Etapa Avaliativa

Agenda
1
Quem sou eu
2
Classificação vs Regressão
3
KNN
Quem sou eu

Vivian Yamassaki
-
Mestra em Sistemas de Informação pela USP
-
Data Scientist Specialist na Creditas
- Co-organizadora da MIA (Mulheres em Inteligência Artificial)
2
Analista de Business Intelligence
2017
4
Data Scientist Specialist
2019 - até hoje

3
Data Scientist
2018
5
Instrutora em aulas e projetos voluntários




1
Graduação e mestrado em Sistemas de Informação
2017
Linha do tempo
Classificação
vs
Regressão
O universo de Machine Learning
Diagrama retirado do Machine Learning For Everyone
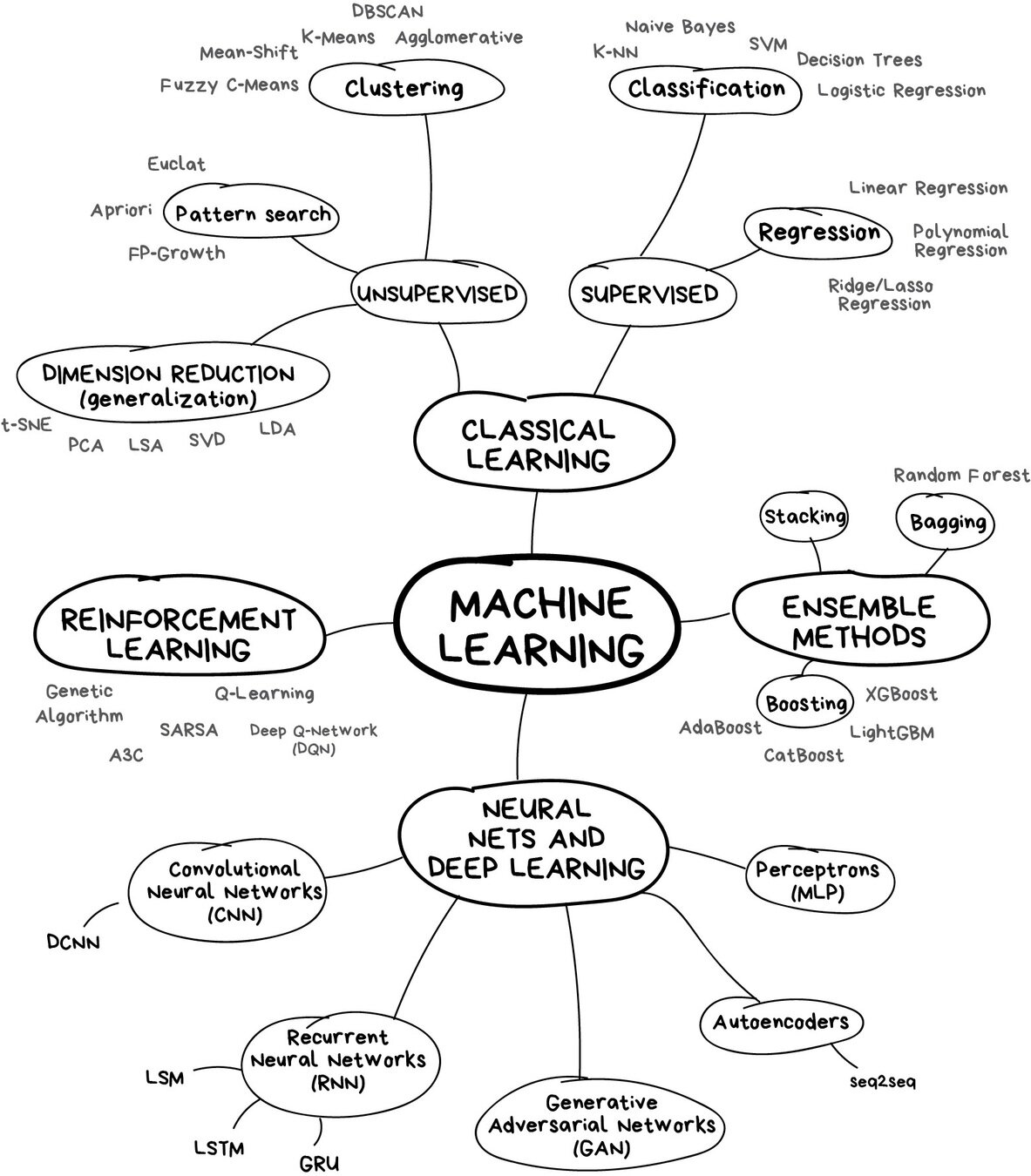
O universo de Machine Learning
Diagrama retirado do Machine Learning For Everyone
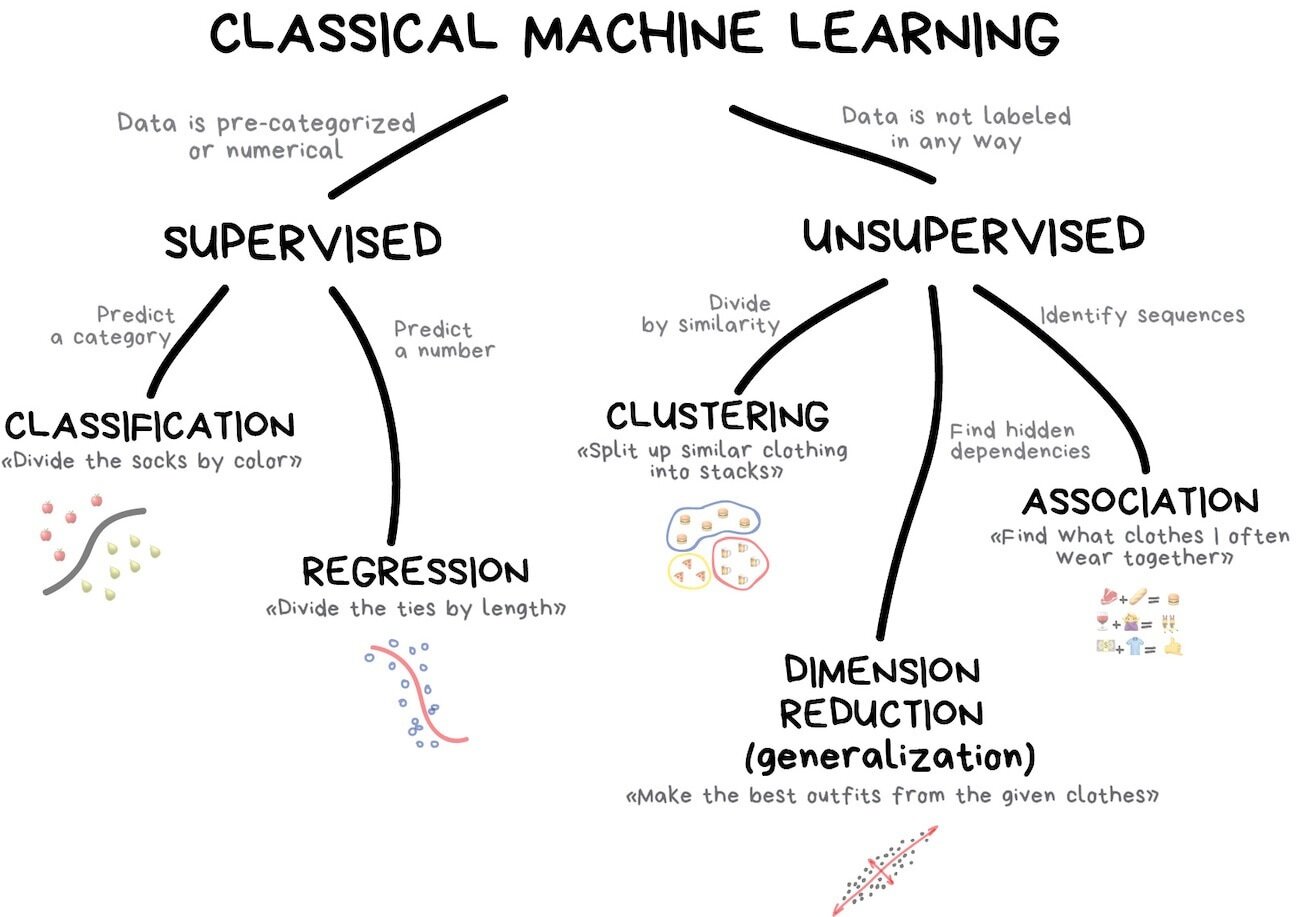
Exemplos
- Se um e-mail é spam ou não
- Se é mau pagador ou não é
Classificação

