Planet: Understanding the Amazon from Space
Vladimir Iglovikov
Sr. Data Scientist at TrueAccord
PhD in Physics
Kaggle top 100
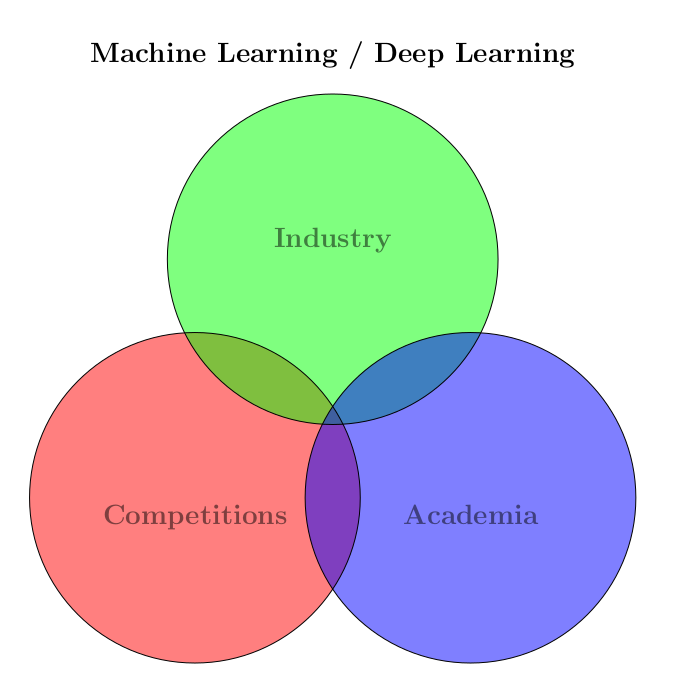
- Industry: interpretability, scalability, size, throughput
- Academia: novelty
- Competitions: accuracy
Team ods.ai
Worked hard
Contributed
Problem description
- Train: 40k images
- Test: 60k images (Public 40k, Private 20k)
Problem description
- Train: 40k images
- Test: 60k images (Public 40k, Private 20k)
- JPG: 3 bands R, G, B 8 bit
- TIF: 4 bands R, G, B, NIR 16 bit
- Resolution (256, 256)
Problem description
- Train: 40k images
- Test: 60k images (Public 40k, Private 20k)
- JPG: 3 bands R, G, B 8 bit
- TIF: 4 bands R, G, B, NIR 16 bit
- Resolution (256, 256)
- Multilabel classification (17 classes)
- Some labels are mutually exclusive.
- Labels based on jpg
Problem description
- Train: 40k images
- Test: 60k images (Public 40k, Private 20k)
- JPG: 3 bands R, G, B 8 bit
- TIF: 4 bands R, G, B, NIR 16 bit
- Resolution (256, 256)
- Multilabel classification (17 classes)
- Some labels are mutually exclusive.
