
Kim Lab
Journal club discussion
Disclaimer: I'll present a lot of suggestions from the paper, but I'll also discuss other points surrounding this topic and share my personal experience/opinionated practices.

already doing a lot of computation in their research/
software developers
new to scientific computing
- Manage data: saving both raw and intermediate forms, documenting all steps, creating tidy data amenable to analysis.
- Software: writing, organizing, and sharing scripts and programs used in an analysis.
- Collaborate: making it easy for existing and new collaborators to understand and contribute to a project.
- Organize: organizing the digital artifacts of a project to ease discovery and understanding.
- Track changes: recording how various components of your project change over time.
- Manuscripts: writing manuscripts in a way that leaves an audit trail and minimizes manual merging of conflicts.
Outline
1. manage data
save & back up raw data
- read-only permission
- hard drive
-
cloud computing resources
- Amazon S3
- Google Cloud Storage
- Microsoft Azure
use meaningful names for files, variables
(even objects in code)
ISO 8601
2019-08-22
2020-06-11_good-enough-practices.pdf
2020-06-10_paper-thumbnail.png
01.download-data.ipynb 02.process-data.ipynb 03.visualize-data.ipynb
record all the steps used to process data
#!/bin/bash
FILES=$(ls reformatted-data/train/hibachi*)
for fname in $FILES; do
echo "Processing $fname file..."
# run mbmdr on each file
for dimension in 1D 2D 3D; do
./mbmdr-4.4.1-mac-64bits.out \
--binary \
-d $dimension \
-o "${fname%.*}_output_$dimension.txt" \
-o2 "${fname%.*}_model_$dimension.txt" \
"$fname" > /dev/null 2>&1
done
done
mv -f reformatted-data/train/*_1D.txt results/
mv -f reformatted-data/train/*_2D.txt results/
mv -f reformatted-data/train/*_3D.txt results/
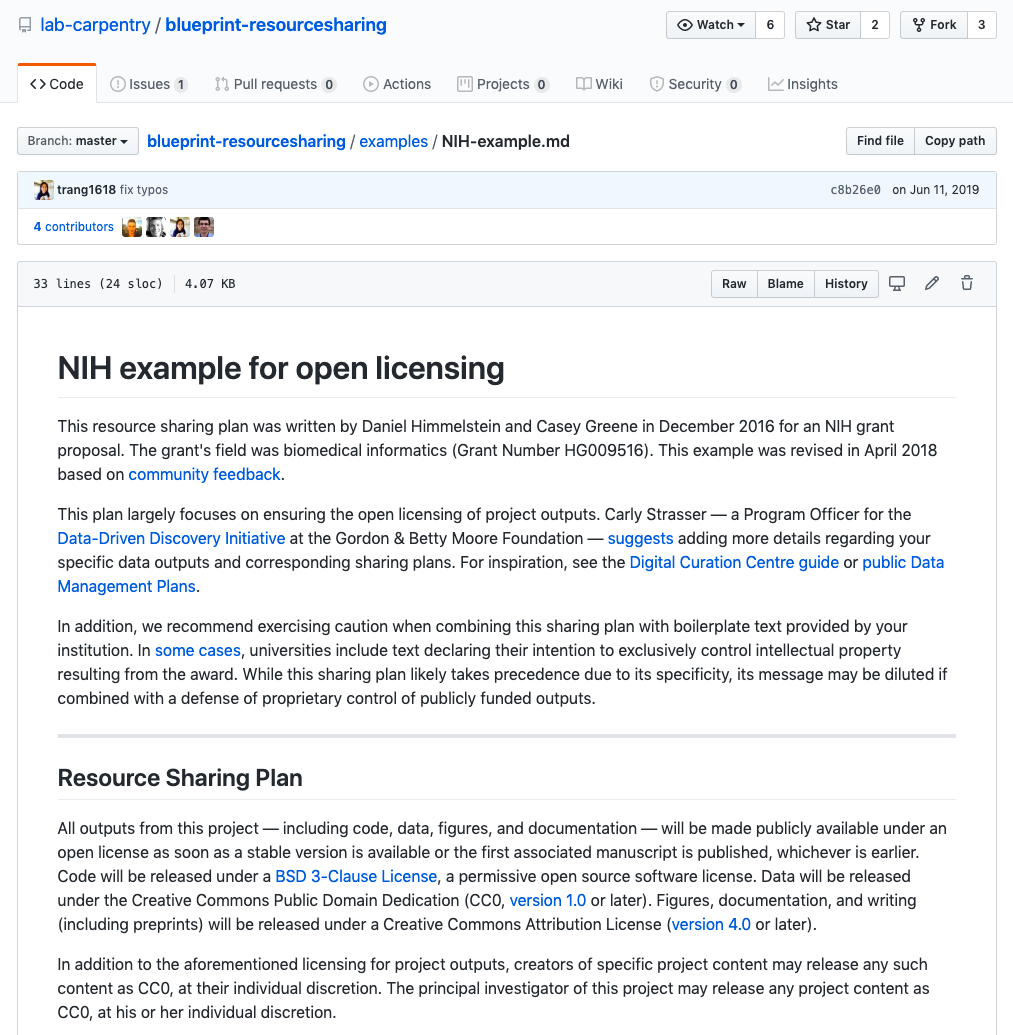
submit data to a reputable
DOI-issuing repository
(FigShare, Zenodo)
save intermediate data in R with .Rdata
- release data under an open license
- University researchers: commit to open in your resource sharing plan
I use CC0
2. software
readable
reusable
testable
- documentation
