Procurando por
Tamanhos de Passo por Coordenada Ótimos com
Victor Sanches Portella
Abril 2025
ime.usp.br/~victorsp
junto de Frederik Kunstner, Nick Harvey, e Mark Schmidt
Multidimensional Backtracking



Unicamp,


Who am I?
Postdoc at USP
ML Theory
Optimization
Randomized Algs
Optimization



My interests according to a student:
"Crazy Algorithms"
Gradient Descent and Line Search
Why first-order optimization?
Training/Fitting a ML model is often cast a (uncontrained) optimization problem
Usually in ML, models tend to be BIG
\(d\) is BIG
First-order (i.e., gradient based) methods fit the bill
(stochastic even more so)
\(O(d)\) time and space per iteration is preferable
Convex Optimization Setting
\(f\) is convex
Not the case with Neural Networks
Still quite useful in theory and practice
More conditions on \(f\) for rates of convergence
\(L\)-smooth
\(\mu\)-strongly convex



"Easy to optimize"
Gradient Descent
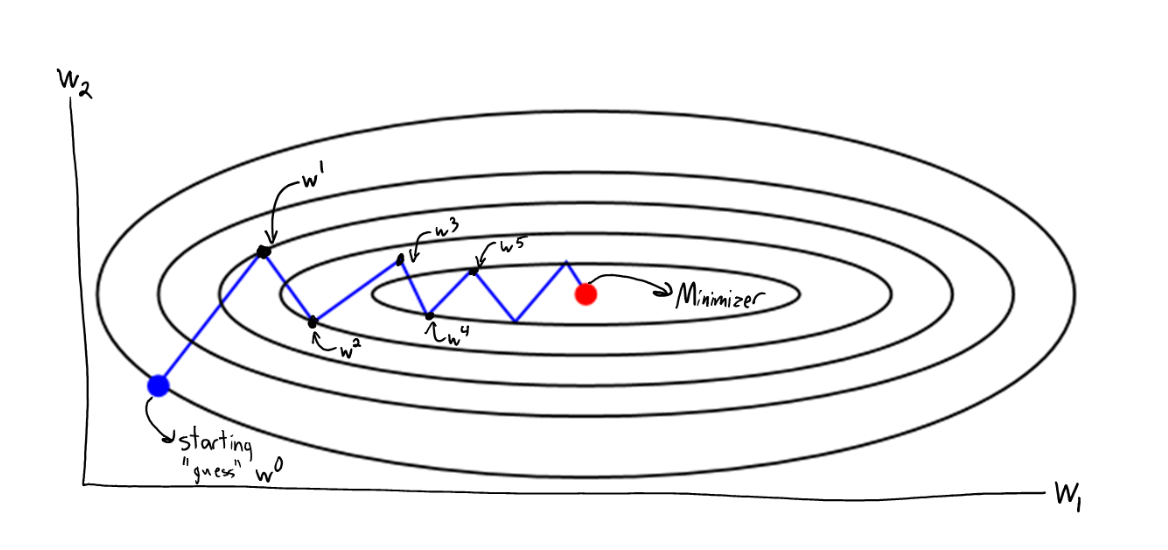
Which step-size \(\alpha\) should we pick?
Condition number
\(\kappa\) Big \(\implies\) hard function
What Step-Size to Pick?
If we know \(L\), picking \(1/L\) always works
and is optimal
What if we do not know \(L\)?
