디비 튜닝 기초
YSM 사내 교육 자료
검색팀 송원석

이 자료는 전문적이지 못합니다.
최대한 특정 디비가 아니라 전반적인 RDB내용을
담으려고 했습니다.
틀린점은 언제든지 지적 해주세요.
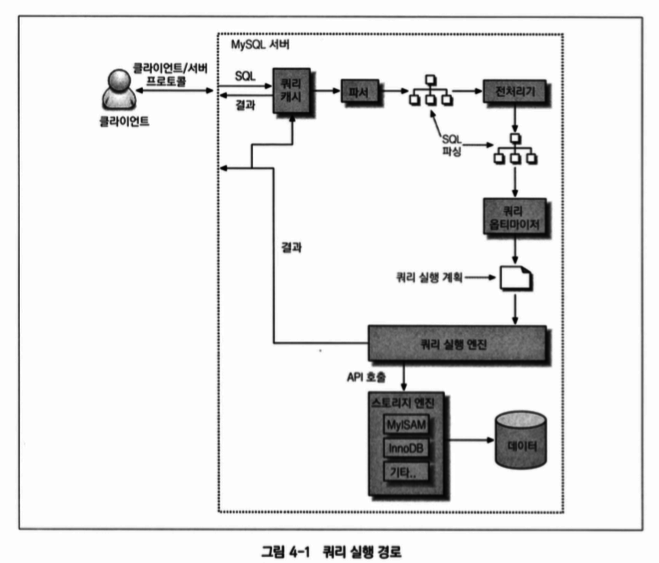
Basic Query Tune
컬럼명을 명시하자
필드명을 명시하지 않으면 DB는 스키마 정보를 얻기위해 추가 SCHEMA테이블을 참조한다.
SELECT * FROM DUAL -- (X)
SELECT id, name FROM DUAL -- (O)WHERE 조건을 가공하지 마라
컬럼 데이터를 연산해서 조건을 거는 경우 인덱스를 탈 수 없다.
다만 오라클은 함수기반인덱스로 우회 가능
SELECT
NAME
FROM
DUAL
WHERE
(COUNT * 2) >= 10 -- (x)
----------------------------
SELECT
NAME
FROM
DUAL
WHERE
DOUBLE_COUNT >= 10 -- (O)NOT조건은 가급적 사용하지 마라
NOT (!= ,<>, NOT IN, NOT EXISTS)조건을 걸면
인덱스 컬럼이어도 조건이 아닌 데이터들을 모두 스캔해봐야 하기 때문에
인덱스를 타기 어렵다.
가변적으로 코드가 늘어나지 않는다면 IN조건을 사용하자
SELECT
NAME
FROM
DUAL
WHERE
CODE_TYPE <> 'A' --(X)
----------------------------
SELECT
NAME
FROM
DUAL
WHERE
CODE_TYPE IN ('B','C','D') -- (O)LIKE는 가급적 뒤에 걸자
앞에 %를 걸면 처음에 어떤 단어가 앞에 올지 모르기 때문에
DB는 전체 모든 테이블 데이터를 스캔한다.
그렇다고 모든 쿼리를 바꾸지 말고 상황을 보고 바꾸자.
(로직상 당연히 필요한데 느리다고 빼버리면 안돼요)
SELECT
NAME
FROM
DUAL
WHERE
ID LIKE CONCAT('%','silvernine', '%') --(X)
----------------------------
SELECT
NAME
FROM
DUAL
WHERE
ID LIKE CONCAT('silvernine','%') -- (O)데이터 존재유무 체크시 EXISTS를 사용하자
COUNT 구문은 조건에 맞는 모든 row를 전부 읽는다.
EXISTS를 쓰면 체크하는 row수가 절감된다.
(mysql은 별로 차이 없는거 같은게 함정..)
SELECT
(SELECT COUNT(*) FROM T_CATE_DEALS B WEHRE B.DID = A.DID) CATE_USE
FROM
T_DEALS A -- (X)
----------------------------
SELECT
EXISTS(SELECT 1 FROM T_CATE_DEALS B WEHRE B.DID = A.DID) CATE_USE
FROM
T_DEALS A -- (O)DISTINCT 함부로 쓰지 말자
DISTINCT는 FULL SCAN의 주범이다. (중복이 얼마나 있는지 다 찾아야하니)
단순 JOIN 중복제거의 목적이면 조건절로 걸러내거나 subquery, semi join
등을 이용하자.