- Labels based on jpg
Metric
Classes


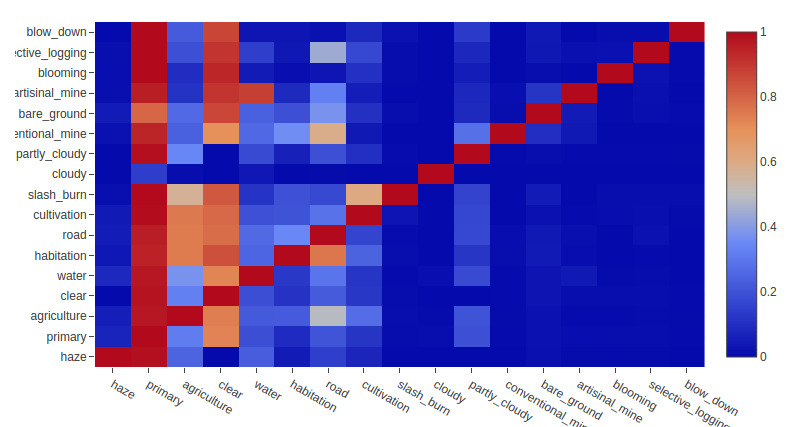
https://www.kaggle.com/anokas/data-exploration-analysis/notebook
Specifics of the data / data leak

- Red: train
- Green: Public test
- Blue: Private test
Way to get => brute force boundary match using L2 distance
- Train 40k
- Stable validation
=>
fight for 0.0001
=>
stacking
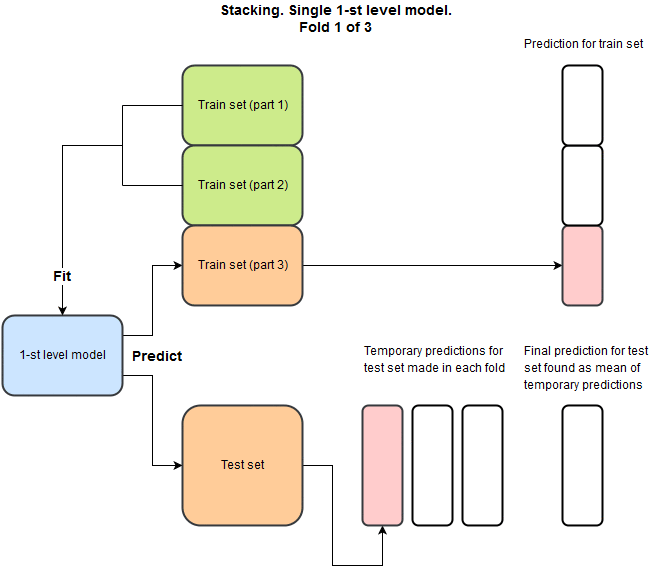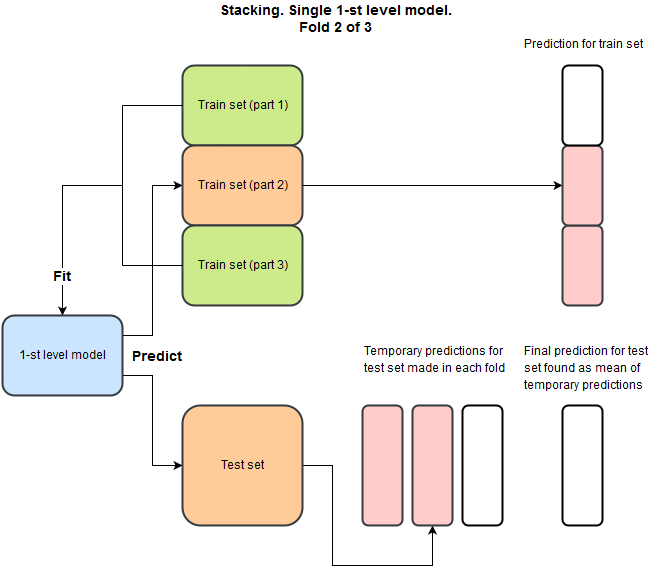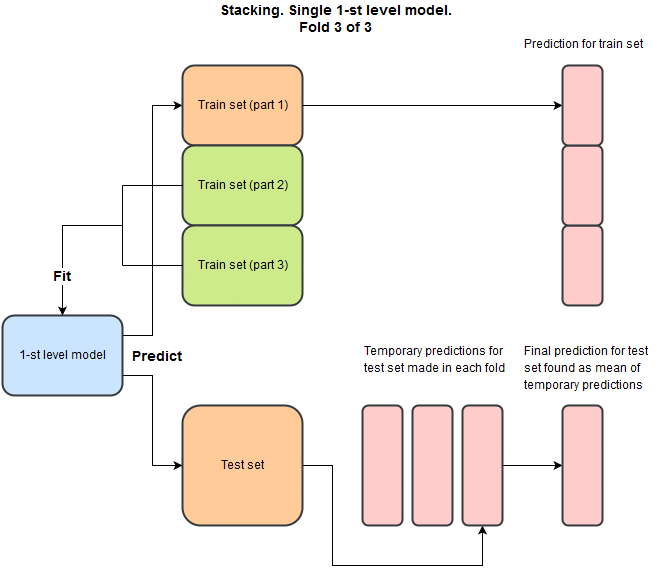
Main idea: building ensemble
Team => set up notation
- Code: Private Repository at GitLab. Folder per person.