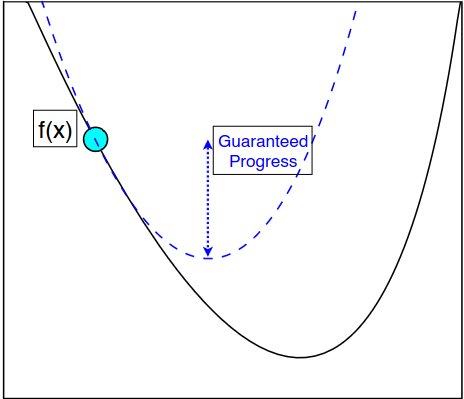
"Descent Lemma"
Idea: Pick \(\eta\) big and see if the "descent condition" holds
(Locally \(1/\eta\)-smooth)
worst-case
Backtracking Line Search
Line-search: test if step-size \(\alpha_{\max}/2\) makes enough progress:
Armijo condition
If this fails, cut out everything bigger than \(\alpha_{\max}/2\)
Backtracking Line-Search
Backtracking Line-Search
Start with \(\alpha_{\max} > 2 L\)
\(\alpha \gets \alpha_{\max}/2\)
If
\(t \gets t+1\)
Else
While \(t \leq T\)
Halve candidate space
Guarantee: step-size will be at least \(\tfrac{1}{2} \cdot \tfrac{1}{L}\)
Makes enough progress?
Beyond Line-Search?
Converges in 1 step
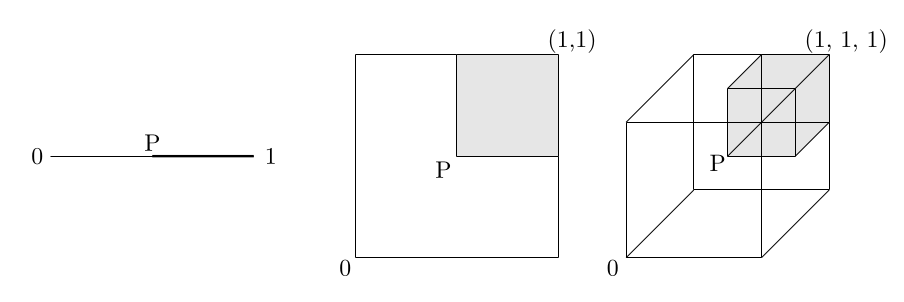
\(P\)
Can we find a good \(P\) automatically?
"Adapt to \(f\)"
Preconditioer \(P\)
"Adaptive" Optimization Methods

Second-order Methods
Newton's method
is usually a great preconditioner
Superlinear convergence
...when \(\lVert x_t - x_*\rVert\) small
Newton may diverge otherwise
Using step-size with Newton and QN method ensures convergence away from \(x_*\)
Worse than GD
\(\nabla^2 f(x)\) is usually expensive to compute
should also help
Quasi-Newton Methods, e.g. BFGS
Non-Smooth (why?) Optimization
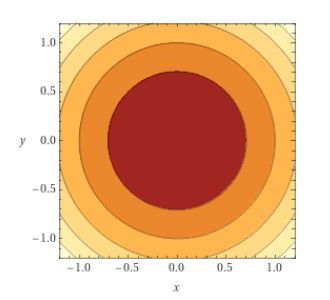
Toy Problem: Minimizing the absolute value function
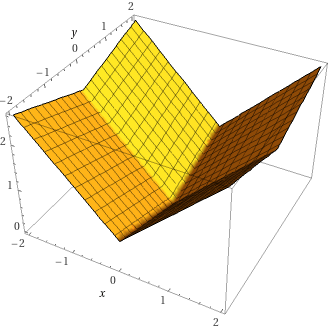
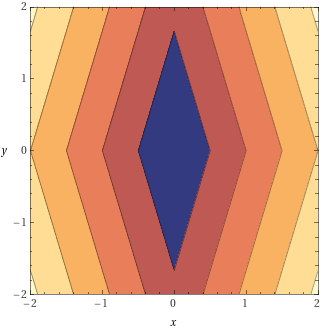
Adaptivity in Online Learning
Preconditioner at round \(t\)
AdaGrad from Online Learning
Convergence guarantees
"adapt" to the function itself
Attains linear rate in classical convex opt (proved later)
But... Online Learning is too adversarial, AdaGrad is "conservative"
Also... "approximates the Hessian" is not quite true
"Fixing" AdaGrad
But... Online Learning is too adversarial, AdaGrad is "conservative"
"Fixes": Adam, RMSProp, and other workarounds
RMSProp
Adam
Uses "momentum" (weighted sum of gradients)
Similar preconditioner to the above
"Fixing" AdaGrad
"AdaGrad inspired an incredible number of clones, most of them with similar, worse, or no regret guarantees.(...) Nowadays, [adaptive] seems to denote any kind of coordinate-wise learning rates that does not guarantee anything in particular."
