











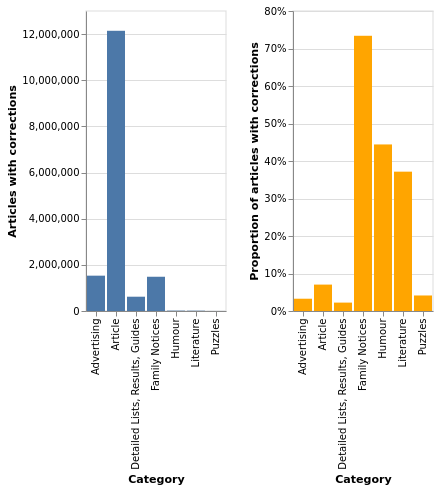










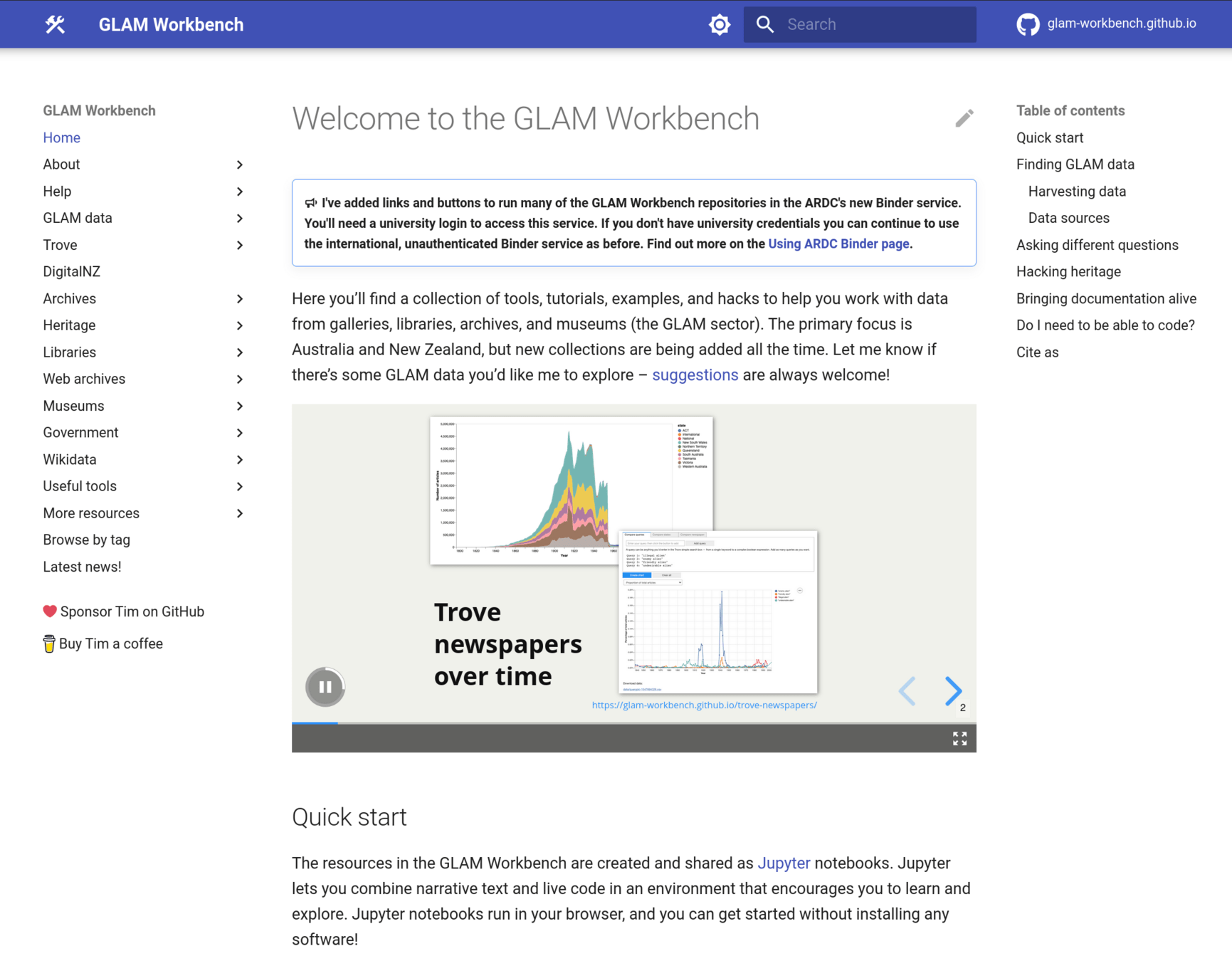












Tim Sherratt PRO
Historian and hacker. All the slide decks available here are licensed under a Creative Commons Attribution 4.0 International License. Fee free to reuse and share!
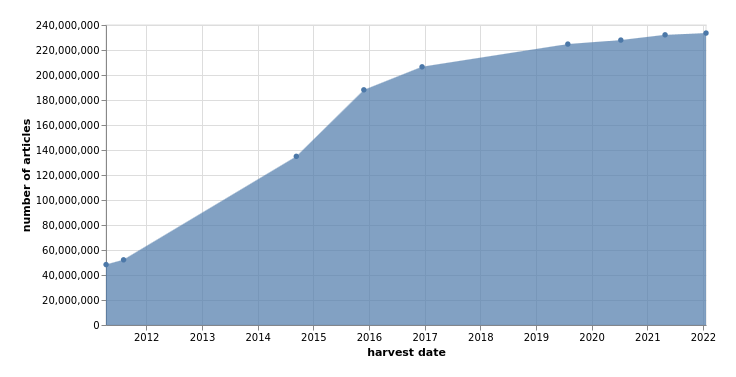
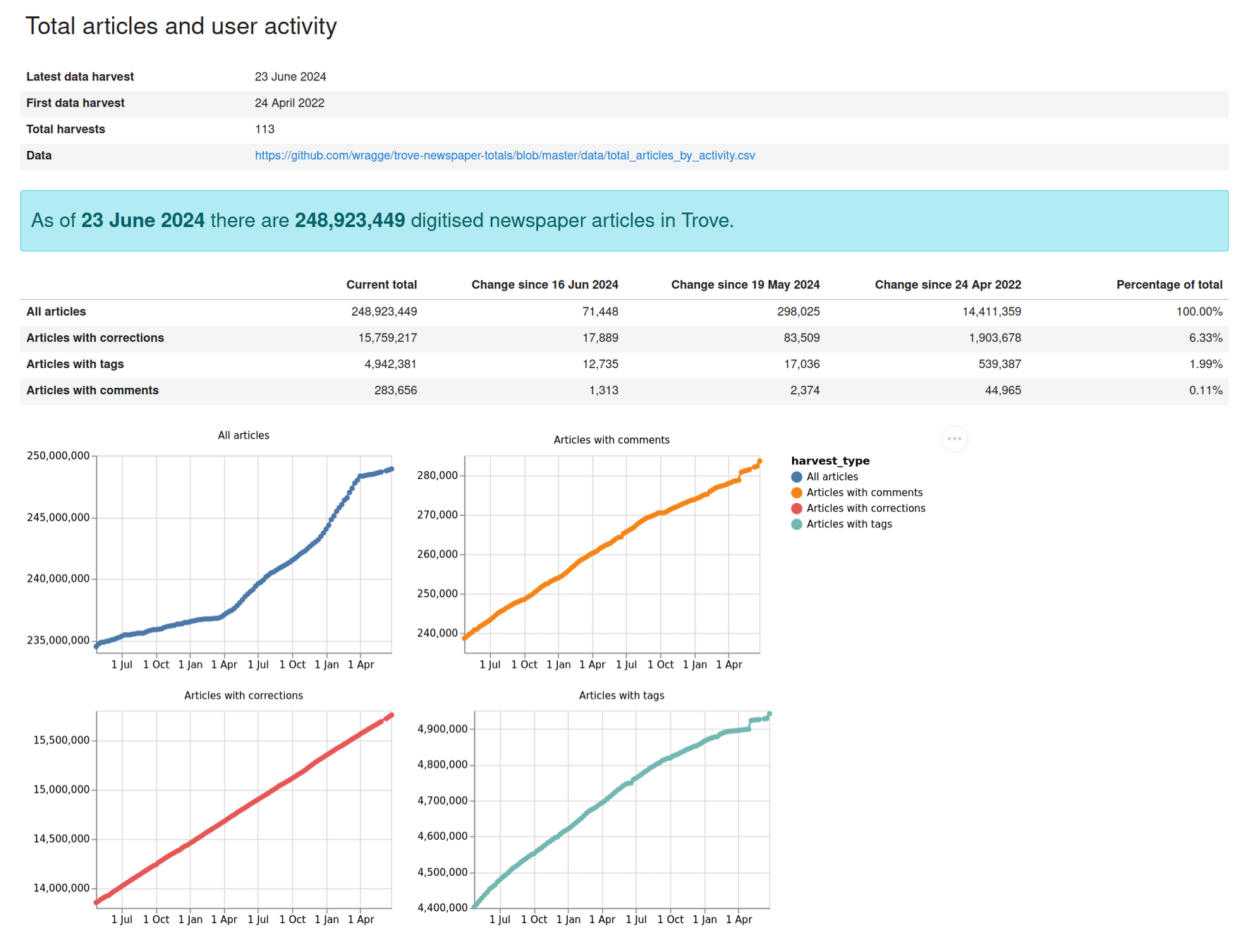
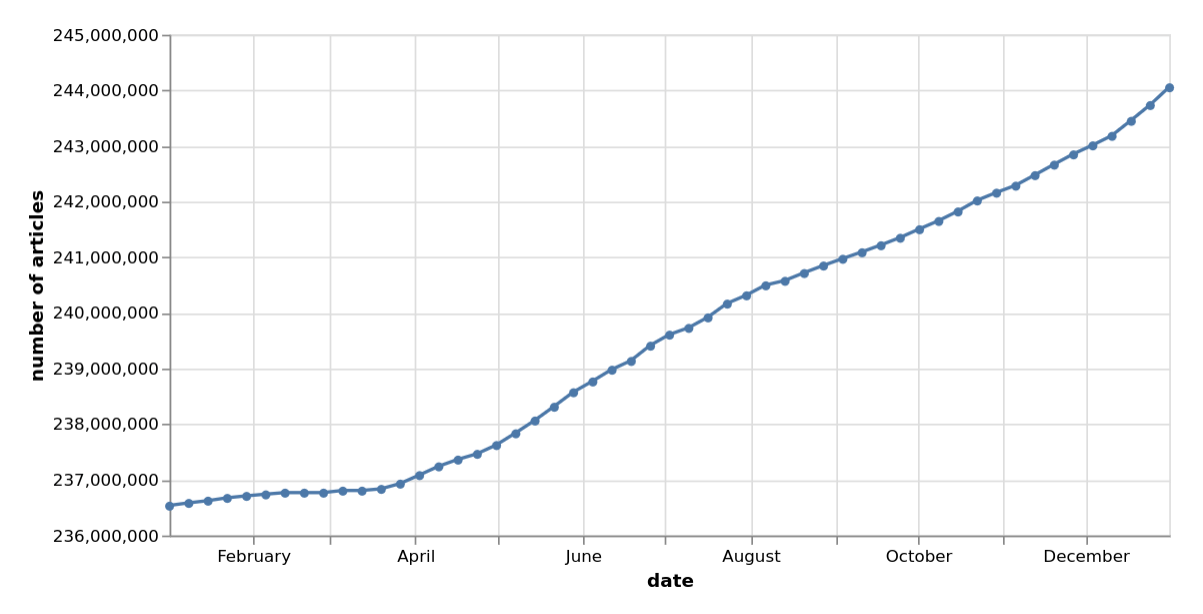
