Reinforcement Learning and Adaptive Sampling for Optimized DNN Compilation
Vinod Ganesan
vinodg@cse.iitm.ac.in
SysDL Reading Group

DNN Compilation



Conv2D

Frameworks
Data Flow graphs
DNN Operator Libraries

Hardware
Engineer Intensive!
Custom Operator libraries


CUDA
DSCs
ReLU
DNN Compilation
DNN Operator Libraries
Hardware
ML based program optimizer
Conv2D
Frameworks
Data Flow graphs
ReLU
DNN Compilation flow

- Data layout transformation
- Dead code elimination
- Operator fusion
- Loop tiling
- Loop unrolling
- Loop interchange
$$ \theta^* = \argmax_\theta f(\tau(\theta)), \theta \in D_\theta$$
- \( \theta^* \) - optimized schedule
- \( \tau \) - code template
- \( \theta = (\theta_1, \theta_2,....., \theta_n) \) tunable knobs
- f - fitness function
- \( D_\theta \) - Design Space
Rich Search Space
Effective search algorithm
Fast fitness estimation
State-of-the-art: TVM
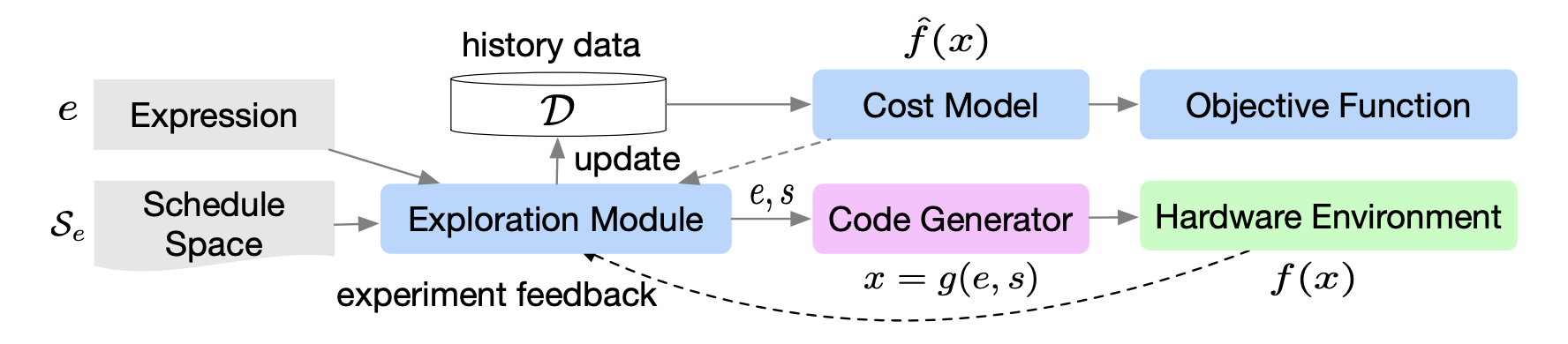
Search for better schedules
Sample for improving fitness estimation

TVM - Disadvantages
- Simulated annealing is slow (ineffective search algorithm!)
- Simulated annealing is oblivious to the gradual changes in the cost model, redundant work done during the search process.
- Greedy sampling and annealing is passive as it relies on cost model. This leads to neglecting good solutions that are distributed non-uniformly.
