Introduction to Machine Learning on IBM Cloud
Upkar Lidder
http://bit.ly/ibm-hive-ml
IBM Developer
https://slides.com/upkar/ai-ml-on-ibm-cloud
> ulidder@us.ibm.com > @lidderupk > upkar.dev
Prerequisites
@lidderupk
IBM Developer
1. Create IBM Cloud Account using THIS URL
3. If you already have an account, use the above URL to sign into your IBM Cloud account.
2. Check your email and activate your account. Once activated, log back into your IBM Cloud account using the link above.
ML Hype
@lidderupk
IBM Developer
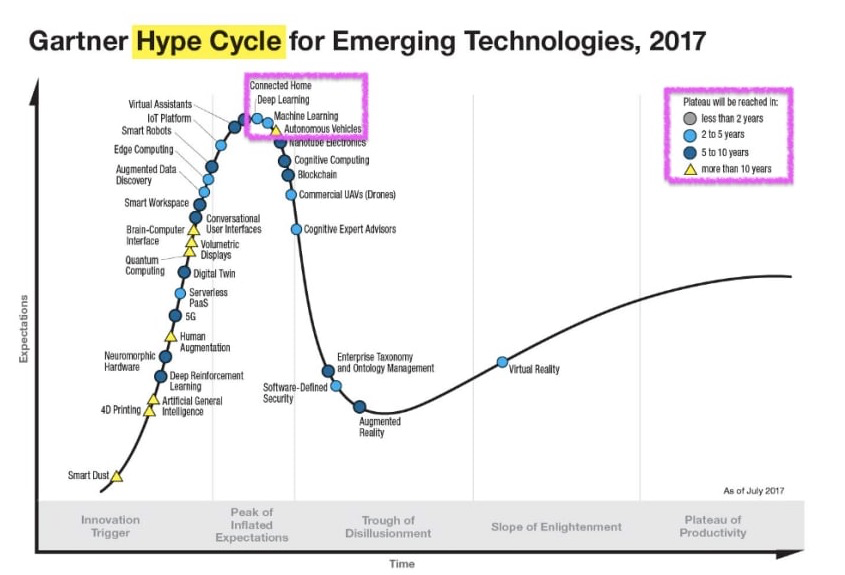

ML on IBM Cloud - Cognitive Services
@lidderupk
IBM Developer
Natural Language Processing
Visual Recognition






IBM Code Patterns
@lidderupk
IBM Developer
Question - predict median price for houses in a block
@lidderupk
IBM Developer

http://bit.ly/california-houses-csv
1. longitude: A measure of how far west a house is; a higher value is farther west
2. latitude: A measure of how far north a house is; a higher value is farther north
3. housingMedianAge: Median age of a house within a block; a lower number is a newer building
4. totalRooms: Total number of rooms within a block
5. totalBedrooms: Total number of bedrooms within a block
6. population: Total number of people residing within a block
7. households: Total number of households, a group of people residing within a home unit, for a block
8. medianIncome: Median income for households within a block of houses (measured in tens of thousands of US Dollars)
9. oceanProximity: Location of the house w.r.t ocean/sea
10. medianHouseValue: Median house value for households within a block (measured in US Dollars)
ML Lifecycle
@lidderupk
IBM Developer
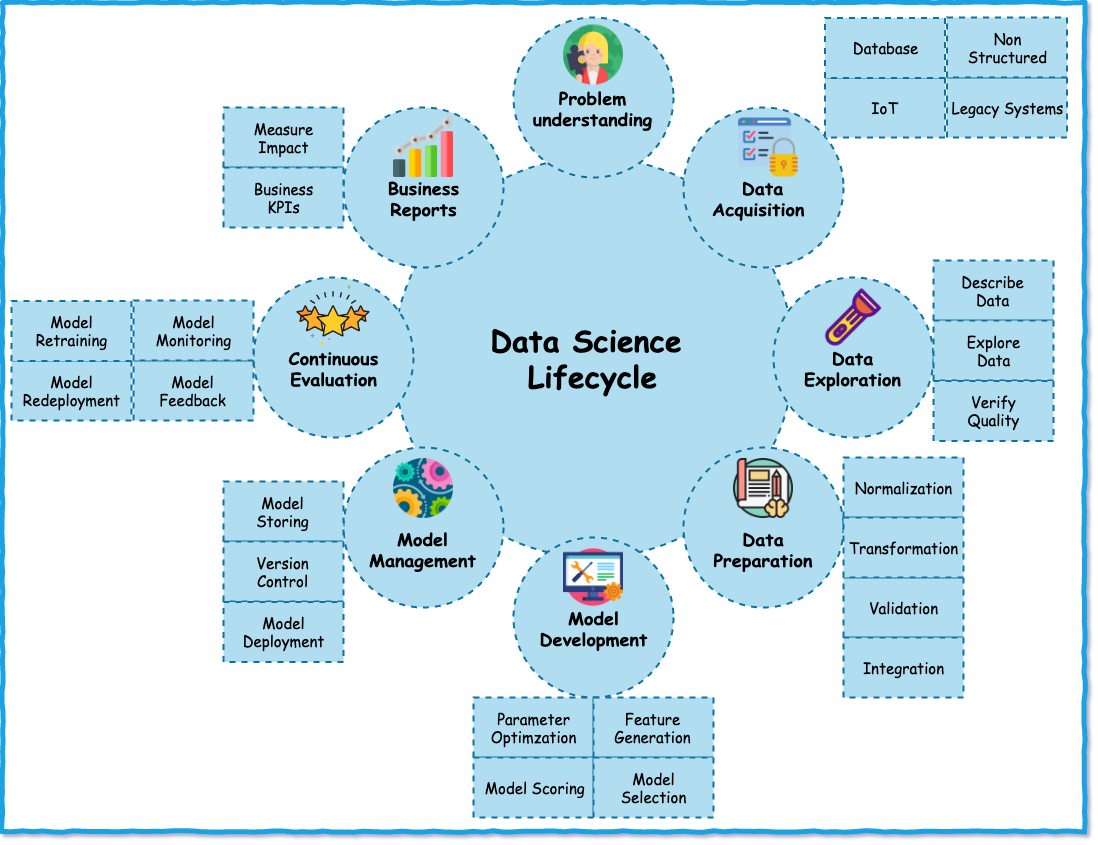
ML on IBM Cloud - Guided ML
@lidderupk
IBM Developer
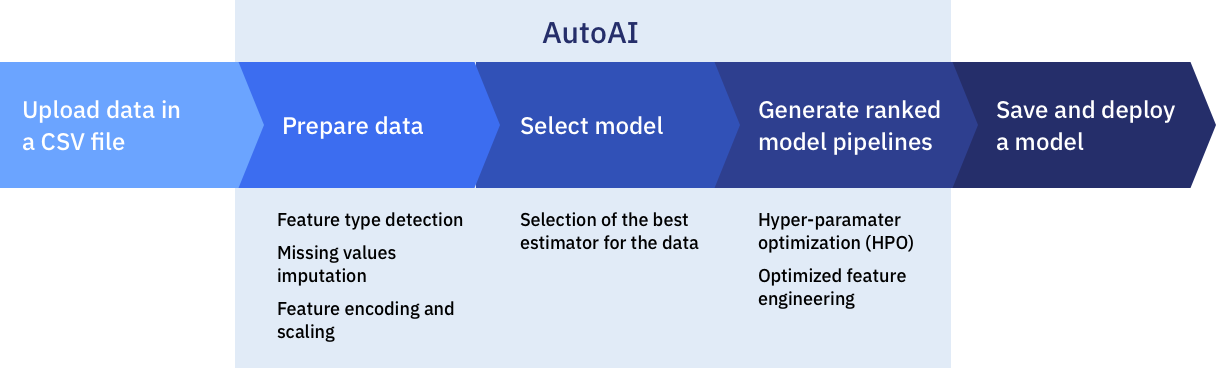
To help simplify an AI lifecycle management, AutoAI automates:
- Data preparation
- Model development
- Feature engineering
- Hyper parameter optimization
I want to build my own!
🤬
😤
Watson Studio & Watson Machine Learning
@lidderupk
IBM Developer
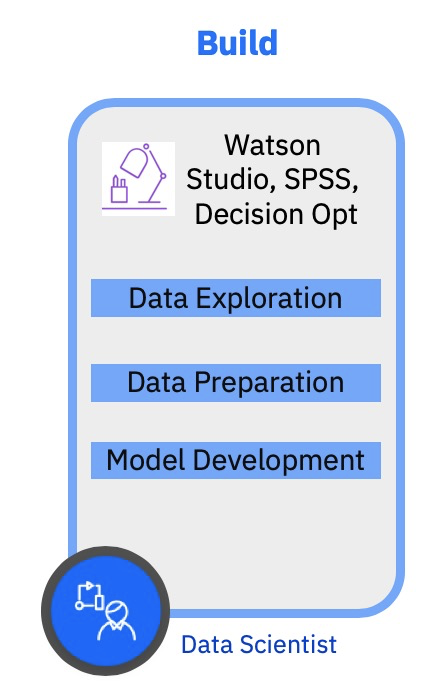
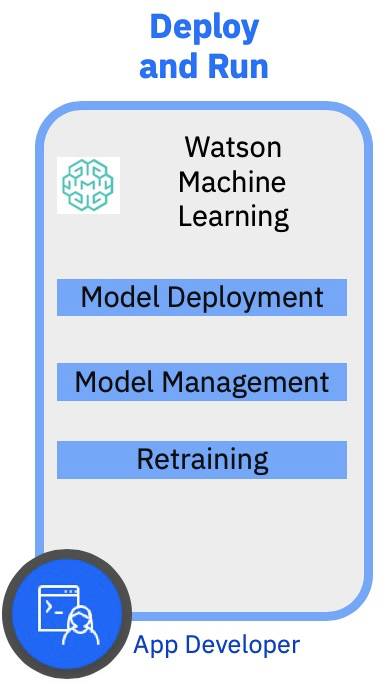




Watson Studio
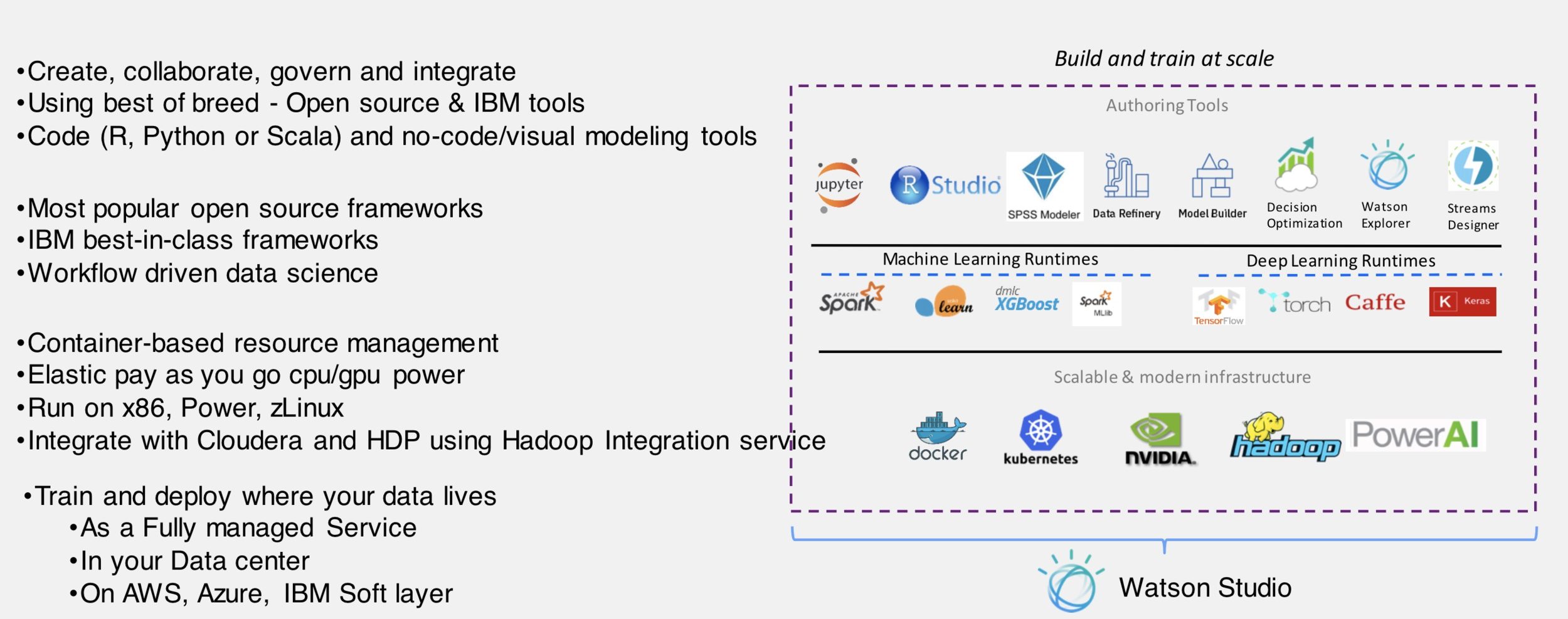
IBM Watson Studio
@lidderupk
IBM Developer
AutoAI
@lidderupk
IBM Developer
IBM Watson Studio - project based development platform
@lidderupk
IBM Developer
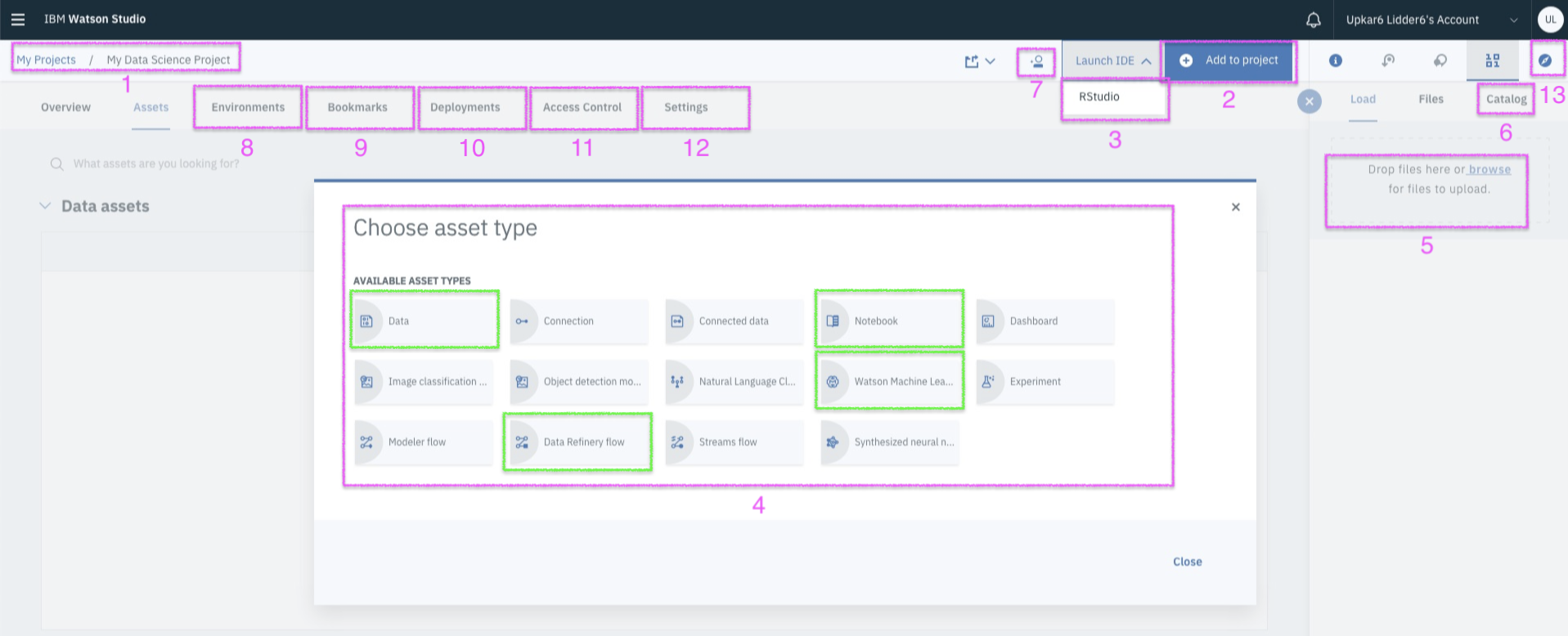
Workshop - Goals
@lidderupk
IBM Developer
Successfully Create, Store and Deploy a Linear Regression Model on IBM Cloud using Watson Studio and Watson Machine Learning Services.