Francesco Orabona in "A Modern Introduction to Online Learning", Sec. 4.3

Hypergradient Methods
Idea: look at step-size/preconditioner choice as an optimization problem
Gradient descent on the hyperparameters
How to pick the step-size of this? Well...

Little/ No theory
Unpredictable
... and popular?!
State of Affairs
What does it mean for a method to be adaptive?
(Quasi-)Newton Methods
Super-linear convergence close to opt
May need 2nd-order information.
Hypergradient Methods
Hyperparameter tuning as an opt problem
Unstable and no theory/guarantees
Online Learning
Formally adapts to adversarial and changing inputs
Too conservative in this case (e.g., AdaGrad)
"Fixes" (e.g., Adam) have few guarantees
State of Affairs
adaptive methods
only guarantee (globally)
In Smooth
and Strongly Convex optimization,
Should be better if there is a good Preconditioner \(P\)
Online Learning
Smooth Optimization
1 step-size
\(d\) step-sizes
(diagonal preconditioner )
Backtracking Line-search
Diagonal AdaGrad
Multidimensional Backtracking
Scalar AdaGrad
(and others)
(and others)
(non-smooth optmization)
Preconditioner Search
Optimal (Diagonal) Preconditioner
Optimal step-size: biggest that guarantees progress
Optimal preconditioner: biggest (??) that guarantees progress
\(L\)-smooth
