Introduction to Apache Spark and PixieDust
Lisa Jung
IBM

Upkar Lidder
IBM
> ulidder@us.ibm.com
> @lidderupk
> upkar.dev
Prerequisites
@lidderupk
IBM Developer
1. Create IBM Cloud Account using THIS URL
3. If you already have an account, use the above URL to sign into your IBM Cloud account.
2. Check your email and activate your account. Once activated, log back into your IBM Cloud account using the link above.
http://bit.ly/pixie-sign
@lidderupk
IBM Developer
Why are we here today?
1. What is Apache Spark?
2. Why do we need it? A historical context
3. Basic architecture and components
4. Spark data structures
5. Commonly used APIs to work with DataFrames
6. Spark and PixieDust demo
@lidderupk
IBM Developer
What is Apache Spark?
Framework for Big Data processing distributed across clusters, like map-reduce. It provides high-level APIs in Java, Scala, Python and R.

- in-memory fast computations
- lazy system
- multiple language support
- real time streaming
- SQL support
- Machine Learning Support
@lidderupk
IBM Developer
Why do we need it? A historical context
Era of Big Data ...
- Volume
- Veracity
- Velocity
- Volatility

ETL tools are old school ...
- Need to know propriety tools
- Cannot work with Language of choice
Hadoop is cool, but ...
- Takes too long
- Lots of disk IO
@lidderupk
IBM Developer
Basic architecture and components
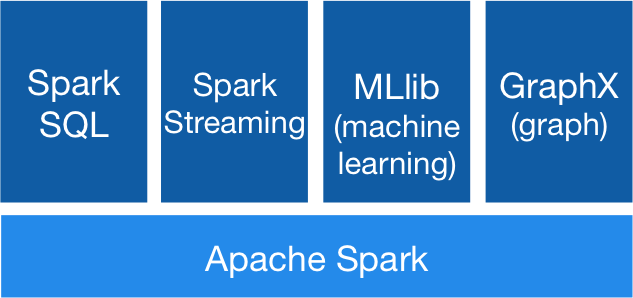
Spark SQL - Full SQL2003 support, DataFrames and Datasets
MLlib - Spark's scalable machine learning library. Supports Classification, Regression, Decision Trees, Recommendation, Clustering with feature transformation, ML pipelines, Model evaluation, hyper-parameter optimization and tuning.
Spark Streaming - brings Apache Spark's language-integrated API to stream processing, letting you write streaming jobs the same way you write batch jobs. It supports Java, Scala and Python.
Spark GraphX - API for graphs and graph-parallel computation.

@lidderupk
IBM Developer
Spark data structures
RDD - Resilient Distributed Dataset
- low level structure, compile-time type safe
- gives full control over physical data placement across the cluster