- Greediness leads to overfitting the cost model - making things worse
- Greedy sampling often gives redundant/invalid configurations - wasting precious hardware measurements
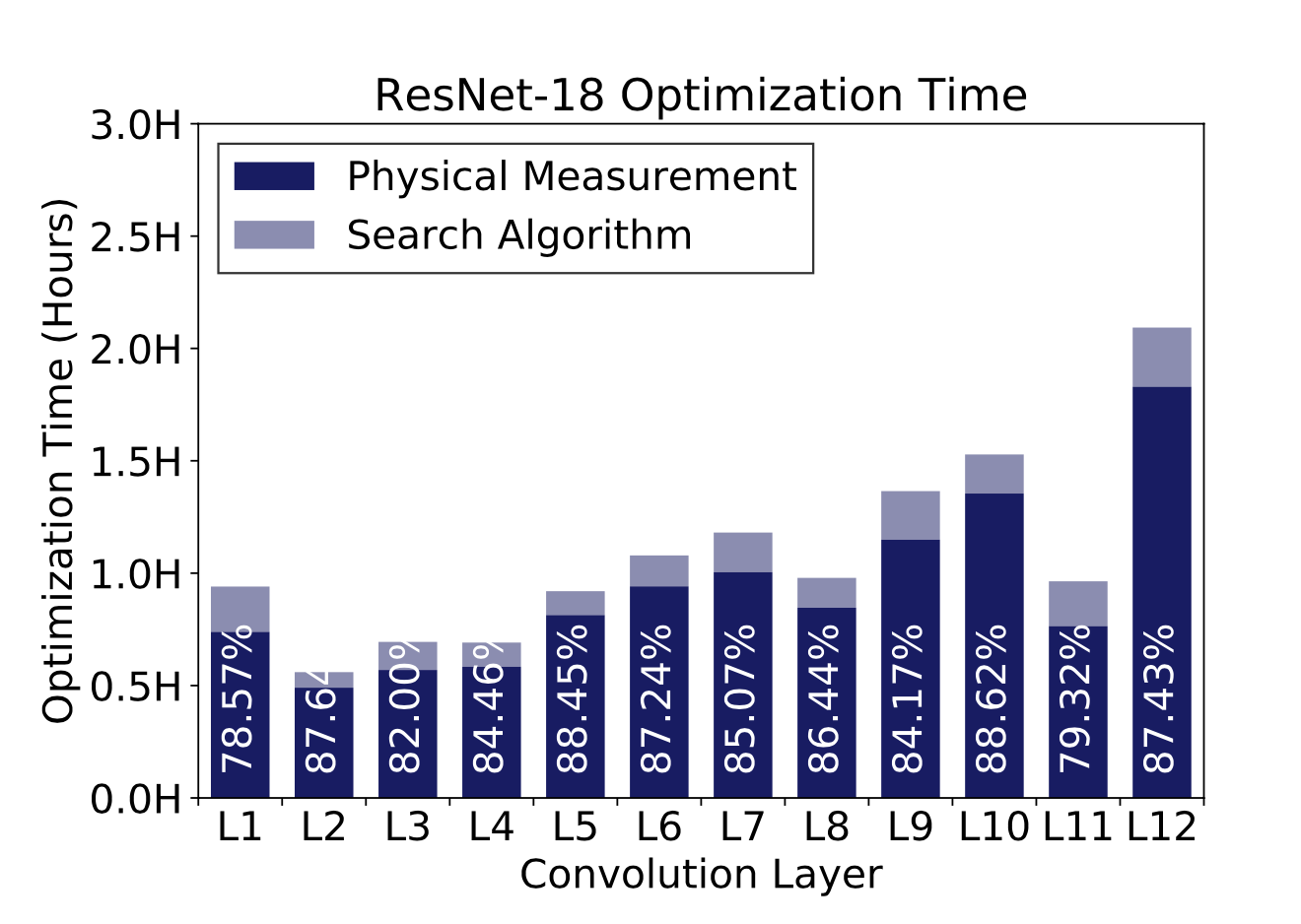
TVM is very slow!
