HADOOP
Software Libre para BIG DATA

@tdelvechio
tomasdelvechio17@gmail.com
aviso
Las presentes slides son una integración y traducción libre y personal de muchas otros trabajos (webs, blogs, artículos, diapositivas, libros, imágenes, etc...) que circulan por la web.
La intención es utilizarlos para fines estrictamente educativos, y se intento citar la fuente debidamente en cada caso. Cualquier error al respecto, será reconocido y modificado ante el correspondiente aviso.
Que es Hadoop
"The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models."
[HAD,2014]
QUE ES HADOOP
A scalable fault-tolerant distributed system for
data storage and processing (open source
under the Apache license).
[CLO, 2011]
que es hadoop
Hadoop provides a distributed file system and a framework for the analysis and transformation of very large data sets using the MapReduce paradigm.
EN DEFINITIVA, ¿QUE ES HADOOP?
Un sistema distribuido que propone una
metodología de desarrollo y procesamiento
que facilita la escalabilidad de aplicaciones.
Provee un Filesystem para el almacenamiento de datos y un modelo de programación para el procesamiento de los mismos.
Proyecto hadoop
escalabilidad
Capacidad de crecer sin la necesidad de reimplementar la arquitectura o algoritmos de la aplicación. [CLO,2011]
Hadoop es un producto que escala.
Especificamente, provee escalabilidad horizontal.
¿Para que escalar?
HadooP: elementos
- Cluster dedicado
- Commodity Hardware (Miles de nodos)
- Las fallas de HW son regla, no excepción
- Aplicaciones trivialmente paralelizables
- Procesamiento Batch, no online (en principio)
- Procesamiento en escala de Tera o Petabytes
- Mover datos es caro
- Mover computo es barato
schema-on-write (Rdbms)
- Esquema previo a la carga de los datos
- Los datos son transformados y cargados a la estructura interna de la DB de forma explicita
- Nuevas columnas deben agregarse previamente a que los datos puedan almacenarse en la DB
Schema-on-read (Hadoop)
- Los datos son copiados al FS, sin cambios
- Una serialización tiene lugar al momento de la lectura
[CLO,2011]
ORIGENES DE HADOOP
El proyecto Apache Nutch (Web Crawler) necesitaba estructuras y capacidad de procesamiento masivas.
En 2003 y 2004 se publican los artículos de MapReduce y GoogleFS, que serán los fundamentos de HADOOP.
En 2006 es fundado el proyecto Hadoop.
Yahoo! es uno de los actores que mas aportes realizo a que Hadoop sea lo que es hoy. En 2010, el 80% del código fuente del core de Hadoop era aportado por Yahoo! [SHV,2010]
Tecnologías subyacentes
- Java
- SSH
- MapReduce [DEA,2004]
-
GFS [GHE,2003]
casos de usos conocidos
Grep distribuido
Sort distribuido
Recorrido de grafos
Análisis de logs
Indexación invertida
Otros mencionados:
Doc clustering
Machine learning
Machine Translation
[DRO,2008]
Data Science - Big Data - IA
¿donde encuentro hadoop?
versiones de hadoop
Hadoop 1 (Old-Stable)
MapReduce - HDFS
Hadoop 2 (Actual)
YARN - HDFS
hadoop versions

http://drcos.boudnik.org
versiones (mas sencillo)
http://drcos.boudnik.org
Arquitectura de hadoop
3 componentes principales del Framework
-
Hadoop Common: Un conjunto de librerías y utilidades genéricas.
-
MapReduce (YARN en V2): Servicio para procesamiento distribuido.
- HDFS: Servicio para FS Distribuido con el objetivo de obtener un alto throughput en el acceso (read) a datos.
Hadoop responde a una arquitectura Master/Slave
(Para cada uno de los servicios que ofrece)
Arquitectura de alto nivel
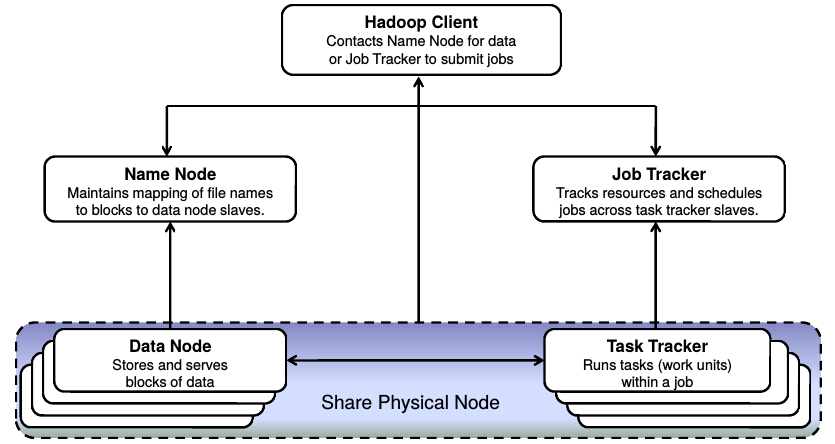
Hadoop 1
arquitectura en HADOOP 2

