#Top3Hadoop
Agenda
-
¿Qué es hadoop?
-
Principales proyectos
- ¿Porqué existen varias distribuciones?
- Ecosistema.
- Empresas asociadas.
- Herramientas desarrolladas.
- Ecosistema.
- Empresas asociadas.
- Herramientas desarrolladas.
- Ecosistema.
- Empresas asociadas.
- Herramientas desarrolladas.
¿Qué es hadoop?
Es un proyecto de desarrollo, con código abierto, de computación:
- Tolerante a fallos.
- Escalable.
- Distribuida.
Apache™ Hadoop®
Principales proyectos
- Hadoop Common
- Hadoop Distributed File System (HDFS™)
- Hadoop YARN
- Hadoop MapReduce
Otros proyectos asociados a hadoop:



¿Porqué existen varias distribuciones?
- Plataformas de proyectos código-abierto.
- Soporte técnico.
- Entrenamientos.

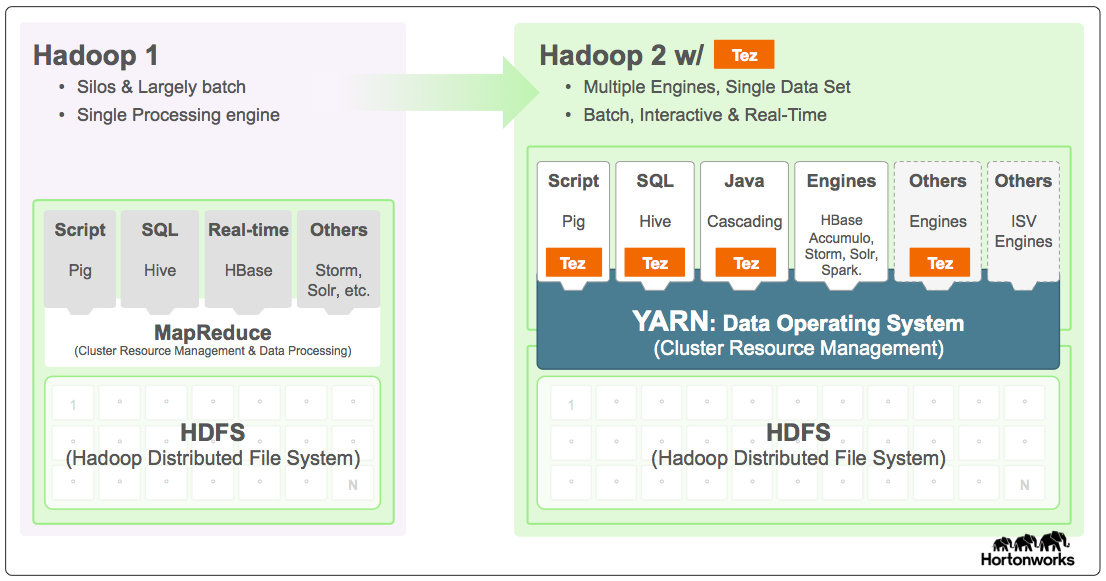
Ecosistema
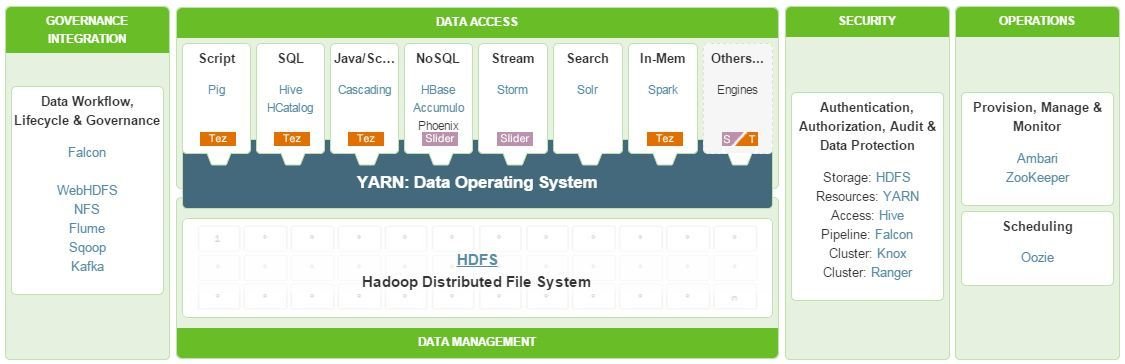
Herramientas desarrolladas
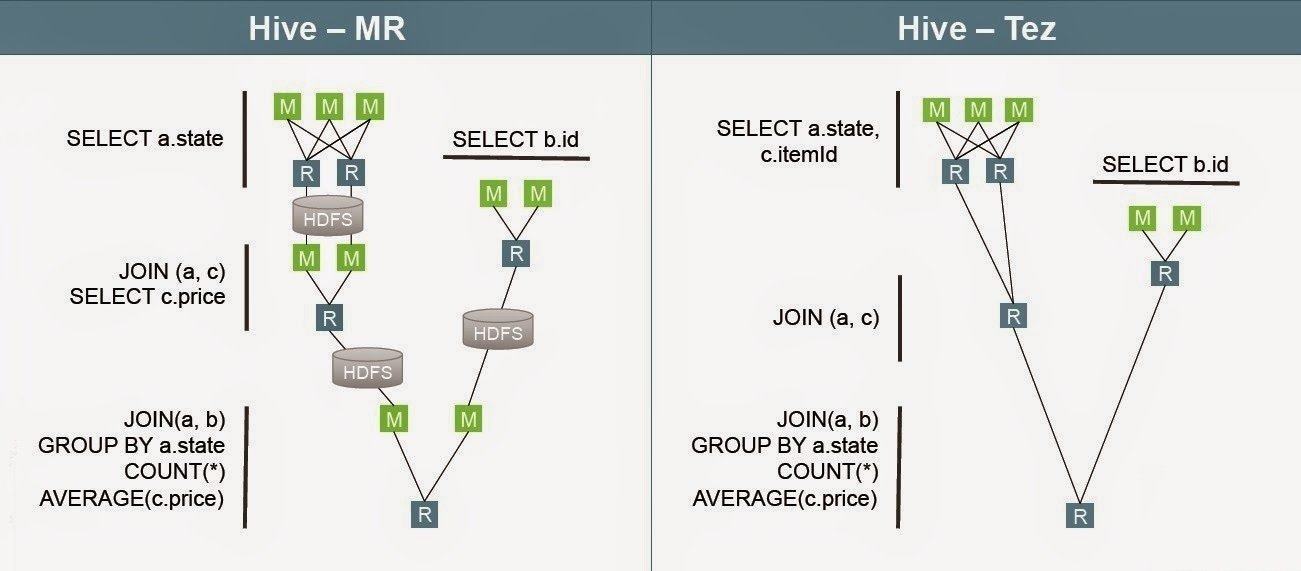
Framework para la construcción de aplicaciones de procesamiento de datos batch e interactivas de alto rendimiento. Tez mejora el paradigma MapReduce.