\(\mu\)-strongly convex
\(f\) is
and
Optimal Diagonal Preconditioner
\(\kappa_* \leq \kappa\), hopefully \(\kappa_* \ll \kappa\)
Over diagonal matrices
minimizes \(\kappa_*\) such that
Optimal (Diagonal) Preconditioner

attain
From Line-search to Preconditioner Search
Line-search
Worth it if \(\sqrt{2d} \kappa_* \ll 2 \kappa\)
Multidimensional Backtracking
(our algorithm)
# backtracks \(\lesssim\)
# backtracks \(\leq\)
Multidimensional Backtracking
Why Naive Search does not Work
Line-search: test if step-size \(\alpha_{\max}/2\) makes enough progress:
Armijo condition
If this fails, cut out everything bigger than \(\alpha_{\max}/2\)
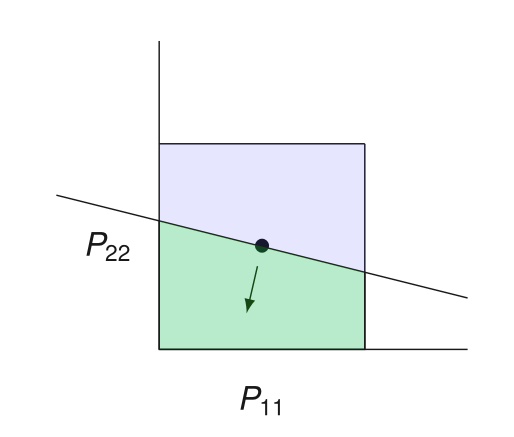
Preconditioner search:
Test if preconditioner \(P\) makes enough progress:
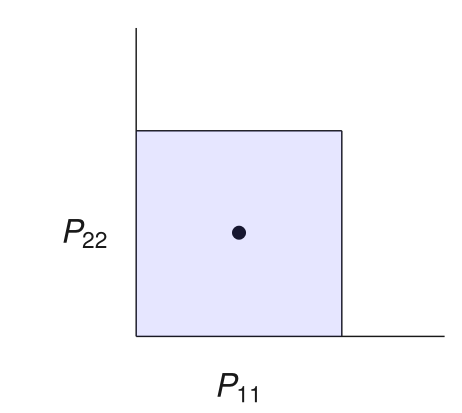
Candidate preconditioners \(\mathcal{S}\): diagonals in a box
If this fails, cut out everything bigger than \(P\)
Why Naive Search does not Work
Preconditioner search:
Test if preconditioner \(P\) makes enough progress:
Candidate preconditioners \(\mathcal{S}\): diagonals in a box
If this fails, cut out everything bigger than \(P\)
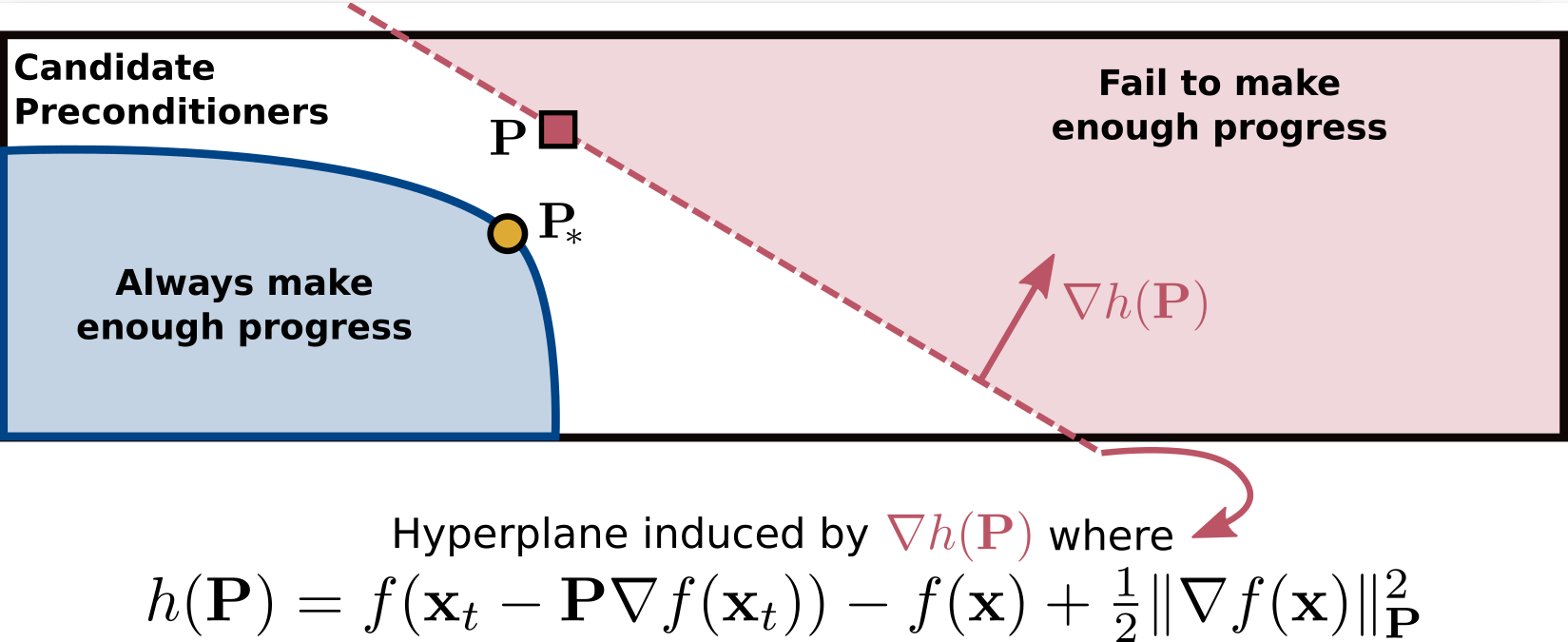
Convexity to the Rescue
\(P\) does not yield sufficient progress
Which preconditioners can be thrown out?
