IA Flash
Pistes de réflexion
Arthur Roullier - EIG3 - 6 novembre 2018
Problématique
-
20 000 000 clichés par an
-
10 000 erreurs (0,05%)
-
des citoyens sont inquiétés à tort
-
coûts en envois inutiles
-
-
possible d'utiliser le Système d’Immatriculation des Véhicules !

"quelle est la voiture sur ce cliché radar ?"
et plus précisément:
"quelle sont les chances que la voiture sur ce cliché
soit une [modèle d'après le SIV] ?"
Ressources
Dossier GitHub ouvert: https://github.com/0-tree/EIG3_IAFlash
(i) utiliser le transfer-learning pour
apprendre de manière supervisée
(ii) labéliser un dataset avec le clustering
(iii) trouver plus
de données avec
le scrapping
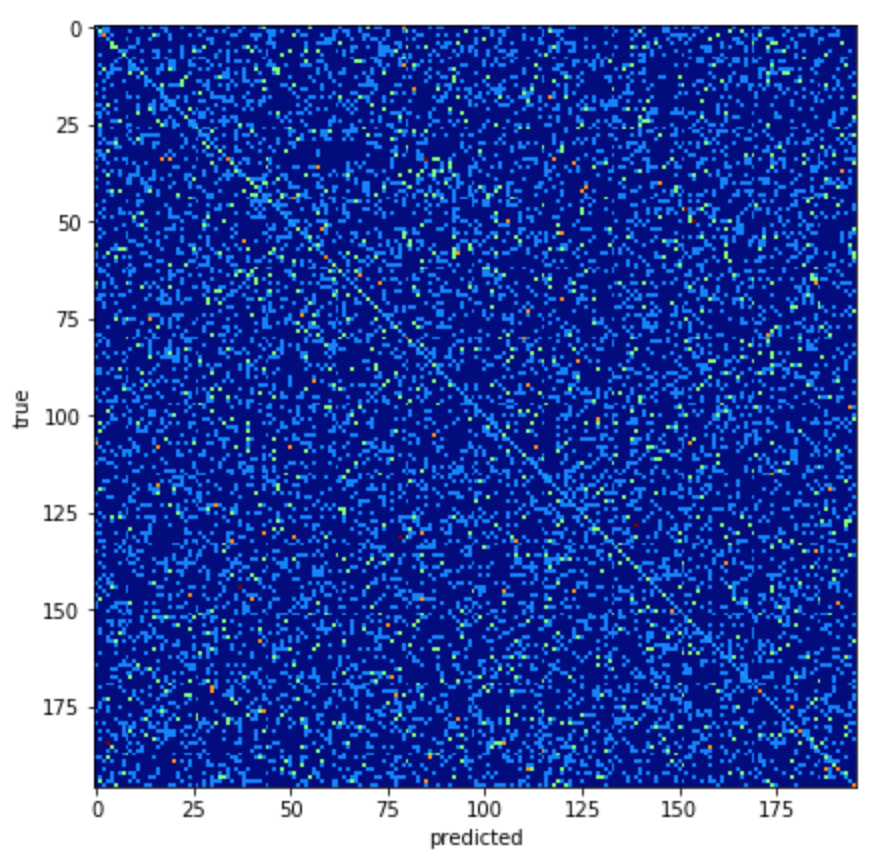



Pistes de réflexion
| contexte | approche | détails | impact |
|---|---|---|---|
| (1) beaucoup de donnés labélisées | apprentissage supervisé "standard" |
- deep learning / transfert learning - feature engineering manuel expert |
- peut viser 70% en top1 classification - et 90% en top5 |
| (2) beaucoup de donnés non labélisées | apprentissage non-supervisé |
- clustering des images par modèle - projeter le SIV sur les clusters |
permet le cas (1) |
| (3) besoin de données en plus ? | scrapping et formatage | - formater les images pour correspondre aux clichés radar | améliore les performances au cas (1) |
Cycle de développement
Kickoff : mise en place du cahier des charges
- type de données (quel "contexte")
- contraintes sur le livrable
Prise en main : découverte des données et plan d'action en conséquence
Développement itératif : produit minimal end-to-end + (idéalement) échanges avec les "clients"
- d'abord le système de reconnaissance de voitures (possible très tôt si accès au SIV)
- puis en parallèle les idées connexes (labalisation automatique et/ou scrapping)
- les améliorations itératives viendront (i) du modèle lui-même à chaque version ; (ii) des apports des idées connexes
kickoff
prise en main
développement itératif
~1S
~2S
échange
échange
~2S itératif
...