-
Generaliza el paradigma MapReduce para ejecutar un DAG de tareas.
-
Dataflow definition API. Permite modelar (construir) el plan de ejecución en forma de grafo.
Vértices: Entrada - Procesamiento - Salida
Aristas: Movimiento de los datos
- Runtime API. Reconfigura dinámicamente el grafo de ejecución.
- Óptimo manejo de los recursos.
Framework para la gestión y despliegue de aplicaciones de acceso a los datos 'long-running'. [Aplicaciones YARN Dinámicas].

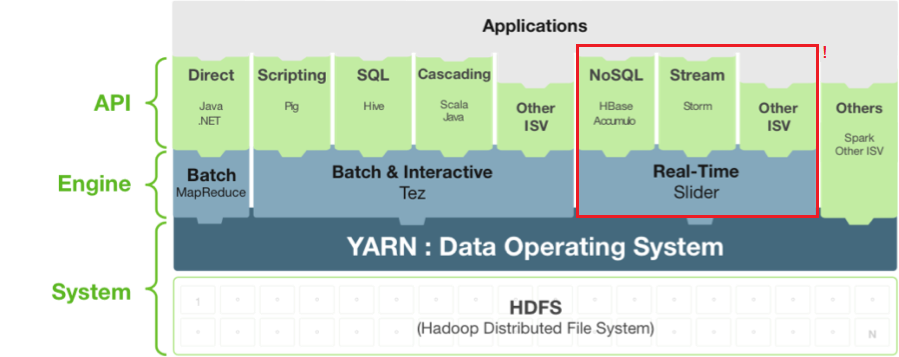
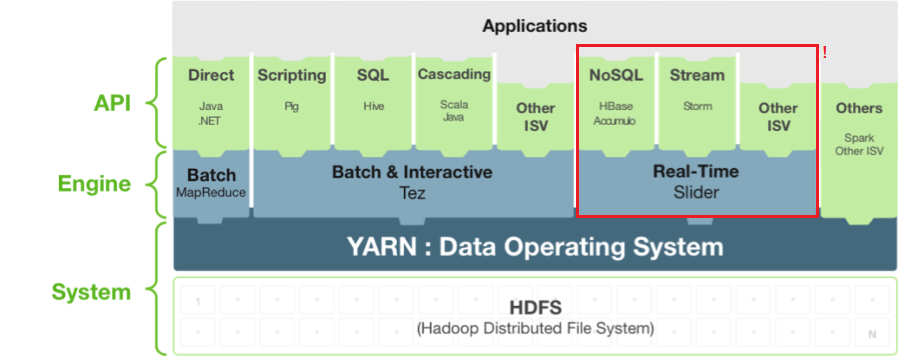
"Complementa a Apache Tez permitiendo que aplicaciones long-running y servicios en tiempo real se integren fácilmente al ecosistema Hadoop"
-
Agregar aplicaciones bajo demanda en un cluster YARN.
-
Ejecutar diferentes versiones de una aplicación.
-
Ejecutar diferentes instancias de una aplicación.
-
Detener, suspender y reanudar instancias de aplicación.
-
Ampliar / reducir instancias de aplicación, según sea necesario.
Permite:
Skin SQL para HBase. Utiliza las API's estándar de JDBC en lugar de las de HBase para crear tablas, insertar y consultar datos.

- Provee una interfaz SQL para manejar datos en HBase.
- Permite crear tablas, insertar y modificar datos con mayor performance.
- Ofrece una forma rápida y fácil de construir aplicaciones en HBase.
- NO es para trabajar con queries que involucren grandes joins o características avanzadas de SQL.
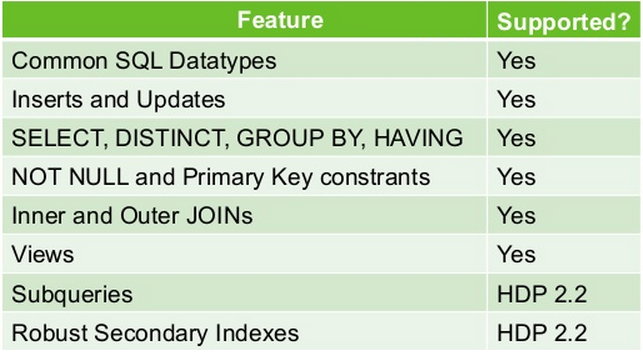

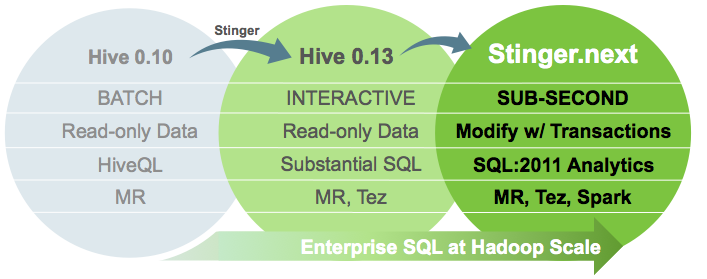
Hive es el estándar de facto para SQL en hadoop. Stinger.next es una iniciativa para evolucionar Hive y proveer SQL empresarial en escala hadoop.

