Étude des performances de code généré par IA
Plénière DISTILLER Avril 2023
Tristan COIGNION
Progrès en IA

Progrès en IA
GitHub Copilot
AI + Green = 💔
Demande beaucoup de ressources à l'entraînement et à la génération
(ex: BLOOM : $2-5M equivalent in cloud computing)
Désolé, j'ai pas eu le temps de trouver mes sources, mais j'ai vu des gens plus intelligents en parler
Est-ce que le gain de temps en vaut la peine ?
Études sur les modèles de génération de code
(ex : Copilot)
Aucune étude sur la performance énergétique des modèles de génération de code (et très peu sur la performance en temps)
Il existe de la recherche sur la consommation énergétique des IAs en général
Est-ce qu'un modèle qui génère plus souvent du code valide, génère du code plus performant ?
Est-ce que certains modèles sont meilleurs que d'autres seulement pour des tâches spécifiques ?
Étude du code généré par les IAs
Quels facteurs vont affecter la performance du code généré ?
On fait générer quoi comme code ?
Des algorithmes
- assurent un temps d'exécution plus long avec une charge plus haute
- courts et faciles à faire générer de manière non supervisée en grande quantité

Un exemple de problème sur Leetcode
Avec quelles modèles d'IA ?
- GitHub Copilot
- Codex - OpenAI
- Codegen (350M, 2B, 6B,
16B) - Salesforce - Santacoder - Community
- CodeT5 - Salesforce
- Incoder (1B, 6B) - Community & MetaAI
- Codeparrot - Community
Modèles fermés
Modèles ouverts
Aparté sur la configuration d'un modèle
Température = Nombre entre 0 et 1.
Température haute -> Modèle "plus créatif"
Pour utiliser les modèles, on les utilises aux températures 0, 0.2, 0.4, 0.6, 0.8 et 1.0.
Il existe d'autres paramètres, mais je ne les fais pas varier.
Procédé
Pour chaque modèle, température et problème
- Génération de 10 solutions potentielles
- Validation de ces solutions auprès de Leetcode. On garde que les solutions qui ont passé tous les tests ou qui ont dépassé la limite de temps
- On bench avec pytest-benchmark chacune des solutions valides
300 problèmes de Leetcode, chacun avec une solution exemple et trois test cases
Résultats

Mini-étude bonus sur le taux de succès des modèles
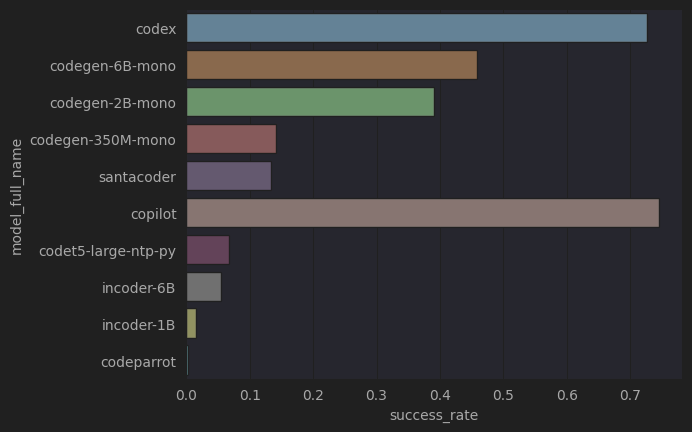
Taux de générations valides par modèle
Les modèles entraînés avec du texte anglais en plus du code réussissent beaucoup mieux que ceux entraînés juste sur du code !
