Understanding Trove
https://slides.com/wragge/aha-2024

please steal these slides!
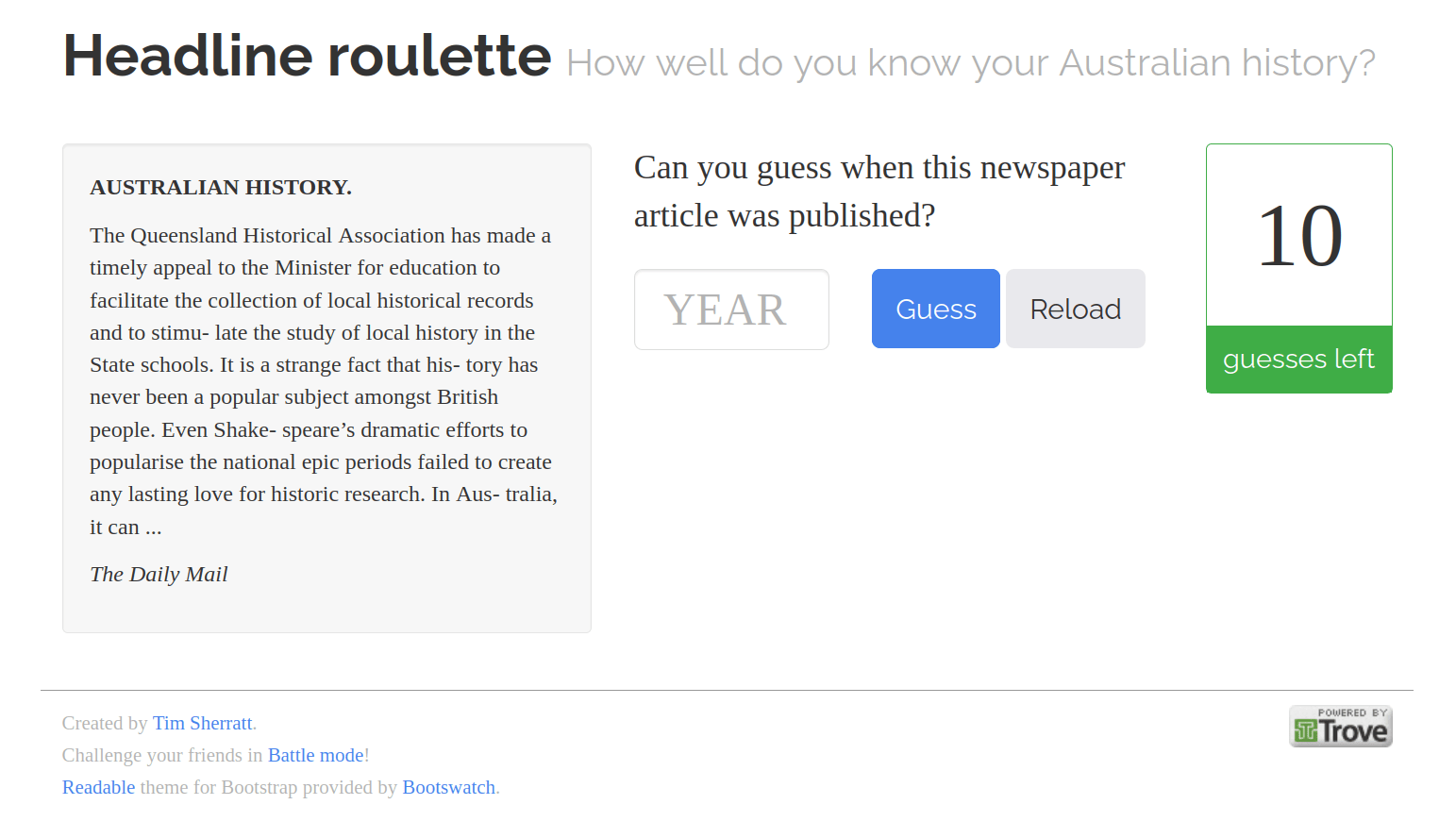

2009–2012

2013–2015

2016–
Trove has a history
Single Business Discovery Project

Trove
structures change
2008
2024

content changes
2022
2011
Trove is constructed
using critically
context?
content?
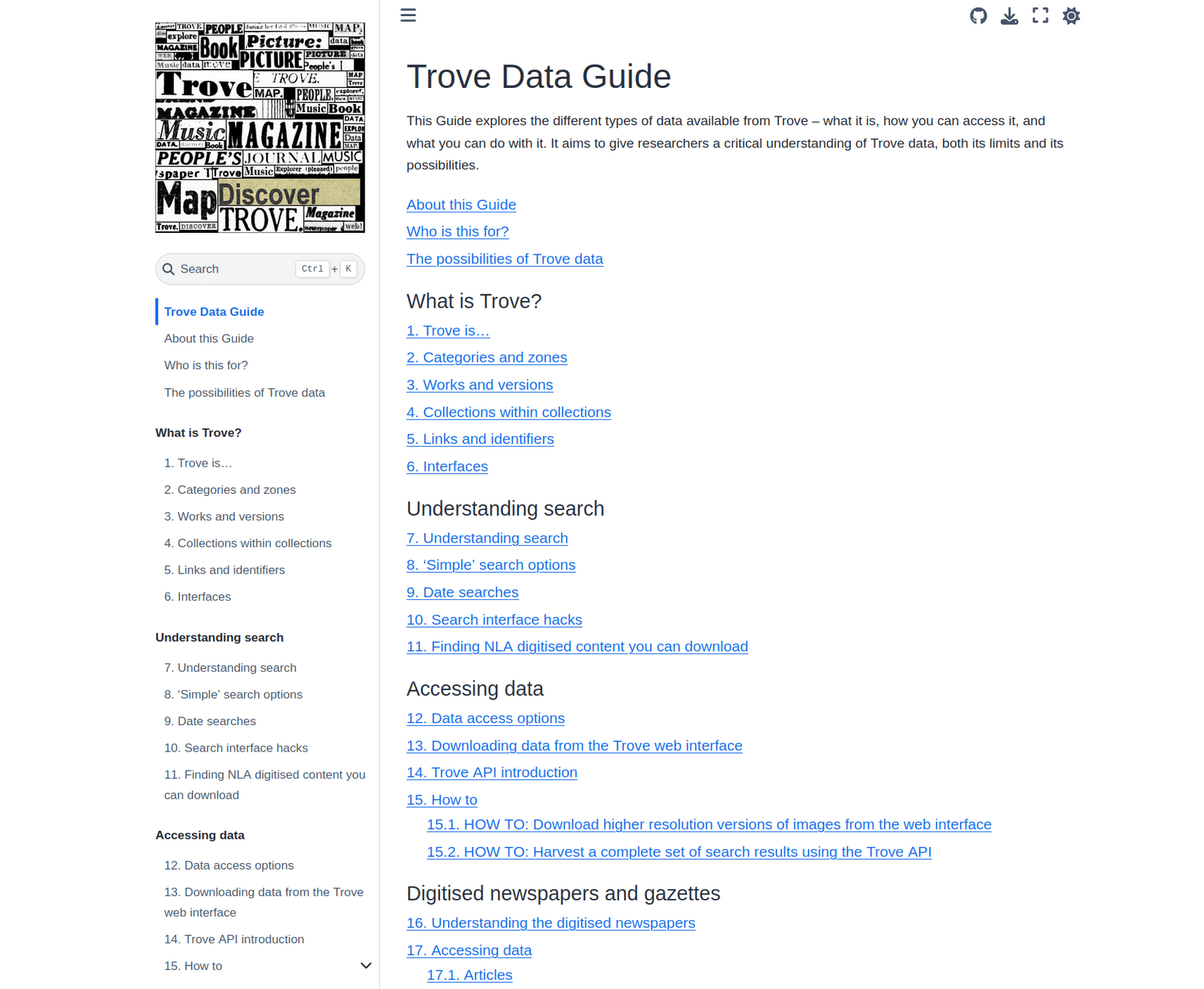
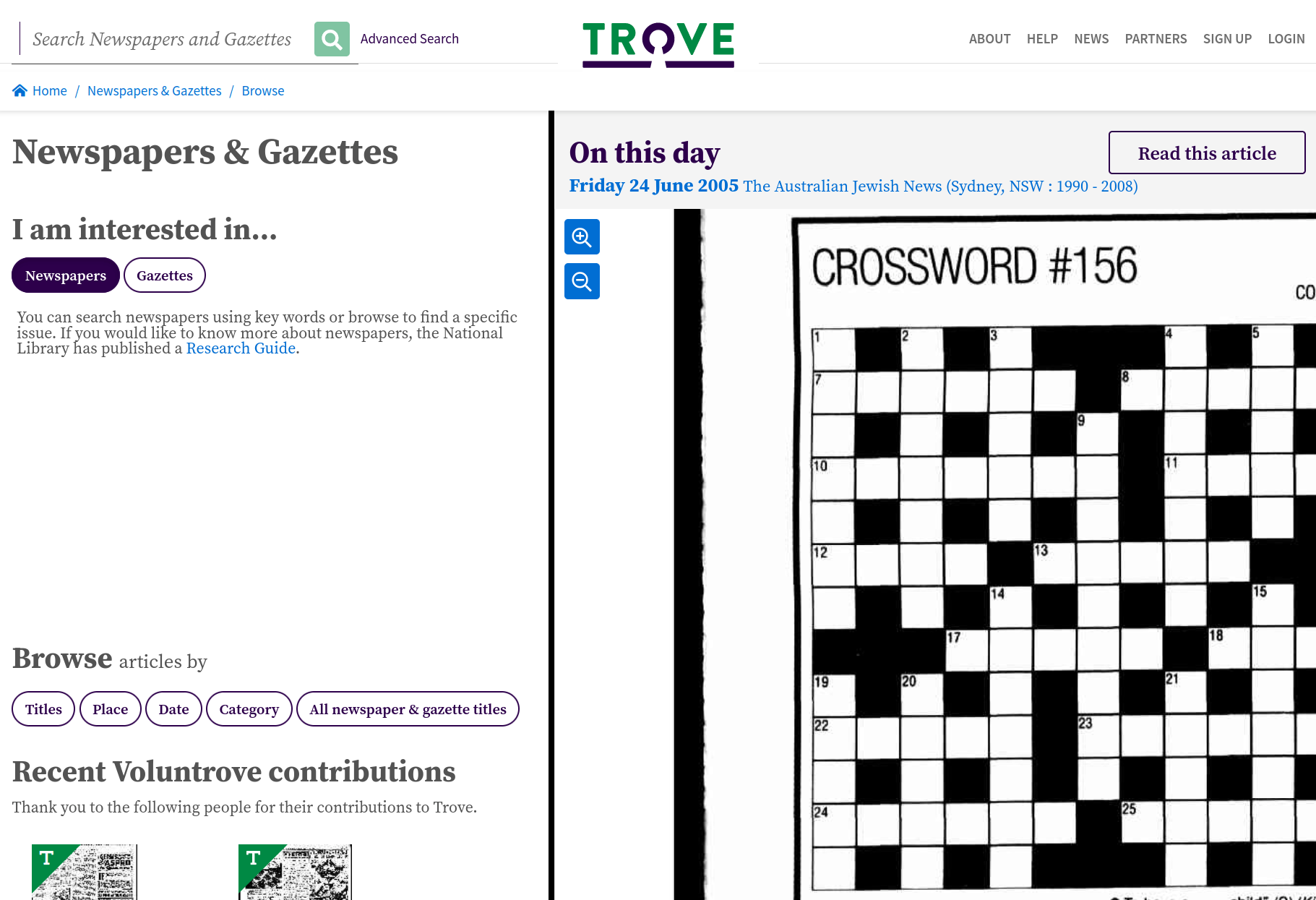
Trove Data Guide content
- Explanation – why is Trove like this?
- Documentation – what you need to know
- How to – complete a specific task
- Tutorials – learn methods, develop skills
- inspired by Diátaxis
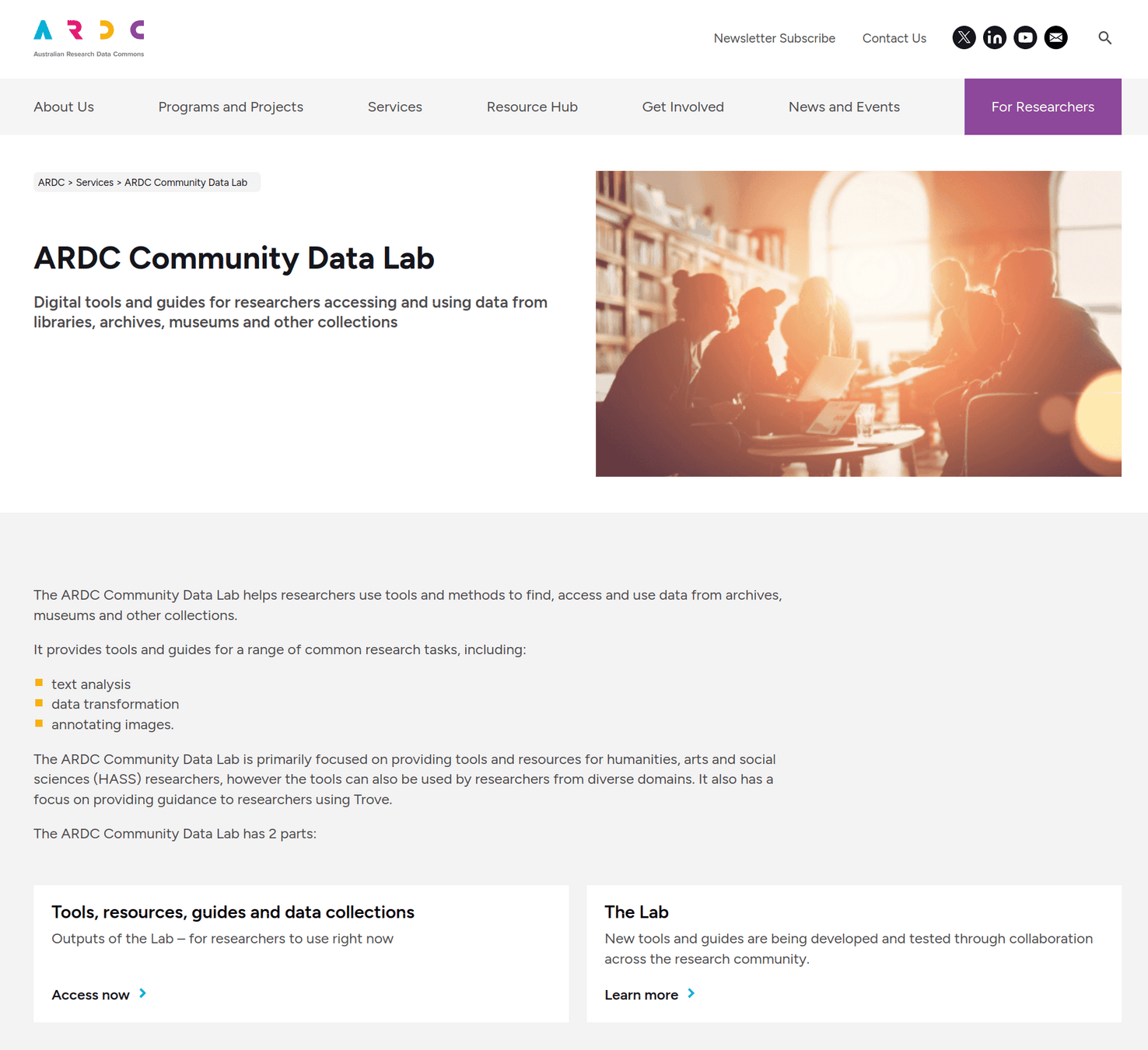
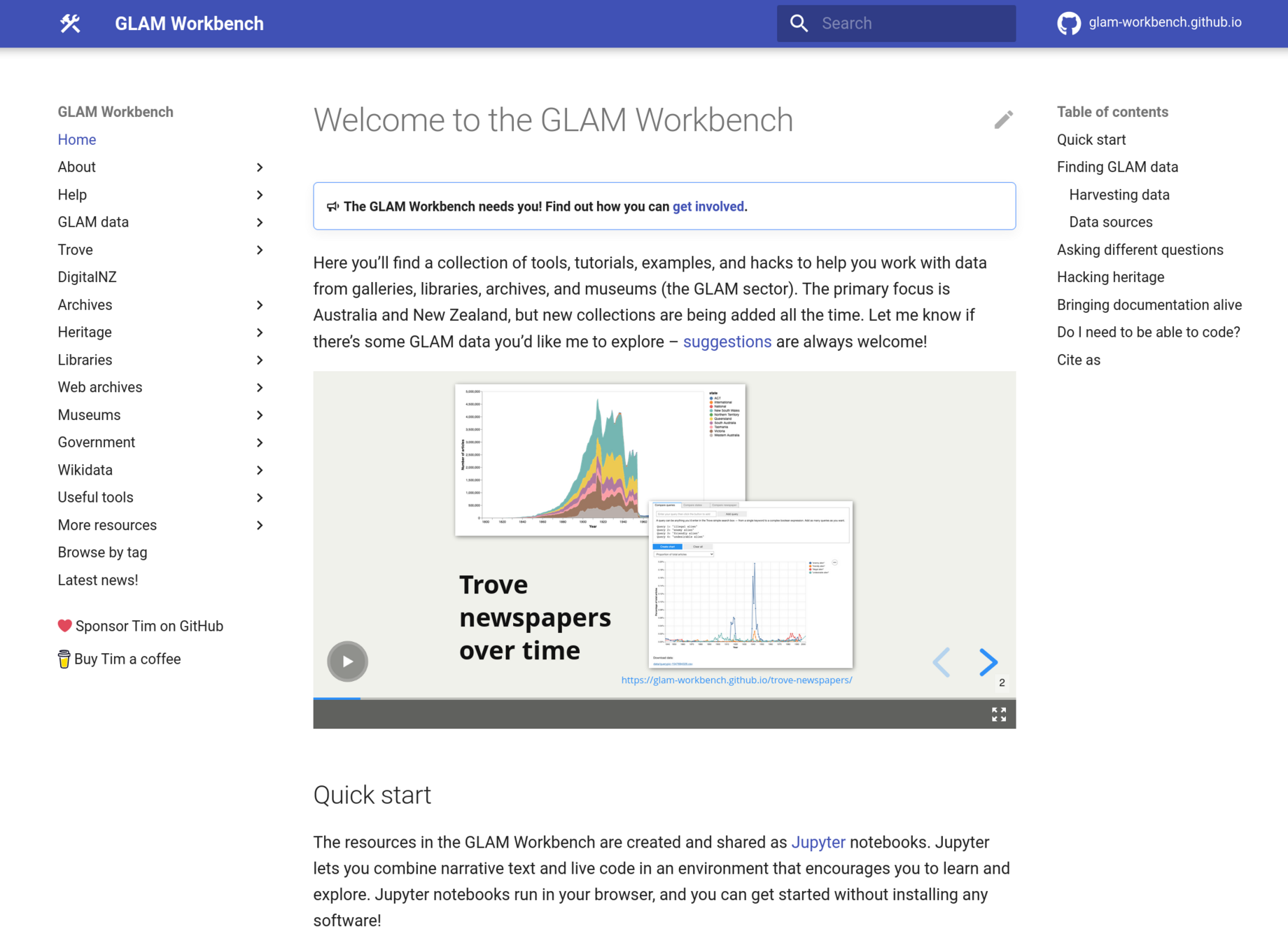
Community Data Lab
Trove Data Guide
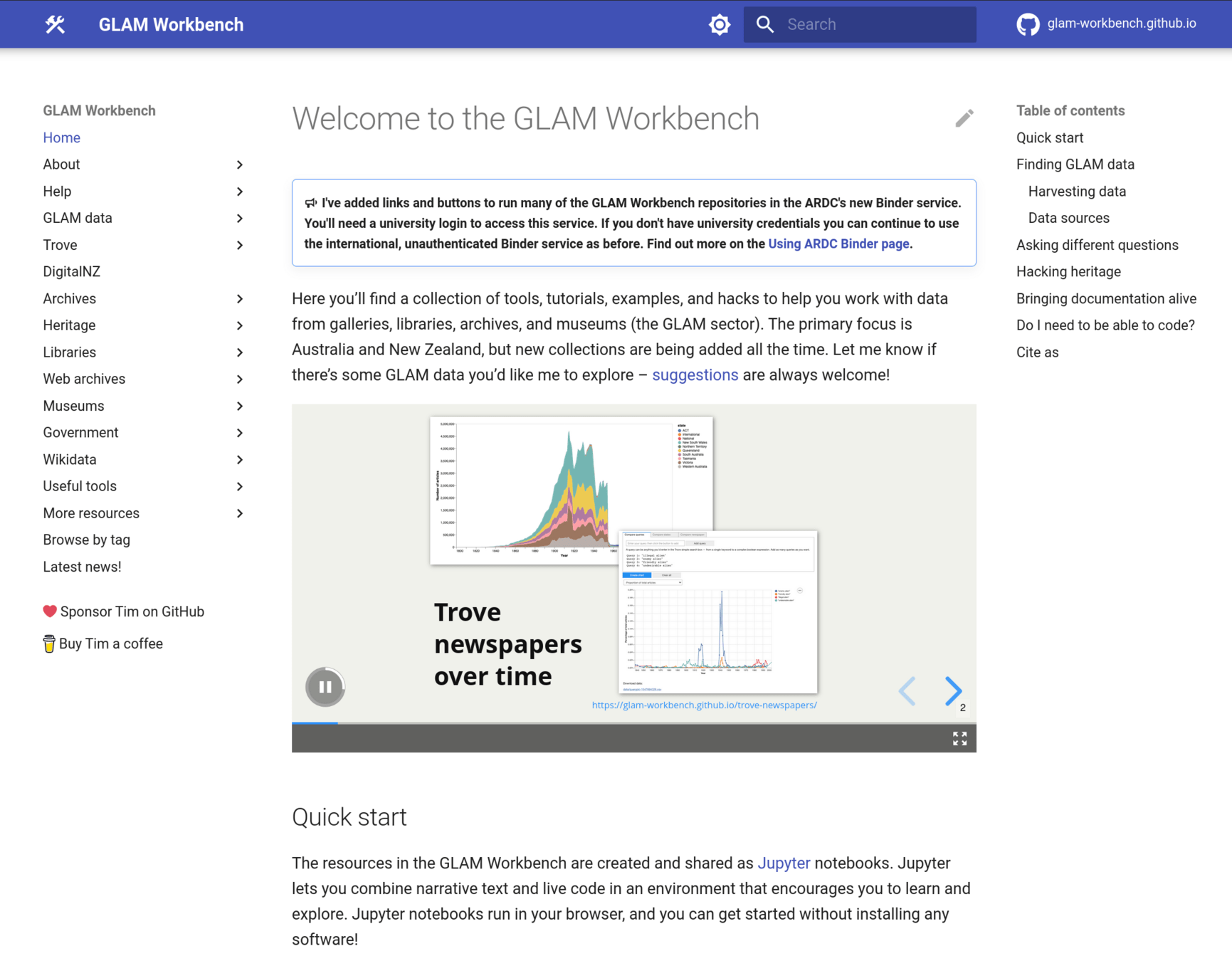
GLAM Workbench
architectures
standards
technologies
principles
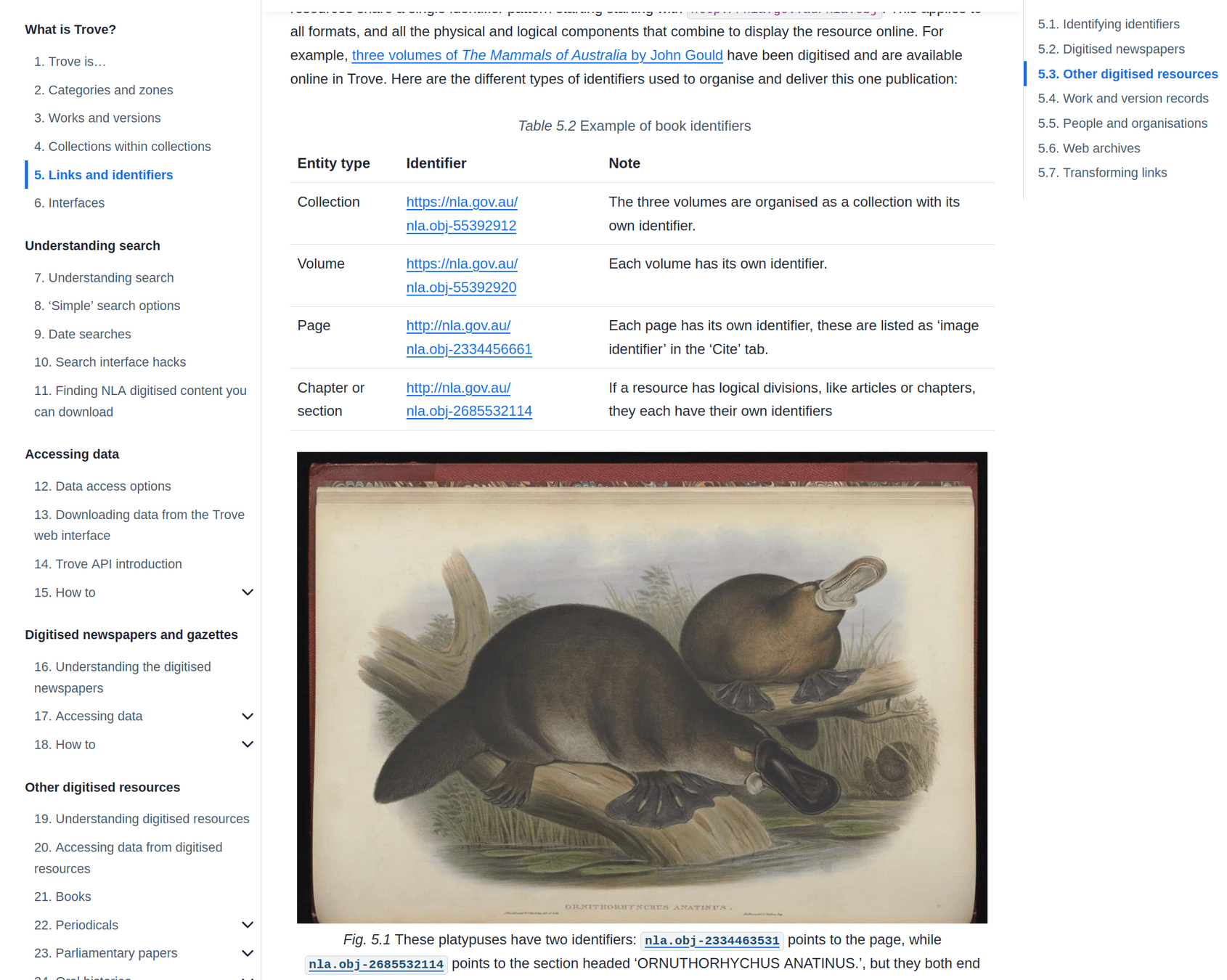
context & content
how many digitised newspaper articles are currently in Trove?
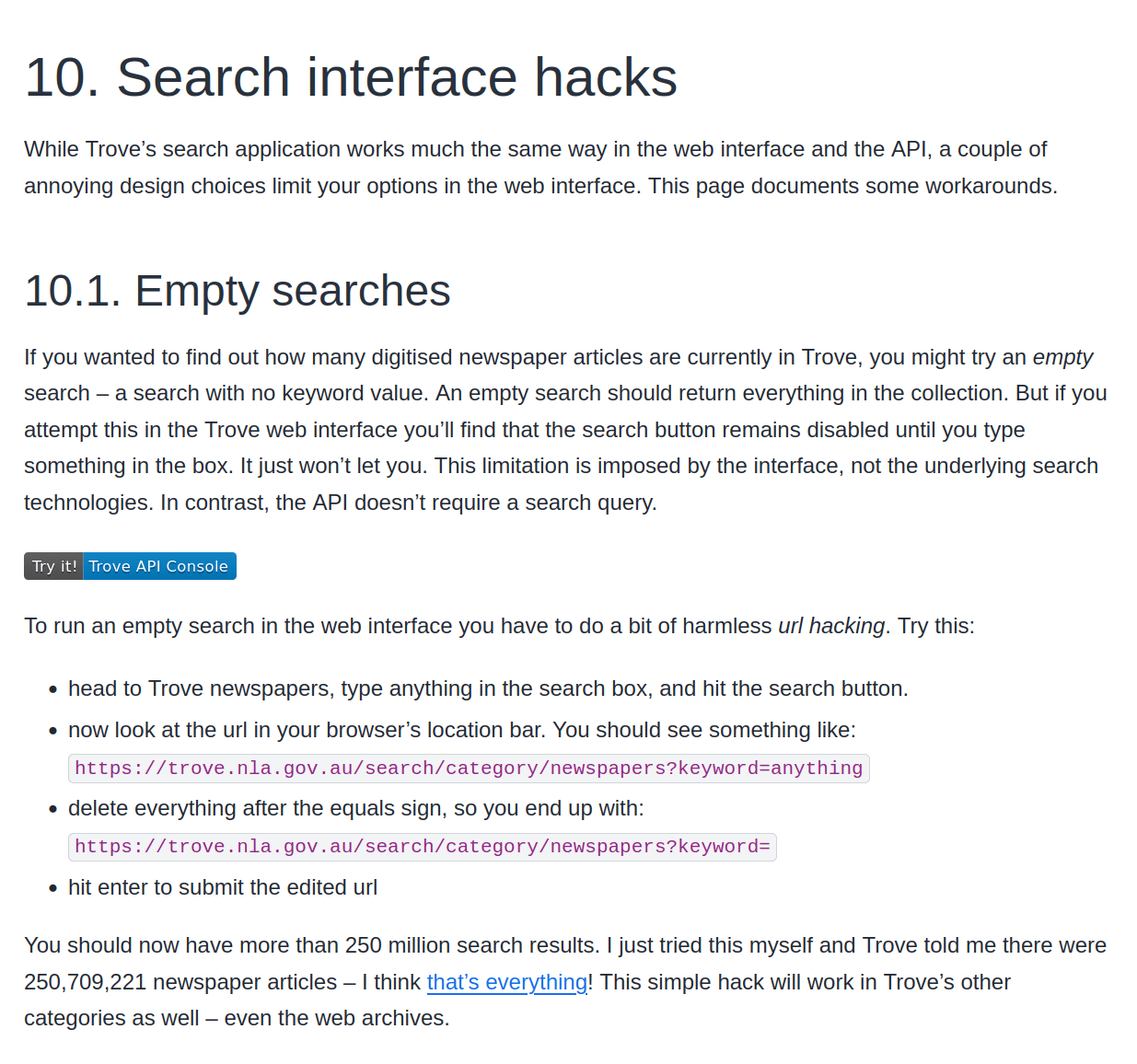
try it!
- go to Trove's newspapers category
- enter any keyword (it doesn't matter what it is)
- look at the url in your browser's location bar and find the part of the url that looks like:
?keyword=[your keyword] - delete the part after the
=sign and hit enter

