Efficient Record-Level Wrapper Induction
Shuyi Zheng Ruihua Song Ji-Rong Wen C. Lee Giles , 2009
Yan-Kai Lai, Yu-An Chou
Outline
-
Abstract
-
Introduction
-
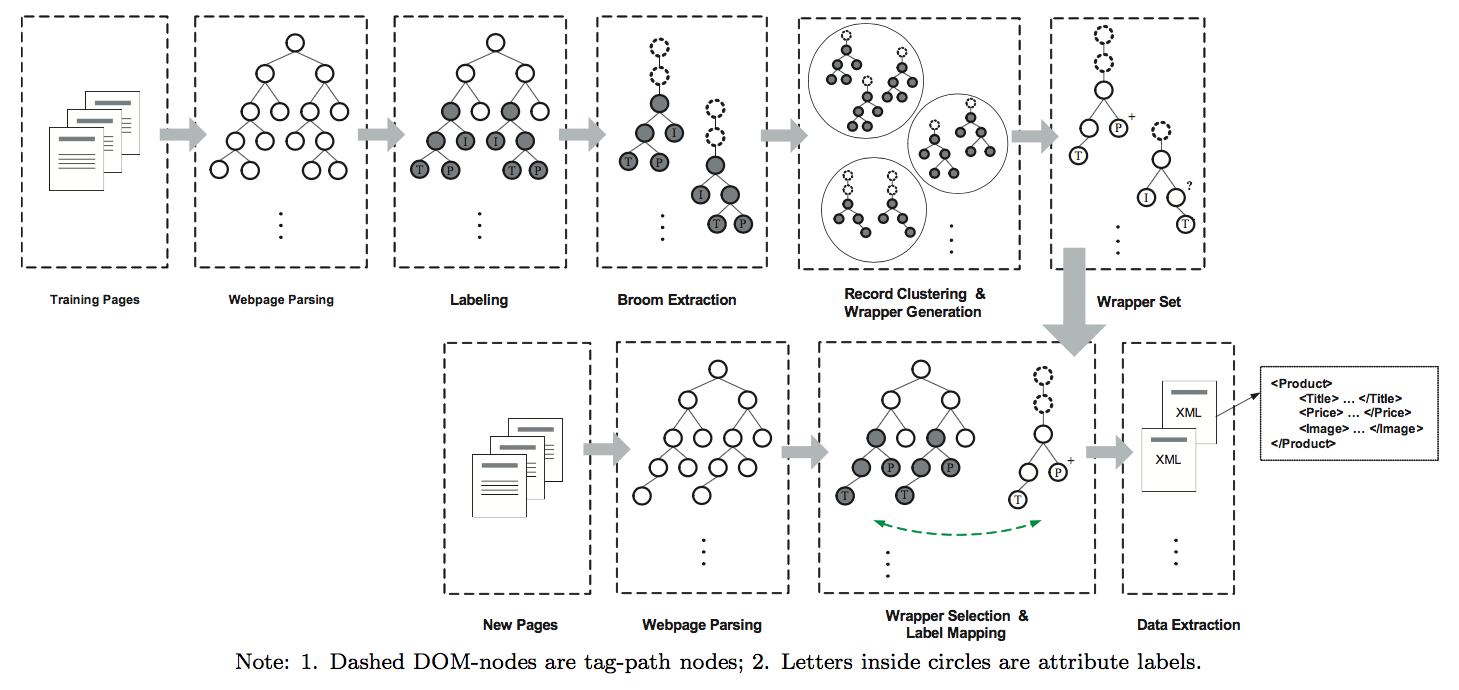
Data Representation
-
System Overview
-
Record Wrapper Induction
-
Algorithm
-
Record Clustering & Wrapper Generation
-
Constructing Wrapper Libraries
-
Record Extraction
-
Record Disambiguation
-
Experiments
-
Conclusion
Abstract
- Web information is often presented in the form of record, e.g., a product record on a shopping website or a personal profile on a social utility website.
- In our system, we use a novel 「broom」 structure to represent both records and generated wrappers.
Introduction
- Much Web information is presented in the form of a Web record which exists in both detail and list pages.

Introduction
- The task of extracting records from web pages is usually implemented by programs called wrappers.
- The process of leaning a wrapper from a group of similar pages is called wrapper induction
Introduction
-
Most traditional wrapper techniques have issues dealing with web records since there is no clear boundary for partitioning different records from the HTML source.