All \(Q\) such that \(P \preceq Q\) works, but it is too weak
\(P \) does not yield sufficient progress \(\iff\) \(h(P) > 0\)
Convexity \(\implies\)
\(\implies\) \(Q\) is invalid
A separating hyperplane!
\(P\) in this half-space
Convexity to the Rescue
Box as Feasible Sets
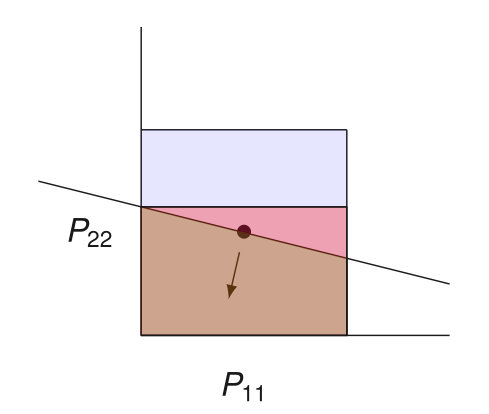
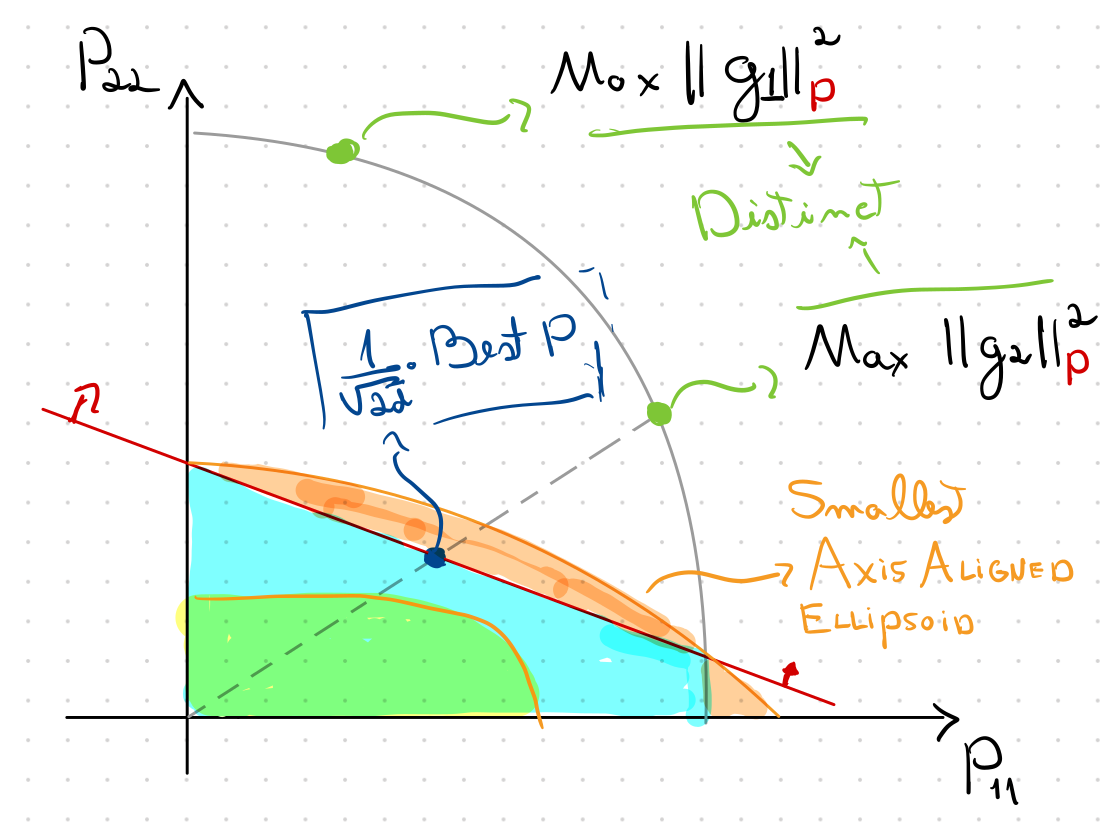
How Deep to Query?