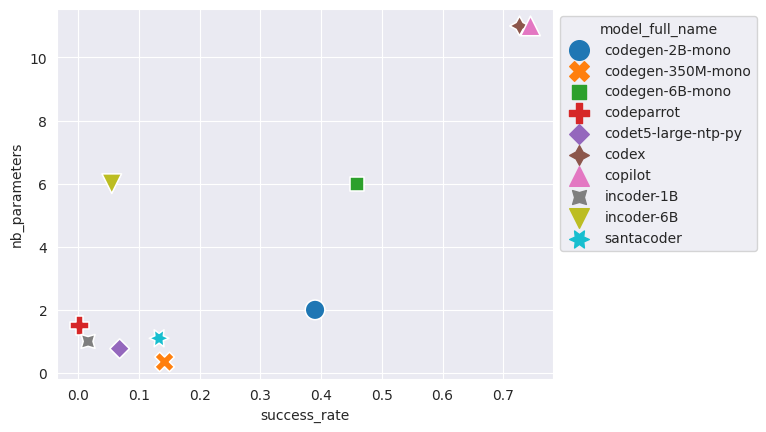
Relation entre la taille du modèle et son taux de succès
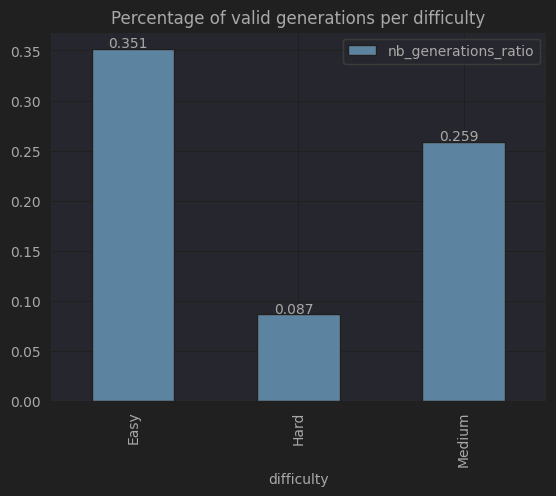
Plus la difficulté des problèmes augmente, plus c'est difficile pour les modèles de générer une solution valide !
Mais aussi, plus c'est difficile, plus la solution attendue est longue.
Certains modèles sont-ils meilleurs que d'autres sur des tâches spécifiques ?
Non.
Il semblerait que l'évolution du taux de réussite d'un modèle à travers des catégories de tâches n'évolue pas à travers les modèles.
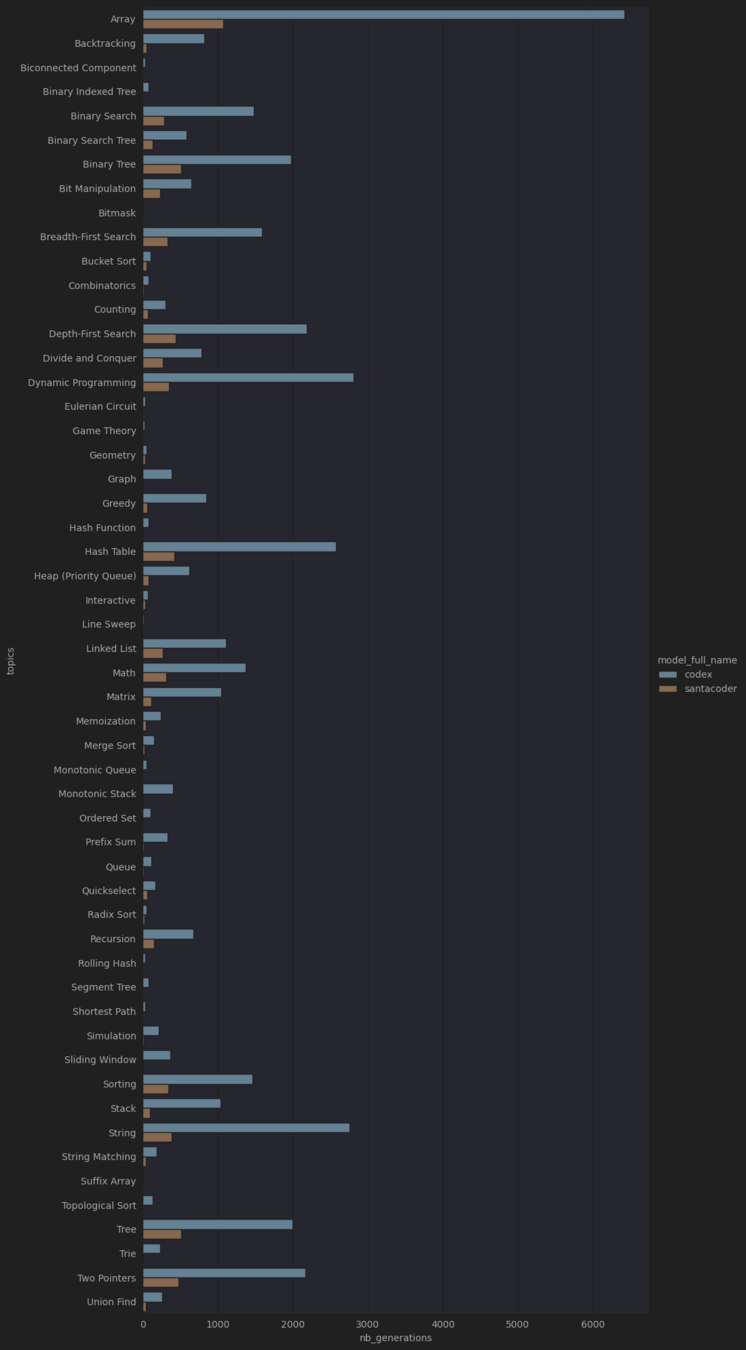

Analyse des performances du code généré
Comparaison par difficulté
Analyse des performances du code généré
Comment comparer les modèles entre eux ?