bonus points!
- add
&pageSize=100to the url in your browser's location bar and hit enter - what happens?
official
Trove
hacker
handy with lists
-
an aggregation of collection metadata
-
a repository of digitised content
-
an archive of Australian web content from 1996 onwards
-
aggregated identity records for people and organisations
-
born-digital publications submitted via eLegal Deposit
-
a platform for user engagement
-
a series of APIs for delivering machine-actionable data
Trove is not one thing...
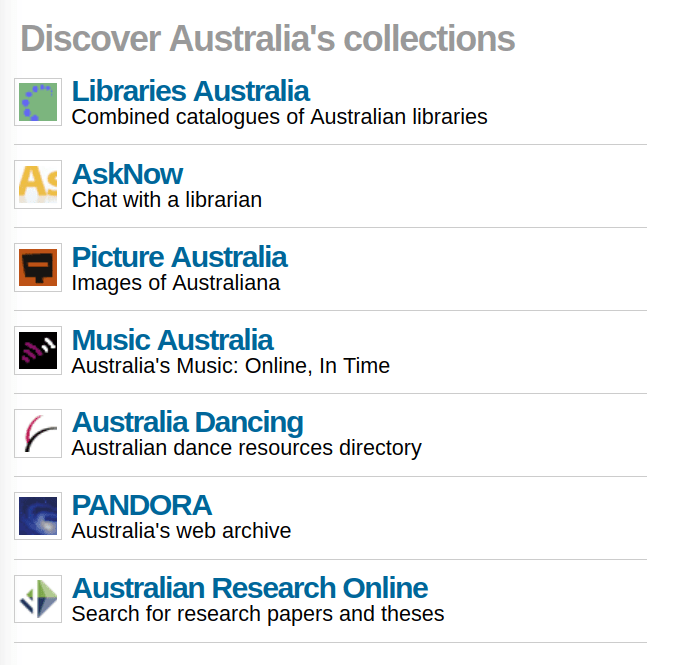
Trove's categories
starting at the top!
-
Books & Libraries
-
Diaries, Letters & Archives
-
Images, Maps & Artefacts
-
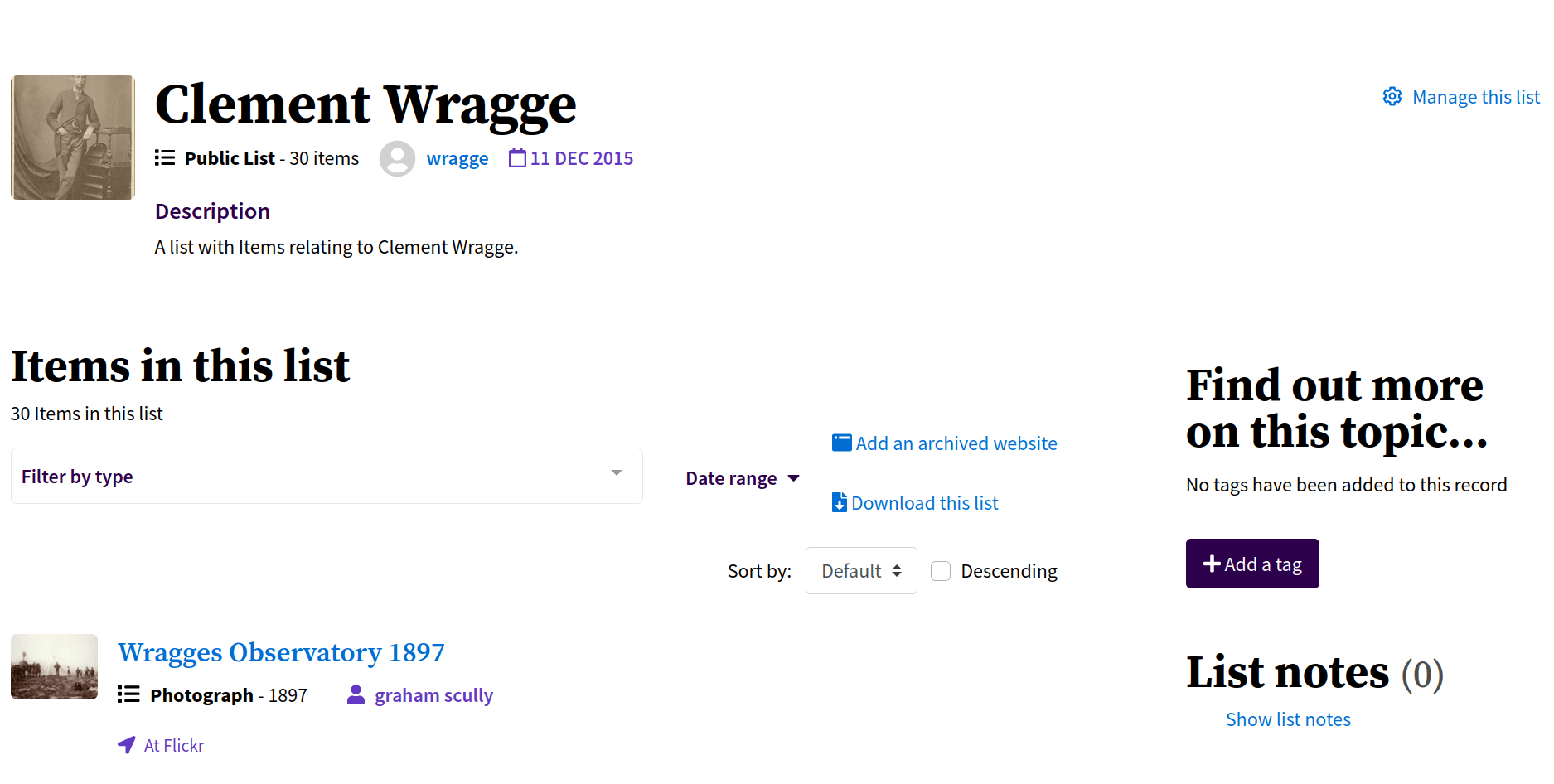
Lists
-
Magazines & Newsletters
-
Music, Audio & Video
-
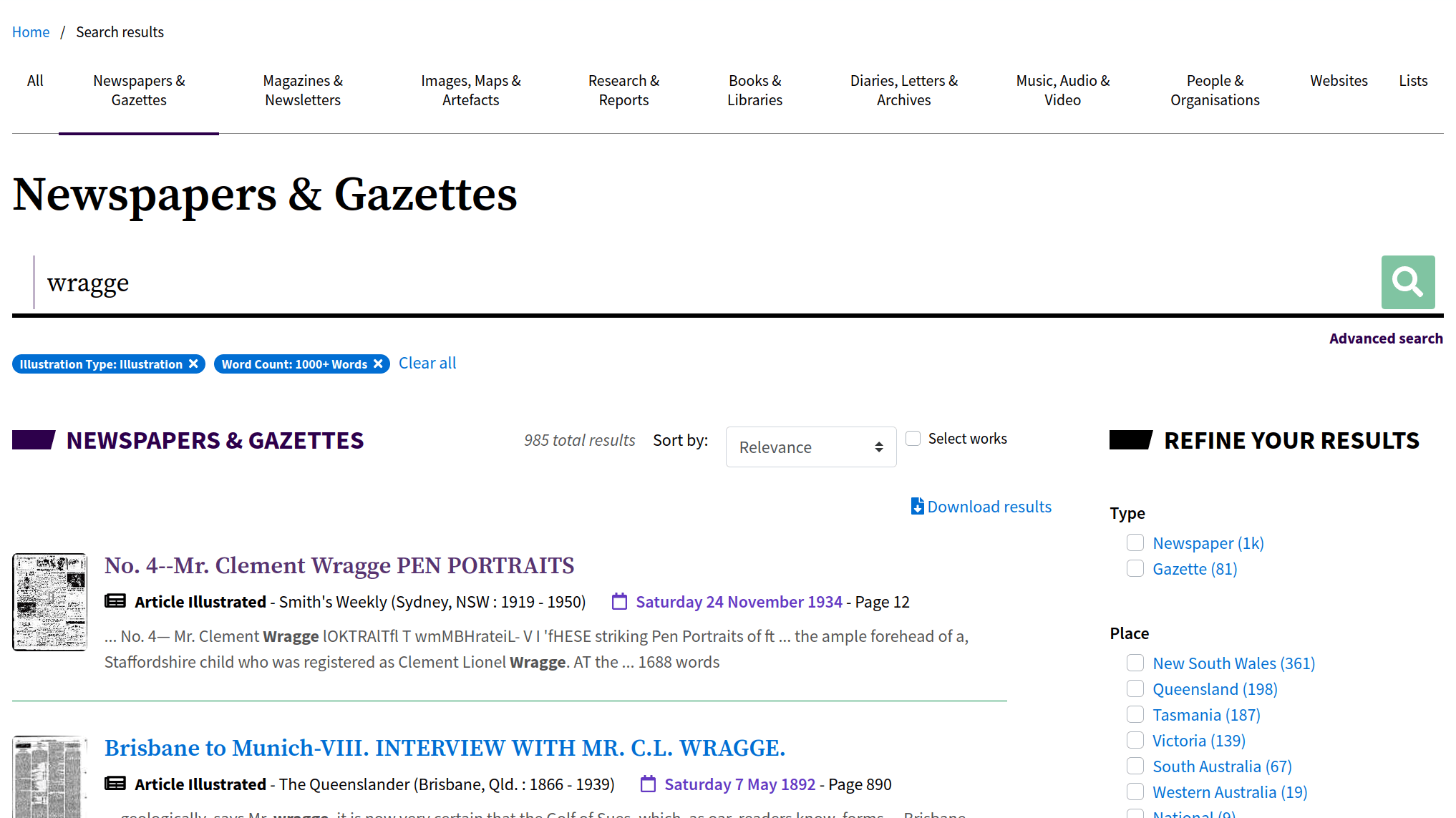
Newspapers & Gazettes
-
People & Organisations
-
Research & Reports
-
Websites
separate systems /
specific types of things
-
Books & Libraries
-
Diaries, Letters & Archives
-
Images, Maps & Artefacts
-
Lists
-
Magazines & Newsletters
-
Music, Audio & Video
-
Newspapers & Gazettes
-
People & Organisations
-
Research & Reports
-
Websites
aggregated metadata
&
digitised resources
-
Books & Libraries
-
Diaries, Letters & Archives
-
Images, Maps & Artefacts
-
Lists
-
Magazines & Newsletters
-
Music, Audio & Video
-
Newspapers & Gazettes
-
People & Organisations
-
Research & Reports
-
Websites
like newspapers, but not...

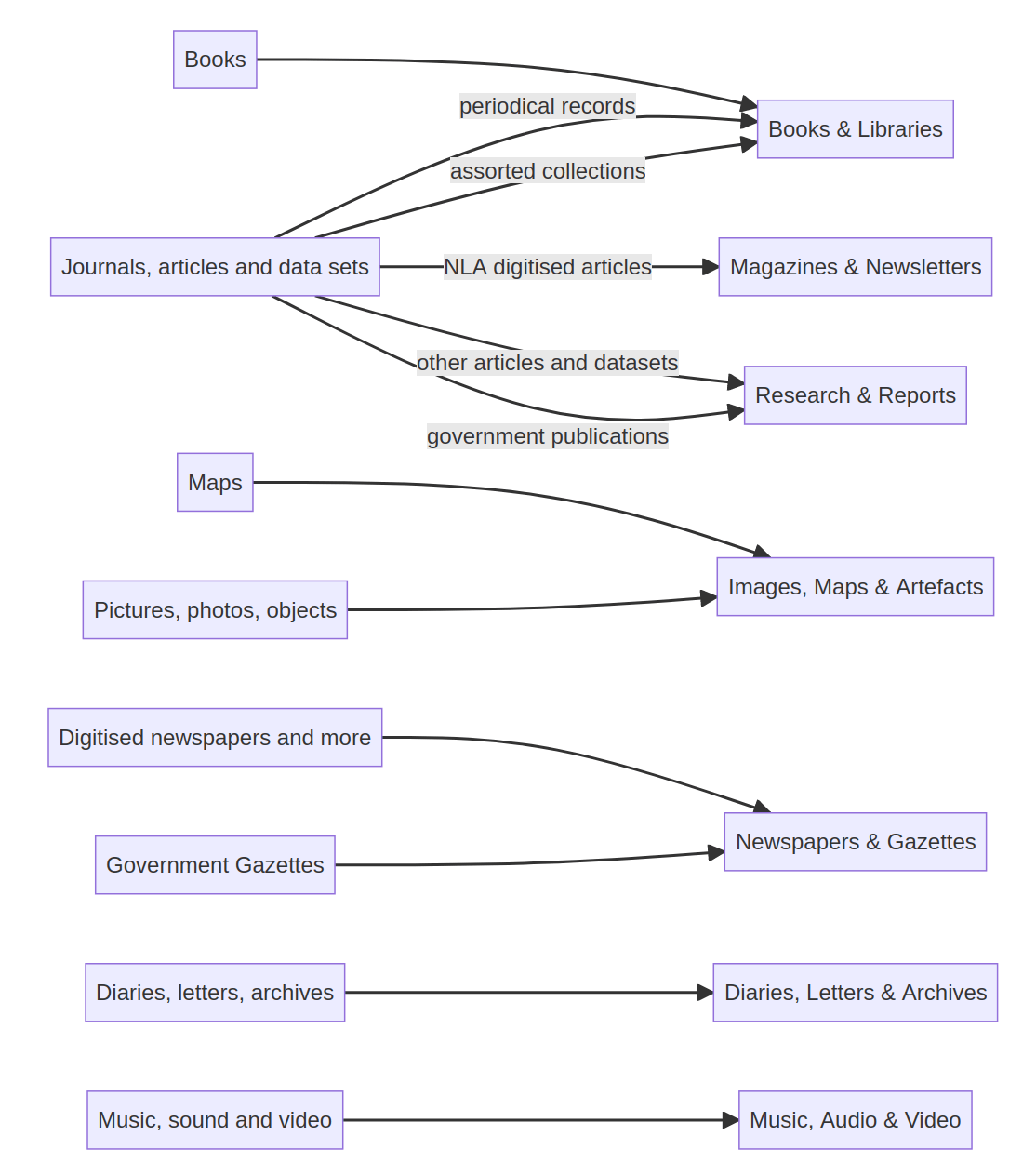
formats by category
categories are containers
categories are contexts for discovery
Trove is designed for discovery not analysis
works and versions
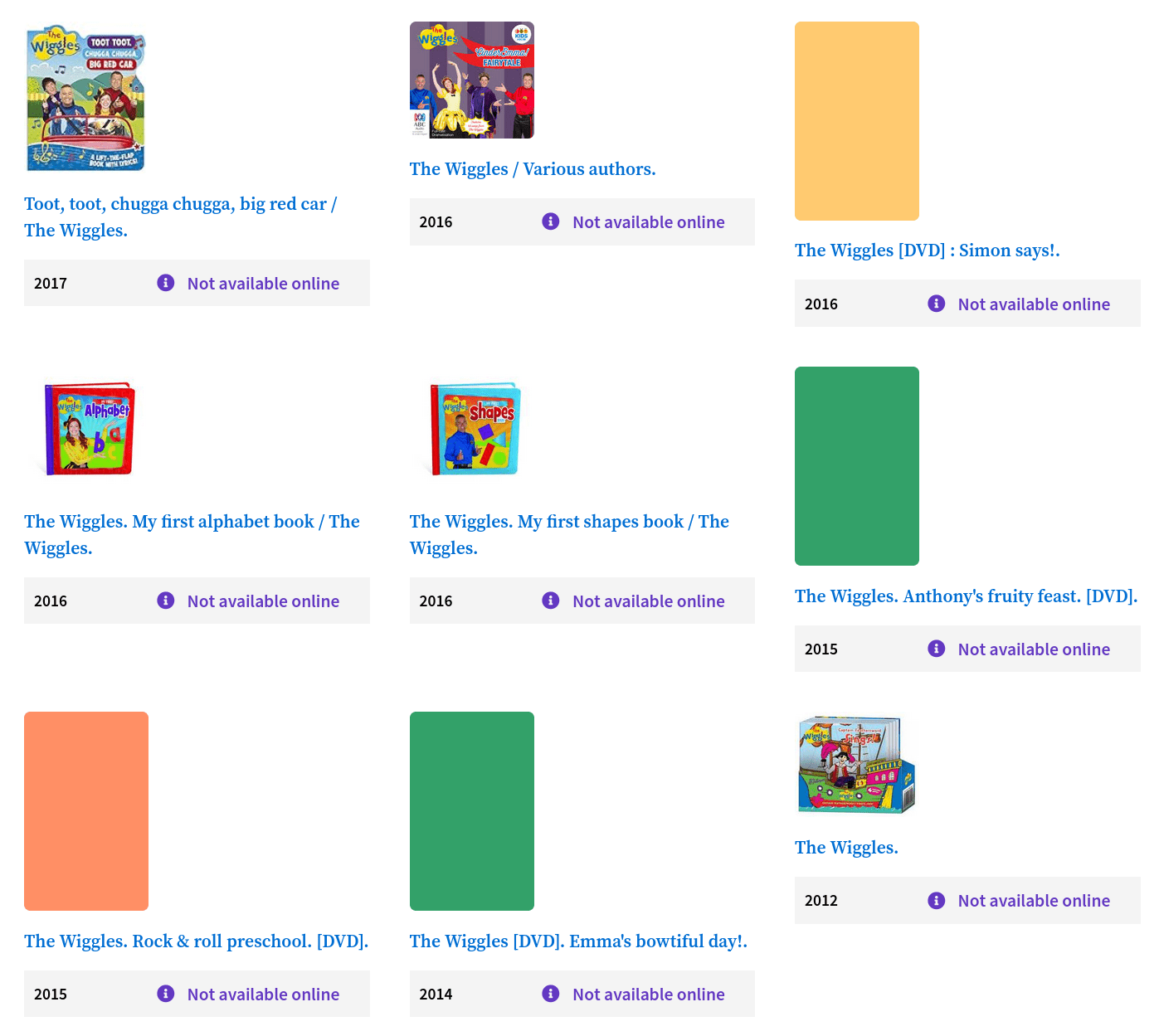
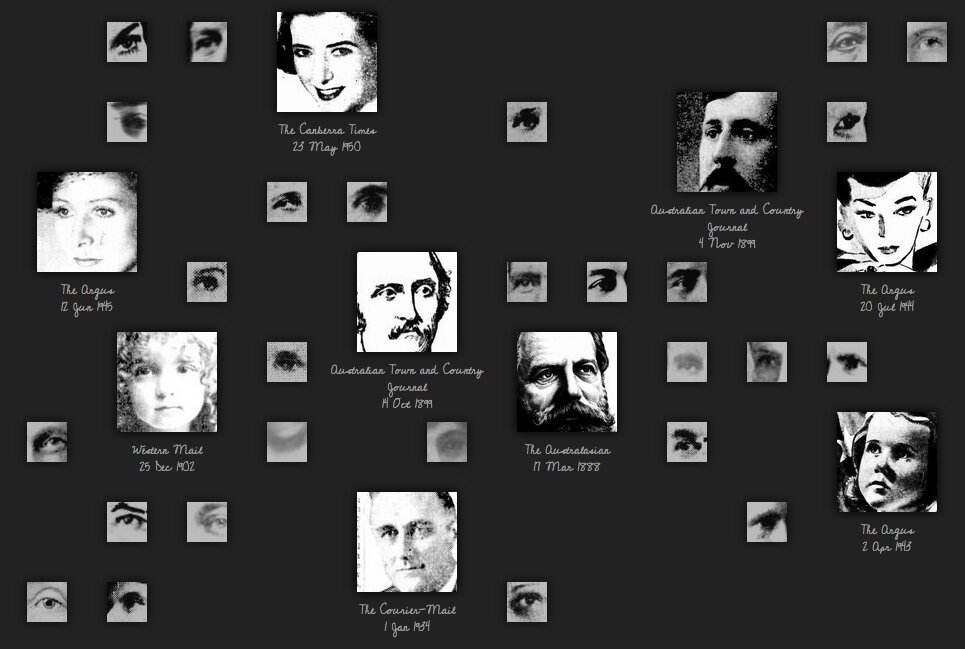
the wrong Wiggles
one work, 106 different press conferences