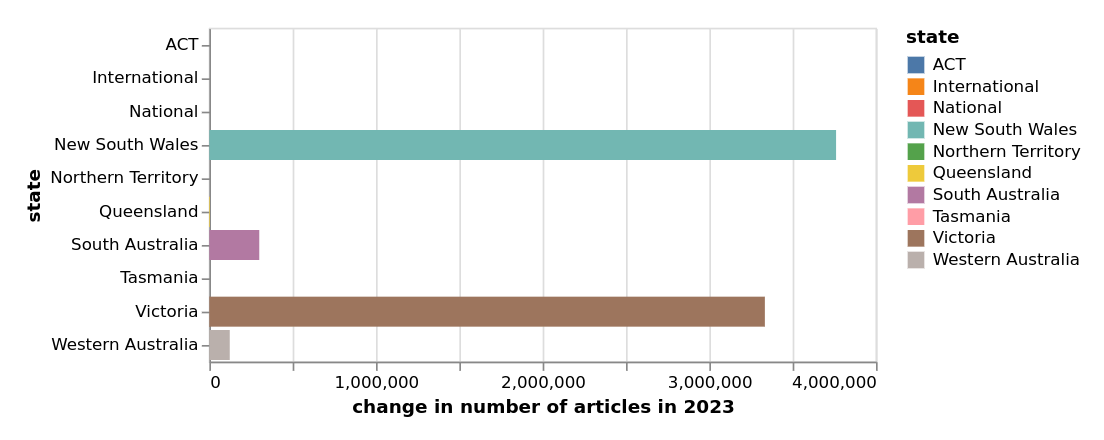
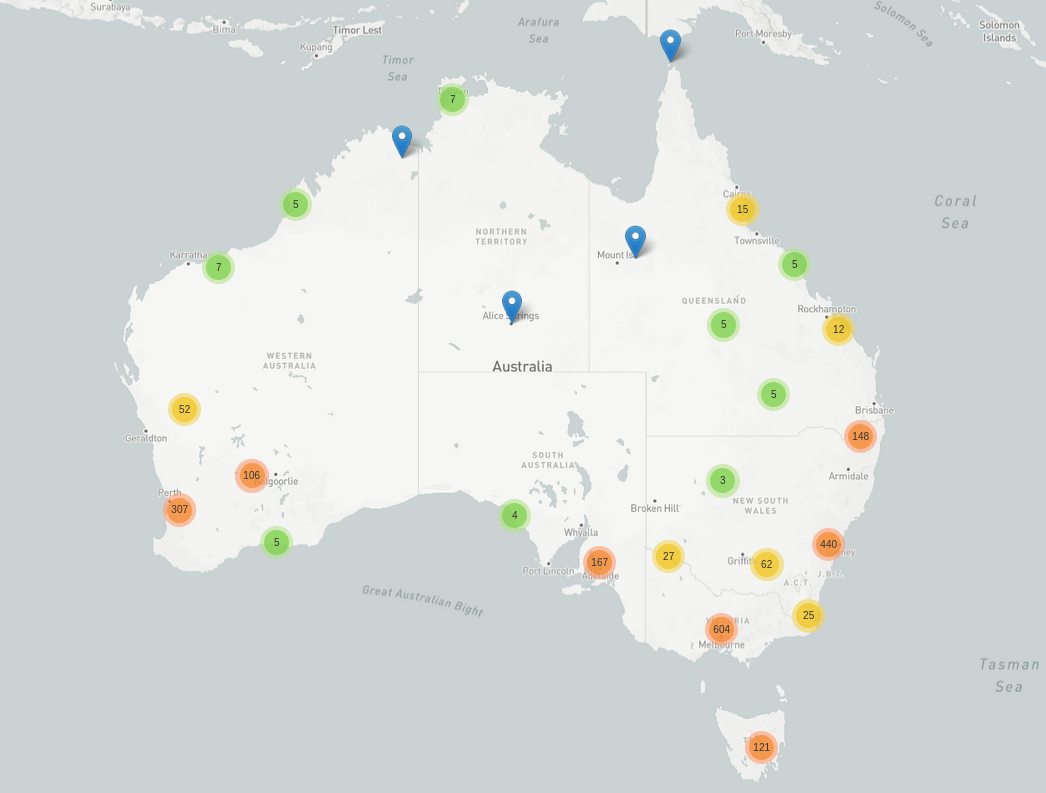
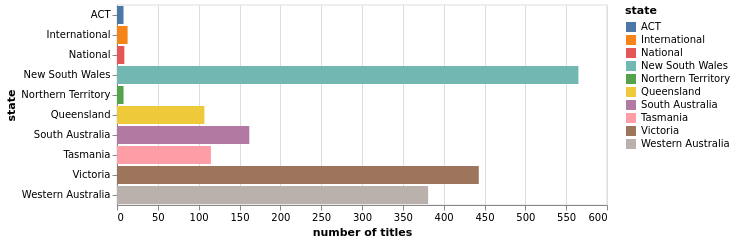
2022
2011
architectures
standards
technologies
principles
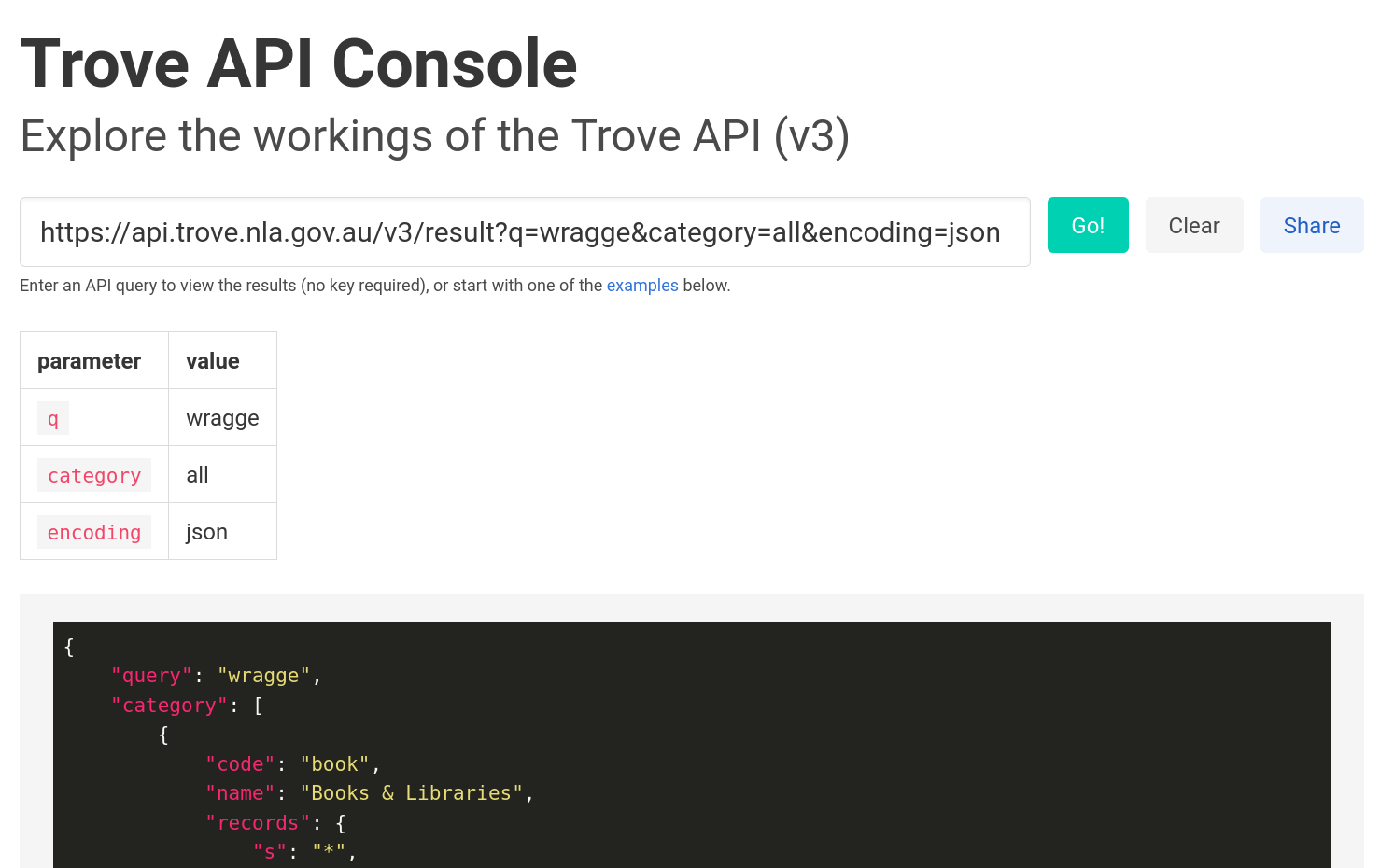
?keyword=[your keyword]
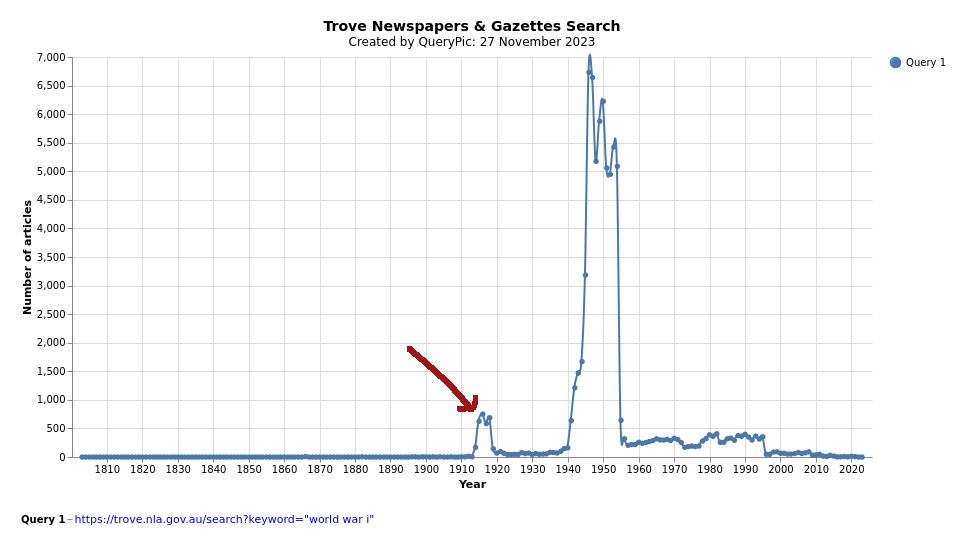
= sign and hit enter&pageSize=100 to the url in your browser's location bar and hit enterofficial
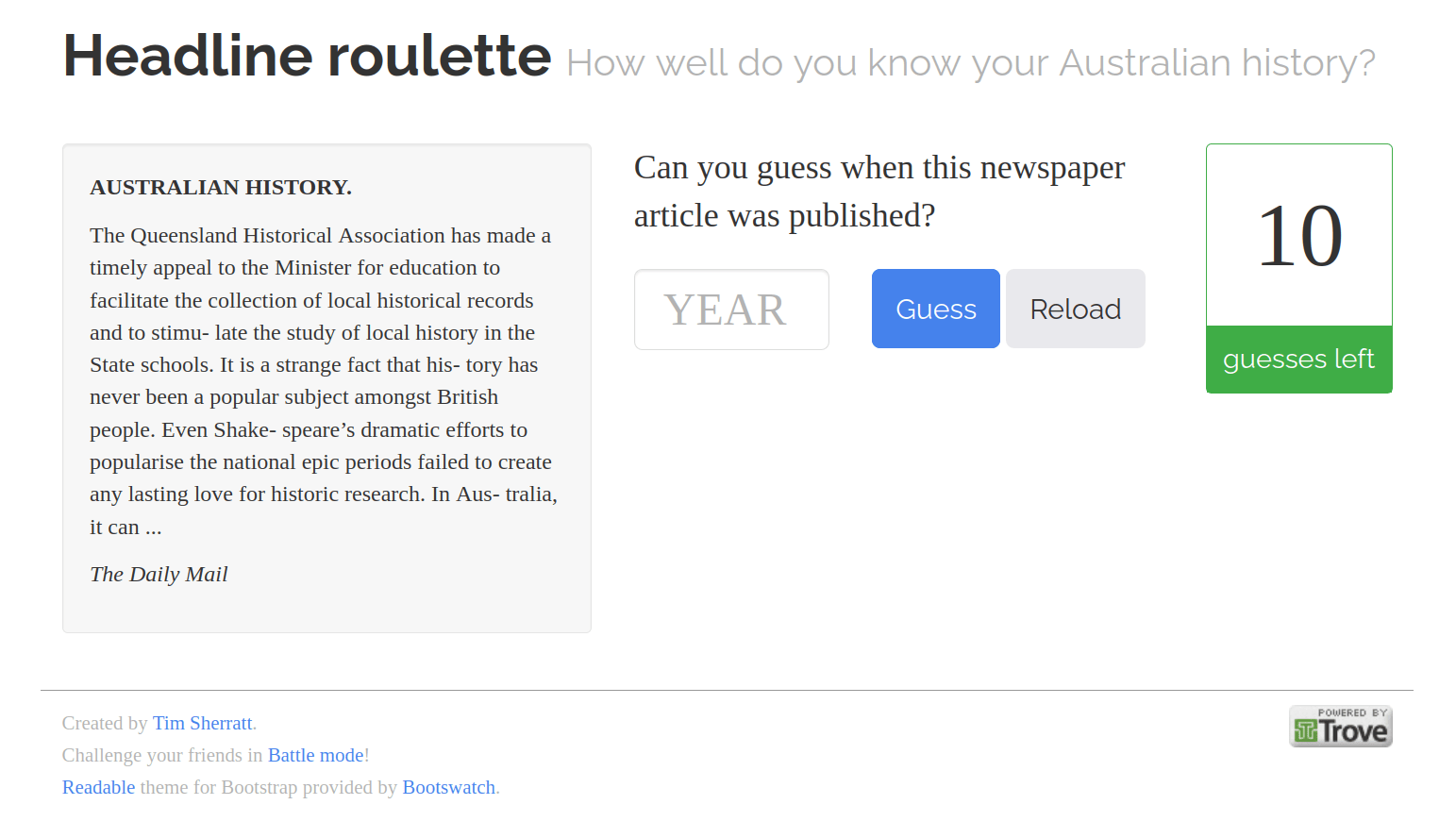