Linear regression - try to fit a line
@lidderupk
IBM Developer
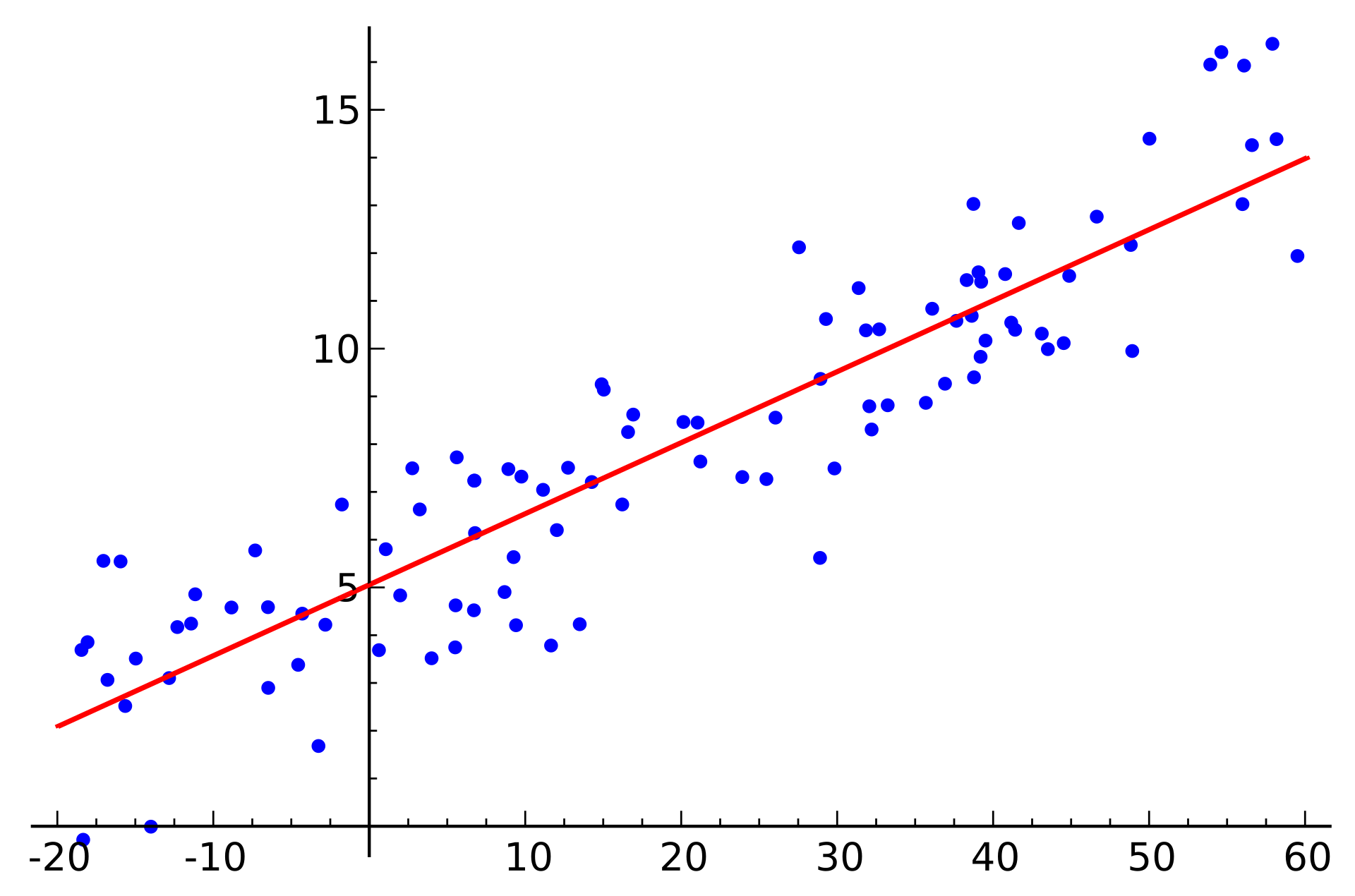
Median House Price
Property Tax
#sqft
Linear regression - loss function to get best fit
@lidderupk
IBM Developer
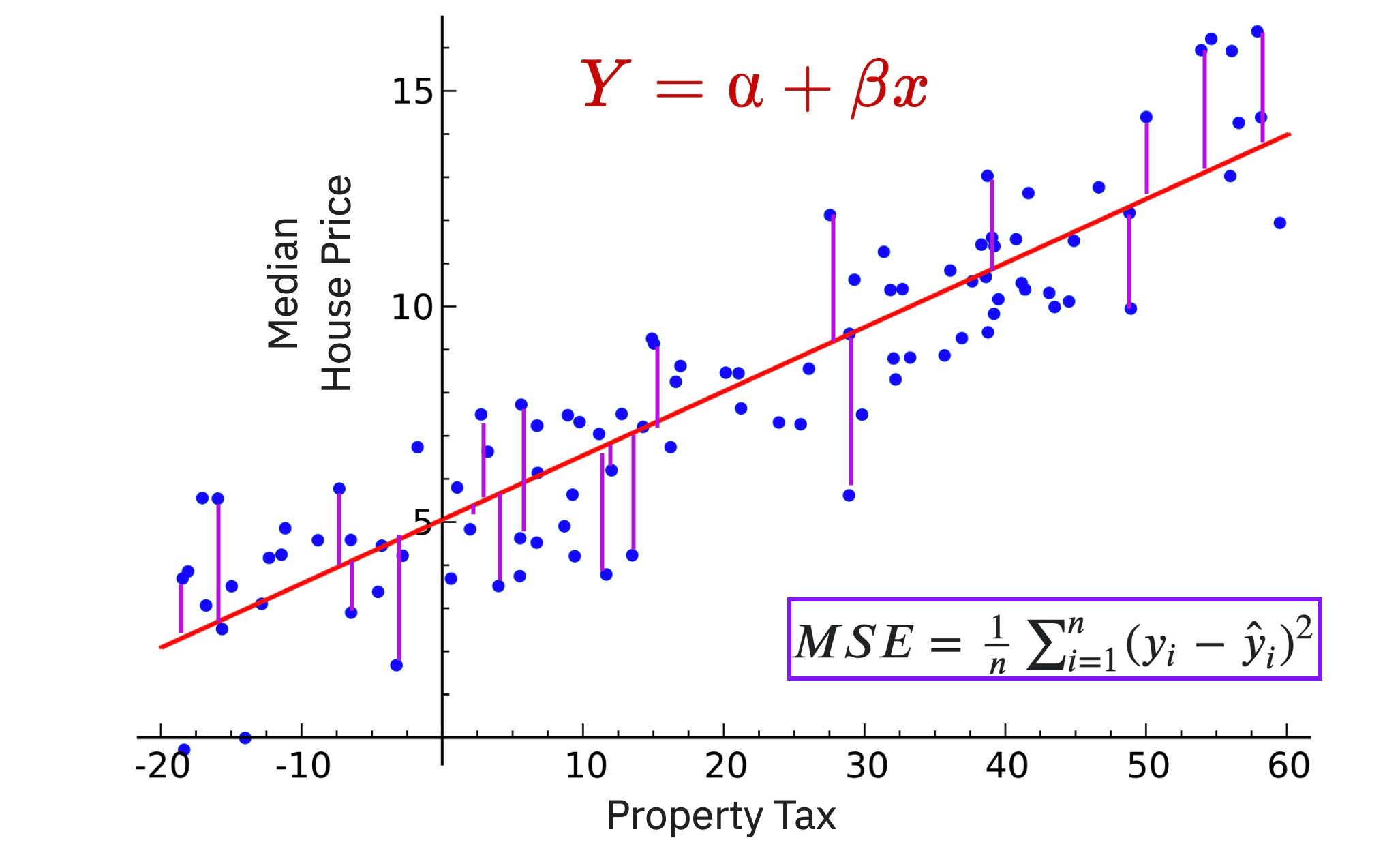
#sqft
Steps
@lidderupk
IBM Developer
- Sign up / Log into IBM Cloud - http://bit.ly/ibm-hive-ml
- Create Watson Studio Service.
- Sign into Watson Studio and create a new Data Science Project. It also creates a Cloud Object Store for you.
- Upload csv data to your project.
- Add a new AutoAI Experiment to your project.
- Create a ML Model and save it to IBM Cloud.
- Create a new deployment on IBM Cloud.
- Test your model !