Intelligent Search algorithm
$$ s_\theta^* = \argmax_{s_\theta \subset S_\theta}(P(f_{ideal}(\tau) - \max_{\theta \in s_\theta}f(\tau(\theta)) = 0) $$
$$ A^* = \argmin_{A}(\#steps(s_{\theta,t} = A(s_{\theta,t-1})) = s_{\theta^*} $$
Exploration
Exploitation
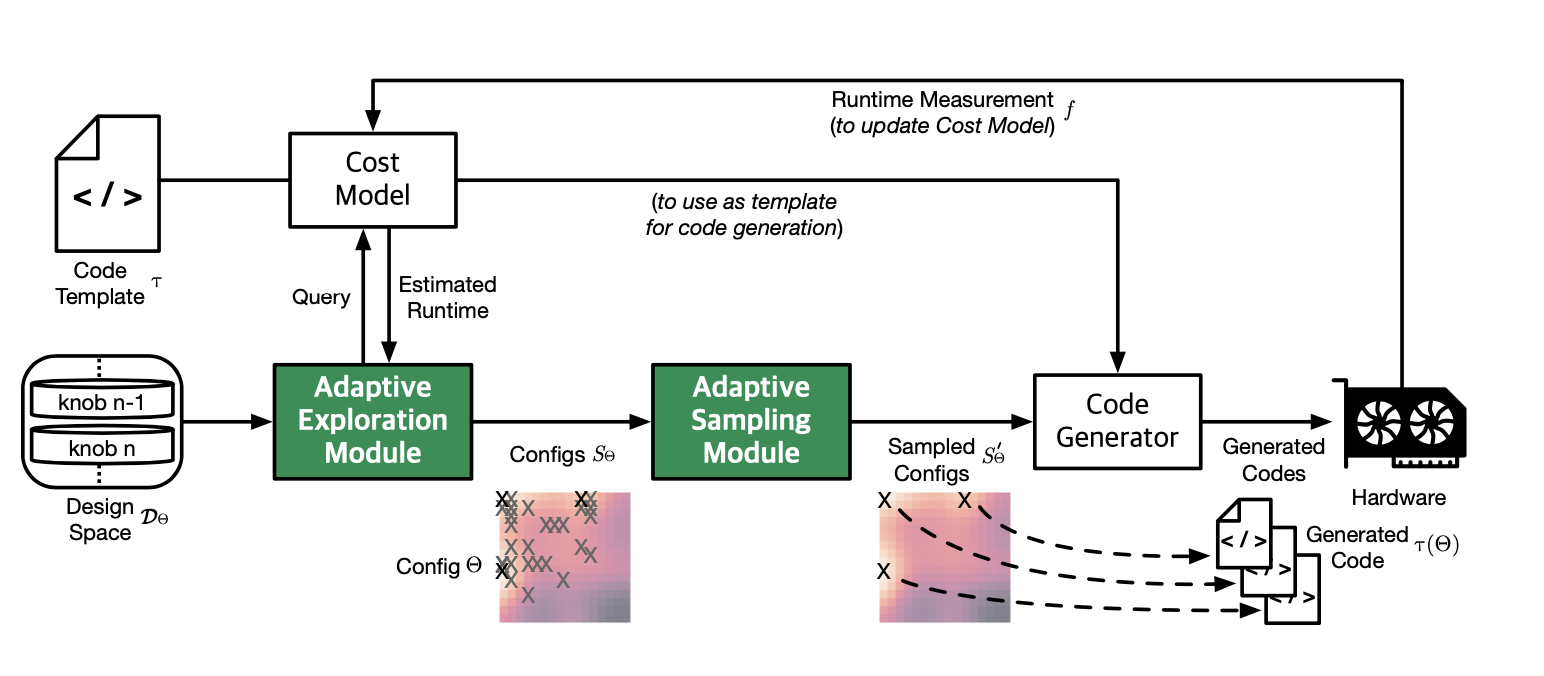
Actor-critic based RL agent employing PPO
Clustering-based sampling
Bread and butter of RL algorithm

State Space
\( \theta = (\theta_0, \theta_1,...,\theta_n) \)
.....