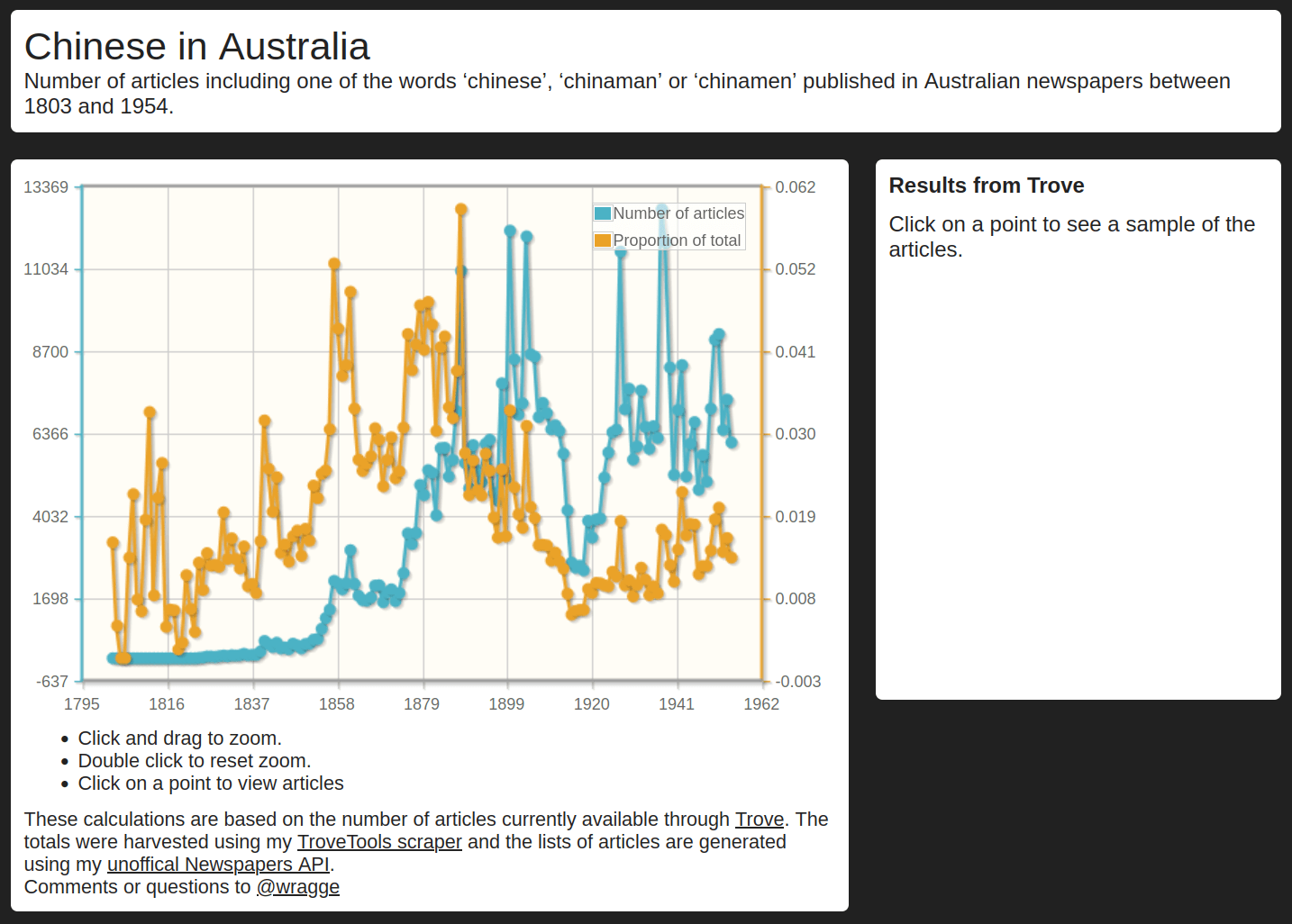
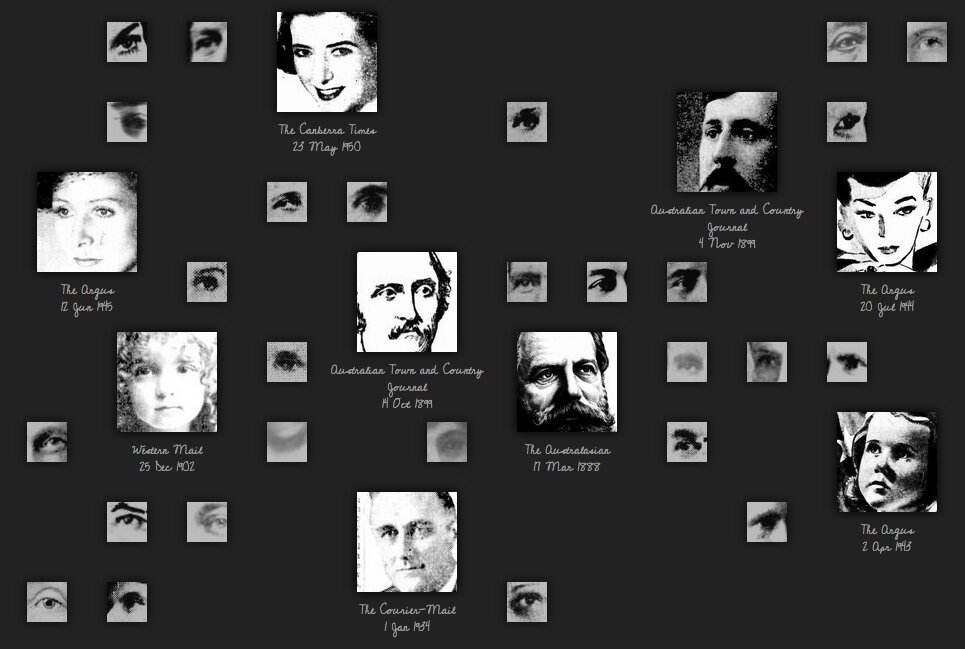
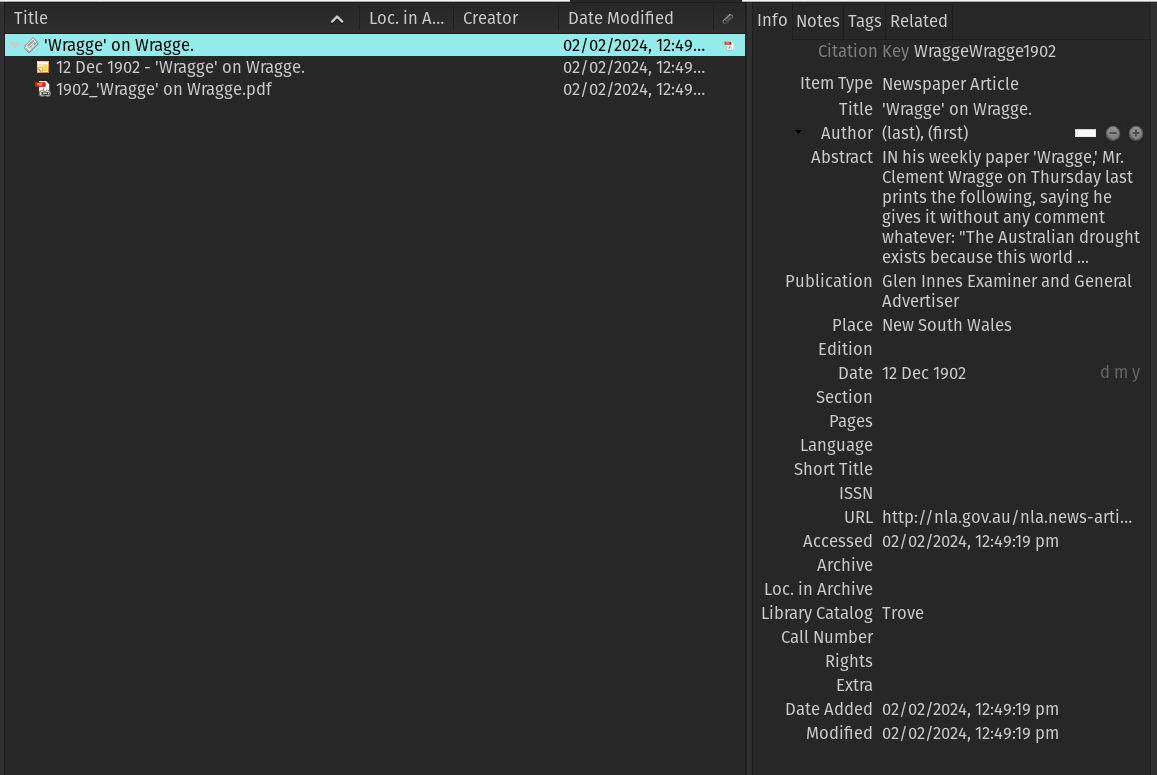
Trove
hacker
handy with lists
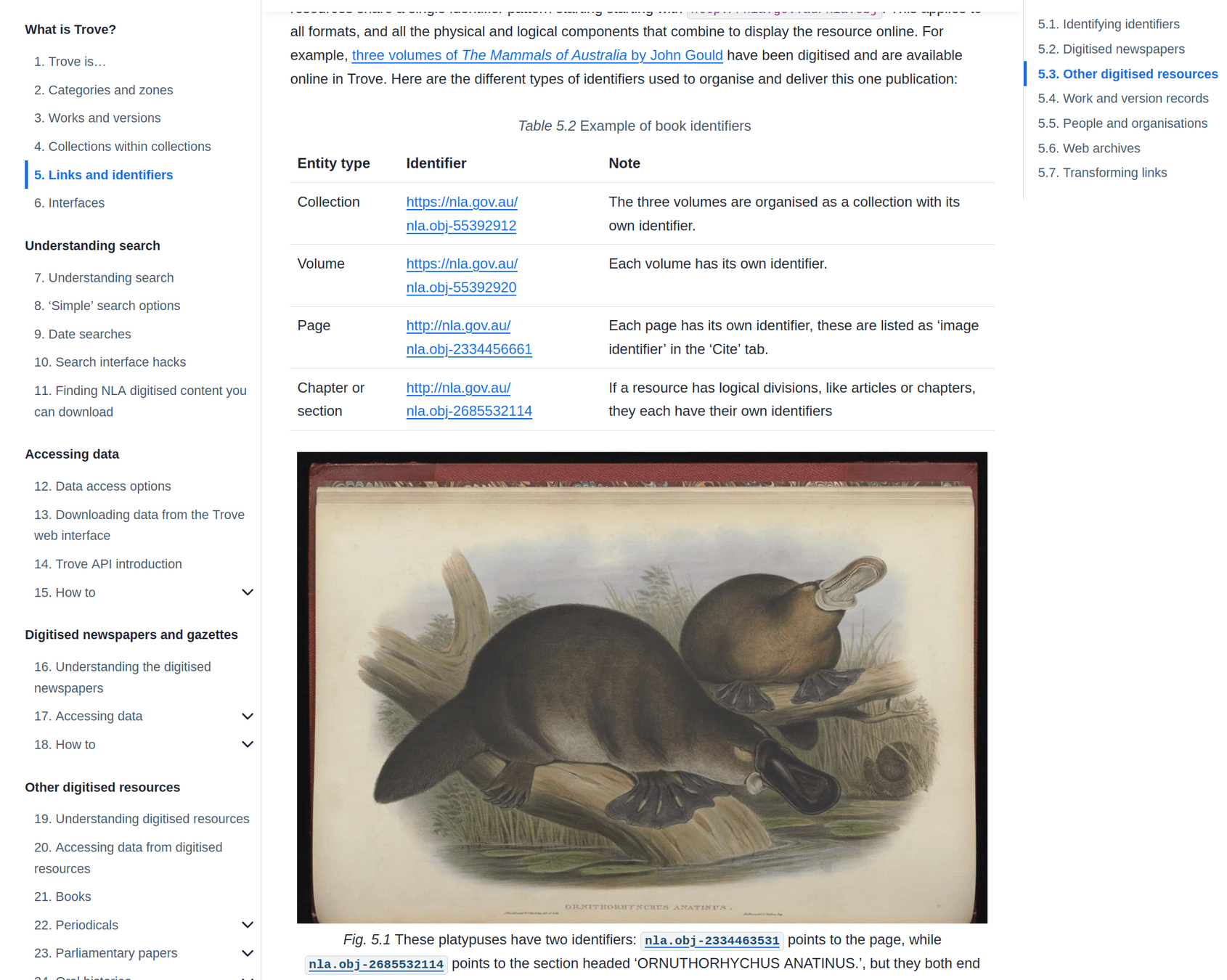
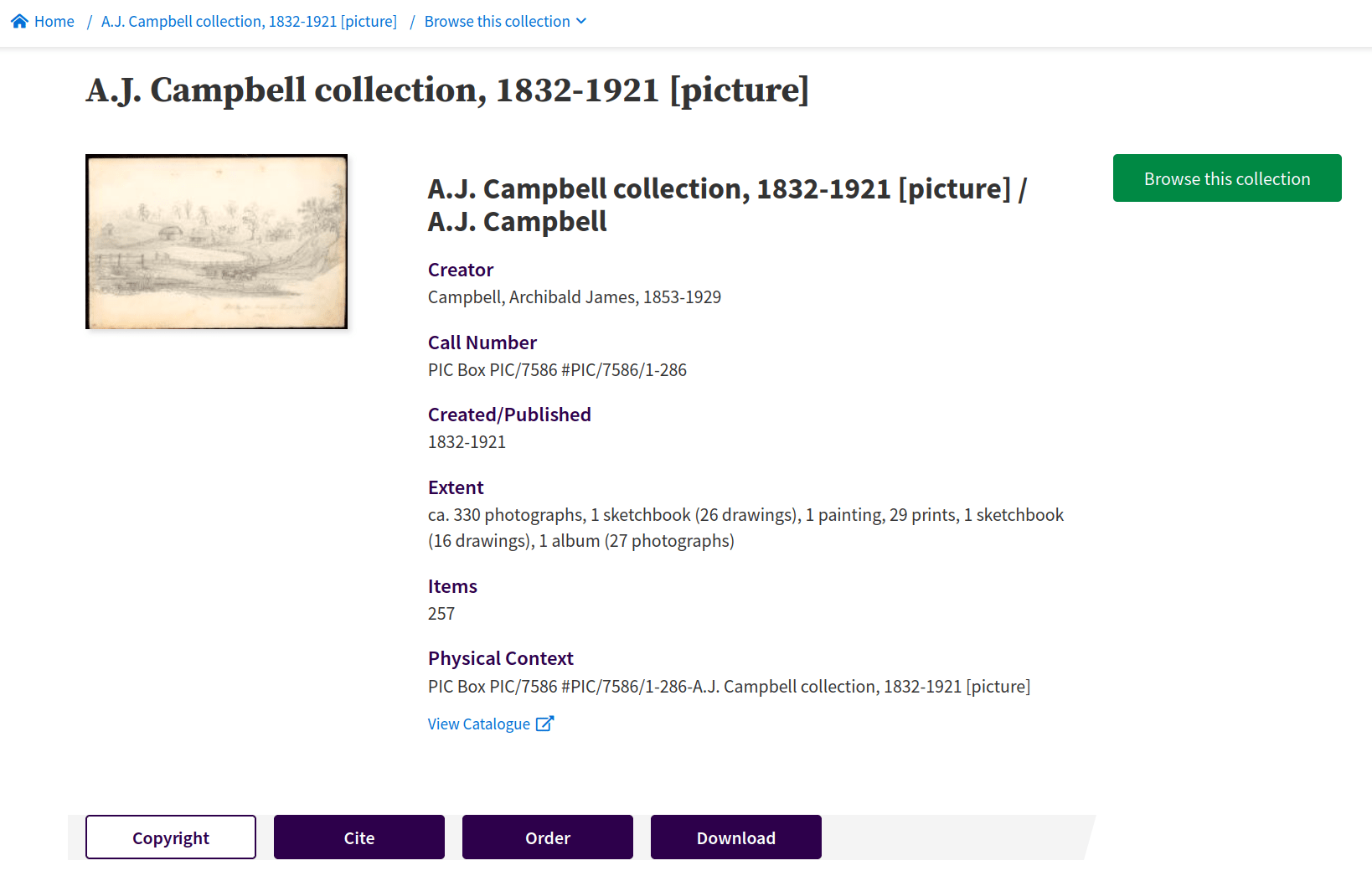
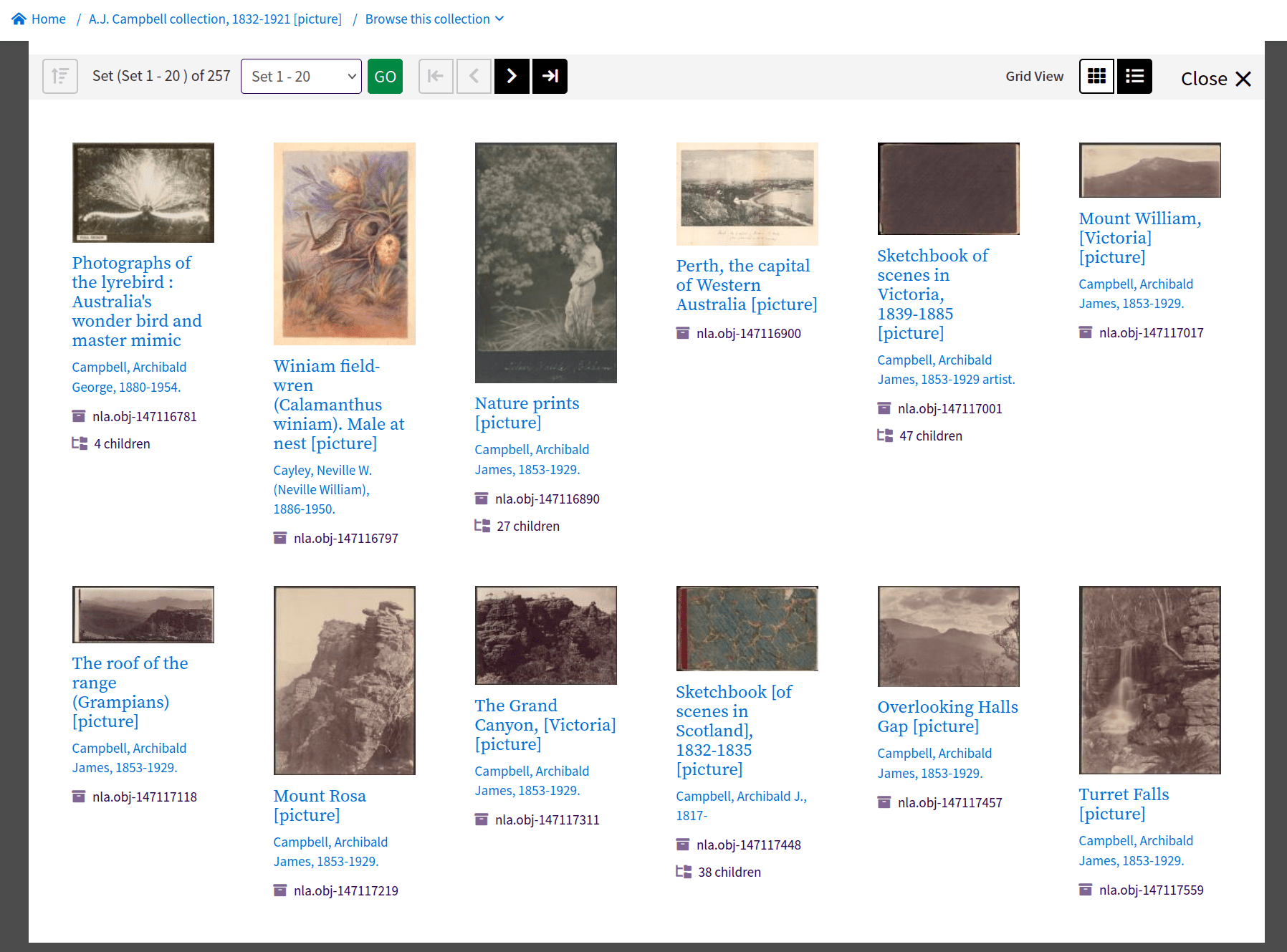
an aggregation of collection metadata
a repository of digitised content
an archive of Australian web content from 1996 onwards
aggregated identity records for people and organisations
