Ch4 문서 트리 구축하기
Feb 26th, 2026
Timothy @ Daangn Frontend Core
Software Engineer, Frontend @Daangn Frontend Core Team
ex) Senior Lead Software Engineer @NHN Dooray (2021 ~ 2023)
ex) Lead Software Engineer @ProtoPie (2016 ~ 2021)
ex) Microsoft MVP


Timothy Lee
이 웅재


4.1 노드 트리
DOM 트리
-
HTML 트리
-
태그 쌍 (여는 태그와 닫는 태그의 쌍)을 위한 노드
-
텍스트 스팬을 위한 노드
-

Token to Node
-
트리의 Leaf 노드가 될 새로운 Text 클래스
class Text:
def __init__(self, text, parent):
self.text = text
self.children = [] # 자식 노드가 필요없지만, 일관성을 위해 추가
self.parent = parentTag to Element
-
여는 태그와 닫는 태그가 하나로 엘리먼트로 변경
class Element:
def __init__(self, tag, parent):
self.tag = tag
self.children = []
self.parent = parentParser
-
소스 코드로부터 노드 트리를 구성하는 것을 파싱이라고 함
-
파서는 앞에서부터 한번에 하나의 엘리먼트나 텍스트 노드를 추가해 감
-
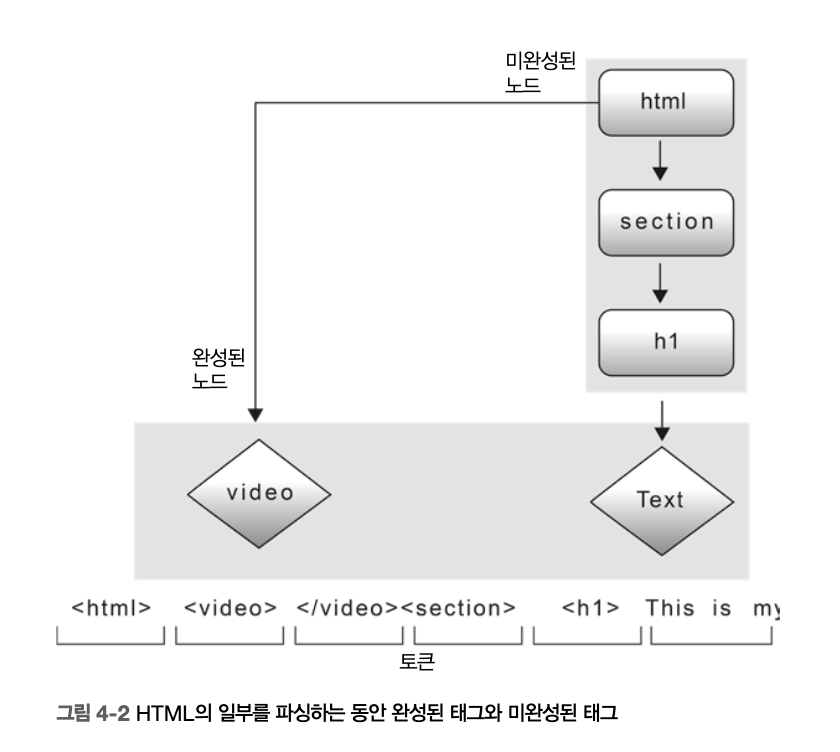
파서가 파싱을 진행하는 동안 불완전한 트리를 저장해야 한다.
-
미완성 태그는 언제나 나올 수 있다.
-
미완성 태그는 항상 열려 있지만, 아직 닫히지 않았고,
-
완성된 노드보다 소스에서 항상 뒤에 나오고,
-
항상 다른 미완성 태그의 자식 노드
-
이 리스트의 첫번째 노드는 HTML 트리의 루트이고,
-
리스트의 마지막 노드는 가장 최근에 추가된 미완성 태그
HTMLParser
class HTMLParser:
def __init__(self, body):
self.body = body
self.unfinished = []
def parse(self):
text = ""
in_tag = False
for c in self.body:
if c == "<":
in_tag = True
if text:
self.add_text(text)
text = ""
elif c == ">":
in_tag = False
self.add_text(text)
text = ""
else:
text += c
if not in_tag and text:
self.add_text(text)
return self.finish()4.2 트리 구축하기
add_text
-
텍스트 노드의 경우 마지막 미완성 노드의 자식 노드로 추가
class HTMLParser:
def add_text(self, text):
parent = self.unfinished[-1] # 미완성 노드의 마지막 노드
node = Text(text, parent) # Text 노드 만들기
parent.children.append(node) # 미완성 노드의 마지막 노드의 자식으로 추가add_tag
-
태그의 경우 여는 태그인지 닫는 태그인지에 따라 다르게 처리해야 함
class HTMLParser:
def add_tag(self, tag):
if tag.startswith("/"):