the same, but different....
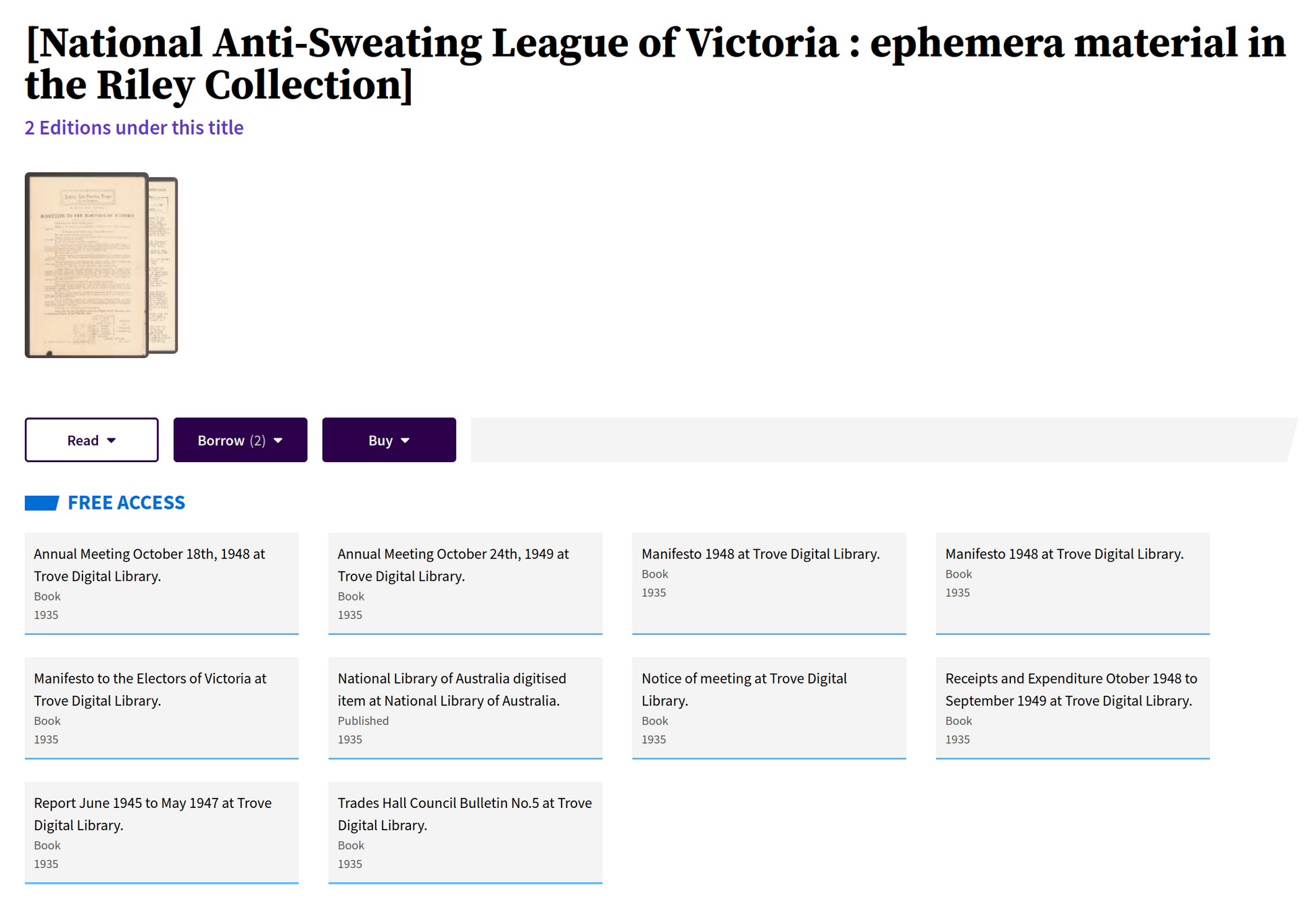
collection items as 'versions'
collections within collections
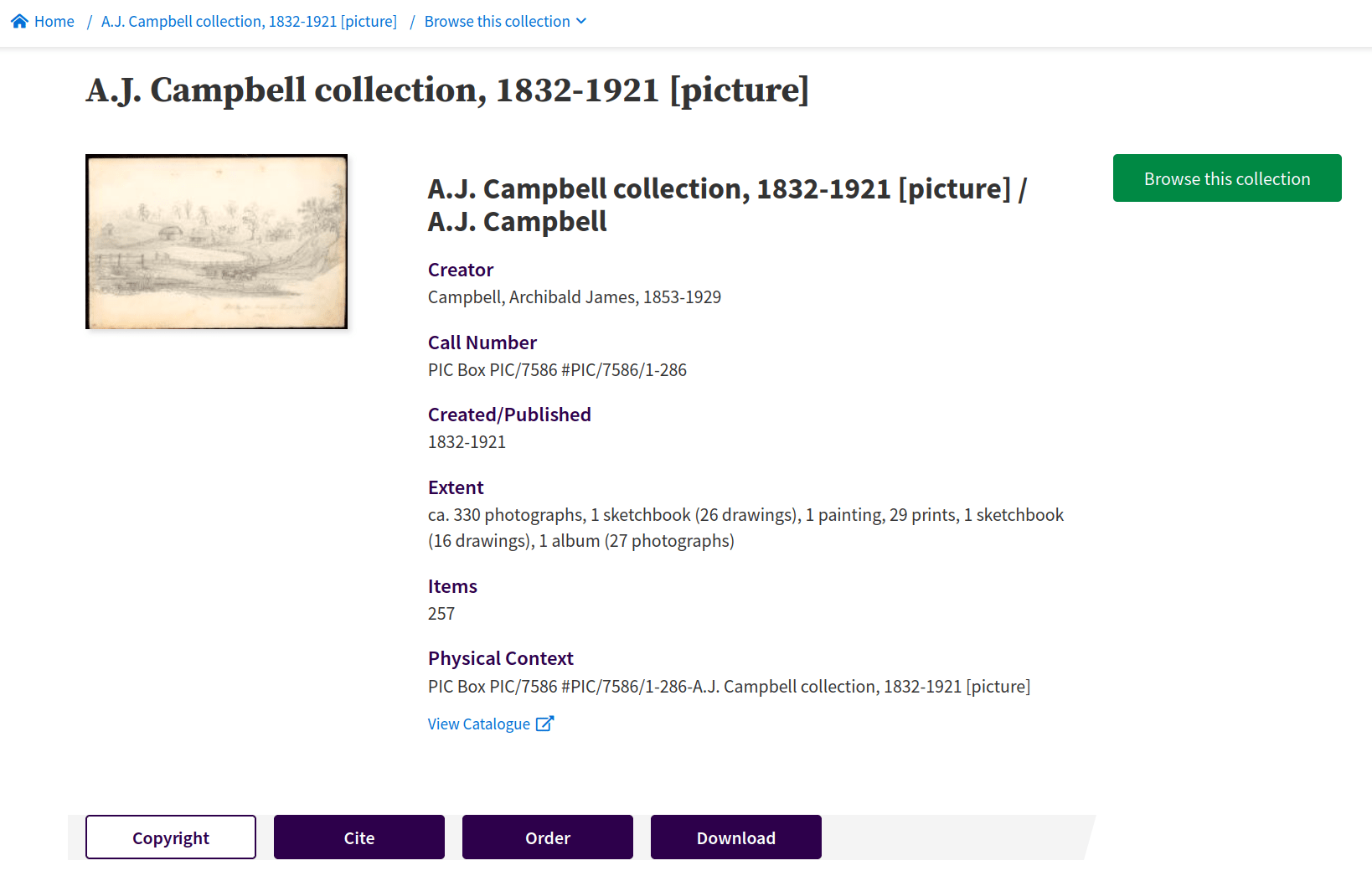
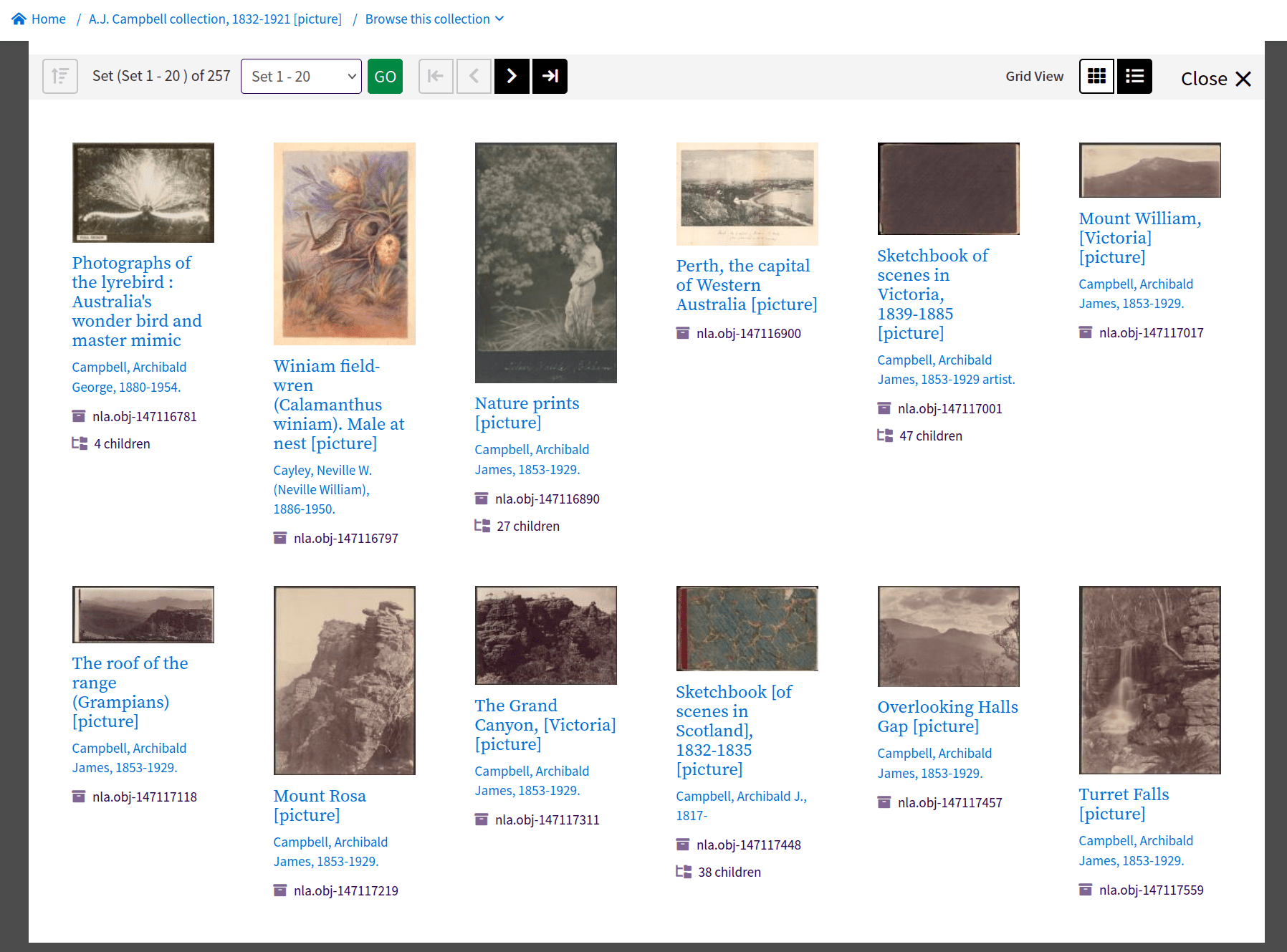
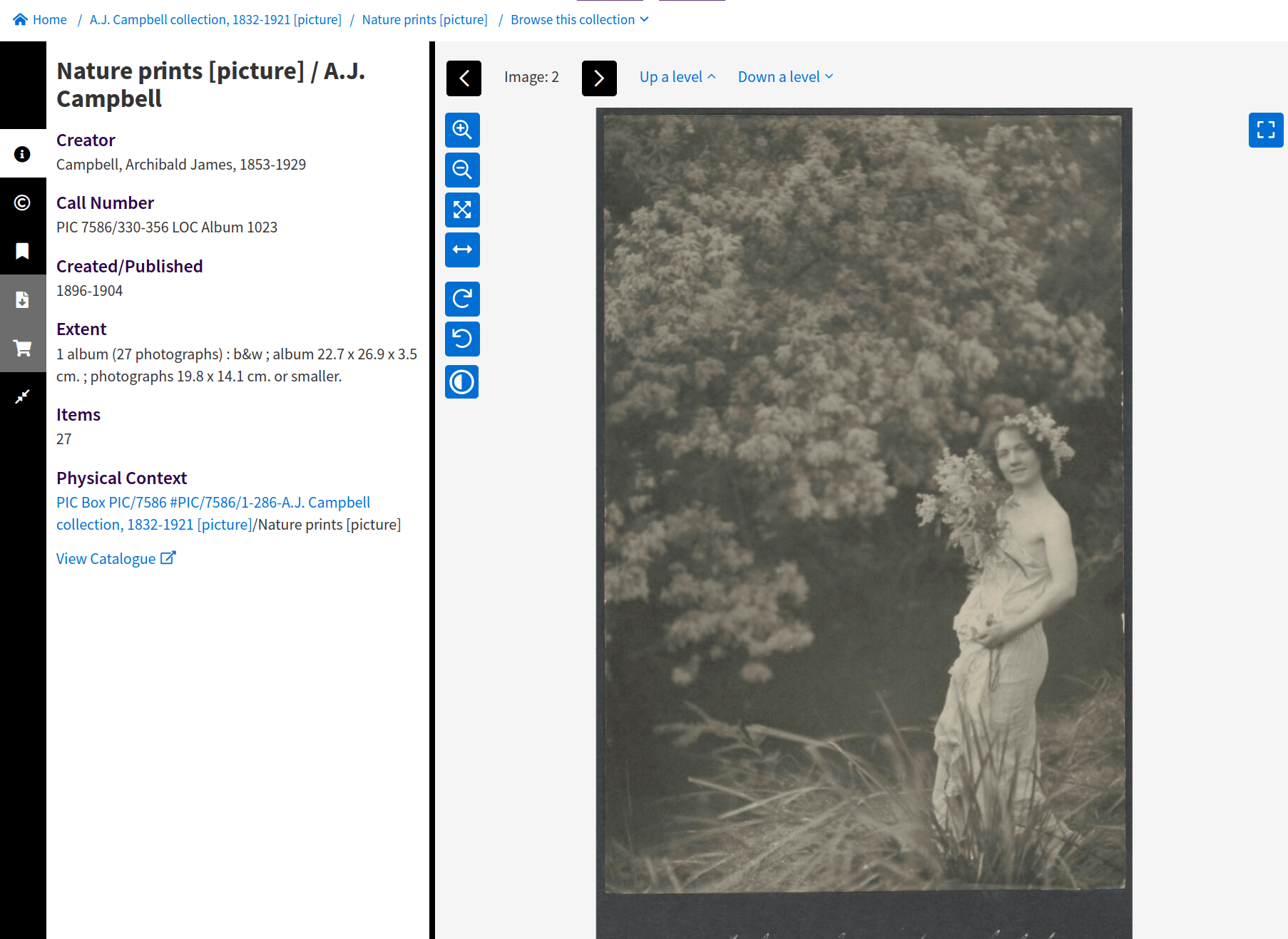
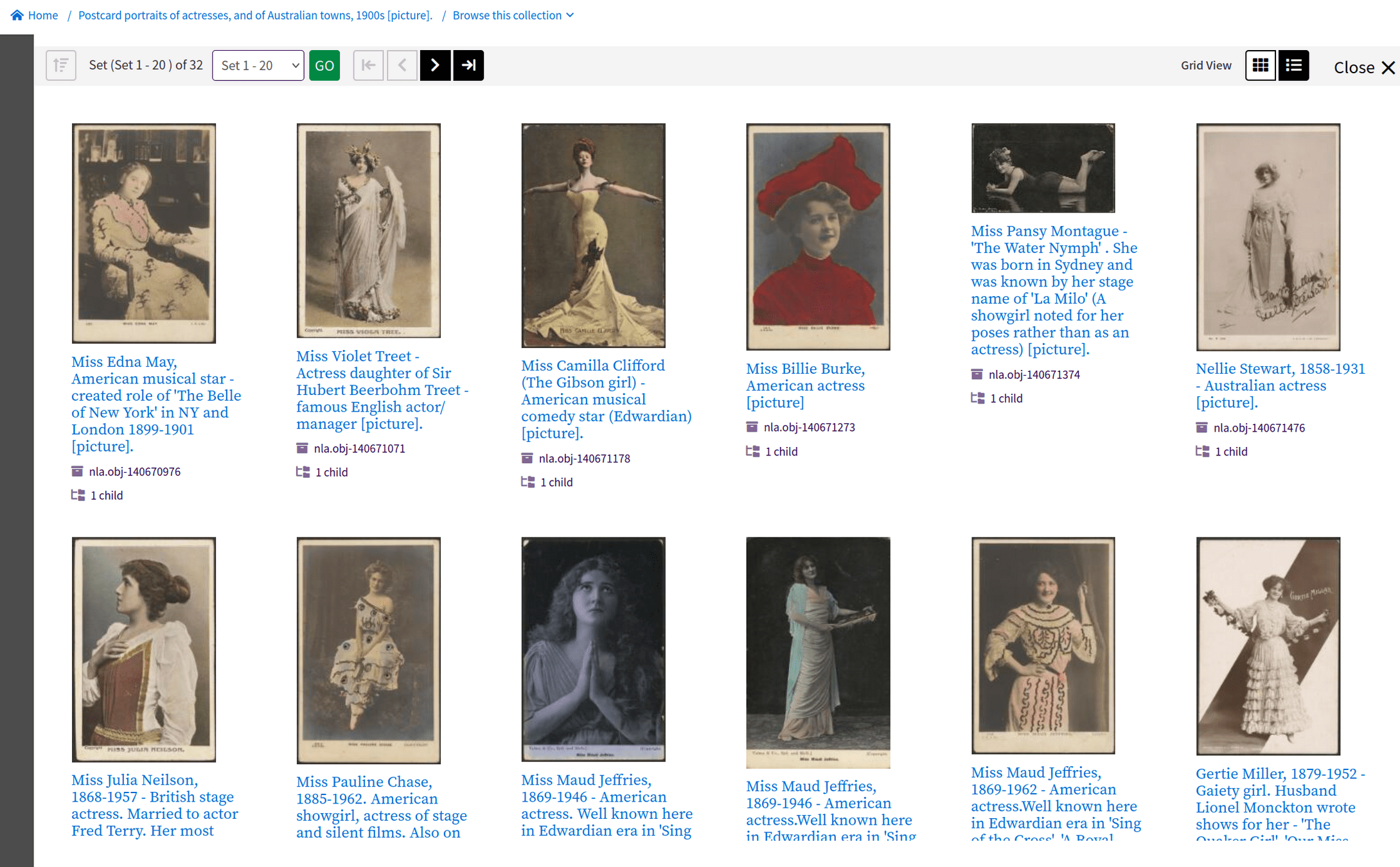
does this matter?
using critically
context?
content?
understanding search
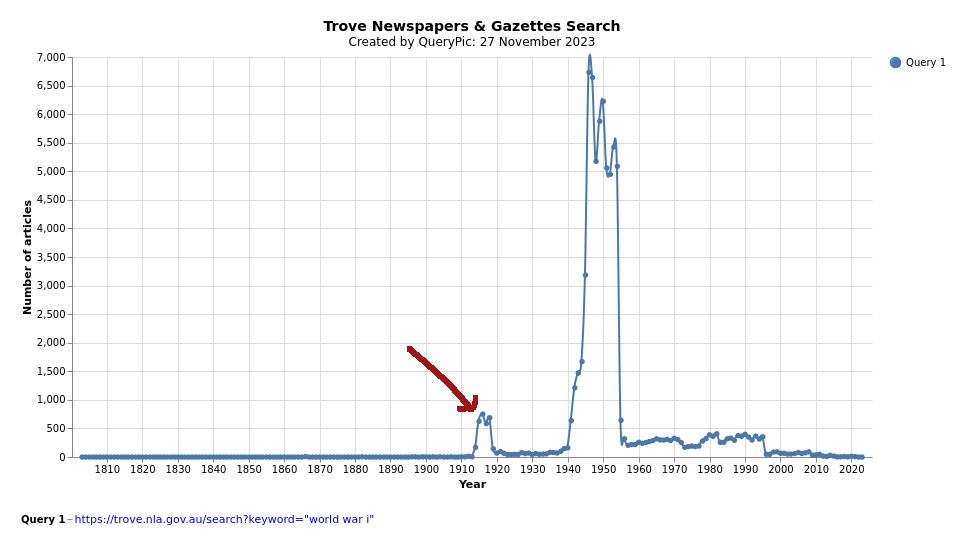
search is a research method
-
Understand the technical context — How does it work? Consult the documentation (and this Guide) to understand your options
-
Be creative and strategic — Solve your puzzle by experimenting and looking for clues in the results
-
Stay critical — Always assume that Trove isn’t telling you everything
simple search isn't...
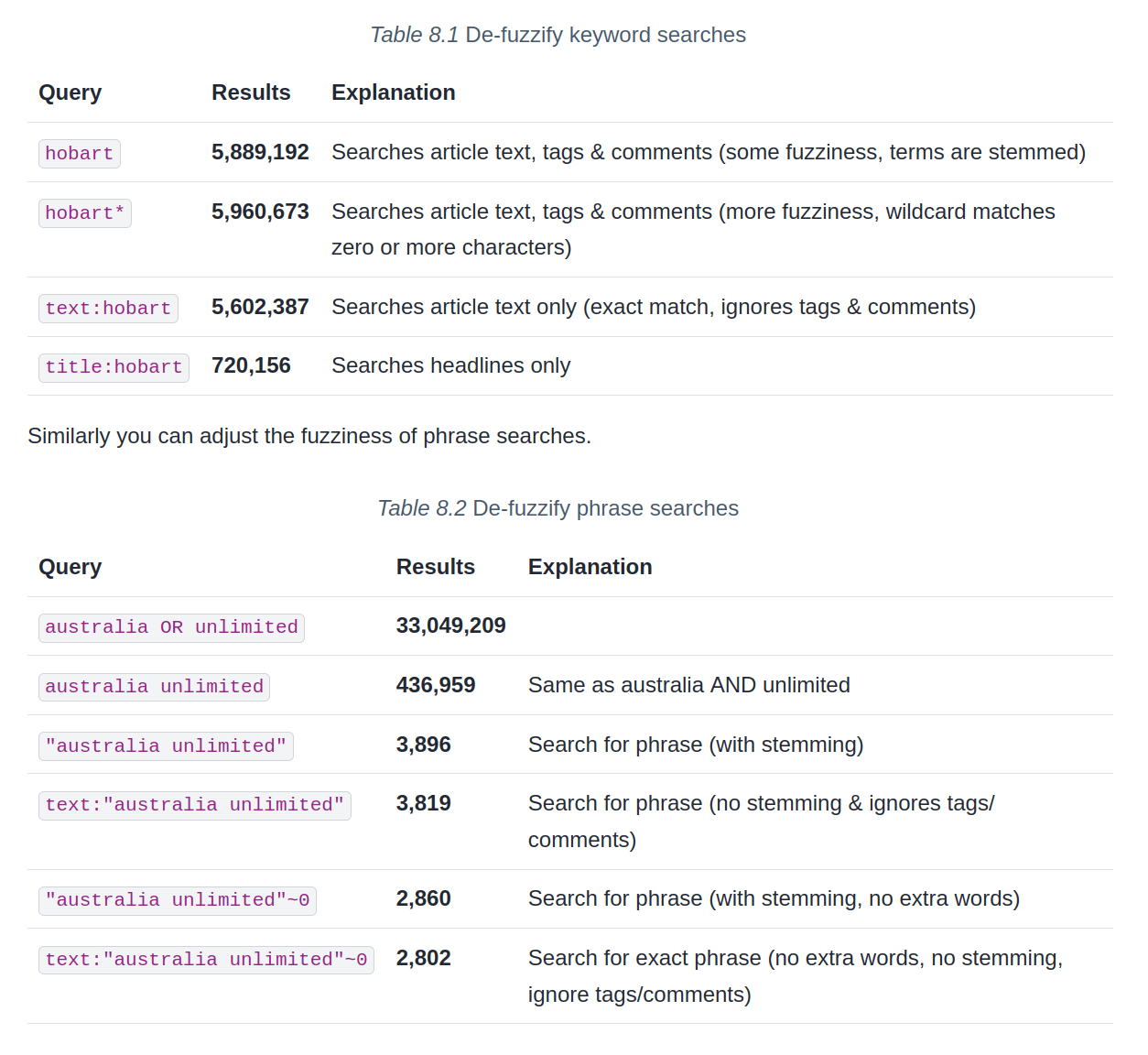
de-fuzzify searches
"isPartOf": [
{
"value": "Australian ephemera collection (Programs and invitations)",
"type": "series"
}
]
using indexes
search the isPartOf values for "ephemera"