Introduction
-
This system is able to effectively extract records and identify their internal semantics at the same time.
-
Our record-level wrapper technique makes the following contributions:
-
We propose a novel 「broom」 structure to represent a record
-
We propose using context words to disambiguate different attributes that are embedded in similar HTML tag trees.
-
Data Representation
-
When a page has more than one record, we assign unique IDs (「record id」) to them.
-
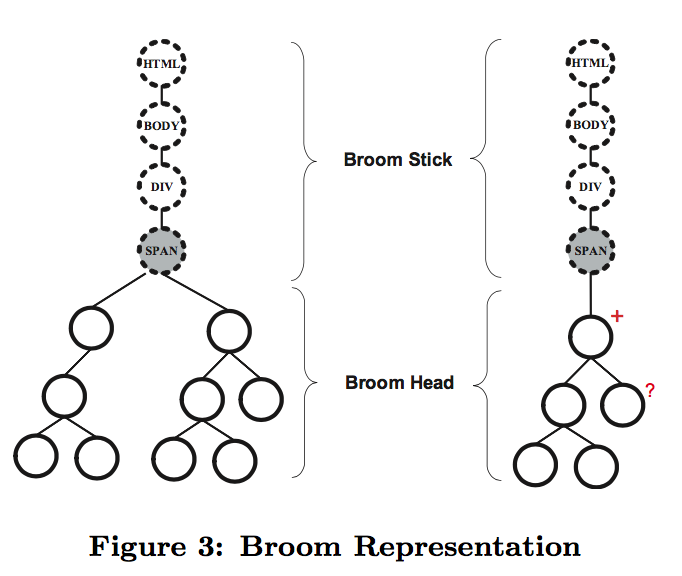
A broom has two parts: the 「head」 and the 「stick」.
-
The broom head is a record region consisting of sub-trees of a DOM-tree;
-
The broom stick is a tag-path starting from the root tag HTML to the top of the record region.
-
-
Wrappers are also represented in such broom structures.
Data Representation
Data Representation
- For a specific website, different types of records may have the same sub-tree structure.
-
Records in a website can be grouped by their tag- paths.
-
A wrapper should be used to only extract records which have the same tag-paths as itself.
-
System Overview
System Overview
Record Wrapper Induction
-
Definition
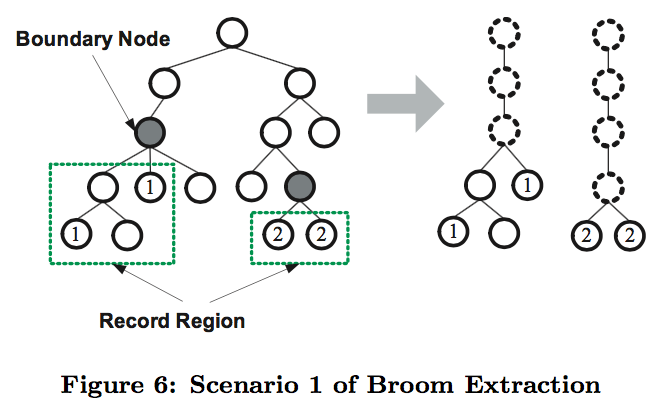
- Boundary Node:Given a labeled DOM- tree and a record ID i, then the boundary node of record i is the root node of a minimal sub-tree which can fully cover all nodes of record i.
-
Record Region:Given a labeled DOM- tree and a record ID i, then the record region of record i is the smallest set of sub-trees (a forest) which satisfies the following conditions: (1) They can fully cover all nodes of record i (2) They are consecutive siblings rooted at the boundary node of record i.
Record Wrapper Induction
Record Wrapper Induction
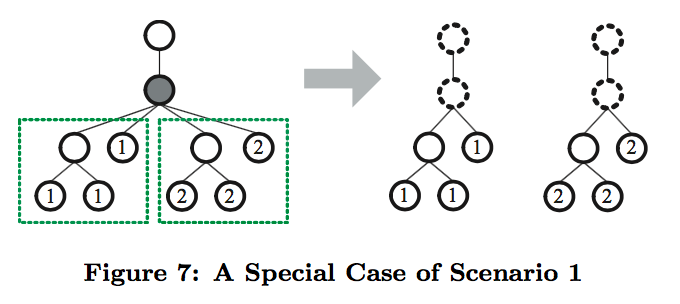
Record Wrapper Induction
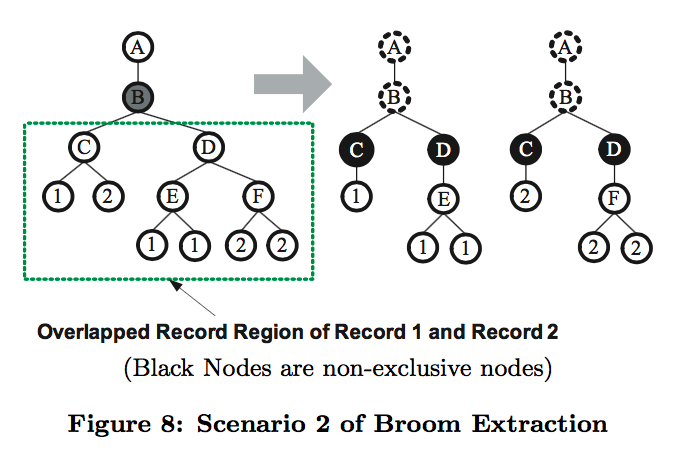
Algorithm

