Journal club

Kim Lab, 2020-08-27

Michael Kearns and Aaron Roth
2019

Cathy O'Neil
2016
Algorithms are currently deployed in
- lending
- college admissions
- criminal sentencing
-
healthcare
- patient triage: prioritize patients based on prediction of their severity
If we strictly adhere to ‘save the most lives’ principle, we will be treating more white people, more men, more wealthy people.
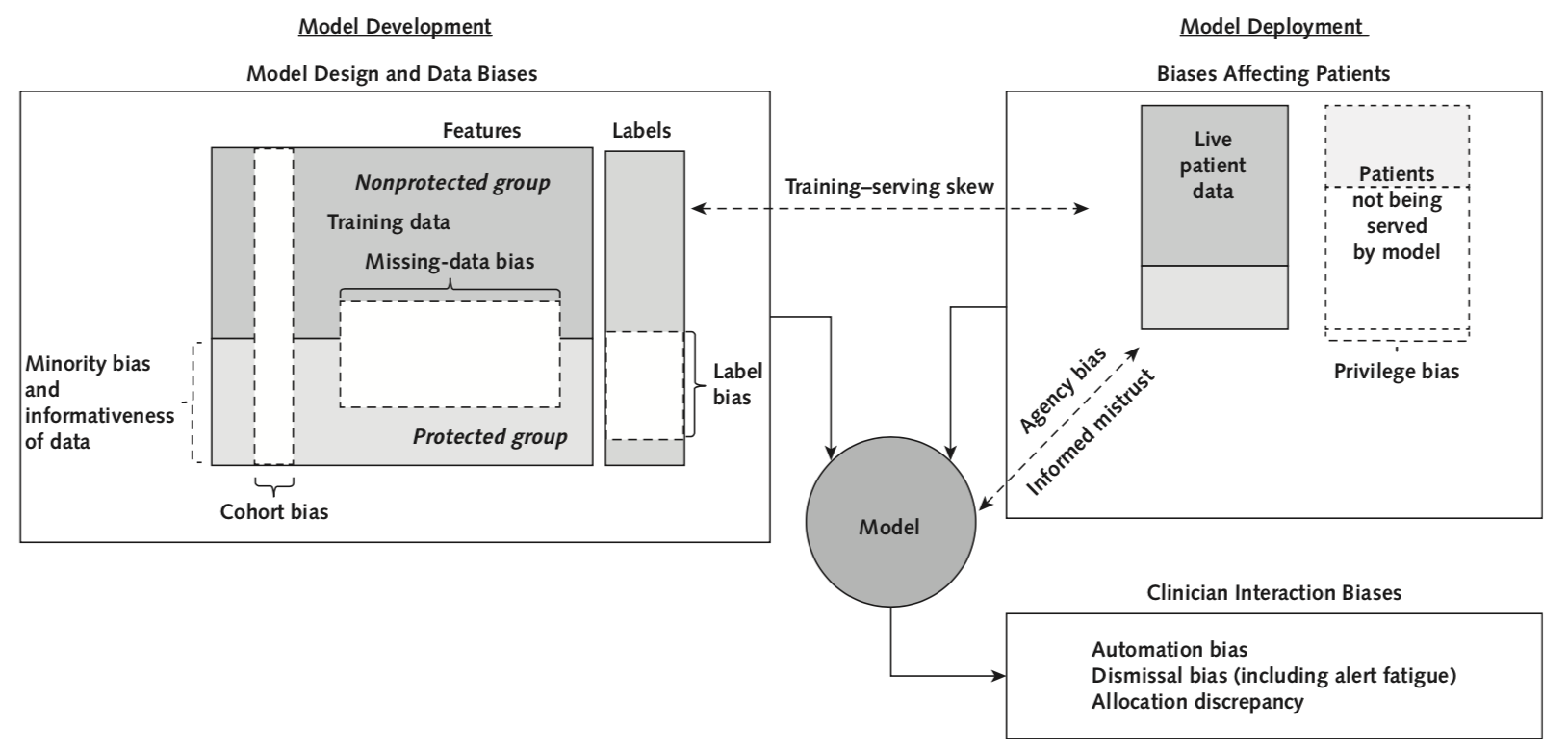
- insufficient numbers of patients in protected group
- features are less informative to render a prediction in a protected group
- Defaulting to easily measured groups without considering other potentially protected groups or levels of granularity
- Data may be missing for protected groups in a nonrandom fashion, which makes an accurate prediction hard to render
- A label that does not mean the same thing for all patients because it is an imperfect proxy that is subject to health care disparities rather than a truth.