born-digital publications submitted via eLegal Deposit
a platform for user engagement
a series of APIs for delivering machine-actionable data
starting at the top!
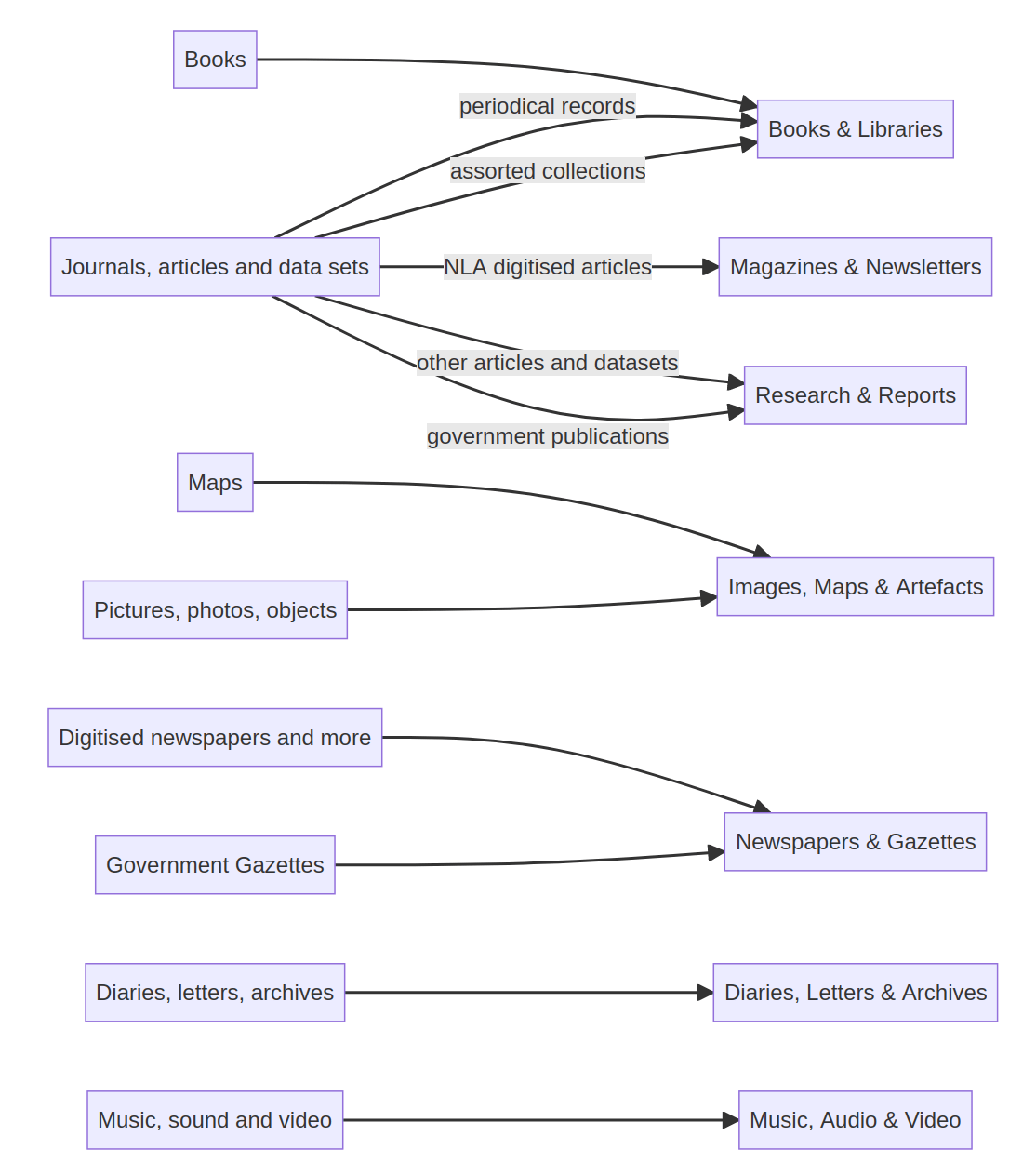
Books & Libraries
Diaries, Letters & Archives
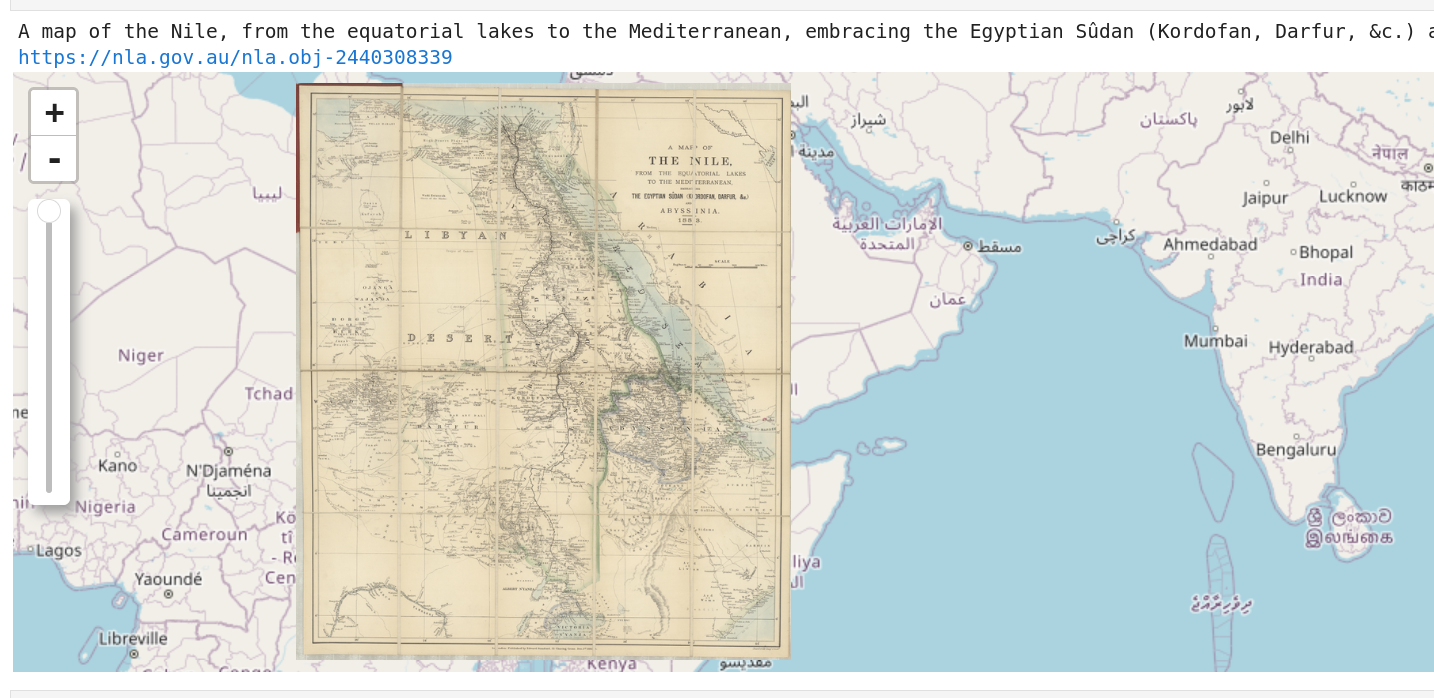
Images, Maps & Artefacts
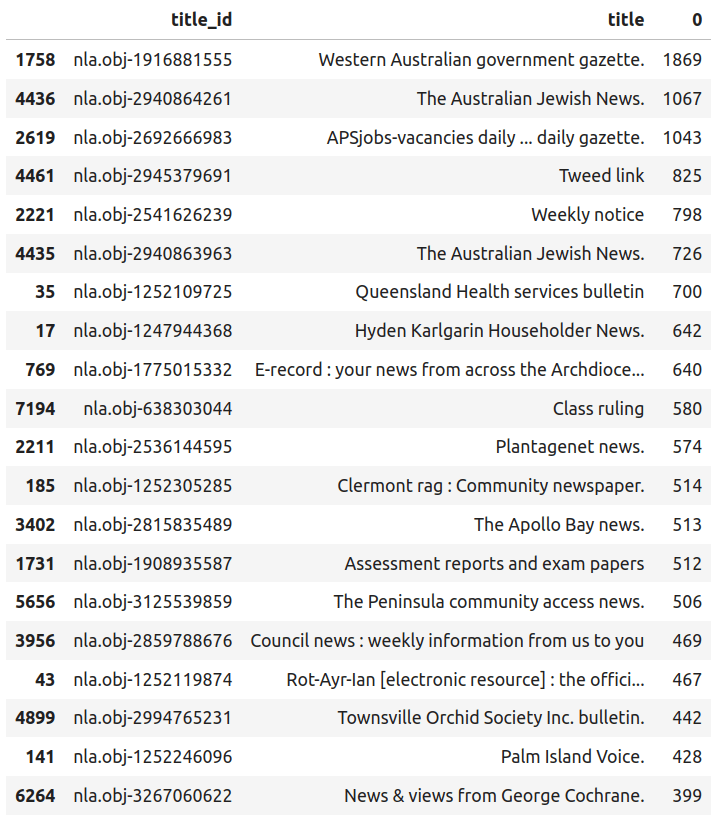
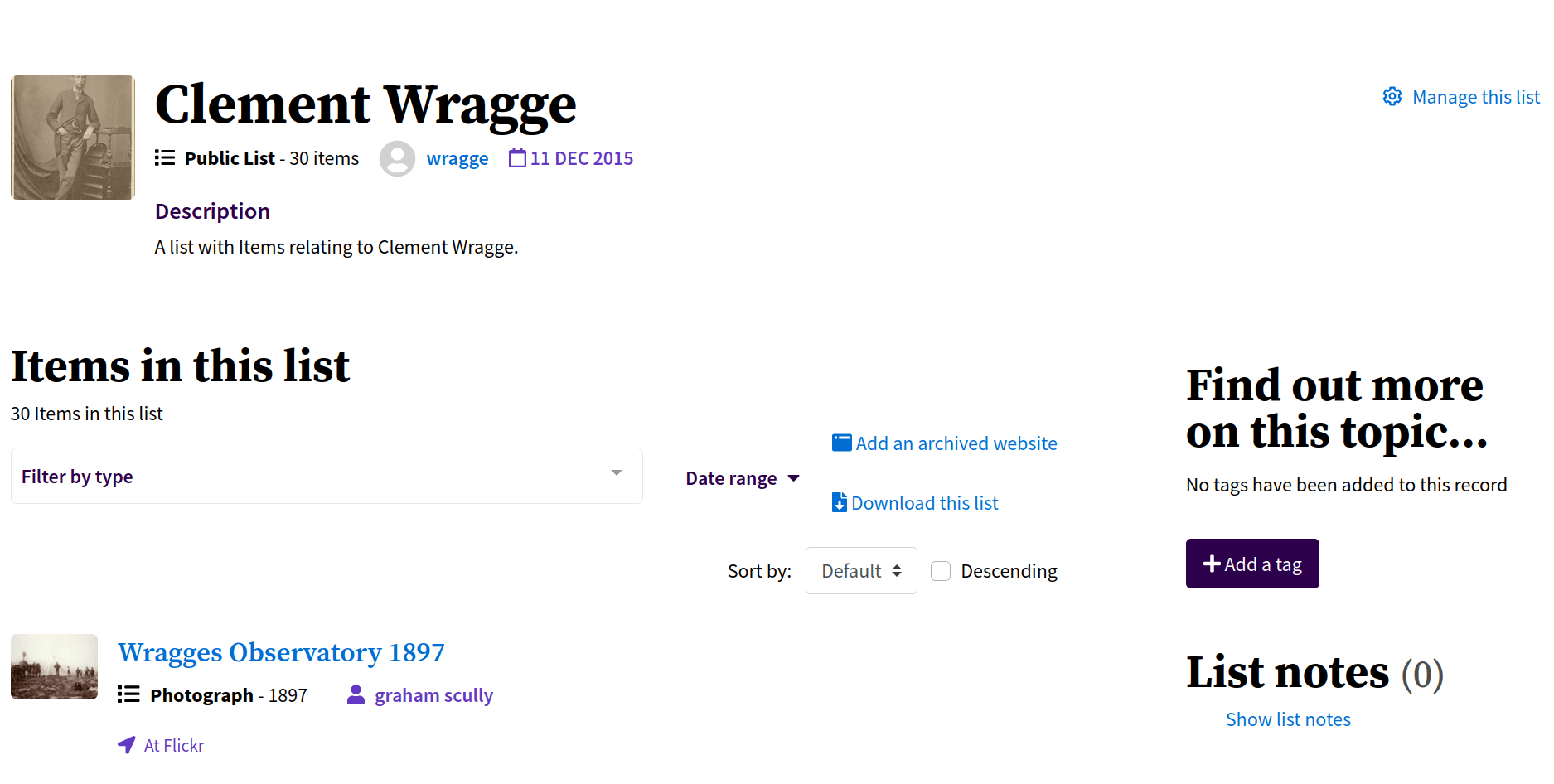
Lists
