DESPOT-\(\alpha\)
DESPOT-α: Online POMDP Planning With Large State And Observation Spaces
Neha P Garg, David Hsu and Wee Sun Lee
Presented by Tyler Becker
Motivation

Small \(|\mathcal{O}|\)
Large \(|\mathcal{O}|\)
Contributions
- Extension of DESPOT to large observation spaces
- Minimizing overhead of expansion to large observation spaces
- Parallelizable leaf node evaluation with \(\alpha\)-vectors
- Extension of Hyp-DESPOT to fully parallelized HyP-DESPOT-\(\alpha\)
DESPOT + Weighted PF + \(\alpha\) vectors
Background
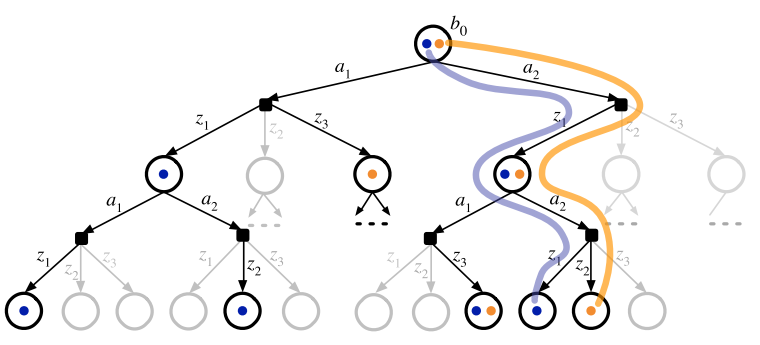
DESPOT
Determinized Scenarios:
Overarching "anytime" algorithmic goal:
Propagate
Reweight
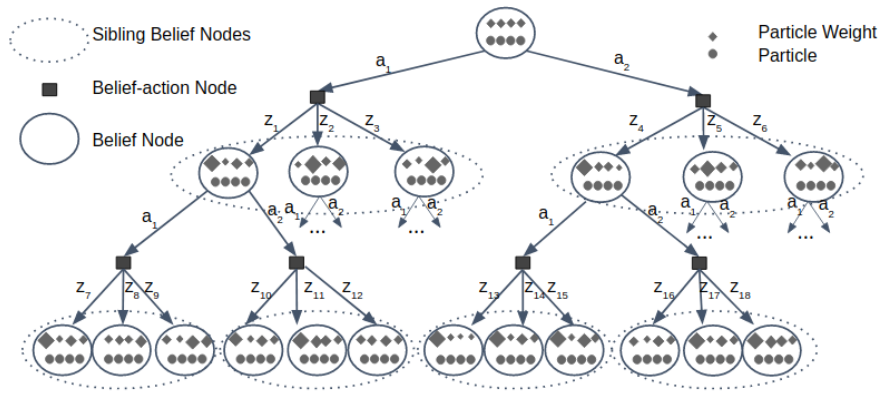
Weighted PF
\(\alpha\) vectors
MDP Bellman
POMDP Bellman
DESPOT utilizes determinized scenarios
Assuming \(\alpha\)'s are similar among sibling nodes, we can estimate value of sibling nodes without having to recalculate \(\alpha\)
Approach
Exploration
Exploration
\(\xi\) : hyperparameter controlling desired leaf node uncertainty
Leaf Node Expansion
Expand all \(a \in \mathcal{A}\)
propagate particles / collect observations
rollout for lower bound \(\alpha(s)\)
Leaf Node Expansion
Create \(C \le K\) new beliefs from size \(C\) subset of sampled observations
For each action
Reweight particles
Estimate Belief Value: \(V(\tau(b,a,z)) = w_{\tau(b,a,z)}^T\alpha\)
Terminate Exploration
\(\text{depth}(b) > D\)
- maximum depth reached
OR
\(\text{WEU}(b) < 0\)
- exploration of belief node no longer heuristically promising
Finally, traverse each node back up to the root performing Bellman backups along the way
Phantom Observation
\(C_{b,a}\) may not contain all possible observations
Claim:
\(\alpha\) now dependent on \(\eta\), which itself is dependent on \(w_b(s) \implies\) can't share \(\alpha\)'s between sibling nodes
Phantom Observation
Proposed Solution
- Introduce some residual observation \((z_{res})\) that accounts for all observations not recovered in \(C_{b,a}\)
- Normalize observation probabilities in a manner that shifts weights towards observations that were collected rather than \(z_{res}\)
Experiments
-
Tiger
- Standard Tiger problem, but continuous \(\mathcal{O}\) and two listening actions (differing in reward and accuracy)
-
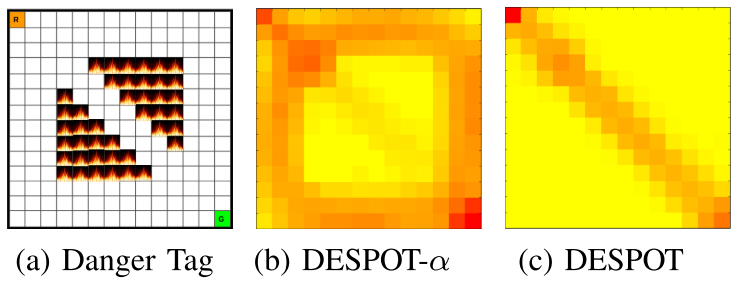
Danger Tag
- Laser Tag, but requires localization and avoidance of dangerous areas
-
Rock Sample (RS)
- Collect good rocks
- given sensor to check each of \(n\) rocks for "goodness"
-
Multi-Agent Rock Sample (MARS)
- Same as RS, but 2 agents (\(|\mathcal{A}|=\)225,400,625)
-
Navigation in Partially known map
- Uncertainty about own position as well as position of certain obstacles in the map
-
Car Driving Among Pedestrians
- Maneuver from start position to goal location without colliding with walking pedestrians with noisy dynamics