that maximizes
Ellipsoid Method to the Rescue
that maximizes

Ellipsoid Method to the Rescue
We want to use the Ellipsoid method as our cutting plane method
\(\Omega(d^3)\) time per iteration
We can exploit symmetry!
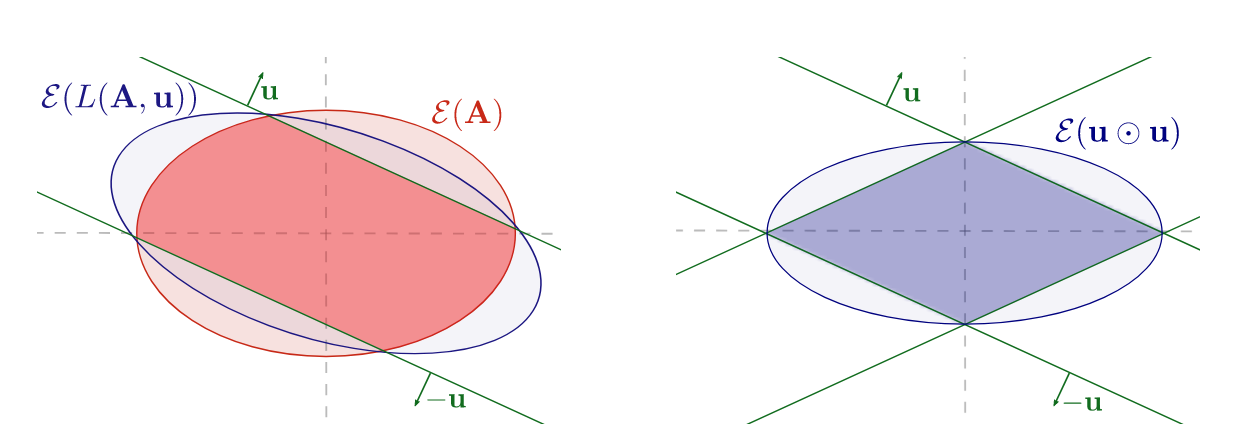
\(O(d)\) time per iteration
Constant volume decrease on each CUT
