementi macrotestuali (e.g. paragrafazione, intestazioni ecc...), gli elementi stilistici-grafici (grandezza del font, margini, ecc...), valenza semantica del testo, la specifica di strutture linguistiche (tipologia di sintagma, analisi morfologica ecc...) e quindi di ogni possibile interpretazione l’editore voglia corredare il testo, esplicitandola formalmente.
I li
I livelli di codifica del testo:

- Proprietario. Le specifiche non sono disponibili apertamente.
- Non proprietario. Risorse open source, fruibili dalla comunità.
- Leggibile. Il file contenente la marcatura è visualizzabile e interpretabile.
- Non leggibile. Il documento è nascosto.
I tipi di codifica
- Procedurale. Contiene istruzioni inerenti l’impaginazione del documento (la
spaziatura, il font, l’interlinea ecc...). - Dichiarativo. Specifica la struttura logica di un documento.
I tipi di codifica

-
Presentazionale. Il linguaggio di markup mira a rappresentare la struttura fisica del testo mettendone in luce le caratteristiche superficiali
-
Analitico. Rende evidente le relazioni logiche e presenti all’interno del testo.
- Il ruolo della codifica come "disciplina comprendente una serie di conoscenze culturali e tecniche che consentono di memorizzare un documento
- I linguaggi di markup - XML/TEI (Text Encoding Initiative)
I Linguaggi di markup
(codifica ad alto livello):
Un linguaggio di markup è un linguaggio che consente di descrivere dati tramite dei marcatori (tag). Un esempio molto popolare di linguaggio di markup è l’HTML, che consente di descrivere pagine per il Web. Il linguaggio HTML utilizza un insieme predefinito di tag per descrivere gli elementi di una pagina Web (es.: <head></head>, <body></body>, ecc.).
I Linguaggi di markup (codifica ad alto livello):
Ma possiamo fermarci a tag predefiniti come l'HTML?
L'HTML è l'ultima fase della realizzazione di un'edizione digitale.

Che cos'è la codifica?
La codifica informatica di un testo è la rappresentazione di un testo su un supporto digitale in un formato comprensibile da un elaboratore elettronico.
Tale definizione sottende però una serie di questioni teoriche (ma anche pratiche!). Innanzitutto il concetto di rappresentazione del testo (a che livello? da quale punto di vista?), e in secondo luogo il problema della comprensione, vale a dire un sistema di comunicazione condiviso dall'uomo e dalla macchina.
Elena Pierazzo, La codifica dei testi letterari, Carocci, 2005 (1 Capitolo)