# ...
# 닫는 태그 처리
else:
# ...
# 여는 태그 처리add_tag 여는 태그 처리
-
여는 태그는 리스트의 끝에 새 미완성 노드로 추가
class HTMLParser:
def add_tag(self, tag):
if tag.startswith("/"):
# ...
else:
parent = self.unfinished[-1]
node = Element(tag, parent)
self.unfinished.append(node)add_tag 닫는 태그 처리
-
닫는 태그는 마지막 미완성 노드를 완성
-
해당 노드를 꺼내 리스트안에 있는 이전 미완성 노드에 추가
class HTMLParser:
def add_tag(self, tag):
if tag.startswith("/"):
node = self.unfinished.pop()
parent = self.unfinished[-1]
parent.children.append(node)
else:
parent = self.unfinished[-1]
node = Element(tag, parent)
self.unfinished.append(node)finish
-
파서가 파싱을 끝내면 미완성 노드를 모두 정리하는 것으로 불완전 트리를 완전 트리로
class HTMLParser:
def finish(self):
while len(self.unfinished) > 1:
node = self.unfinished.pop()
parent = self.unfinished[-1]
parent.children.append(node)
return self.unfinished.pop()최초의 여는 태그는 부모가 없는 엣지 케이스
-
파서가 파싱을 끝내면 미완성 노드를 모두 정리하는 것으로 불완전 트리를 완전 트리로
class HTMLParser:
def add_tag(self, tag):
if tag.startswith("/"):
node = self.unfinished.pop()
parent = self.unfinished[-1]
parent.children.append(node)
else:
parent = self.unfinished[-1] if self.unfinished else None #
node = Element(tag, parent)
self.unfinished.append(node)가장 마지막 태그도 엣지 케이스