SELECT
DISTINCT A.DID, B.DID AS CATE_DID
FROM
T_DEALS A INNER JOIN B T_CATE_DEALS --(X)
----------------------------
SELECT
A.DID,
(SELECT B.DID FROM
T_CATE_DEALS B
WHERE B.DID = A.DID LIMIT 1) AS CATE_DID
FROM
T_DEALS A -- (O)
----------------------------
SELECT
A.DID
FROM
T_DEALS A
WHERE
A.DID IN (SELECT DID FROM T_CATE_DEALS)Subquery보다는 join으로
일반적으로 dependent subquery (scalar subquery)
보다는 join이 더 빠른것으로 인지되나
case by case 일 수 있으므로
실행계획을 참조하는것이 좋습니다.
view는 신중히 사용하자
view는 단순히 쿼리를 미리 저장해놓은 개념
view에 명시된 조건은 무조건 쿼리 실행시 시행됨.
application관점으로 필요치 않은 view조건이 호출될 수 있음.
view에 명시된 조건과 추가로 select view로 넣은 조건이 Optimize안될 수 있음
Oracle은 Material View를 이용해 view형식으로 데이터를 따로저장해 퍼포먼스 향상가능
실행계획을 보자
같은 쿼리라도 통계 데이터와 옵티마이저에 의해서 다른 결과가 나올수도 있음
그리고 기존에 알던 정보가 DB가 버전업이 되면서 다르게 동작하는 케이스도 있음
그러므로 인터넷 그냥 믿지 마시고 무조건 직접! 실행계획 보는것은 필수
Join
Nested Loop Join
- NL Join, 우리말로 중첩된 루프 조인
- 일반적인 Join 수행 방식 이라면 이것을 의미
- Random Access 기반 Join방식
- Mysql은 이 방식밖에 없음. (이었으나 최근 버전엔 좀 더 다양한 알고리즘을 지원)
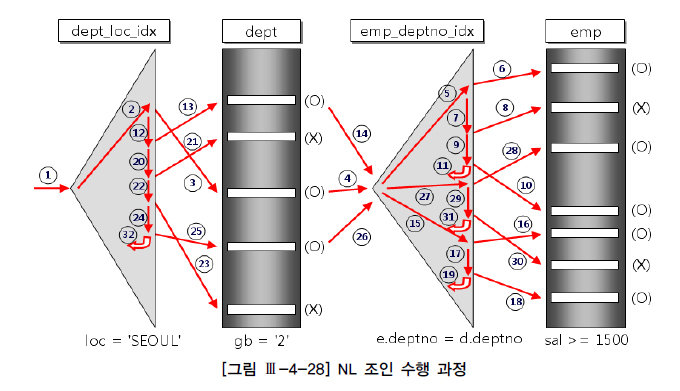
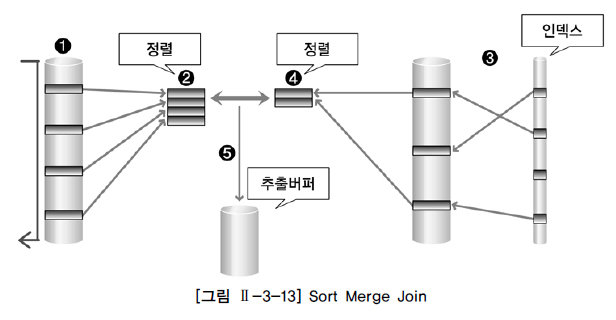
Sort merge Join
Join 컬럼을 기준으로 데이터 정렬후 수행
전체 범위 처리 유리
Mysql은 아직 지원 안하는듯(?)
Hash Join
Join 컬럼을 별도의 hash set을 생성하여 join
대용량 처리 유리
mysql에는 block nested loop hash이라는 명칭으로 최근에 추가됨
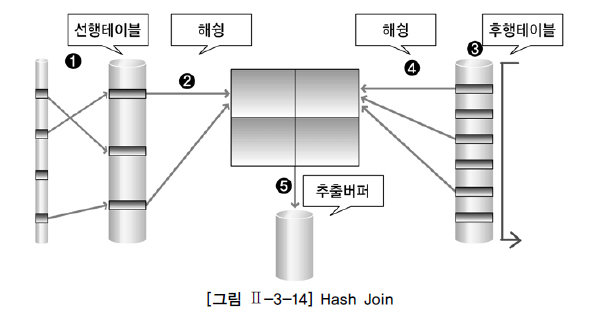
양컬럼에 인덱스가 모두 있는지 확인해본다.