La codifica gioca un ruolo importante per la rappresentazione e modellizzazione del documento in quanto, ogni volta che un atto di comunicazione ne viene attuato, si opera una selezione e una organizzazione dell'informazione da trasmettere.
La codifica di un testo, quindi, può essere definita come una rappresentazione di un testo su un supporto digitale, in funzione di un determinato punto di vista, secondo un codice condiviso in modo sostanziale dall'uomo e dall'elaboratore elettronico cui tale codifica è destinata.
Nel caso dei manoscritti antichi abbiamo tre modelli di edizione possibili:
// Meccanico. Una riproduzione tecnica, un facsimile, del manoscritto.
// Diplomatico-interpretativo. Il testo rispetta quello attestato e in nota vengono esplicitate le scelte dell’editore.
// Critico. Tenta la riproduzione (per congettura) del presunto testo originale.
MODELLI DI EDIZIONE
Nel caso di testi a stampa, la ricostruzione dell’esemplare ideale è il modello più rilevante. Quando ci si propone di realizzare un’edizione digitale si dovrà scegliere - o saper fare convivere - il tipo di edizione e quindi quali informazioni codificare.
MODELLI DI EDIZIONE
Un’edizione digitale deve offrire strumenti efficienti per la visualizzazione e la fruizione del testo, superando i limiti imposti dal supporto cartaceo (costi, diffusione, limiti spaziali e organizzativi, ecc...).
La codifica del testo digitale consente potenzialmente di:
Edizione scientifica digitale
- gestire contemporaneamente più livelli (il facsimile, l’edizione diplomatica, l’edizione critica), senza imporre un testo base in fase di visualizzazione.
- Le scelte e la responsabilità dell’editore sono sempre evidenti, benchè il testo non sia “fisso”, suscettibile di modifiche.
xml (Extensible Markup Language)
È un metalinguaggio di markup, cioè un linguaggio che permette di definire “altri linguaggi” a seconda della sua applicazione.
è uno standard ufficiale sviluppato dal W3C (World Wide Web Consortium) nel 1999: deriva da SGML quale suo sottoinsieme semplificato, ma ad oggi lo sostituisce. (http://www.w3.org/XML)
Nasce con l’obiettivo di rappresentare documenti (e.g. un testo letterario) e/o dati strutturati (e.g. i riferimenti bibliografici) su supporto digitale.
xml (Extensible Markup Language)
È un metalinguaggio di markup, cioè un linguaggio che permette di definire “altri linguaggi” a seconda della sua applicazione.
è uno standard ufficiale sviluppato dal W3C (World Wide Web Consortium) nel 1999: deriva da SGML quale suo sottoinsieme semplificato, ma ad oggi lo sostituisce. (http://www.w3.org/XML)
Nasce con l’obiettivo di rappresentare documenti (e.g. un testo letterario) e/o dati strutturati (e.g. i riferimenti bibliografici) su supporto digitale.
xml (Extensible Markup Language)
Un testo marcato in sintassi XML è detto documento XML: contiene sia il testo che i tag (anch’essi testo) utilizzati per descrivere le informazioni insite nel testo;
è “leggibile” dall’utente senza l’utilizzo di software specifici (i.e. con qualsiasi editor di testo). É infatti indipendente da qualsiasi software e hardware.
