What is Hadoop?
Hadoop is a platform that provides both distributed storage and distributed computational capabilities of processing very large data sets on computer clusters built from commodity hardware.
As for that name, Hadoop, it’s simply the name that Doug Cutting’s son gave to his stuffed elephant. He used it since it was easy to pronounce and google.
(Doug Cutting is, of course, the co-creator of Hadoop.)
History
- originated from Nutch, an open source Web crawler
- inspired by work done by Google
- In April 2008, Hadoop broke a world record by sorting a terabyte of data in 209 seconds, running on a 910-node cluster.
- In May 2009, Yahoo! was able to use Hadoop to sort 1
terabyte in 62 seconds
The Hadoop environment is a distributed system that runs on commodity hardware.

Distributed Computation
Distributed Storage
commodity hardware
Hadoop
MapReduce / YARN
HDFS
Hadoop Environment
Hadoop Ecosystem
Hadoop core:
- HDFS (Hadoop Distributed File System)
- MapReduce (v1,v2)
- YARN (Yet Another Resource Negotiator )
+
Hadoop Common
(to support other modules)
The Hadoop technology stack includes more than a dozen components, or subprojects making it impossible to list them all.
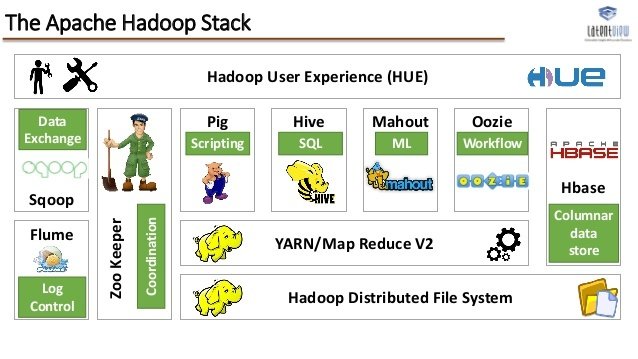
*There are many more projects not shown above
see: http://incubator.apache.org/projects/index.html#graduated
These various sub projects deal with:
- Data Access.
Interact with your data in a wide variety of ways – from batch to real-time. - Data Governance & Integration.
Quickly and easily load data, and manage according to policy. - Security. (more needs to be done here)
Address requirements of Authentication, Authorization, Accounting and Data Protection. - Operations.
Provision, manage, monitor and operate Hadoop clusters at scale.
HDFS
The Hadoop Distributed File System (HDFS) is a distributed file system designed to run on commodity hardware.
It has many similarities with existing distributed file systems. However, the differences from other distributed file systems are significant. HDFS is highly fault-tolerant and is designed to be deployed on low-cost hardware.
HDFS provides high throughput access to application data and is suitable for applications that have large data sets. HDFS relaxes a few POSIX requirements to enable streaming access to file system data.
HDFS was originally built as infrastructure for the Apache Nutch web search engine project. HDFS is now an Apache Hadoop subproject. The project URL is http://hadoop.apache.org/hdfs/.