Un seul problème,
une génération par modèle
On compare simplement le temps en secondes des runs du problème
Un seul problème,
plusieurs générations par modèle
Même chose qu'avant, mais on fait la moyenne des runs d'un même modèle
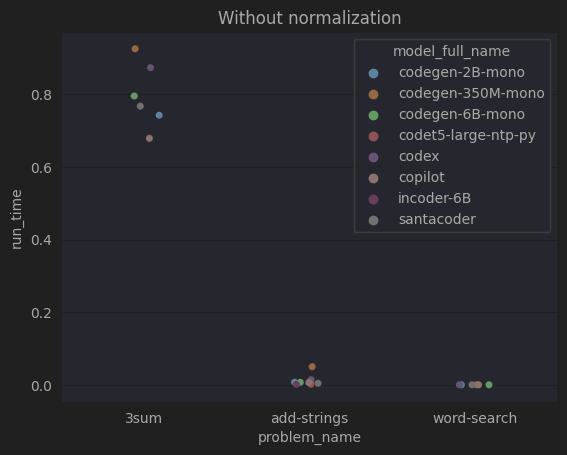
Mais, et si on a plusieurs problèmes, avec chacun des échelles de temps différentes ?
Plusieurs problèmes,
plusieurs générations par modèle
Même méthode qu'avant, on va normaliser les temps au sein de chacun des problèmes
On ne peut pas faire comme avant et simplement faire la moyenne de tous les problèmes
=> En faisant la moyenne, on va perdre l'information de classement de nos modèles

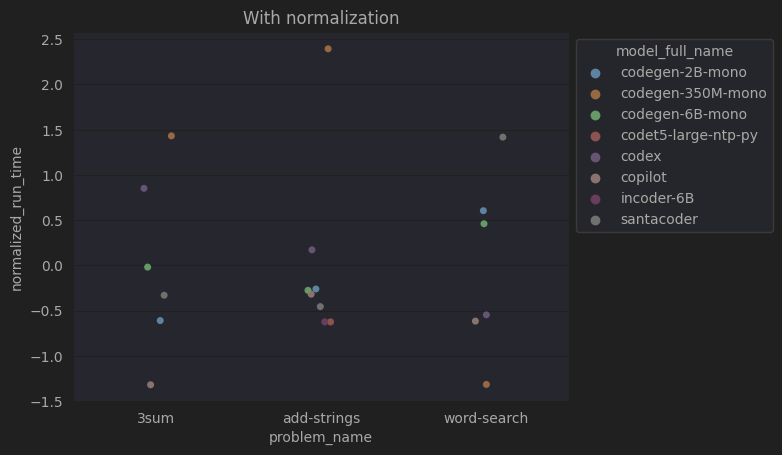
La normalisation garde les informations de classement et de distance entre les problèmes
Si on faisait une moyenne de chaque modèle ici, le classement final serait très sûrement le même que celui du premier problème.
