Minor Project
Mentor - Anuj Mahajan
Project - Github Recommendation System
Use - It can recommend repos to the user in which they can contribute.
Introduction
What is GitHub?
GitHub is a Web-based Git version control repository hosting service. It is mostly used for computer code. It offers all of the distributed version control and source code management (SCM) functionality of Git as well as adding its own features. It provides access control and several collaboration features such as bug tracking, feature requests, task management, and wikis for every project.
Tech Stack Used:
- Google BigQuery
- Python
- IPython Notebook
- Machine Learning for Network Analysis
- Google Cloud Platform (for Machine Learning)
Dataset Involved:
- Github Repository Dataset
link: https://bigquery.cloud.google.com/dataset/bigquery-public-data:github_repos
Description of Dataset:
GitHub is how people build software and is home to the largest community of open source developers in the world, with over 12 million people contributing to 31 million projects on GitHub since 2008.
This 3TB+ dataset comprises the largest released source of GitHub activity to date. It contains a full snapshot of the content of more than 2.8 million open sources GitHub repositories including more than 145 million unique commits, over 2 billion different file paths, and the contents of the latest revision for 163 million files, all of which are searchable with regular expressions.
Limitations:
- Data not fitting in our local machines memories.
How did we overcome this difficulty?
- C-Farm provided instances
Specifications of Instance that we used -
- IBM Power8
What we did in the project :
Divided the project into several steps.
- Analysis of Repos
- Analysis of Users
- Segment Users into Groups
- Segment Repos into Groups
- Understand relation between different groups of Users and Repos
- Record our findings
Analysis of Repos/Projects:
- More watch count implies maturity of the project.
- Variability of Commits describes the availability
of tasks.
- Repos with more discussion in issues section implies beginner friendly community.
Possible Approaches -
To construct this project-project network, a trivial solution is to check one project with every other project and look for the number of common developers. However, this would be costly.
To alleviate this computation issue, we perform the steps described in Algorithm 1. For each project, we first get the developers that work for it, we then find all the projects that the developers work for. This set of projects is typically a small size. We then just compare the input project with all projects in the set.
Algorithm 1- Selecting Efficiently
Input: Projects // set of projects
Network ← ∅ // Project-project network
for each (project Qa in Projects) do
Developers ← listDevelopersInvolved(Pa)
for each (developer Da in Developers) do
smallSetProjects ← listProjects(Da)
for each (project Qb in smallSetProjects) do
link ← countCommonDevelopers(Qa, Qb)
Network ← {Network, link}
return Network
In this network, we have Project - Project relation.
Analysis of Users:
- Understanding the process of contributing to a New Repo by a New User
- New User contributes to Active Projects
- Area of specificity of the developer guides the interest of developer
In a developer-developer network, each node represents a given developer in our dataset. The corresponding graph contains an edge between two vertices when the corresponding developers work together in at least one common project. Thus the developer-developer network is built based on collaborations among developers, where collaboration is simply defined as working together towards the same goal or purpose, i.e., completing a software project.
Similarly to the project-project graph, we associate a weight to each edge taking into account the number of projects where the two relevant developers work together. To build the developer-developer network, we proceed with the same methodology as for the project-project network.
Algorithm 2- Selecting Efficiently
Input: Developers // set of projects
Network ← ∅ // Developer-Developer network
for each (developer Da in Developers) do
Projects ← listProjectsInvolved(Da)
for each (project Pa in Projects) do
smallSetDevelopers ← listdevelopers(Pa)
for each (developer Db in smallSetDevelopers) do
link ← countCommonProjects(Da, Db)
Network ← {Network, link}
return Network
In this network, we have Developer - Developer relation.
Why all this?
By this, we were able to decide on which parameters to include in our final algorithm, which is subject to change with further analysis.
We had certain strategies to choose from.
1. Collaborative Filtering
2. Content-Based Filtering
3. Hybrid Approach
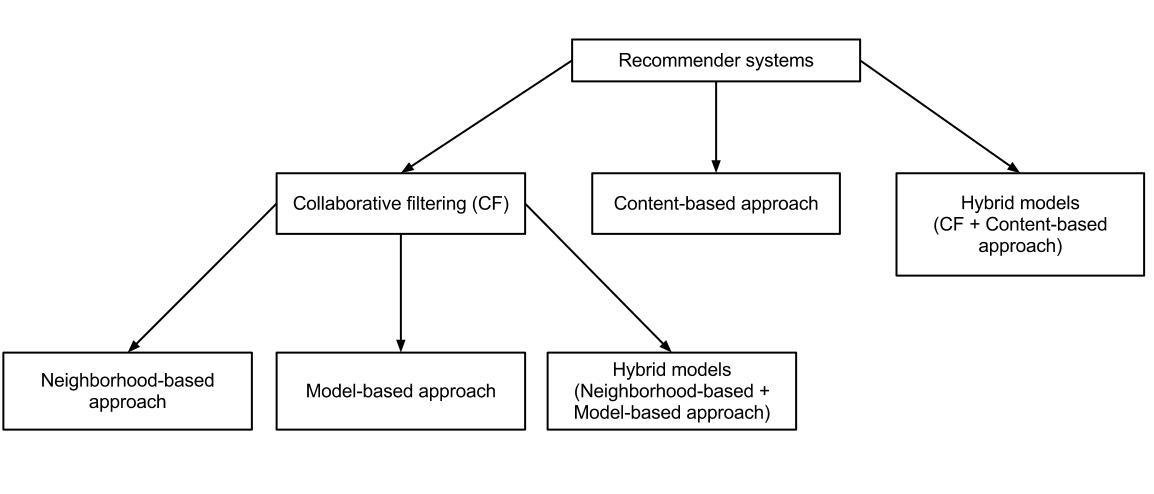
Collaborative filtering methods are based on collecting and analyzing a large amount of information on users’ behaviors, activities or preferences and predicting what users will like based on their similarity to other users.
Content-based filtering methods are based on a description of the item and a profile of the user’s preferences.
Hybrid Approach, a mix of both the above approaches.
Finally we ended up pursuing the hybrid approach.
We are working on the algorithm and will continue our work on the same.
Collecting More Data :
> Developer REST API (https://developer.github.com/v3/)
> Developer GraphQL API (https://developer.github.com/v4/)
After our network is prepared of Developers and Projects. We moved toward the making of the frontend and backend service required for the project.
For front-end part we are using AngularJS.
For back-end part we are using Node and Express.
We are actually Implementing the Github OAuth2 authentication for login via Github
Basic Flow of application-
1. The AngularJS app is requesting to GitHub the authorization code by opening the GitHub popup window.
2. Github is issuing an authorization code.
3. The AngularJS app is requesting an Access token to a Node.js Server which is requesting it to the GitHub API
Back-end Code Snippet
Conclusion -
This term we were able to find out and explore the various possibility of what is possible with data.
We were able to notice some trend that was helpful in designing the final algorithm for the recommendation. We are also looking forward to including the work of other people who have worked on this problem.
This can impact the engagement of the new user and is really relevant according to the current times. We went through certain papers and were able to confirm their findings.
Questions?
Thank You