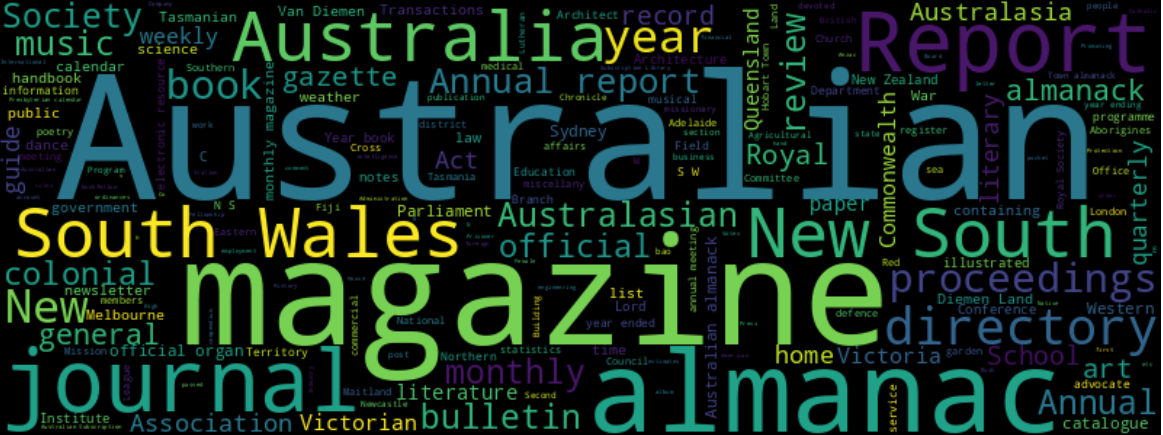
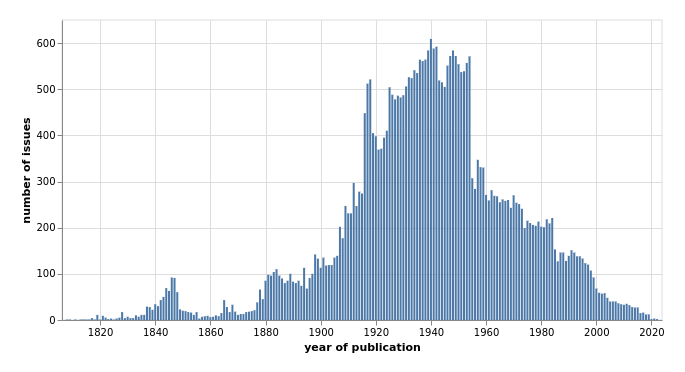
Magazines & Newsletters
Music, Audio & Video
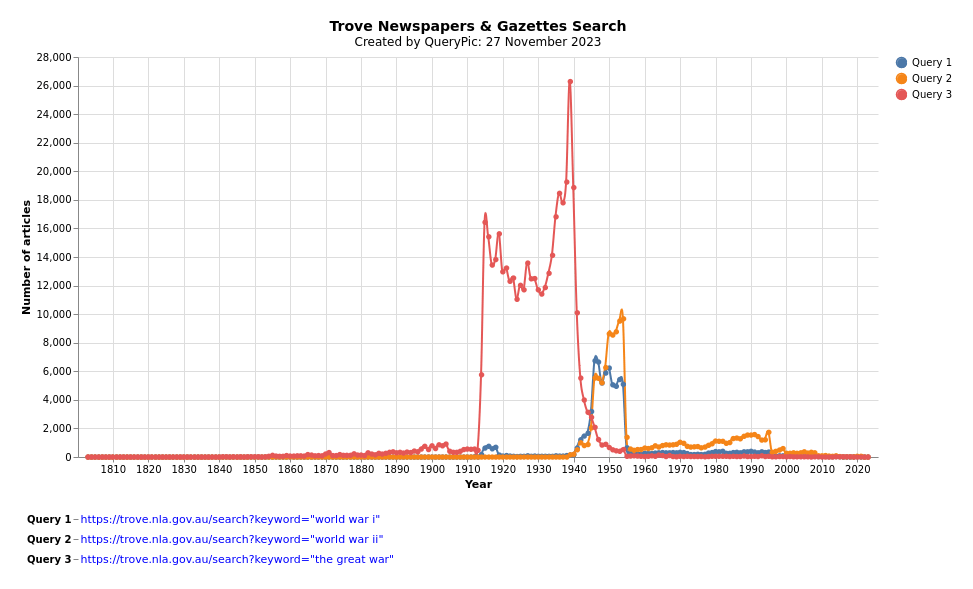
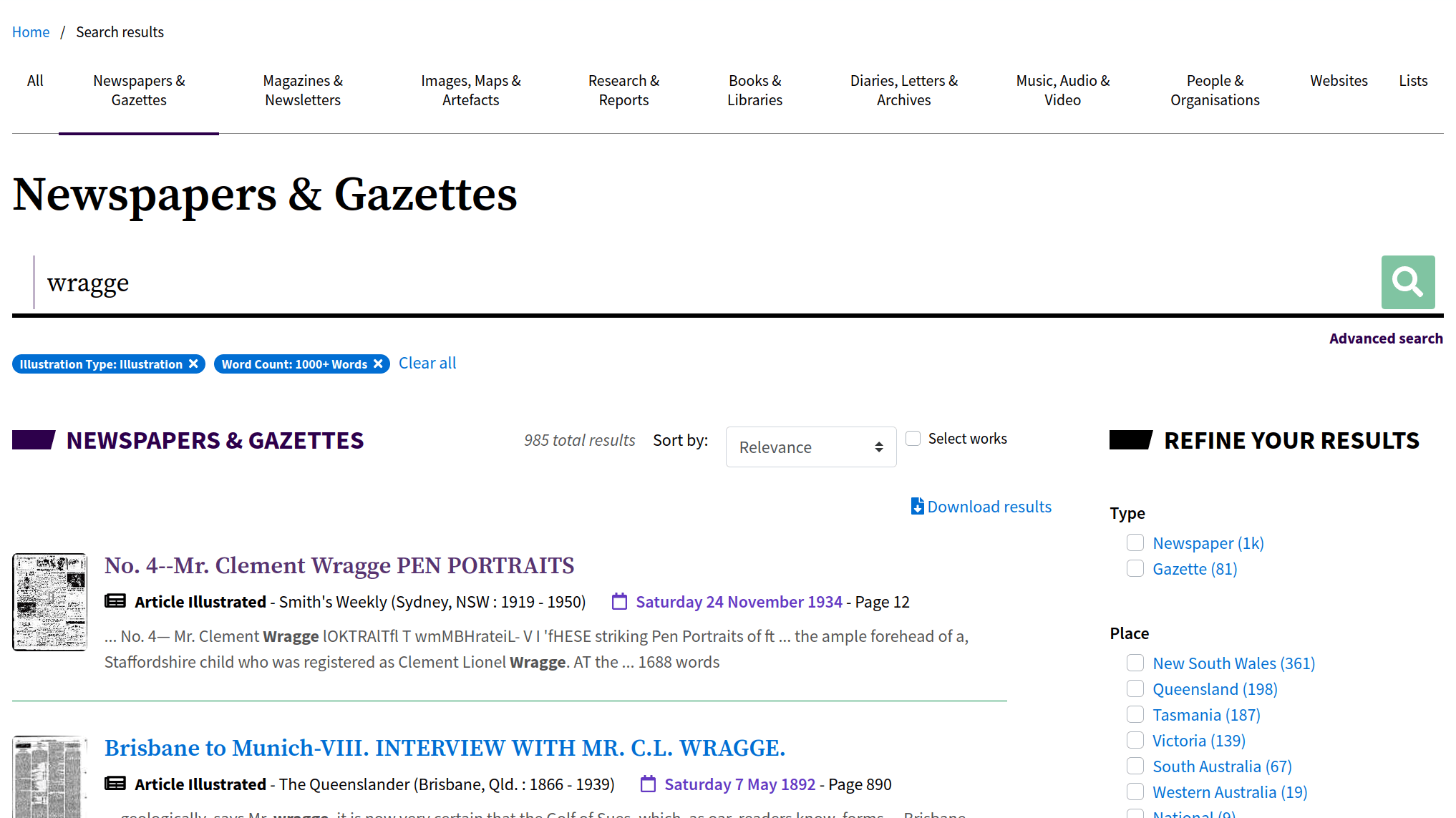
Newspapers & Gazettes
People & Organisations
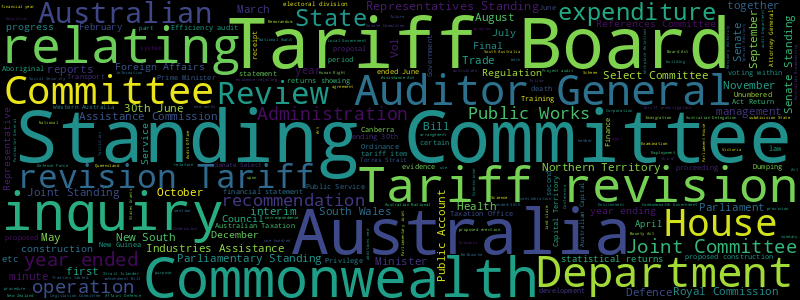
Research & Reports
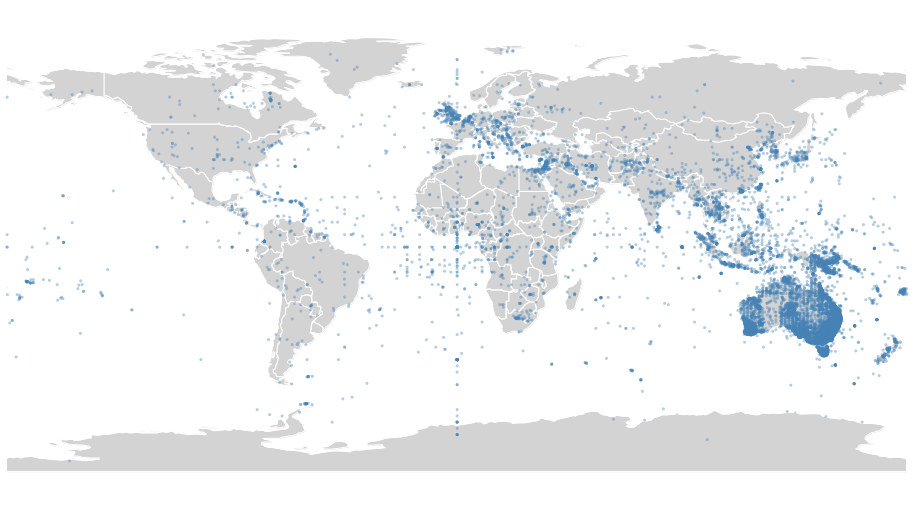
Websites
Books & Libraries
Diaries, Letters & Archives
Images, Maps & Artefacts
