Big Data y Construcción de Índices con Restricción de Recursos
Big Data
Son procesos, herramientas y técnicas que tienen por objetivo el tratamiento de volúmenes de información de fuentes diversas que no es viable procesar en dispositivos individuales en tiempos adecuados para los procesos de las organizaciones.
Big Data: Caracterización
- Volumen - Cantidad de datos disponibles
- Variedad - Fuentes de datos diversas
- Veracidad - Confiabilidad de los datos
- Velocidad - Resultados en tiempos cada vez mas cortos
Plataformas



Recuperación de Información
Técnicas de resolución de necesidades de información sobre colecciones de documentos sin estructura
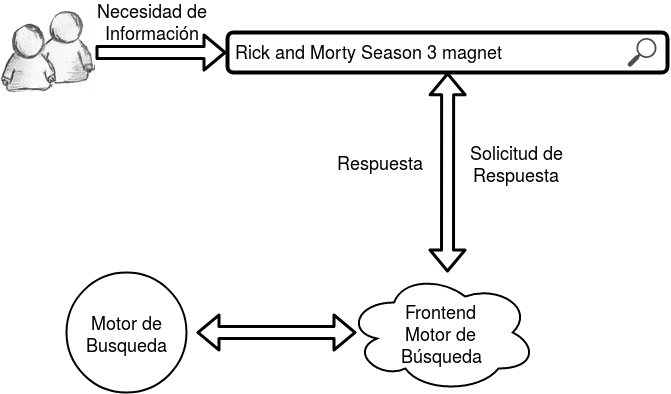
Terminología
Cluster
Procesamiento Distribuido
Indice Invertido / Posting List
Commodity Hardware (siguiente slide)
Colección de documentos
Escalabilidad vertical y horizontal
Commodity Hardware
- Contexto de disponibilidad de recursos limitada
- No se puede recurrir a la nube por cuestiones de costos o legales
- Hardware económico en Argentina no es lo mismo que en USA o Europa
- La solución es mejorar la configuración y el uso de recursos en lugar de agregar mas "fierro"
Trabajo Final
CONSTRUCCIÓN DE ÍNDICES
PARA DATOS MASIVOS
Objetivos
- Implementar algoritmos de indexación en un entorno distribuido de hardware económico y prestaciones limitadas.
- Probar el comportamiento de un cluster con plataformas usadas en Big Data en tareas intensivas de creación de índices.
- Medir la eficiencia de un algoritmo diseñado para MapReduce para procesar una colección de documentos con diferentes configuraciones de la plataforma.
Áreas de interés
- Construcción de estructuras distribuidas
- Técnicas de procesamiento masivo de datos
- Compresión de datos
- Impacto de la configuración de parámetros en plataforma de procesamiento
Áreas de interés
- Estrategias de distribución de datos y procesamiento
- Estrategias de monitorización de procesos distribuidos
- Impacto del Hardware disponible en el proceso
- Diseño de algoritmos de indexación que contemplen y se adapten a la plataforma
Áreas de interés
- Todos los procesos de Recuperación de Información en un contexto de recursos distribuidos
- Recorrido de colecciones
- Análisis de documentos y construcción de indices en memoria y disco
- Distribución del Índice en el cluster para soportar búsquedas avanzadas