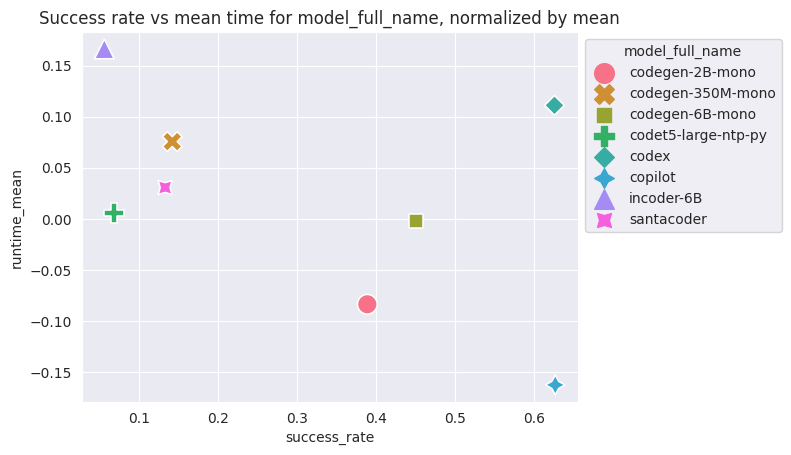
Comparaison générale des modèles
(Toutes températures comprises)
Plus c'est bas, plus c'est rapide !
Plus c'est à droite, plus c'est souvent valide !
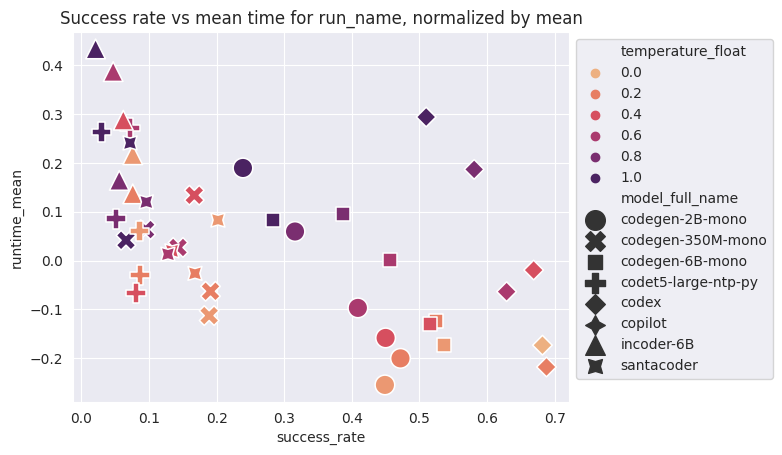
Comparaison générale des modèles, décomposés par température
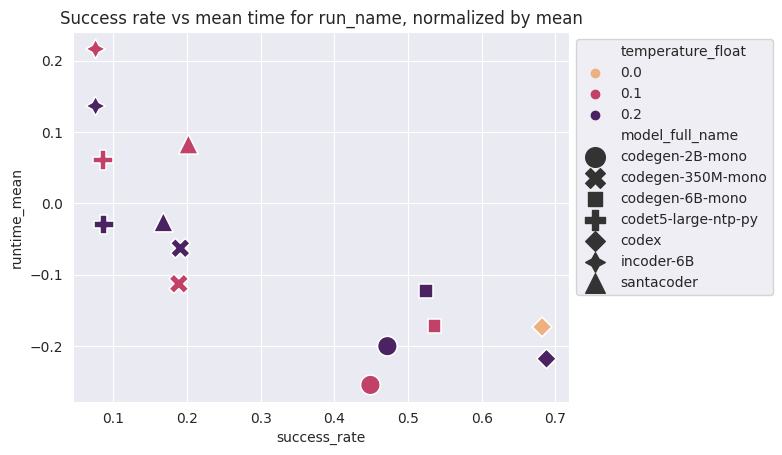
Comparaison générale des modèles, décomposés par température.
