CNNs @ 3IT
Victor Schmidt & Simon Verret
Mila
3IT - Université de Sherbrooke
14 Novembre 2019
Hier
MLP
Loss
Backprop
Aujourd'hui
Convolutions
Réseaux convolutionnels
GANs
Motivation



Classification
Semantic Segmentation
Detection
Instance Segmentation
Image Generation
Image to Image Translation



How to deal with Images?
Filters




Stride = 2
Padding = 1
Convolutional layers
Some more convolutions
Padding = same

Dilated
Transposed
Small translations: pooling

In practice


Convolutional
Neural
Networks
Multi-channel convolutions

Normalizing the inputs

A first network: LeNet

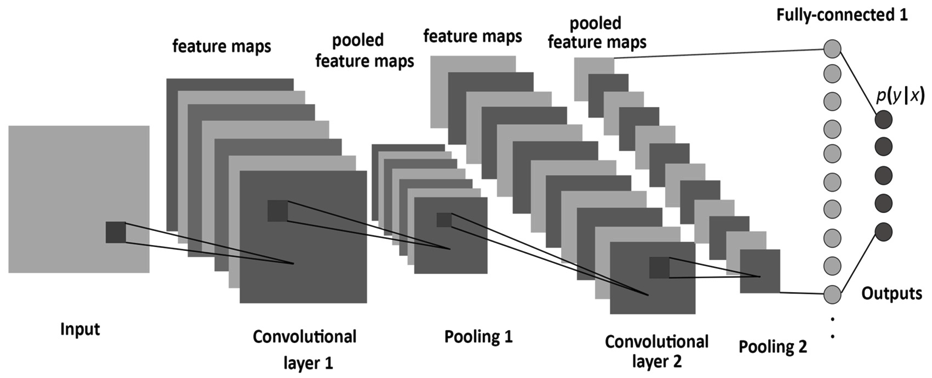
LeCun, 1998
Stabilising training: Batch Norm

Allows the training of deeper networks
Less sensitive to initialization
Larger learning rates can be used
Faster and more stable convergence
Ioffe, 2015
Updated LeNet

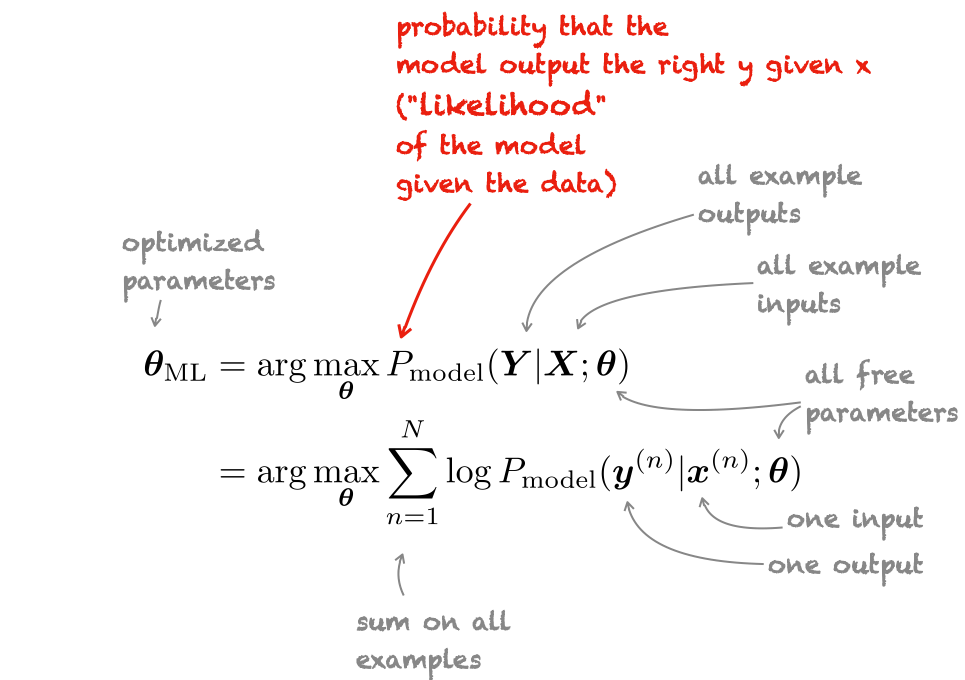
Everything's differentiable!
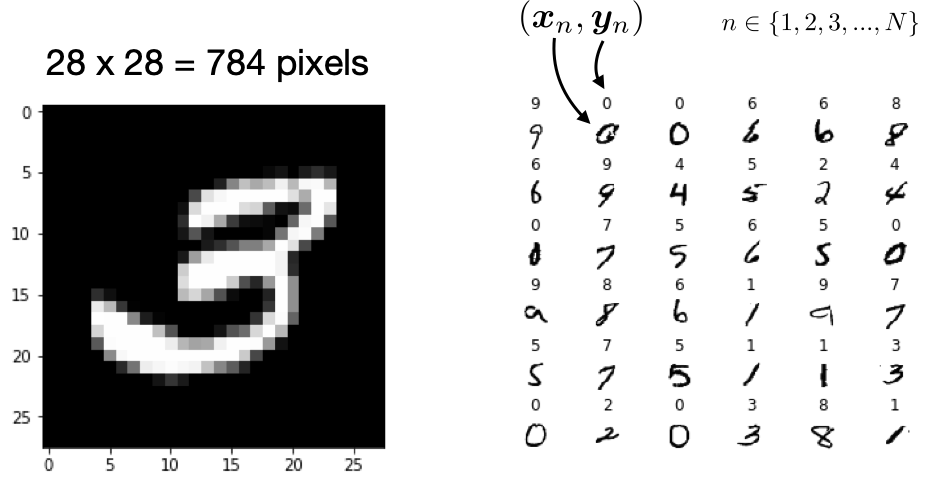
Some more classification
ImageNet