xml (Extensible Markup Language)
- XML adotta un paradigma di codifica dichiarativo e descrittivo
- XML descrive un documento come una struttura ad albero
- XML introduce il concetto di “tipo di documento” e di “sintassi del documento”
xml (Extensible Markup Language
Un linguaggio di programmazione normalmente impone una terminologia per esprimere concetti e istruzioni.
XML - che non è un linguaggio di programmazione - dice solo come esprimere formalmente i concetti tramite una sintassi vincolante, ma la semantica degli elementi è decisa dall’utente!
XML - SCHEMA
XML SCHEMA fornisce però esclusivamente norme di tipo sintattico, cioè stabilisce quali sono gli ELEMENTI per fare il markup di un documento ma non dà alcuna indicazione sui nomi da usare per assegnare a una porzione del documento una certa interpretazione.
Per far fronte a questo esistono gli schemi, ossia, un vocabolario di marcatura per l'Xml
(Francesca Tomasi, Rappresentare e conservare in L'umanista digitale)
XML - SCHEMA
Per far fronte a questo esistono gli schemi, ossia, un vocabolario di marcatura per l'Xml
(Francesca Tomasi, Rappresentare e conservare in L'umanista digitale)
Sono linguaggi scritti in XML e sono Document Type Definition (DTD) , XML Schema e RELAX NG.
Strumenti della TEI - Roma
XML-TEI
XML RELATED TECHNOLOGIES
XML-SCHEMA
XPATH
XQUERY
XSLT
Riassumiamo
- I sistemi di codifica permetteno lo scambio di informazioni attraverso la rappresentazione delle informazioni testuali.
- La codifica è un'attività scientifica e di ricerca, ma a sua volta può supportare la ricerca.
- Rendono esplicito alla macchina cosa è implicito per la persona.
- La definizione del markup e il processo di codifica è uno degli aspetti che caratterizza la nuova forma di editore.
- La scelta del markup non è neutra ed è frutto di interpretazione permessa soltanto da un'analisi e conoscenza del testo.
Riassumiamo
Riassumiamo
Riassumiamo
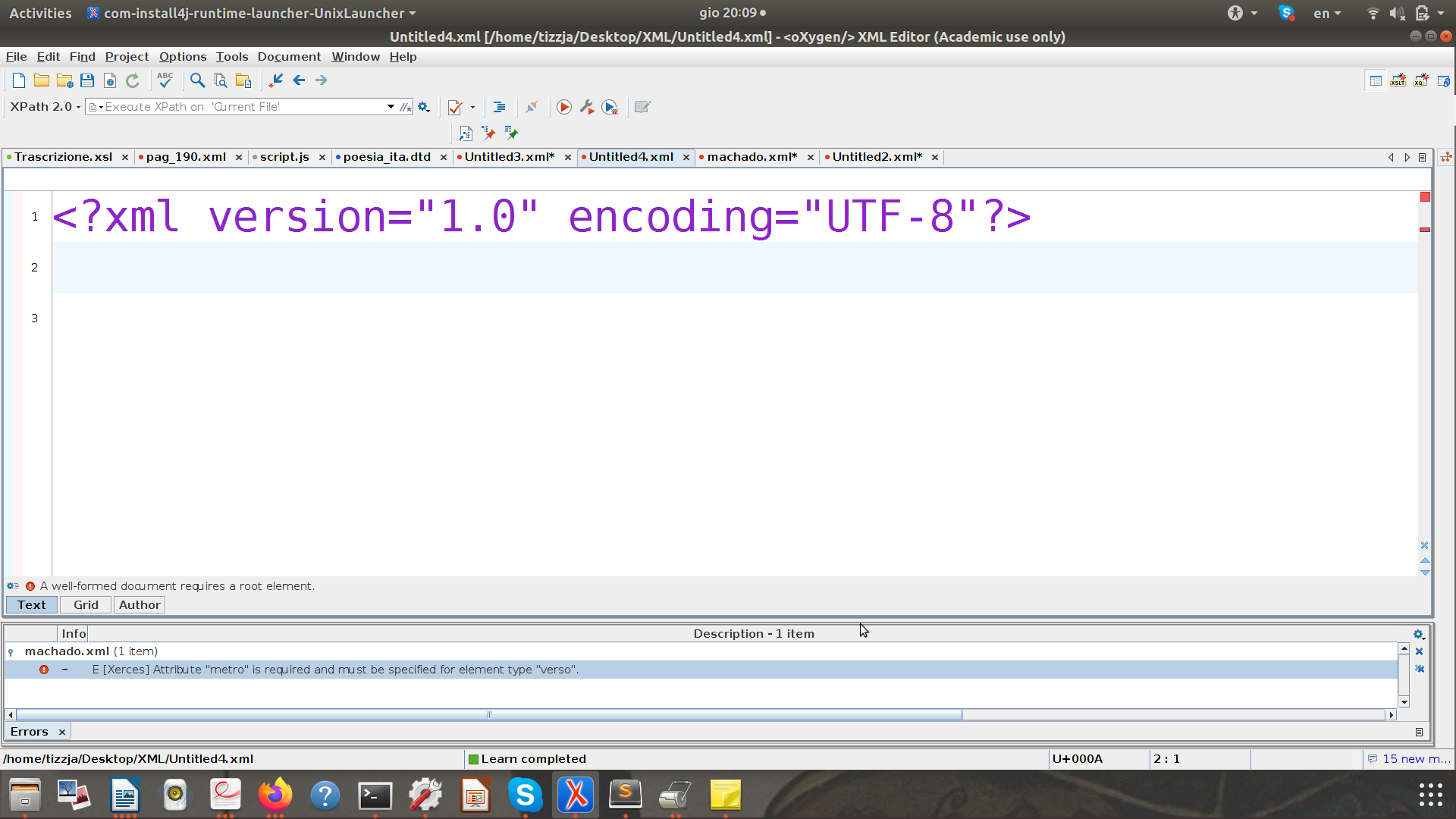
Dichiarazione XML: <?xml version="1.0" encoding="UTF-8"?>
È il primo tag che incontriamo.
Riassumiamo
Il secondo è un'istruzione che collega il file XML
al file dello SCHEMA
Riassumiamo
Il secondo è un'istruzione che collega il file XML
al file dello SCHEMA
Quali sono le fasi ?
scelta del testo
studio e analisi
creazione del
modello
scelta del
modello di edizione
scelta dei TAG TEI
Schema
XML/TEI
XSLT
(o altri linguaggi)
HTML
ePub
OUTPUT
La TEI - Text Encoding Initiative - è un consorzio di istituzioni internazionali, di ambito linguistico e letterario, con l'obiettivo di sviluppare standard per la codifica di testi umanistici e per promuovere e sostenere il loro uso per progetti istituzionali o di singoli individui.
TEI
Text Encoding Initiative
Nel sito della TEI possiamo trovare:
- Linee guida della TEI
- una serie di tool per la creazione di documenti TEI e stylesheets per la trasformazione in differenti formati (e.g. HTML, Word, PDF, Databases, RDF/Linked Data, Slides, ePub, Schemas, etc.)
Text Encoding Initiative
TEI
Text Encoding Initiative
http://www.tei-c.org/index.xml
schema
Database
XML
Ebooks
Json
HTML
Linked
data
TEI


