
Terminei a modelagem, e agora?
André Oliveira e Vivian Yamassaki
Python Brasil 2021

Sobre nós :)
- Mestra em Sistemas de Informação pela USP
- Data Scientist na Creditas
- Co-organizadora da MIA (Mulheres em Inteligência Artificial)
- Graduado em Engenharia de Automação e Controle pela FEI
- MBA em IA e Machine Learning pela FIAP
- Machine Learning Specialist na Creditas


Com o aumento das vagas na área de Dados, também tivemos um aumento no oferecimento de cursos na área
Fonte: Google Trends
Interesse pelo termo "Data Science" aqui no Brasil
Com o aumento das vagas na área de Dados, também tivemos um aumento no oferecimento de cursos na área

Com o aumento das vagas na área de Dados, também tivemos um aumento no oferecimento de cursos na área








Mas nem todos passam por todas as etapas de um fluxo de Data Science...
Entendimento do problema
Coleta e limpeza dos dados
Análise exploratória
Feature Engineering
Modelagem
Avaliação dos resultados
Deploy do modelo
Antes de chegarmos do deploy, vamos falar de algumas coisas que precisamos fazer antes disso...
Para isso, vamos utilizar como exemplo o famoso desafio do Titanic!
Quem quiser, pode pegar os dados aqui:

Para esse exemplo, vamos considerar apenas algumas variáveis
Primeira coisa que precisamos fazer: cuidar da feature engineering!


- Como podemos fazer a normalização de dados que chegam em produção?


Primeira coisa que precisamos fazer: cuidar da feature engineering!
- Como podemos tratar valores faltantes que chegam no modelo?