-
처리할 미완성 노드가 없기 때문
class HTMLParser:
def add_tag(self, tag):
if tag.startswith("/"):
if len(self.unfinished) == 1: #
return #
node = self.unfinished.pop()
parent = self.unfinished[-1]
parent.children.append(node)
else:
parent = self.unfinished[-1] if self.unfinished else None
node = Element(tag, parent)
self.unfinished.append(node)Speculative Parsing
-
브라우저가 HTML을 파싱할 때 성능을 높이기 위해 사용하는 최적화 기법
-
배경
-
<script>태그를 만나면 파싱을 멈추고(blocking), 스크립트를 다운로드, 실행한 뒤에야 파싱을 재개 -
이 때 외부 리소스(CSS, 이미지, 폰트 등)를 미리 발견하지 못해 네트워크가 낭비
-
-
브라우저가 메인 파서가 블로킹된 동안 별도의 스레드(preload scanner)로 나머지 HTML을 미리 훑어보며 리소스를 조기에 발견하고 다운로드를 시작하는 기법
-
요약
-
블로킹된 시간을 낭비하지 말고 미리 할 수 있는 일을 하자는 발상
-
페이지 로딩 성능을 실질적으로 개선하는 브라우저의 핵심 최적화 중 하나
-
4.3 파서 디버깅하기
print_tree
-
가장 쉬운 디버깅 방법은 로그 찍기 ㅋㅋ
def print_tree(node, indent=0):
print(" " * indent, node) # 들여쓰기 처리하고 출력한 뒤
for child in node.children:
print_tree(child, indent + 2) # 재귀적으로 호출def __repr__(self) -> str:
-
로그 출력시 객체가 적절하게 문자열로 출력되도록 구현 추가
class Text:
def __repr__(self) -> str:
return repr(self.text)
class Element:
def __repr__(self) -> str:
return "<" + self.tag + ">"트리 노드 시각화
class Browser:
def load(self, url):
body = url.request()
nodes = HTMLParser(body).parse()