Che cos'è la TEI?
Perché devo studiare uno SCHEMA creato da altri?
Cosa abbiamo detto sul markup?
- Markup è utilizzato per molti scopi e in campi differenti.
- Permette di creare risorse e rappresentare la conoscenza
- Ha il compito di rendere esplicito (alla macchina) cosa è implicito a una persona (disambiguazione)
- Facilita il riuso dei materiali:
- in differenti formati
- in contesti differenti
Cosa abbiamo detto sul markup?
- Ci impone di dare una struttura ai dati
- Permette di collegare informazioni, data, risorse
- Permette di selezionare aspetti del testo che ci interessano
- Aiuta a farci condividere le nostre risorse intellettuali attraverso un vocabolario comune
- Un markup descrittivo ci dà la possibilità di fare esplicite distinzioni per processare delle stringhe di caratteri
funzioni del markup
- Nominare, annotare, descrivere dei dati
- attraverso un linguaggio formale
- per poter riusare quei dati in forme diverse
- e condividere i nostri progetti con altre risorse
Cosa abbiamo detto su
XML (EXtensible Markup Language) ?
- Ha molti aspetti in comune con l'HTML ma non è HTML!
- Quali sono le differenze?
- è extensible
- Deve essere ben formato
- può essere validato
- è indipendente da software, programmi, piattaforme
Cosa abbiamo detto su
XML (EXtensible Markup Language) ?
Esiste un (e uno solo) elemento, detto elemento radice (corrispondente al nodo radice dell’albero), che non è contenuto da nessun altro e che contiene direttamente o indirettamente tutti gli altri
