Happy Day!!!


TPOT: A Tree-based Pipeline Optimization Tool
Trang Lê
mathematician
postdoctoral researcher
@UPenn IBI
amateur runner
@trang1618

Clean data
Select features
Preprocess features
Construct features
Select classifier
Optimize parameters
Validate model
Raw data
Automate
Typical ML pipeline
Automate
Open source AutoML tools
- auto-sklearn (python) github.com/automl/auto-sklearn
- Bayesian optimzation over a fixed 3-step ML pipeline
-
auto-Weka (java) github.com/automl/autoweka
- similar to auto-sklearn, built on top of Weka
-
H20.ai (java w/ python, scala, R, web GUI) github.com/h2oai/h2o-3
- basic data prep w/ grid/random search over ML algorithms
-
devol (python) github.com/joeddav/devol
- deep learning architecture search via GP

Randy Olson

- DEAP
- Objective:
- maximize pipeline's CV classification performance
- minimize pipeline’s complexity
- Pareto front with NSGA-II
TPOT

Weixuan Fu
Entire data set
Entire data set
PCA
Polynomial features
Combine features
Select k best features
Logistic regression
Multiple copies of the data set can enter the pipeline for analysis
Pipeline operators modify the features
Modified data set flows through the pipeline operators
Final classification is performed on the final feature set
Genetic programming
GP primitives Dataset selectors, Feature selectors & preprocessors, Supervised classifiers
Population sequences of pipeline operators
Generations
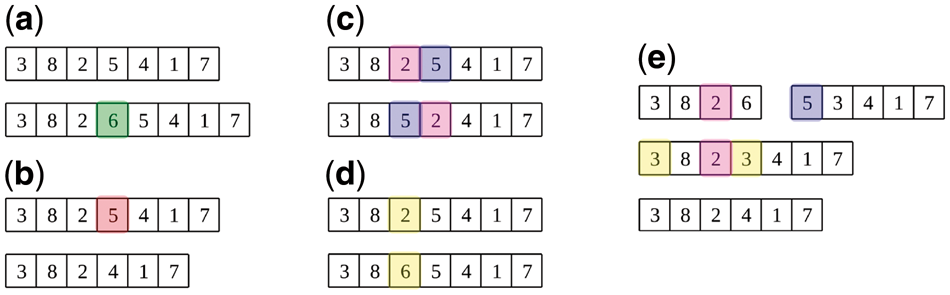
Mutation and crossover
(a) insertion mutation
(b) deletion mutation
(c) swap mutation
(d) substitution mutation