- lazily evaluated and automatically distributed
- DataFrames and Datasets compile down to RDD
DataFrames --> Dataset[Row]
- untyped - checked against built in schema at runtime
- each record is of type Row
- higher level abstraction -> logical plan -> physical plan -> optimized
Datasets
- typed - checked at compile type
- can only be used with JVM languages - Java and Scala
- offer strong type-safety
- added in Spark 1.6
@lidderupk
IBM Developer
Operations on RDD
| Transformations | Actions |
|---|---|
| select | count |
| distinct | collect |
| sum | save |
| filter | show |
| limit | more ... |
| groupBy | |
| more ... |
Transformations
Actions
- Create new dataset from an existing one.
- All transformations are lazy.
- Return a value after running a computation.
- Nothing actually happens until you call an action!
@lidderupk
IBM Developer
createDataFrame with Row
A dataframe is collection of pyspark.sql.Row
from pyspark.sql import Row
california = Row(state='California', abbr='CA')
arizona = Row(state='Arizona', abbr='AZ')
states = spark.createDataFrame([california, arizona])
@lidderupk
IBM Developer
Handle missing values
# drop(how='any', thresh=None, subset=None)
df5 = df4.na.drop()
df5.show()
# fill(value, subset=None)
df4.na.fill(50).show()
df5.na.fill(False).show()
# replace(to_replace, value=<no value>, subset=None)[source]
df4.na.replace(10, 20).show()
df4.na.replace('Alice', None).show()
df4.na.replace(['Alice', 'Bob'], ['A', 'B'], 'name').show()
@lidderupk
IBM Developer
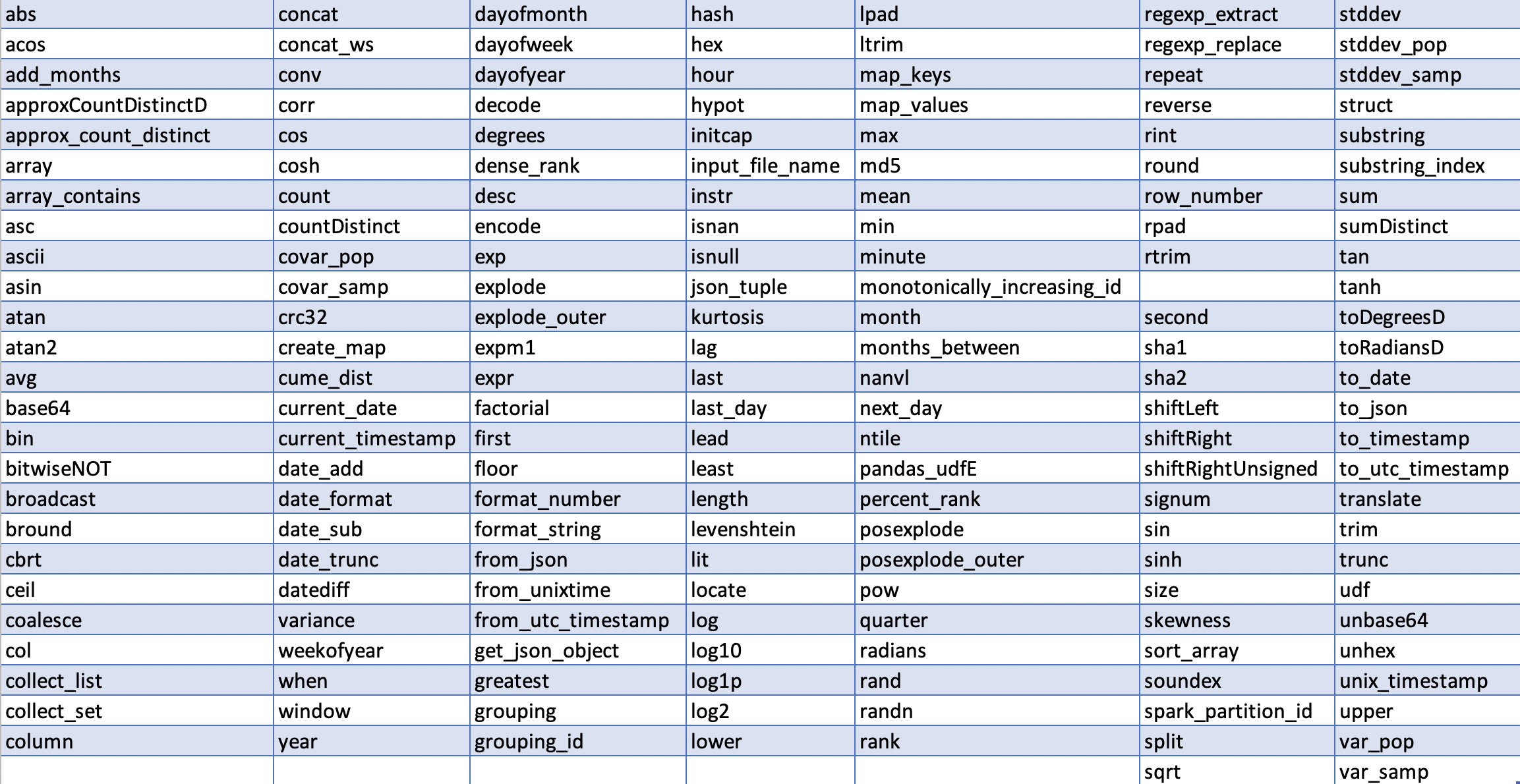
Built-in Functions for dataframes
@lidderupk
IBM Developer
withColumn, lit, alias
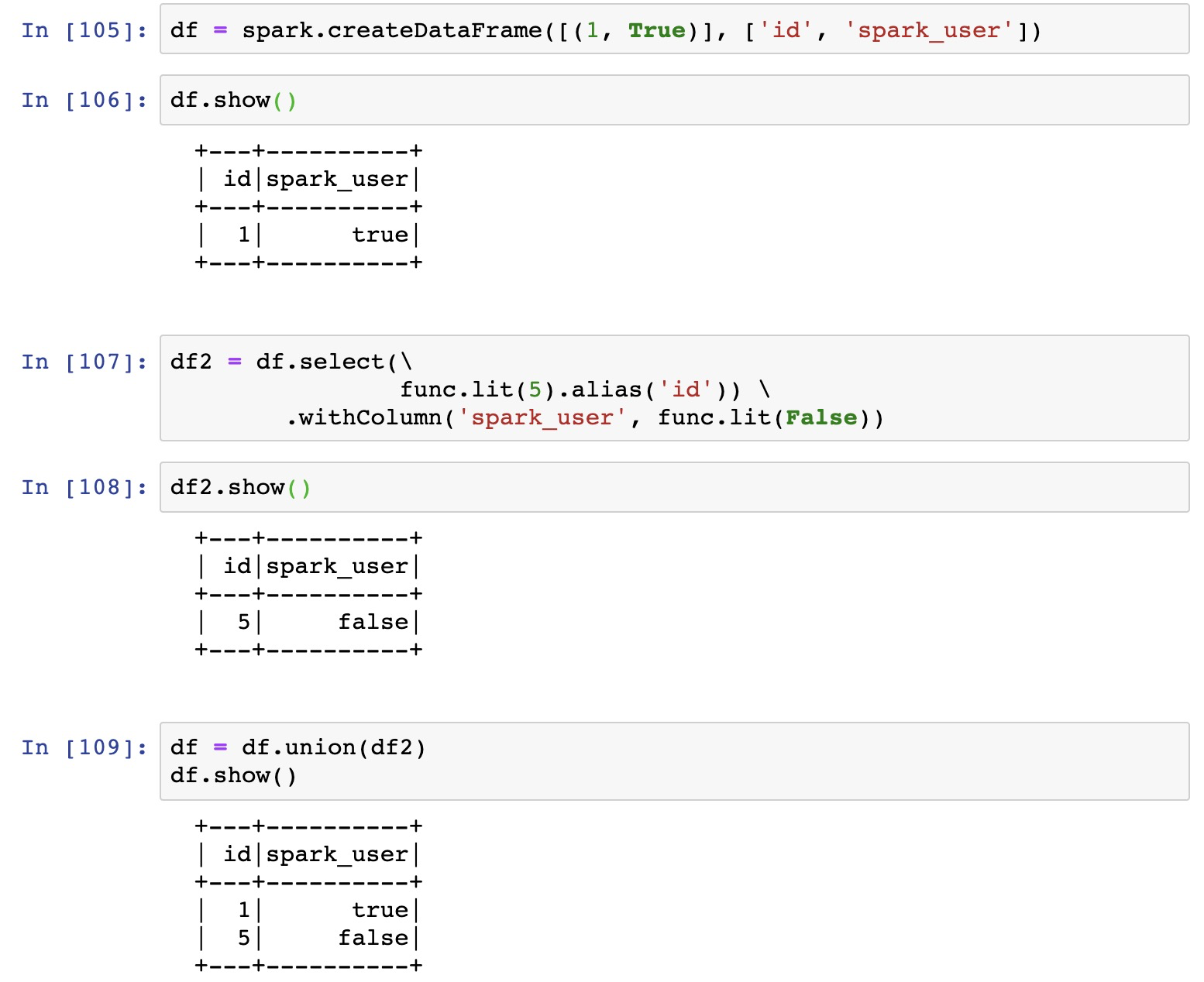
import pyspark.sql.functions as func
@lidderupk
IBM Developer
User Defined Functions 1
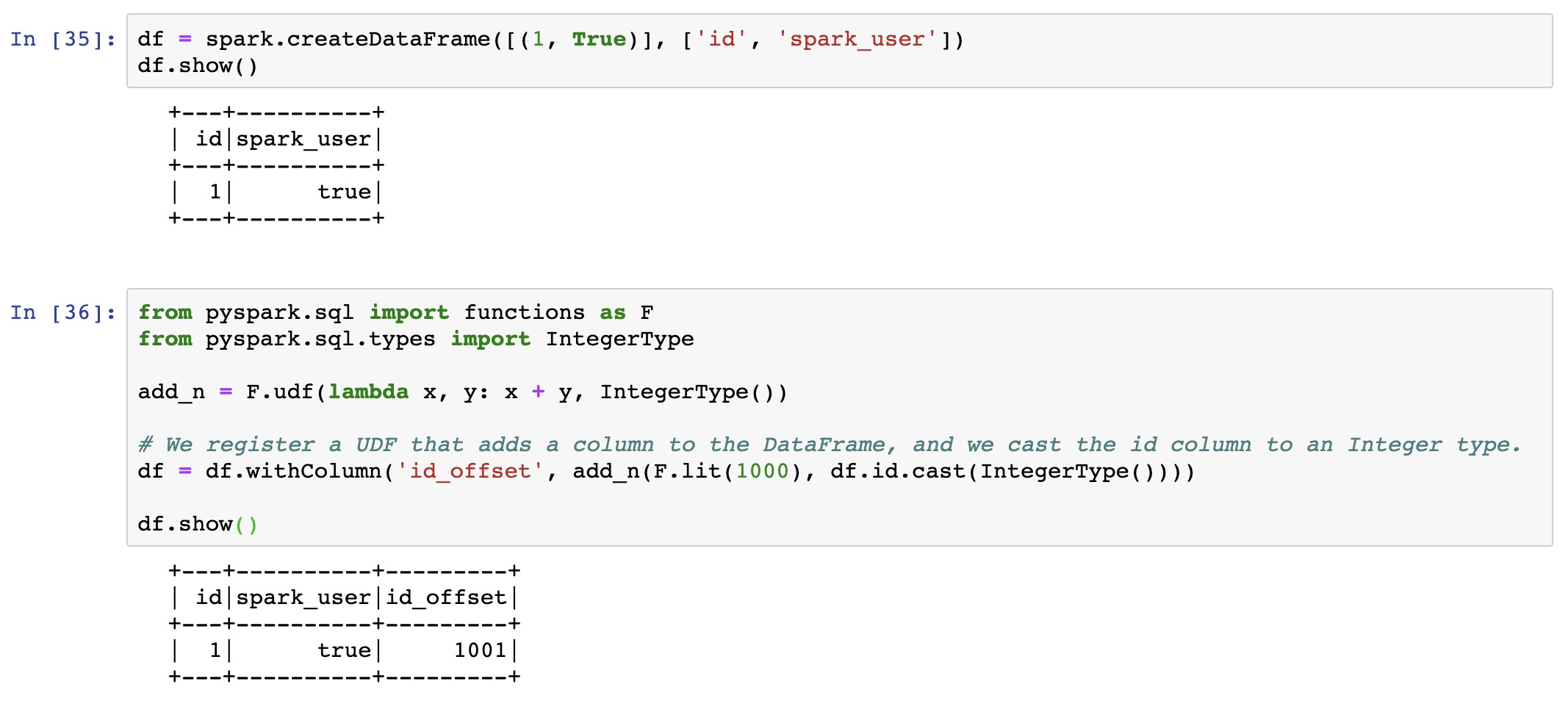
@lidderupk
IBM Developer
User Defined Functions 2
# ---------------------------------------
# Cleanse age (enforce numeric data type)
# ---------------------------------------
def fix_age(col):
"""
input: pyspark.sql.types.Column
output: the numeric value represented by col or None
"""
try:
return int(col)
except ValueError:
# age-33
match = re.match('^age\-(\d+)$', col)
if match:
try:
return int(match.group(1))
except ValueError:
return None
return None
fix_age_UDF = func.udf(lambda c: fix_age(c), types.IntegerType())
customer_df = customer_df.withColumn("AGE", fix_age_UDF(customer_df["AGE"]))
customer_df
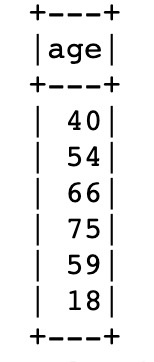
@lidderupk
IBM Developer
User Defined Functions 3
# ------------------------------
# Derive gender from salutation
# ------------------------------
def deriveGender(col):
""" input: pyspark.sql.types.Column
output: "male", "female" or "unknown"
"""
if col in ['Mr.', 'Master.']:
return 'male'
elif col in ['Mrs.', 'Miss.']:
return 'female'
else:
return 'unknown';
# register the user defined function
deriveGenderUDF = func.udf(lambda c: deriveGender(c), types.StringType())
# crate a new column by deriving GENDER from GenderCode
customer_df = customer_df.withColumn("GENDER", deriveGenderUDF(customer_df["GenderCode"]))
customer_df.cache()

@lidderupk
IBM Developer
filter
import matplotlib.pyplot as plt
import pandas as pd
%matplotlib inline
# nothing happens
condition_gen_x_y = "GENERATION = 'Gen_X' or GENERATION = 'Gen_Y'"
# nothing happens
boomers_df = customer_df.filter("GENERATION = 'Gen_X' or GENERATION = 'Gen_Y'")
# something happens now!
boomers_df.groupBy('GENERATION').count().show()
# convert to pandas dataframe from spark dataframe!
boomers_df = boomers_df.toPandas()
# eager evaluation now!
boomers_df.groupby('GENERATION')['GENERATION'].count().plot(kind='bar')
plt.show()
@lidderupk
IBM Developer
Transformation and action - Example
lines = sc.textFile("data.txt")
lineLengths = lines.map(lambda s: len(s))
totalLength = lineLengths.reduce(lambda a, b: a + b)@lidderupk
IBM Developer
What's up with PixieDust?
PixieDust is an open source helper library that works as an add-on to Jupyter notebooks to improve the user experience of working with data.
One single API called display() lets you visualize your Spark object in different ways: table, charts, maps, etc.
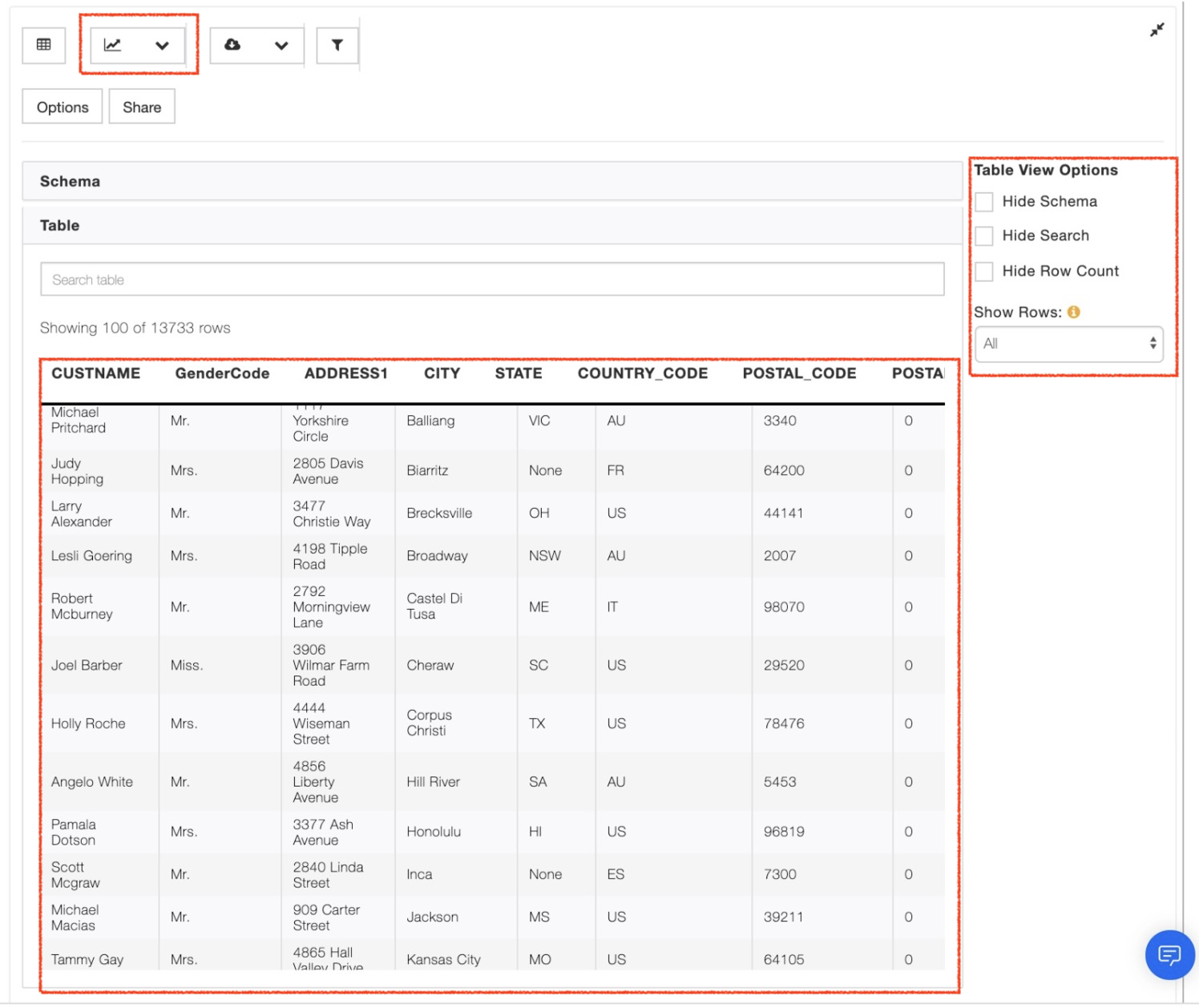
display(raw_df)@lidderupk
IBM Developer
What's up with PixieDust?