Step 1 - sign up/ log into IBM Cloud
@lidderupk
IBM Developer
Step 2 - locate Watson Studio in Catalog
@lidderupk
IBM Developer
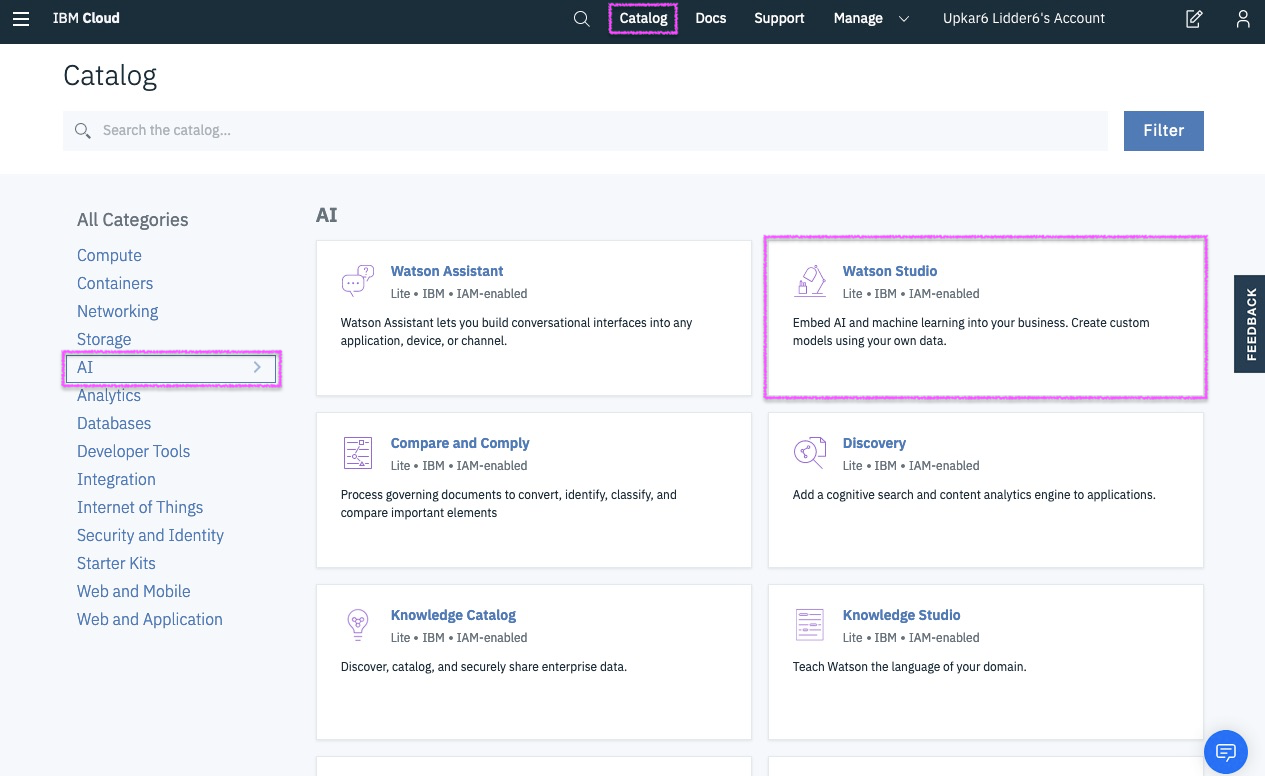
Step 3a - create Watson Studio instance
@lidderupk
IBM Developer
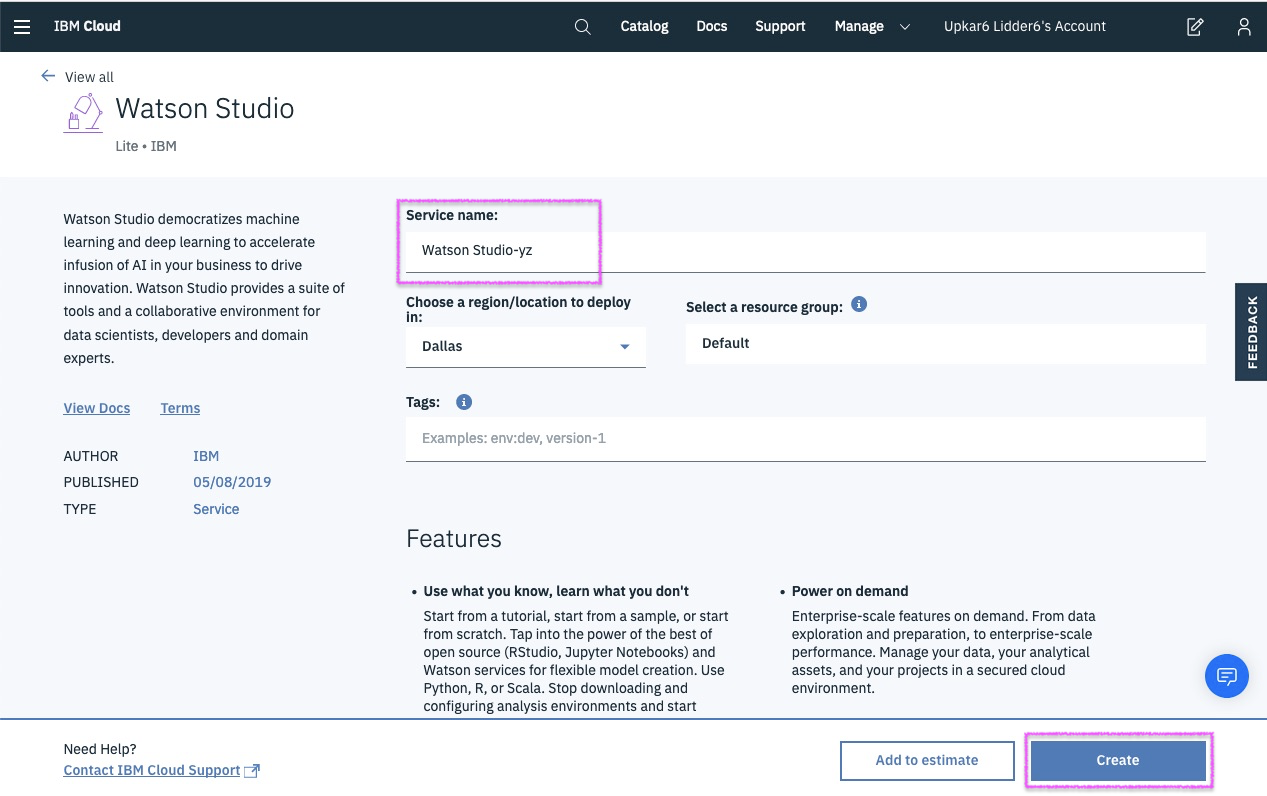
Step 3b - already have Watson Studio? Find it in Resources
@lidderupk
IBM Developer
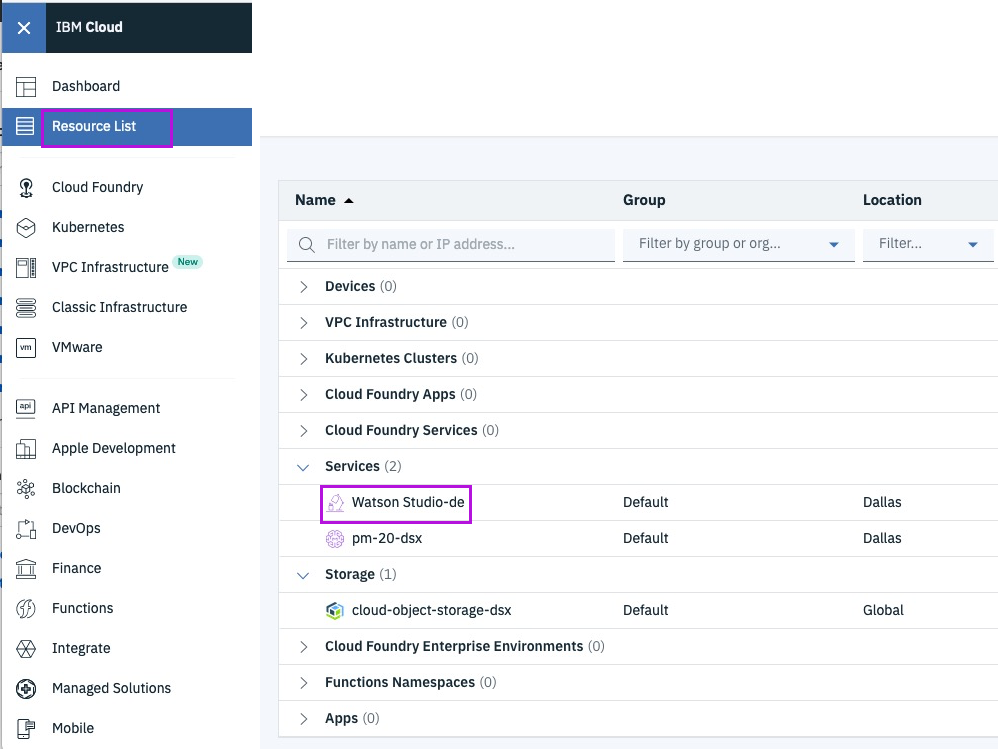
Step 4 - launch Watson Studio
@lidderupk
IBM Developer
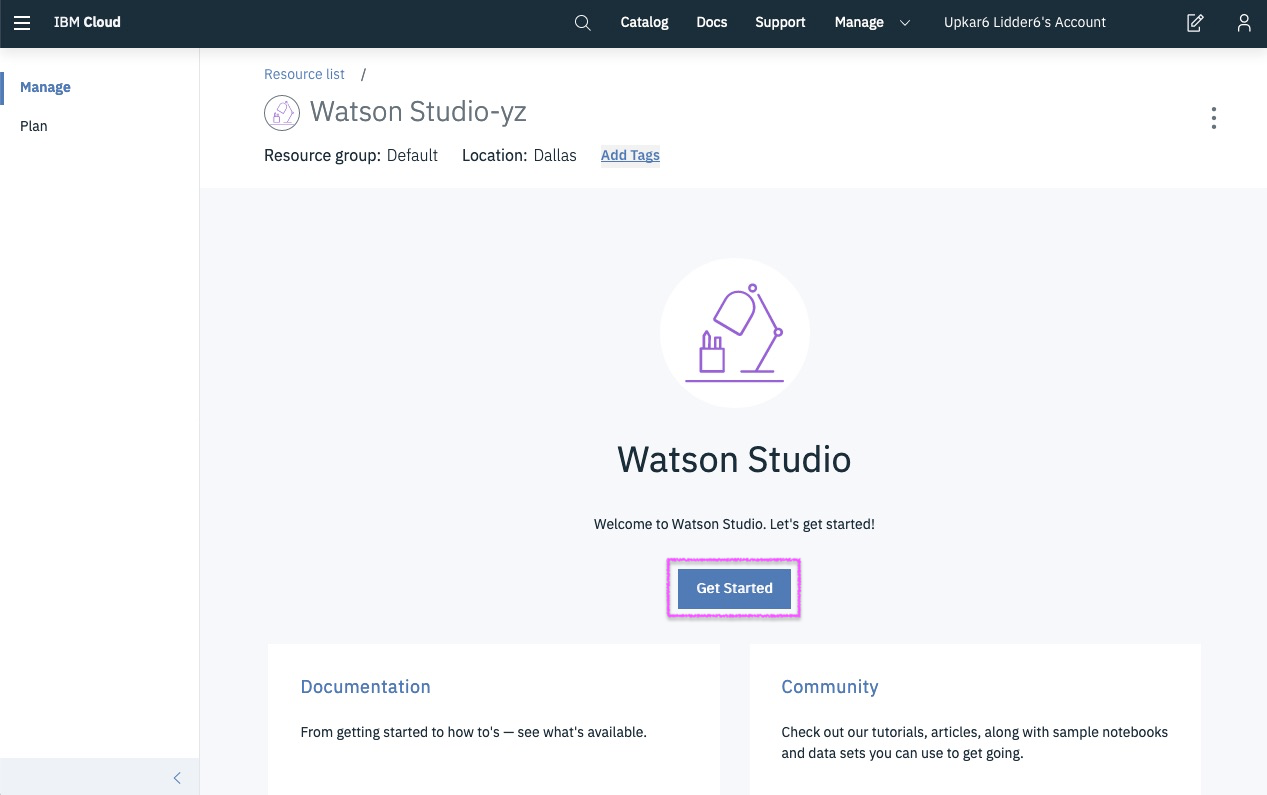
Step 5 - create a new project
@lidderupk
IBM Developer