Ogni elemento, escluso l’elemento radice, deve essere contenuto da un solo elemento (elemento padre) e può contenere altri sotto-elementi (elementi figli) e/o stringhe di caratteri.
Esiste un sottoinsieme di elementi che non contengono altri elementi e che possono
- essere vuoti
- contenere esclusivamente stringhe di caratteri
come ci comportiamo con caratteri che xml non legge?
In linguaggi di markup quali HTML, XML e altri derivati dall'SGML, le entità (in inglese entity) sono una codifica (CODIFICA DI LIVELLO ) testuale usata per inserire alcuni caratteri speciali in maniera indipendente dalla tastiera e dal sistema operativo usato.
La loro forma generale è: "&" + codice identificativo + ";". Il codice identificativo può essere alfanumerico o numerico, basato sul relativo codice nel set di caratteri ASCII, nel qual caso "#" introduce un numero decimale e "#x" un numero esadecimale; per esempio: "è", "è" e "è" sono le tre codifiche della lettera "e" con l'accento grave (è).
Cosa abbiamo detto su
XML (EXtensible Markup Language) ?
La codifica degli attributi:
- Ogni elemento XML può avere uno o più attributi
- Un attributo ha un nome e un valore, che può assumere diverse tipologie
Cosa abbiamo detto su
XML (EXtensible Markup Language) ?
<text resp=“Italo Svevo” n=“Senilità”>
<div n=“1”>
<p id=“C1P1”>Subito, con le prime parole che le rivolse, volle avvisarla
