Tree-based automated machine learning for analyzing biomedical big data
Trang Lê
University of Pennsylvania
2021-03-31

@trang1618

https://slides.com/trang1618/tpot-bms/
About me
PhD Mathematics, Dec 2017


Laureate Institute for Brain Research
- imaging, BrainAGE
- pseudopotential for fractional-d
- use differential privacy to reduce
- overfitting in high-d biological data
PetroVietnam → University of Tulsa
now...
Computational Genetics Lab
UPenn


Let's talk about autoML.
Clean data
Select features
Preprocess features
Construct features
Select classifier
Optimize parameters
Validate model
Pre-processed data
Automate
Typical supervised ML pipeline
Automate
TPOT is a an AutoML system that uses GP to
optimize the pipeline with the objective of
- maximizing cross-validated score
- minimizing pipeline complexity

Entire data set
Entire data set
PCA
Polynomial features
Combine features
Select 10% best features
Support vector machines
Multiple copies of the data set can enter the pipeline for analysis
Pipeline operators modify the features
Modified data set flows through the pipeline operators
Final classification is performed on the final feature set
an example individual
GP primitive Feature selector & preprocessor, Supervised classifier/regressor
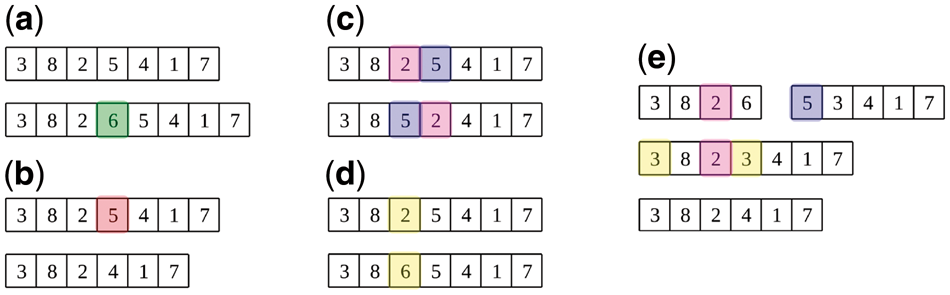
Mutation and crossover
(a) insertion mutation
(b) deletion mutation
(c) swap mutation
(d) substitution mutation
(e) crossover
from tpot import TPOTClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(
iris.data, iris.target,
train_size = 0.75, test_size = 0.25, random_state = 42)
tpot = TPOTClassifier(generations = 50, population_size = 100,
verbosity = 2, random_state = 42)
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
tpot.export('tpot_digits_pipeline.py')import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import Normalizer
from tpot.export_utils import set_param_recursive
# NOTE: Make sure that the outcome column is labeled 'target' in the data file
tpot_data = pd.read_csv(
'PATH/TO/DATA/FILE', sep='COLUMN_SEPARATOR', dtype=np.float64)
features = tpot_data.drop('target', axis=1)
training_features, testing_features, training_target, testing_target = \
train_test_split(features, tpot_data['target'], random_state=42)
# Average CV score on the training set was: 0.9826086956521738
exported_pipeline = make_pipeline(
Normalizer(norm="l2"),
KNeighborsClassifier(n_neighbors=5, p=2, weights="distance")
)