Hadoop 2
ALGO Mas sobre LA arquitectura
Por defecto solo hay un nodo Master,
que contiene los Masters de YARN
(ResourceManager) y de HDFS (NameNode).
Los Esclavos Incluyen los servicios esclavos de YARN (NodeManager) y de HDFS (DataNode)
HDFS
Sistemas de archivos distribuido
Orden de magnitud
Decenas de miles de nodos (al 2011)
Petabytes de almacenamiento
commodity hardware
Redundancia mediante replicación
Manejo de fallas y recuperación
Low-cost Hardware
Coherencia de datos
Modelo "Write once, read many"
Solo soporta "append" para archivos existentes
Localidad de datos
HDFS ofrece al framework un conocimiento de la ubicación
de los datos que ningún otro DFS proporciona de forma directa.
A pesar de esto, es posible trabajar con otro DFS.
Espacio de nombres único del cluster
chunks de archivos (bloques)
- Bloques entre 64Mb (default) a 256Mb (Configurable)
- Bloques distribuidos sobre nodos
- 1 Archivo consiste en B bloques distribuido en N nodos
- Los Bloques se REPLICAN, y estas replicas se distribuyen
hdfs puede usarse con mapreduce
o como un dfs stand-alone
arquitectura Master/slave

NAMENODE (Master)
- Gestiona el NameSpace del FS
- Mapea nombre de archivos a bloques
- Mapea bloques a DataNodes
- Configuración del cluster
- Gestiona la replicación
datanodes (Slaves)
- Servidor de Bloques
- Almacena los datos en el FS local
- Almacena metadatos de los bloques (Hash)
- Sirve metadatos a los clientes
- Provee pipelines a otros DataNodes.
hdfs blocks y replicacion

hdfs blocks
- 1 Archivo es dividido en bloques de 64Mb por default
- Los bloques se replican en el cluster, por default 3 replicas
- HDFS esta optimizado para:
- Alto Throughput en Read
- Appends
- La replicación se realiza buscando:
- Durabilidad
- Disponibilidad
- Throughput
- Los bloques se distribuyen en los nodos y racks (rack-aware)
HDFS BLOCKS y Replicas (EJemplo)
HDFS Architecture
Conceptos y elementos básicos del DFS [SHV,2010]
Namenodes
- Namespaces: Archivos y Carpetas
- inodes: Representa un elemento con sus atributos
- Archivos, Bloques.
- Información de replicación.
- Mapeo de Bloques a DataNodes.
- Mantiene el NameSpace en memoria principal -> Es el limite del cluster.
datanodes
- Contienen las replicas de los bloques. Una replica son dos archivos: Datos y metadatos.
- Almacenamiento optimizado.
- Startup: Handshake, Namespace ID y version. Registro. Storage ID persistente.
- Block Reports: Regularmente desde DN hacia NN.
- Heartbeats: Para saber la disponibilidad de nodos y sus bloques. 3 segundos. Mas de 10 minutos, se marca como no disponible. También agrega información del DN.
- Si un DN sale del cluster, el NN comienza a replicar los bloques para mantener el factor de replicación.
HDFS Client
- Implementa la interfaz de acceso a HDFS
- Operaciones básicas de I/O FS.
- Namespace jerárquico
- Abstrae la complejidad del cluster
- API HDFS para MapReduce

otros componentes
Image - Journal - Checkpoint

CHECKPOIntnode
Proceso de creación de CKP periódico
Nodo dedicado.
backupnode
Opera de forma similar al NameNodePermite que el NameNode no necesite persistir los cambios
snapshot
Creado a demanda (Por el administrador del cluster)
Propósito de backup previo a migración de versión.
Persiste TODO el FS (no solo los metadatos)
hdfs operations
Como trabaja HDFS [GAR,2013]
HDFS READS en hadoop 1