che non intendeva compromettersi in una relazione troppo seria…</p>
<p id=“C1P2”>La sua famiglia? Una sola sorella non ingombrante né fisicamente
né moralmente, piccola e pallida, di qualche anno più giovane di lui…</p>
<pb n=“5”/>
Perché utilizziamo TEI?
TEI è un progetto internazionale che ha visto coinvolte le maggiori organizzazioni internazionali dedicate all'Informatica Umanistica
Qual È la strttura della tei?
tag root: TEI
<teiHeader>
<text>
Tutti i testi conformi alla TEI contengono:
una trascrizione del testo vero e proprio marcata con l'elemento <text>.
Una TEI <teiHeader>, da considerarsi il frontespizio del documento elettronico;
<TeiHeader>
L’intestazione elettronica TEI contiene informazioni analoghe a quelle contenute nel titolo della pagina di un testo stampato:
documentazione della responsabilità editoriale, dati bibliografici, metodologie adottate per la codifica, etc
oXygen prevede un "Framework Template" per lo SCHEMA della TEI
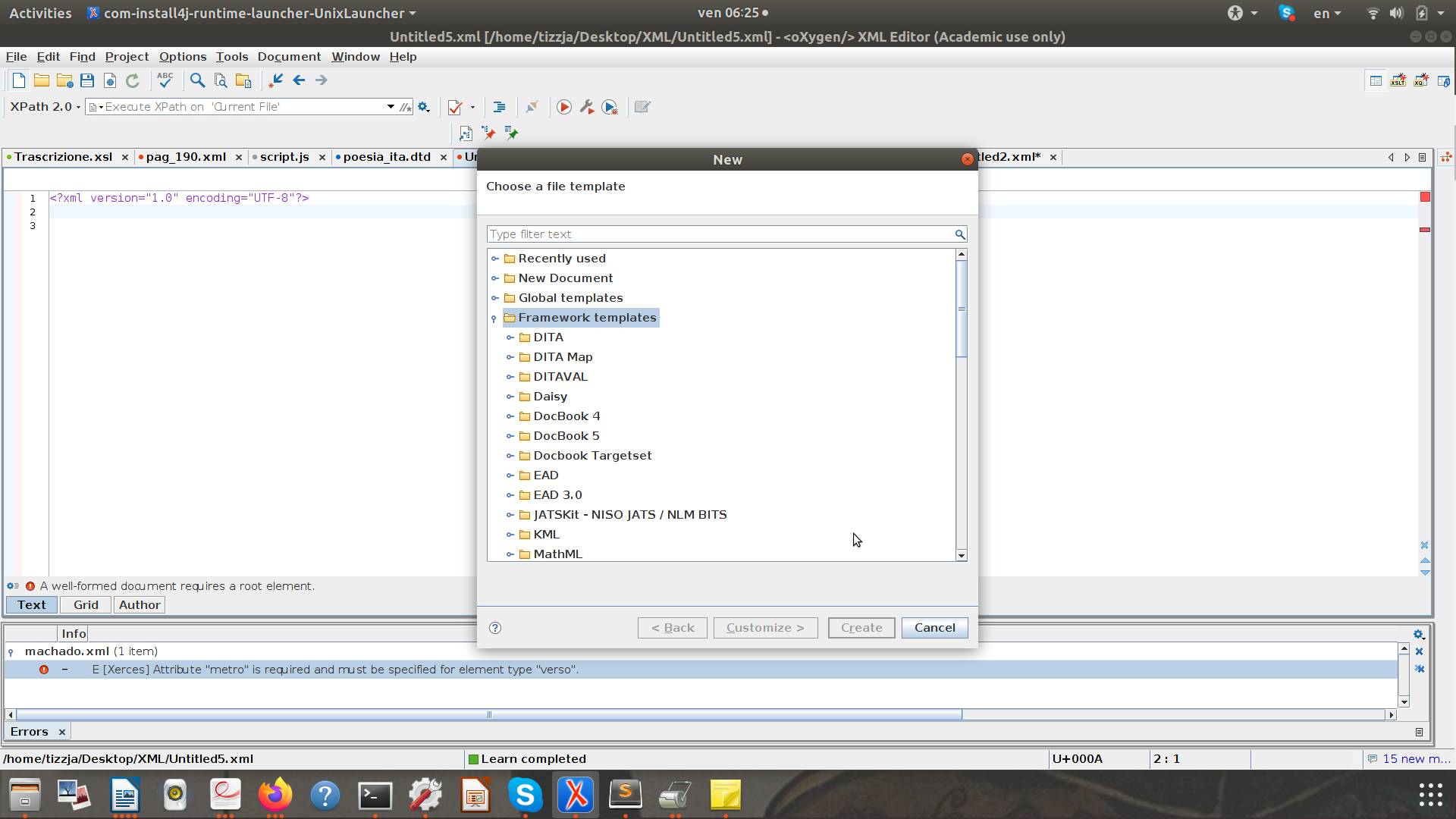
- Vai su "Nuovo" e clicca su "Framework templates"
oXygen prevede un "Framework Template" per lo SCHEMA della TEI
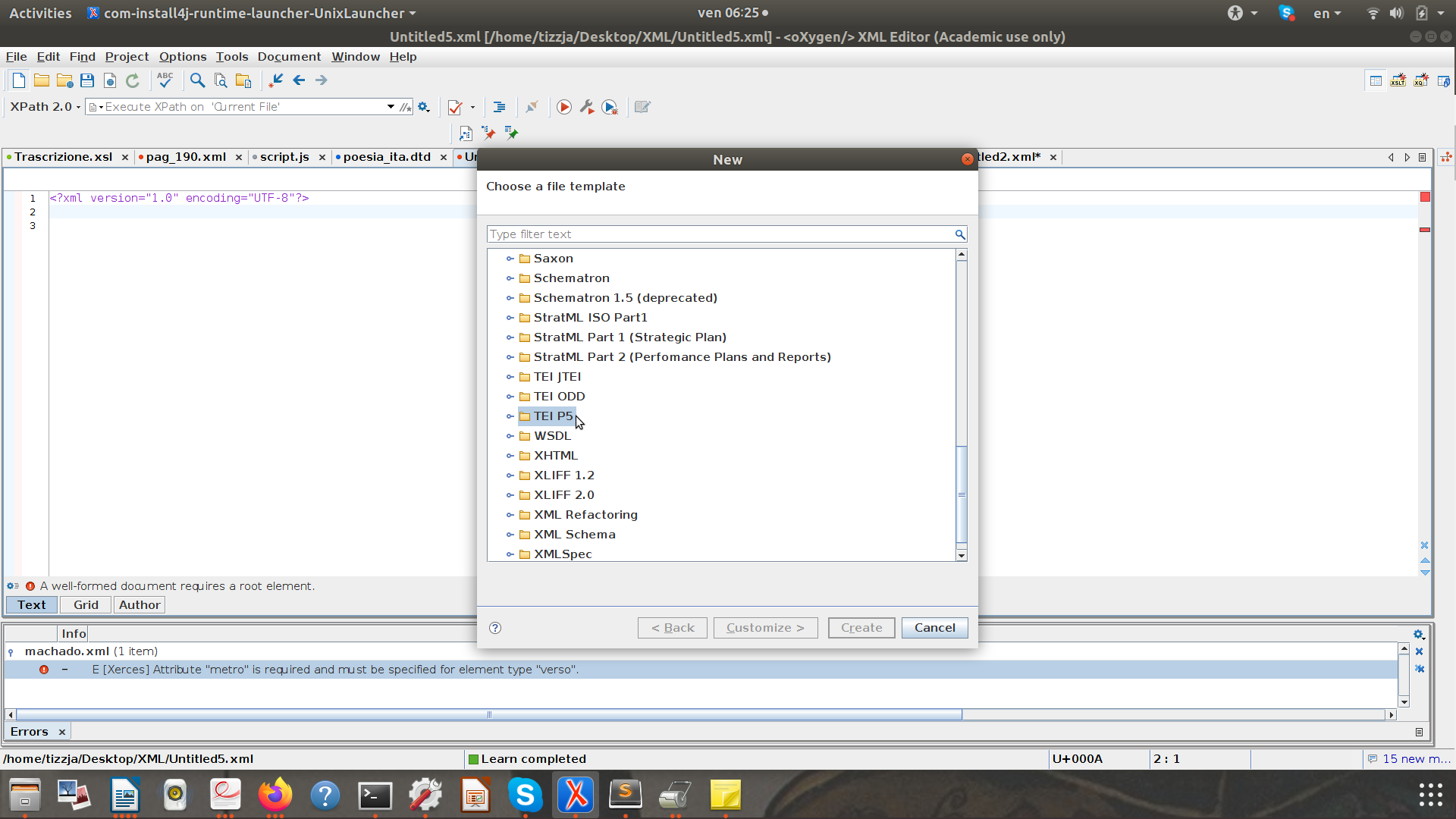
- Vai su "TEI P5"
oXygen prevede un "Framework Template" per lo SCHEMA della TEI
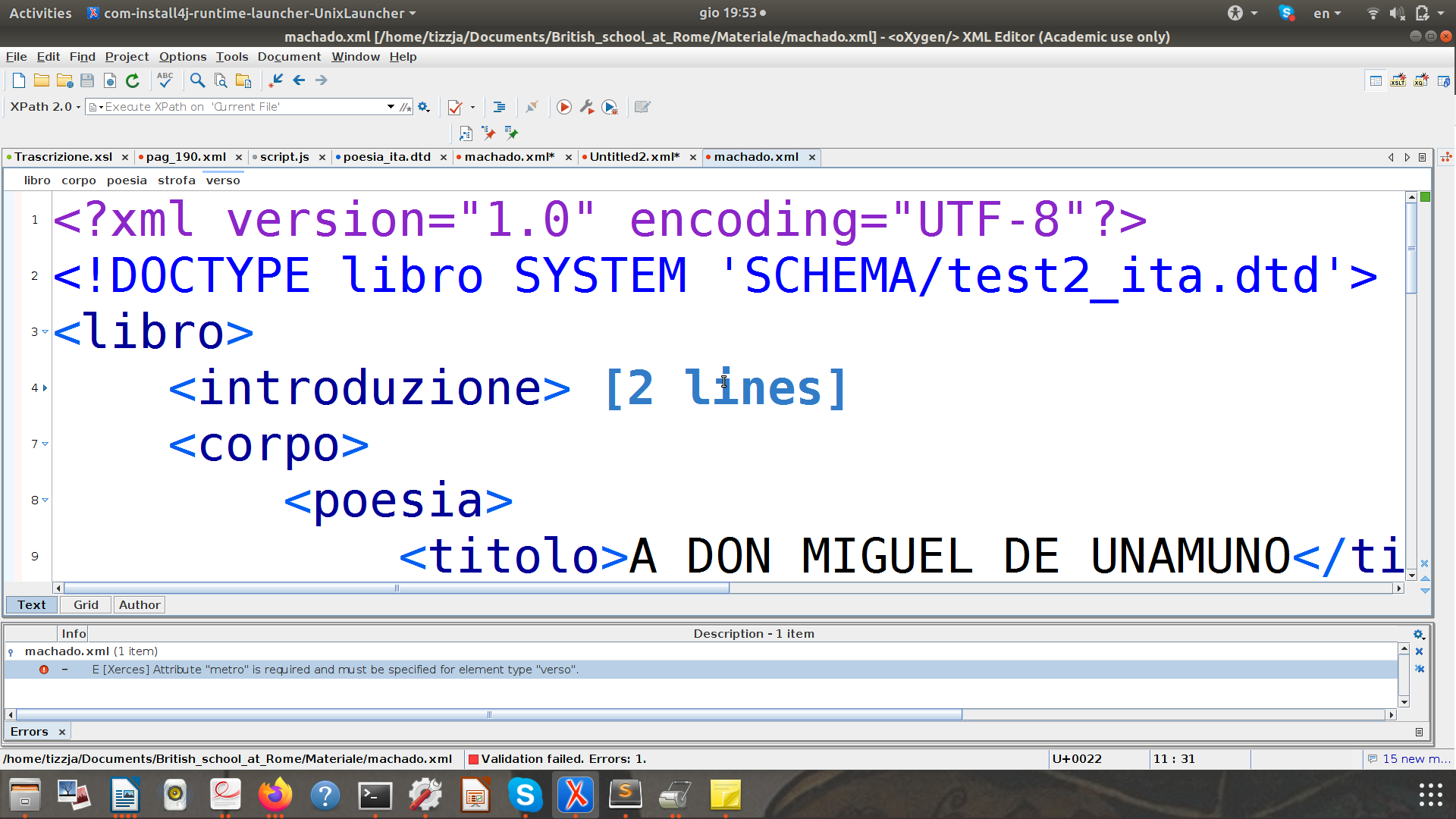
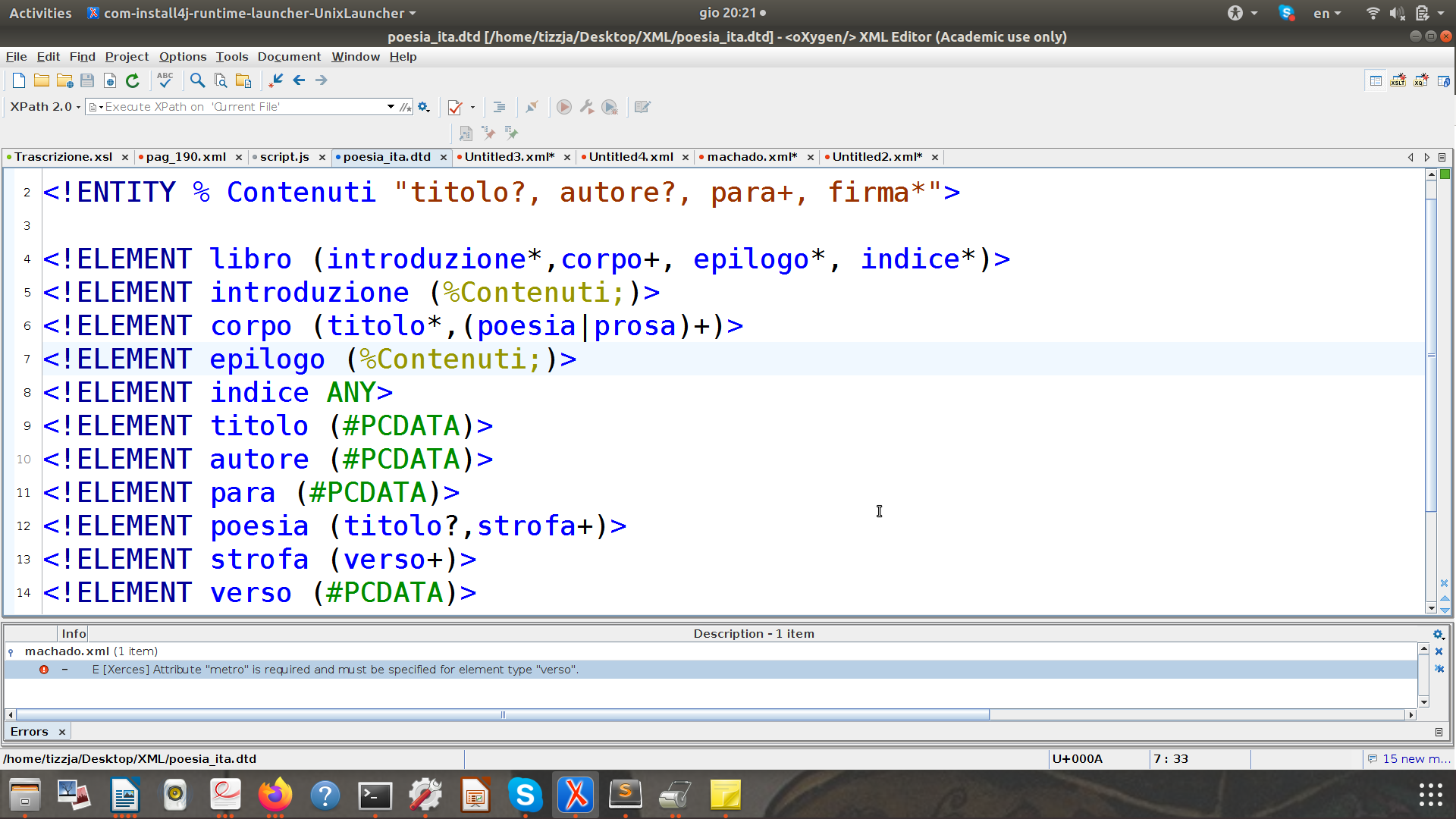
- Lo SCHEMA??????
Impariamo a utilizzare le linee guida e gli strumenti della tei!