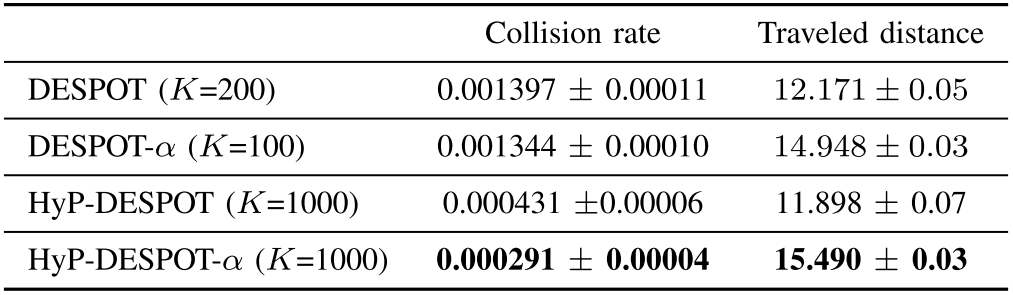
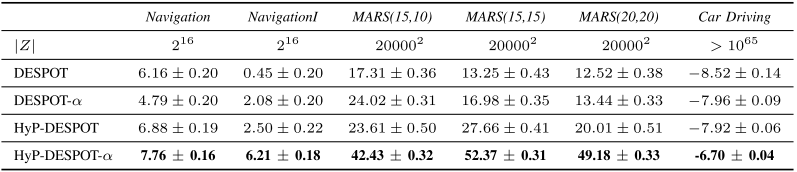
Computation
- Planning Times
- 0.1s for driving scenario, 1s otherwise
- DESPOT/DESPOT-\(\alpha\) using only CPU, no parallelization
- HyP-DESPOT/HyP-DESPOT-\(\alpha\) using both CPU and GPU with parallelization
- CPU parallelizes tree traversal
- GPU parallelizes rollouts + sibling node evaluation
Legacy
- 11 citations
- All connectedpapers listings only reference DESPOT-\(\alpha\) in background sections

Critiques
- Insufficient justification of "phantom" observation (\(z_{res}\))
- Exhaustive \(\mathcal{A}\) search
- Every scenario takes every action
- Messy pseudocode
- No comparison to other large \(\mathcal{O}\) algorithms

Contributions (Recap)
- Extension of DESPOT to large observation spaces
- Minimizing overhead of expansion to large observation spaces
- Parallelizable leaf node evaluation with \(\alpha\)-vectors
- Extension of Hyp-DESPOT to fully parallelized HyP-DESPOT-\(\alpha\)
DESPOT + Weighted PF + \(\alpha\) vectors