Lists
Magazines & Newsletters
Music, Audio & Video
Newspapers & Gazettes
People & Organisations
Research & Reports
Websites
Books & Libraries
Diaries, Letters & Archives
Images, Maps & Artefacts
Lists
Magazines & Newsletters
Music, Audio & Video
Newspapers & Gazettes
People & Organisations
Research & Reports
Websites
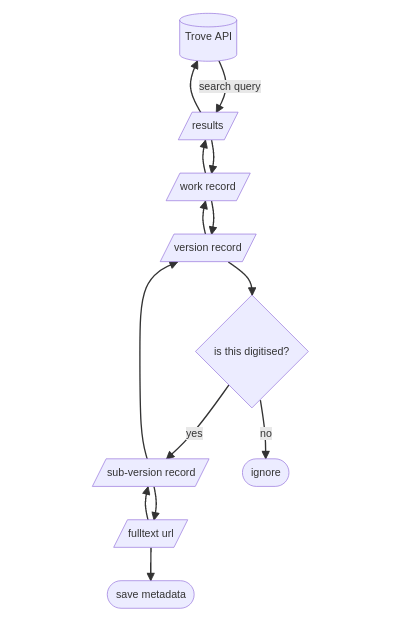
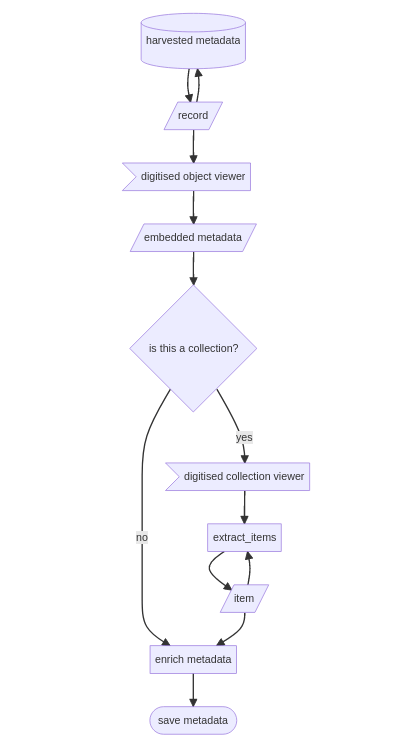