La codifica di un testo lirico

- Quale modulo?
- E in che modo viene utilizzato quel tag?
La codifica di un testo lirico
<lg>
<l>There were eight pretty walkers who went up a hill;</l>
<l>They were Jessamine, Joseph and Japhet and Jill,</l>
<l>And Allie and Sally and Tumbledown Bill,</l>
<l rend="i10">And Farnaby Fullerton Rigby.</l>
</lg>Text
body
div type="poem"
div type="poem"
head
head
lg type="stanza"
lg type="stanza"
lg type="stanza"
lg type="stanza"
l n="1"
l n="1"
l n="2"
l n="3"
l n="2"
come fare uno "scenarios"

- click on the tool icon

2. Click on the format you would like to choose (HTML/PDF)
come fare uno "scenario"
3.
come fare uno "scenario"
3.
come fare uno "scenario"
Quando si ha un XSLT?
come fare uno "scenario"
Introduzione al IIIF
(The International Image Interoperability Framework)





perché è così importante il iiif per le edizioni digitali?

le immagini digitali continuano a ricoprire un ruolo prioritario sia per quanto concerne le collezioni digitali native sia per quanto attiene agli ingenti patrimoni analogici, con particolare attenzione all’ambito dei beni culturali, oggetto di innumerevoli campagne di digitalizzazione
perché è così importante il iiif per le edizioni digitali?
se l’immagine statica, in senso lato, si pone come un medium al momento insostituibile in un panorama generale di sviluppo delle digital libraries, rimangono del tutto aperte le questioni, in senso proprio, relative alle pratiche concrete di digitalizzazione, tanto in riferimento ai formati così come alle caratteristiche dei repositories nei quali esse sono conservate.
perché è così importante il iiif per le edizioni digitali?
In altri termini, ogni progetto digitale che comporti il trattamento di immagini persegue i propri obiettivi con specifiche soluzioni tecniche, ideate ed implementate ad hoc
perché è così importante il iiif per le edizioni digitali?

Ci troviamo, quindi, nella paradossale situazione di un mondo di immagini digitali sempre più ricco ma, al contempo, poco agevole da percorrere in modo trasversale
Text
che cos'è iiif?
Il progetto affonda le proprie radici nel sostrato biblioteconomico, a dimostrazione del fatto – se ce ne fosse ancora bisogno – che la vocazione e la tradizione dei bibliotecari a lavorare sulla base di procedure standardizzate e condivise, anche allo scopo di rendere agevole l’interscambiabilità dei dati, si rivela un valore fondamentale per lo sviluppo di risorse realmente condivisibili in Rete.
che cos'è iiif?
Ma veniamo alle caratteristiche portanti di IIIF e chiediamoci innanzitutto perché esso viene definito come ‘framework’. Il significato di questo termine nell’ambito dei sistemi informativi è stato declinato, volta per volta, in modi differenti: strumento, modello, standard, infrastruttura
che cos'è iiif?
l’obiettivo di IIIF consiste nell’elaborare un ambiente interoperabile in grado di permettere ai diversi software applicativi con cui si gestiscono le immagini digitali via Web
di poter dialogare reciprocamente in una modalità molto più efficace di quanto oggi non avvenga, in modo da fornire agli utenti “an unprecedented level of uniform and rich access to image-based resources hosted around the world”

che cos'è iiif?
Tradotta in pratica, la definizione di questo ambiente si concentra al momento su tre API destinate, in specifico, alla descrizione delle immagini, alla strutturazione dei repository e alle funzionalità di ricerca
che cos'è iiif?
un’API (acronimo di Application Programming Interface) è definibile come un insieme di procedure standardizzate che consente allo sviluppatore di un determinato software di
‘richiamare’ all’interno di esso parti di quei programmi con cui il software stesso deve interagire, risparmiandosi così la fatica di scrivere decine e decine di righe di codice per definire, ogni volta che se ne presenti la necessità, quelle routine di base comuni a tutte le applicazioni di un medesimo applicativo

che cos'è iiif?
La prima API sviluppata nell’ambito del progetto IIIF riguarda l’identificazione di un’immagine e delle sue specifiche attraverso una URI veicolata tramite i protocolli HTTP o HTTPS. Questa soluzione consente ad un client di ‘puntare’ ad un’immagine disponibile sul Web
che cos'è iiif?
richiedendo, contestualmente, la fornitura della medesima da parte del server con determinati parametri formali espressi in modo esplicito nella formulazione della stessa URI secondo questa sintassi:
{scheme}://{server}{/prefix}/{identifier}/{region}/{size}/{rotation}/{quality}.{format}
che cos'è iiif?
Una possibile URI derivante dall’applicazione di questi parametri si presenta in questo modo:
l’opportunità di poter usufruire di una URI che consenta non solo di identificare un’immagine ma una porzione di essa, restituibile con diversi parametri di dimensione e cromia
che cos'è il manifest iiif?
‘Manifest’ rappresenta la descrizione complessiva dell’oggetto digitale e, quindi, contiene tutte le informazioni utili per la sua identificazione e per poter correlare in maniera corretta i diversi componenti; 14 ‘sequence’, come ovvio, indica la sequenza di default (ed eventualmente le altre possibili diverse sequenze) con cui l’oggetto digitale risulta percorribile;
http://iiif.bodleian.ox.ac.uk/iiif/image/ec27d96e-d8dc-40a3-a205-1c0ad732949a/info.json
ELEMENTO <FACSIMILE>
<facsimile> contiene una rappresentazione di una qualche fonte scritta sotto forma di una serie di immagini piuttosto che di testo trascritto o codificato [11.1 Digital Facsimiles]
ELEMENTO <PB>
<pb> (interruzione di pagina) indica il limite tra una pagina di un testo e la successiva in un sistema di riferimento standard [3.10.3 Milestone Elements]
ESERCIZIO 2