date searches
what are we searching?
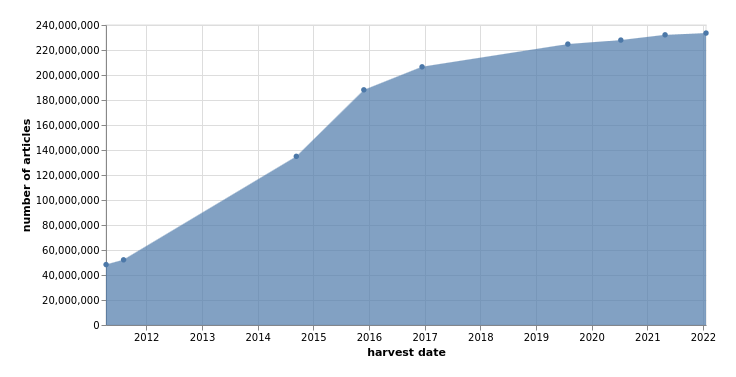
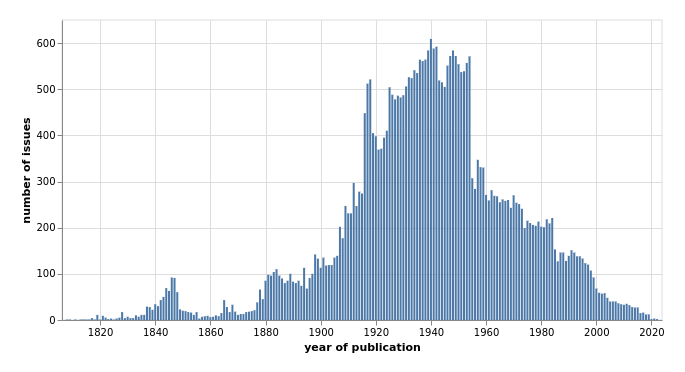
change over time
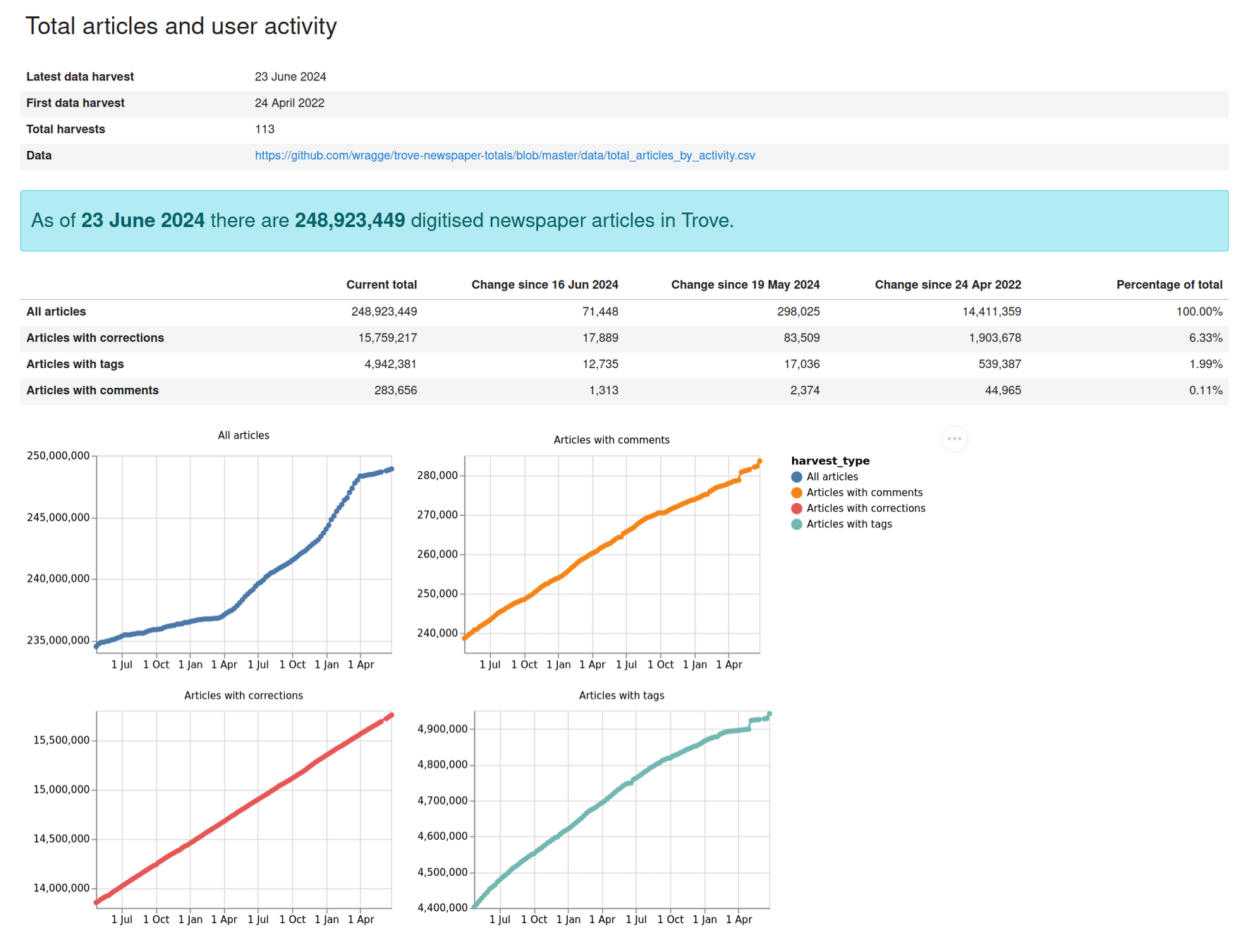
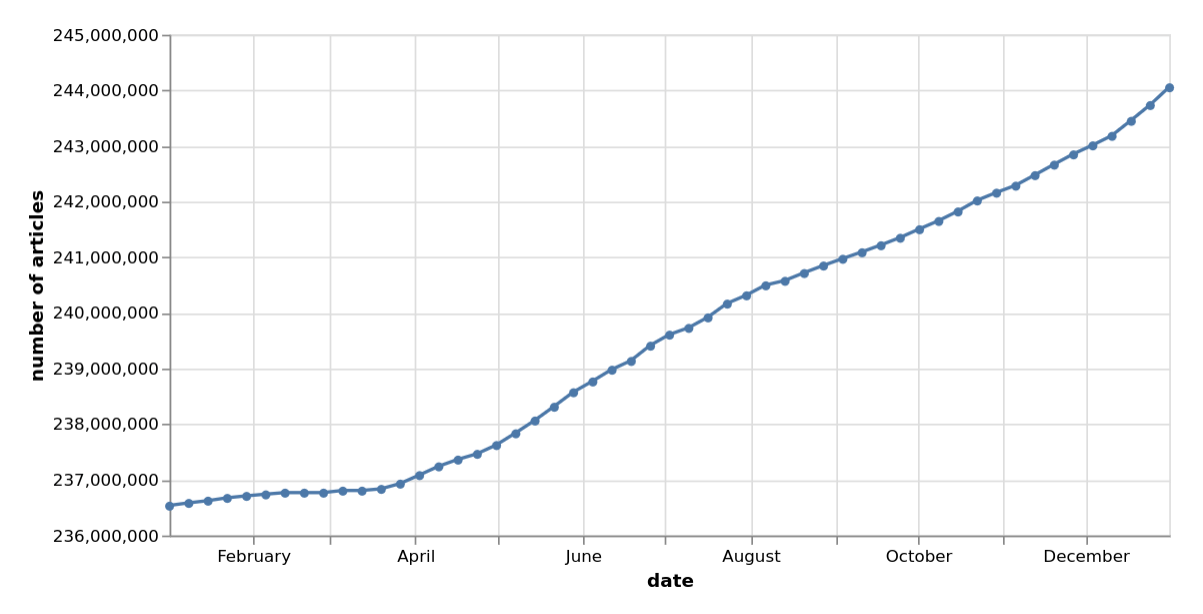
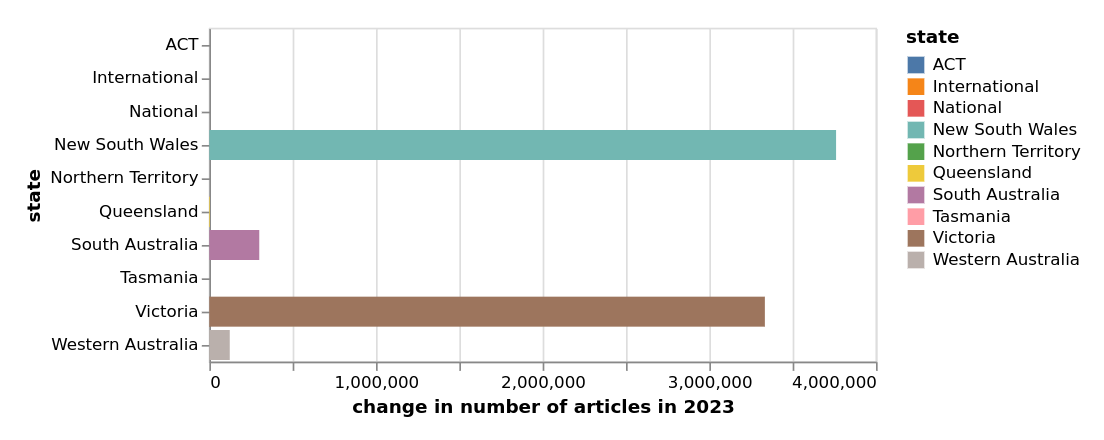
7,518,764 articles added in 2023
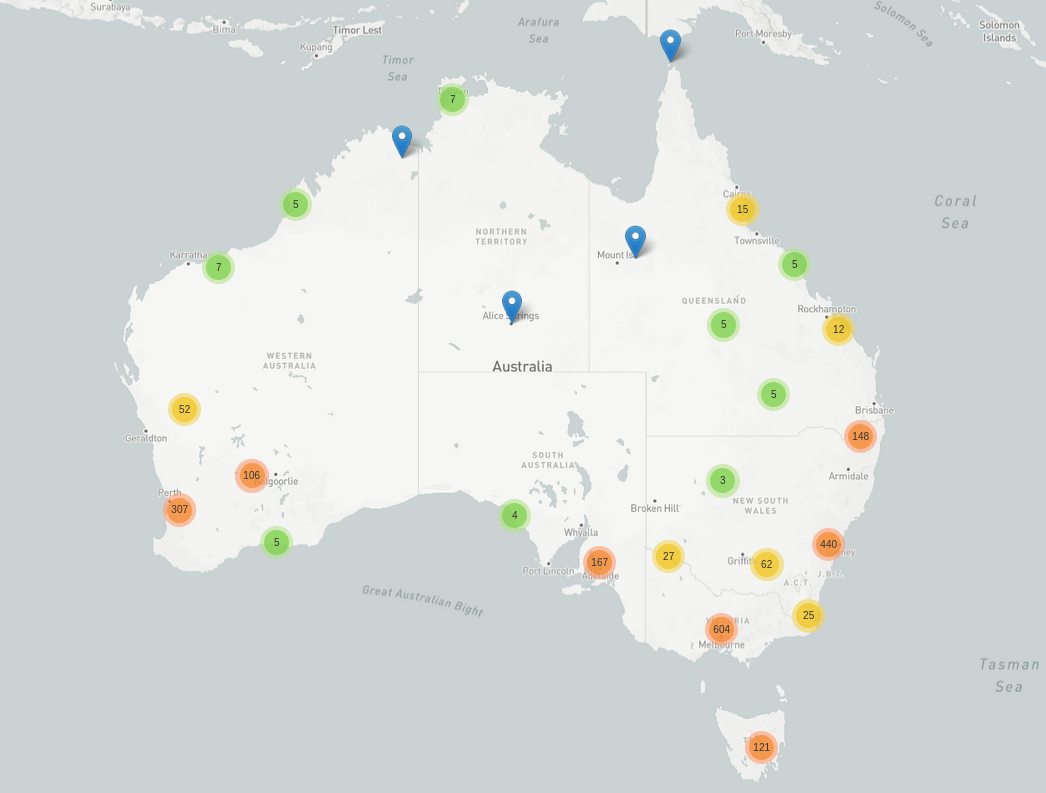
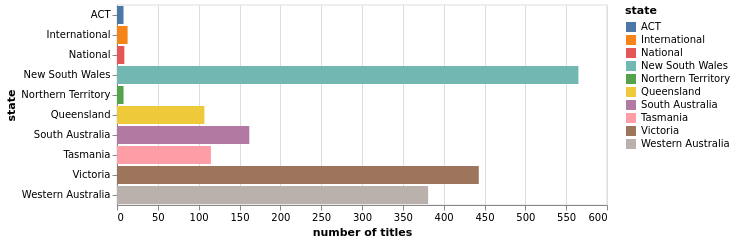
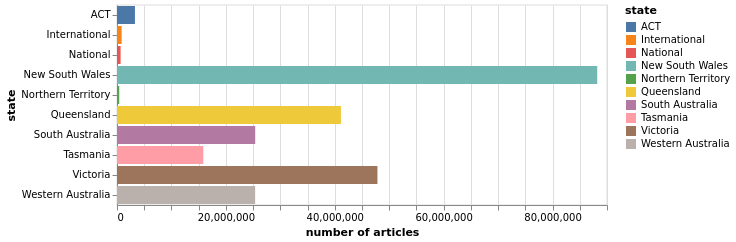
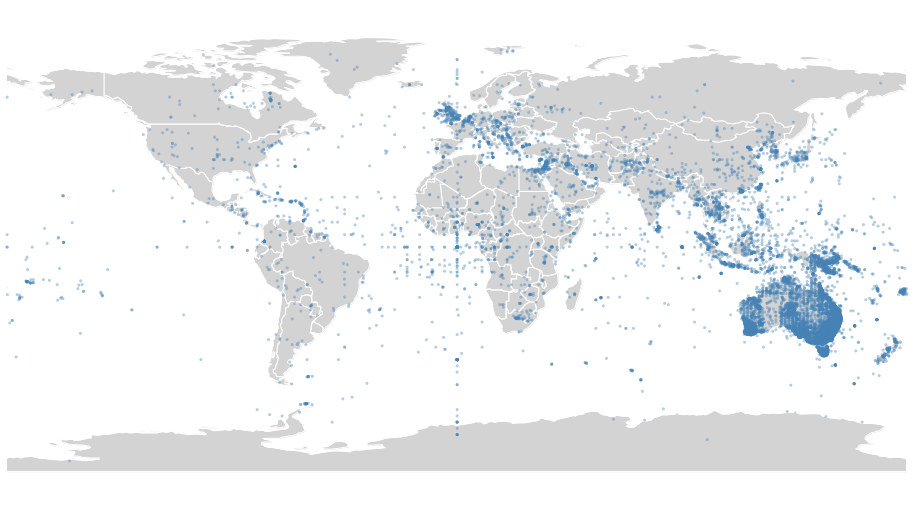
newspaper locations

what's missing?
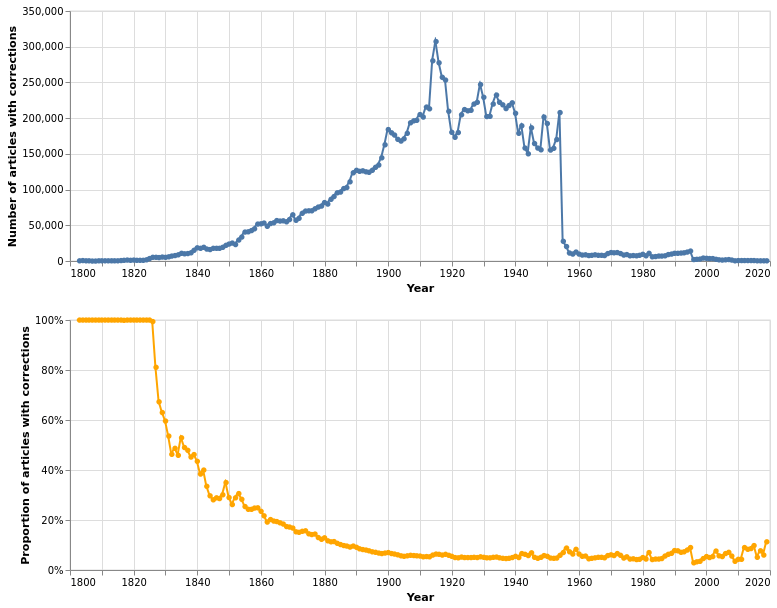
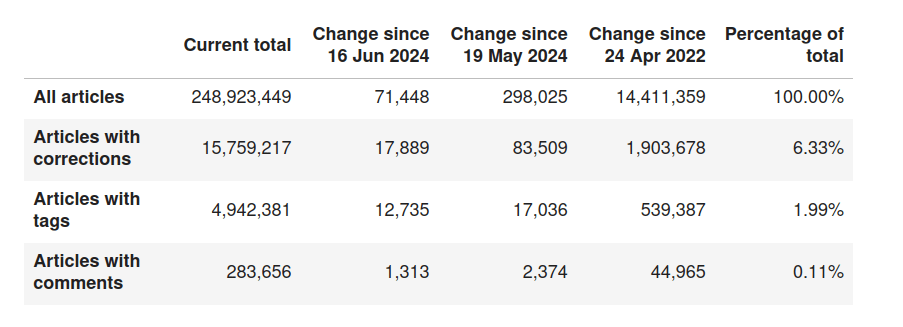
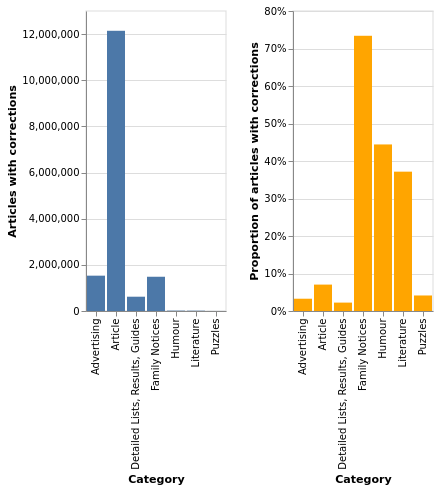
OCR corrections
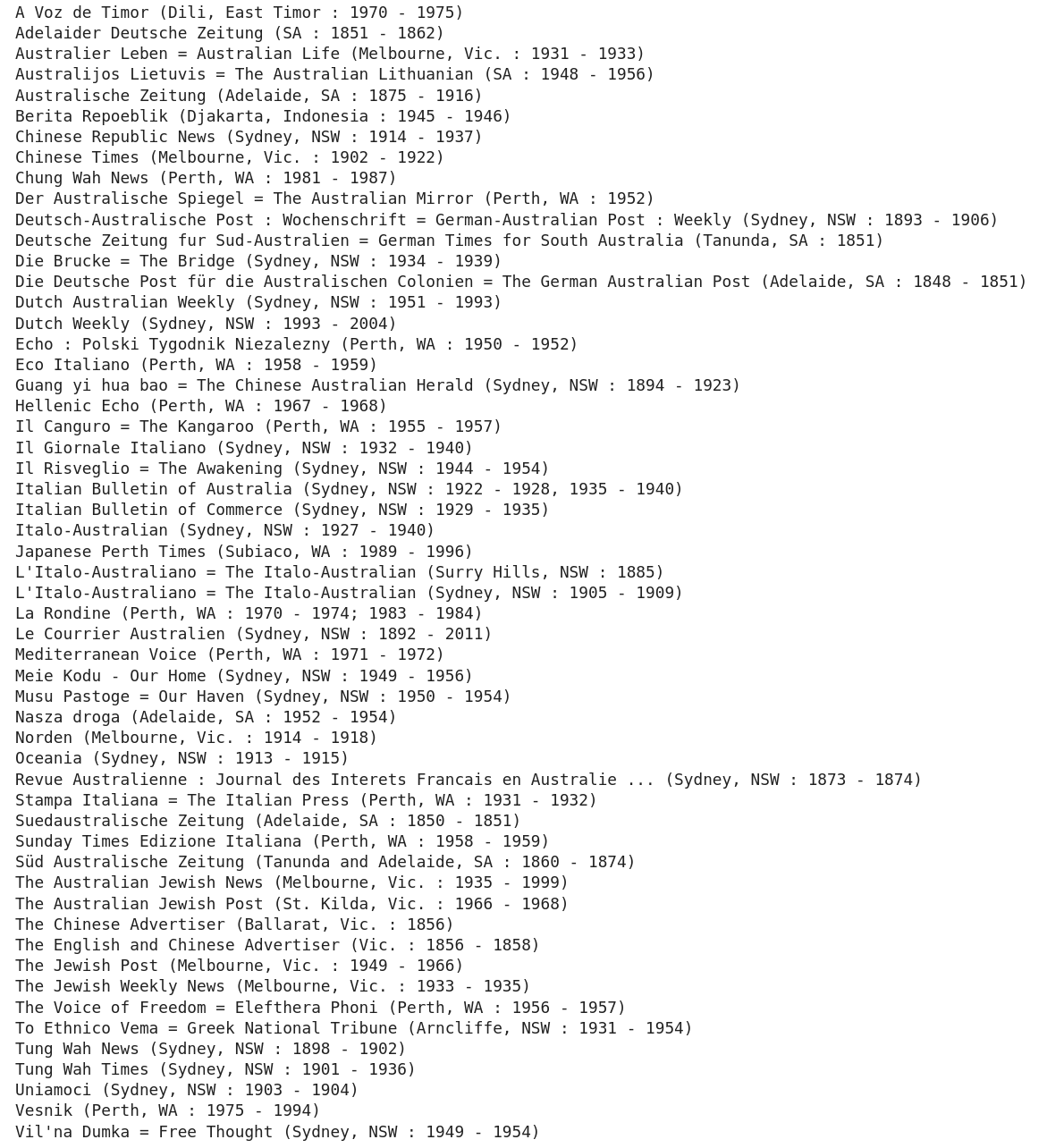
non-English language newspapers
not just newspapers
- 20,000 books (and ephemera)
- 900 periodicals containing 37,000 issues
- 30,000 maps
- 24,000 Parliamentary Papers
- 6,000 oral histories
- 85,000 web page titles
- 7,000 born-digital periodicals containing 150,000 issues
more than...
where are they?