FK(Foreign Key)는 인덱스가 아님. (중요)
그냥 A테이블 B테이블 모두 잘 정렬 돼있어야 좋은 퍼포먼스가 나옴
Join 하는 컬럼의 schema는 같아야 한다.
data Type, length, charset
mysql의 경우 Storage engine 부터 collation까지 모두!!
Join 순서는 매우 중요하다.
- Join순서에 따라서 데이터를 얼마만큼 연산하냐가 틀려질 수 있음
- 일반적으로 Join Optimizer가 판단하여 적절히 Join순서를 결정하나 이상한 판단을 내릴때가 있음 (통계 때문에)
- Mysql의 경우 STRAIGHT_JOIN 힌트를 이용해서 명시한 순서대로 JOIN을 하게 설정 가능
JDBC
Prepared Statement를 사용
- db에서 사용할 조건과 전송할 컬럼을 미리 알고 있으면 빠르게 값을 리턴할 수 있다.
- mybatis등에서 $구문을 사용하지 않으면 Pstmt로 동작한다.
- Pstmt로 작성하면 SQL Injection등의 공격에 대비할수도 있다.
대용량 데이터 select시 fetchSize조절
Statement.setFetchSize(Integer.MIN_VALUE)
세팅시 data를 stream방식으로 가지고옴
(mysql or mariadb)
Out of memory 조심
myBatis에서는 select tag의 attribute로 fetchSize를 지정 가능
<select id="select" fetchSize="1000">
SELECT * FROM DUAL
</select>대용량 데이터 insert시
jdbc url에
rewriteBatchedStatements=true
설정하면 batch insert시 속도를 향상 시킬 수 있다.
mysql driver와 maria driver가 서로 지원하는 설정값이 틀리다.
(mysql이 지원하는 파라미터가 좀 더 많음)
뭐가 더 낫다고 얘기하긴 어려우니 잘 판단하여 사용합시다.
Slow Query
Monitoring
- slow_query_log config enable
- default가 로깅off기 때문에 설정 enable필요
-
SELECT * FROM mysql.slow_log 혹은 file에 적재
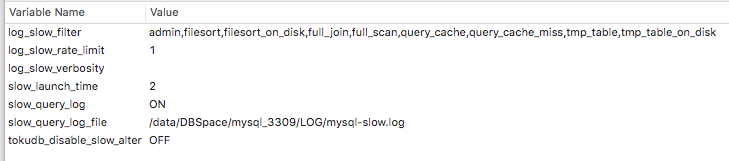
쿠차 테스트DB 슬로우쿼리 설정
Mysql Slow Query
v$sql 혹은 v$sqlarea 에 elapsed_time 컬럼으로 조건을 걸어서 확인 가능
-- 가장 시간이 오래걸린 10개 목록을 가지고오는 쿼리
SELECT * FROM
(SELECT
sql_fulltext,
sql_id,
elapsed_time,
child_number,
disk_reads,
executions,
first_load_time,
last_load_time
FROM v$sql
ORDER BY elapsed_time DESC)
WHERE ROWNUM < 10Oracle Slow Query
MS에서 지원하는 Sql Server Profiler를 이용해 실시간 모니터링 가능
Mssql Slow Query
Explain Plan
쿼리 앞에 explain
EXPLAIN
SELECT * FROM DUALoracle

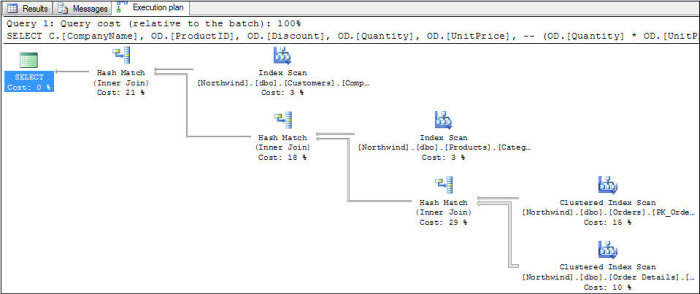
mssql
mysql

① rowid에 의해 단일행 실행
– 가장 빠름
– ROWID 구성 : 6(객체번호:emp) – 3 – 6(블럭주소) – 3(블럭에서 순번)
② cluster-join에 의한 단일행 실행
③ unique-key, primary-key를 사용한 hash-cluster key에 의한 단일행 실행
④ unique-key, primary-key에 의한 단일행 실행
– create unique index pk_emp on big_emp (deptno);
⑤ cluster 조인
⑥ hash-cluster key
⑦ 인덱스화된 cluster-key
⑧ 복합 인덱스
– create index deptno_job_idx on big_emp (job, deptno);
⑨ 단일 컬럼 인덱스(equal)
– create index sal_idx on big_emp (sal);
⑩ 인덱스가 구축된 컬럼에 대한 제한된 범위 검색
– between, like, < and >, = 표현식
– crete index ename_idx on big_emp (ename);
select ename, deptno from big_emp where ename between ‘B%’ and ‘S%’;
⑪ 인덱스가 구축된 컬럼에 대한 무제한 범위의 검색
– >=,=< 표현식
– crete index ename_idx on big_emp (sal);