Query point \(1/\sqrt{2d}\) away from boundary
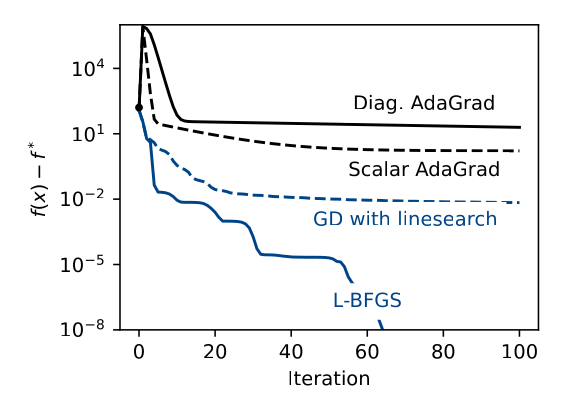
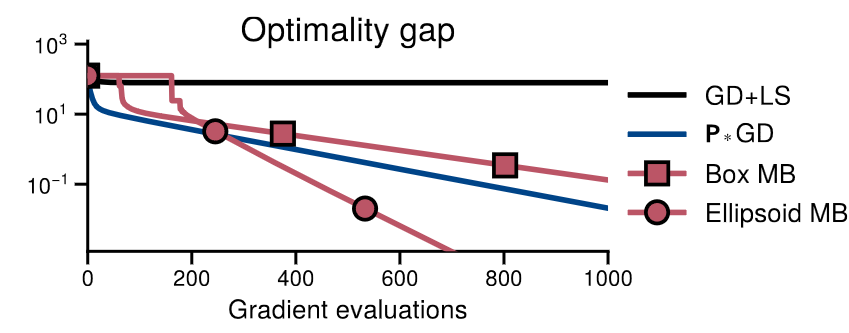
Experiments
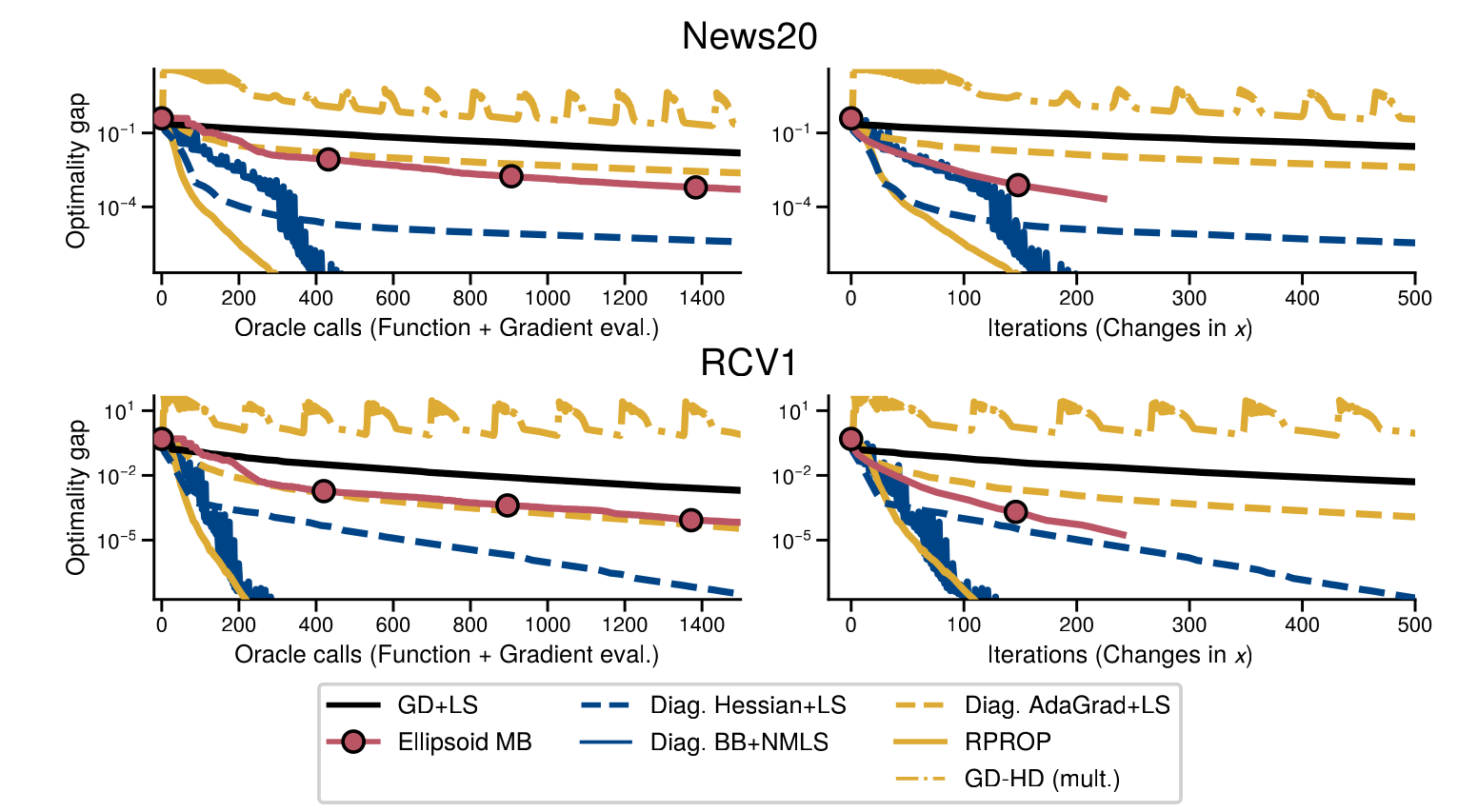
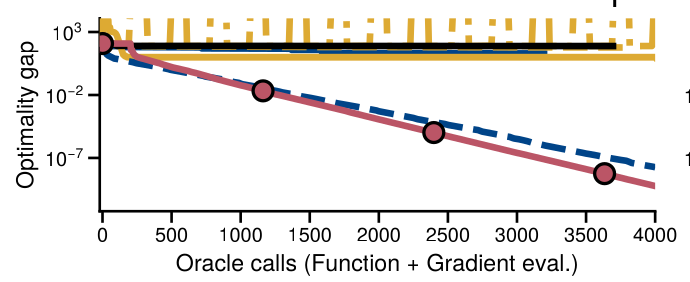
Experiments
Conclusions
Theoretically principled adaptive optimization method for strongly convex smooth optimization