HDFS writes en hadoop 1

HDFS READS en hadoop 2

HDFS writes en hadoop 2

Map reduce (v1)
Framework de procesamiento masivamente paralelo
map reduce
- Entorno para distribuir procesamiento de forma masiva
- Ofrece un modelo de programación (MapReduce)
- Funciones de procesamiento provistas por el usuario
- Mappers y Reducers
- El computo hacia los datos, no al revés
- Usa los bloques del DFS, e intenta que sea un Map por Bloque
- Por defecto es Java, aunque es posible usar otros lenguajes
- Es independiente de HDFS
QUE problemas aborda mapreduce
Jobtracker y tasktrackers
jobtracker (master)
- Contiene metadatos del Job (trabajo en ejecución)
- Estado del job
- Estado de las Tasks corriendo en TaskTrackers
- Decide el "Schedule"
Tasktrackers (slaves)
- Recibe trabajo desde el JT
- Solicita el codigo a ejecutar
- Aplica configuraciones propias del Job
- Comunicacion con el JT:
- Envia salida, mata tasks, actualiza tasks
limitaciones en hadoop 1 [GAR,2013]
- Limites de 4.000 nodos por cluster
- Complejidad O(#tasks en cluster)
- JobTracker es un cuello de botella
- Gestiona recursos
- Planifica Jobs
- Monitorización
- HDFS tiene un único espacio de nombres
- Slots Map y Reduce estáticos
- Limitado a un esquema MapReduce
Map reduce (v2): YARN
Evolucion de MapReduce. Scheduler genérico.YARN
Mas que un cambio de nombre. Scheduling de tareas en paralelo generalizado. MapReduce es un caso particular.

[HOR,2014]
¿Por que YARN?

CARACTERISTICAS
hadoop 2 [GAR,2013]
- Estimado en 10.000 nodos por cluster
- Multiples namespaces en HDFS
- Eficiencia en utilización del cluster
- Debido a YARN
- Compatible con las aplicaciones MRv1
mapreduce core
Como realiza el procesamiento con MapReduce
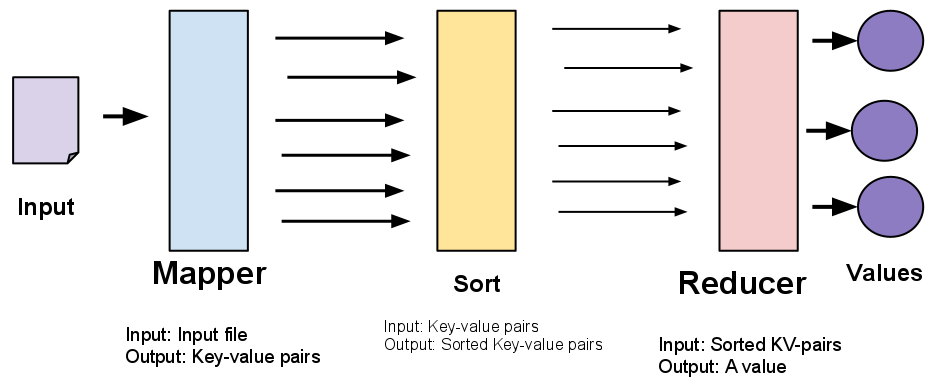
Como funciona mapreduce
Existen 2 fases: El Map y Reduce.
Pero esto es una abstracción para los desarrolladores.
Los desarrolladores 'solo' programan un map y un reduce.
El framework trabaja por nosotros:
- Antes de ejecutar el Map
- Entre las etapas de Map y Reduce
- Después del Reduce
mapreduce [DEA,2004]
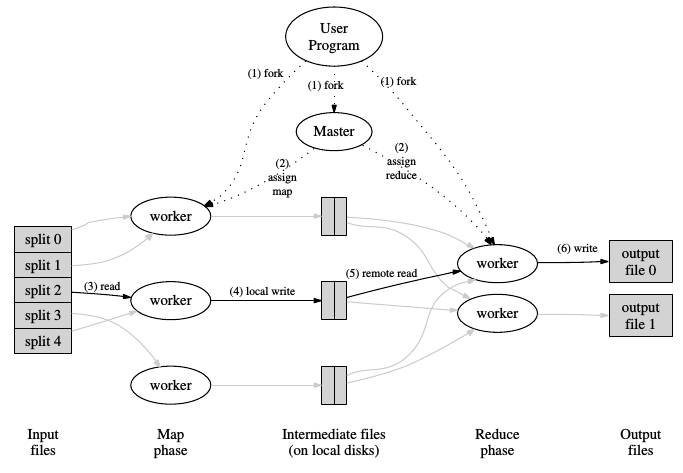
hadoop mapreduce (overview)
http://www-inst.eecs.berkeley.edu/~cs61a/sp12/labs/lab14/mapreduce_diag.png
mapreduce en hadoop