print_tree(nodes)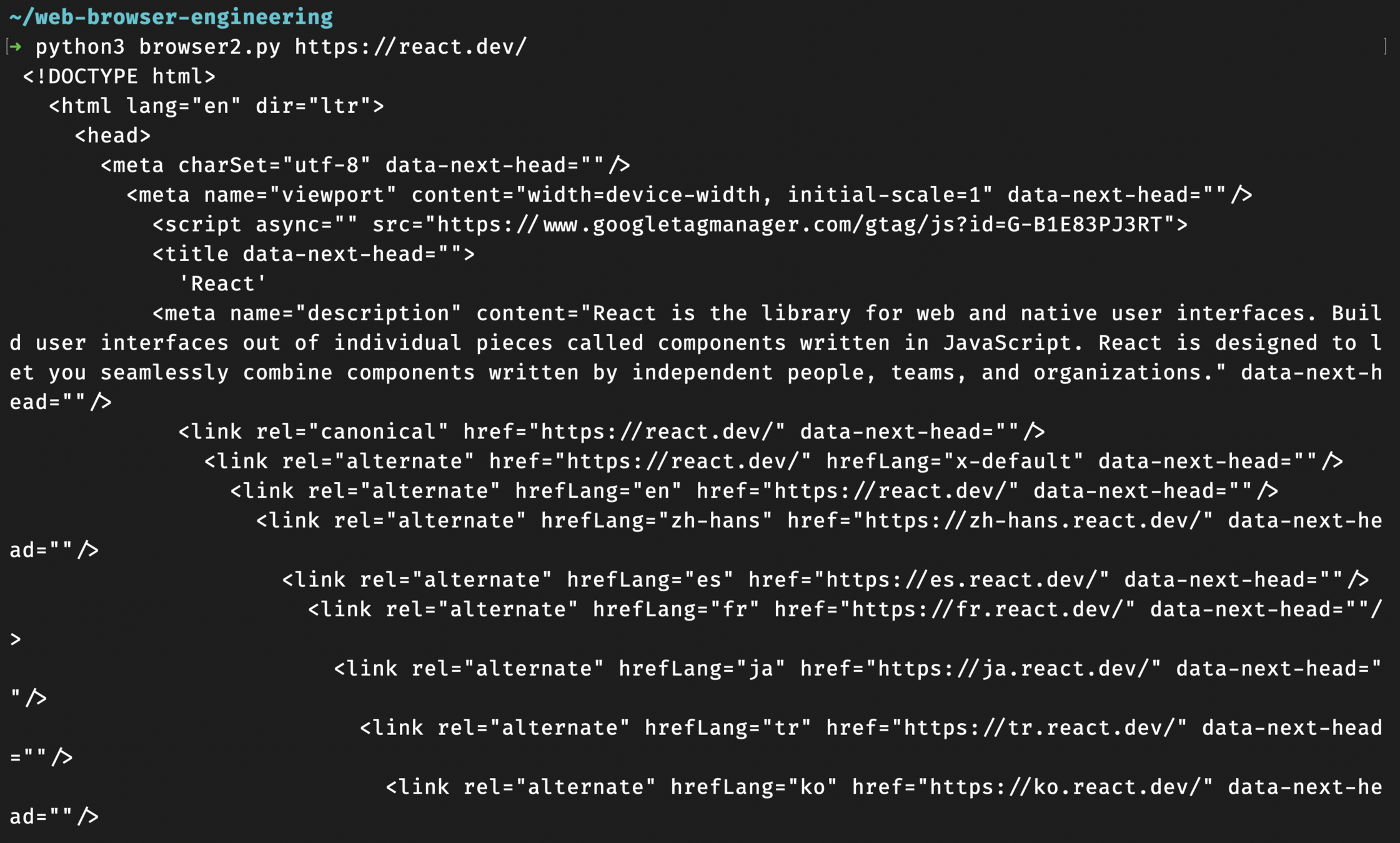
<!DOCTYPE html> 제거
class HTMLParser:
def add_tag(self, tag):
if tag.startswith("!"): # <!-- 주석 --> 도 함께 제거
return #
if tag.startswith("/"):
if len(self.unfinished) == 1:
return
node = self.unfinished.pop()
parent = self.unfinished[-1]
parent.children.append(node)
else:
parent = self.unfinished[-1] if self.unfinished else None
node = Element(tag, parent)
self.unfinished.append(node)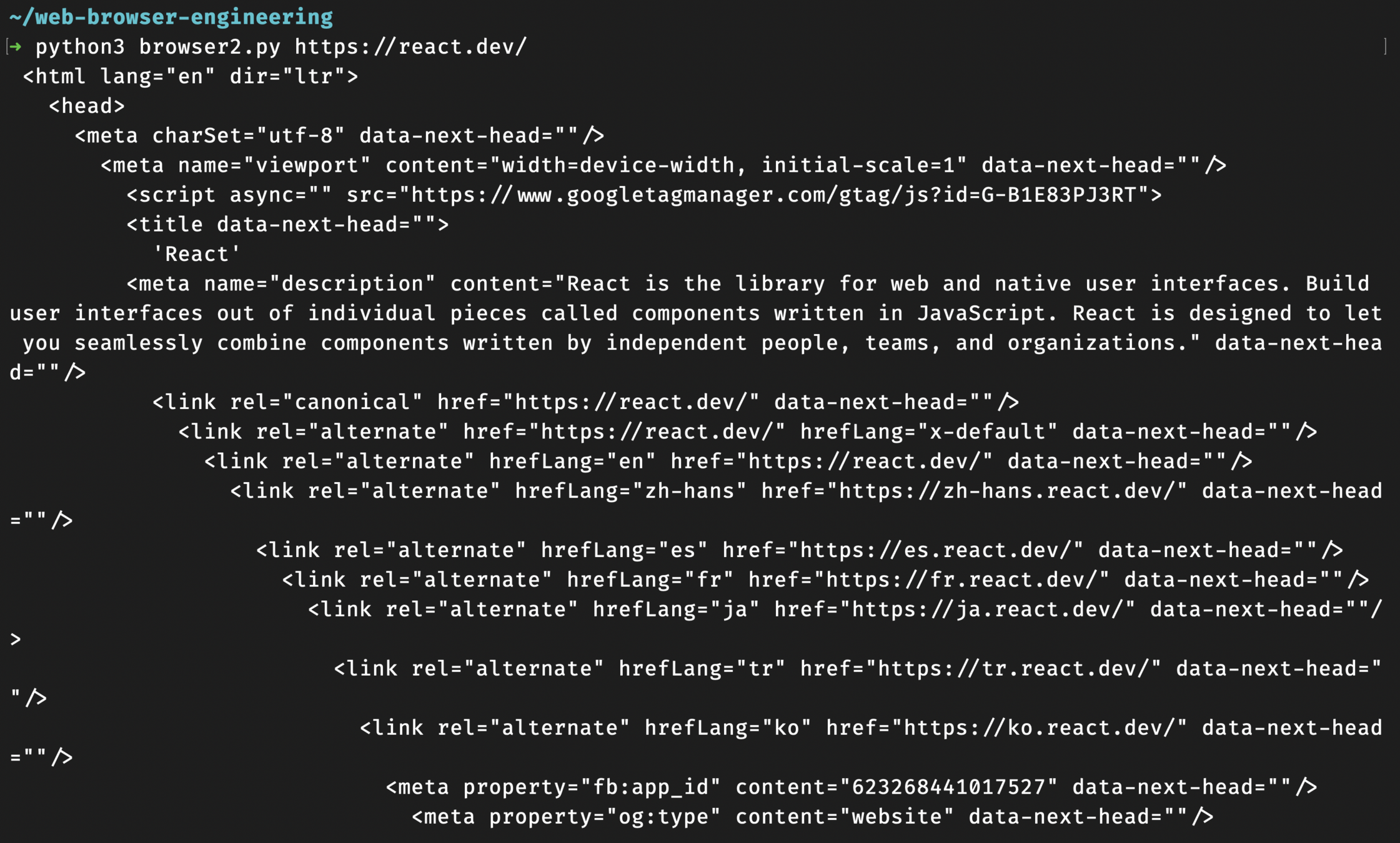
화이트스페이스만 있는 텍스트 노드 건너 띄기
class HTMLParser:
def add_text(self, text):
if text.isspace(): #
return #
parent = self.unfinished[-1]
node = Text(text, parent)
parent.children.append(node)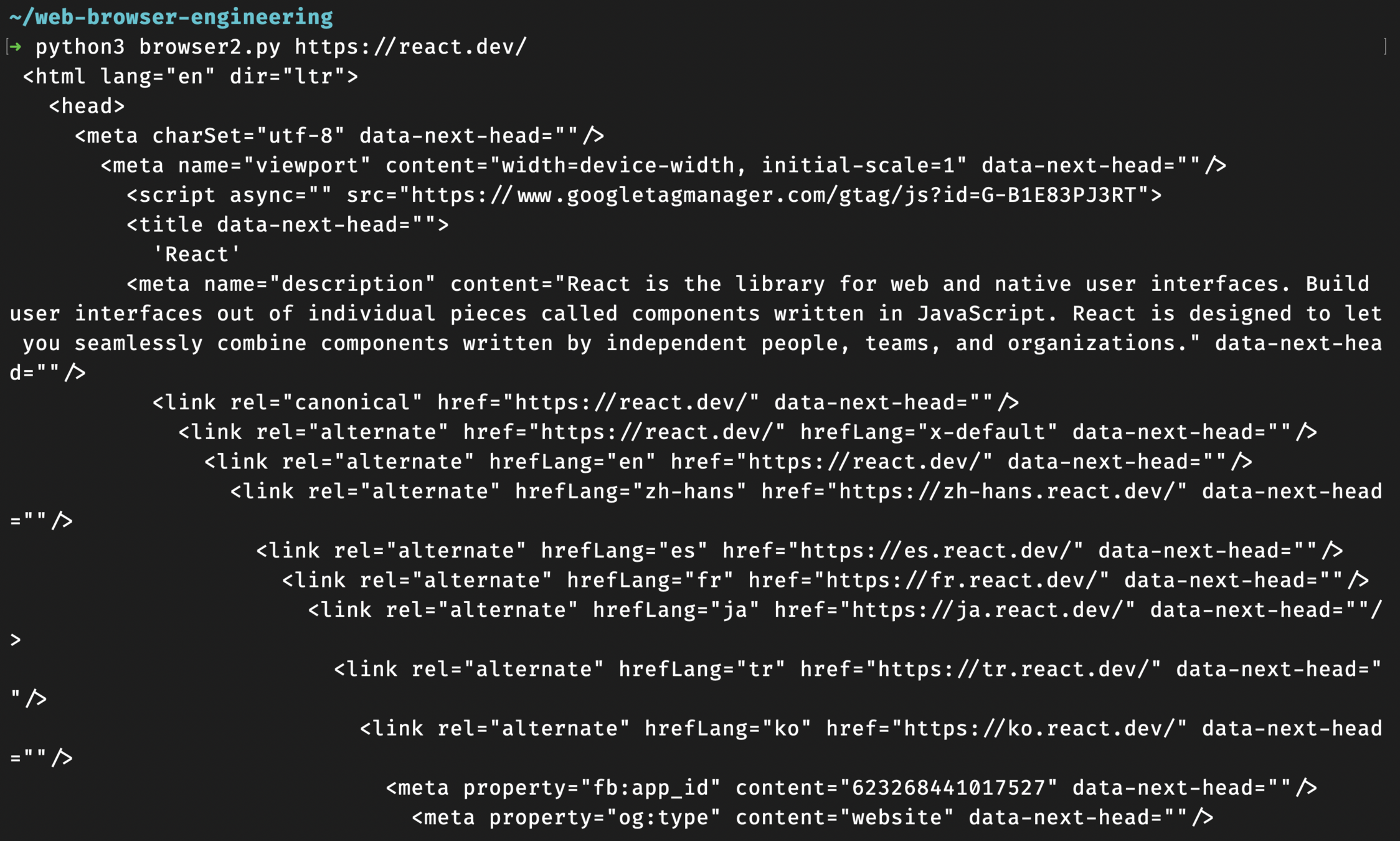
4.4 셀프 클로징 태그
셀프 클로징 태그
-
<meta /> <link />
-
void 태그
-
아래 리스트에 있는 태그는 바로 닫아야 함
class HTMLParser:
SELF_CLOSING_TAGS = [
"area", "base", "br", "col", "embed", "hr", "img", "input",
"link", "meta", "param", "source", "track", "wbr",
]add_tag 에 셀프 클로징 태그 처리
class HTMLParser:
def add_tag(self, tag):
if tag.startswith("!"):
return
if tag.startswith("/"):
if len(self.unfinished) == 1:
return
node = self.unfinished.pop()
parent = self.unfinished[-1]