-
Omissione
LA TRASCRIZIONE: un modo particolare di lettura del testo?
<gap extent="1" unit="word" reason="illegible"/>LA TRASCRIZIONE: un modo particolare di lettura del testo?
<choice>
<orig>ę</orig>
<reg>ae</reg>
</choice>
Elements Available in All TEI Documents -- Example
.
An <choice>
<corr cert="high">Autumn</corr>
<sic>Antony</sic>
</choice>
it was, That grew the more by reaping
.
.
the <choice>
<expan>World Wide Web Consortium</expan>
<abbr>W3C</abbr>
</choice>
.
.
...how godly a <choice>
<orig>dede</orig>
<reg>deed</reg>
</choice>
LA TRASCRIZIONE: un modo particolare di lettura del testo?
<subst><del>vindicatus est et</del>
<add hand="#Bh2" place="margin">venenum
<choice><abbr>datū</abbr>
<expan>datu<ex>m</ex></expan></choice>MSdescriprion
La codifica <msDesc>
<msContents>: una lista delle informazioni e note sul manoscritto
<physDesc>: informazioni sugli aspetti fisici del documento
<history>: fornisce la storia del manoscritto
MSdescriprion
Text
<msIdentifier>
<country>United States of America</country>
<region>Texas</region>
<settlement>Austin</settlement>
<institution> The University of Texas at Austin </institution>
<repository>Harry Ransom Centre</repository>
<collection>Wilfred Owen Collected Letters</collection>
<idno type="folio">ff504</idno>
<altIdentifier>
<idno>Letter no. 535 Ed. 'Wilfred Owen Collected Letters'</idno>
</altIdentifier>
<msName>Letter to Leslie Gunston</msName>
</msIdentifier>MSdescriprion
Text
<msIdentifier>
<country>United States of America</country>
<region>Texas</region>
<settlement>Austin</settlement>
<institution> The University of Texas at Austin </institution>
<repository>Harry Ransom Centre</repository>
<collection>Wilfred Owen Collected Letters</collection>
<idno type="folio">ff504</idno>
<altIdentifier>
<idno>Letter no. 535 Ed. 'Wilfred Owen Collected Letters'</idno>
</altIdentifier>
<msName>Letter to Leslie Gunston</msName>
</msIdentifier>MSdescriprion
<objectDesc>: sulla descrizione fisica
<handDesc>: quali sono gli strati di scrittura
MSdescriprion
<objectDesc>: sulla descrizione fisica
<handDesc>: quali sono gli strati di scrittura
MSdescriprion
Text
<objectDesc form="codex">
<supportDesc material="mixed">
<p>Early modern <material>parchment</material> and
<material>paper</material>.</p>
</supportDesc>
<layoutDesc>
<layout columns="1" ruledLines="25 32"/>
</layoutDesc>
</objectDesc>MSdescriprion
Text
<handDesc hands="2">
<handNote xml:id="Eirsp-1" scope="minor" script="other">
<p>The first part of the manuscript,
<locus from="1v" to="72v:4">fols 1v-72v:4</locus>, is
written in a practised Icelandic Gothic bookhand. This hand
is not found elsewhere.</p>
</handNote>
<handNote xml:id="Eirsp-2" scope="major" script="other">
<p>The second part of the manuscript,
<locus from="72v:4" to="194v">fols 72v:4-194</locus>, is
written in a hand contemporary with the first; it can also
be found in a fragment of <title>Knýtlinga saga</title>,
<ref>AM 20b II fol.</ref>.</p>
</handNote>
</handDesc>MSdescriprion
Text
<physDesc>
<objectDesc form="folio">
<supportDesc material="paper">
<support>A single folio of <material>paper</material> in
the collection as ff504 recto and verso</support>
</supportDesc>
<layoutDesc>
<layout columns="1" writtenLines="20">Written full width
as a single column, with approximately 20 lines per
page</layout>
</layoutDesc>
</objectDesc>
<handDesc hands="1">
<handNote>Written in <persName ref="#WO">Wilfred
Owen's</persName> hand.</handNote>
</handDesc>
</physDesc>PersName
<rs> ("referring string") -- qualsiasi frase che si riferisce a una persona
‘the girl you mentioned’, ‘my husband’...
<name> - qualsiasi nome
‘Siegfried Sassoon’ , ‘Calais’, ‘John Doe’ ...
<persName>, <placeName>, <orgName>: ‘syntactic sugar’ for
<name type="person"> etc.
<surname>, <forename>, <geogName>,
<geogFeat> etc.
PersName
Dove descrivo questi elementi?
PersName
1. Nella TeiHeader TEI > teiHeader > profileDesc > particDesc
aggiungi l'elemento <listPerson> </listPerson>
persName
2. Aggiungi l'elemento <person> nella lista <listPerson>:
<person xml:id="[ID]">
<persName>[NAME]</persName>
<birth>[BIRTH]</birth>
<death>[DEATH]</death>
<socecStatus>[STATUS]</socecStatus>
<note type="Biographical">[NOTE]</note>
</person>