- functions
- utilize existing libraries
- know your IDE shortcuts (tab completion)
- release your software under an open license (I use MIT)
- submit code to a reputable
DOI-issuing repository
3. collaborate
- Create an overview of your project (3a).
- README
- CONTRIBUTING guide
- Create a shared "to-do" list
- GitHub issues
- agree on LICENSE
- Lack of an explicit license does not mean there isn't one;
it implies the author is keeping all rights and others are not allowed to reuse or modify the material.
- Lack of an explicit license does not mean there isn't one;
4. organize
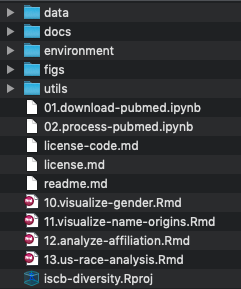
project folder

.svg, .png, .eps
.html
.R, .py
Dockerfile
raw/ processed/ metadata/
can be under
src/ scripts/
etc.
Do not use sequential numbers like result1.csv, result2.csv
-
restart & run all
-
single script to run entire pipeline
caution
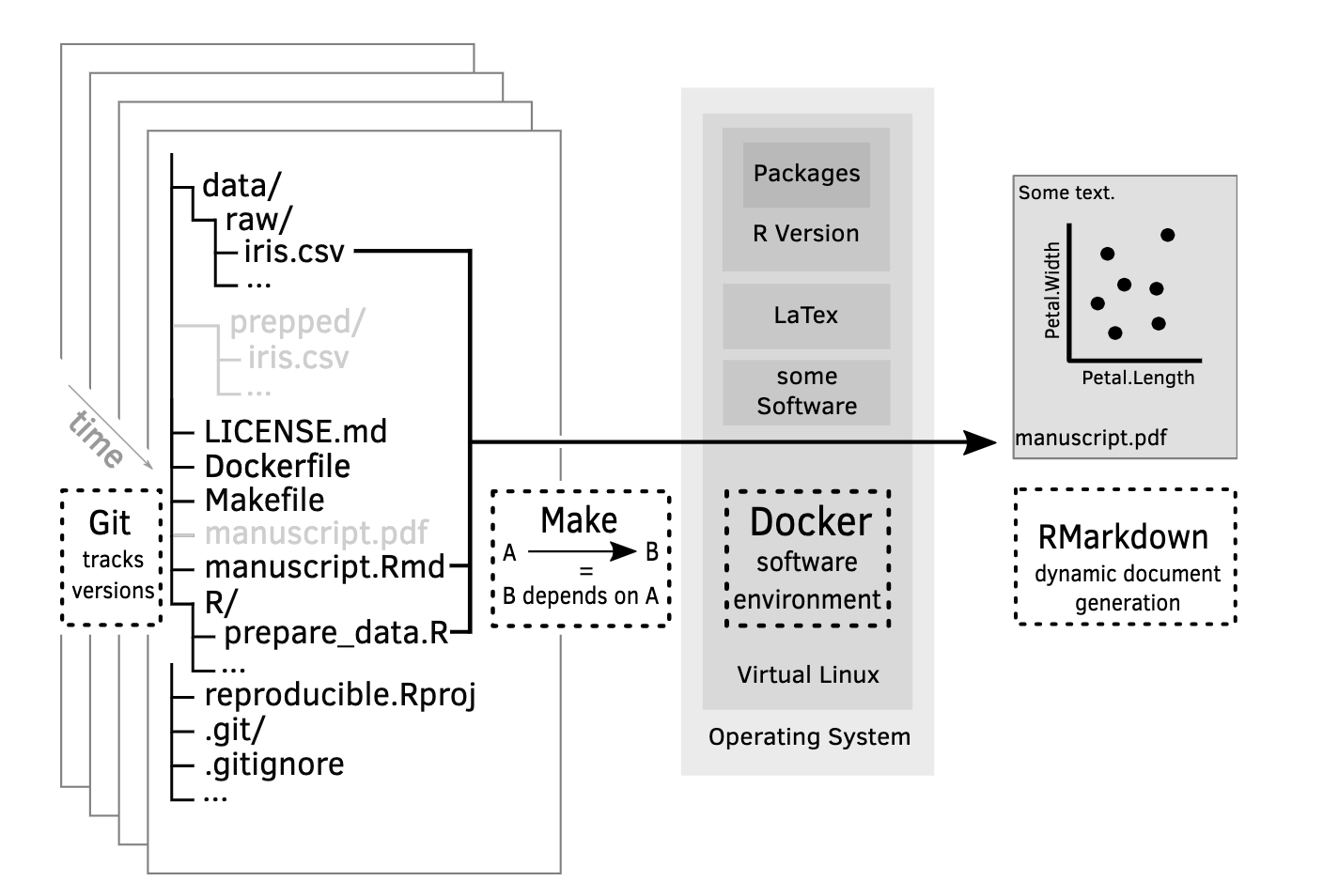
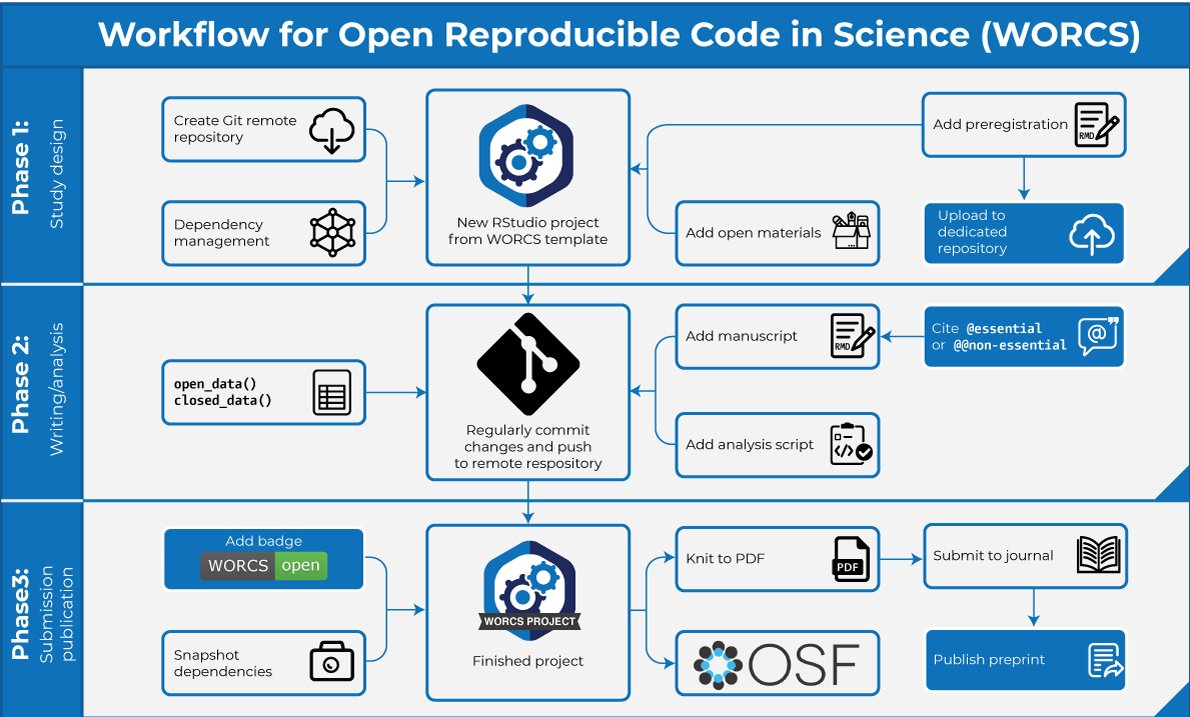
5. track changes
from manual to
(partly) version control
Copy the entire project whenever a significant change has been made.