Action Space
\( \theta = (inc, dec, stay,....,inc) \)
Reward Formulation
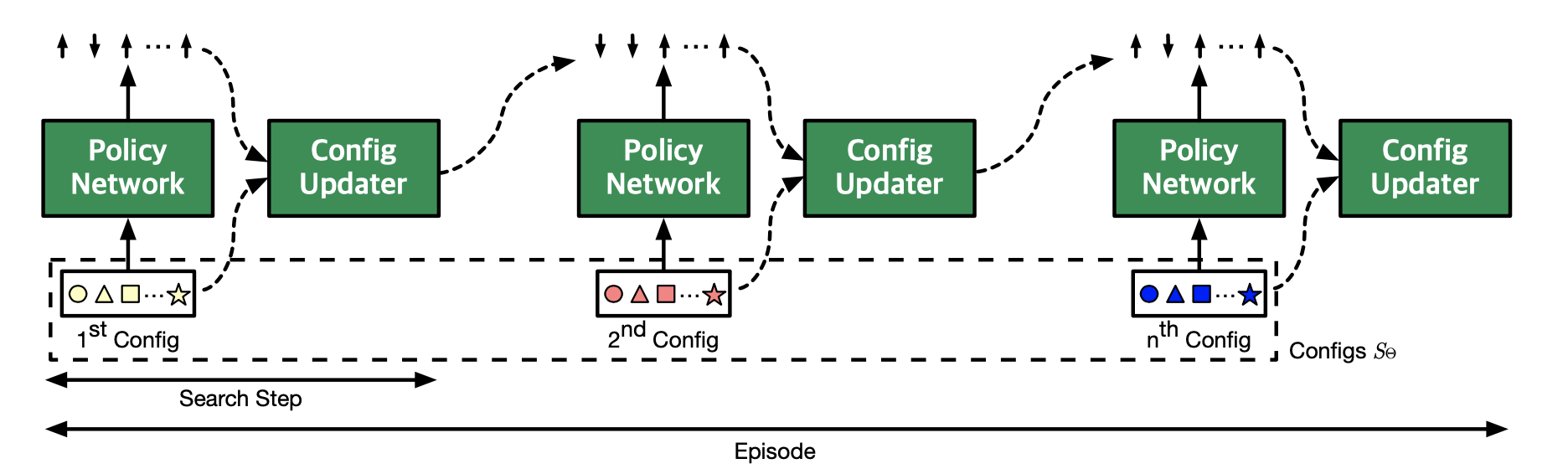
RL Agent - policy and value networks
- Policy network takes \( \theta \) and returns a vector of directions
- The value network returns the value of the action.
- Config updater takes the previous config and the vector of directions to generate the next set of configs.
- All n configurations from an episode ( \( S_\theta \) ) are evaluated on the cost model, and are used to generate rewards