Primeira coisa que precisamos fazer: cuidar da feature engineering!
- O que fazer quando recebemos um valor categórico desconhecido pelo modelo?
Primeira coisa que precisamos fazer: cuidar da feature engineering!
Supondo que fizemos uma transformação utilizando o MixMaxScaler em nosso conjunto de treinamento
Precisamos de alguma forma salvar a forma como essa transformação foi feita para que seja replicada em produção!
Normalização de dados
Isso pode ser feito salvando o scaler como um objeto binário
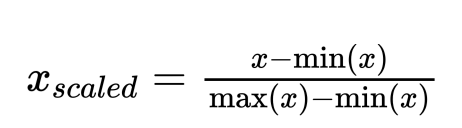
from sklearn.preprocessing import MinMaxScaler
import pickle
scaler = MinMaxScaler()
scaler.fit(df)
with open("models/scaler.pkl", "wb") as pickle_file:
pickle.dump(scaler, pickle_file)Normalização de dados
Podemos fazer isso da seguinte forma:
Tratamento de valores faltantes
Pensando em produção, não podemos simplesmente fazer o seguinte tratamento de valores faltantes:
df["Age"].fillna(df["Age"].median(), inplace=True)Assim, temos algumas alternativas:
median_age = 35
df['Age'].fillna(median_age, inplace=True)- Salvar o valor da mediana do conjunto de treinamento para cada variável
Tratamento de valores faltantes
Assim, temos algumas alternativas:
2. Criar um imputer para calcular a mediana e usá-la para preencher valores faltantes (aqui estamos usando o SimpleImputer)
from sklearn.impute import SimpleImputer
import pickle
import pandas as pd
imputer = SimpleImputer(strategy='median')
imputer.fit(df)
with open("models/imputer.pkl", "wb") as pickle_file:
pickle.dump(imputer, pickle_file)Tratamento de valores faltantes
Para valores categóricos desconhecidos pelo modelo, temos duas alternativas
- Vamos querer que ele retorne um erro caso receba um valor desconhecido
- Valor querer que ele gere uma predição, por mais que receba um valor desconhecido
Tratamento de dados categóricos - One-hot encoding
import pandas as pd
from sklearn.preprocessing import OneHotEncoder
import pickle
enc = OneHotEncoder(handle_unknown='ignore', drop='if_binary')
enc.fit(df['Sex'].values.reshape(-1, 1))
with open("models/ohe.pkl", "wb") as pickle_file:
pickle.dump(enc, pickle_file)Para o segundo caso, podemos utilizar o OneHotEncoder e criá-lo de modo que ele ignore valores desconhecidos:
Tratamento de dados categóricos - One-hot encoding
Pipeline é uma classe do Scikit-learn que permite que as transformações da feature engineering sejam feitas na sequência uma das outras.
Para isso, cada uma das transformações será feita em arquivos separados e terá métodos de fit e transform.
Uma coisa importante que também usamos para organizar a feature engineering são os Pipelines
As vantagens de se utilizar pipelines são:
- Permitir que seja criado um padrão que possa ser entendido por outras pessoas do time
- Permitir a organização da feature engineering
Uma coisa importante que também usamos para organizar a feature engineering são os Pipelines
from abc import ABC
from sklearn.pipeline import Pipeline
from missing_imputer import MissingValuesImputer
from numerical_scaler import NumericalFeaturesScaler
from ohe_transformer import OneHotEncode
class FeatureEngineering(ABC):
def get_pipeline(self):
return Pipeline(
[
("ohe", OneHotEncode()),
("missing_imputer", MissingValuesImputer()),
("numerical_scaler", NumericalFeaturesScaler(numerical_features=['Age', 'Fare', 'Pclass'])),
]
)Para o nosso exemplo, podemos ter esse pipeline:
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.preprocessing import MinMaxScaler
import pickle
class NumericalFeaturesScaler(BaseEstimator, TransformerMixin):
def __init__(self, numerical_features):
self.features = numerical_features
self.scaler = self.load_numerical_features_scaler()
def fit(self, df):
self.scaler.fit(df[self.features])
with open("models/scaler.pkl", "wb") as pickle_file:
pickle.dump(self.scaler, pickle_file)
return self
def transform(self, df):
df[self.features] = self.scaler.transform(df[self.features])
return df
def load_numerical_features_scaler(self):
try:
with open("models/scaler.pkl", "rb") as pickle_file:
return pickle.load(pickle_file)
except FileNotFoundError:
return MinMaxScaler()Cada um dos transformers vai ter as transformações necessárias para a feature engineering
from abc import ABC
from sklearn.pipeline import Pipeline
from missing_imputer import MissingValuesImputer
from numerical_scaler import NumericalFeaturesScaler
from ohe_transformer import OneHotEncode
class FeatureEngineering(ABC):
def get_pipeline(self):
return Pipeline(
[
("ohe", OneHotEncode()),
("missing_imputer", MissingValuesImputer()),
("numerical_scaler", NumericalFeaturesScaler(numerical_features=['Age', 'Fare', 'Pclass'])),
]
)Note que a ordem do pipeline é importante!
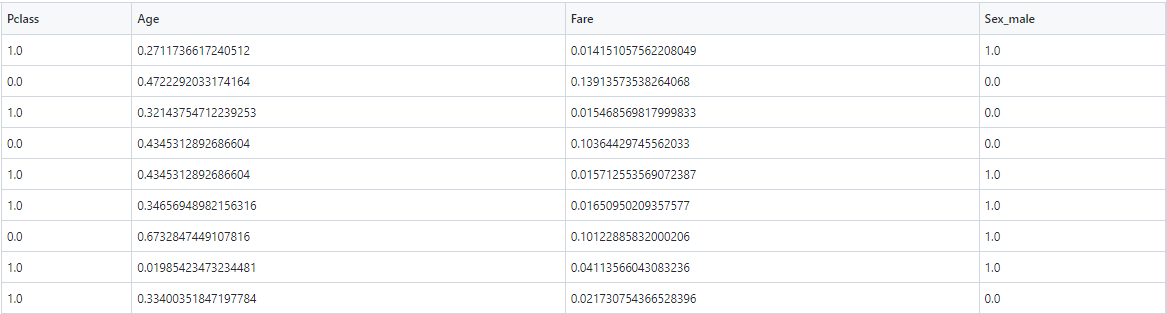
Como saída desse pipeline, teríamos o seguinte conjunto de treinamento:
import pandas as pd
import pickle
from sklearn.linear_model import LogisticRegression
from feature_engineering_pipeline import FeatureEngineering
def main():
train = pd.read_csv('data/train.csv')
X_train = train.drop(['Survived'], axis=1)
y_train = train['Survived']
X_test = pd.read_csv('data/test.csv')
features = ['Pclass', 'Age', 'Sex', 'Fare']
X_train = X_train[features]
X_test = X_test[features]
feature_engineering_pipeline = FeatureEngineering().get_pipeline()
X_train = feature_engineering_pipeline.fit_transform(X_train)
X_test = feature_engineering_pipeline.transform(X_test)
X_train.to_csv('data/train_after_feature_engineering.csv', index=False)
X_test.to_csv('data/test_after_feature_engineering.csv', index=False)
model = LogisticRegression(random_state=42)
model.fit(X_train, y_train)
with open('models/model.pkl', 'wb') as pickle_file:
pickle.dump(model, pickle_file)
if __name__ == '__main__':
main()Além de salvar as transformações da feature engineering, também é importante salvar o modelo!!!
Quando executamos esse código, temos um arquivo do modelo salvo no formato pickle e conseguimos utilizá-lo posteriormente sem depender de um notebook :)

Mas podemos utilizá-lo em notebooks também se assim quisermos!