Empresas asociadas

Ecosistema
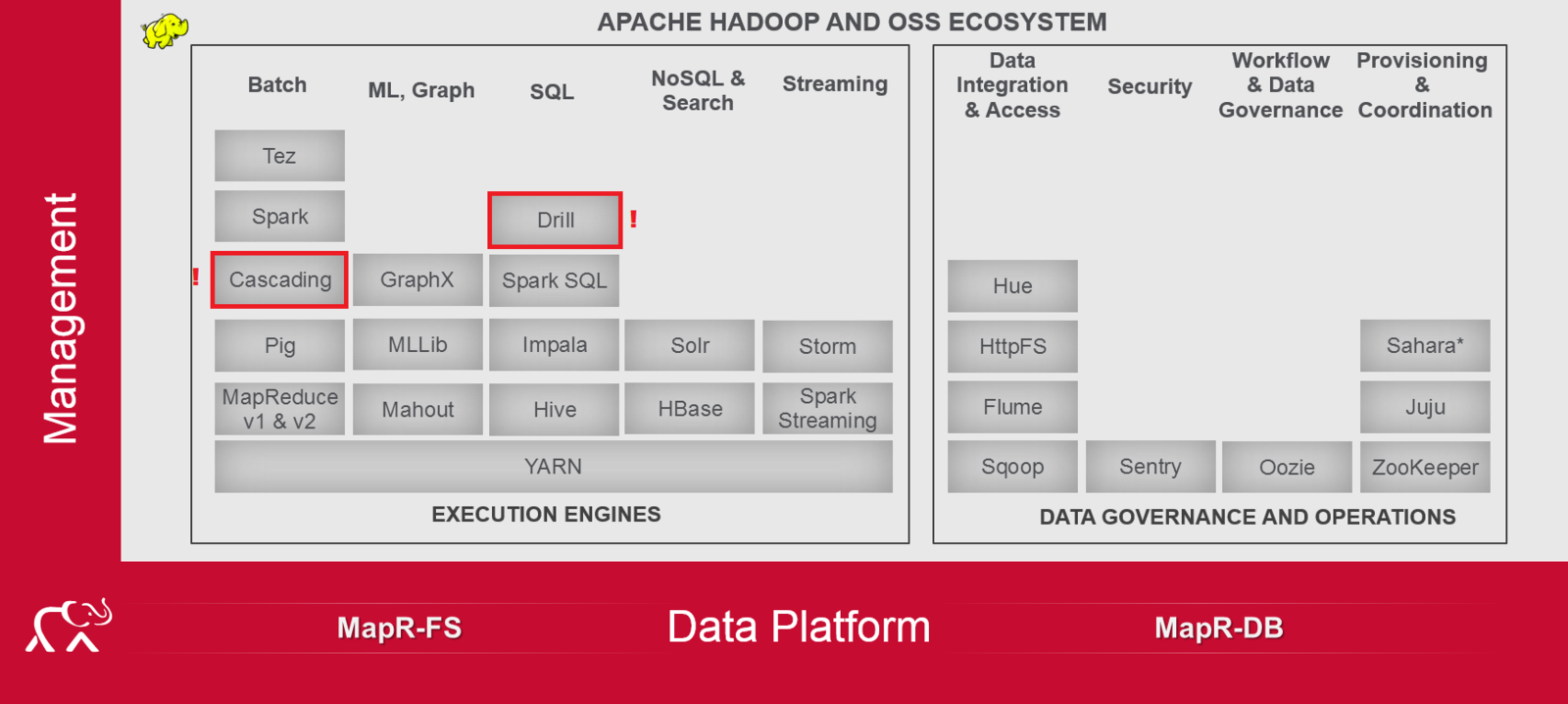
Herramientas desarrolladas

Es un motor de consultas distribuida de baja latencia para conjuntos de datos a gran escala, incluyendo datos estructurados y semi-estructurados / anidados. Se caracteriza por:
- Ha sido diseñado para escalar a varios miles de nodos y petabytes de consulta de datos.
- Posee a Drillbit como responsable de aceptar las peticiones de los clientes, procesamiento de consultas y provisión de resultados al cliente.
Empresas asociadas


