Сегментация и детекция
Владимир Игловиков
Classification


Cat (0.99)
Dog(0.01)
Segmentation

- Сегментация = попиксельная классификация
- Не требует большого объема тренировочных данных.
- Все сегментационные сети - это архитектуры вида FCN.
Segmentation: Metric
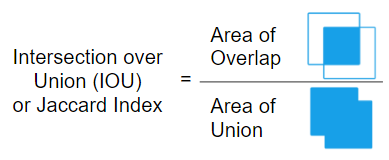

Чаще всего используют Dice - особенно в медицинских снимках
и Jaccard (IoU)
Fully Convolutional Network: FCN

- Оторвать Dense слой, или Dense => Conv.
- В сети мало параметров.
- Берет на вход картинки любого размера.
Jonathan Long, Evan Shelhamer, Trevor Darrell; The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015, pp. 3431-3440
FCN = Efficient Sliding Window


Classification to Segmentation

- Оторвать Dense или Dense => Conv
- Добавить декодер
Jonathan Long, Evan Shelhamer, Trevor Darrell; The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015, pp. 3431-3440
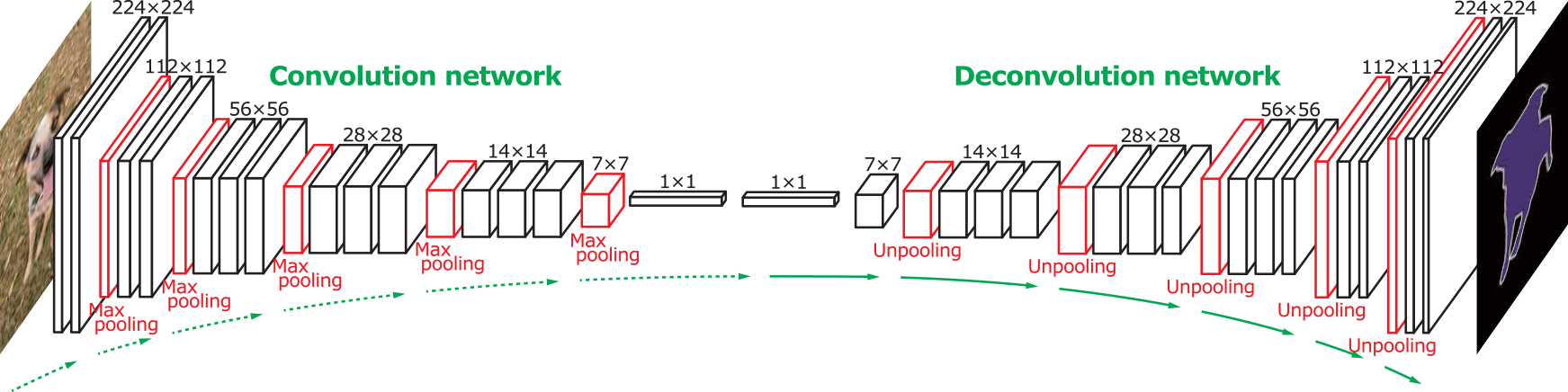
FCN8 to SegNet

FCN8
SegNet
Заменить Upsampling на иерархический Upsampling
V. Badrinarayanan, A. Kendall, and R. Cipolla, “Segnet: A deep convolutional encoder-decoder architecture for image segmentation,” arXiv:1511.00561, 2015
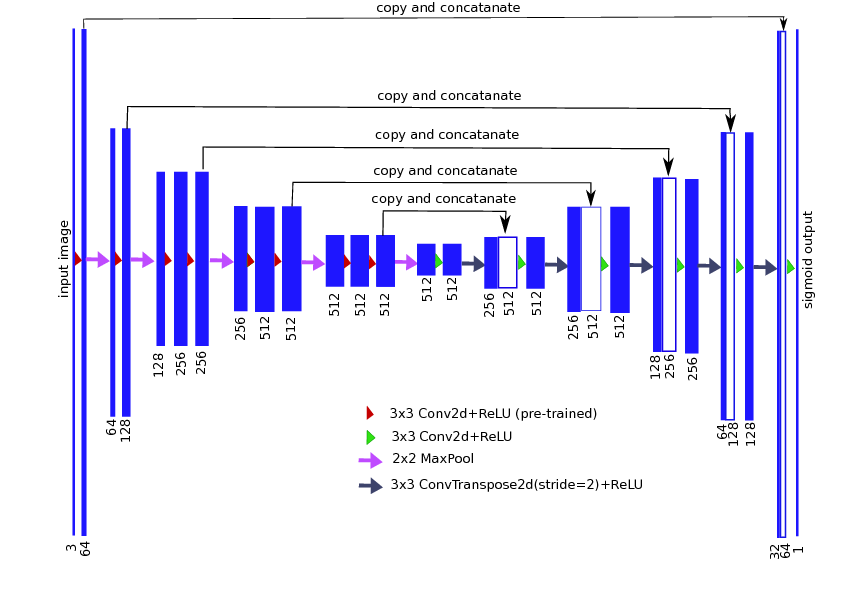
SegNet to UNet
SegNet
UNet
Added skip connections