http://escience.washington.edu/sites/default/files/images/hadoop_web_0.jpg
mapreduce stages (wordcount)
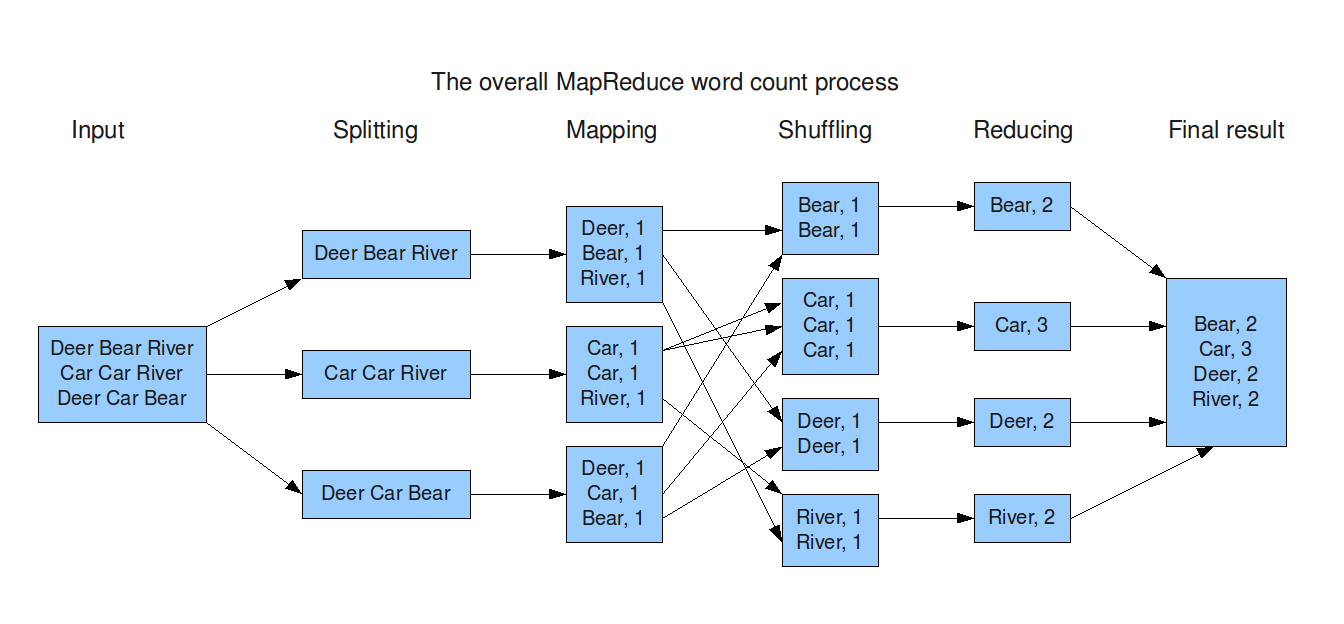
http://devveri.com/wp-content/uploads/2012/07/mapreduce.png
¿Cuantos procesos MAPs? [MCT,2011]
- Relacionado con el tamaño de la entrada
- Un correcto nivel de paralelismo de map se da entre 10-100 Maps/nodo (Es empírico, no teórico).
- Ejemplo: 10TB de Input y HDFS tiene un tamaño de bloque de 128MB:
10TB = 10.485.760 MB
10.485.760 MB / 128 MB por Map = 81.920 ~ 82.000 Maps
Para tener 100 maps por nodo,
82.000 maps / 100 maps por nodo = 820 nodos
MAPREDUCE OPERATIONS
Como trabaja MapReduce [GAR,2013]
ejecutando trabajos en hadoop 1