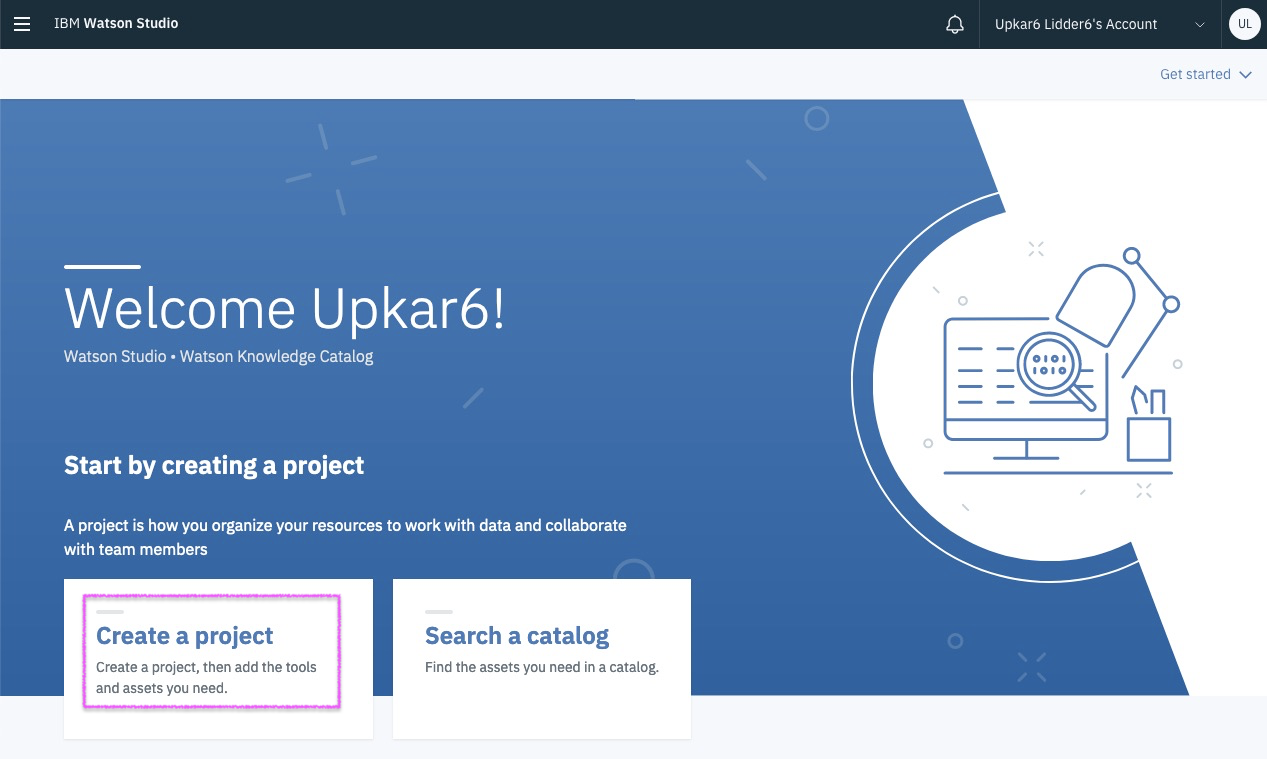
Step 6 - pick Data Science starter
@lidderupk
IBM Developer
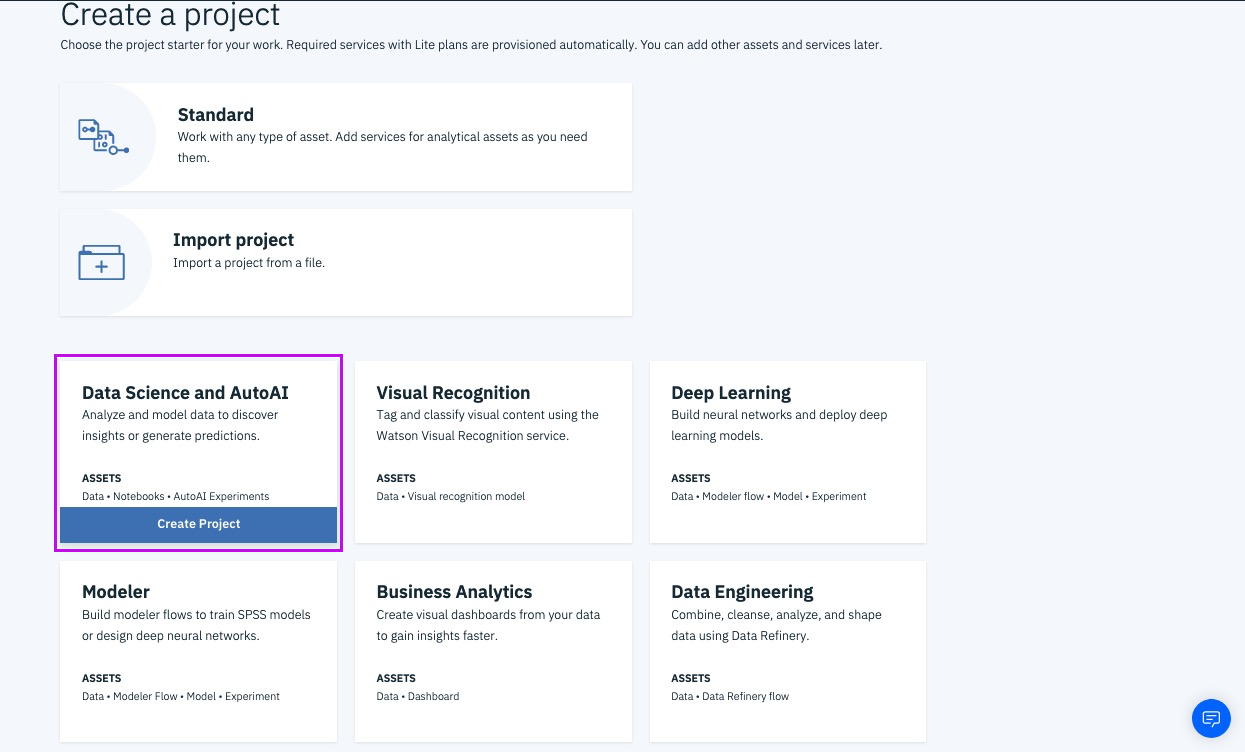
Step 6a - pick region [US South]
@lidderupk
IBM Developer
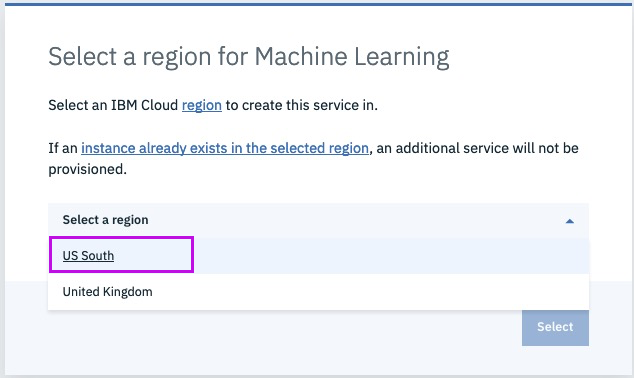
Step 7 - give the project a name and assign COS
@lidderupk
IBM Developer
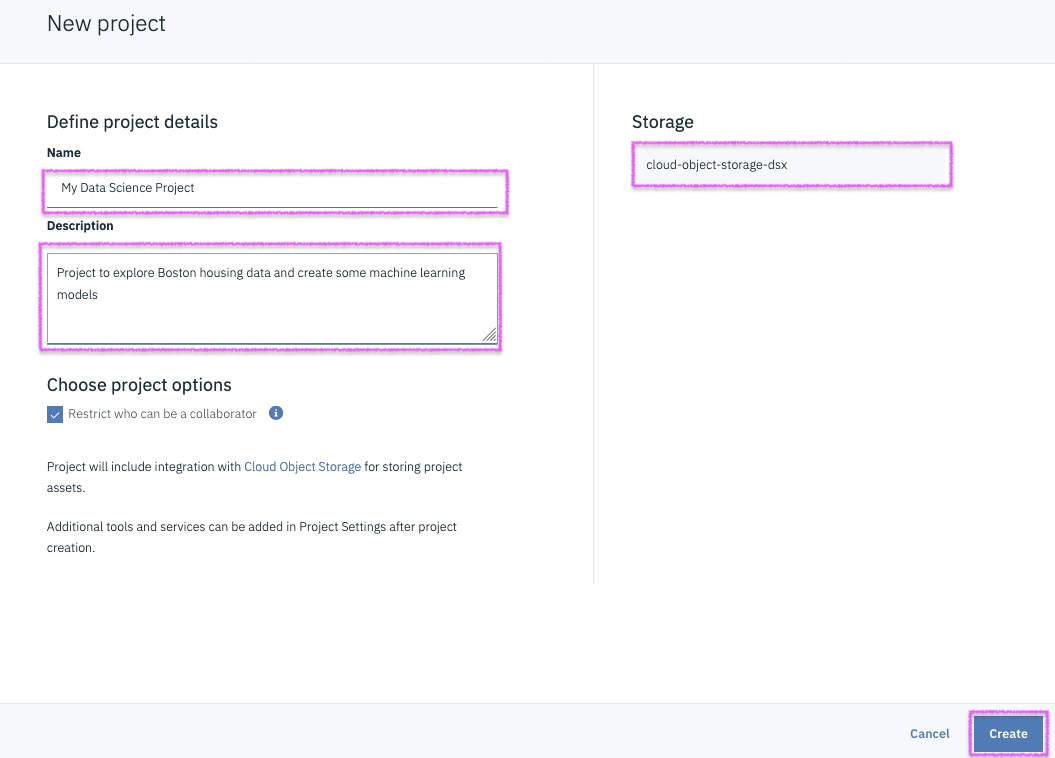
Step 8 - open asset tab, this is your goto page!
@lidderupk
IBM Developer
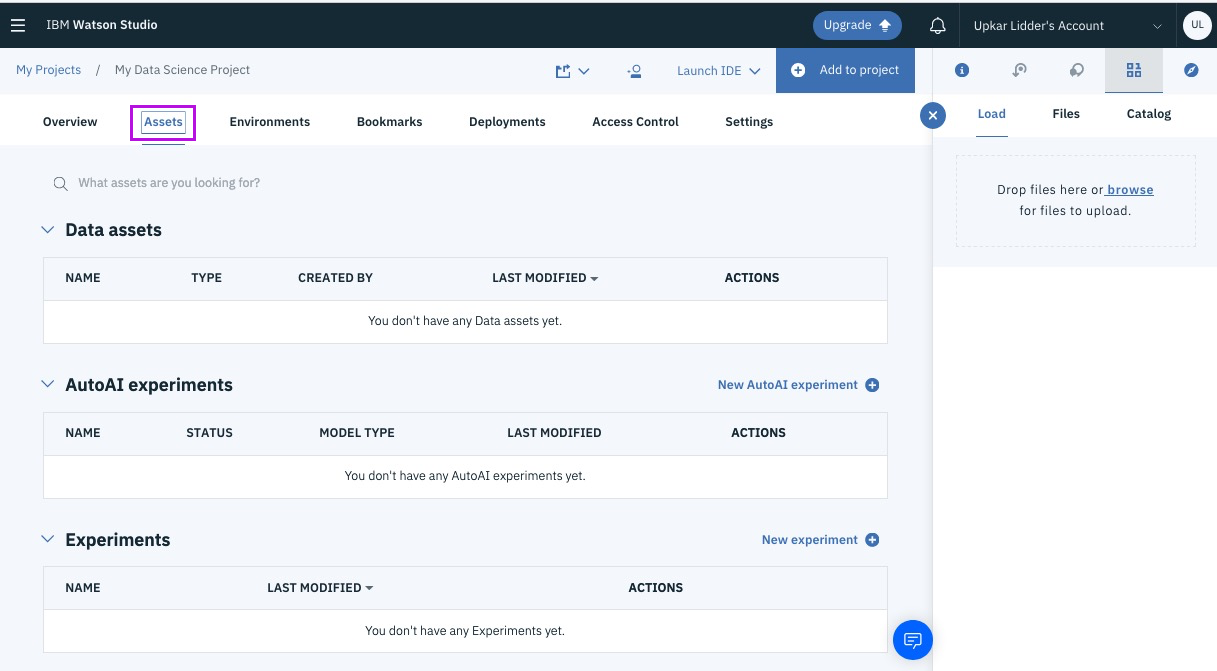
Step 9 - create a new AutoAI experiment
@lidderupk
IBM Developer