Avec les deux plus basses températures
Comparaison générale des modèles, décomposés par température
Plus la température augmente, plus les performances générales sont dégradées
Dans les trois meilleurs modèles (english-trained), le taux de succès n'est pas corrélé avec la performance du code
Les meilleurs modèles produisent du code beaucoup plus lent à haute température que des modèles moins bon à basse température
Comparaison générale des températures (Bonus)
Plus la température augmente, plus les performances générales sont dégradées
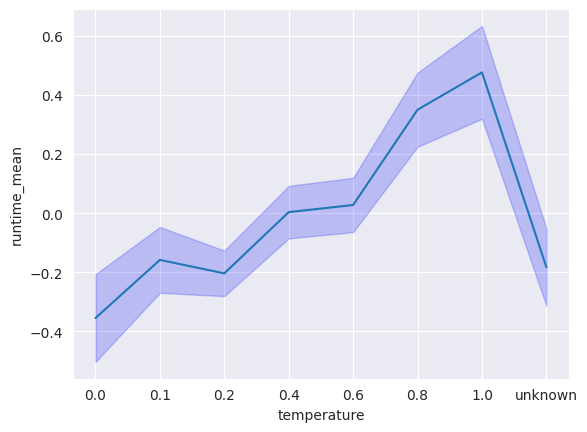
Performances de Copilot
Comparaison générale des températures (Bonus)
Plus la température augmente, plus les performances générales sont dégradées
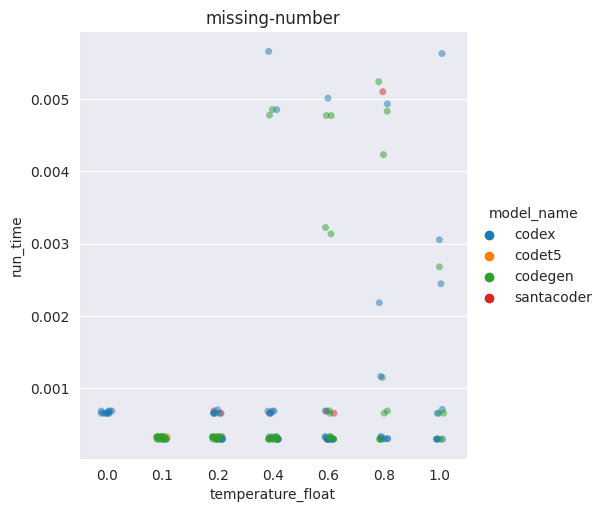
Exemple sur un seul problème
A de plus hautes températures, des solutions moins efficaces vont voir le jour
Comparaison générale des températures (Bonus)
Plus la température augmente, plus les performances générales sont dégradées
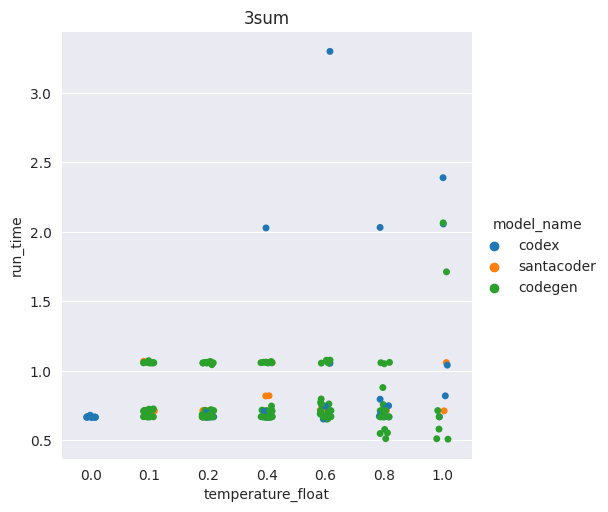
Il peut arriver que de meilleures solutions soient générées, mais c'est rare
Conclusion
- Les modèles entraînés sur de l'anglais sont meilleurs avec des exercices de programmation
- Plus la température est haute, moins le modèle est bon, et plus il va produire du code non-performant, voire parfois nul (boucle infinie, complexité exponentielle etc.)
- Passé un certain stade, améliorer le taux de succès du modèle n'améliore pas la performance de son code
Et après ?
- Étude du gain de temps avec un assistant de code (Copilot)
- Étude de la consommation d'un modèle lorsqu'il est utilisé
- Étude de la consommation du code généré.
- Comparer avec GPT4.
- Utiliser du prompt engineering pour améliorer la performance.
- Étudier l'usage et la consommation d'un assistant de code lorsqu'il est utilisé par un dev (avec FauxPilot)
Merci de m'avoir écouté !