Ecosistema
Desarrollo
- Implementa un motor de consultas distribuido.
- Admite consultas en tiempo-real(o por lotes).
- Más rápido que Hive dependiendo el tipo de consulta.
Impala
- Dado que las consultas son locales se evitan los cuellos de botella.
- Un único, abierto y unificado almacén de meta-datos.
- Conversión de formatos de los datos es innecesaria.
Impala
- Consultas Google-like en HDFS y HBase.
- Consultas orientadas a texto.
- Amigable al usuario.
- Casi tiempo-real(near real-time).
- Actualizaciones dinámicas de indexación.
- Admite estructura de datos mixtas.
- Implementa el API estándar de Solr.
- Trabaja sobre HDFS y HBase.
- Implementa trabajos de MapReduce para la indexación.
- Interactúa directamente con la data indexada en Flume.



- Spark SQL.
- Spark Streaming.
- MLlib (machine learning).
- GraphX.
Es un motor rápido y general para el procesamiento de datos a gran escala, usando:

Admite SQL con programas Spark
Admite consultas a diversas fuentes de datos (Hive tables, JSON, etc)
Compatible con HiveQL
Estándar de compatibilidad ODBC

Streaming, batch and interactive.
Tolerancia a fallos de estado y operadores sin código adicional.
Soporta Scala, Python y Java.
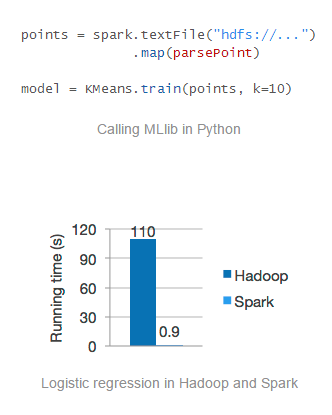

Visualización de datos en gráficos o colecciones
- Compatible con cualquier tecnología basada en hadoop.
- Gestiona de flujos de trabajo con Oozie.
- Gestiona trabajos de Impala, Hive.
- Corre sobre el browser y no requiere instalación desde el cliente .
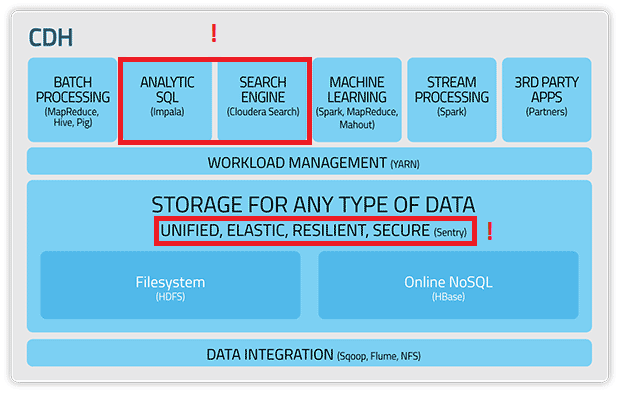
Es un conjunto de aplicaciones web que interactúan con CDH (Cloudera Data Hub):



- Administración basada en roles.
- Clasificación de datos.
- Aplicaciones multi-usuarios.
- Control de acceso de grano fino.
Es un módulo de seguridad que gestiona el acceso a la mayoría de herramientas SQL y de BI, posee las siguientes características:
- Permite auditar de forma unificada a través de hadoop.
- Incluye cifrado integral y gestión de claves.
- Audita eventos como: IP, objetos accedidos, usuarios, servicios, timestamp, entre otros.
Es una herramienta de gestión de datos integrada de manera nativa con hadoop, posee las siguientes características:
Navigator


Empresas asociadas

Conclusiones

- Única plataforma 100% open-source. Única distribución que corre en Windows.
- Crearon su propio sistema de archivos distribuido (MapR-FS). Han demostrado mayor eficiencia y escalabilidad.
- Es la plataforma más madura. Han añadido componentes al ecosistema Hadoop de gran importancia como Impala y Cloudera Search.
Conclusiones
La mejor forma de aprender Hadoop = SANDBOX !

www.hortonworks.com www.mapr.com www.cloudera.com