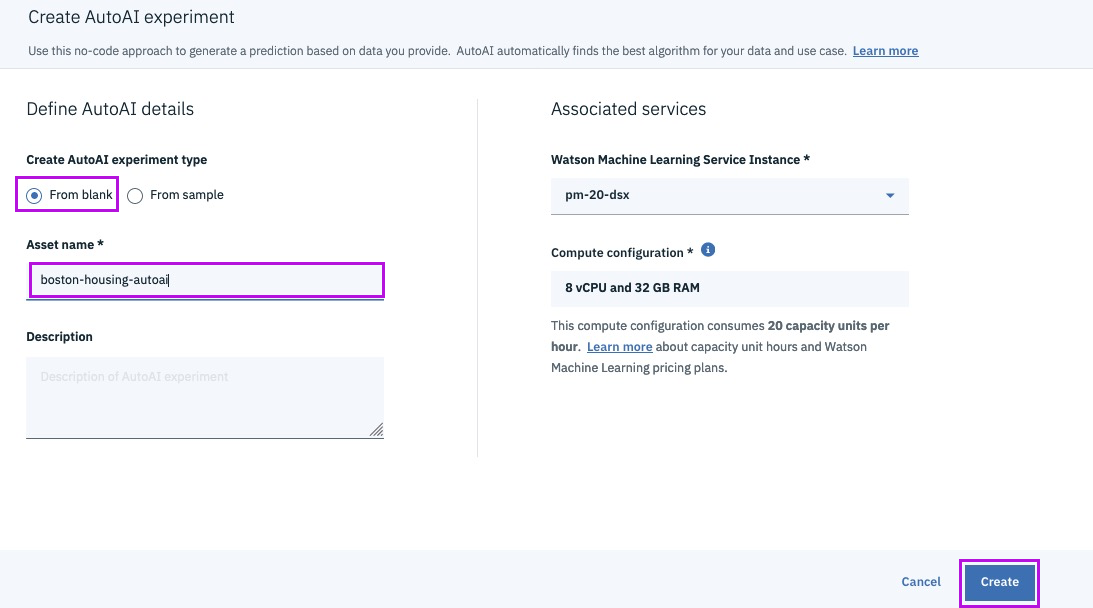
Step 10 - adding training data
@lidderupk
IBM Developer
http://bit.ly/boston-house-csv
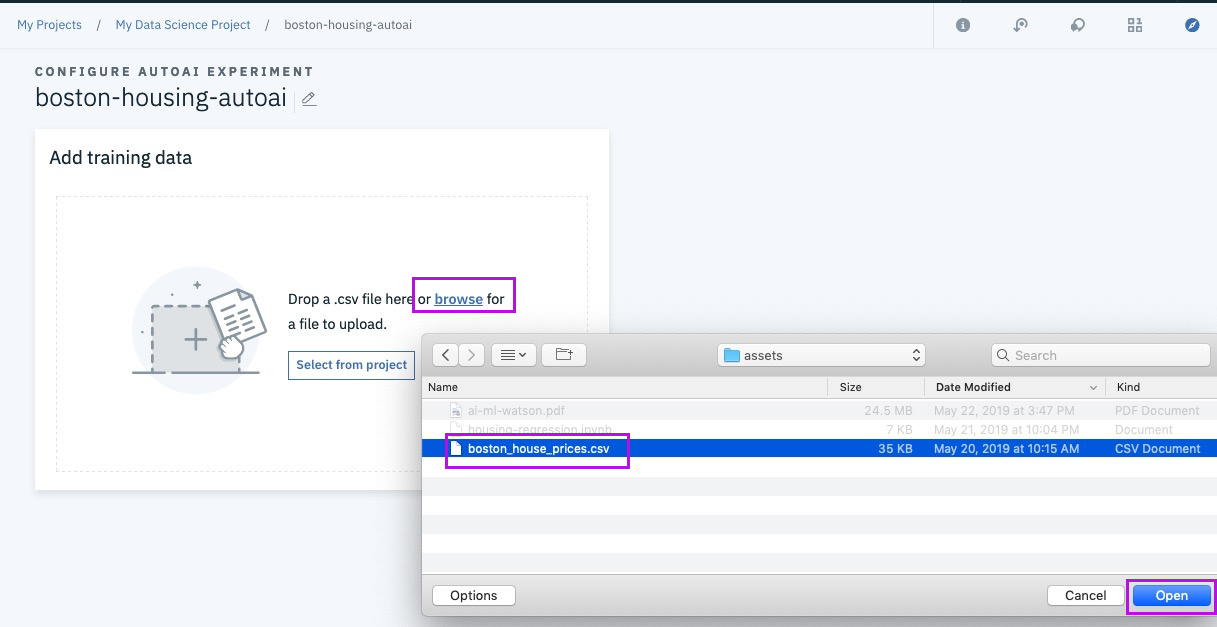
Step 11 - pick target column to predict
@lidderupk
IBM Developer
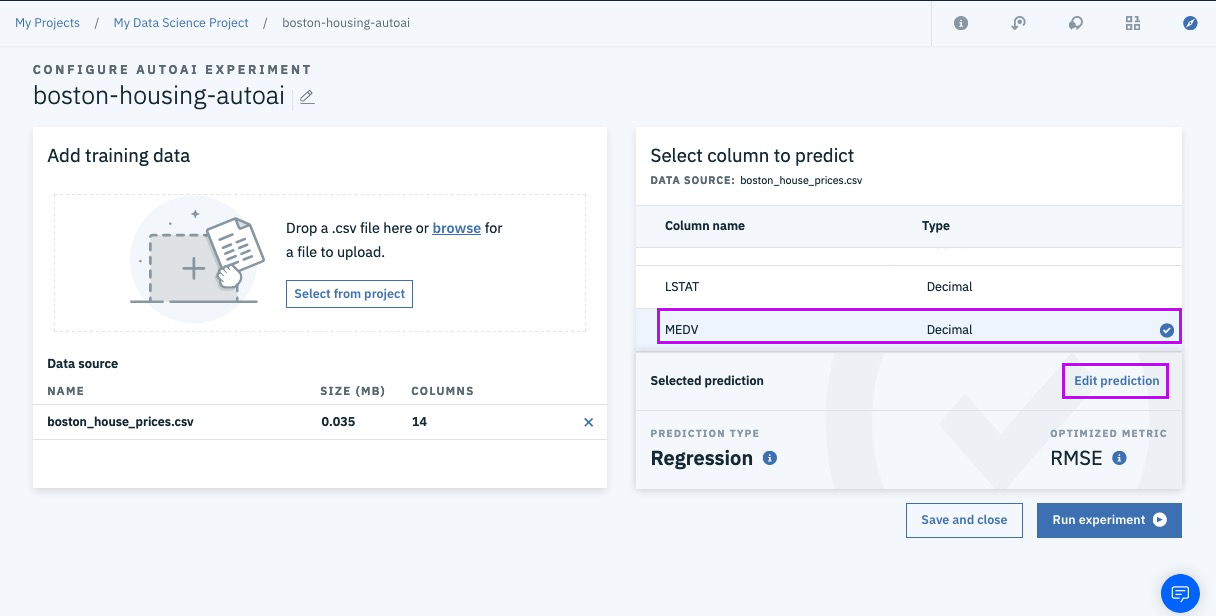
Step 11a - change model and metric if needed
@lidderupk
IBM Developer
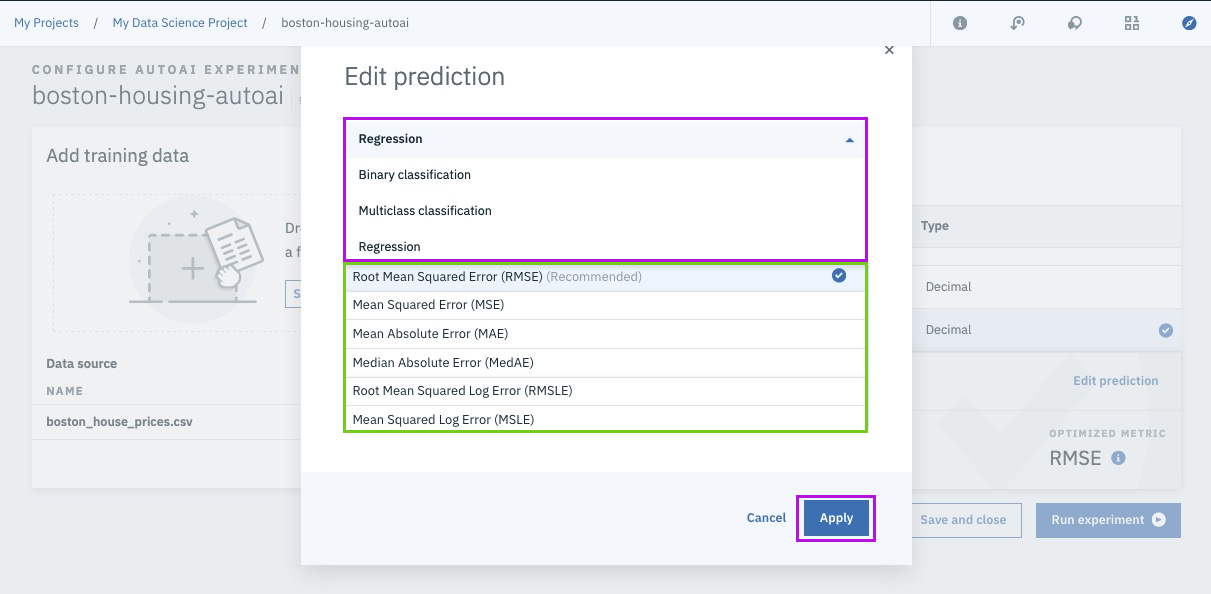
Step 12 - run experiment
@lidderupk
IBM Developer
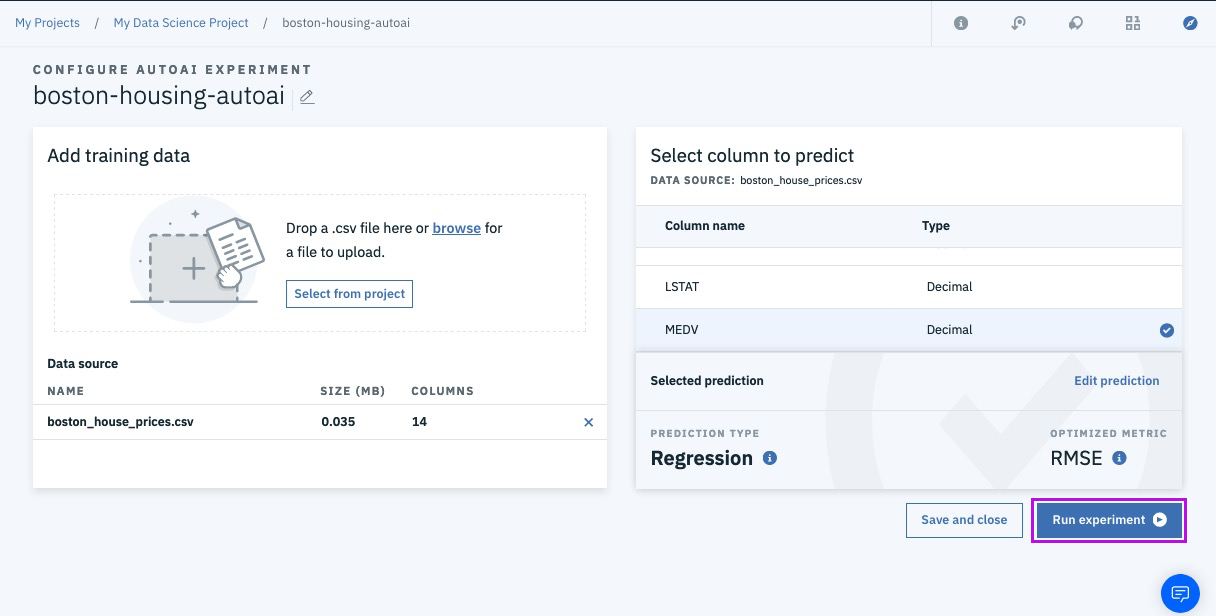
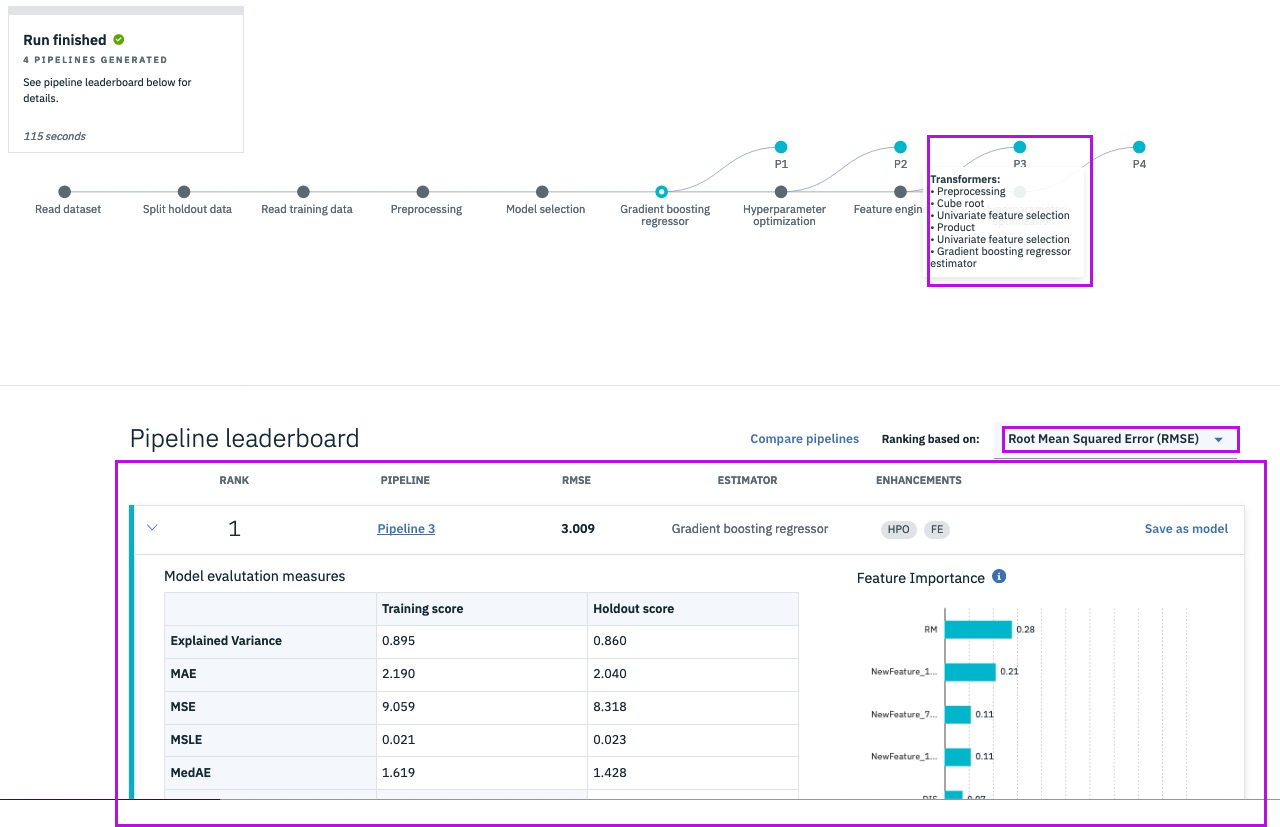
Step 13a - sit back and relax!