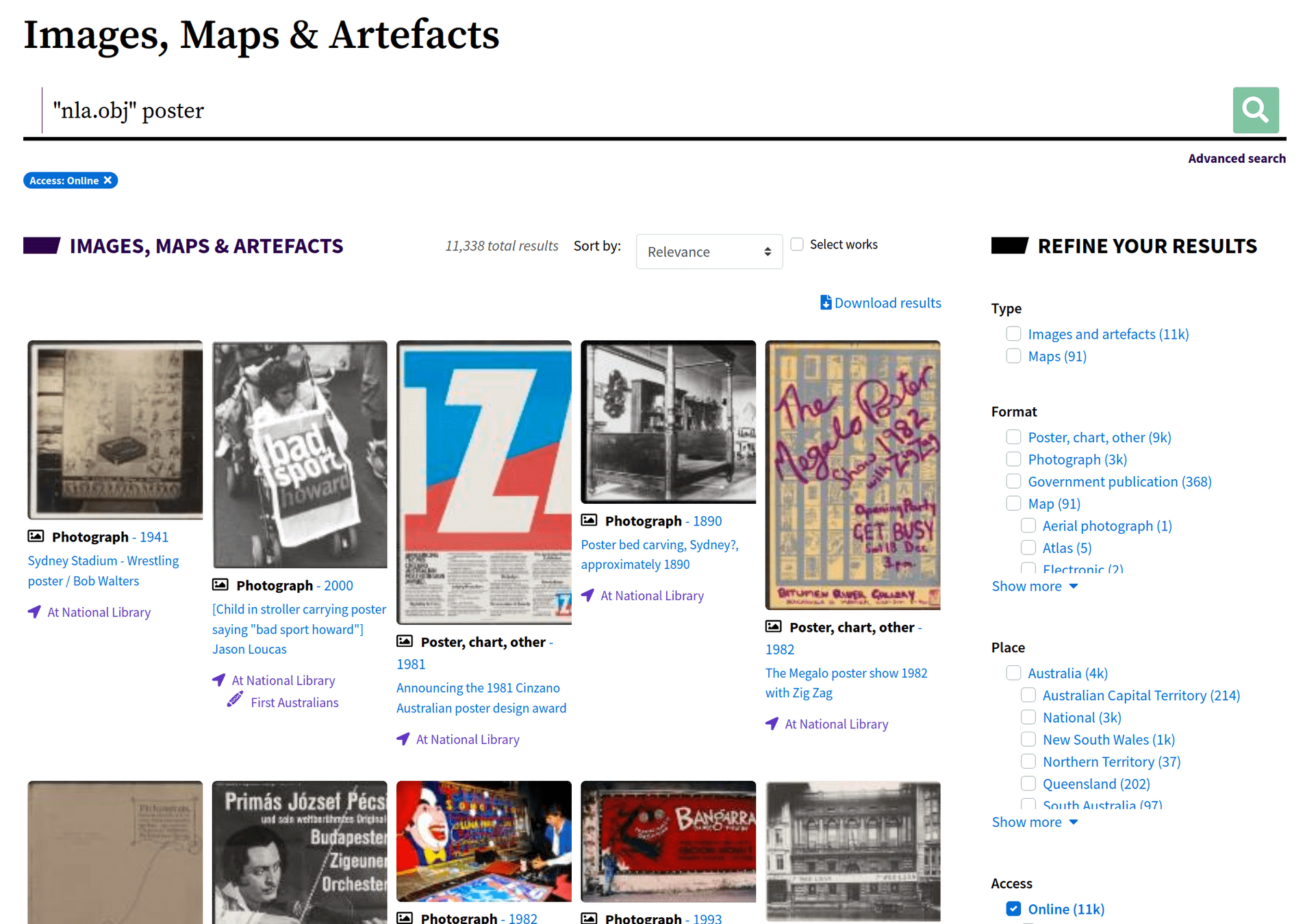
try it!
- go to the Images, Maps & Artefacts category
- search for
"nla.obj"(with the quotes) - select 'Online' from the 'Access' facet
- add additional keywords or facets!
- for example here are digitised posters
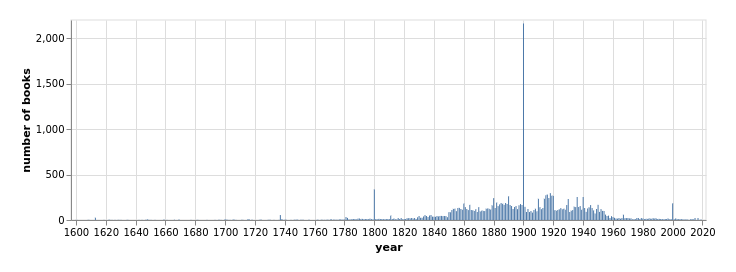
books
- 21,218 'books'
- 17,695 with OCR
- 1,473,339 pages

periodicals
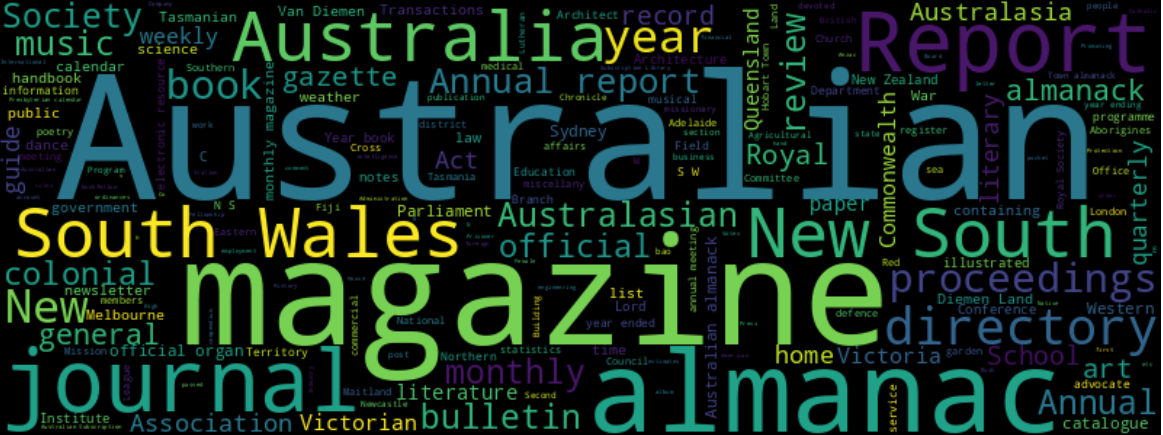
- 908 titles
- 37,015 issues


- 6,202 online
- 1,781 transcripts
- 15,107 hours
oral histories
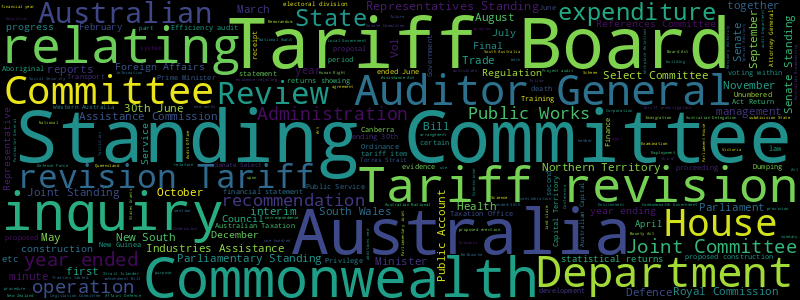

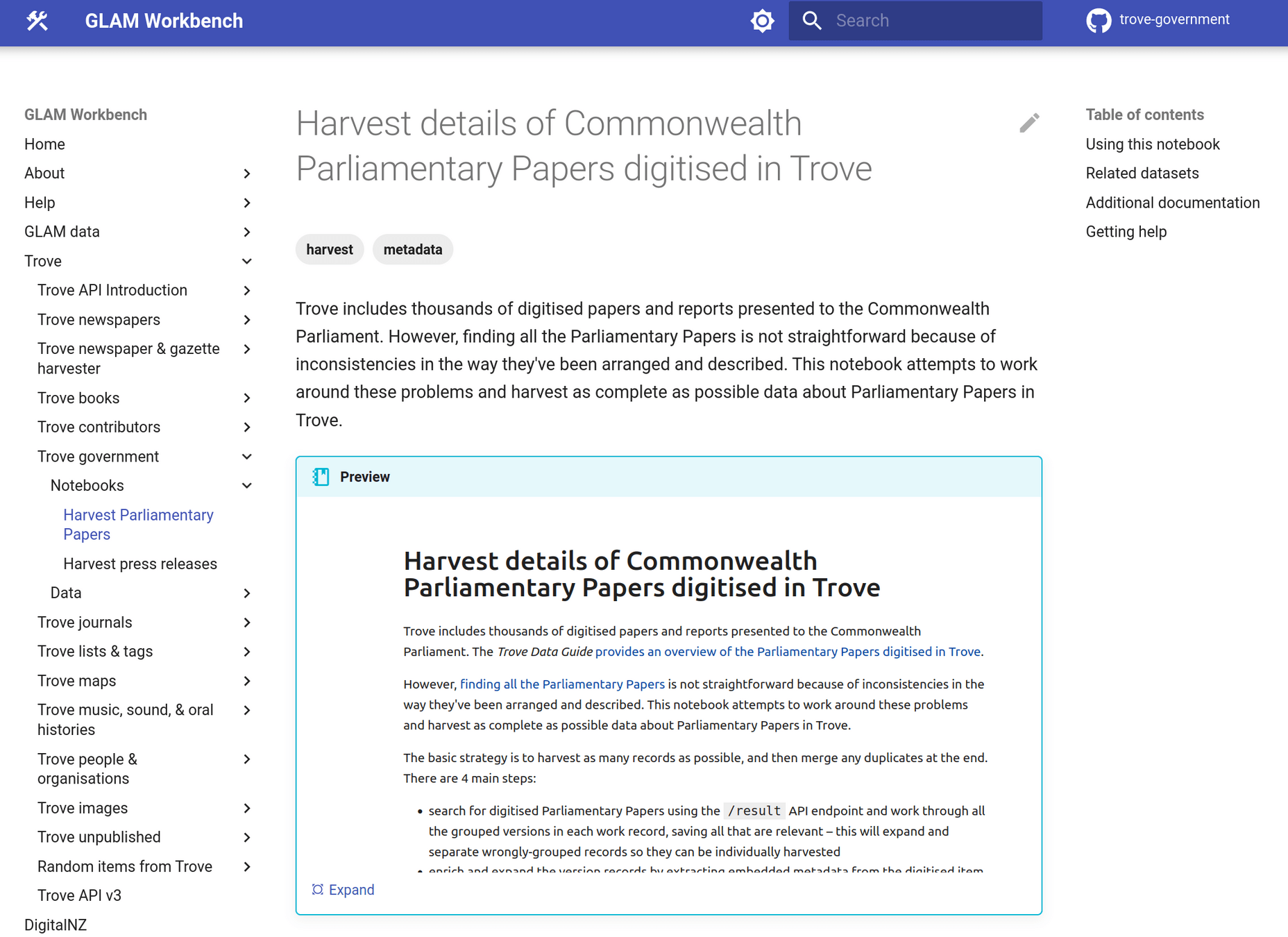
Parliamentary Papers
- 24,990 publications
- 2,448,522 pages
- 4 gb of OCRd text

Finding Parliamentary Papers
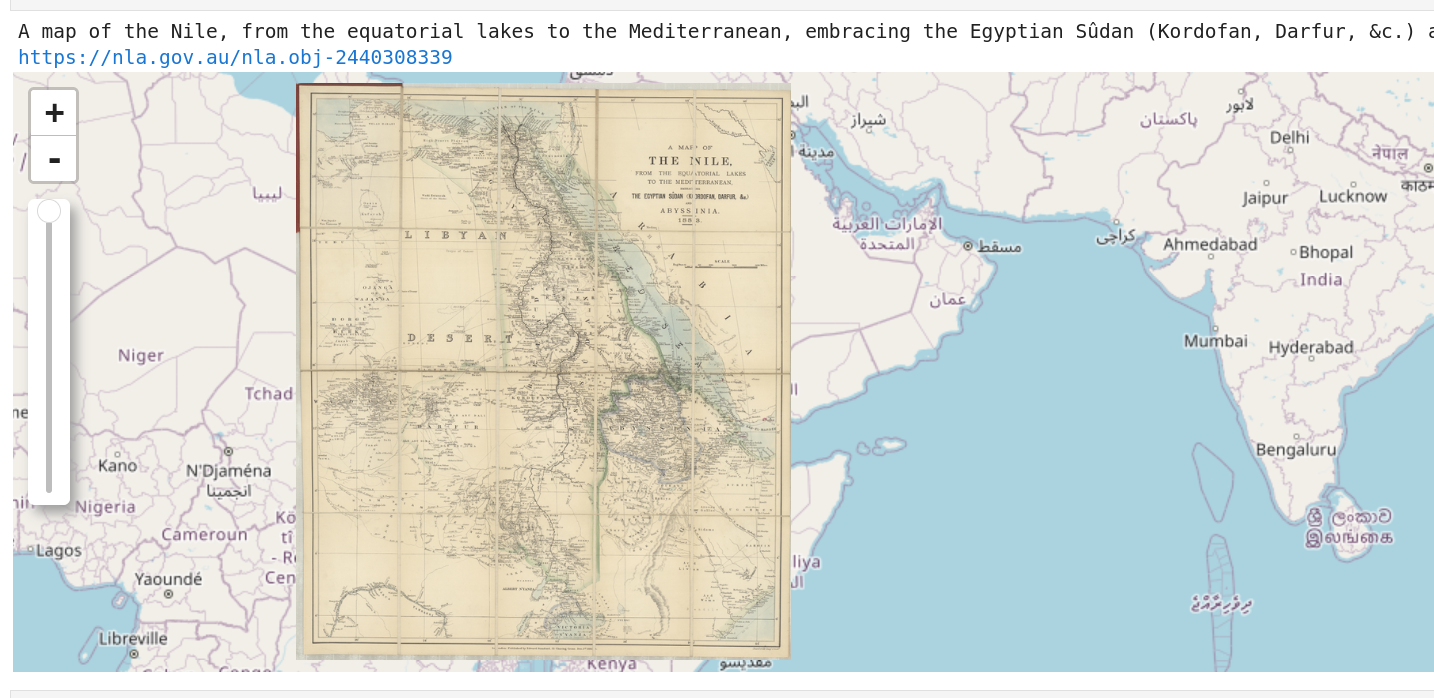
maps
- 35,042 'single' maps
- 30,344 high-res TIFFs
- 14.41 TB of images
- 28,205 with coordinates
NED periodicals
- 7,973 periodicals
- 156,151 issues
- 154,976 PDFs
- 138,557 full access
🔭 explore
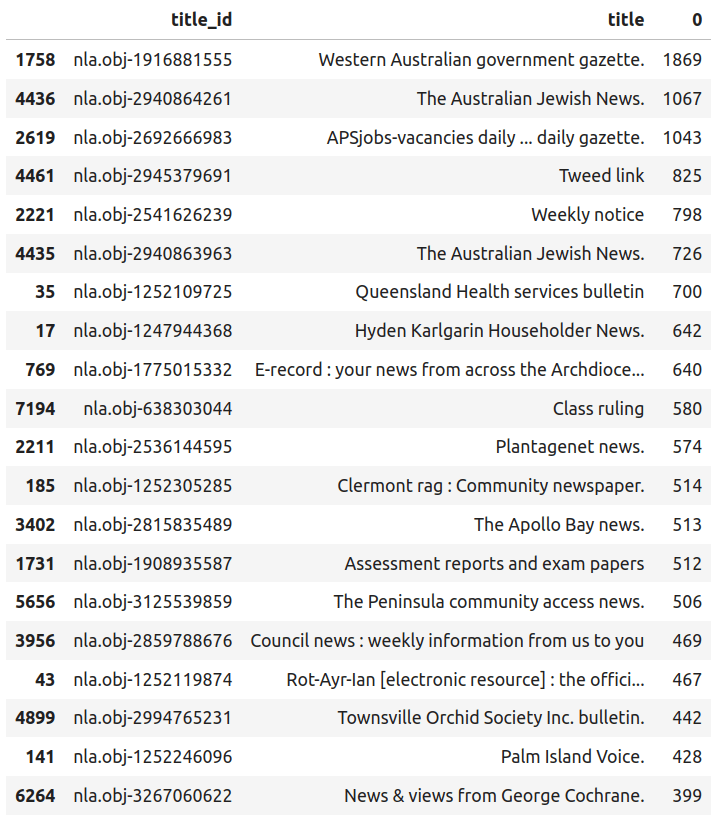
websites
- > 8 billion pages
- 87,757 selected titles
- 149 subjects
- 1,920 collections
🔭 explore
BREAK
what data?
- metadata
- text
- images
- sound
- born digital objects
- user generated
- system statistics
{
what data?
metadata
{
- catalogue entries
- authority records
- library holdings
- results of processing (eg OCR coordinates)
text
{
- created by OCR / HTR
- corrected by users
- extracted from web pages
- oral history transcripts
- titles, abstracts
images
{
- created by digitisation (photos, maps, book pages, manuscripts)
- born digital (via Flickr)
sound
{
- digitised and born digital oral history recordings
born digital
{
- web pages (including images, PDFs, videos)
- web harvest metadata
- ePubs (via legal deposit)
user generated
{
- tags
- comments
- lists
- corrections
system stats
{
- infer totals from search results
- contributors
- exploring scale
- analysing content
- annotation and enrichment
- creating collections
beyond Trove's web interface 🚀
why data?