Reducing costly hardware measurements
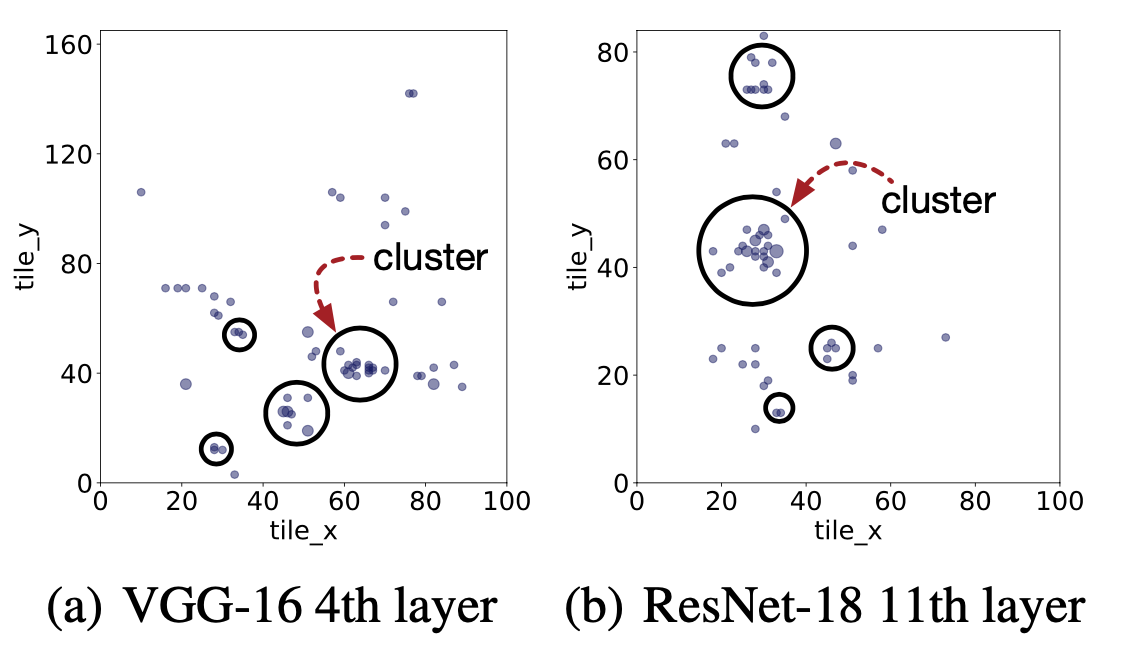
Clustering adapts to the changing landscape of the design space and non-uniformity of distribution
- Cluster configurations ( \( s_\theta \) ) based on k-means clustering by finding optimal value of k
- Maintain the history of previously visited configurations
- Use the centroids alone for hardware measurement. If a centroid is previously visited, ignore it and choose an unseen config
Evaluation - Improving efficacy of search