@lidderupk
IBM Developer
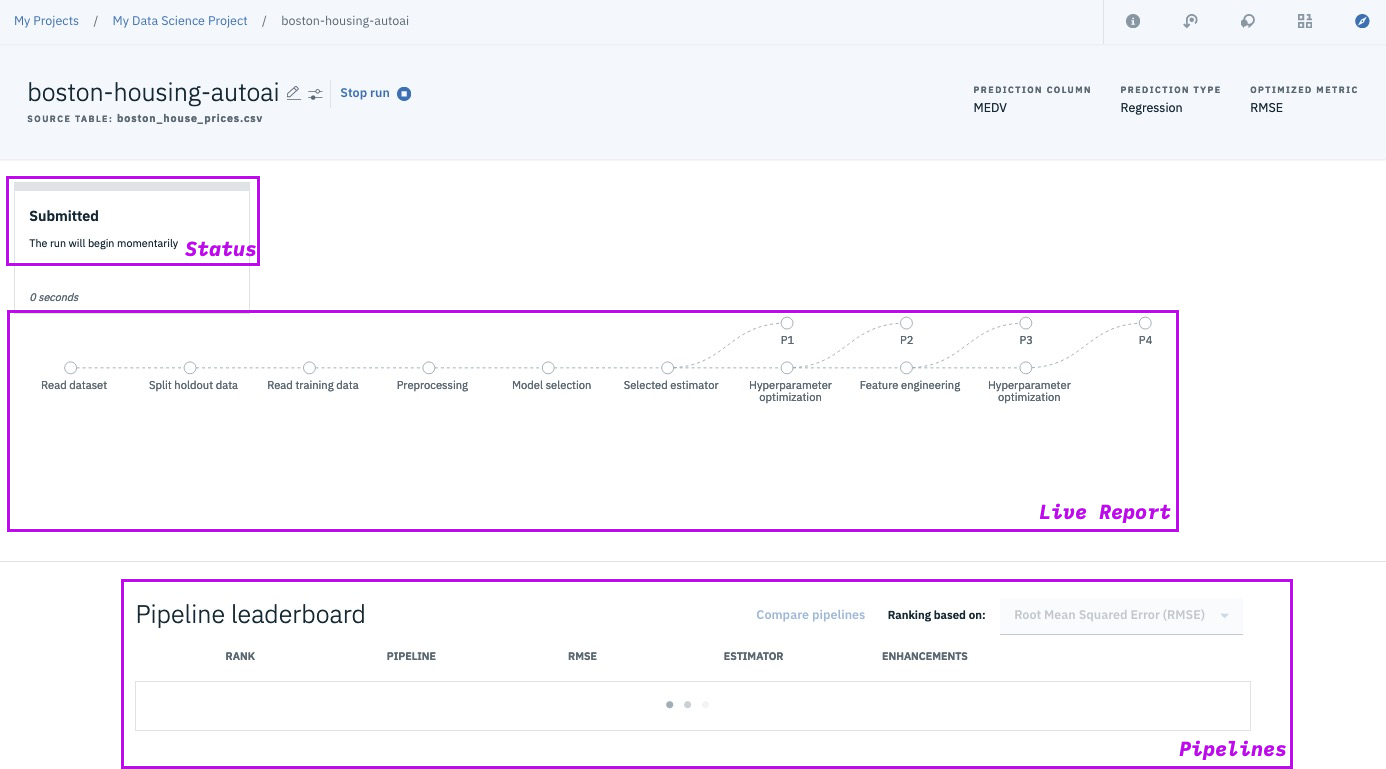
Step 13b - explore different models in the pipeline
@lidderupk
IBM Developer
Step 14 - save the best model
@lidderupk
IBM Developer
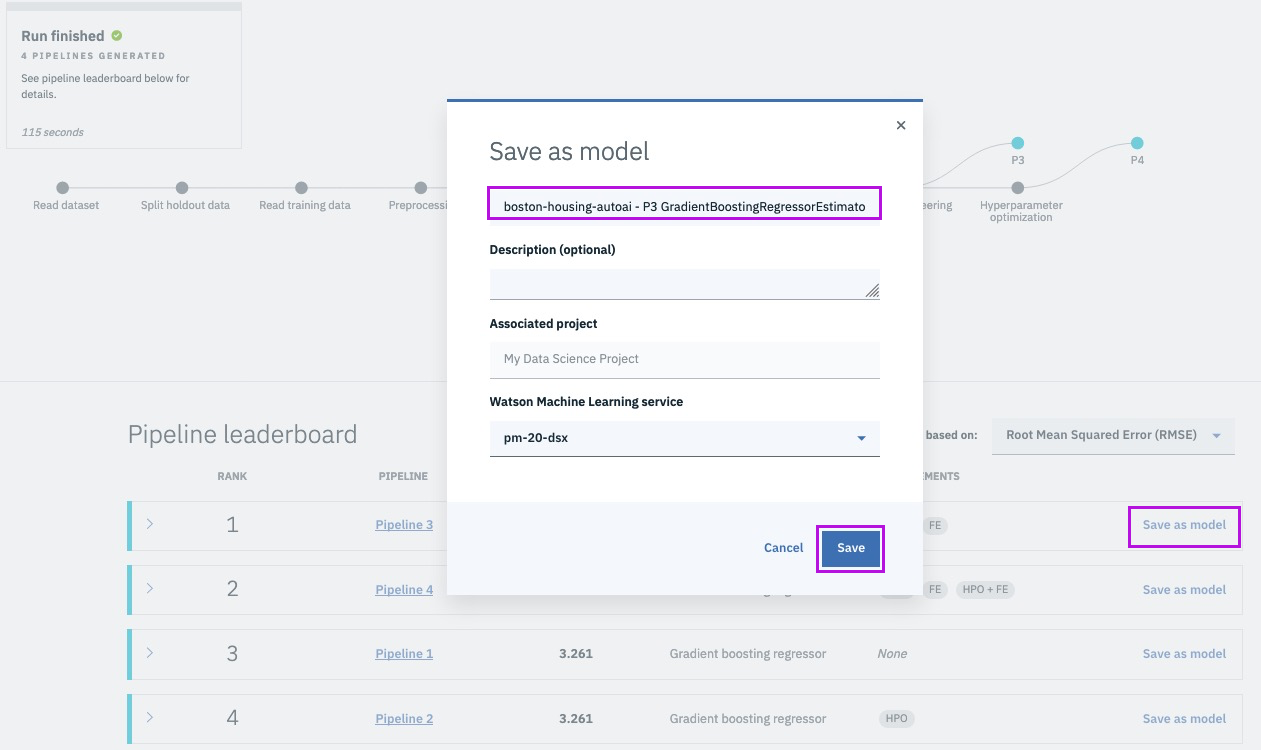
@lidderupk
IBM Developer
Step 15a - view the model

@lidderupk
IBM Developer
Step 15b - view the model, another way
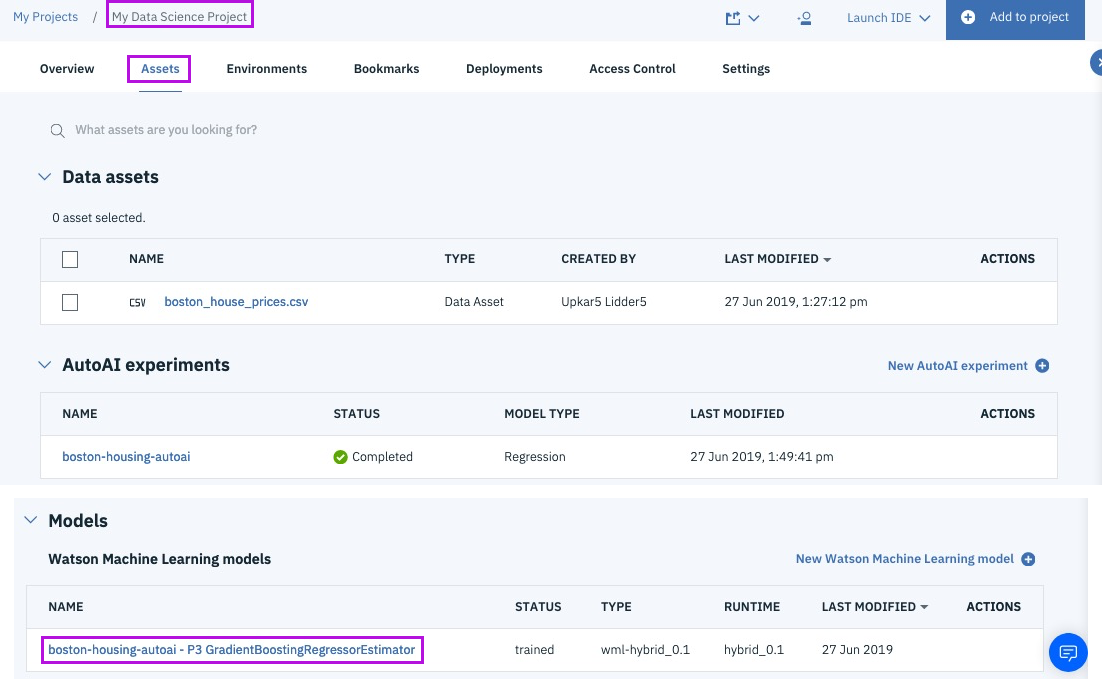
@lidderupk
IBM Developer
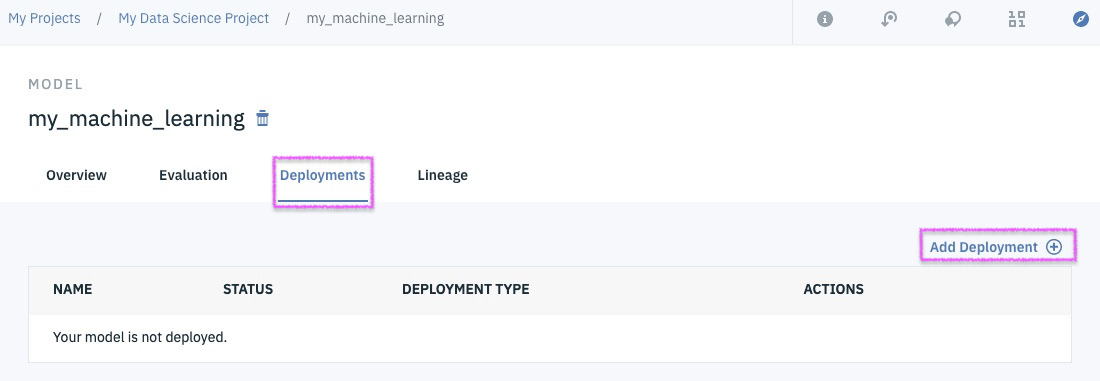
Step 16 - add a new deployment
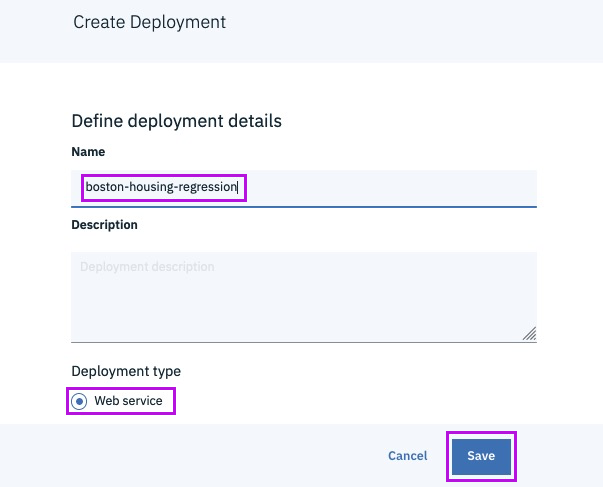
@lidderupk
IBM Developer
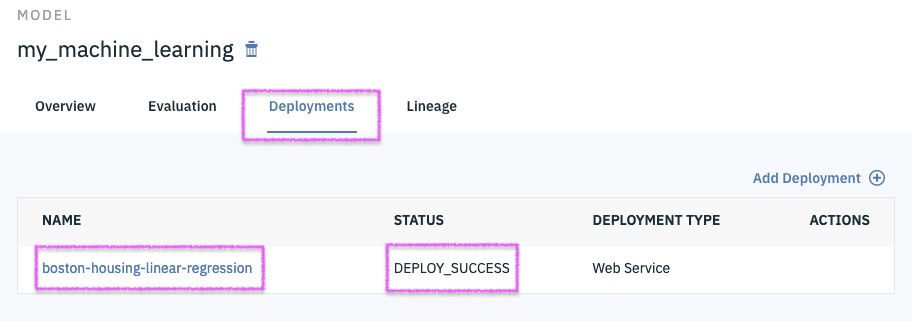
1
2
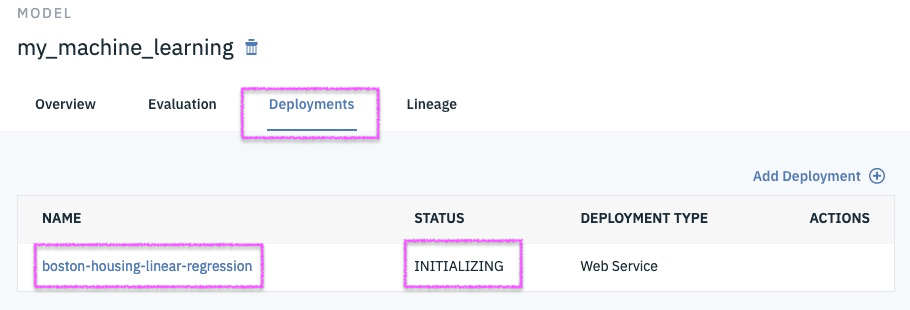
Step 17 - ensure that deployment is successful with ready status
@lidderupk
IBM Developer
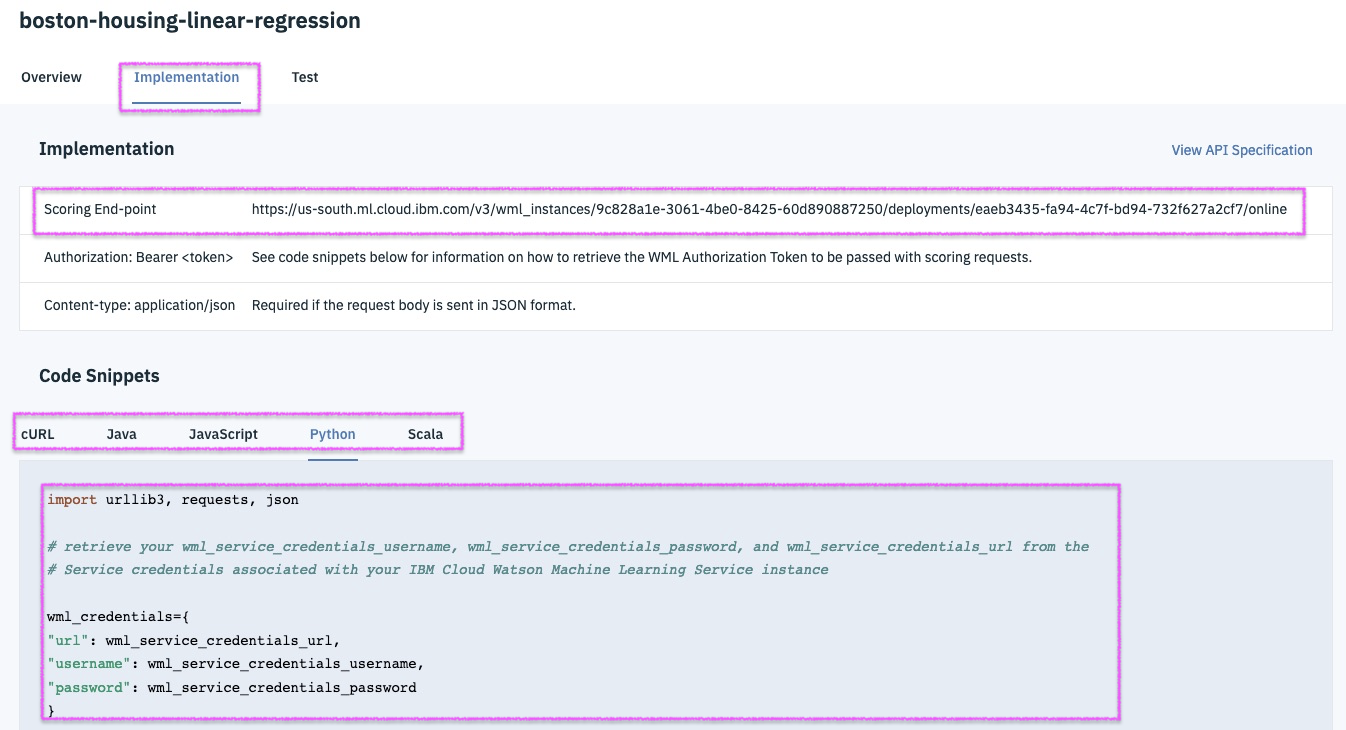
Step 18a - implementation / test the deployed model
@lidderupk
IBM Developer
{"input_data":[{
"fields": ["CRIM","ZN","INDUS","CHAS","NOX","RM","AGE","DIS","RAD","TAX","PTRATIO","B","LSTAT"],
"values": [[0.00632,18,2.31,0,0.538,6.575,65.2,4.09,1,296,15.3,396.9,4.98]]
}]}Step 18b - implementation / test the deployed model
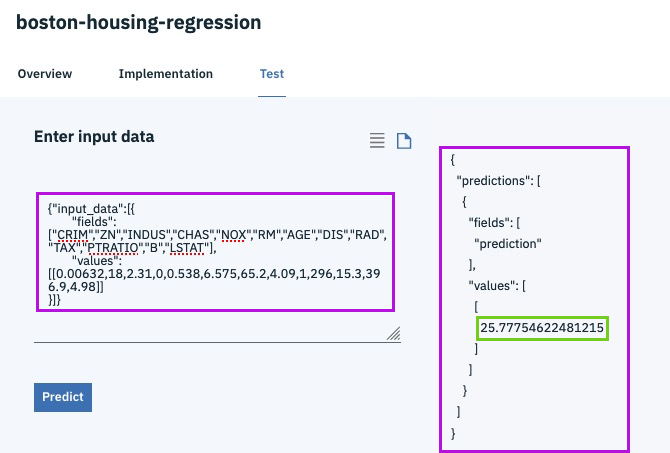
@lidderupk
IBM Developer
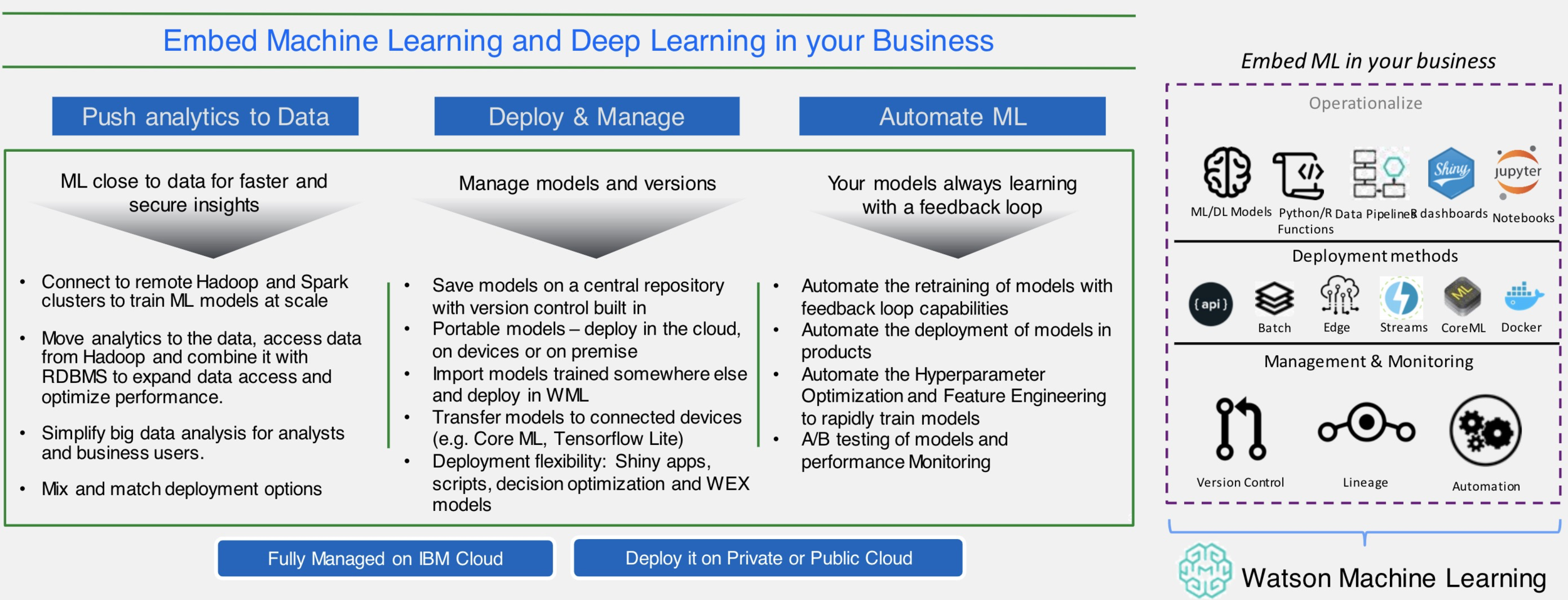
AutoAI - Behind the scenes
Data pre-processing
- analyze, clean and prepare raw data for ML
- automatically detects and categorizes features based on data type
- missing value imputation
- feature encoding
- feature scaling
Automated model selection
- test and rank candidate estimators