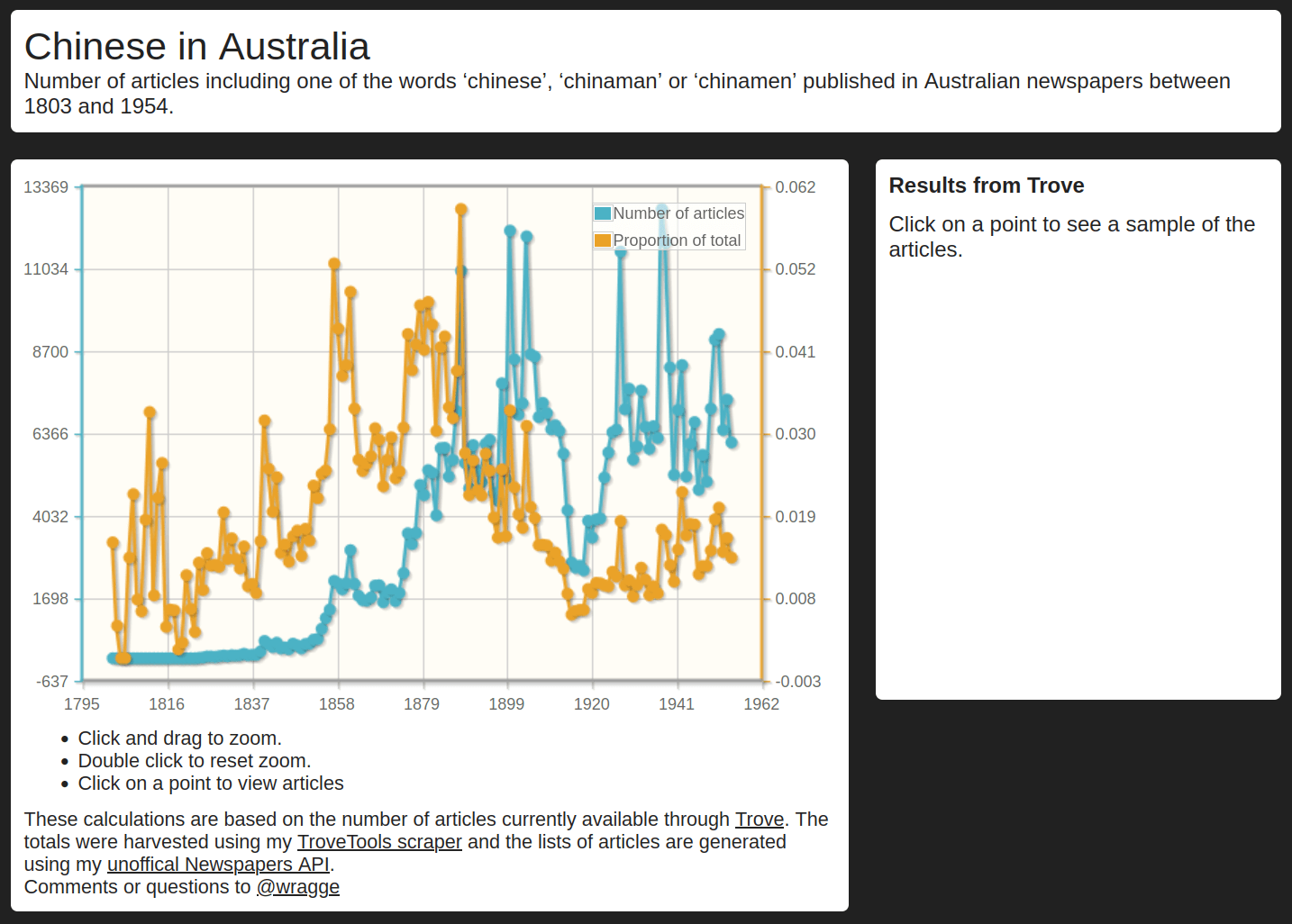
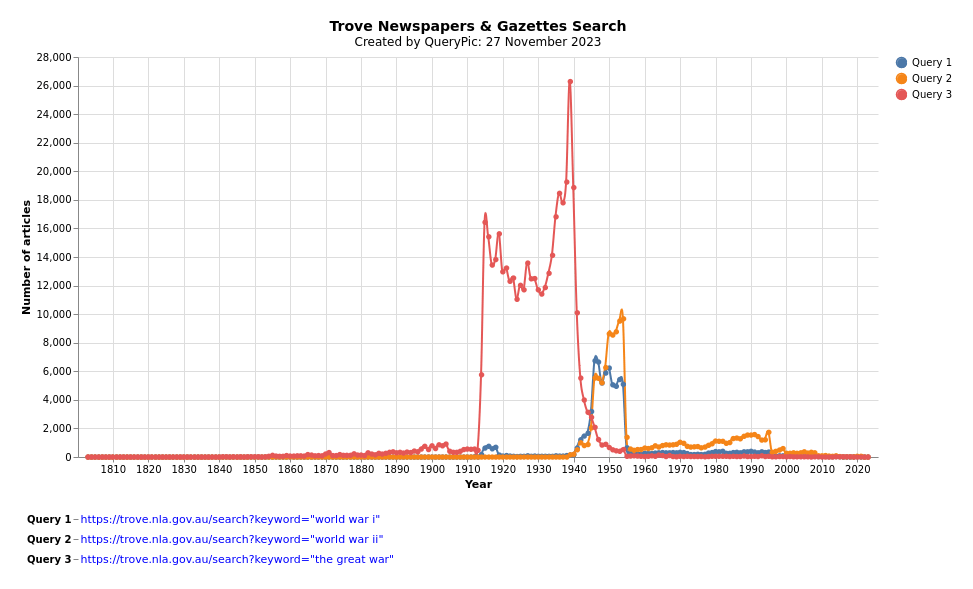
Querypic
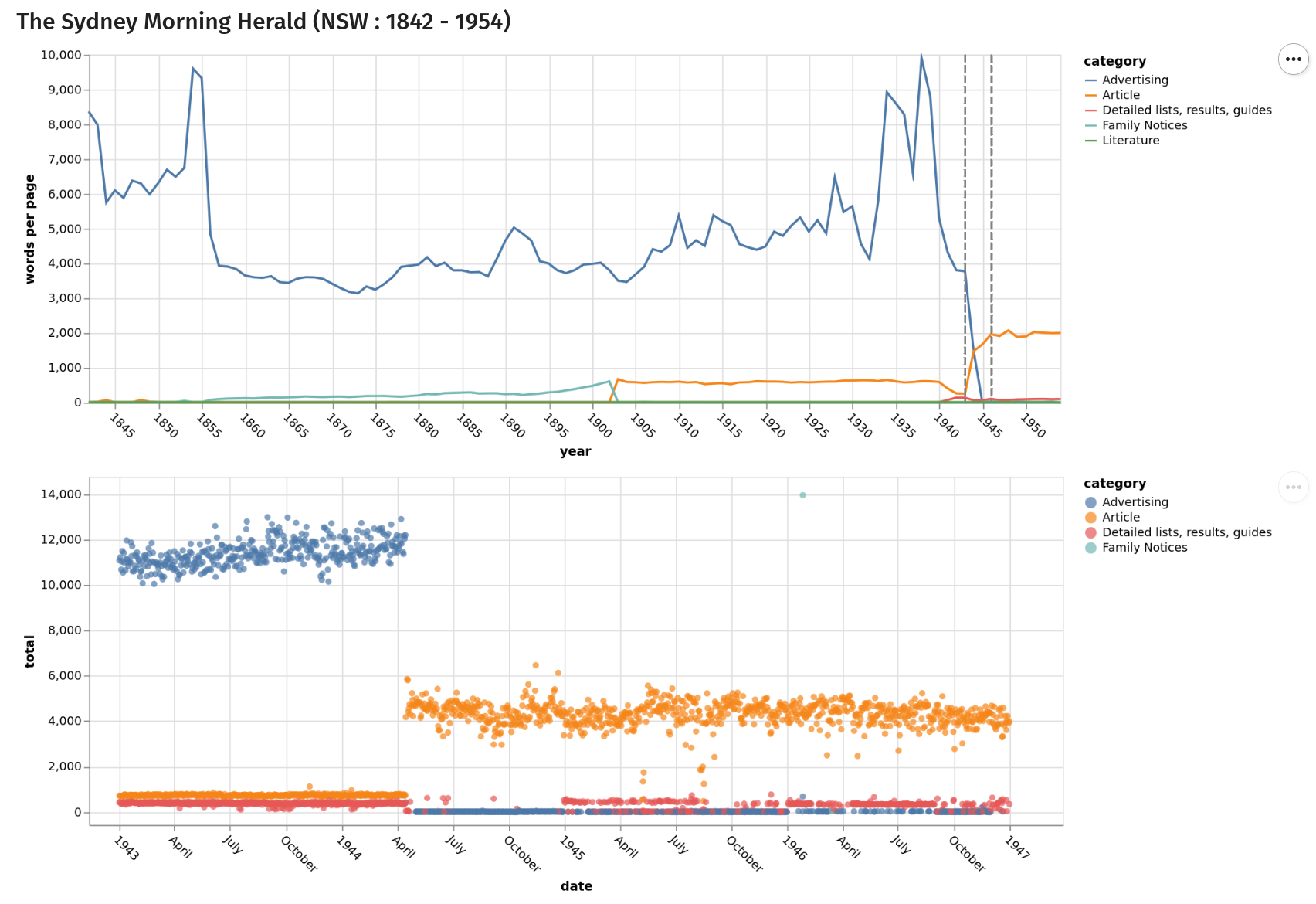
19 million articles
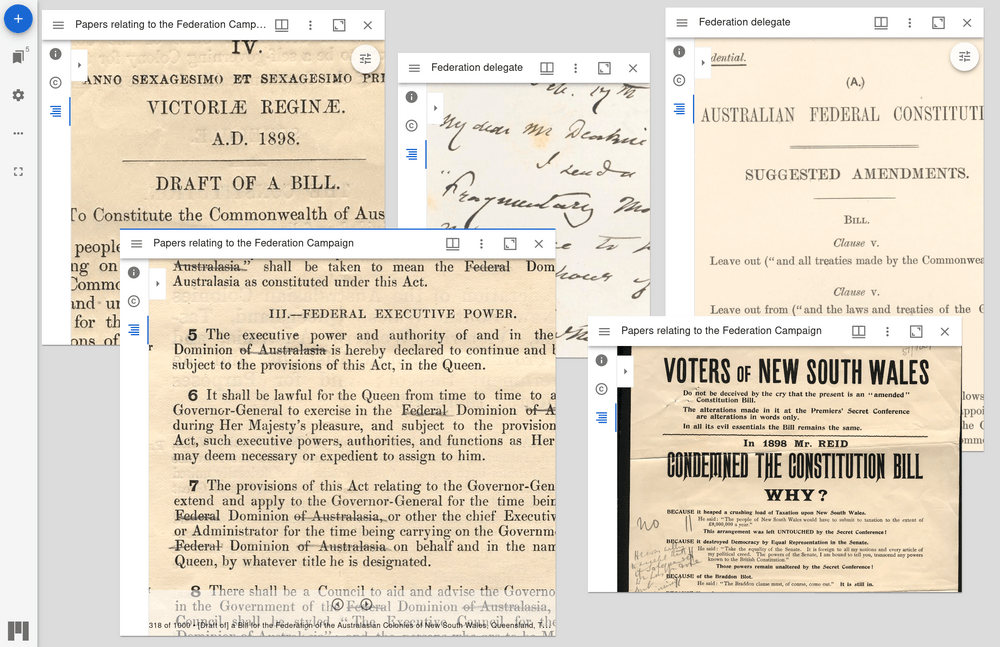
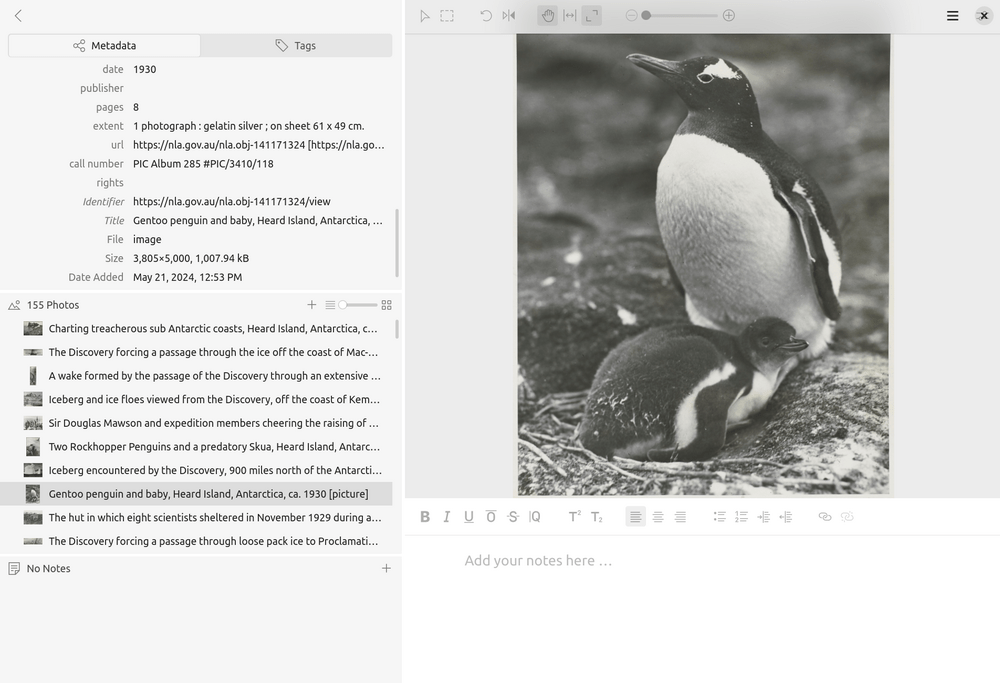
image workspaces
try it!

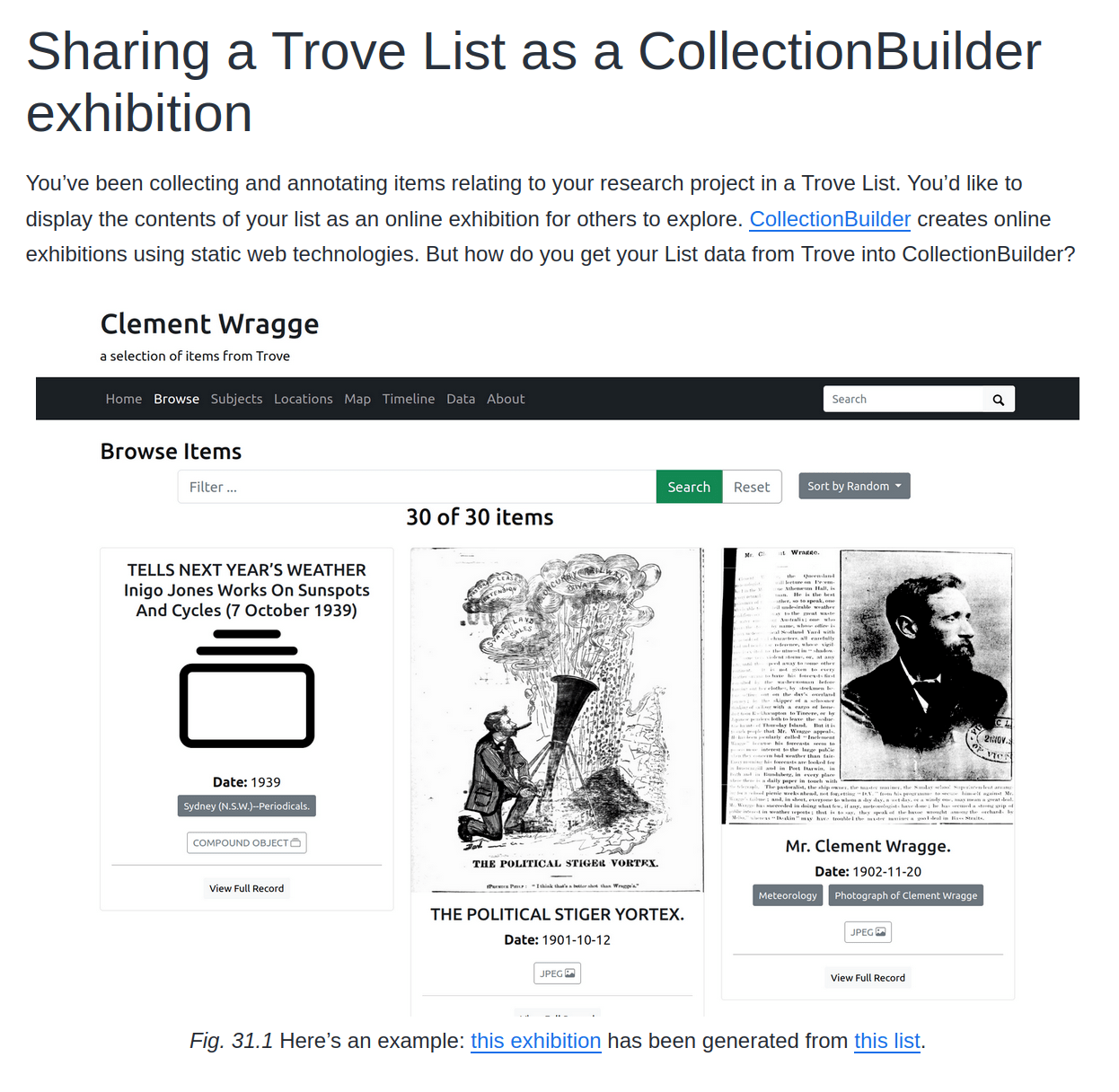
accessing data
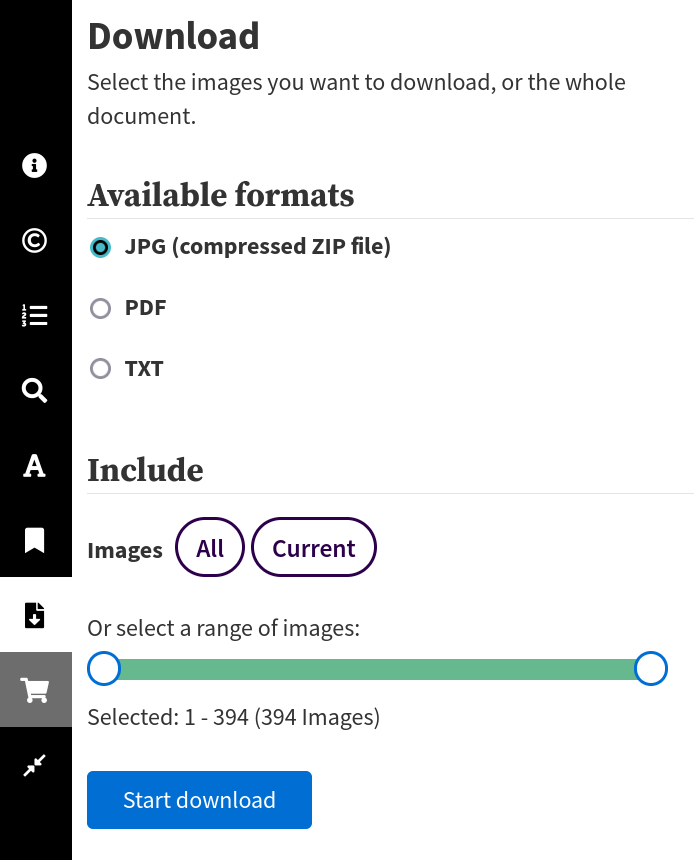
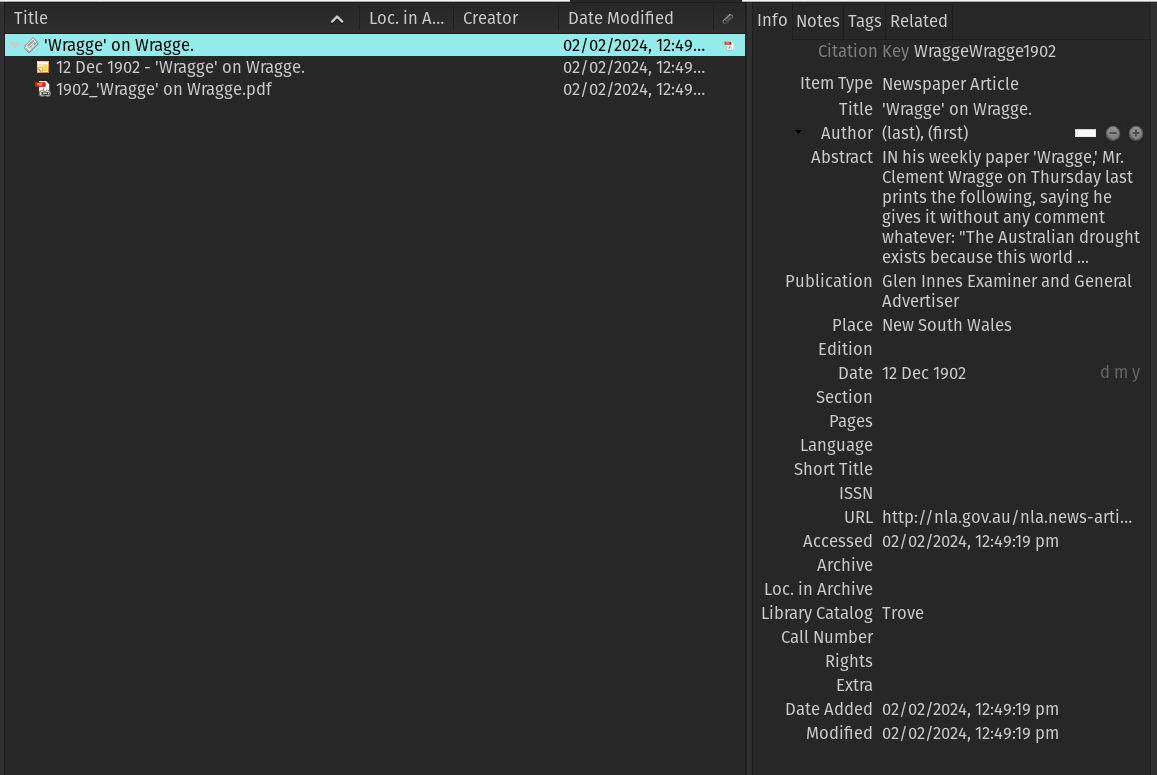
data from the web interface

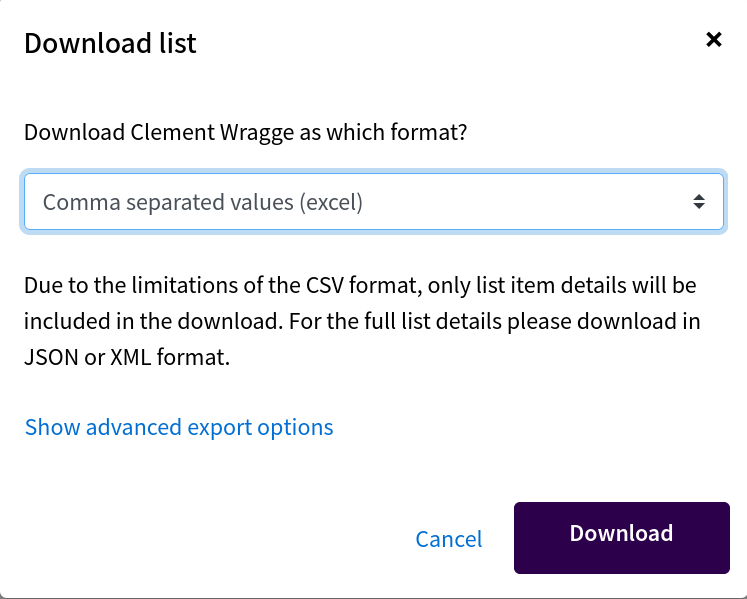
downloading as 'image' delivers an HTML page