(e) crossover
TPOT configs
- Default TPOT
- TPOT light
- TPOT sparse
- TPOT-MDR (Multi-Directional Reduction)
- Classification
- Regression
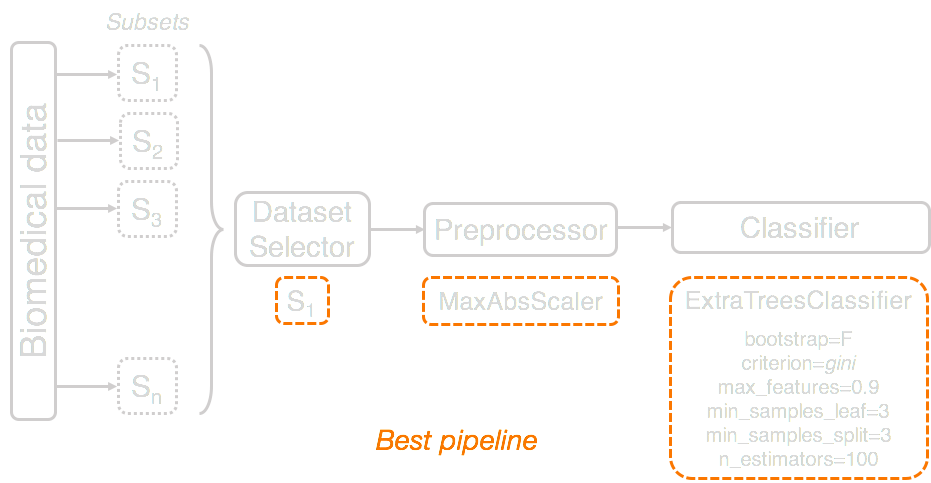
Template + Dataset Selector
Mutation restriction
Complexity reformulation
- Number of pipeline operators
- Flexibility of each operator
- Runtime
- Number of features used in pipeline
- Number of parameters
- By accessing over-fitting: stability of the covariance of predictors, rank differences of importance metrics
Integration with neural nets
Challenges
- preprocessing
- scalability
- computational expense
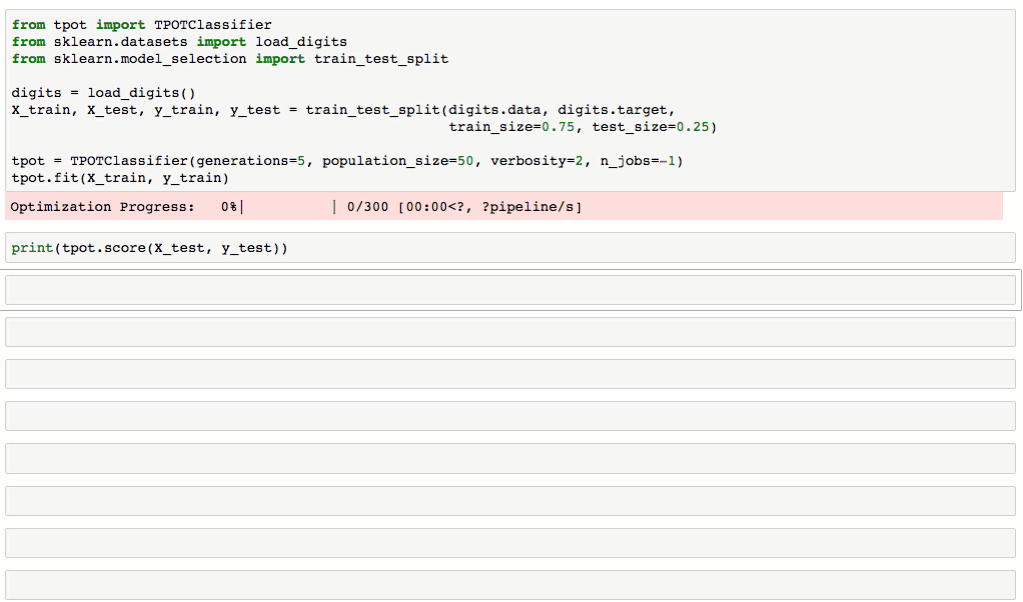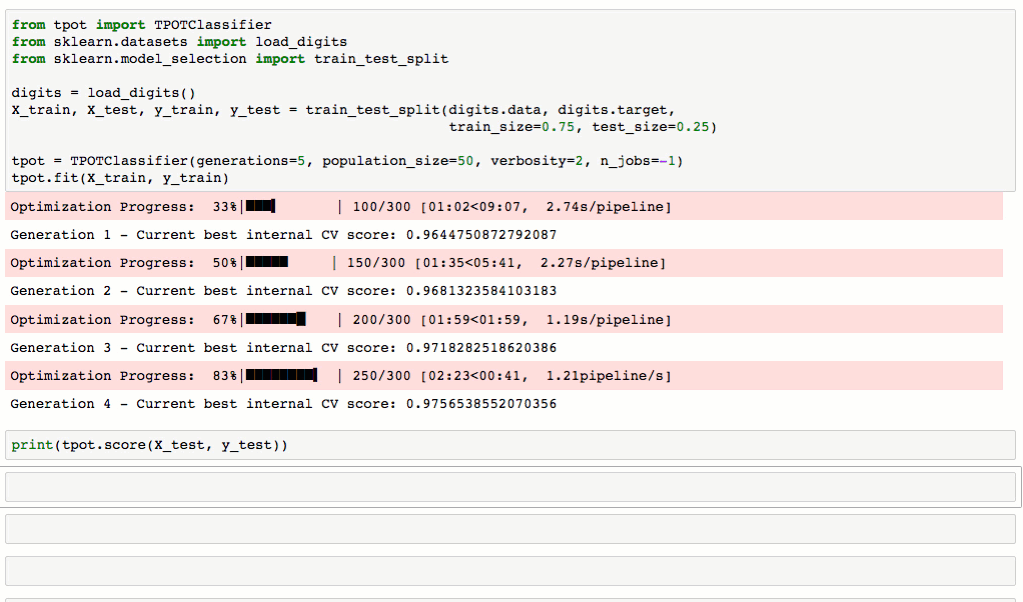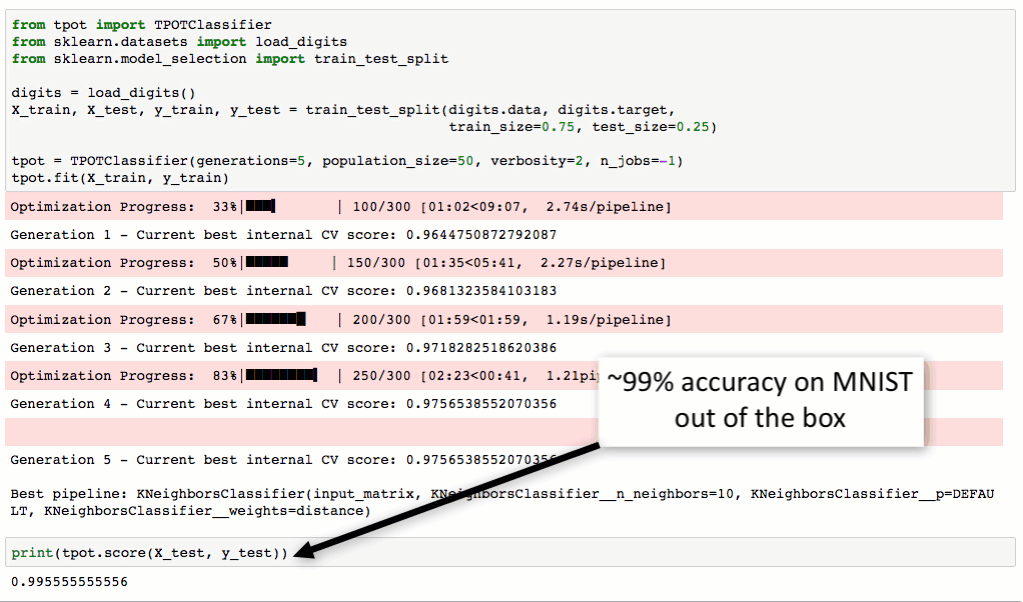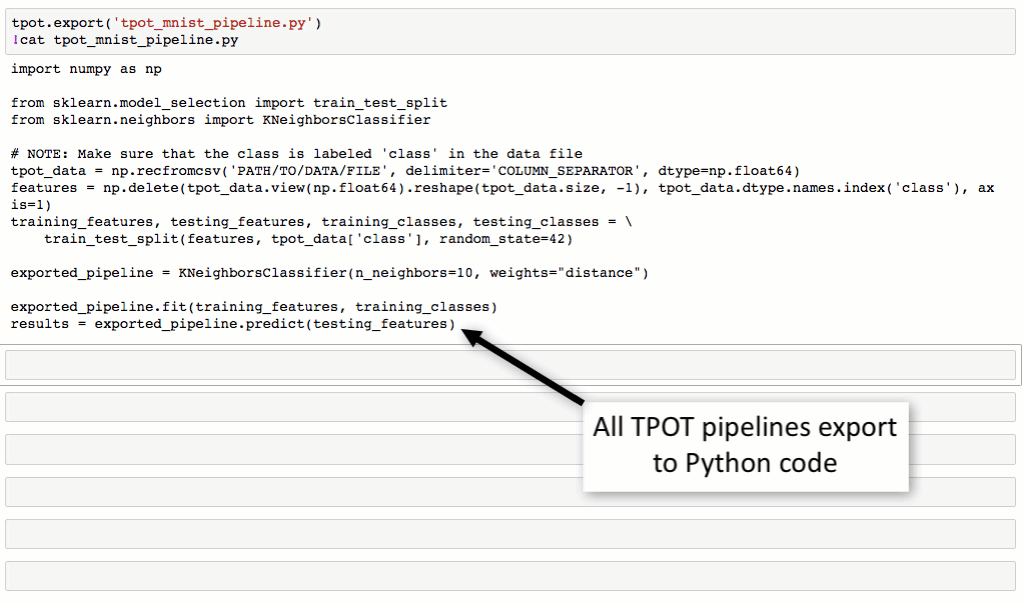
Live demo!

Jason Moore
Weixuan Fu