Assumptions and Goals:
- Hardware Failure
- Streaming Data Access
- Simple Coherency Model
- Moving Computation is Cheaper than Moving Data
- Portability Across Heterogeneous Hardware and Software Platforms
Features:
- Rack Awareness (has to configured manually)
- High Reliability (through block replication)
- High Throughput (mainly because of above points)
HDFS has a master/slave architecture. Components:
-
NameNode (handles metadata) [SPOF]
- 1/cluster
- manages the file system namespace
- regulates access to files by clients
- executes file system namespace operations
- determines the mapping of blocks to DataNodes -
DataNode (handles data "blocks")
- 1/node
- manage storage attached to the nodes
- serve read and write requests from the file system’s clients
- perform block creation, deletion, and replication upon instruction from the NameNode. - SecondaryNameNode (does checkpointing)
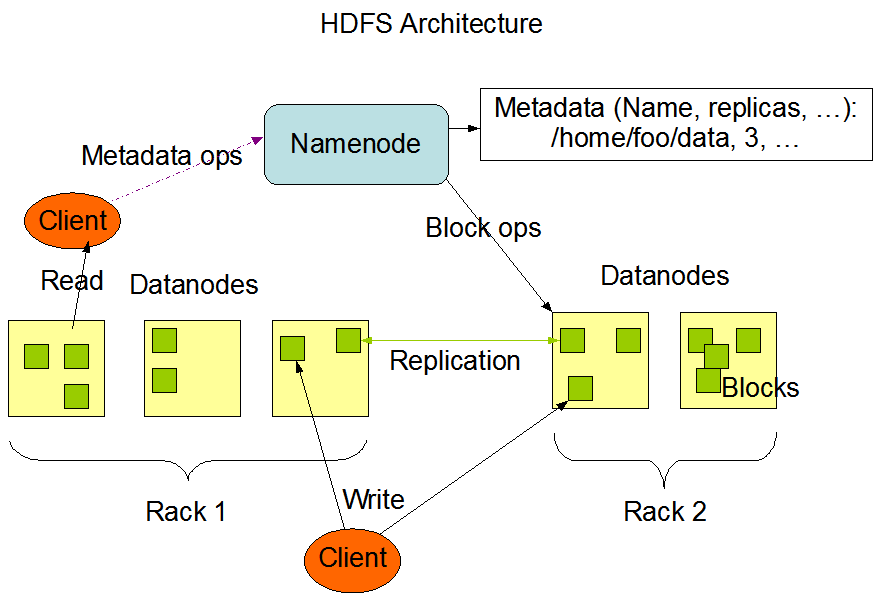
The File System Namespace
HDFS supports a traditional hierarchical file organization. HDFS does not yet implement user quotas. HDFS does not support hard links or soft links. However, the HDFS architecture does not preclude implementing these features.
The NameNode maintains the file system namespace. Any change to the file system namespace or its properties is recorded by the NameNode. An application can specify the number of replicas of a file that should be maintained by HDFS. The number of copies of a file is called the replication factor of that file. This information is stored by the NameNode.
Data Replication
HDFS stores each file as a sequence of blocks; all blocks in a file except the last block are the same size. The blocks of a file are replicated for fault tolerance. The block size and replication factor are configurable per file. An application can specify the number of replicas of a file. The replication factor can be specified at file creation time and can be changed later. Files in HDFS are write-once and have strictly one writer at any time.
The NameNode makes all decisions regarding replication of blocks. It periodically receives a Heartbeat and a Blockreport from each of the DataNodes in the cluster. Receipt of a Heartbeat implies that the DataNode is functioning properly. A Blockreport contains a list of all blocks on a DataNode.
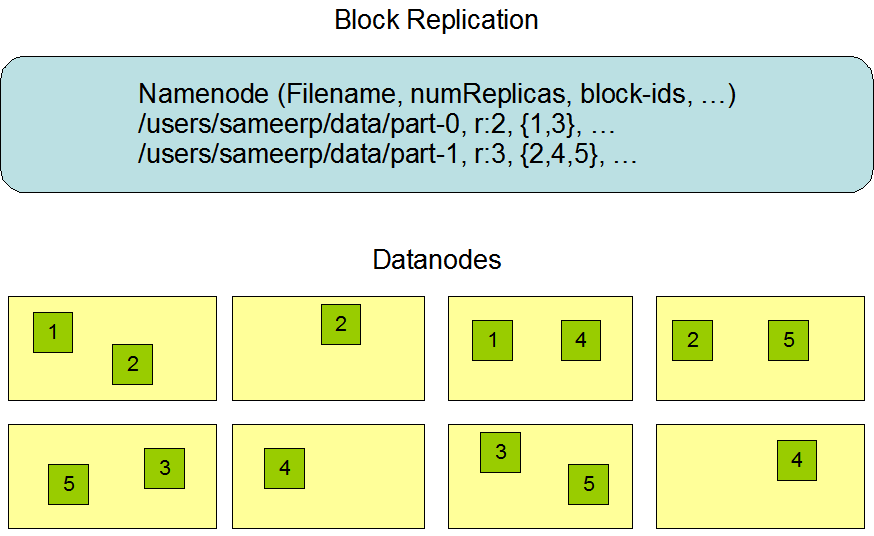
Replica Placement
Optimizing replica placement distinguishes HDFS from most other distributed file systems.