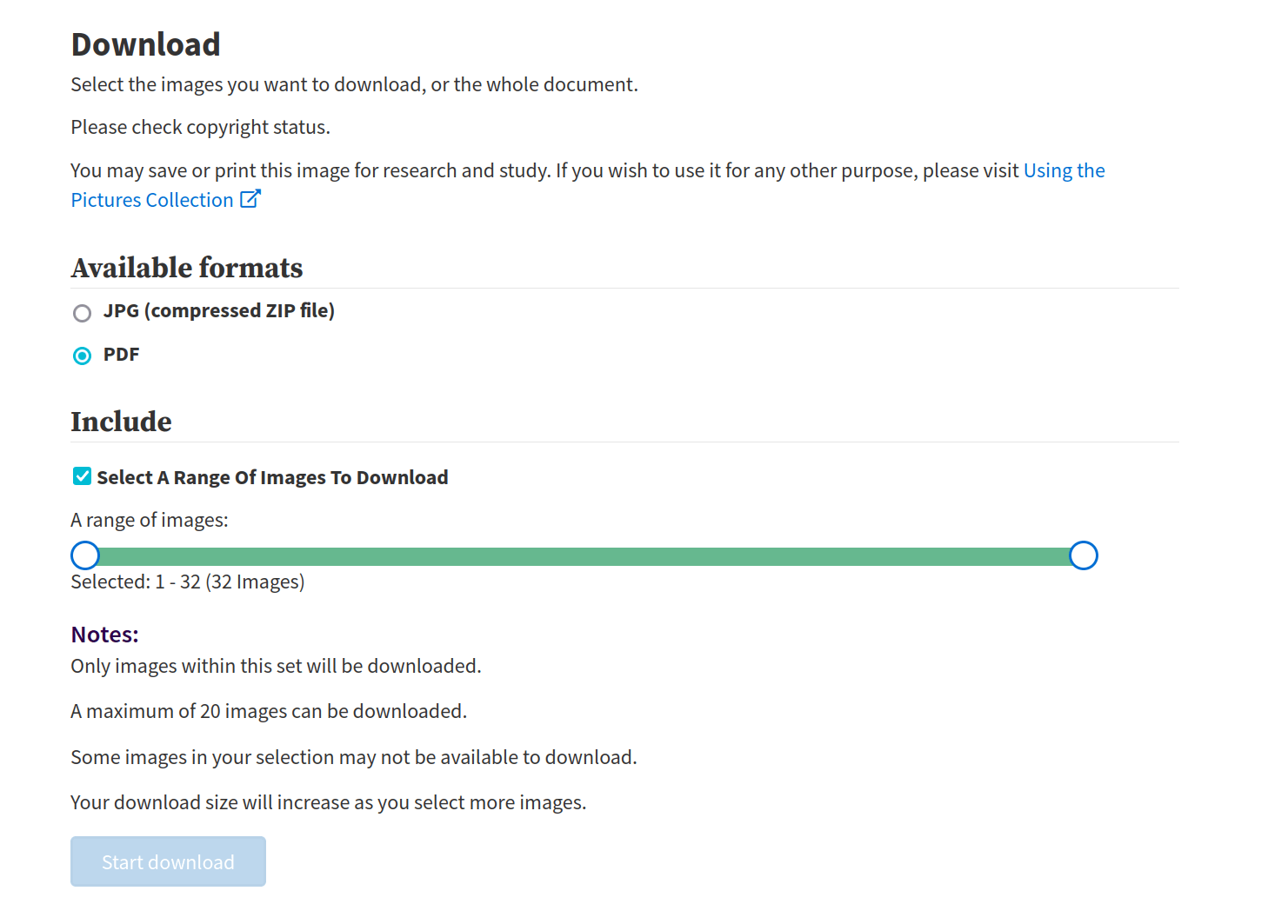
-
limit of 20
-
backs missing
(no sub-collections)
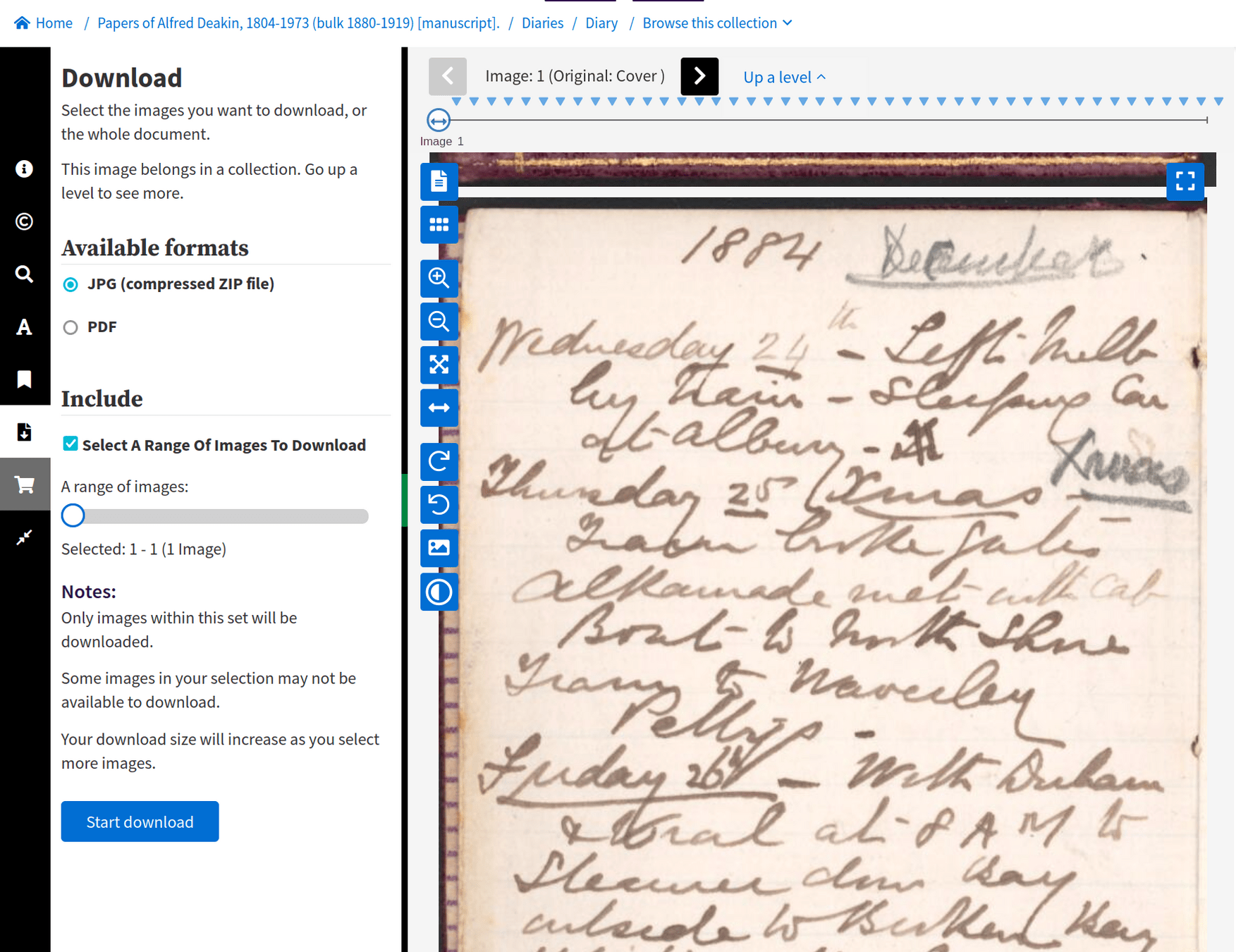
low resolution (1000px x 1588px)
missing metadata
- limited metadata
- no full text
- < 1 million results
Scaling up?
- text from all articles in a newspaper search
- all covers from a journal
- all images from a finding aid
- text from all issues in a journal
- all digitised maps of Australia
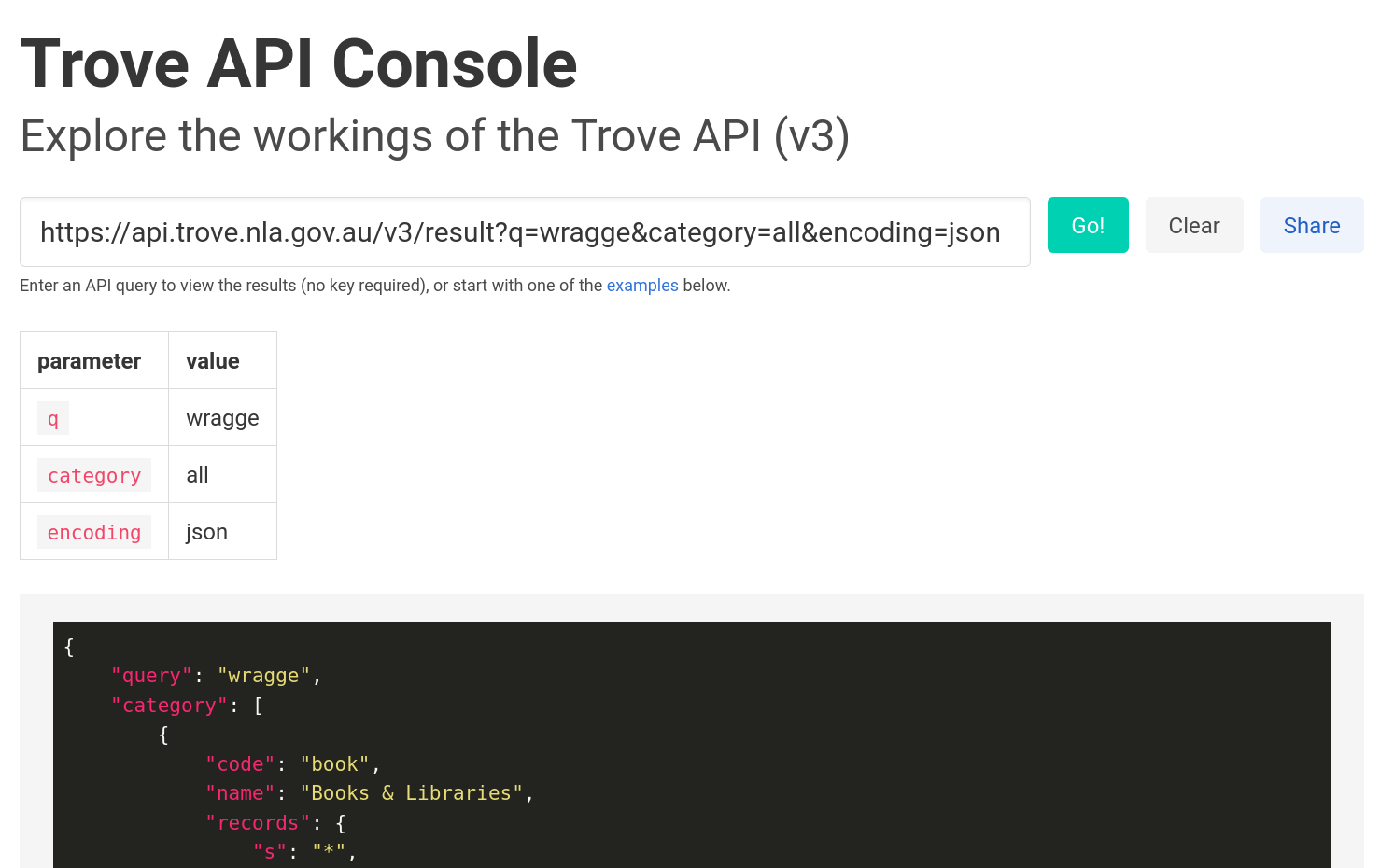
creating datasets
{
"id": "61389505",
"url": "https://api.trove.nla.gov.au/v3/newspaper/61389505",
"heading": "MR. WRAGGE'S \"WRAGGE.\"",
"category": "Article",
"title": {
"id": "64",
"title": "Clarence and Richmond Examiner (Grafton, NSW : 1889 - 1915)"
},
"date": "1902-07-15",
"page": "4",
"pageSequence": "4",
"troveUrl": "https://nla.gov.au/nla.news-article61389505"
}
Trove API
use the API, but...
- skills?
- documentation?
- examples?
- tools?
🤯
API limits
- items in a digitised collection
- links to download images
- text from books or periodical issues
- text from Australian Women's Weekly
🐞 and bugs!
🪠 data plumbing
gaps & blockages

researchers 👩🔧
researchers 👩🔧
collaboration

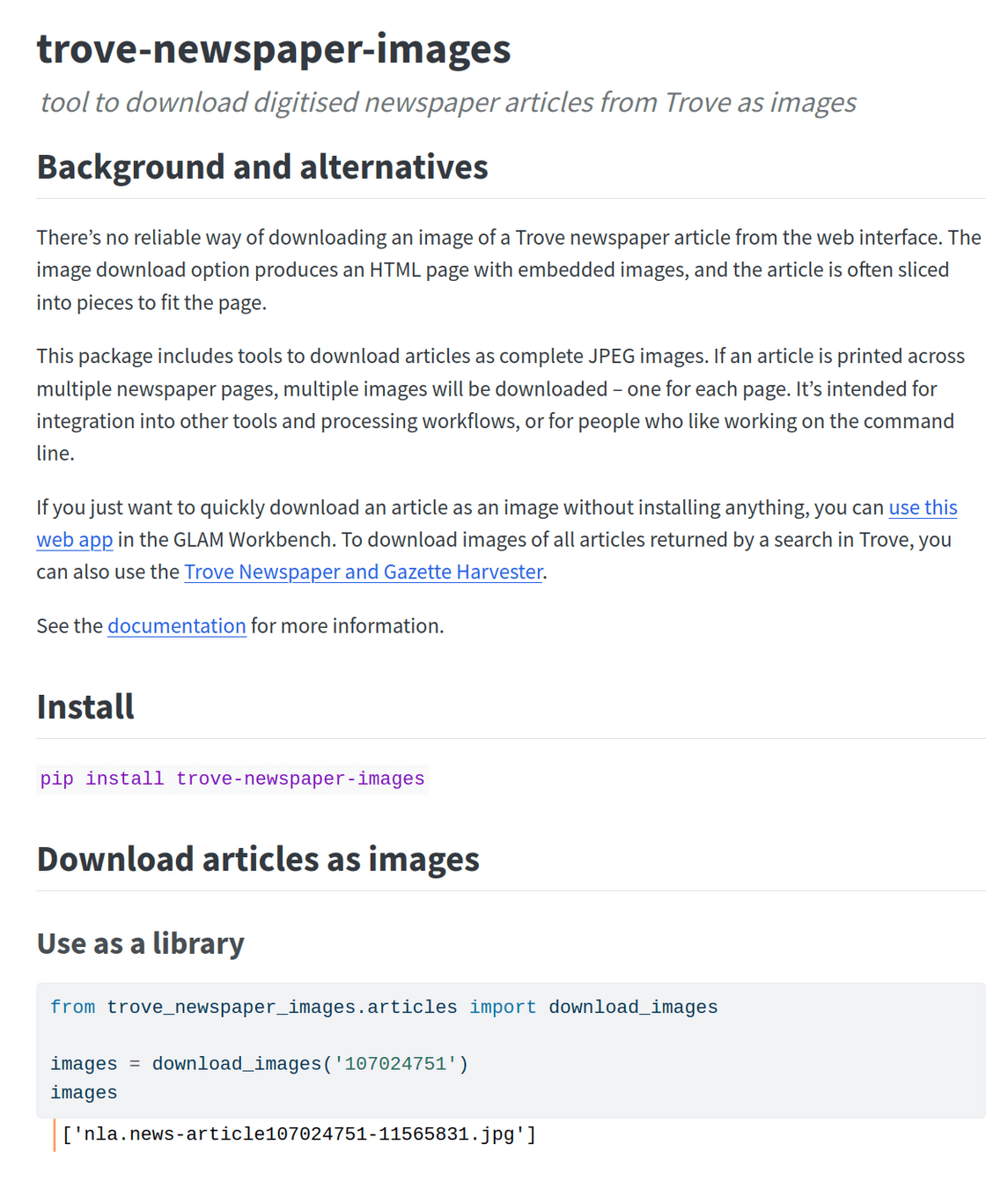
articles as images
try it!
- find a newspaper article (here's one)
- copy the url of the newspaper article from your browser's location bar
- go to the newspaper image app in the GLAM Workbench
- paste the url into the box
- click on Get images
- select 'Save image as...'
from right click menu

check 'mask image' and try again – what changes?


save
high-res images
try it!
- search for a digitised photo (remember the "nla.obj" trick)
- here's an example if you can't think of anything to search for
- click on the View link to load the image in the digitised item viewer
-
change the url suffix from /view to /image in your browser's location bar
-
click enter to view the image
-
choose 'Save image as...' from the right click menu to download the image


harvest newspaper articles
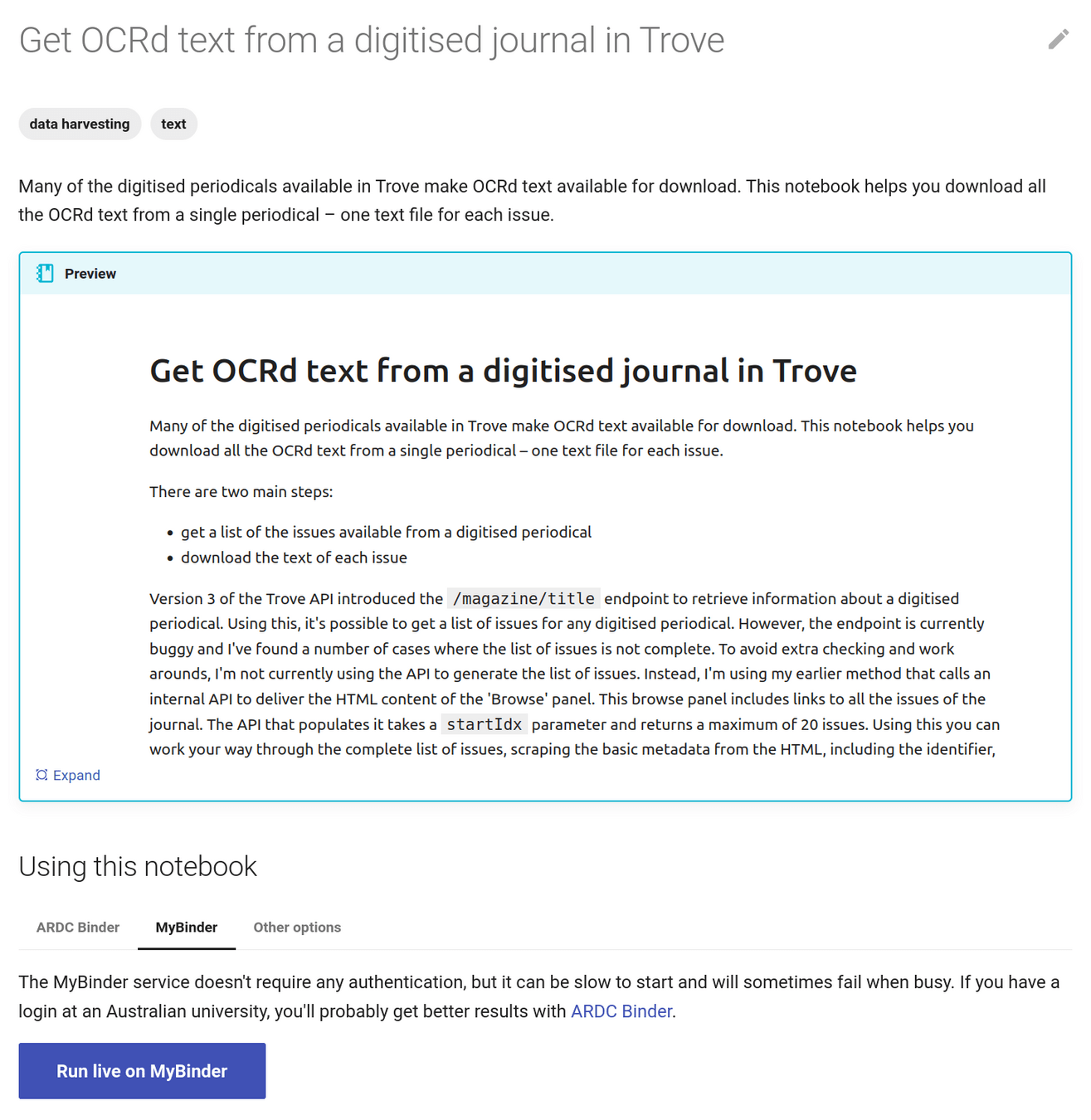
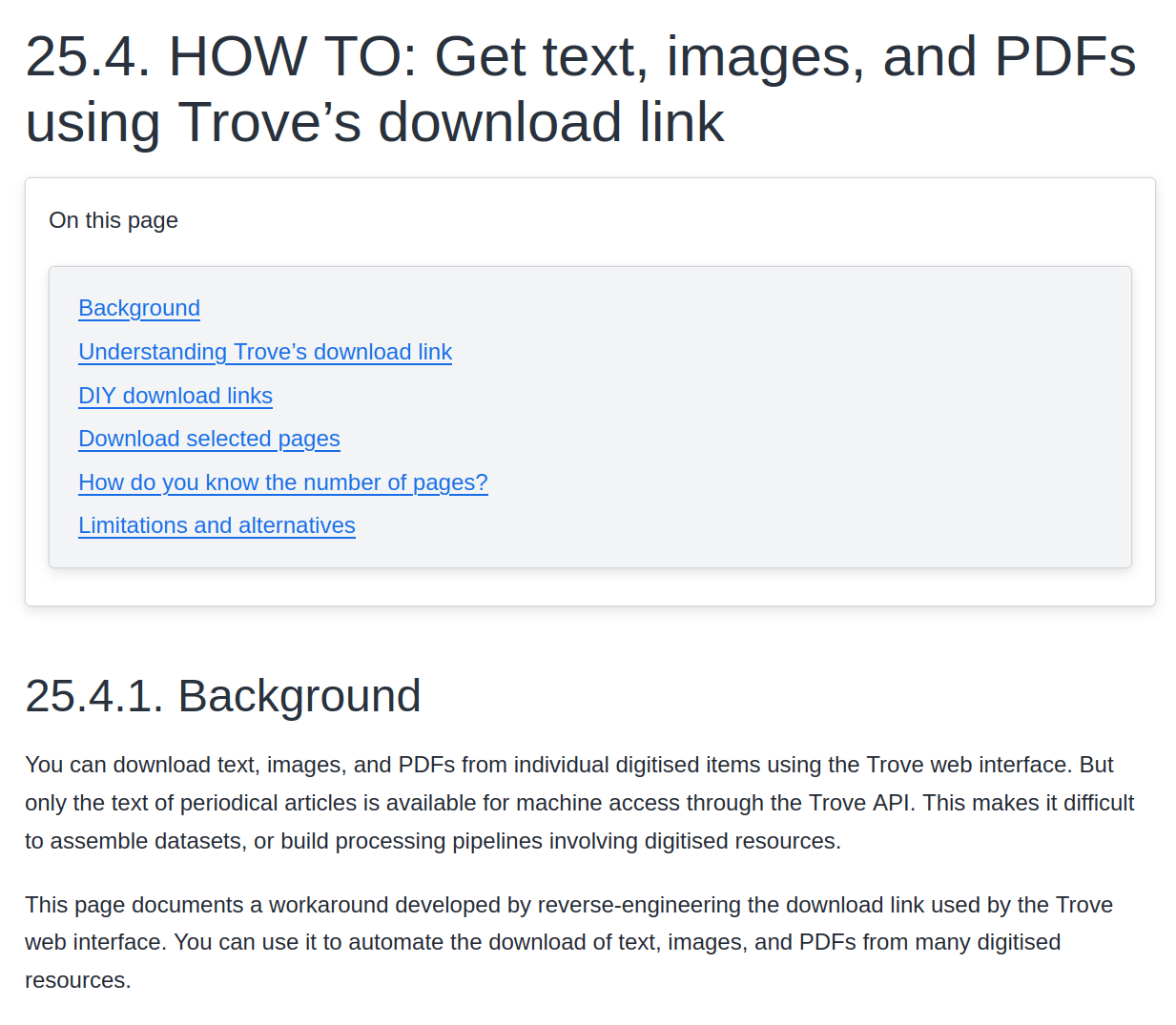
text from books & periodicals
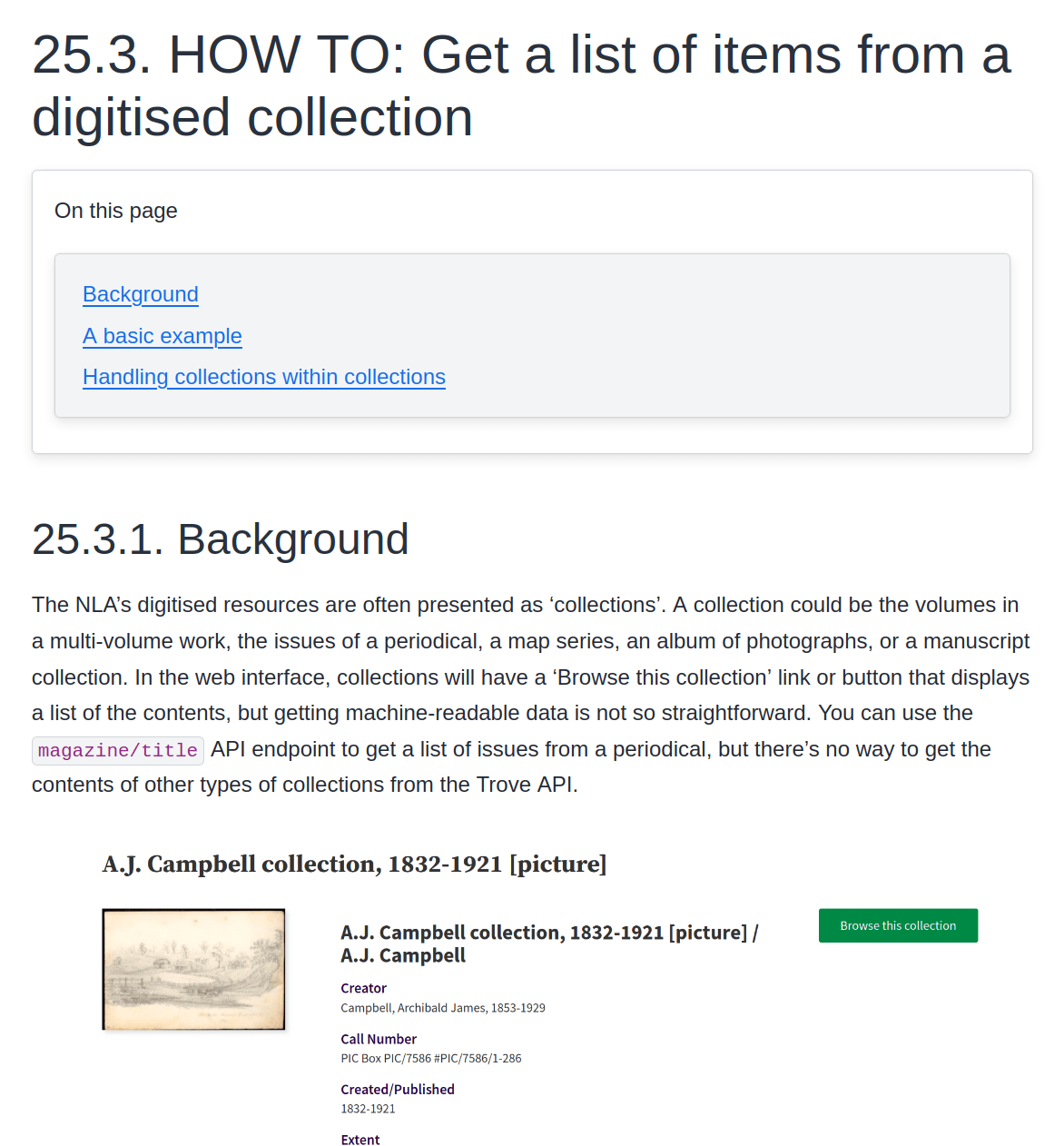
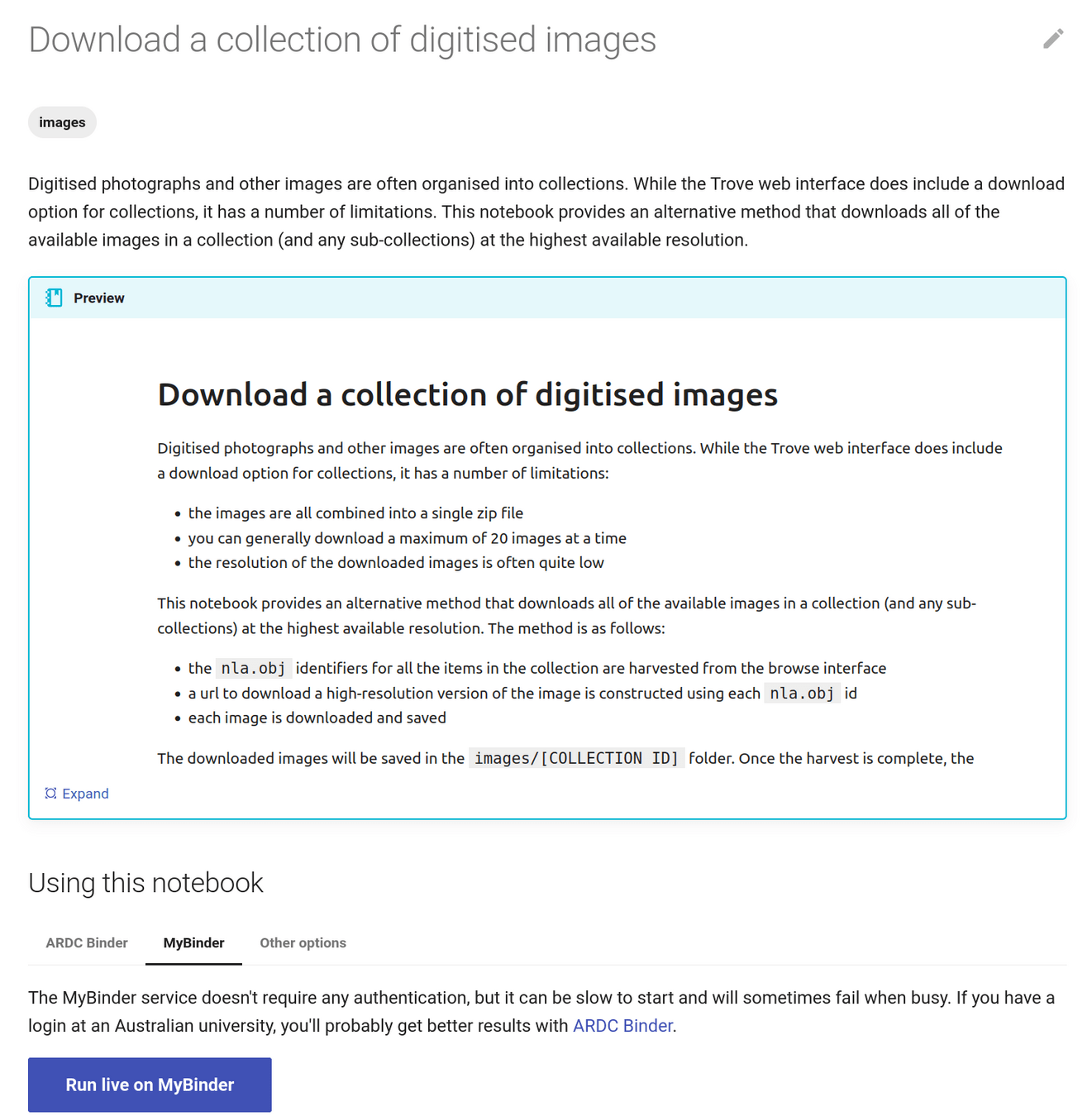
images in a collection