A theoretically-informed use of "hypergradients"
ML Optimization meets Cutting Plane methods
Stochastic case?
Heuristics for non-convex case?
Other cutting-plane methods?
?
?
?
Thanks!
Backup Slides
How Deep to Query?
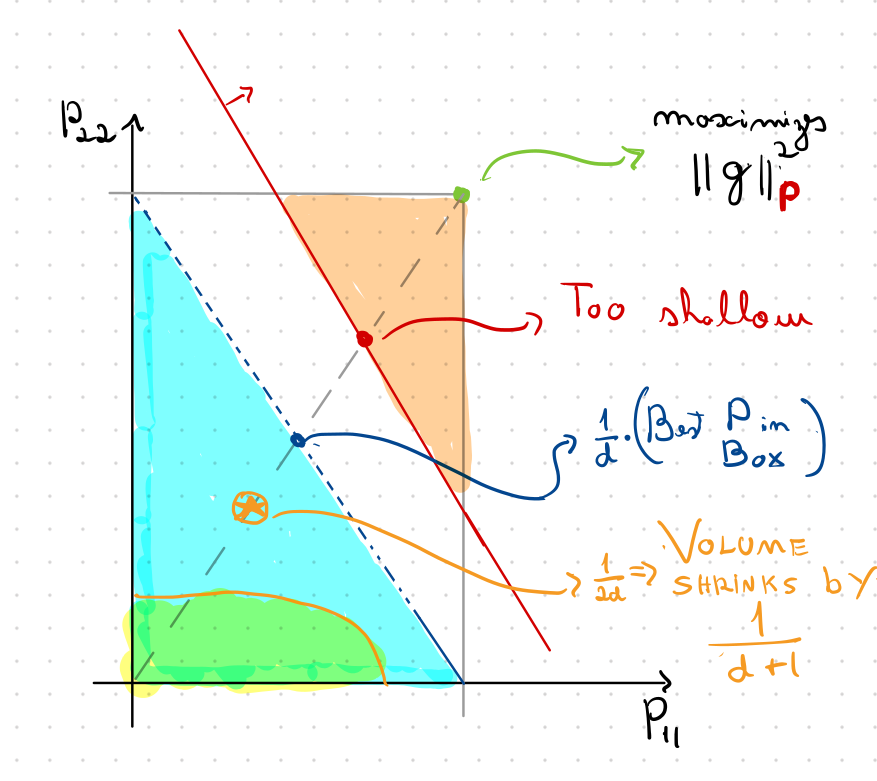
Ellipsoid Method to the Rescue