Record Clustering & Wrapper Generation
- As both template detection and wrapper generation are based on a well-defined pair-wise similarity metrics, that approach can achieve a joint optimization by the criterion of extraction accuracy.
Constructing Wrapper Libraries
- The main task of this construction process is to merge different tag-paths into a tree structure
- This is a top-down process of merging same prefixes of multiple tag-paths
Constructing Wrapper Libraries
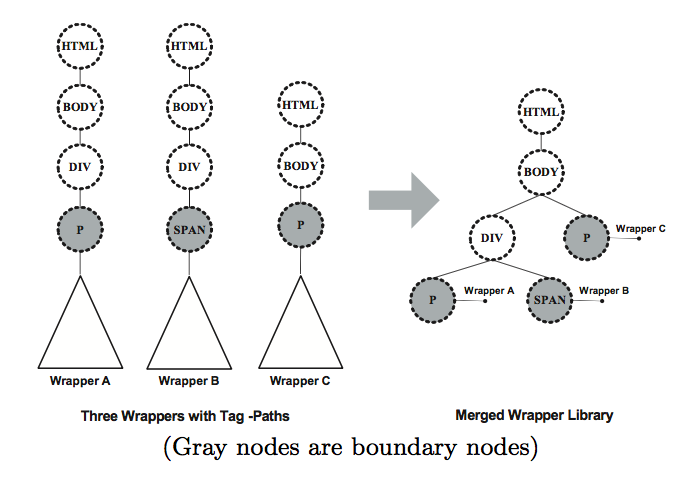
Record Extraction


Record Disambiguation
-
Our approach considers surrounding text in wrapper induction selectively.
-
There are multiple possible alignments with the same smallest aligning cost, the one with less text mismatch will be chosen as the final solution.

Experiments
-
Dataset
-
We collected our experimental data from 16 real-life large- scale websites belonging to four different domains.
-
Experiments
- :the extracted metadata
- :the manually labeled ground-truth metadata
- suppose record in is aligned with record in , the attribute-level precision ( ) and recall ( ) for record re can be calculated with the following equations
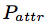
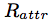
Experiments

Experiments

Experiments
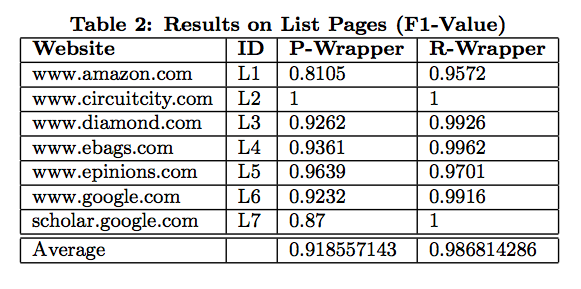

Experiments
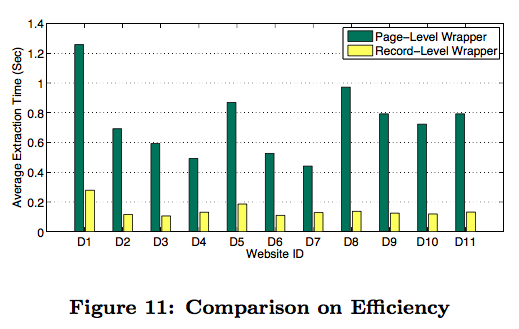
Conclusion
-
This paper describes a record-level wrapper induction system which is able to effectively extract records and identify their internal semantics at the same time.
-
Compared to traditional page-level wrapper methods, the proposed approach not only saves a lot of effort made in manually labeling but also performs data extraction more efficiently.