1000 classes
~10 000 images per classes
1.4M in total
Top-1 ou Top-5 accuracy
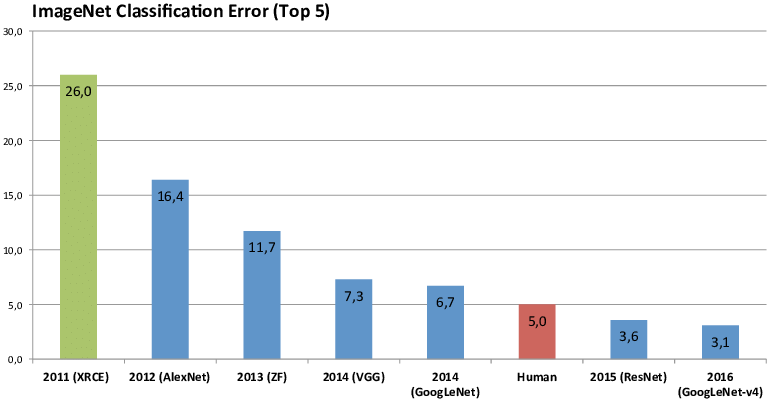
AlexNet

First deep networks to win "ImageNet competition"
Krizhevsky, 2012
VGG

Even deeper, more regular kernels (3x3)
Simonyan, 2014
GoogLeNet

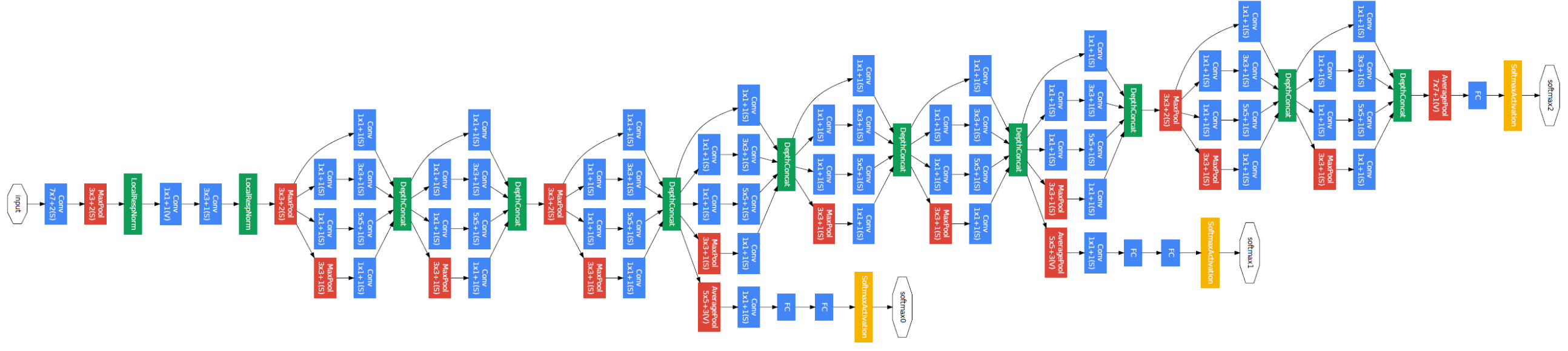
"We need to go deeper"
Szegedy, 2014
Depth is not everything

Or is it? : ResNet



He, 2015
SOTA

Xie, 11 Nov 2019
Transfer Learning
Strategies

When?


Generative Adversarial Networks
Models
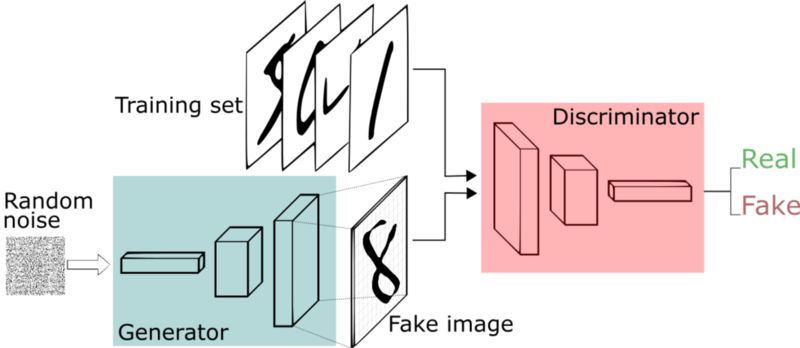
Value function

Goodfellow, 2014
Conditioning

Mirza, 2014
Unsupervised Image to Image Translation

Zhu, 2017

Merci!