#Spark CSV Loading
from pyspark.sql import SparkSession
try:
from urllib import urlretrieve
except ImportError:
#urlretrieve package has been refactored in Python 3
from urllib.request import urlretrieve
data_url = "https://data.cityofnewyork.us/api/views/e98g-f8hy/rows.csv?accessType=DOWNLOAD"
urlretrieve (data_url, "building.csv")
spark = SparkSession.builder.getOrCreate()
building_df = spark.read\
.format('org.apache.spark.sql.execution.datasources.csv.CSVFileFormat')\
.option('header', True)\
.load("building.csv")
building_dfimport pixiedust
pixiedust.sampleData(data_url)Spark
PixieDust
Code from Data Analysis with Python, David Taieb
@lidderupk
IBM Developer
Let's look at some data!
http://bit.ly/pixie-lab
Workshop - Goals
@lidderupk
IBM Developer
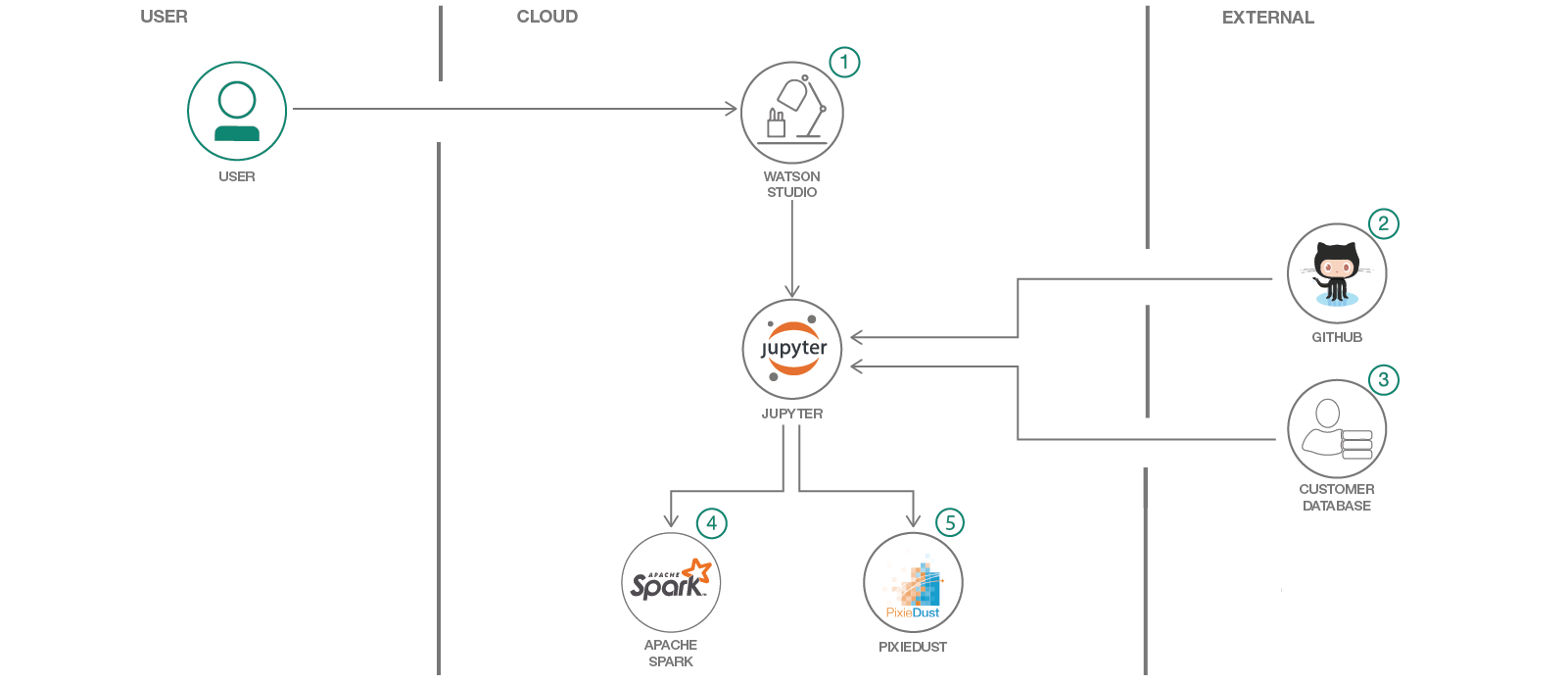
Use Apache Spark, PixieDust and Jupyter Notebooks to analyze and visualize customer purchase data from Github. Run the notebook on a cluster of distributed nodes on IBM Cloud.
Steps
@lidderupk
IBM Developer
- Sign up / Log into IBM Cloud - http://bit.ly/pixie-sign
- Create Watson Studio Service.
- Sign into Watson Studio and create a new Data Science Project. It also creates a Cloud Object Store for you.
- Add a Notebook to your project