select ename from big_emp where sal > 3000;
⑫ 정렬-병합 조인
⑬ 인덱스가 구축된 컬럼에 대한 MAX, MIN
⑭ 인덱스가 구축된 컬럼에 대한 ORDER BY
⑮ Full-Table Scan – 가장 느림
Oracle Rule-Based Optimizer
select_type
| SIMPLE | 단순 SELECT (UNION 이나 서브쿼리를 사용하지 않음) |
| PRIMARY | 가장 외곽의 SELECT |
| UNION | UNION 에서의 두번째 혹은 나중에 따라오는 SELECT |
| DEPENDENT UNION | UNION 에서의 두번째 혹은 나중에 따라오는 SELECT, 외곽쿼리에 의존적이다. |
| UNION RESULT | UNION 의 결과물. |
| SUBQUERY | 서브쿼리의 첫번째 SELECT |
| DEPENDENT SUBQUERY | 서브쿼리의 첫번째 SELECT, 외곽쿼리에 의존적이다. |
| DELIVERD | SELECT 로 추출된 테이블 (FROM 절 내부의 서브쿼리) |
| UNCACHEABLE SUBQUERY | |
| UNCACHEABLE UNION | |
| MATERIALIZED | 서브쿼리 임시테이블 조회시 사용 |
| INSERT | INSERT or UPDATE or DELETE 구문 |
type
| system | 테이블에 단 하나의 행만 존재(시스템 테이블). const join 의 특수한 경우이다. |
| const | 많아야 하나의 매치되는 행만 존재하는 경우. 하나의 행이기 때문에 각 컬럼값은 나머지 연산에서 상수로 간주되며, 처음 한번만 읽어들이면 되기 때문에 무지 빠르다. SELECT * FROM tbl_name WHERE primary_key=1; |
| eq_ref | 조인수행을 위해 각 테이블에서 하나씩의 행만이 읽혀지는 형태. const 타입이외에 가장 훌륭한 조인타입이다. SELECT * FROM ref_table,other_table WHERE ref_table.key_column=other_table.column; |
| ref | 이전 테이블과의 조인에 사용될 매치되는 인덱스의 모든행이 이 테이블에서 읽혀진다. (PK or Unique key X) |
| fulltext | mariaDB의 fulltext검색을 사용시 |
| ref_or_null | ref와 같으며 null이 포함된 데이터 참조시 |
| index_merge | 인덱스 병합으로 최적화 적용시 |
type
| unique_subquery |
value IN (SELECT primary_key FROM single_table WHERE some_expr) unique_subquery 는 성능향상을 위해 서브쿼리를 단순 index 검색 함수로 대체한다. |
| index_subquery | unique_subquery와 같으며 non unique사용시 value IN (SELECT key_column FROM single_table WHERE some_expr) |
| range | 인덱스를 사용하여 주어진 범위 내의 행들만 추출된다. key 컬럼은 사용된 인덱스를 나타내고 key_len 는 사용된 가장 긴 key 부분을 나타낸다. ref 컬럼은 이 타입의 조인에서 NULL 이다. range 타입은 키 컬럼이 상수와 =, <>, >, >=, <, <=, IS NULL, <=>,BETWEEN 또는 IN 연산에 사용될때 적용된다. |
| index | index scan. index가 들어갔다고 빠르다고 생각하면 안됨 |
| ALL | TABLE FULL SCAN |
Extra
| using index | 가지고 오는 데이터를 인덱스에서만 가지고 왔다는 표시. 일반적으로 좋은 성능. corverd index라고 불리며 mssql에서는 index lookup으로 부름 |
| using index condition | where조건이 인덱스 조건을 탈 수 있는 경우 |
| using where | 일반적인 조건에서 보여지며 스토리지 엔진에서 읽은 데이터를 필터링으로 버린것을 의미 |
| using temporary | 쿼리 처리시 중간 결과 저장을 위해 임시 테이블을 사용할때보여짐. 임시테이블은 메모리에 생성될수도 있고 디스크에 생성되었을 수도 있음. 일반적으로 derived, union, distinct count시에 보여짐. |
| using filesort | 인덱스를 사용하지 않고 정렬이 될때 나옴. 튜닝 필요. (RDB에서 일반적으로 file이란 단어가 들어가면 느리다고 봐도 무관함) |
extra는 종류가 많아 일부만 명시합니다.