# Fix random state for all the steps in exported pipeline
set_param_recursive(exported_pipeline.steps, 'random_state', 42)
exported_pipeline.fit(training_features, training_target)
results = exported_pipeline.predict(testing_features)but... there's a caveat
primitives/operators
-
feature selector
-
feature transformer
-
supervised classifier/regressor
-
feature set selector (FSS)
parameters
-
generations
-
population_size
-
offspring_size
-
mutation_rate
-
...
-
...
-
template
new features
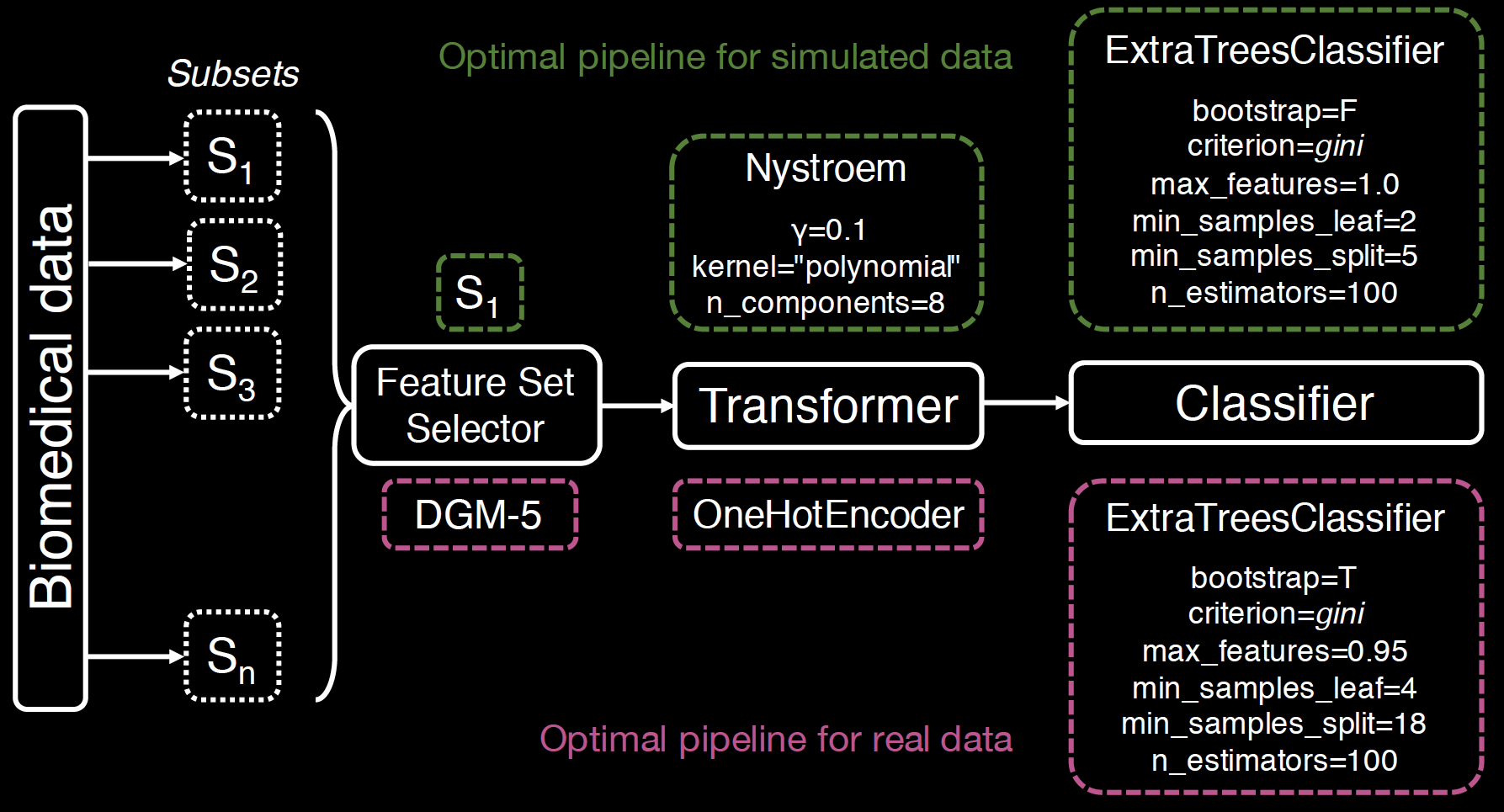
template:
FeatureSetSelector-Transformer-ClassifierTemplate + feature set selector
from tpot.config import classifier_config_dict
classifier_config_dict['tpot.builtins.FeatureSetSelector'] = {
'subset_list': ['subsets.csv'],
'sel_subset': range(19)
}
tpot = TPOTClassifier(
generations = 100, population_size = 100,
verbosity = 2, random_state = 42, early_stop = 10,
config_dict = classifier_config_dict,
template = 'FeatureSetSelector-Transformer-Classifier')For each training and testing set
- m = 200 observations (Outcome: 100 cases and 100 controls)
-
p = 5 000 real-valued features
- 4% functional: true positive association with outcome
- Subsetting: functional features more likely to be included in earlier subsets (a lot of functional features in \(S_1\), some in \(S_2\), very few to 0 in \(S_{10}, ..., S_{20}\))
100 replicates of TPOT runs
Data simulation
template:
FeatureSetSelector-Transformer-Classifier
The optimal pipelines from TPOT-FSS significantly outperform those of XGBoost and standard TPOT.

In 100 replications, FSS correctly selects subset \(S_1\) 75 times.
- 78 individuals with MDD
- 79 healthy controls (HCs)
- 19 968 protein-coding genes → 5 912 transcripts
- Feature sets: 23 depression gene modules (DGMs)
Real-world RNA-Seq expression data
previous findings
template:
FeatureSetSelector-Transformer-ClassifierThe outperformance is still statistically significant.

Pipelines that include DGM-5, on average, produce higher MDD prediction accuracies in the holdout set.
- TPOT-FSS is the first AutoML tool to offer the option of feature selection at the group level.
- FSS can identify the most meaningful group of features to include in the prediction pipeline.
- Reducing pipeline complexity can lead to considerable increase in interpretability and generalizability.
Ongoing works
- extend to other data types
- incorporate other operators
- re-formulate complexity
- number of features used in pipeline
- each operator: flexibility, runtime
- assess over-fitting