Understand the technical context — How does it work? Consult the documentation (and this Guide) to understand your options
Be creative and strategic — Solve your puzzle by experimenting and looking for clues in the results
Stay critical — Always assume that Trove isn’t telling you everything
"isPartOf": [
{
"value": "Australian ephemera collection (Programs and invitations)",
"type": "series"
}
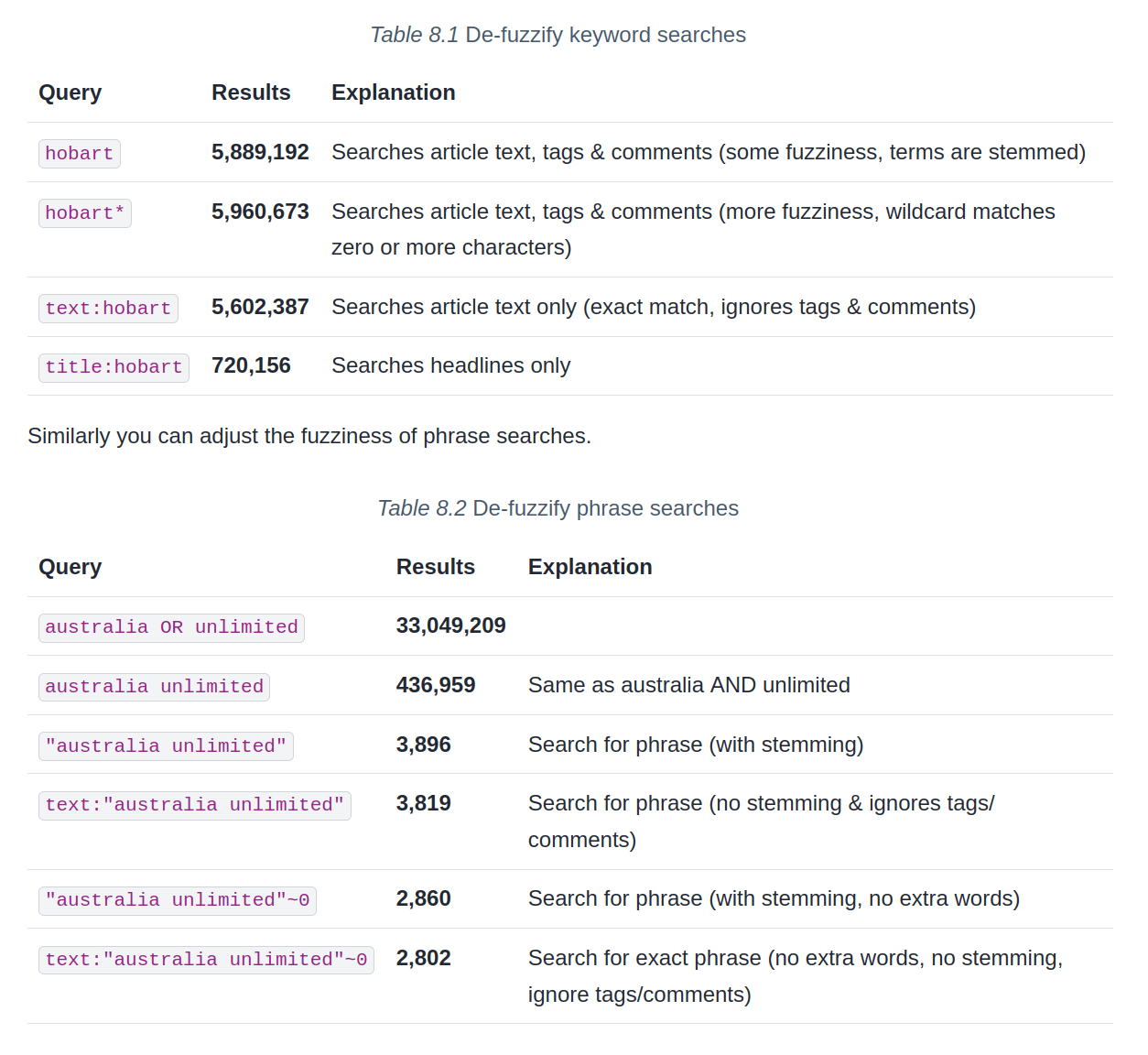