parent.children.append(node)
elif tag in self.SELF_CLOSING_TAGS:
parent = self.unfinished[-1]
node = Element(tag, parent)
parent.children.append(node)
else:
parent = self.unfinished[-1] if self.unfinished else None
node = Element(tag, parent)
self.unfinished.append(node)attributes 처리
-
HTML 어트리뷰트는 엘리먼트에 대한 추가적인 정보를 제공
-
공백 문자로 분할하여 태그명과 어트리뷰트 이름-값 쌍으로 나누기
class HTMLParser:
def get_attributes(self, text):
parts = text.split()
tag = parts[0].casefold()
attributes = {}
for attrpair in parts[1:]:
#
return tag, attributesattrpair 안에 "=" 가 있는 경우
class HTMLParser:
def get_attributes(self, text):
parts = text.split()
tag = parts[0].casefold()
attributes = {}
for attrpair in parts[1:]:
if "=" in attrpair:
key, value = attrpair.split("=", 1) #
attributes[key.casefold()] = value #
return tag, attributesattrpair 안에 "=" 가 없는 경우
class HTMLParser:
def get_attributes(self, text):
parts = text.split()
tag = parts[0].casefold()
attributes = {}
for attrpair in parts[1:]:
if "=" in attrpair:
key, value = attrpair.split("=", 1)
attributes[key.casefold()] = value
else:
attributes[attrpair.casefold()] = "" #
return tag, attributesvalue 에 따옴표(', ")가 있는 경우
class HTMLParser:
def get_attributes(self, text):
parts = text.split()
tag = parts[0].casefold()
attributes = {}
for attrpair in parts[1:]:
if "=" in attrpair:
key, value = attrpair.split("=", 1)
if len(value) > 2 and value[0] in ["'", "\""]: #
value = value[1:-1] #
attributes[key.casefold()] = value
else:
attributes[attrpair.casefold()] = ""
return tag, attributes어트리뷰트를 Element에 저장
class Element:
def __init__(self, tag, attributes, parent): #
self.tag = tag
self.attributes = attributes #
self.children = []
self.parent = parentadd_tag 에서 어트리뷰트 처리
class HTMLParser:
def add_tag(self, tag):
tag, attributes = self.get_attributes(tag)
if tag.startswith("!"):
return
if tag.startswith("/"):
if len(self.unfinished) == 1:
return
node = self.unfinished.pop()
parent = self.unfinished[-1]
parent.children.append(node)
elif tag in self.SELF_CLOSING_TAGS:
parent = self.unfinished[-1]
node = Element(tag, attributes, parent)
parent.children.append(node)
else:
parent = self.unfinished[-1] if self.unfinished else None
node = Element(tag, attributes, parent)
self.unfinished.append(node)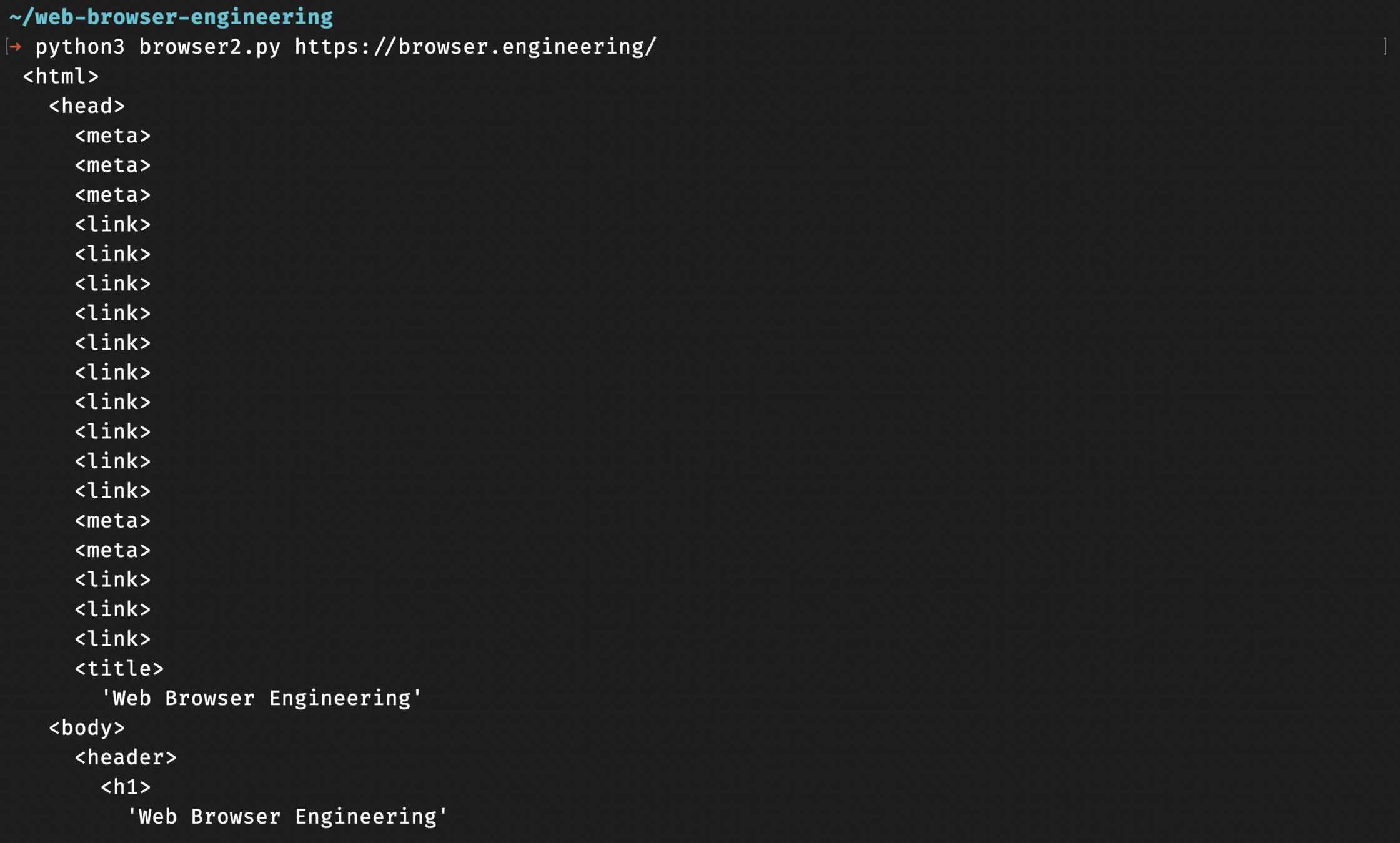
4.5 노드 트리 사용하기
Layout) Token 단위 to Node 단위
-
def token
-
def open_tag
-