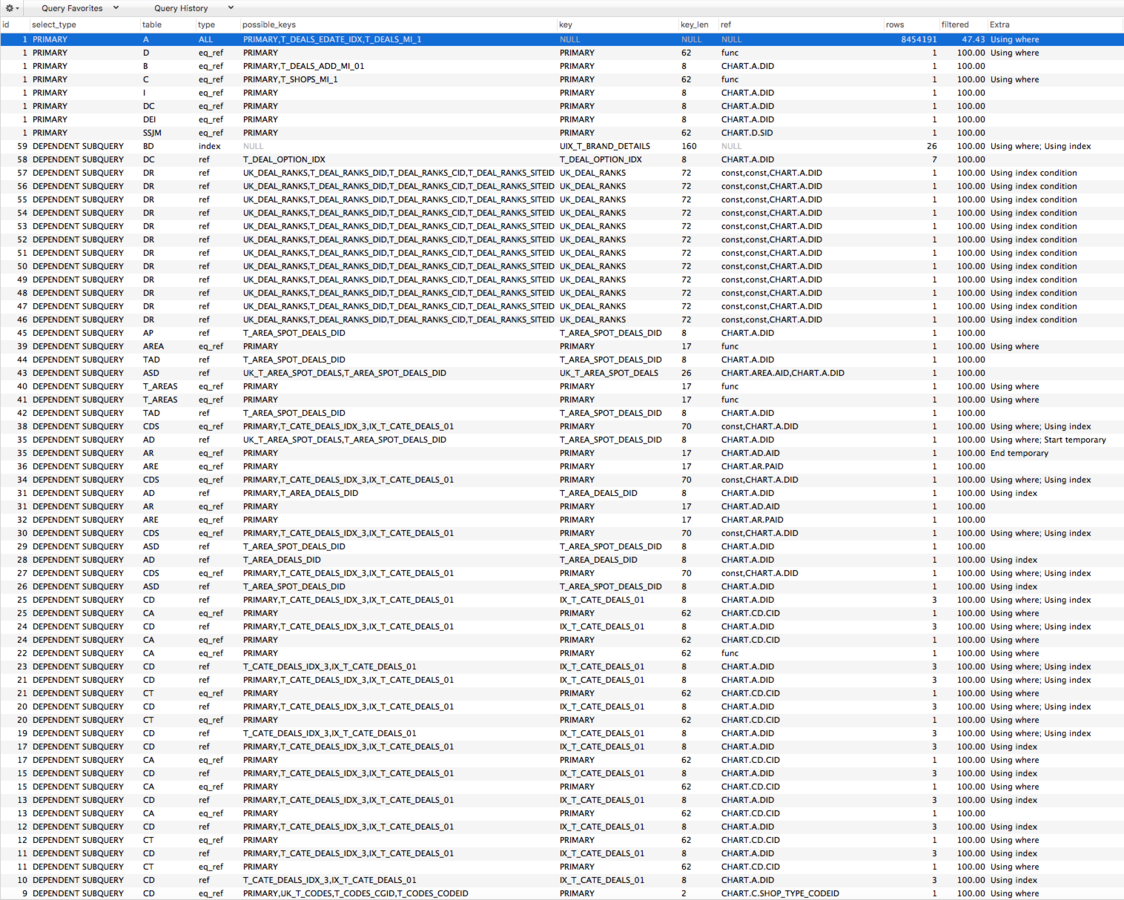
검색 색인 쿼리 실행계획
뭘 어떻게 수정해야돼죠?