- deployment data ≠ training data
- Protected groups do not have input into the development, use, and evaluation of models. They may not have the resources, education, or political influence to detect biases, protest, and force correction.
- Models may be unavailable in settings where protected groups receive care or require technology/sensors disproportionately available to the non-protected class.
- If clinicians are unaware that a model is less accurate for a specific group, they may trust it too much and inappropriately act on inaccurate predictions.
Other biases...
historical bias
A metaanalysis of 20 years of published research found that
Black patients were 22% less likely than
white patients to get any pain medication and
29% less likely to be treated with opioids.
In minority communities, racial discrimination is thought to increase the magnitude of existing stigma against substance users, creating a “double stigma.” Add to all that the common characterization of “innocent white victims” of over-prescribing by health-care providers, which can create the misimpression that black patients who do develop opioid use disorder are more to blame than white patients. Thus a third layer of stigma is created.
Case study
Potential issue: too few Black patients
→ Within this protected group:
- lower TPR: miss more patients at risk
- higher FPR: more likely to be false positive → alert fatigue
Task: predict risk for deterioration
automation bias
dismissal bias
Case study
Potential issue: patients in predominantly Black neighborhoods are predicted to have longer stays
→ resource allocated away from these patients
Task: use demographic variables to predict inpatients with shortest stays
Case study
issue: less accurate on people of color
(measurement are systematically inaccurate)
Task: use green light technology to track heart rate (Fitbit)


The MDRD equation underestimates the prevalence of chronic kidney disease among blacks and overestimates the prevalence of CKD among whites compared to the CKD-EPI equation
If race is excluded, more black patients could also be falsely labeled as having kidney disease or having a more advanced stage of disease, potentially leading to anxiety or unnecessary treatment.
But...
-
use health care expense as a proxy for sickness level
-
but Black patients received less health care for a given sickness level
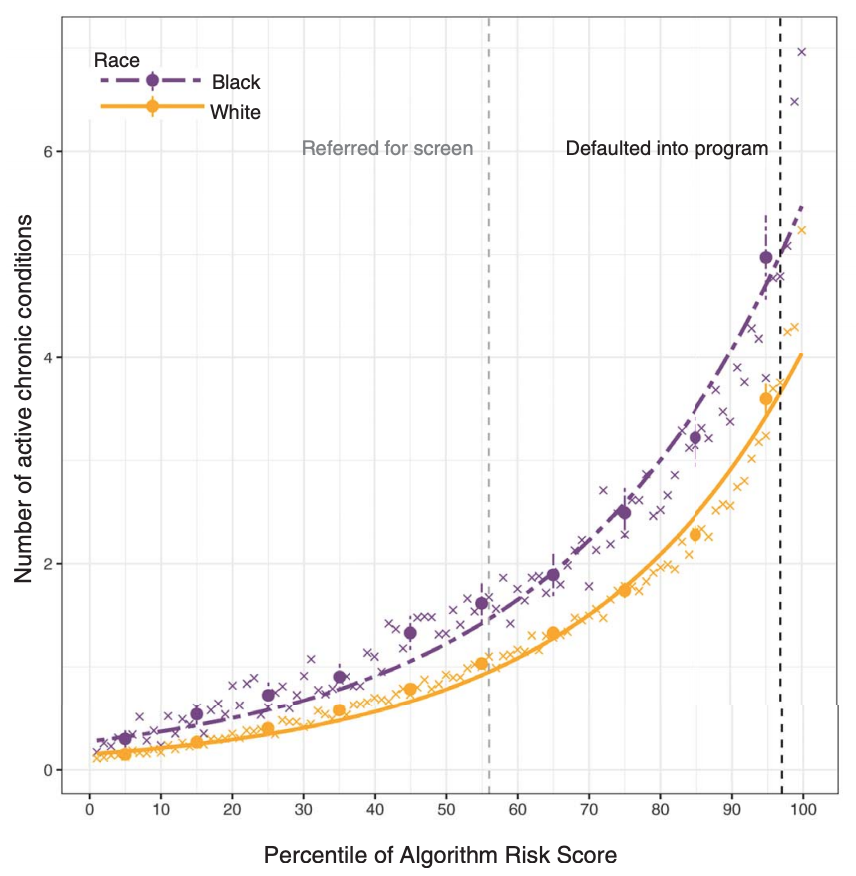
-
Equal patient outcomes
The model should lead to equal patient outcomes across groups.