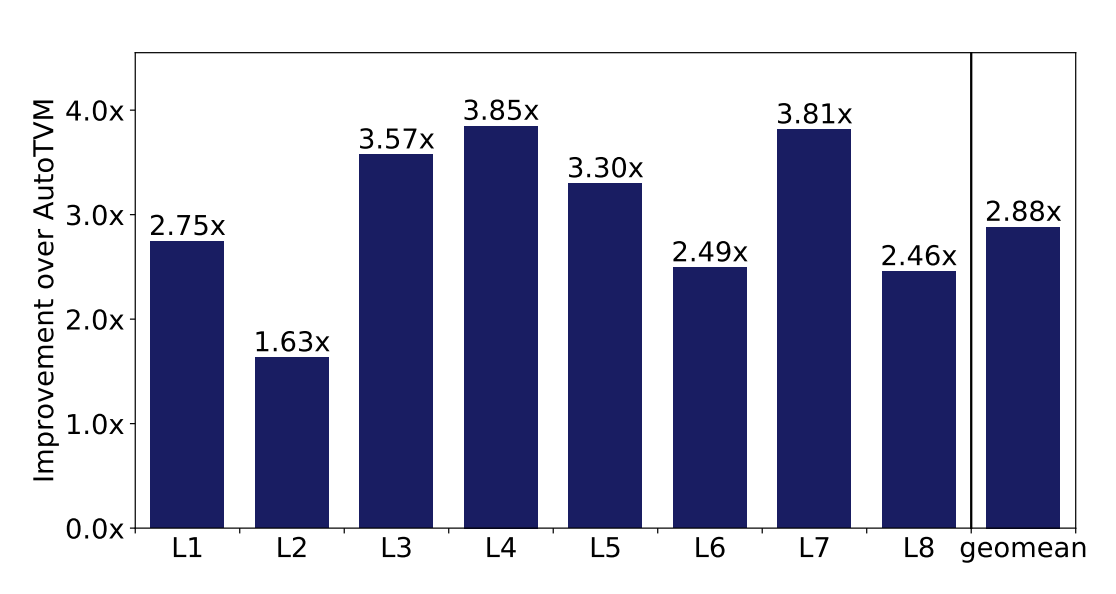
Reduction in Search steps over TVM
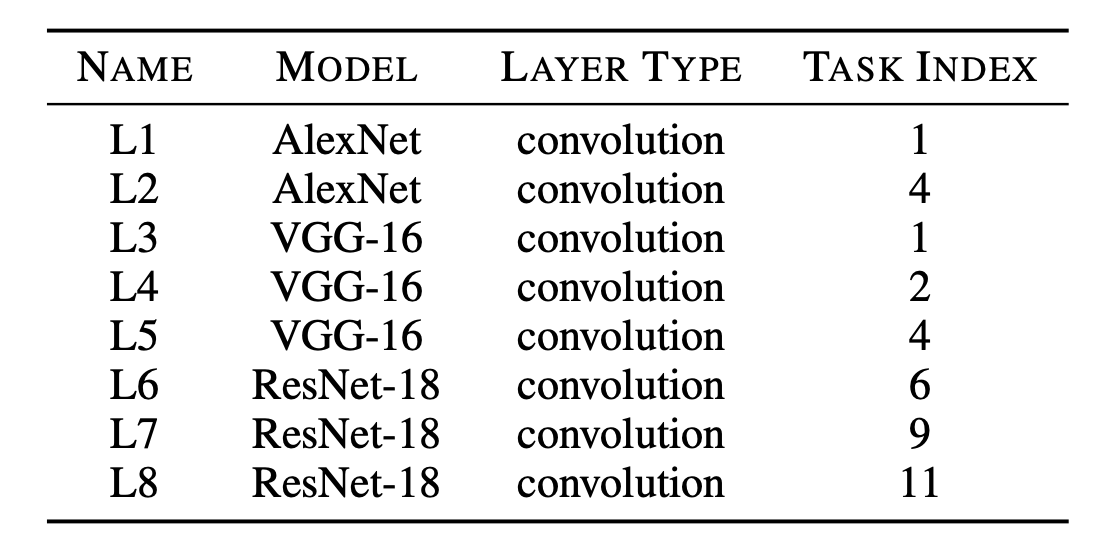
RL agent is able to quickly learn the correlations amongst different knobs
Reuses information from previous iterations, unlike simulated annealing!
Evaluation - Reducing hardware measurements
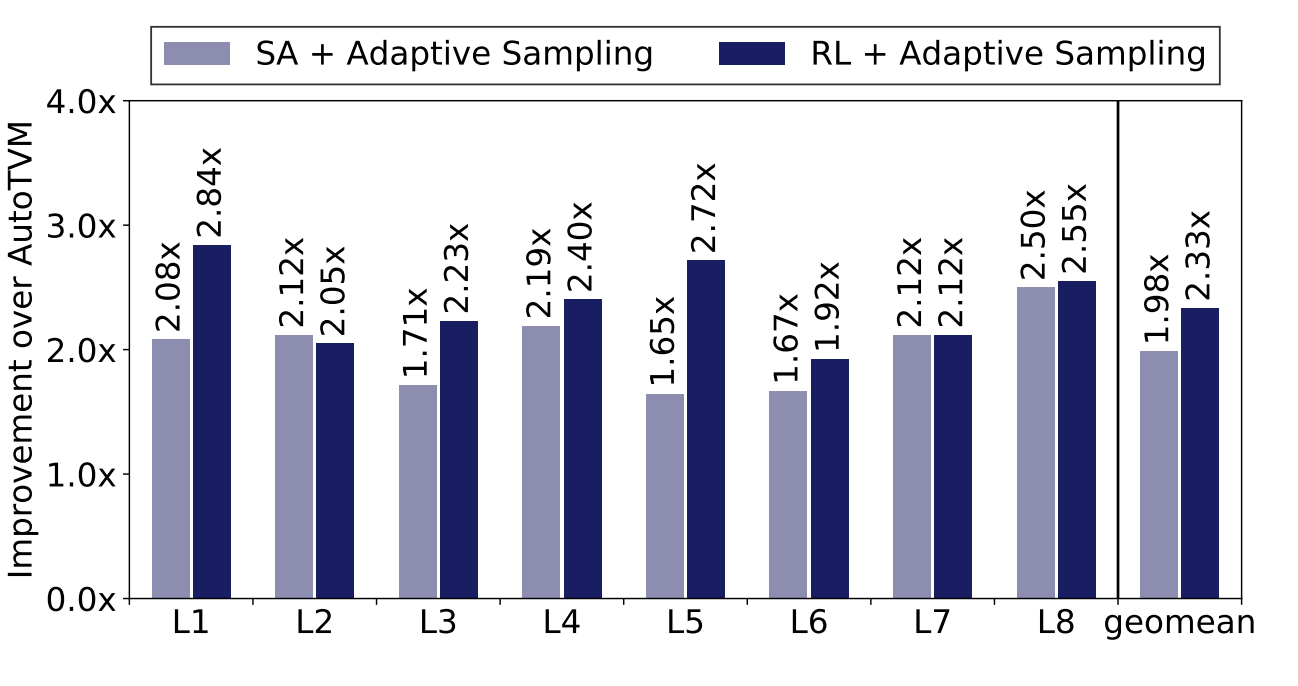
- Adaptive sampling works well with RL since RL is able to localize the search to meaningful samples (exploration) while maintaining diversity (exploitation)