illustrations from books & periodicals
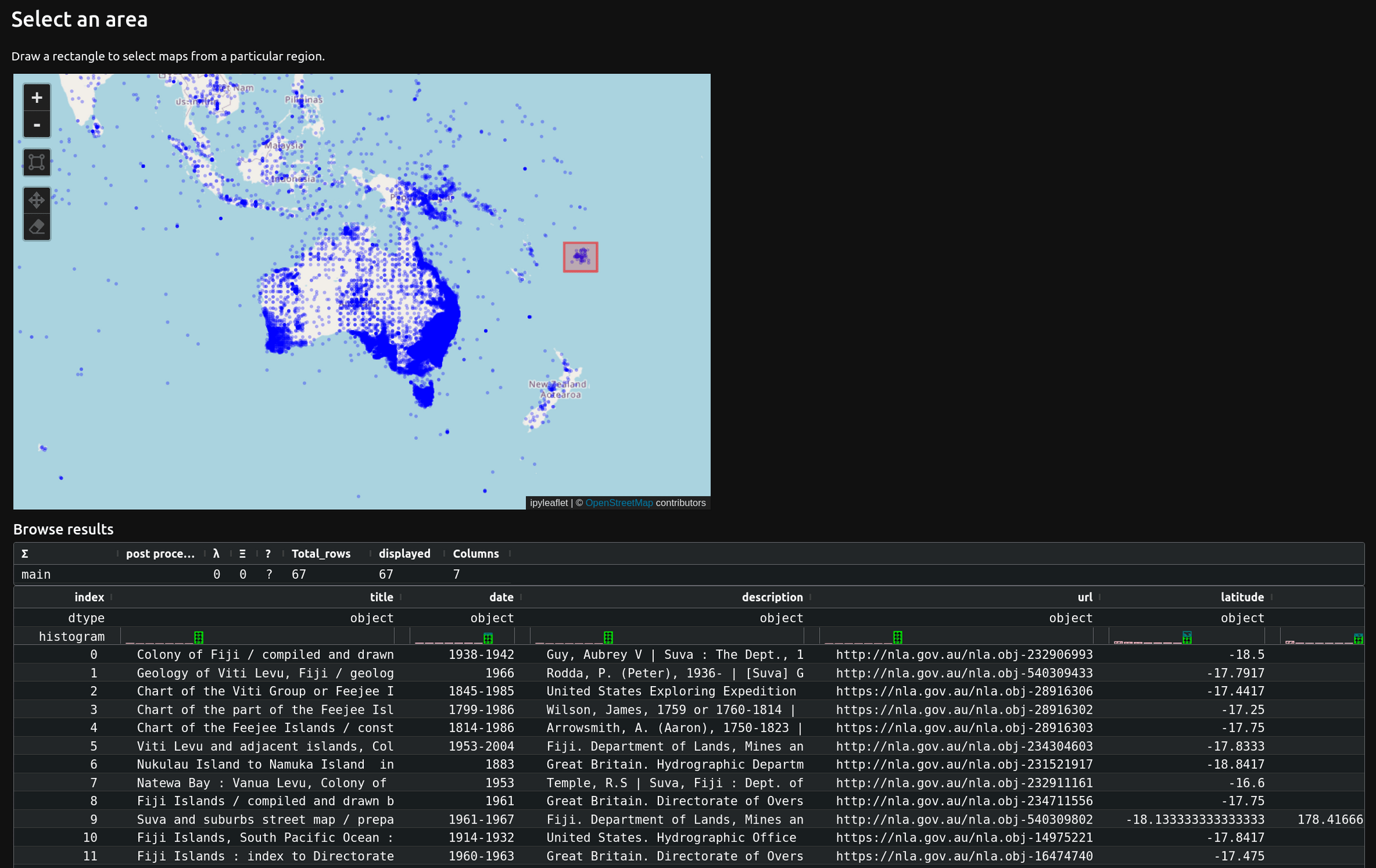
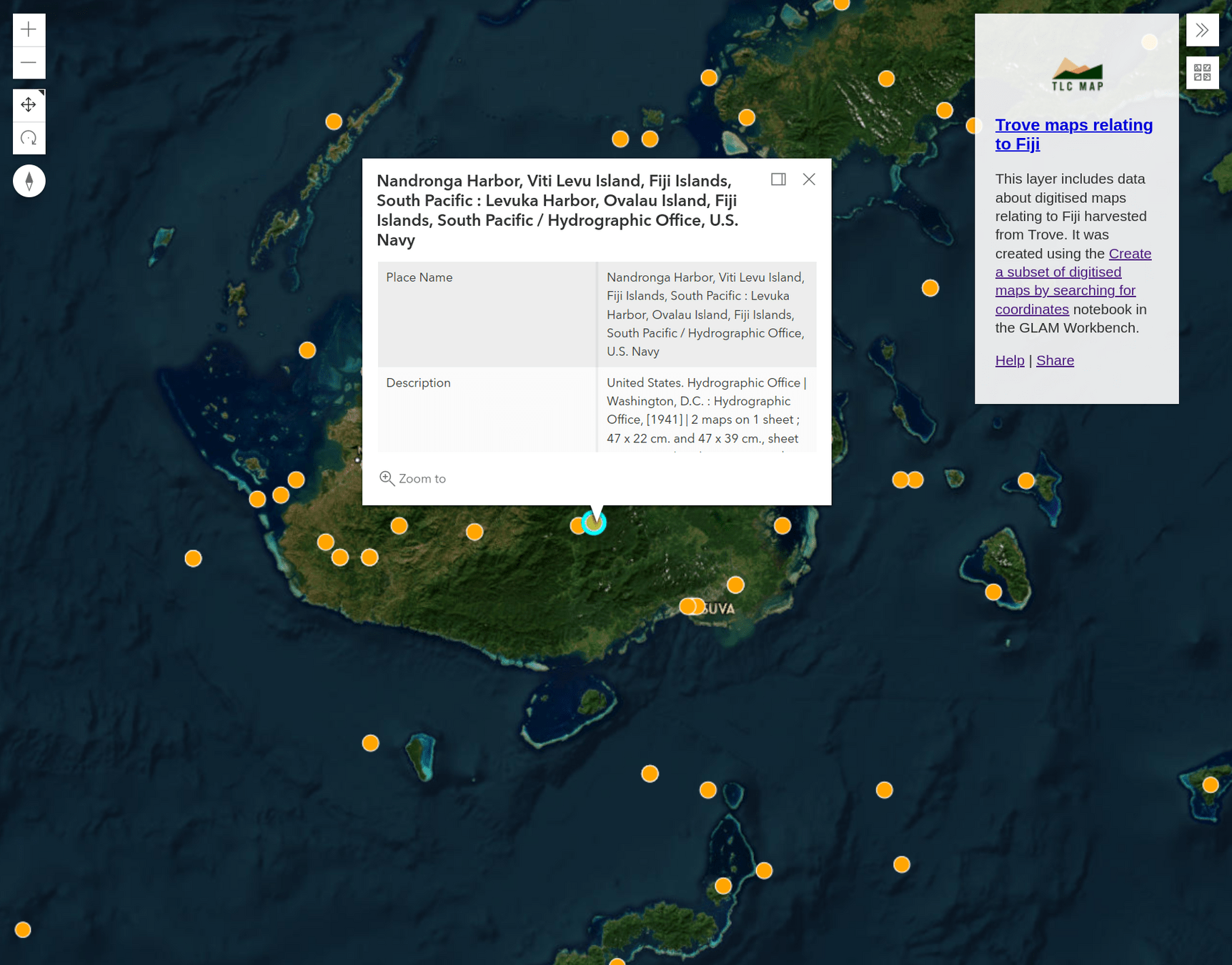
maps by location
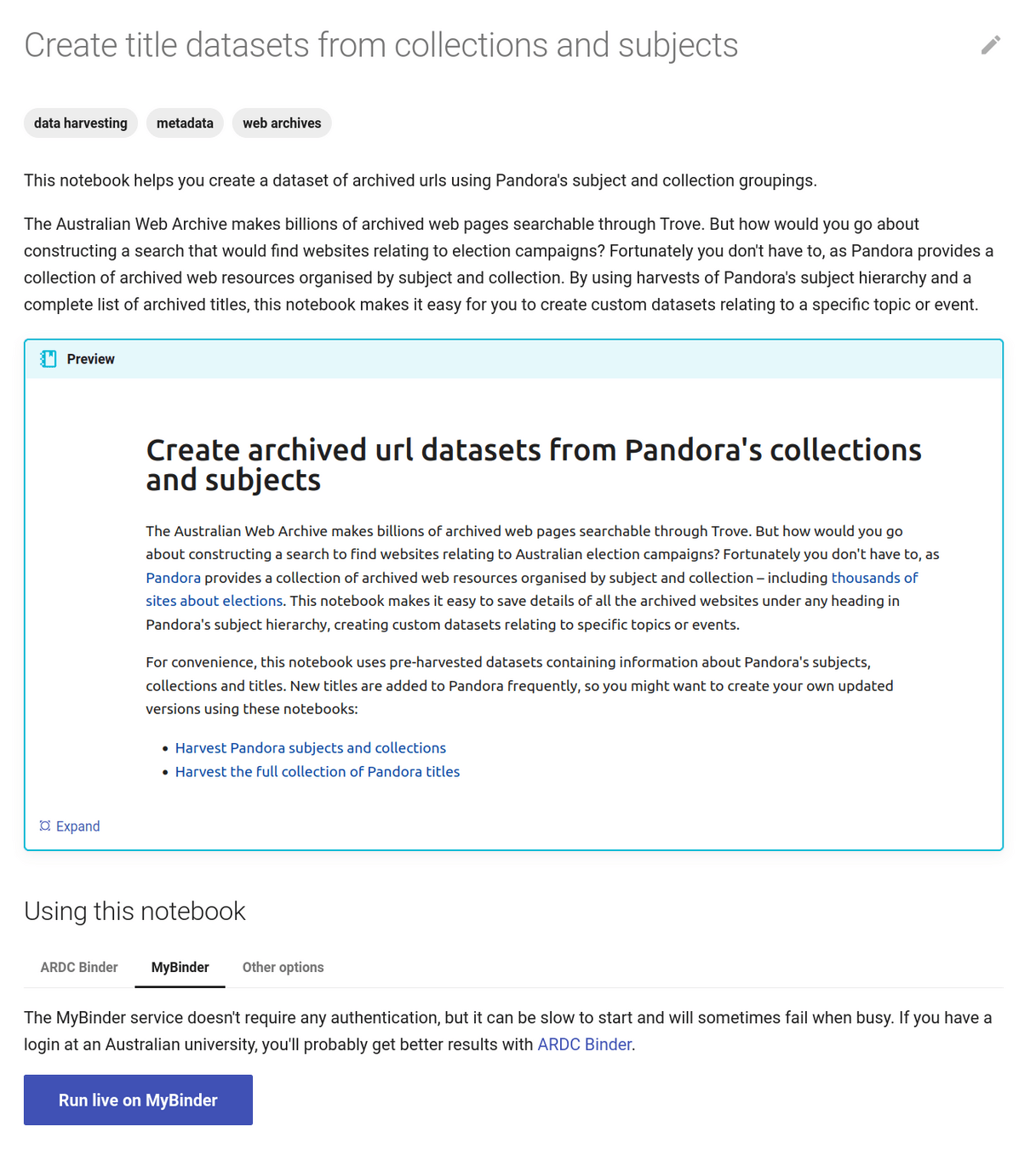
archived websites by topic
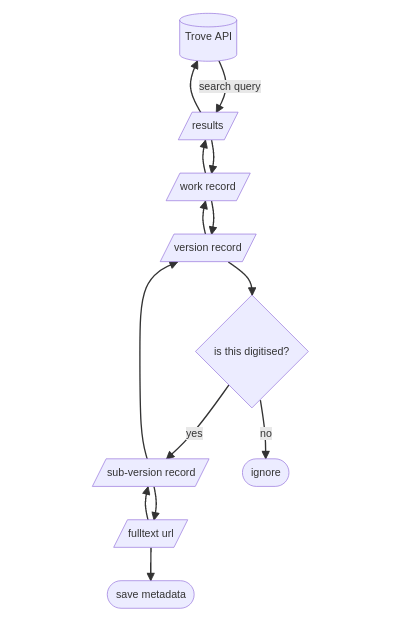
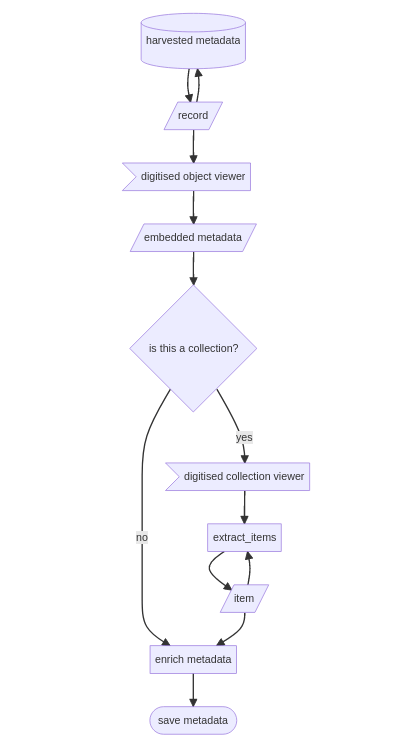
harvesting digitised resources
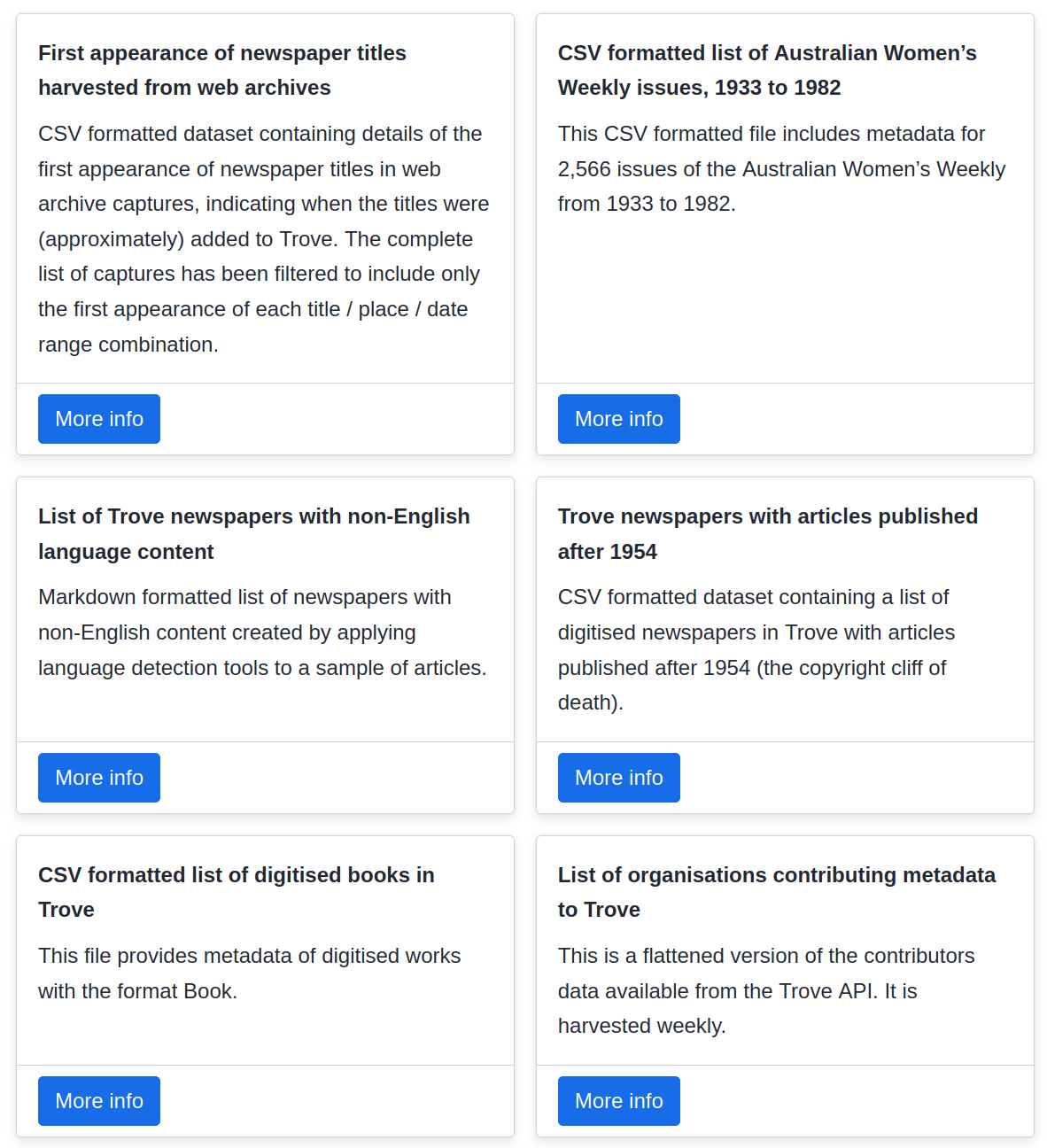

more data sources

🔭 explore
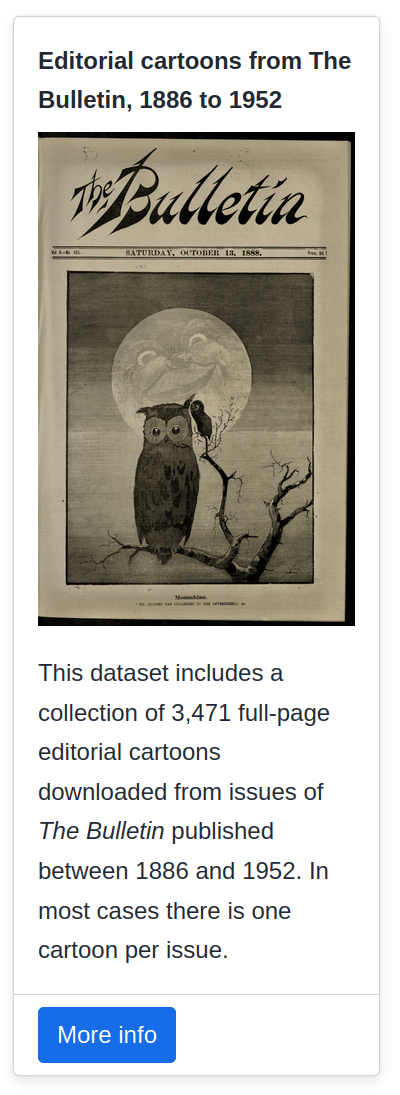
- 3,471 cartoons
- 1886 to 1962
you can help!
add notes, tags, links....
add ideas!
report problems!
share everything!
- openly licensed to encourage reuse
- use for your own research
- use in teaching & research training
- no need to ask for permission
steal everything!
pay it forward!

stay connected!
stay connected!
Tim Sherratt
email: tim@timsherratt.au
web: timsherratt.au
mastodon: @wragge@hcommons.social
updates: https://updates.timsherratt.org/