- select the best performing estimator with the ranking choice made by the user
Automated Feature Engineering
- transform raw data into combination of features that best fit the model
Hyperparameter Optimization
- refine the best performing model
@lidderupk
IBM Developer
AutoAI - Supported Estimators
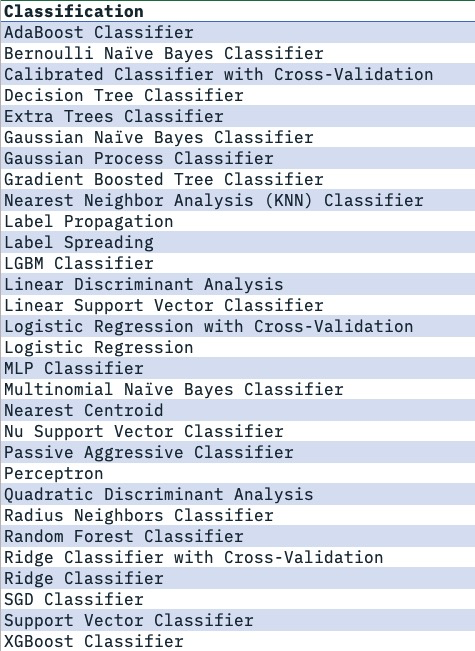
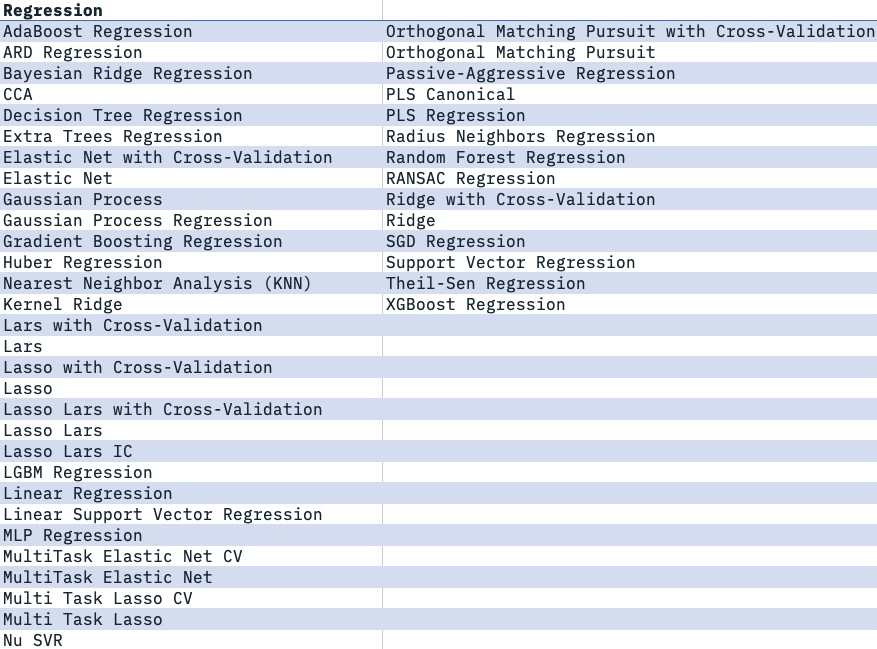
Watson Machine Learning
WML - Supported Frameworks as of 06.21.19
@lidderupk
IBM Developer








IBM Watson Machine Learning
@lidderupk
IBM Developer
IBM Watson Machine Learning Client
@lidderupk
IBM Developer

http://wml-api-pyclient.mybluemix.net/index.html
WML - create scikit-learn linear regression model
@lidderupk
IBM Developer
#import libraries
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder
import pandas as pd
import numpy as np
#read the dataset
housing = df_data_1
#remove empty rows. Ideally we would populate with a reasonable value (median, mean)
housing = housing.dropna(axis=0)
train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)
housing_labels = train_set["median_house_value"].copy()
X_test = test_set.drop("median_house_value", axis=1)
y_test = test_set["median_house_value"].copy()
# use one hot encoding on the categorial columns
cat_attribs = ["ocean_proximity"]
full_pipeline = ColumnTransformer([
("cat", OneHotEncoder(), cat_attribs),
])
housing_prepared = full_pipeline.fit_transform(train_set)
lin_reg = LinearRegression()
lin_reg.fit(housing_prepared, housing_labels)
#let's make some predictions!