Regressão
- Predição de valor de um imóvel
- Predição de renda de cliente
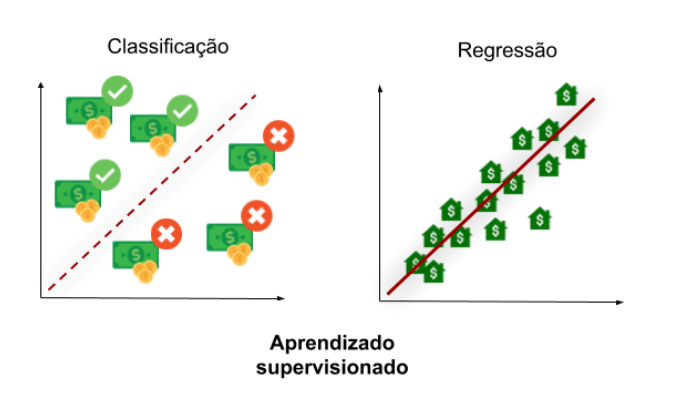
Predizer uma classe/categoria
Predizer um número contínuo
Exemplo
| Idade | Renda | Valor pré-aprovado |
|---|---|---|
| 18 | 1.000 | 2.000 |
| 25 | 2.500 | 3.500 |
| 50 | 4.500 | 4.500 |
| 42 | 10.000 | 20.000 |
| 33 | 6.000 | 8.000 |
Exemplo Regressão
| Idade | Renda |
|---|---|
| 18 | 1.000 |
| 25 | 2.500 |
| 50 | 4.500 |
| 42 | 10.000 |
| 33 | 6.000 |
| Valor pré-aprovado |
|---|
| 2.000 |
| 3.500 |
| 4.500 |
| 20.000 |
| 8.000 |
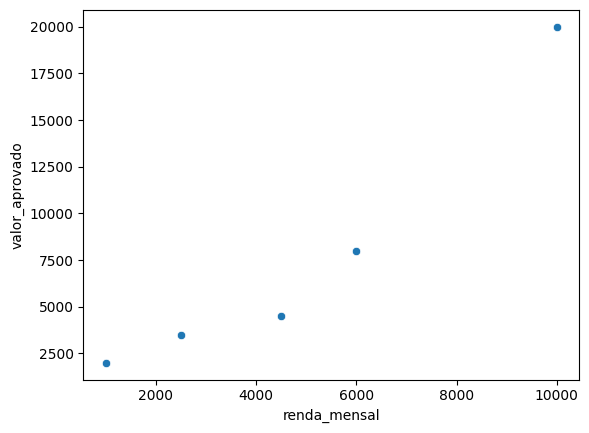
Valor pré-aprovado vs renda mensal
Exemplo Classificação
| Idade | Renda |
|---|---|
| 18 | 1.000 |
| 25 | 2.500 |
| 50 | 4.500 |
| 42 | 10.000 |
| 33 | 6.000 |
| Valor acima de 4k |
|---|
| 0 |
| 0 |
| 1 |
| 1 |
| 1 |
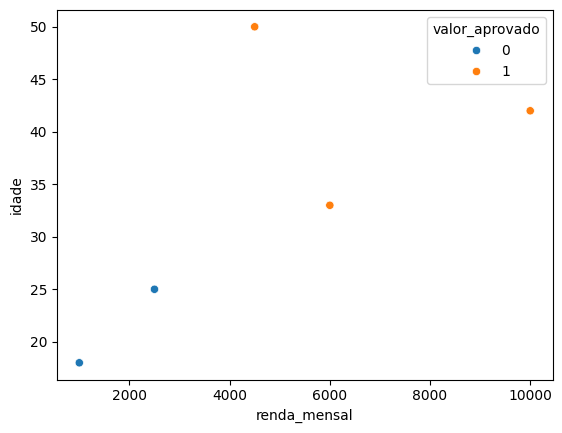
Variáveis vs target de classificação
- Um dos modelos mais simples que existem!
- Não existe, de fato, um treinamento
KNN - K Nearest Neighbors
Como assim não existe treinamento?
Seu aprendizado é, na realidade, apenas o armazenamento dos dados de treinamento!
A predição é feita comparando o novo dado com os k dados de treino mais próximos.
Então, o dado novo é classificado com a classe mais comum entre seus “vizinhos”.
KNN

