Parsing text with Python
Expectation is the root of all heartache.

Agenda
- Why parse files?
- The big picture
- Parsing text in standard format
- Parsing text using string methods
- Parsing text in complex format using regular expressions
- Is this the best solution?
- Reference to blog
Why parse files?

Definition
Convert data in a certain format into a more usable format.

The Big Picture
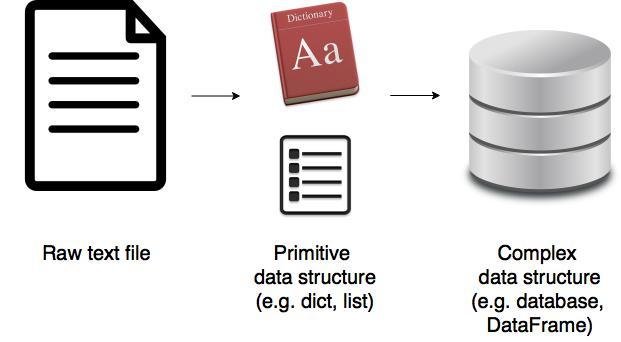
pandas
Insanely powerful data analysis
An abstraction on top of Numpy which provides multi-dimensional arrays, similar to Matlab
The DataFrame is a 2D array
MultiIndex allows it to store multi-dimensional data.
SQL or database style operations are easy
A suite of IO tools

Parsing text in standard format
a,b,c
1,2,3
4,5,6
7,8,9import pandas as pd
df = pd.read_csv('data.txt')
df
a b c
0 1 2 3
1 4 5 6
2 7 8 9Parsing text using string methods
my_string = 'Names: Romeo, Juliet'
# split the string at ':'
step_0 = my_string.split(':')
# get the first slice of the list
step_1 = step_0[1]
# split the string at ','
step_2 = step_1.split(',')
# strip leading and trailing edge
# spaces of each item of the list
step_3 = [name.strip() for name in step_2]
Step 0: ['Names', ' Romeo, Juliet']
Step 1: Romeo, Juliet
Step 2: [' Romeo', ' Juliet']
Step 3: ['Romeo', 'Juliet']Parsing text in complex format using regular expressions
Sample text
A selection of students from Riverdale High and Hogwarts took part in a quiz.
Below is a record of their scores.
School = Riverdale High
Grade = 1
Student number, Name
0, Phoebe
1, Rachel
Student number, Score
0, 3
1, 7
Grade = 2
Student number, Name
0, Angela
1, Tristan
2, Aurora
Student number, Score
0, 6
1, 3
2, 9
School = Hogwarts
Grade = 1
Student number, Name
0, Ginny
1, Luna Name Score
School Grade Student number
Hogwarts 1 0 Ginny 8
1 Luna 7
2 0 Harry 5
1 Hermione 10
3 0 Fred 0
1 George 0
Riverdale High 1 0 Phoebe 3
1 Rachel 7
2 0 Angela 6
1 Tristan 3
2 Aurora 9import re
import pandas as pd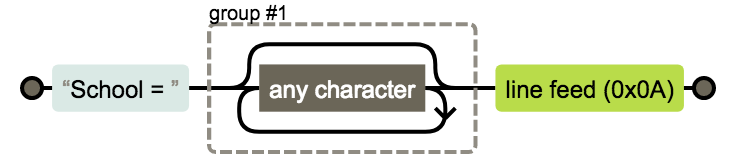
'School = (?P<school>.*)\n'# set up regular expressions
# use https://regexper.com to visualise these if required
rx_dict = {
'school': re.compile(r'School = (?P<school>.*)\n'),
'grade': re.compile(r'Grade = (?P<grade>\d+)\n'),
'name_score': re.compile(r'(?P<name_score>Name|Score)'),
}def _parse_line(line):
"""
Do a regex search against all defined regexes and
return the key and match result of the first matching regex
"""
for key, rx in rx_dict.items():
match = rx.search(line)
if match:
return key, match
# if there are no matches
return None, Nonedata = [] # create an empty list to collect the data
# open the file and read through it line by line
with open(filepath, 'r') as file_object:
line = file_object.readline()
while line:
# at each line check for a match with a regex
key, match = _parse_line(line)
# extract school name
if key == 'school':
school = match.group('school')
# extract grade
if key == 'grade':
grade = match.group('grade')
grade = int(grade)# create a dictionary containing this row of data
row = {
'School': school,
'Grade': grade,
'Student number': number,
value_type: value
}
# append the dictionary to the data list
data.append(row)data = pd.DataFrame(data)