A simple but non-optimal policy is to place replicas on unique racks. This prevents losing data when an entire rack fails and allows use of bandwidth from multiple racks when reading data. This policy evenly distributes replicas in the cluster which makes it easy to balance load on component failure. However, this policy increases the cost of writes because a write needs to transfer blocks to multiple racks. For the common case, when the replication factor is three, HDFS’s placement policy is to put one replica on one node in the local rack, another on a node in a different (remote) rack, and the last on a different node in the same remote rack.
This policy cuts the inter-rack write traffic which generally improves write performance. The chance of rack failure is far less than that of node failure; this policy does not impact data reliability and availability guarantees. However, it does reduce the aggregate network bandwidth used when reading data since a block is placed in only two unique racks rather than three. With this policy, the replicas of a file do not evenly distribute across the racks.
One third of replicas are on one node, two thirds of replicas are on one rack, and the other third are evenly distributed across the remaining racks. This policy improves write performance without compromising data reliability or read performance.
Replica Selection
To minimize global bandwidth consumption and read latency, HDFS tries to satisfy a read request from a replica that is closest to the reader.
If there exists a replica on the same rack as the reader node, then that replica is preferred to satisfy the read request.
If angg/ HDFS cluster spans multiple data centers, then a replica that is resident in the local data center is preferred over any remote replica.
Safemode
On startup, the NameNode enters a special state called Safemode and replication of data blocks does not occur when the NameNode is in the Safemode state.
The NameNode receives Heartbeat and Blockreport messages from the DataNodes. A Blockreport contains the list of data blocks that a DataNode is hosting.
Each block has a specified minimum number of replicas. A block is considered safely replicated when the minimum number of replicas of that data block has checked in with the NameNode.
After a configurable percentage of safely replicated data blocks checks in with the NameNode (plus an additional 30 seconds), the NameNode exits the Safemode state.
It then determines the list of data blocks (if any) that still have fewer than the specified number of replicas. The NameNode then replicates these blocks to other DataNodes.
Other topics in HDFS
- The Persistence of File System Metadata
- The Communication Protocols
-
Robustness
- Data Disk Failure, Heartbeats and Re-Replication
- Cluster Rebalancing
- Data Integrity
- Metadata Disk Failure
- Snapshots -
Data Organization
- Data Blocks
- Staging
- Replication Pipelining - Accessibility (FS Shell, DFSAdmin, Browser Interface)
- Space Reclamation
- File Deletes and Undeletes
- Decrease Replication Factor
MapReduce (the programming model)
MapReduce is a programming model and an associated implementation for processing and generating large data sets with a parallel, distributed algorithm on a cluster.
A MapReduce program is composed of a Map() procedure (method) that performs filtering and sorting (such as sorting students by first name into queues, one queue for each name) and a Reduce() method that performs a summary operation (such as counting the number of students in each queue, yielding name frequencies). The "MapReduce System" (also called "infrastructure" or "framework") orchestrates the processing by marshalling the distributed servers, running the various tasks in parallel, managing all communications and data transfers between the various parts of the system, and providing for redundancy and fault tolerance.
MapReduce libraries have been written in many programming languages, with different levels of optimization.
function map(String name, String document):
// name: document name
// document: document contents
for each word w in document:
emit (w, 1)
function reduce(String word, Iterator partialCounts):
// word: a word
// partialCounts: a list of aggregated partial counts
sum = 0
for each pc in partialCounts:
sum += pc
emit (word, sum)The prototypical MapReduce example counts the appearance of each word in a set of documents:
Hadoop MapReduce
Hadoop MapReduce is a software framework for easily writing applications which process vast amounts of data (multi-terabyte data-sets) in-parallel on large clusters (thousands of nodes) of commodity hardware in a reliable, fault-tolerant manner.
A MapReduce job usually splits the input data-set into independent chunks which are processed by the map tasks in a completely parallel manner. The framework sorts the outputs of the maps, which are then input to the reduce tasks. Typically both the input and the output of the job are stored in a file-system. The framework takes care of scheduling tasks, monitoring them and re-executes the failed tasks.