É definida por uma métrica de distância. A mais comum é a distância Euclidiana:
X1 = (x11,x12, ...,x1n)
X2 = (x21,x22, ...,x2n)
Essa distância é calculada entre o dado novo e todos os dados do conjunto de treinamento.
KNN
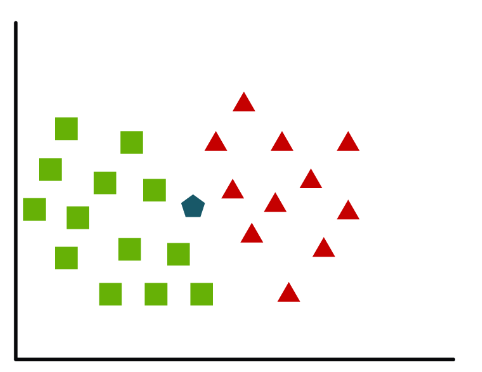
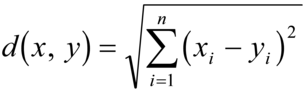
Como sei quais os “vizinhos”?
KNN
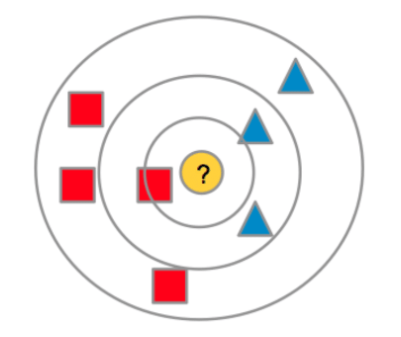
Selecionar os k “vizinhos”: aqueles em que a distância foi menor!
k=1 : Pertence a classe de quadrados
k=3 : Pertence a classe de triângulos
k=7 : Pertence a classe de quadrados
KNN
Mas se pode mudar de classe dependendo de k, como definir k?
Testando vários valores para k!
Usamos o conjunto de teste para avaliar o erro do modelo. O valor de k que der o menor erro é selecionado!
- Simples de entender e explicar
- Poucos parâmetros (k e medida de distância)
Vantagens
Desvantagens
- Muito lento para predições quando o conjunto de dados é muito grande
- Sensível aos outliers