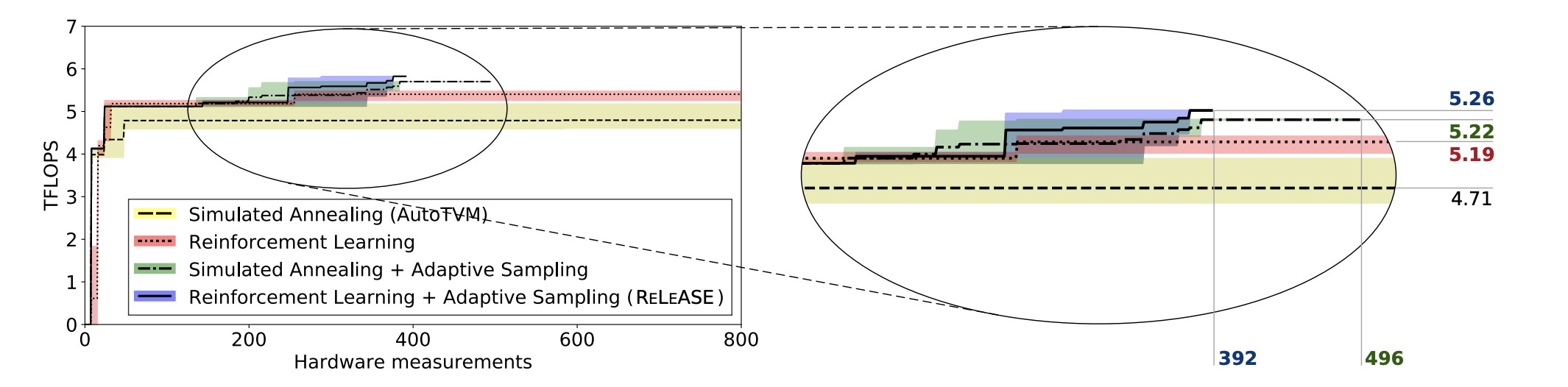
Putting it all together
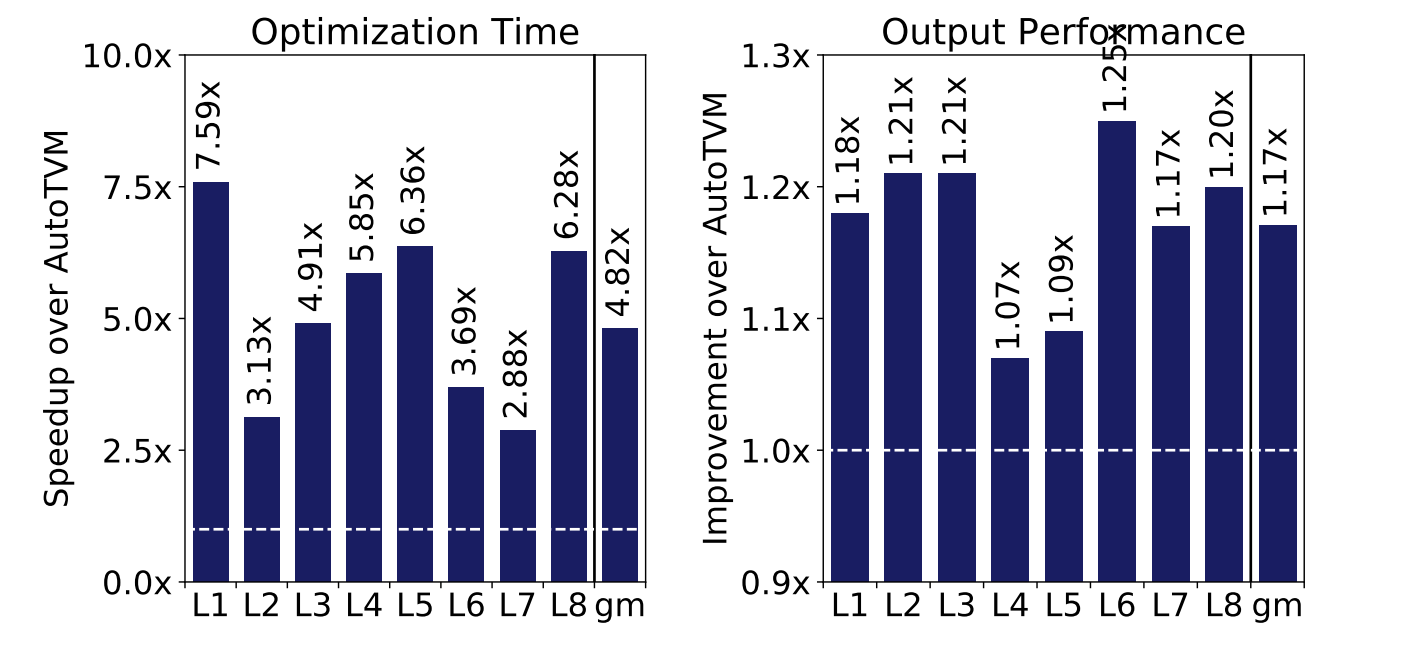
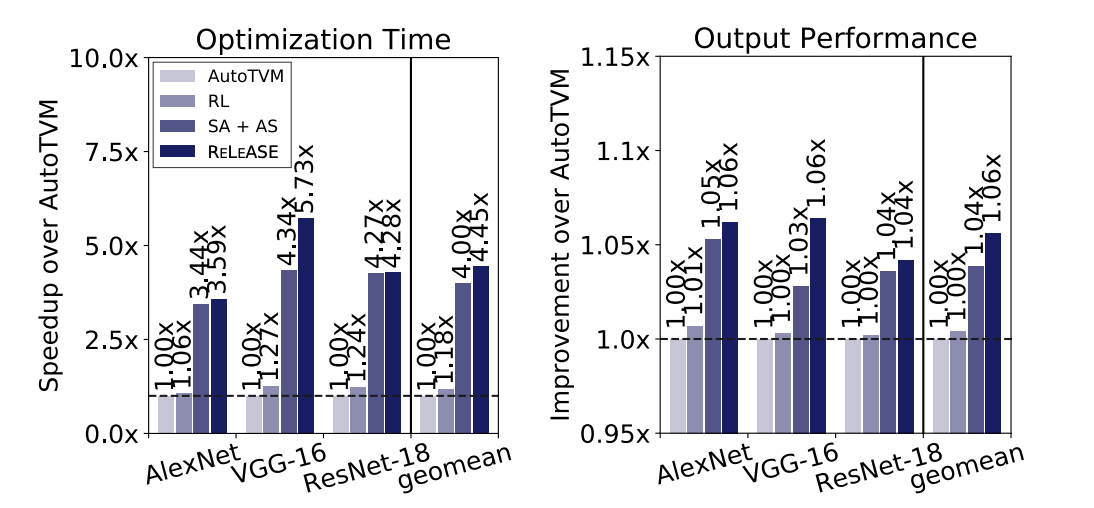
Mean reduction of 4.45x in compilation time, and mean improvement of 6% in output performance
Mean reduction of 4.82x in compilation time, and mean improvement of 17% in performance
My key takeaways
- RL + Adaptive sampling can improve the optimization time significantly while also improving the performance
- Most of the speed-up comes from reducing the hardware measurements, as seen from the results. A marginal speed-up also comes from re-using previous configurations, where the RL agent is useful!
- Bottom-line: It is not completely clear if all the claims of RL being very effective for search are coming out in the results since the gains are very disproportional
- DNNs are not representative of current State-of-the-art!
There probably is a God. Many things are easier to explain if there is than if there isn't
- Von Neumann
Vinod Ganesan
SysDL Reading Group
vinodg@cse.iitm.ac.in