1Tb hard drive = $50
50 Gigabytes < $5
Data are cheap, time is expensive
- Back up (almost) everything created by a human being
-
Keep changes small
- commit early, commit often
-
Share changes frequently
- avoid conflicts (especially when for manual versioning)
- merge as soon as possible
- Use a checklist for saving and sharing changes to the project
- Store each project in a folder that is mirrored off the researcher's working machine with Dropbox or GitHub. Synchronize at least daily.
Manual versioning requires self-discipline.
Version control tools accelerate and enforce the discipline needed to produce reliable results.
(many advantages in Box 4)
what not to put under version control?
- binary files (.docx, .pdf, .csv, .png)
- raw data
- (mega)large files
I still do!!!
I still do!!!
I still do!!!
But be aware of the changes (or at least the size of the changes) you're making!
Some GitHub tricks
- press y for permalink
- to download a file: right click on Raw → Save Link As
- Display the rich diff to see differences between figures
6. manuscripts
Doing the research is the first 90% of any project; writing up is the other 90%.
…try to explain the notion of compiling a document to an overworked physician you collaborate with. Oh, but before that, you have to explain the difference between plain text and word processing. And text editors. And Markdown/LaTeX compilers. And BiBTeX. And Git. And GitHub. Etc. Meanwhile, he/she is getting paged from the OR…
Google Docs excels at easy sharing, collaboration, simultaneous editing, commenting, and reply-to-commenting. Sure, one can approximate these using text-based systems and version control. The question is why anyone would like to…
The goal of reproducible research is to make sure one can reproduce… computational analyses. The goal of version control is to track changes to source code. These are fundamentally distinct goals, and while there is some overlap, version control is merely a tool to help achieve that and comes with so much overhead and baggage that it is often not worth the effort.
Stephen Turner
Arjun Raj
But what about text-based documents?
(LaTeX, Markdown, Manubot, etc.)
use text-format files
(.tsv, .csv, .json) for tables
in supplement
No PDFs!!!
- Branches
- Build tools
- Unit tests
- Coverage
- Continuous integration
- Profiling and performance tuning
- The semantic web
- Documentation
- A bibliography manager
- Code reviews and pair programming
Tools and practices that take a larger investment before they start to pay off
citation by persistent identifier
This is a sentence with 5 citations [ @doi:10.1038/nbt.3780; @pmid:29424689; @pmcid:PMC5938574; @arxiv:1407.3561; @url:https://greenelab.github.io/meta-review/ ].
References
-
Reproducibility of computational workflows is automated using continuous analysis
Brett K Beaulieu-Jones, Casey S Greene
Nature Biotechnology (2017-03-13) https://doi.org/f9ttx6
DOI: 10.1038/nbt.3780 · PMID: 28288103 · PMCID: PMC6103790
-
Sci-Hub provides access to nearly all scholarly literature.
Daniel S Himmelstein, Ariel Rodriguez Romero, Jacob G Levernier, Thomas Anthony Munro, Stephen Reid McLaughlin, Bastian Greshake Tzovaras, Casey S Greene
eLife (2018-03-01) https://www.ncbi.nlm.nih.gov/pubmed/29424689
DOI: 10.7554/elife.32822 · PMID: 29424689 · PMCID: PMC5832410
-
Opportunities and obstacles for deep learning in biology and medicine
Travers Ching, Daniel S. Himmelstein, Brett K. Beaulieu-Jones, Alexandr A. Kalinin, Brian T. Do, Gregory P. Way, Enrico Ferrero, Paul-Michael Agapow, Michael Zietz, Michael M. Hoffman, … Casey S. Greene
Journal of the Royal Society Interface (2018-04) https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5938574/
DOI: 10.1098/rsif.2017.0387 · PMID: 29618526 · PMCID: PMC5938574
-
IPFS - Content Addressed, Versioned, P2P File System
Juan Benet
arXiv (2014-07-14) https://arxiv.org/abs/1407.3561v1
-
Open collaborative writing with Manubot
Daniel S. Himmelstein, David R. Slochower, Venkat S. Malladi, Casey S. Greene, Anthony Gitter
(2018-08-03) https://greenelab.github.io/meta-review/
This is a sentence with 5 citations [1,2,3,4,5].
CC-BY 4.0
Use archive services:
- arxiv
- biorxiv
- medrxiv
- psyarxiv