def close_tag
-
class Layout:
def open_tag(self, tag):
if tag == "i":
self.style = "italic"
elif tag == "b":
self.weight = "bold"
elif tag == "small":
self.size -= 2
elif tag == "big":
self.size += 4
elif tag == "br":
self.flush()class Layout:
def close_tag(self, tag):
if tag == "i":
self.style = "roman"
elif tag == "b":
self.weight = "normal"
elif tag == "small":
self.size += 2
elif tag == "big":
self.size -= 4
elif tag == "p":
self.flush()
self.cursor_y += VSTEPLayout.recurse
-
def recurse
-
def open_tag
-
def close_tag
-
Text
-
class Layout:
def recurse(self, tree):
if isinstance(tree, Text):
for word in tree.text.split():
self.word(word)
else:
self.open_tag(tree.tag)
for child in tree.children:
self.recurse(child)
self.close_tag(tree.tag)token to recurse
class Layout:
def __init__(self, tree): #
self.display_list = []
self.cursor_x = HSTEP
self.cursor_y = VSTEP
self.weight = "normal"
self.style = "roman"
self.size = 12
self.line = []
self.recurse(tree) #
self.flush()Browser.load
class Browser:
def load(self, url):
body = url.request()
nodes = HTMLParser(body).parse()
print_tree(nodes)
self.display_list = Layout(self.nodes).display_list