- Import ipynb file from Github
- Explore!
Step 1 - sign up/ log into IBM Cloud
@lidderupk
IBM Developer
http://bit.ly/pixie-sign
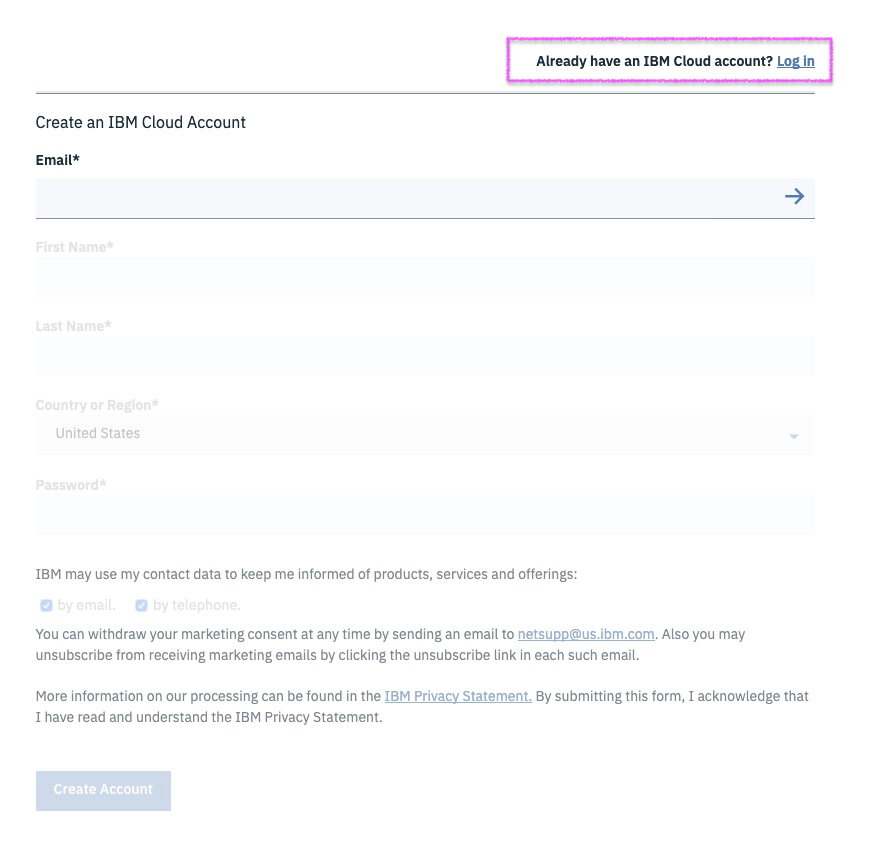
Step 2 - locate Watson Studio in Catalog
@lidderupk
IBM Developer
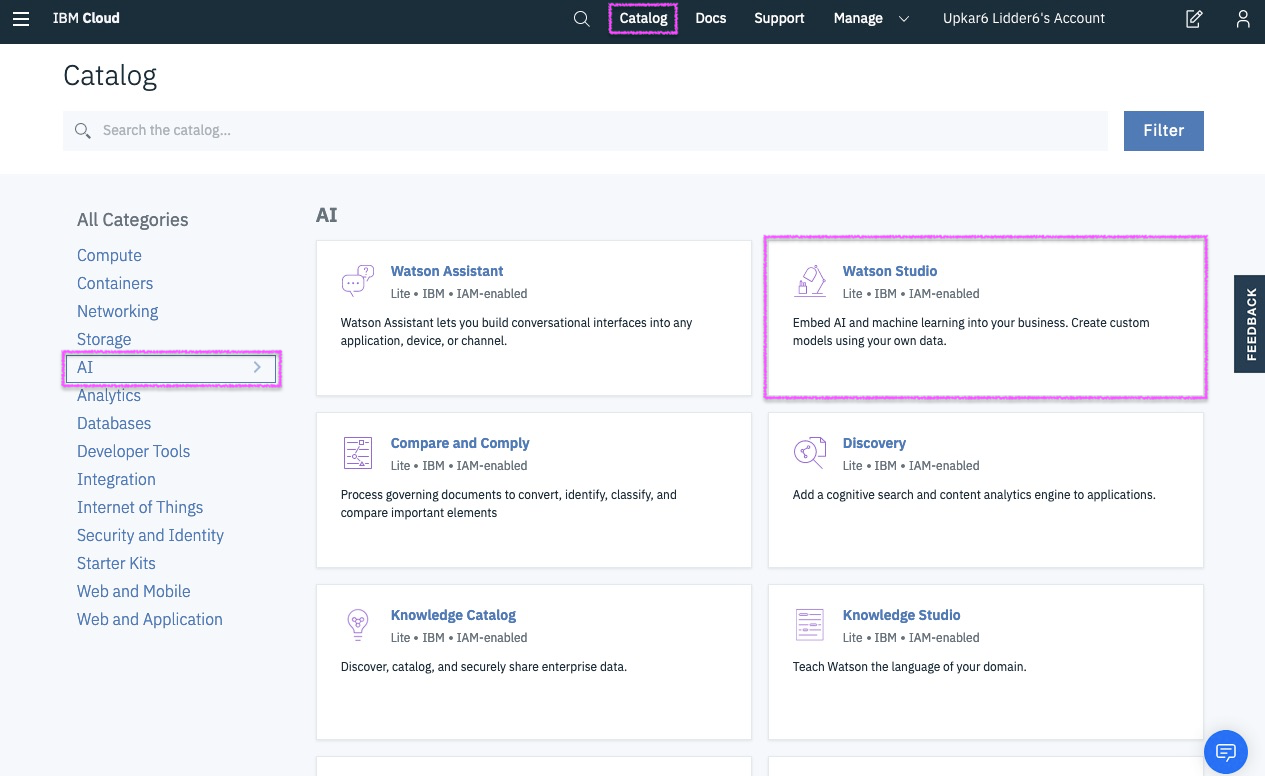
Step 3a - create Watson Studio instance
@lidderupk
IBM Developer
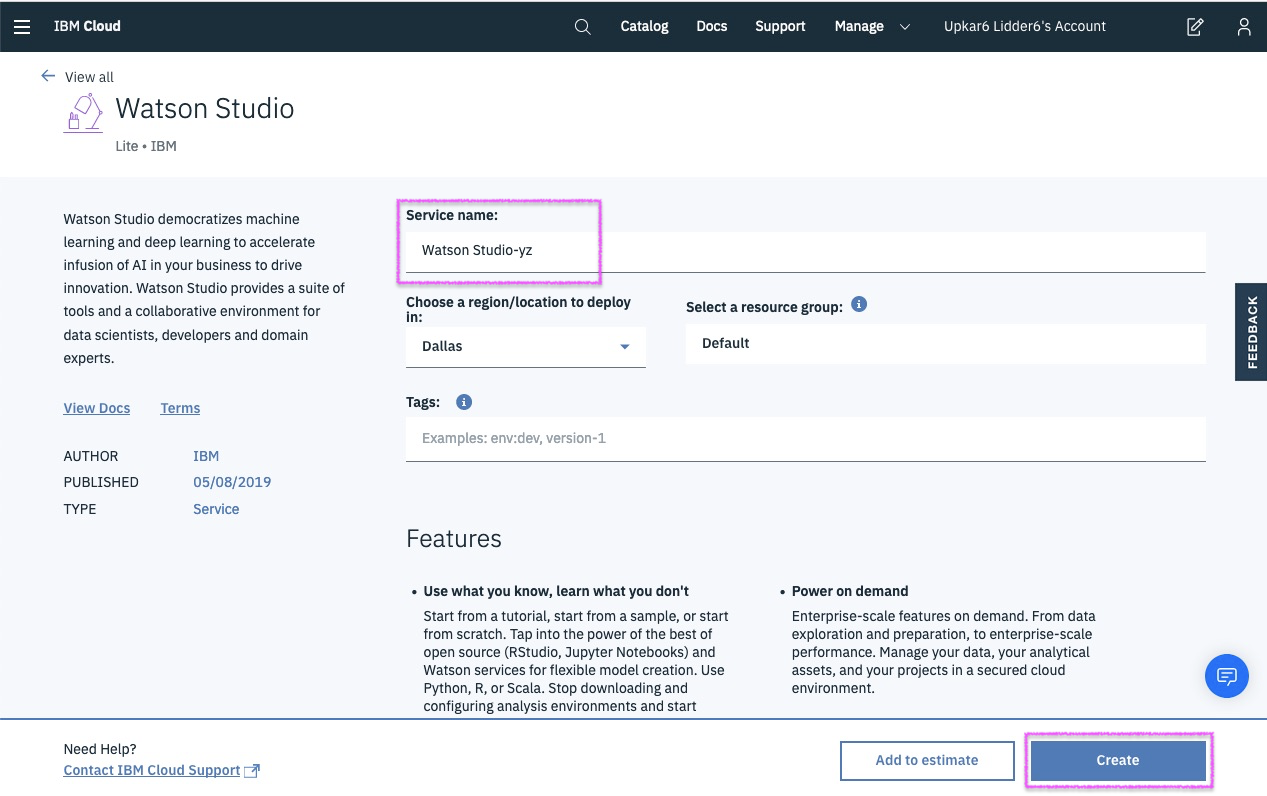
Step 3b - already have Watson Studio? Find it in Resources
@lidderupk
IBM Developer
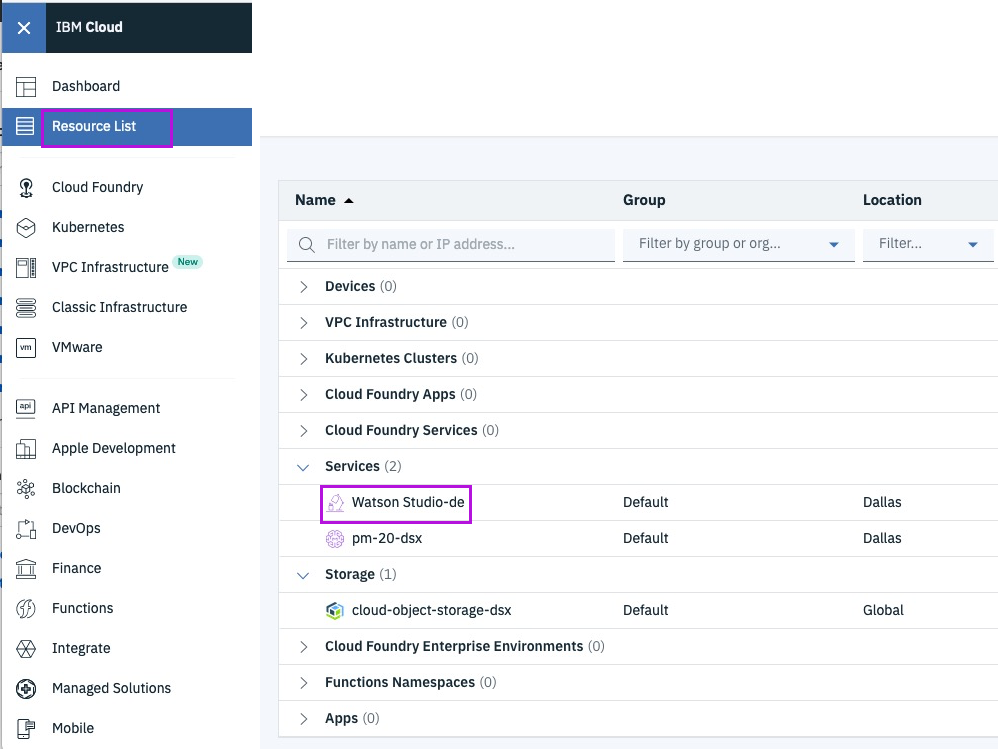
Step 4 - launch Watson Studio
@lidderupk
IBM Developer
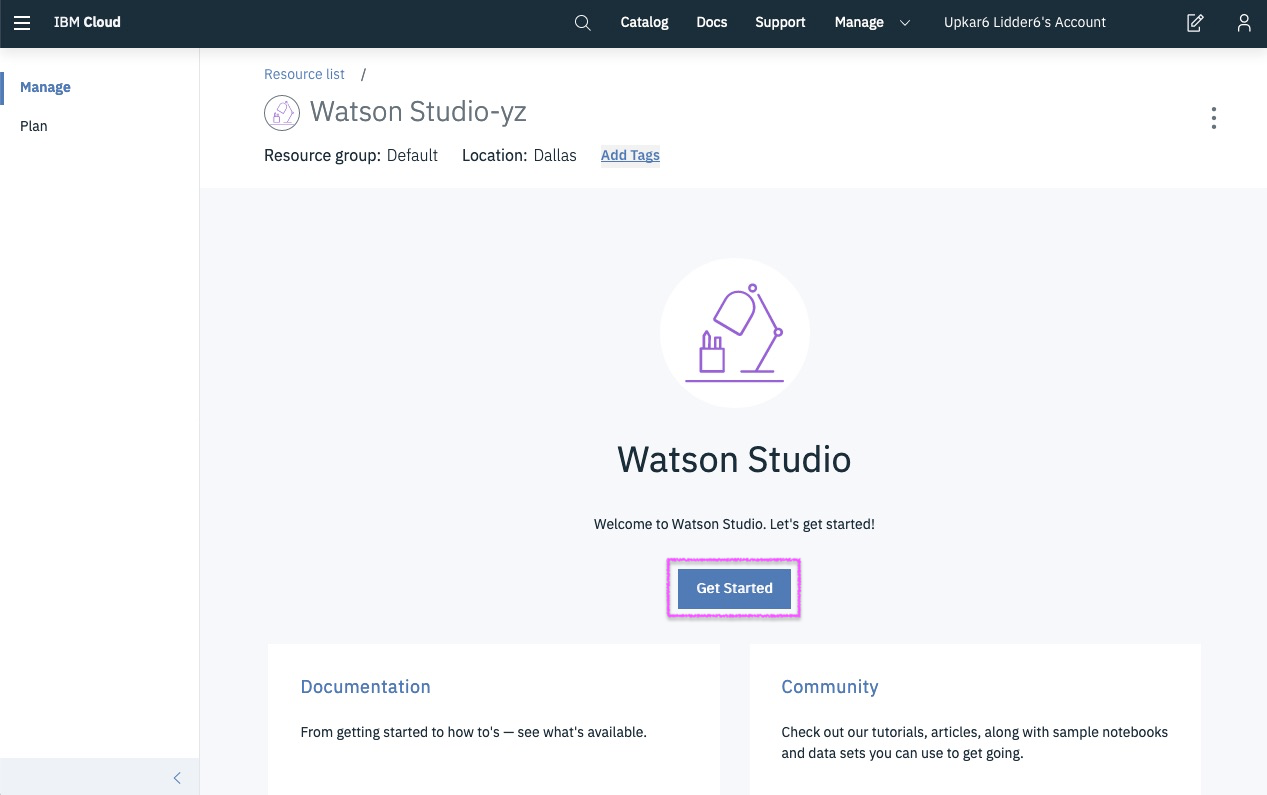
Step 5 - create a new project