- 인덱스를 최대한 태우세요
- row수를 최대한 줄이세요 (필요한 만큼만 나오게)
- extra의 using filesort나 temporary 등을 없에세요 (물론 어쩔 수 없이 필요한 경우는 제외)
- 필요없는 컬럼 가지고 오는걸 제외해서 using index를 노리세요
- 더 빠른 TYPE조건으로 만드세요
- 플랜에서 사용하는 key, key_len 길이을 가급적 줄이세요
그래도 뭔가 부족하면
SET profiling = 1;
SHOW PROFILE;
실제 쿼리를 날려 데이터 처리 순서대로 시간별 정보를 볼 수 있음
어느 테이블에 어느 데이터를 처리하는지 까지는 보이지 않음
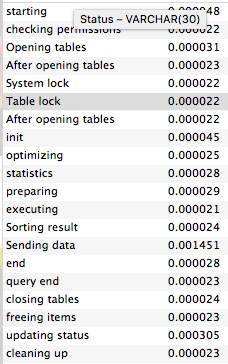
set profiling = 1;
select * from CHART.T_DEALS order by DID desc limit 100;
show profile;그래도 뭔가 부족하면
-
MYSQL은 EXPLAIN EXTENDED으로 filter 정보를 추가로 볼 수 있음 - SHOW WARNINGS; 명령어로 추가 정보를 더 볼 수 있음
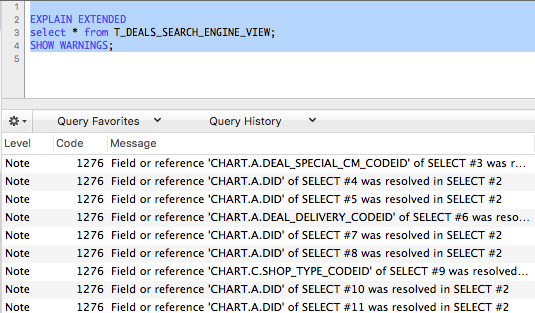
Statistics
통계란?
- 색인 및 테이블의 간략한 취합정보를 저장해놓은 정보
- 옵티마이저가 실행계획을 세울때 참조하는 데이터
- 이 정보가 잘못돼있으면 옵티마이저가 이상한 결과를 내기도함
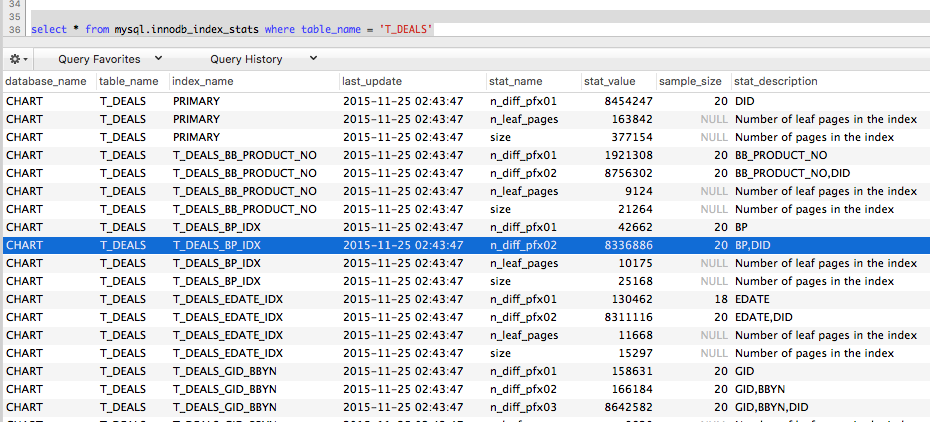

통계란?
- 통계는 일반적으로 실시간으로 갱신되지 않는다.
- innoDB도 비동기적으로 통계를 갱신하며 online으로 통계를 갱신한다.