ejecutando trabajos en hadoop 2

Proyectos asociados
Pig: Lenguaje de alto nivel para análisis de datasets
Hive: Para DataWarehouse
HBase: Base de datos distribuida
Cassandra: NoSQL Database
Muchos mas...
limitaciones o alcance
- No existe control nativo sobre el orden de ejecución de cada map o reduce.
- Para alcanzar el máximo paralelismo, no se puede depender de datos generados durante una misma ejecución de una aplicación MapReduce.
- Un SGBD con un indice sera mas veloz que un job Hadoop sin indices.
- Los reducers no inician el procesamiento hasta que la fase de map finaliza completamente. Conceptualmente, antes de iniciar los reducers se establece un punto de sincronización.
- La salida de los Reduce debe ser pequeña comparada con la entrada a los Maps. Empíricamente se utiliza la regla de "Una App MapReduce lee mucho mas de lo que escribe".
conclusiones
lo bueno
- Procesamiento y almacenamiento a (muy) gran escala
- Consumo local de datos (por nodo), mediante la API
- Archivos grandes (Bloques de al menos 64Mb)
- Archivos pequeños: Inicialmente no, pero ver HAR
- Proyecto muy activo.
- 2 releases "grandes" en lo que va de 2015.
conclusiones
lo malo
- La instalación y gestión de un cluster propio no es trivial
- JAVA dependiente en la infraestructura
- Documentación MUY dispersa
- Desactualizada muchas veces (La mitad de las búsquedas en google hacen referencia a la API Hadoop V1).
- Limitado a aplicaciones paralelizables
- Sin estado
- ¿Obsoleto?
- Storm, Spark
- [ROT,2014]
Soporte online
Comunidades muy activas
general@hadoop.apache.org -> Lista de correo de anuncios
user@hadoop.apache.org -> Lista de usuarios de hadoop
StackOverflow: Suscripcion a los Tags
"Hadoop", "Hadoop 2", "Map Reduce"
Blogs, sitios, Cloudera, Hortonworks...
Referencias (1)
[HAD,2014]: Apache Hadoop Official Web. Enlace.
[CLO,2011]: Amr Awadallah. "Introducing Apache Hadoop: The Modern Data Operating System".
Stanford EE380 Computer Systems Colloquium. 2011. Enlace.
[HAL,2009]: A. Halevy et al, “The Unreasonable Effectiveness of Data”, IEEE Intelligent Systems, March 2009. Enlace.
[HOR,2014]: Hortonworks Project. YARN.
[LAM,2011]: Evert Lammerts. "Large-Scale Data Storage and Processing for Scientists in The Netherlands". NBIC BioAssist Programmers Day. 2011. Enlace.
[DRO,2008]: Isabel Drost. "Apache Hadoop. Large Scale data processing". 2008.
[DEA,2004]: Dean, J. Et. all. "MapReduce: Simplified Data Processing on Large Clusters". OSDI. 2004. Enlace.
referencias (2)
[GHE,2003]: Ghemawat, S. Et. all. "The Google File System". ACM. 2003. Enlace.
[MCT,2011]: McTaggart, C. "Hadoop MapReduce". CSCI 5448 Course. 2011. Enlace.
[ROT,2014]: Rotem-gal-oz, A. "Is there a future for Map/Reduce?". DZone.com. 2014. Enlace.
[GAR,2013]: Garcia, M. "Hadoop 1.X vs Hadoop 2". Hortonworks. 2013. Enlace.
[SHV,2010]: Shvachko, K. Et. all. "The Hadoop Distributed File System". IEEE. 2010.
[WHI,2012]: T. White, Hadoop: The definitive guide, 2012.
[BON,2015]: Marko Bonaci. The history of Hadoop. Medium. 2015. Enlace.