self.draw()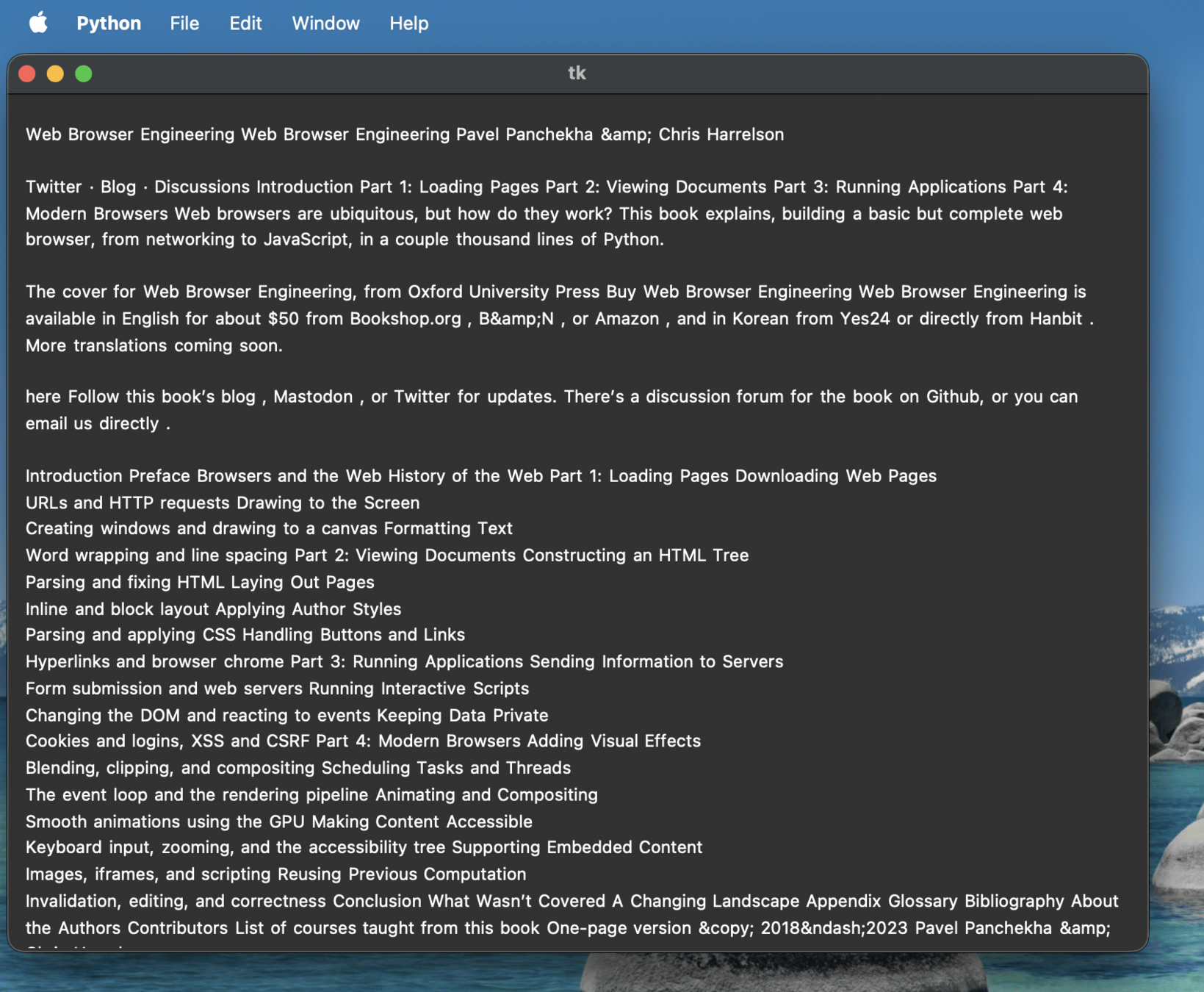
4.6 페이지 오류 다루기
암시적 태그
-
<html><head></head><body></body></html> 여섯개는 없으면 추가
class HTMLParser:
def add_text(self, text):
if text.isspace():
return
self.implicit_tags(None) #
# ...
def add_tag(self, tag):
tag, attributes = self.get_attributes(tag)
if tag.startswith("!"):
return
self.implicit_tags(tag) #
# ...finish에 추가
-
빈 문자열에 대해서도 <html> 과 <body> 가 추가되어야 함
class HTMLParser:
def finish(self):
if not self.unfinished: #
self.implicit_tags(None) #
while len(self.unfinished) > 1:
node = self.unfinished.pop()
parent = self.unfinished[-1]
parent.children.append(node)
return self.unfinished.pop()implicit_tags
class HTMLParser:
HEAD_TAGS = [
"base", "basefont", "bgsound", "noscript",
"link", "meta", "title", "style", "script",
]
def implicit_tags(self, tag):
while True:
open_tags = [node.tag for node in self.unfinished]
if open_tags == [] and tag != "html":
self.add_tag("html")
elif open_tags == ["html"] \
and tag not in ["head", "body", "/html"]:
if tag in self.HEAD_TAGS:
self.add_tag("head")
else:
self.add_tag("body")
elif open_tags == ["html", "head"] and \
tag not in ["/head"] + self.HEAD_TAGS:
self.add_tag("/head")
else:
break