- 통계는 특정상황에서 갱신되며 굳이 일부러 갱신할 필요는 없다.
- 데이터가 일정 사이즈 이상 변경된경우, 수동으로 ANALYZE TABLE명령어를 수행한경우, index를 rebuild한경우 등이 통계가 갱신됨 (DB종류에 따라 다를 수 있음)
INDEX
좋은 인덱스를 만드려면
- 분포도 (Cadinality)는 높으면 높을수록 좋다. unique하게 만들수록 좋다.
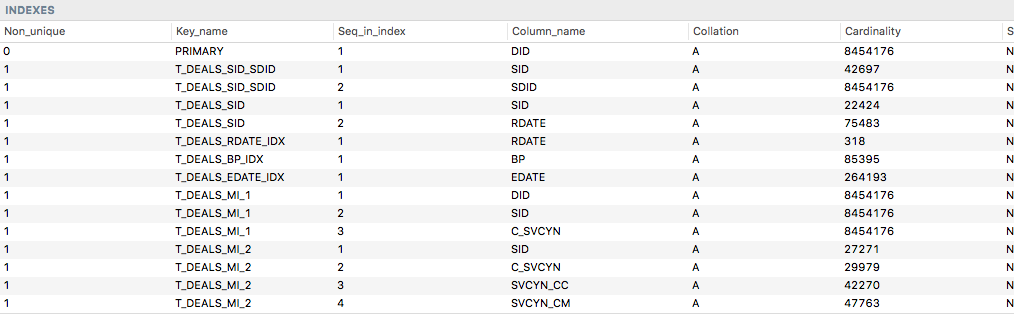
좋은 인덱스를 만드려면
- 조건절에 사용된다고 분포도가 낮은 컬럼 (BOOLEAN같은) 에 인덱스를 만들지 말자.
- 데이터가 많이 분포돼있다 하더라도 너무 한쪽에 치우친 데이터를 보유하고 있다면 색인을 고려해보는것이 좋다. (가령 A부터Z까지 저장되는 컬럼에 A값만 80%이상이라면 인덱스가 좋은 퍼포먼스를 내기 힘들다)
- 조건이 너무 자주 사용되 색인이 불가피 하다면 자주 사용하는 다른 where 조건 컬럼과 묶어 인덱스를 걸어 cardinality를 높여보자.
좋은 인덱스를 만드려면
- 인덱스를 너무 많이 생성하지 말자. 인덱스를 많이 생성할수록 table에 insert되는 속도가 저하된다. (비지니스적으로 read가 많은지 write가 많은지에 따라 인덱스 전략을 세우자)
빠르게 한다고 이 조건들을 다 인덱스를 걸수는 없으니;;
좋은 인덱스를 만드려면
- NULL이 들어가는 컬럼에 인덱스를 걸지 말자. NULL인 데이터는 인덱스로 만들 수 없다.
- 진짜 정 어쩔 수 없는 케이스에는 secondary column으로라도 설정하자
좋은 인덱스를 만드려면
- DB의 인덱스는 B-TREE만 있는건 아니다.
- 오라클은 B-Tree, Bitmap, Reverse Key, Function Base등이 있고 mysql은 스토리지 종류에 따라 Hash, R-tree등을 사용 가능 (근데 innoDB는 Btree만 되는건 함정..)
- mssql은 테이블당 Clustered Index를 한개 설정할 수 있고 일반적으로 PK에 설정되고, PK보다 다른 컬럼의 조건을 더 자주 사용하는경우 다른 인덱스로 바꿔줄수도 있다.
좋은 인덱스를 만드려면
인덱스는 비지니스적으로 접근하자.
- read가 많은가 write가 많은가
- 어떤 종류의 데이터가 저장되나
- 어떤 쿼리가 많이 호출되나 (호출이 많은 쿼리 부터 집중적으로 튜닝)
- 결론적으로 테이블에 접근하는 쿼리와 데이터의 종류에 따라 다른 인덱스 전략을 세울 수 있음
Connection Monitoring
DB Schema
Buffer
Storage Engine
Skip Scan
lock
하고 싶은건 많지만 ...

Q&A

자료출처
- Real Maria DB (책)
- Mysql 성능 최적화(책)
- 구루비 (구 오라클클럽)
- 디비 사랑넷
- http://gywn.net/