@lidderupk
IBM Developer
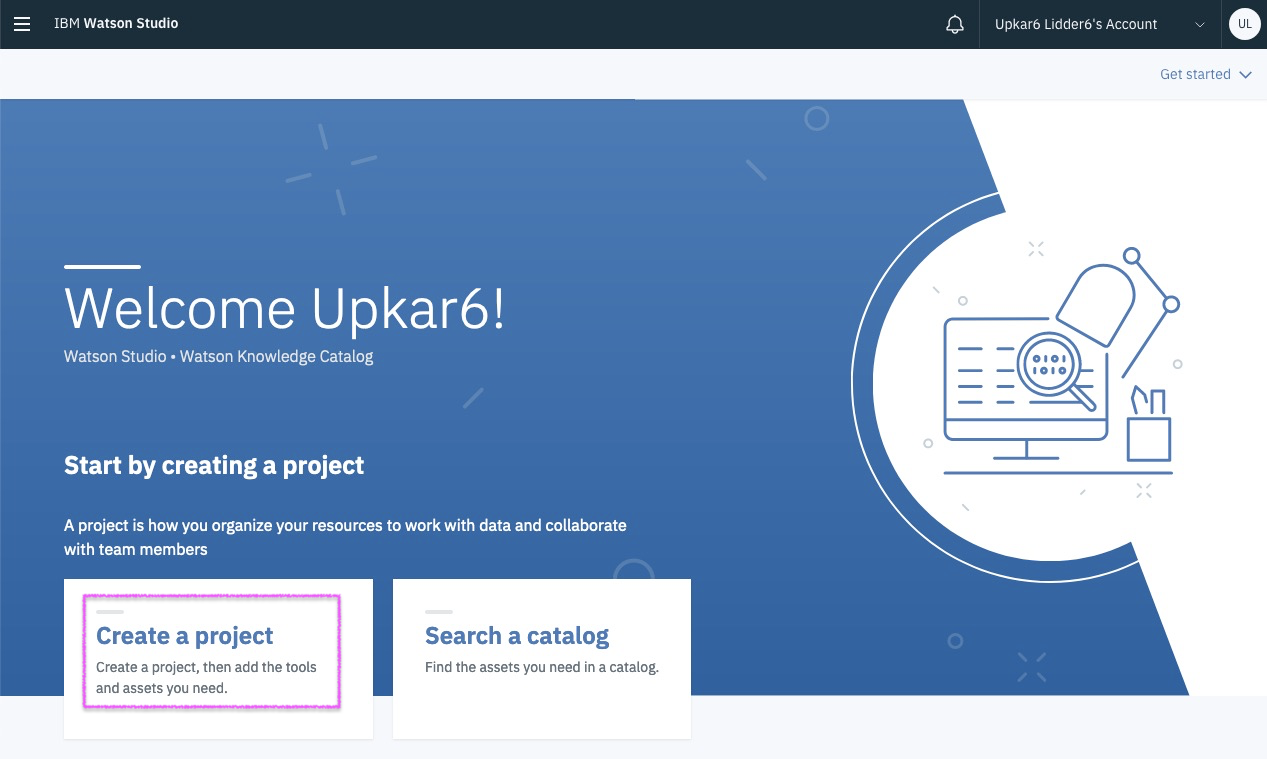
Step 6a - pick Data Science starter
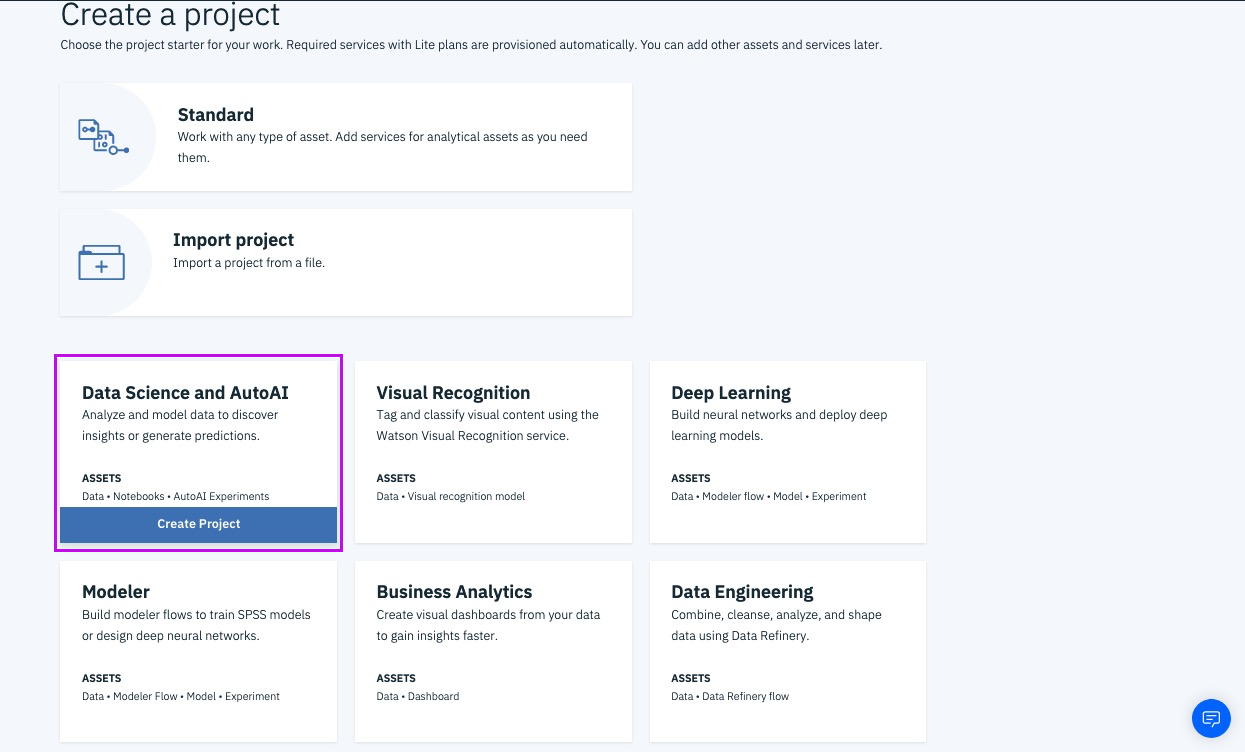
@lidderupk
IBM Developer
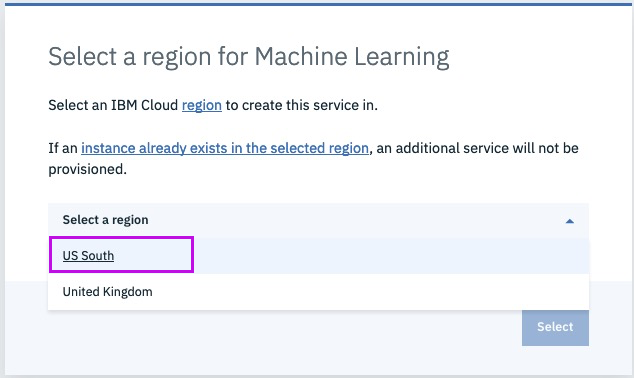
Step 6b - pick region [US South]
@lidderupk
IBM Developer
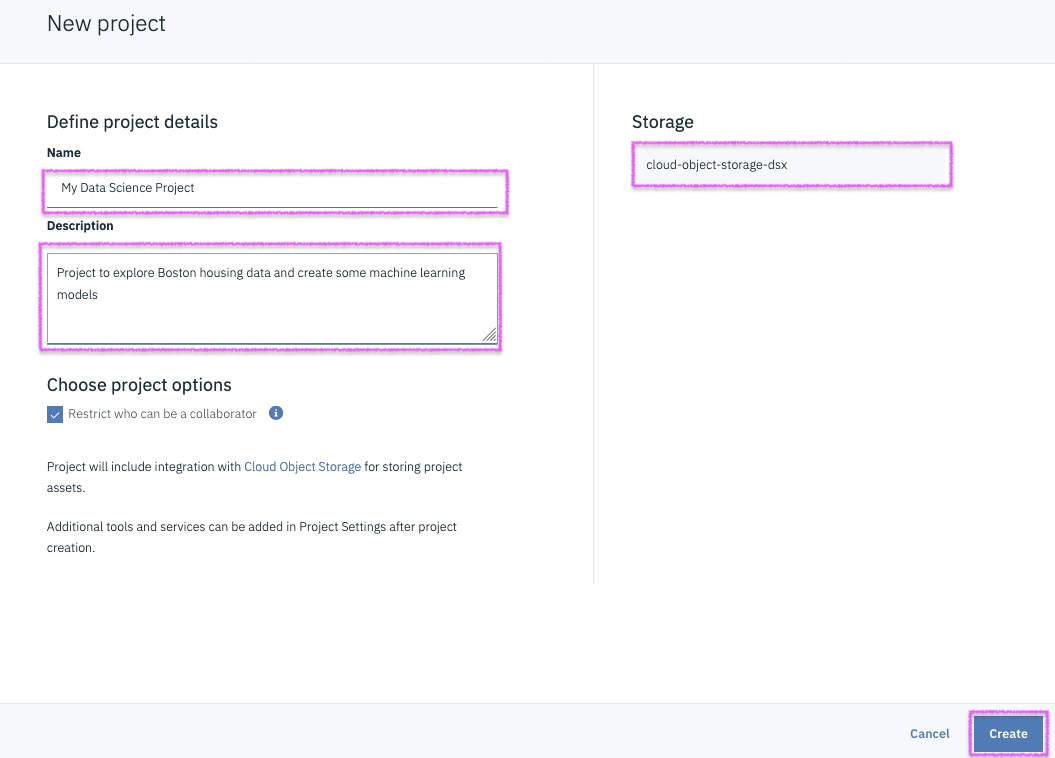
Step 7 - give the project a name and assign COS
@lidderupk
IBM Developer
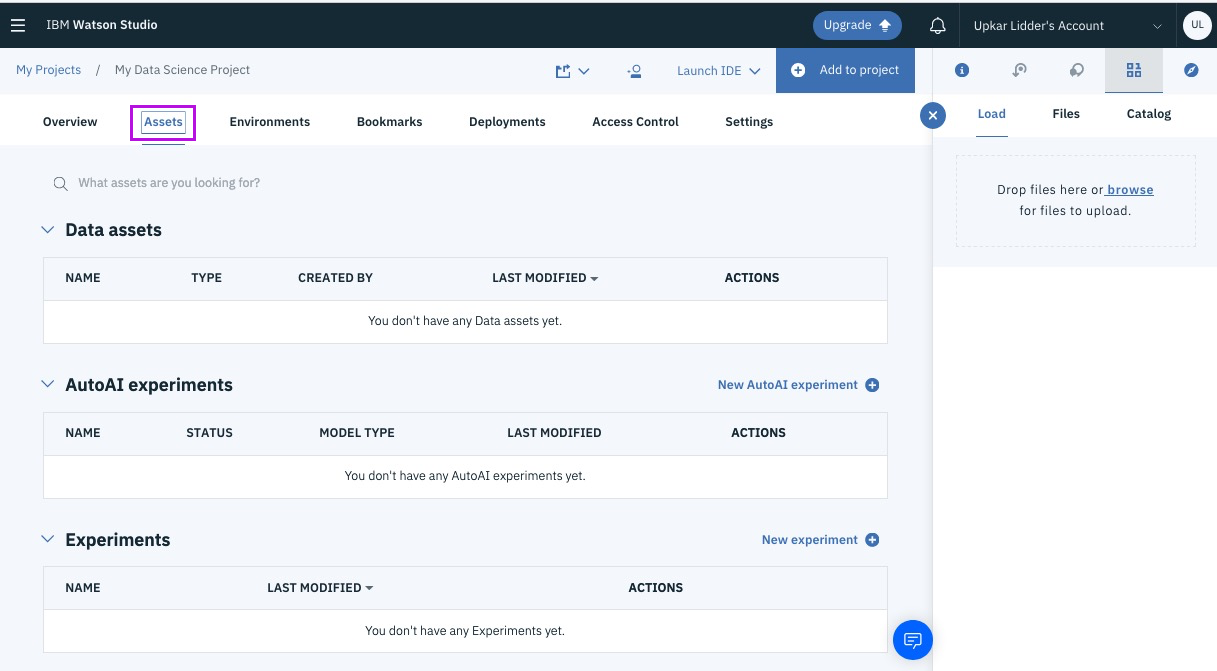
Step 8 - open asset tab, this is your goto page!
@lidderupk
IBM Developer
@lidderupk
IBM Developer
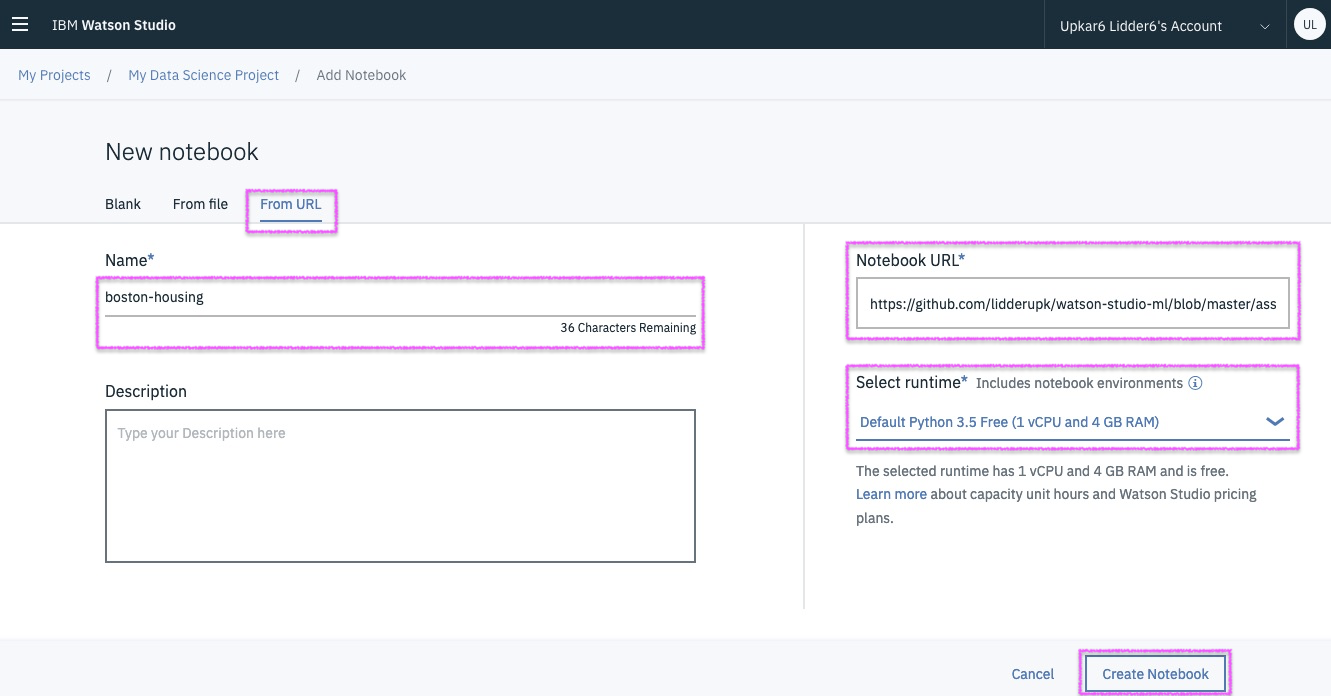
Step9 - create a new notebook from URL
Grab the FULL URL from : http://bit.ly/pixie-lab-notebook

@lidderupk
http://bit.ly/pixie-lab-notebook
https://training.databricks.com/visualapi.pdf
@lidderupk
IBM Developer
More Resources
Slides explaining transformations and actions with visuals
https://spark.apache.org/docs/2.3.3/api/python/index.html
Spark official docs
https://docs.databricks.com/spark/latest/dataframes-datasets/index.html
Databricks training
https://developer.ibm.com/patterns/category/spark/?fa=date%3ADESC&fb=
IBM Code Patterns
Thank you
Let's chat !

@lidderupk
IBM Developer
Upkar Lidder, IBM
@lidderupk
https://github.com/lidderupk/
ulidder@us.ibm.com