- Data: Google drive
- Docs: Google docs / Google sheets
Google Drive => Predictions on train / test per fold in hdf5.
10 Folds
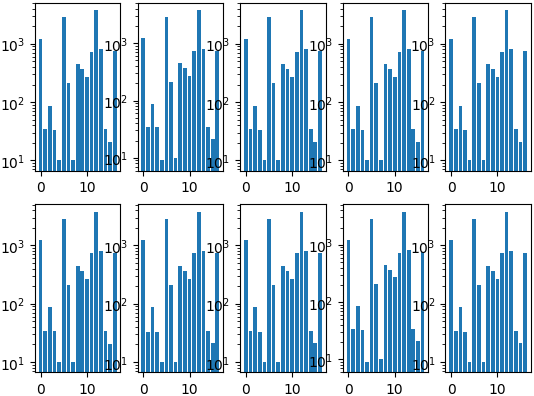
Stratified in a loop starting from the rarest labels
Ways to split into folds:
- KFold
- Stratified KFold
- GridSearch to find good random seed
- More advanced techniques (recall Mercedes problem)
Let's throw models into stacker...
For each model, for each fold we generate prediction on val and test
Architectures
- Densenet 121, 169, 201
- Resnet 34, 50, 101, 152
- ResNext 50, 101
- VGG 11, 13, 16, 19
- DPN 92, 96
Let's throw models into stacker...
For each model, for each fold we generate prediction on val and test
Architectures
- Densenet 121, 169, 201
- Resnet 34, 50, 101, 152
- ResNext 50, 101
- VGG 11, 13, 16, 19
- DPN 92, 96
Initialization
- From scratch
- ImageNet
- ImageNet 11k + Places 365
Let's throw models into stacker...
For each model, for each fold we generate prediction on val and test
Architectures
- Densenet 121, 169, 201
- Resnet 34, 50, 101, 152
- ResNext 50, 101
- VGG 11, 13, 16, 19
- DPN 92, 96
Initialization
- From scratch
- ImageNet
- ImageNet 11k + Places 365
Loss
- binary_crossentropy
- bce - log(F2_approximation)
- softmax(weather) + bce(other)
Let's throw models into stacker...
For each model, for each fold we generate prediction on val and test
Architectures
- Densenet 121, 169, 201
- Resnet 34, 50, 101, 152
- ResNext 50, 101
- VGG 11, 13, 16, 19
- DPN 92, 96
Initialization
- From scratch
- ImageNet
- ImageNet 11k + Places 365
Loss
- binary_crossentropy
- bce - log(F2_approximation)
- softmax(weather) + bce(other)
Training
- Freezing / non-freezing weights
- Different lr schedule
- Optimizers Adam, SGD
- Keras, PyTorch, MXNet
Augmentations
- Flips
- Rotations + Reflect
- Shear
- Scale
- Contrast
- Blur
- Channel multiplier
- Channel add
numpy + ImgAug + OpenCV

https://github.com/aleju/imgaug
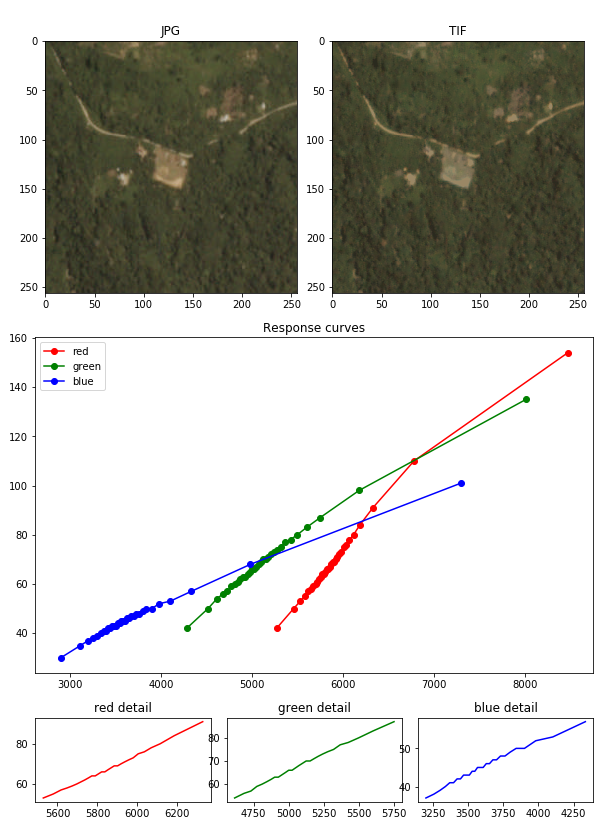
What about Tiff?