some_data = housing.iloc[:5]
some_labels = housing_labels.iloc[:5]
some_data_prepared = full_pipeline.transform(some_data)
print("Predictions:", lin_reg.predict(some_data_prepared))
#evaluate on the test data
X_test_prepared = full_pipeline.transform(X_test)
final_predictions = lin_reg.predict(X_test_prepared)
final_mse = mean_squared_error(y_test, final_predictions)
final_rmse = np.sqrt(final_mse)
print('Final rmse: ', final_rmse)
WML - create scikit-learn linear regression model
@lidderupk
IBM Developer
housing_prepared = full_pipeline.fit_transform(train_set)
lin_reg = LinearRegression()
lin_reg.fit(housing_prepared, housing_labels)
#let's make some predictions!
some_data = housing.iloc[:5]
some_labels = housing_labels.iloc[:5]
some_data_prepared = full_pipeline.transform(some_data)
print("Predictions:", lin_reg.predict(some_data_prepared))
#evaluate on the test data
X_test_prepared = full_pipeline.transform(X_test)
final_predictions = lin_reg.predict(X_test_prepared)
final_mse = mean_squared_error(y_test, final_predictions)
final_rmse = np.sqrt(final_mse)
print('Final rmse: ', final_rmse)
Predictions: [257941.45656895 257941.45656895 257941.45656895 257941.45656895 257941.45656895]
Final rmse: 101502.3371732095
WML - get Machine Learning service credentials
@lidderupk
IBM Developer
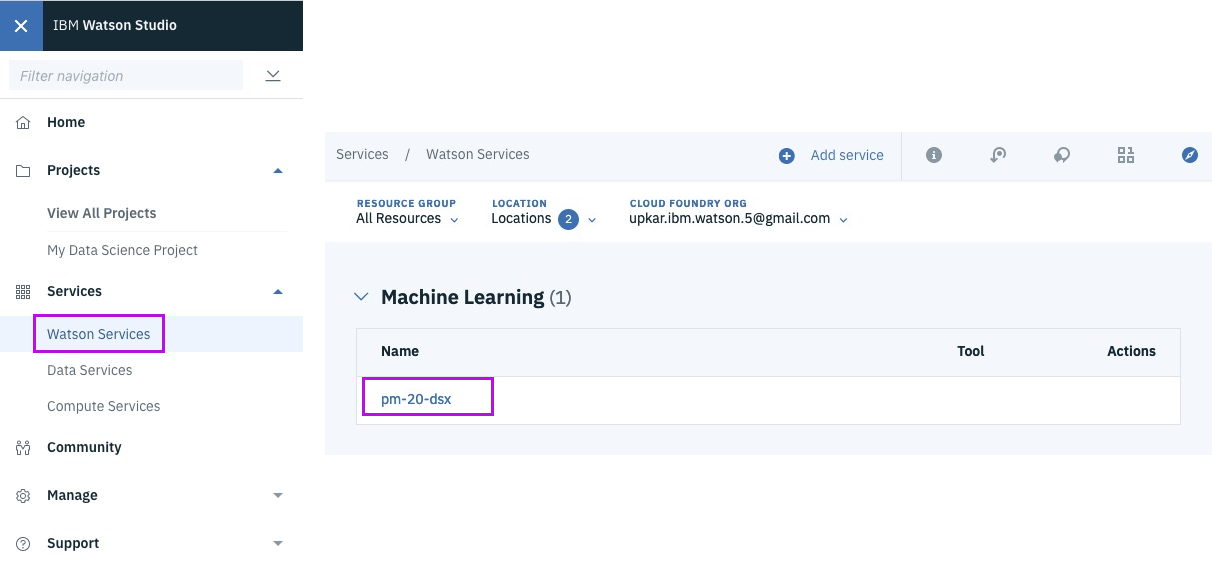
WML - get Machine Learning service credentials
@lidderupk
IBM Developer
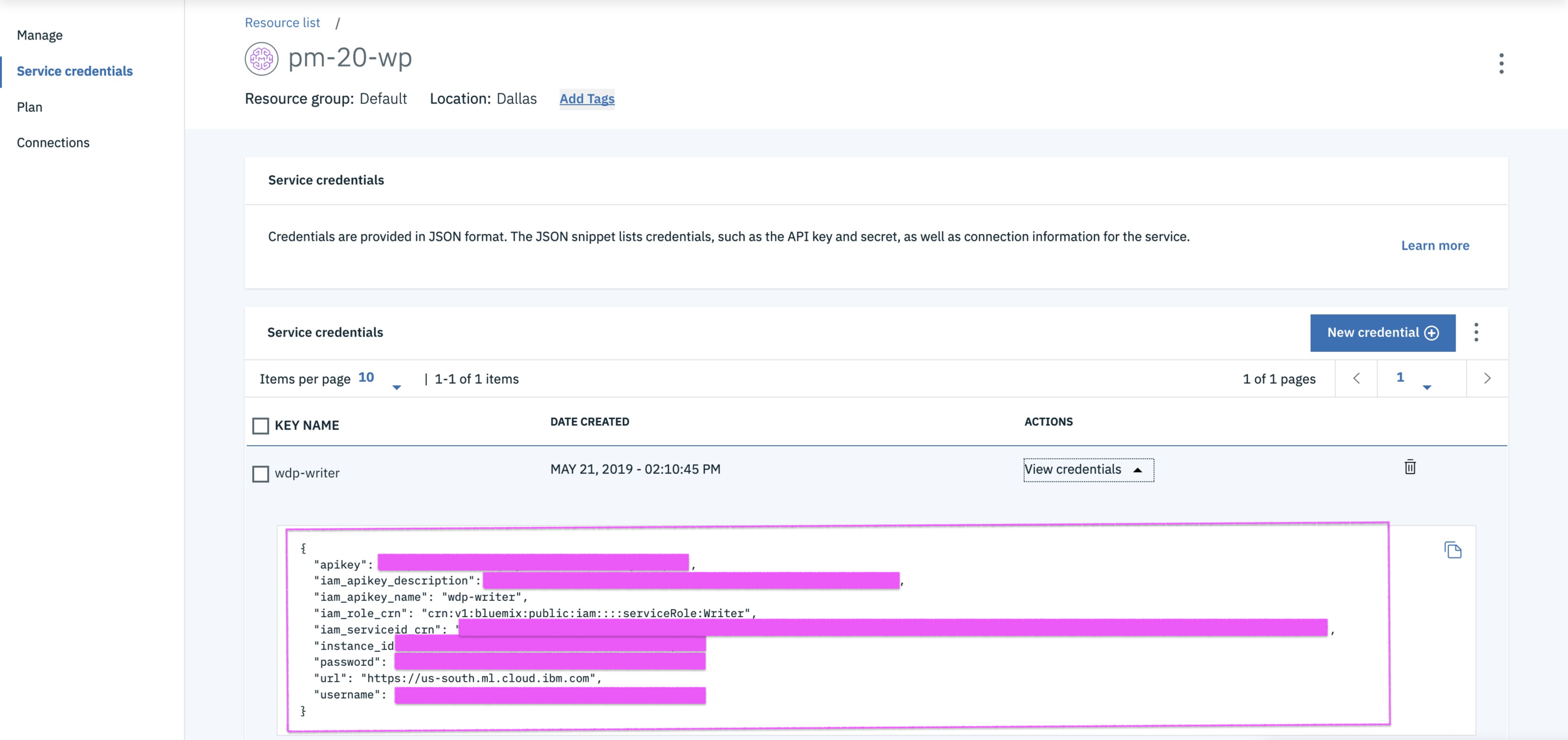
WML - save scikit-learn linear regression model
@lidderupk
IBM Developer
# we will use WML to work with IBM Machine Learning Service
from watson_machine_learning_client import WatsonMachineLearningAPIClient
# Grab your credentials from the Watson Service section in Watson Studio or IBM Cloud Dashboard
wml_credentials = {
}
# Instantiate WatsonMachineLearningAPIClient
from watson_machine_learning_client import WatsonMachineLearningAPIClient
client = WatsonMachineLearningAPIClient( wml_credentials )
# store the model
published_model = client.repository.store_model(model=LR_model,
meta_props={'name':'upkar-housing-linear-reg'},
training_data=X_train, training_target=y_train)WML - deploy scikit-learn linear regression model
@lidderupk
IBM Developer
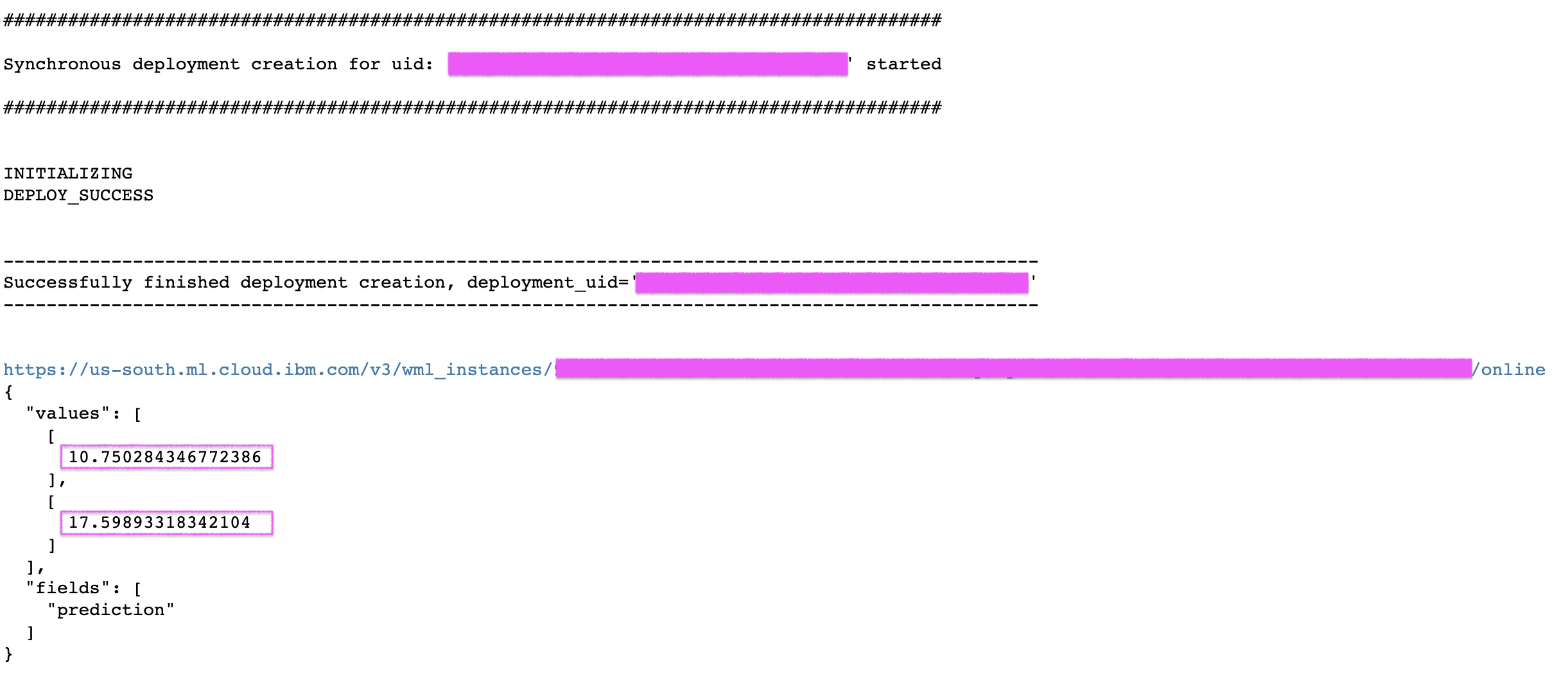
import json
# grab the model from IBM Cloud
published_model_uid = client.repository.get_model_uid(published_model)
# create a new deployment for the model
model_deployed = client.deployments.create(published_model_uid, "Deployment of scikit model")
#get the scoring endpoint
scoring_endpoint = client.deployments.get_scoring_url(model_deployed)
print(scoring_endpoint)
#use the scoring endpoint to predict house median price some test data
scoring_payload = {"values": [list(X_test[0]), list(X_test[1])]}
predictions = client.deployments.score(scoring_endpoint, scoring_payload)
print(json.dumps(predictions, indent=2))WML - deploy scikit-learn linear regression model
@lidderupk
IBM Developer
Thank you
Let's chat !

@lidderupk
IBM Developer
Upkar Lidder, IBM
@lidderupk
https://github.com/lidderupk/
ulidder@us.ibm.com
@lidderupk
IBM Developer



@lidderupk
IBM Developer