Typically the compute nodes and the storage nodes are the same, that is, the MapReduce framework and the Hadoop Distributed File System (see HDFS Architecture Guide) are running on the same set of nodes. This configuration allows the framework to effectively schedule tasks on the nodes where data is already present, resulting in very high aggregate bandwidth across the cluster.
The MapReduce framework consists of a single master JobTracker and one slave TaskTracker per cluster-node. The master is responsible for scheduling the jobs' component tasks on the slaves, monitoring them and re-executing the failed tasks. The slaves execute the tasks as directed by the master.
Minimally, applications specify the input/output locations and supply map and reduce functions via implementations of appropriate interfaces and/or abstract-classes. These, and other job parameters, comprise the job configuration. The Hadoop job client then submits the job (jar/executable etc.) and configuration to the JobTracker which then assumes the responsibility of distributing the software/configuration to the slaves, scheduling tasks and monitoring them, providing status and diagnostic information to the job-client.
Although the Hadoop framework is implemented in Java, MapReduce applications need not be written in Java.
Inputs and Outputs
The MapReduce framework operates exclusively on <key, value> pairs, that is, the framework views the input to the job as a set of <key, value> pairs and produces a set of <key, value> pairs as the output of the job, conceivably of different types.
Input and Output types of a MapReduce job:
(input) <k1, v1> -> map -> <k2, v2> -> combine -> <k2, v2> -> reduce -> <k3, v3> (output)
YARN (Apache Hadoop NextGen MapReduce)
MapReduce has undergone a complete overhaul in hadoop-0.23 and we now have, what we call, MapReduce 2.0 (MRv2) or YARN.
The fundamental idea of MRv2 is to split up the two major functionalities of the JobTracker, resource management and job scheduling/monitoring, into separate daemons.
The idea is to have a global ResourceManager (RM) and per-application ApplicationMaster (AM). An application is either a single job in the classical sense of Map-Reduce jobs or a DAG of jobs.
The ResourceManager and per-node slave, the NodeManager (NM), form the data-computation framework. The ResourceManager is the ultimate authority that arbitrates resources among all the applications in the system.
The per-application ApplicationMaster is, in effect, a framework specific library and is tasked with negotiating resources from the ResourceManager and working with the NodeManager(s) to execute and monitor the tasks.
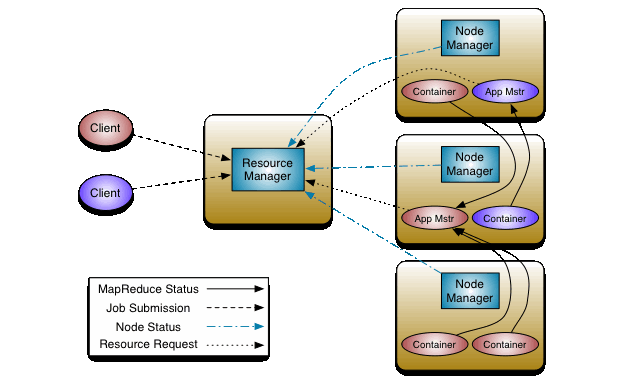
Componets
-
ResourceManager (has 2 subcomponents)
- Scheduler
- responsible for allocating resources to the various running applications
- scheduling function based the resource requirements (memory) of the applications
- plugin types: CapacityScheduler, FairScheduler, etc - ApplicationsManager
- responsible for accepting job-submissions, negotiating the first container for executing the application specific ApplicationMaster
- provides the service for restarting the ApplicationMaster container on failure
- Scheduler
2. NodeManager
- 1/node framework agent
- responsible for containers, monitoring their resource usage (cpu, memory, disk, network)
- reporting the same to the ResourceManager/ Scheduler.
3. ApplicationMaster
- responsibility of negotiating appropriate resource containers from the Scheduler
- tracking resource containers status and monitoring for progress
MRv2 maintains API compatibility with previous stable release (hadoop-1.x). This means that all Map-Reduce jobs should still run unchanged on top of MRv2 with just a recompile.
Recommended Reading:
- Hadoop: The Definitive Guide, 4th Edition by Tom White
- Hadoop in Action by Chuck Lam
References:
- https://hadoop.apache.org/docs/stable/index.html
- https://en.wikipedia.org/wiki/MapReduce