Distributive justice options for machine learning
-
Equal performance
The model performs equally well across groups for such metrics as accuracy, sensitivity, specificity, and positive predictive value.- equal sensitivity (TPR)
- equal odds (TPR and TNR)
- equal positive predictive value
Distributive justice options for machine learning
-
Equal allocation
Allocation of resources as decided by the model is equal across groups, possibly after controlling for all relevant factors
Distributive justice options for machine learning
Recommendations
La Cava & Moore, GECCO 2020
Recent results show that the problems of both learning and auditing classifiers for rich subgroup fairness are computationally hard.
- Determine the goal of a machine-learning model and review it with diverse stakeholders, including protected groups.
- Ensure that the model is related to the desired patient outcome and can be integrated into clinical workflows.
- Discuss ethical concerns of how the model could be used.
- Decide what groups to classify as protected.
- Study whether the historical data are affected by health care disparities that could lead to label bias. If so, investigate alternative labels.
Design
- Collect and document training data to build a machine-learning model.
- Ensure that patients in the protected group can be identified (weighing cohort bias against privacy concerns).
- Assess whether the protected group is represented adequately in terms of numbers and features.
Data collection
Train a model taking into account the fairness goals.
- Measure important metrics and allocation across groups.
- Compare deployment data with training data to ensure comparability. Assess the usefulness of predictions to clinicians initially without affecting patients.
Evaluation
Training
Evaluate whether a model should be launched with all stakeholders, including representatives from the protected group.
Launch review
- Systematically monitor data and important metrics throughout deployment.
- Gradually launch and continuously evaluate metrics with automated alerts.
- Consider a formal clinical trial design to assess patient outcomes. Periodically collect feedback from clinicians and patients.
Monitored deployment
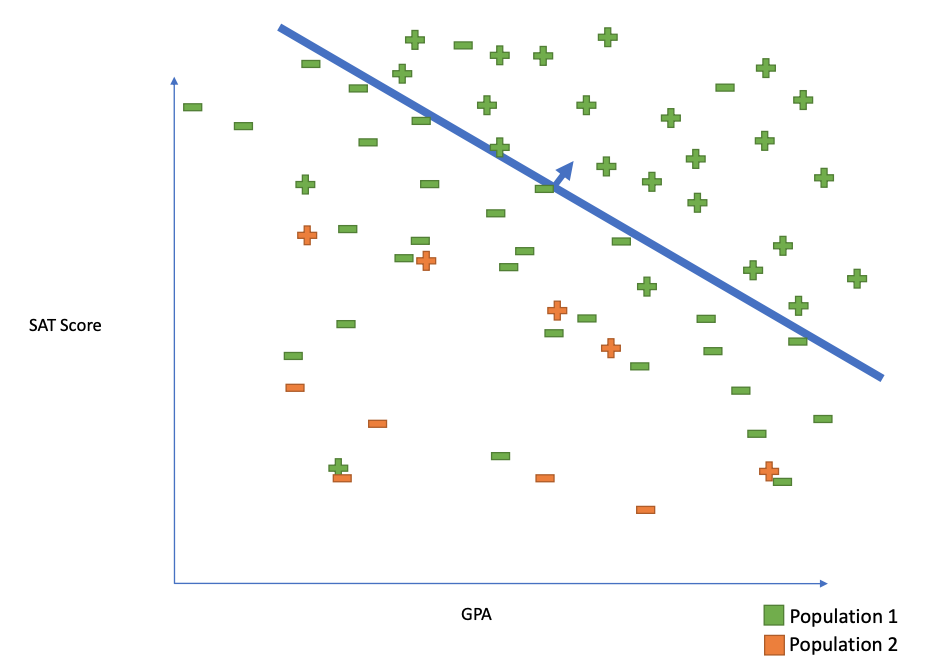
"blinding" or "unawareness"
is NOT sufficient
References
- Timnit Gebru
- Rachel Thomas
- Joy Buolamwini
- Michael Kearns
- Aaron Roth
Scientists are some of the most dangerous people in the world because we have this illusion of objectivity
-- Timnit Gebru
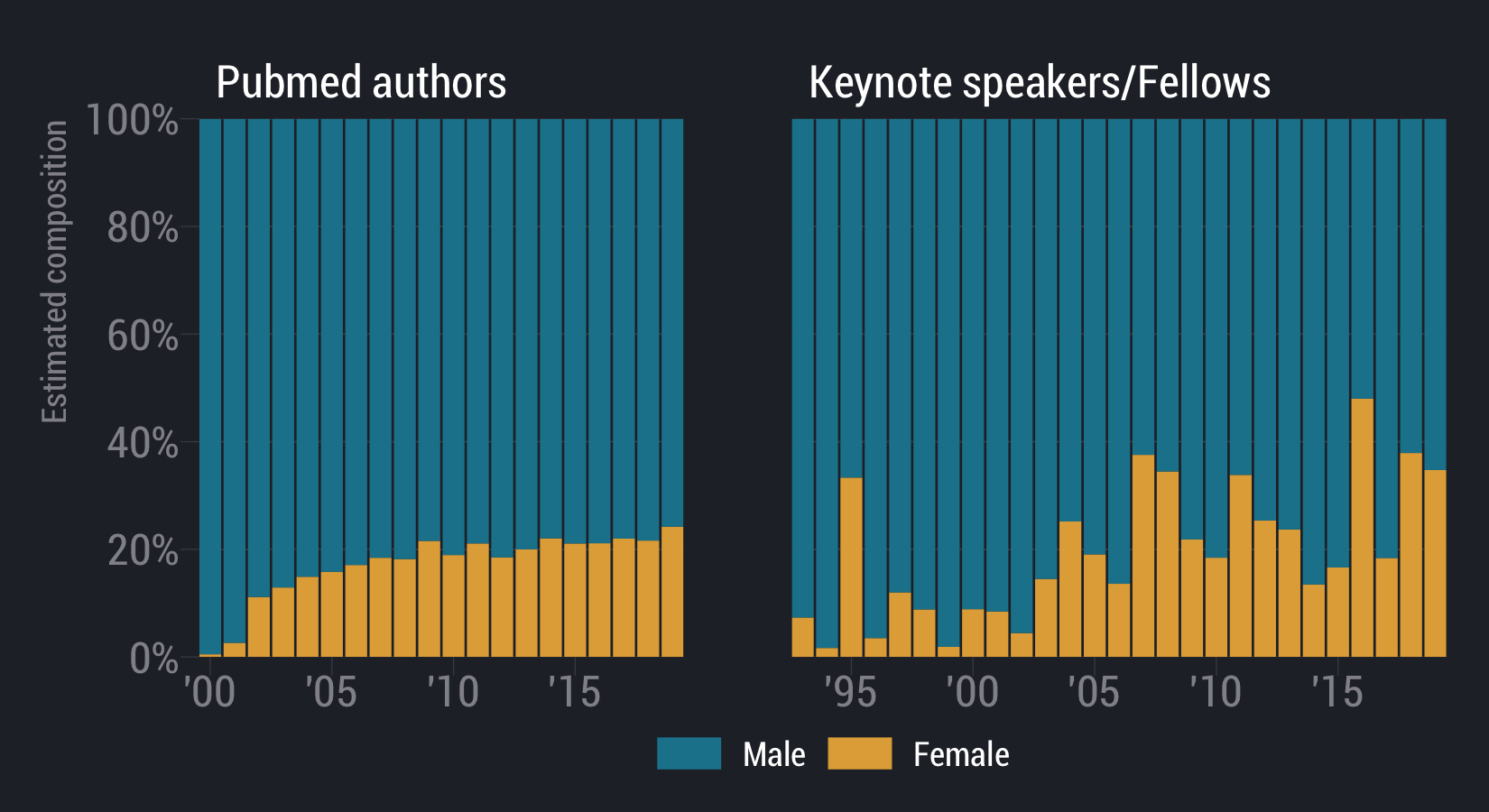
Le et al. 2020, bioRxiv
-
Individual fairness
similar individuals treated similarly
-
Statistical Parity
Ask for equivalent error rates across protected attributes (e.g. race, sex, income)
-
Subgroup Fairness
-
ask for equivalent error rates intersections/conjunctions of groups
-
-