O. Ronneberger P. Fischer T. Brox "U-net: Convolutional networks for biomedical image segmentation" Proc. Med. Image Comput. Comput.-Assisted Intervention pp. 234-241 2015.
UNet => TernausNet
Text
Iglovikov, V., Shvets, A.: Ternausnet: U-net with vgg11 encoder pre-trained on imagenet for image segmentation. arXiv preprint arXiv:1801.05746 (2018)
Энкодер инициализируем весами с ImageNet
Any binary Image Segmentation => UNet


Medical Imaging


Satellite Imaging
Feature Pyramid Networks (FPN)

- Легко добавить во многие архитектуры.
- Помогает с multiscale
Tsung-Yi Lin, Piotr Dollar, Ross Girshick, Kaiming He, Bharath Hariharan, Serge Belongie; The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 2117-2125
U-Net + FPN

Segmentation Loss Function
Каждый пиксель классификатор => Categorical / Binary Cross Entropy(CCE, BCE)
Но! Метрика Dice / Jaccard
Dice / Jaccard недифференцируемы =>
Soft Dice / Soft Jaccard
и добавляем в loss

Lovasz-Softmax loss
Использовать для FineTune
Berman, M., Rannen Triki, A., Blaschko, M.B.: The lovász-softmax loss: a tractable surrogate for the optimization of the intersection-over-union measure in neural networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4413–4421 (2018)
Detection

Предсказываем:
- координаты боксов
- класс
- опционально атрибуты
Detection Metric: mAP

Метрика крайне замороченная.
Нужно свести в одно число:
- Точность бокса
- Confidence класса
Для каждого класса:
- Хотим получить Precision Recall Curve.
- Цикл по трешходам confidence.
- Трешхолд по IOU => TP, FP, FN
- mAP = area under PR Curve
Non Maximum Supression (NMS)
Detection = Предсказываем много боксов, а потом фильтруем


Detection
One-shot (быстрые)
YOLO, SSD, RetinaNet,
SqueezeNet, DetectNet
Two-shot (точные)
R-FCN, Fast RCNN, Faster-RCNN

One shot detectors

Для каждой ячейки в последнем conv слое предказываем координаты бокса и класс объекта с центром в ячейке.
One shot detectors: YOLO
Для каждой ячейки в последнем conv слое предказываем координаты бокса и класс объекта с центром в ячейке.

One shot detector with FPN = SSD

| mAP | FPS | |
|---|---|---|
| YOLO v2 | 21.6 | 91 |
| SSD | 28.0 | 59 |
Two shot: R-CNN


R-CNN = Selective Search
+ Classification
Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik; The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014, pp. 580-587
Two shot: Fast-RCNN


R-CNN => Fast R-CNN
Меняем порядок Crop и ConvNet
50 секунд => 2 секунды (25 раз быстрее)
Fast => Faster
Fast R-CNN => Faster R-CNN
Вычисляем proposals самой сетью.
2 секунды => 0.2 секунды (10 раз быстрее)

Two shot: performance

Improvements
- Тяжелые backbones
- FPN
- ROI Pooling => ROI Align
- Аугментации
| Backbone | FPN | mAP |
|---|---|---|
| ResNet 50 | No | 34.8 |
| ResNet 50 | Yes | 36.8 |
| ResNet 101 | Yes | 39.1 |
| ResNext 101 | Yes | 41.2 |