O TL;DR então é
- Salve o modelo e as transformações feitas na feature engineering (preenchimento de valores faltantes, normalizações dos dados e tratamento de valores categóricos)!
- Use pipelines para facilitar o entendimento e a organização da feature engineering.
Hora de implantar o modelo!

Vamos apresentar apenas uma de muitas formas possíveis para implantar o modelo. Alguns casos de usos podem precisar de algumas alterações.
Hora de implantar o modelo!

Etapas para implantação do modelo



Scripts da Feature Engineering
Serviço de predição
"Dockerização"
Implantação do modelo
Integração/Entrega Contínua
Serviço de predição

Serviço de predição

Serviço de predição usando FastAPI
import os
import logging
import pandas as pd
from fastapi.responses import JSONResponse
import uvicorn
from fastapi import FastAPI
from typing import List
from predictor.pipeline.predictor import Predictor
from predictor.serializers.response import ResponseSerializer
from predictor.serializers.passenger import Passenger
from predictor.settings import CONFIGS
from feature_engineering.feature_engineering_pipeline import FeatureEngineering
logger = logging.getLogger(__name__)
app = FastAPI()
@app.get('/health', status_code=200)
def health_check():
return JSONResponse({"status": "healthy"})
@app.post('/predict')
async def predict(data: List[Passenger]):
ids, raw_data = to_dataframe(data)
processed_data = FeatureEngineering(CONFIGS['numerical_features']).transform(raw_data)
predictions = Predictor(CONFIGS['model_path']).predict(processed_data)
return ResponseSerializer().serialize(ids, predictions)
def to_dataframe(data: List[Passenger]) -> pd.DataFrame:
id_column = CONFIGS['id']
df = pd.DataFrame([vars(passenger) for passenger in data])
return df[id_column], df.drop(id_column, axis=1)
if __name__ == "__main__":
uvicorn.run(
"app:app",
host='0.0.0.0',
port=os.environ.get('PORT', 8000),
log_level=os.environ.get('LOGLEVEL', 'info').lower()
)Instalação das dependências com Pipfile
[[source]]
url = "https://pypi.python.org/simple"
verify_ssl = true
name = "pypi"
[packages]
# test requirements
pytest = "*"
pytest-cov = "*"
pytest-asyncio = "*"
# service requirements
fastapi = "*"
uvicorn = {extras = ["standard"], version = "*"}
gunicorn = "*"
pylint = "*"
# model requirements
scikit-learn = "==1.0"
pandas = "*"
numpy = "*"
[dev-packages]
jupyterlab = "*"
[requires]
python_version = "3.7"Dockerização
FROM python:3.7-slim-buster
RUN mkdir /home/app
WORKDIR /home/app
COPY Pipfile .
COPY Pipfile.lock .
RUN apt-get update \
&& pip install --no-cache-dir pipenv pylint \
&& pipenv install --system --deploy --ignore-pipfile
COPY . .
ENTRYPOINT ["sh", "entrypoint.sh"]
Integração/Entrega Contínua
version: 2.1
orbs:
aws-ecr: circleci/aws-ecr@7.0.0
aws-ecs: circleci/aws-ecs@02.2.1
workflows:
build-and-deploy:
jobs:
- aws-ecr/build-and-push-image:
context: deploy
repo: kaggle-titanic-deploy
tag: "${CIRCLE_SHA1}"
filters:
branches:
only:
- main
- aws-ecs/deploy-service-update:
context: deploy
requires:
- aws-ecr/build-and-push-image
filters:
branches:
only:
- main
family: kaggle-titanic-deploy-task
cluster-name: $ECS_CLUSTER_NAME
container-image-name-updates: "container=kaggle-titanic-deploy,tag=${CIRCLE_SHA1}"
force-new-deployment: true
service-name: kaggle-titanic-deploy-service
É necessário criar o cluster ECS previamente

Fluxo de implantação

E se você tiver muitos modelos?
- Como garantir que os dados em produção são iguais aos de desenvolvimento?
- Duplicação de código
- monitoramento
- Como acessar o histórico de predições?
- Como rastrear o experimento a partir do modelo

Quer saber mais?

Quer saber mais?


Em breve vamos publicar um artigo no Medium da Creditas Tech!
Quer saber mais?

Obrigado! :)
Nossos contatos
Nosso Twitter
Blog sobre Tech
Comunidade no Meetup
Linkedin e Instagram
Vagas
Slides disponíveis em: https://slides.com/vivianmayumiyamassaki/apresentacao_python_brasil_2021
Estamos com vagas abertas!!! 💚
Obrigado! :)
Nossos contatos
Nosso Twitter
Blog sobre Tech
Comunidade no Meetup
Linkedin e Instagram
Vagas
Slides disponíveis em: https://slides.com/vivianmayumiyamassaki/apresentacao_python_brasil_2021