- Labels based on JPG
- JPG carry enough information
- Shifts between JPG and TIFF
- All networks pre-trained on 8 bit
It is still possible to get 0.93+ on Tiff.
https://www.kaggle.com/bguberfain/tif-to-jpg-by-matching-percentiles
- TIFF (RGB + N) => NGB
- Percentile matching
General pipeline
48 networks
*
10 folds
=
480 networks
ExtraTrees
NN
Weighted
average
Threasholding
LR
Mean
Model importance (xgb)
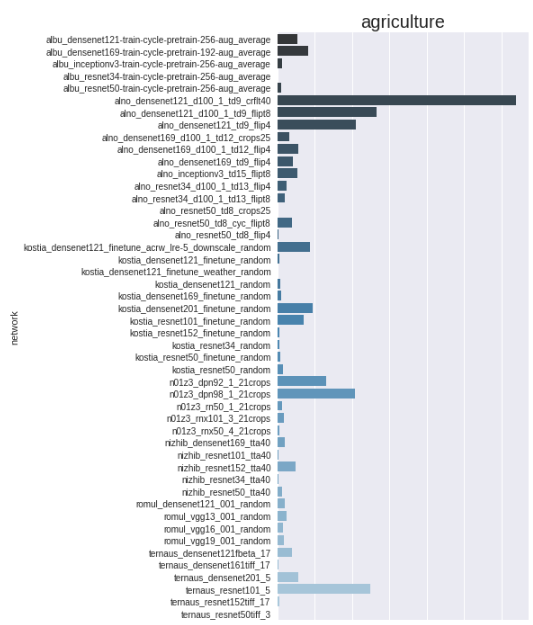
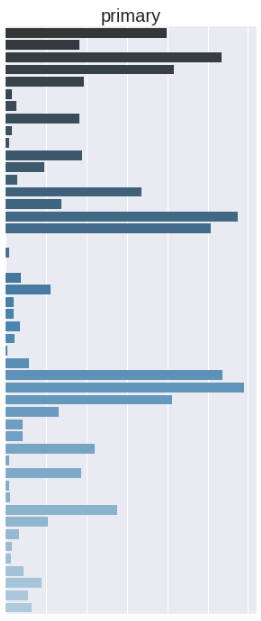
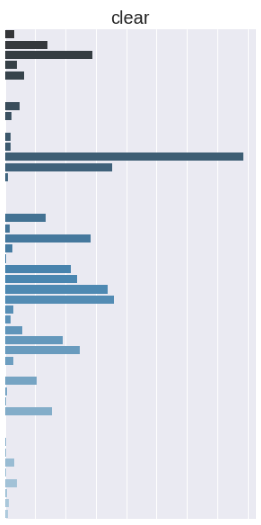

Manual Review
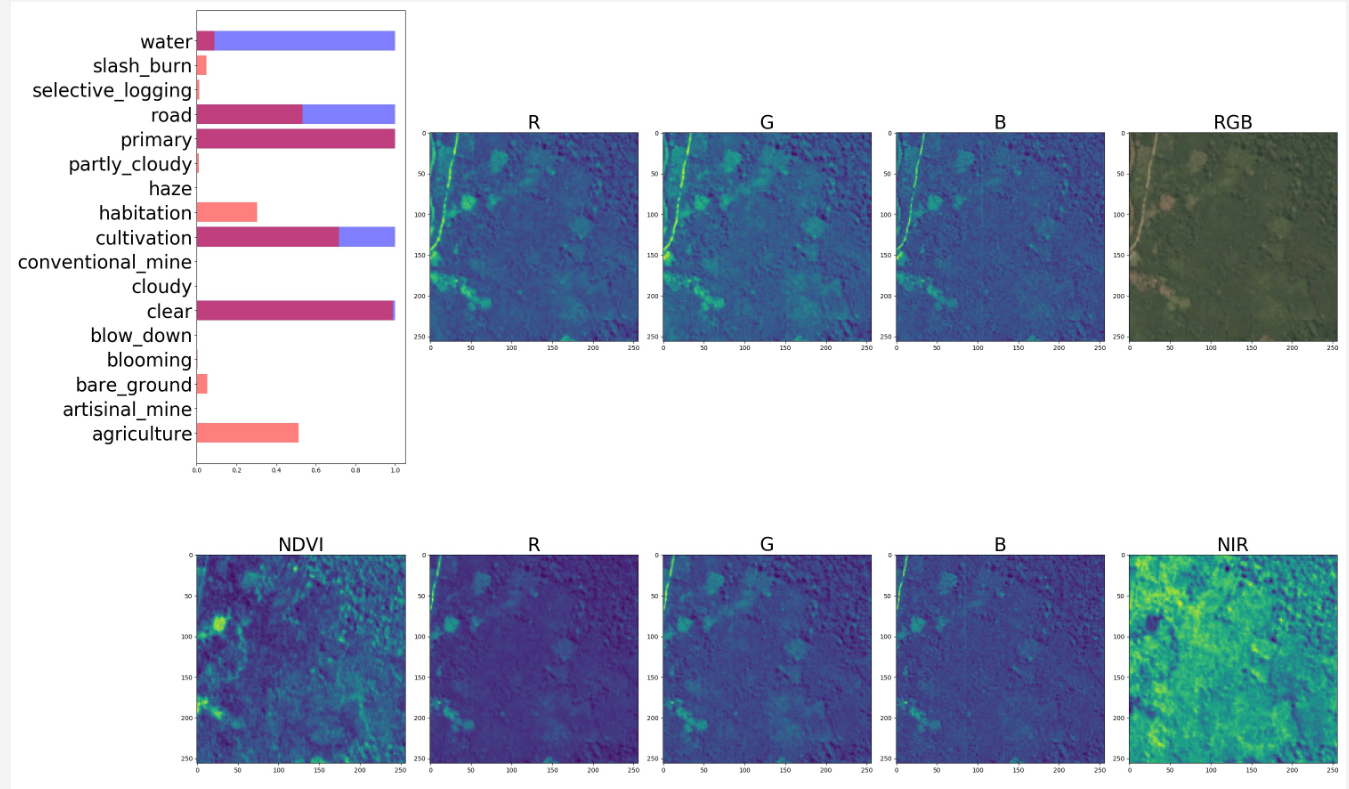
Thresholding
- Gives a lot.
- Different class thresholds depend on each other
- Weather hack (if cloudy => lower other)
Worked the best:
On the Bayes-optimality of F-measure maximizers
https://arxiv.org/abs/1310.4849
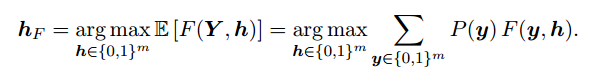
Did not work
- Tiff
- indices (NDWI, EVI, SAVI, etc)
- Fbeta loss
- Two headed networks (weather + softmax, bce for the rest)
- Dehazing
- Mosaic features
Summary
- Three weeks
- ~20 GPUs
- 480 Networks
- 7th Place
Q: How many networks do we need to make it a product?
A: One.
Thank you. Let's stay in touch!
- LinkedIn: https://www.linkedin.com/in/iglovikov/
- GitHub: https://github.com/ternaus
- Kaggle: https://www.kaggle.com/iglovikov
- Twitter: https://twitter.com/viglovikov
- Google Scholar: https://scholar.google.com/citations?user=vkjh9X0AAAAJ&hl=en&authuser=1