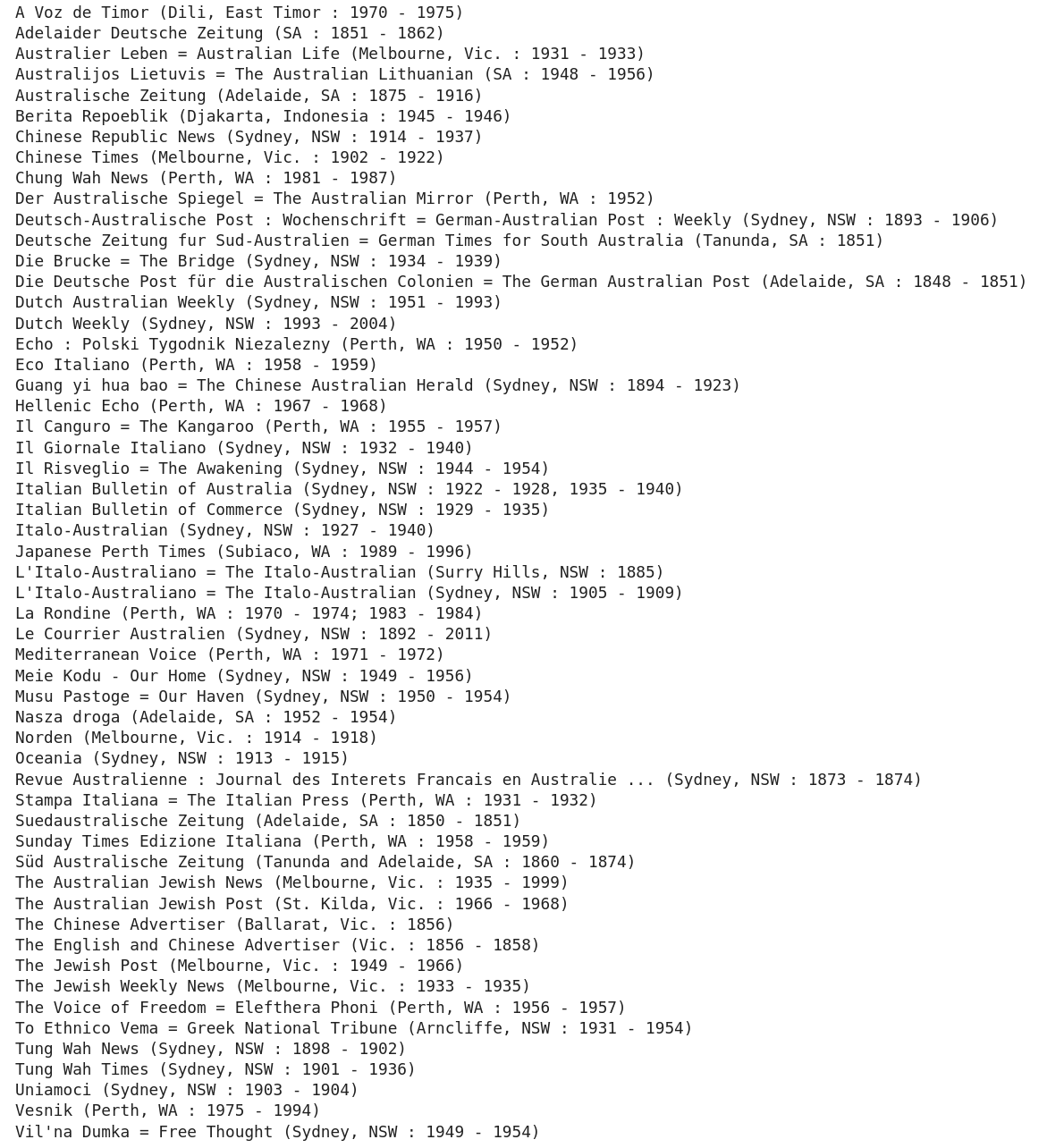
]search the isPartOf values for "ephemera"
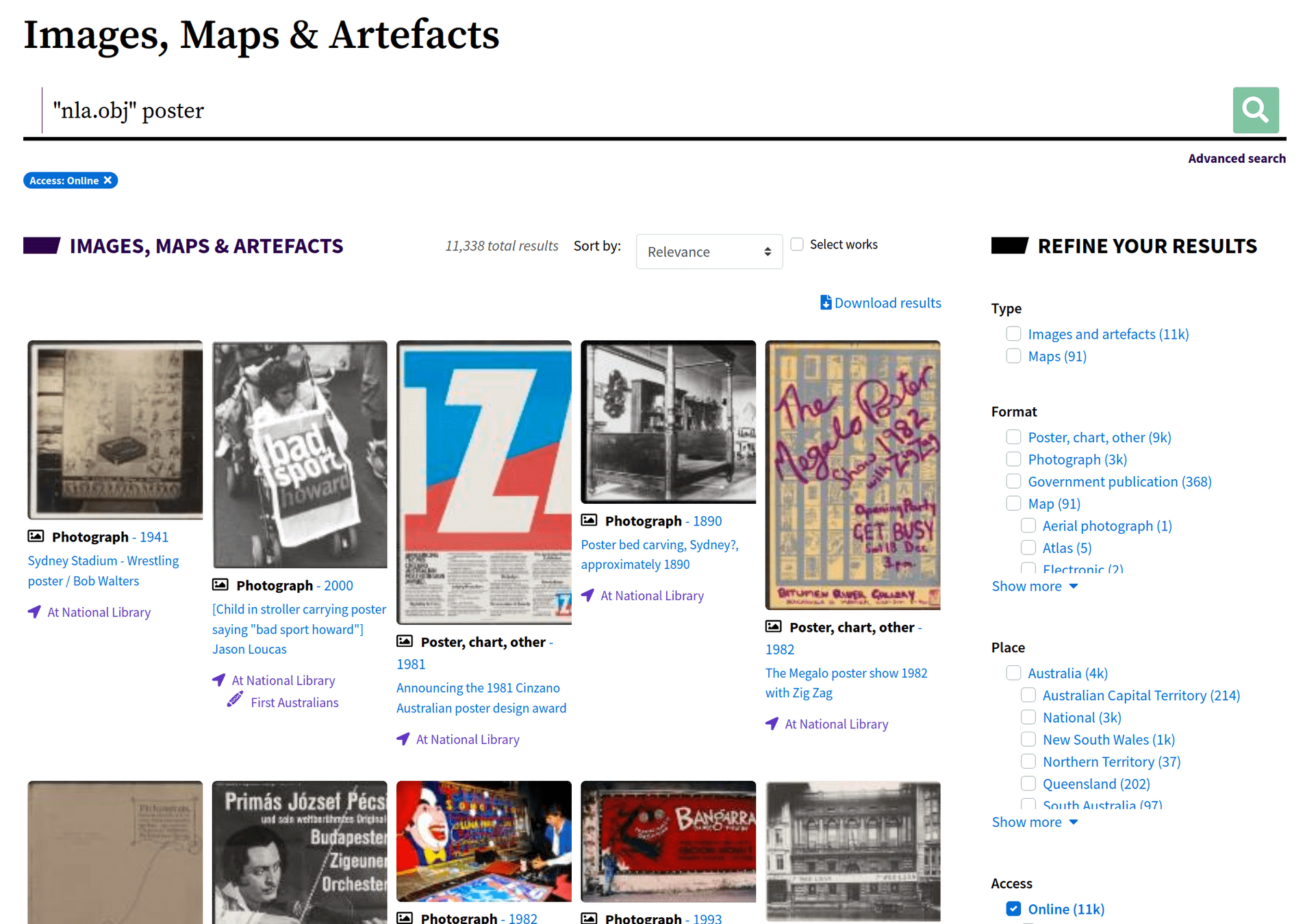
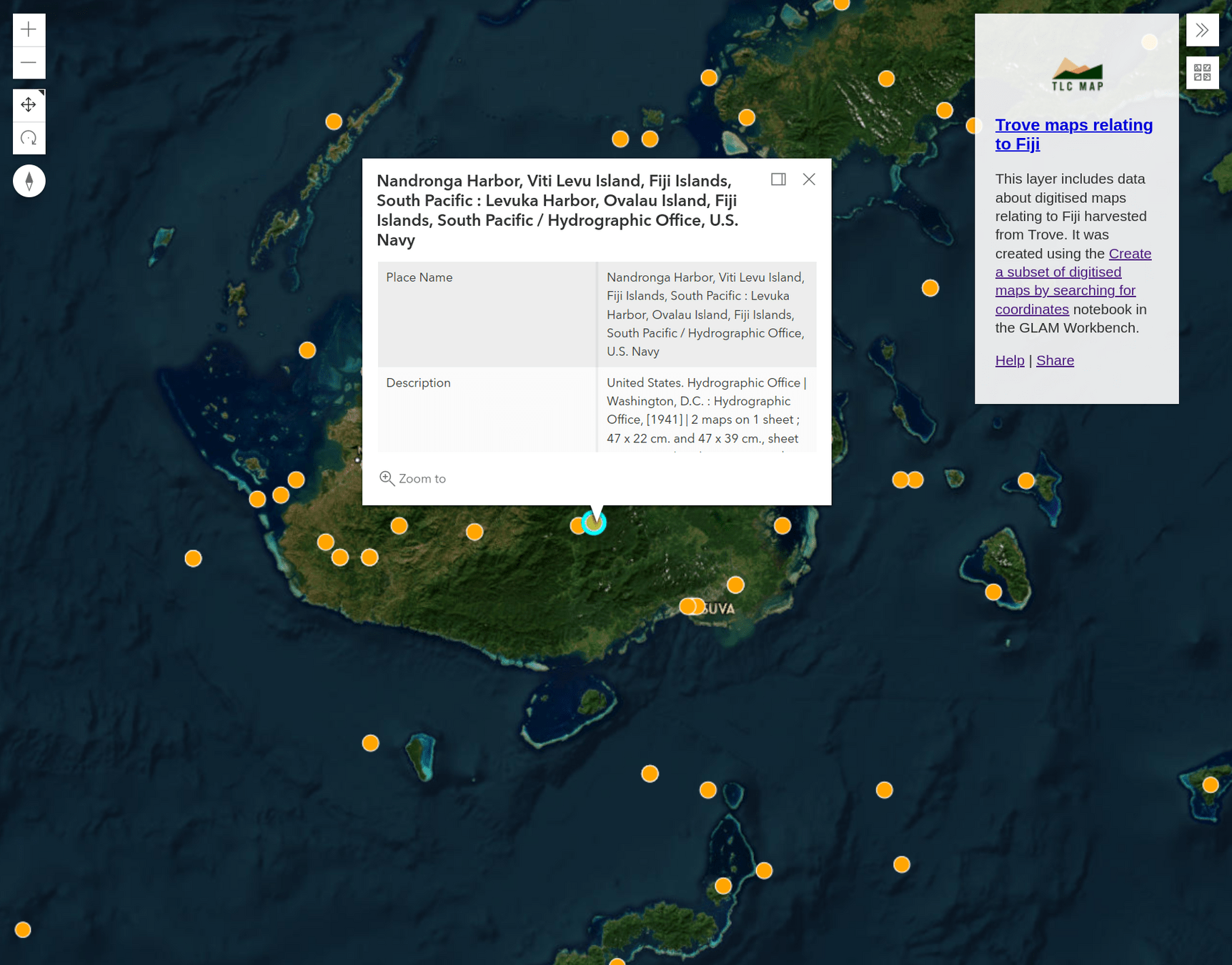
"nla.obj" (with the quotes)🔭 explore
🔭 explore
{
{
{
{
{
{
{
{
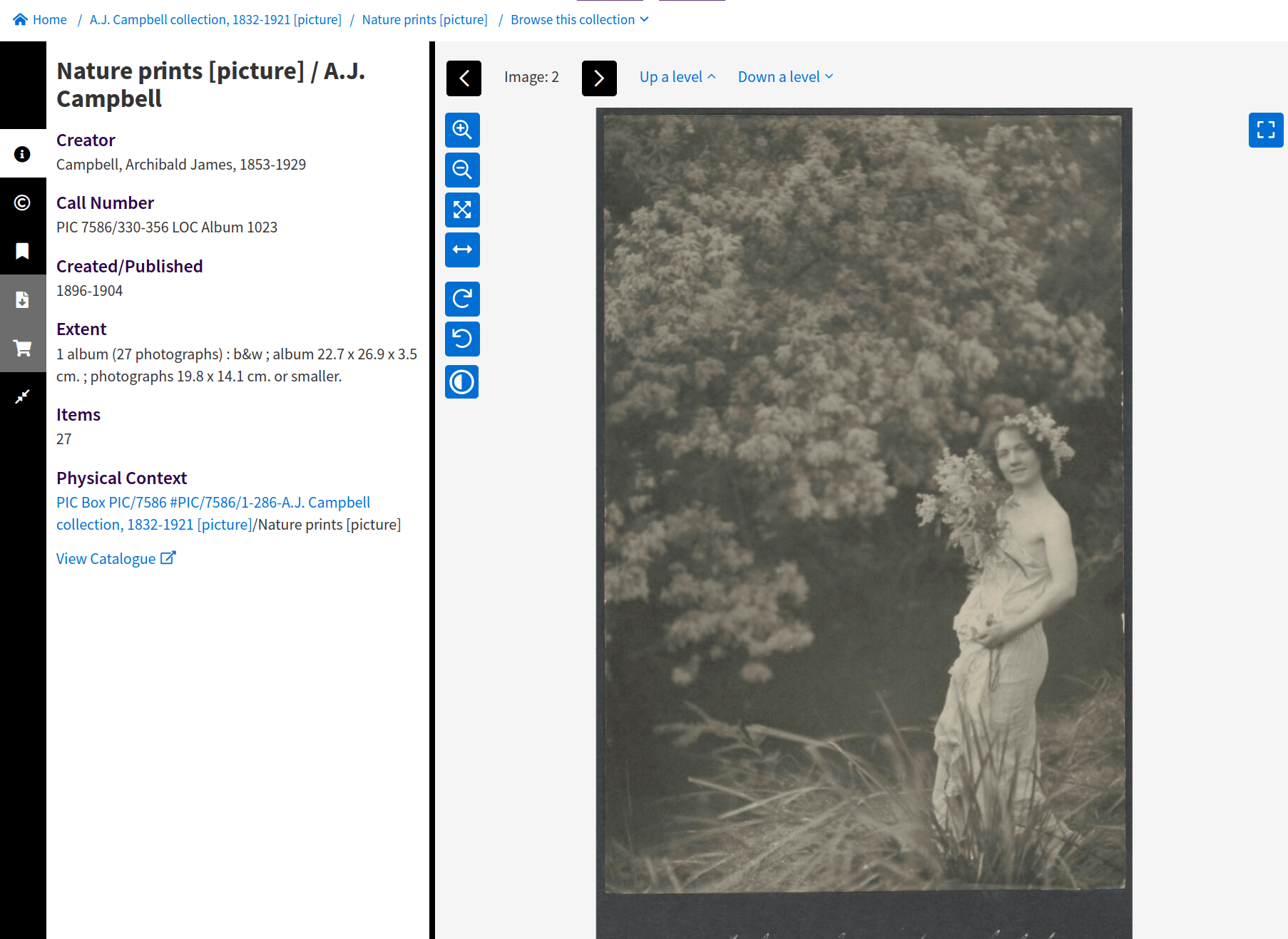
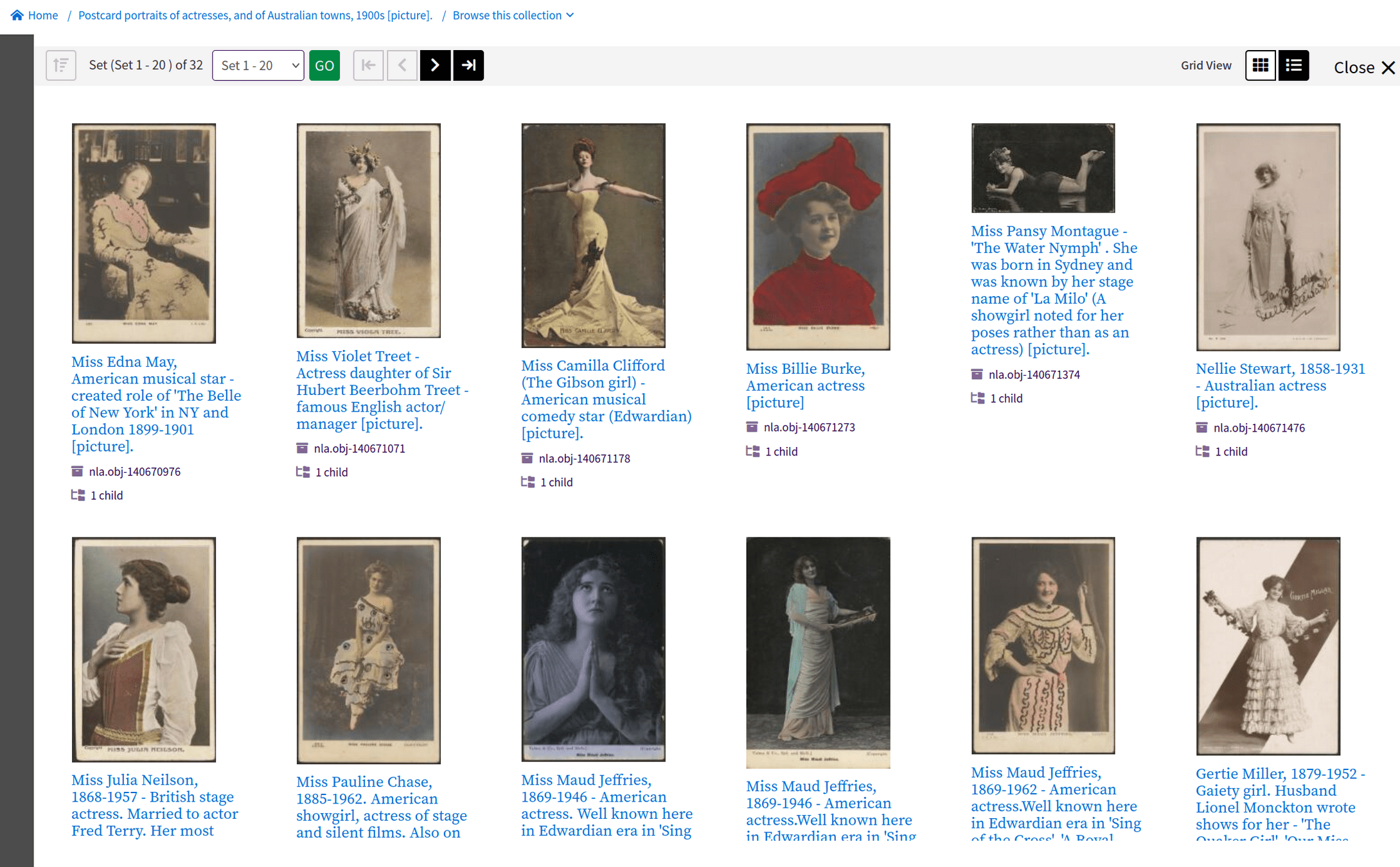
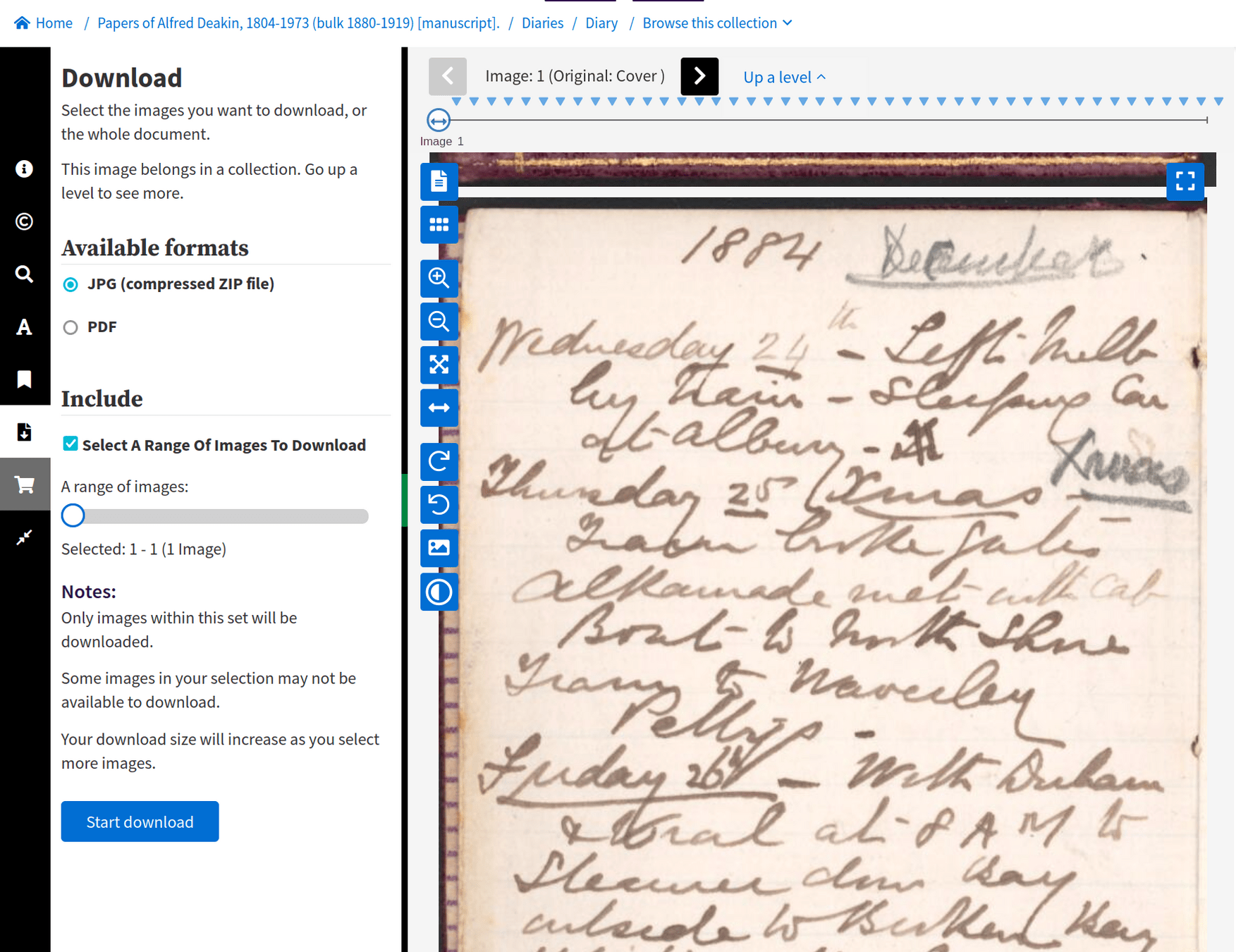
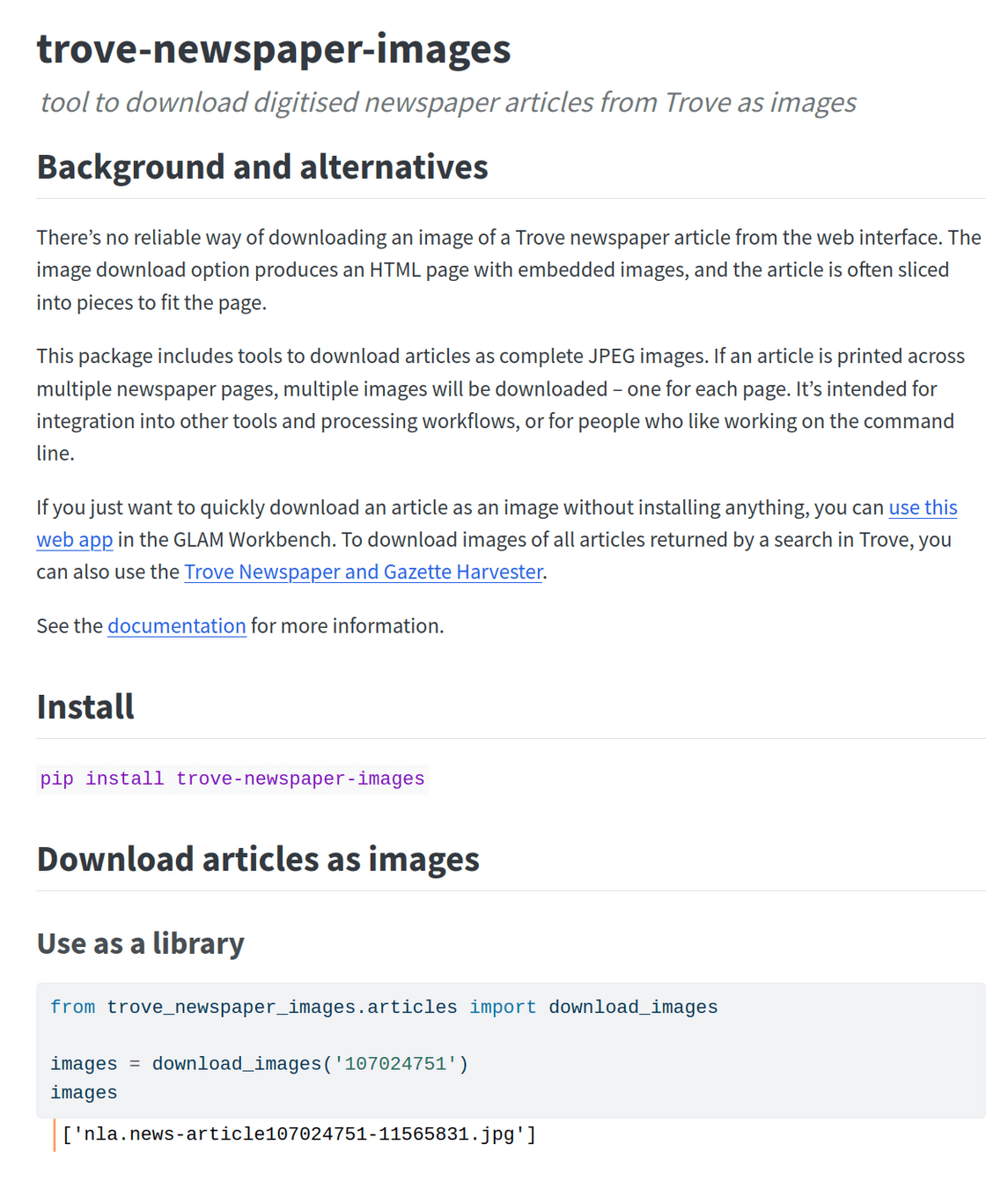
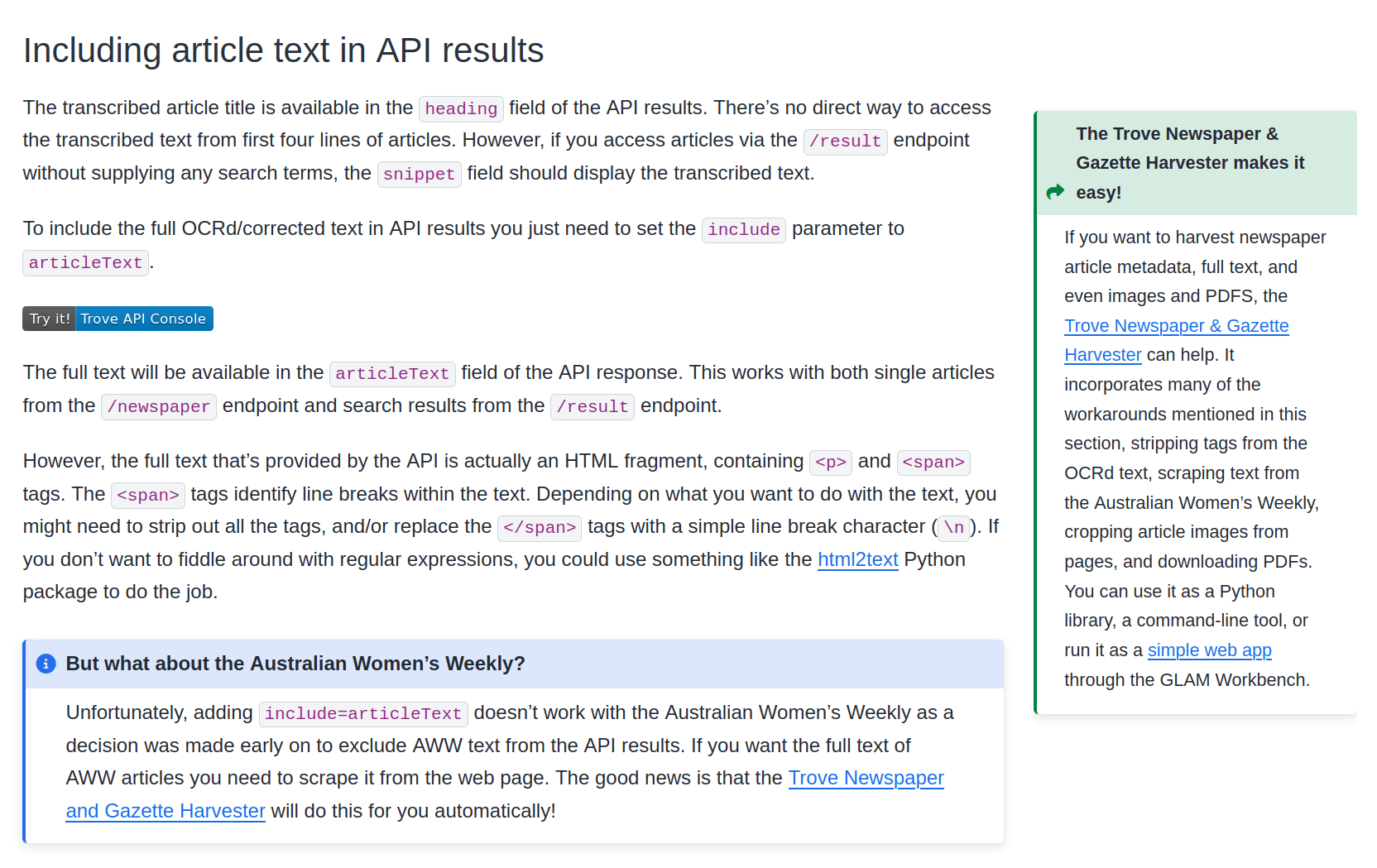
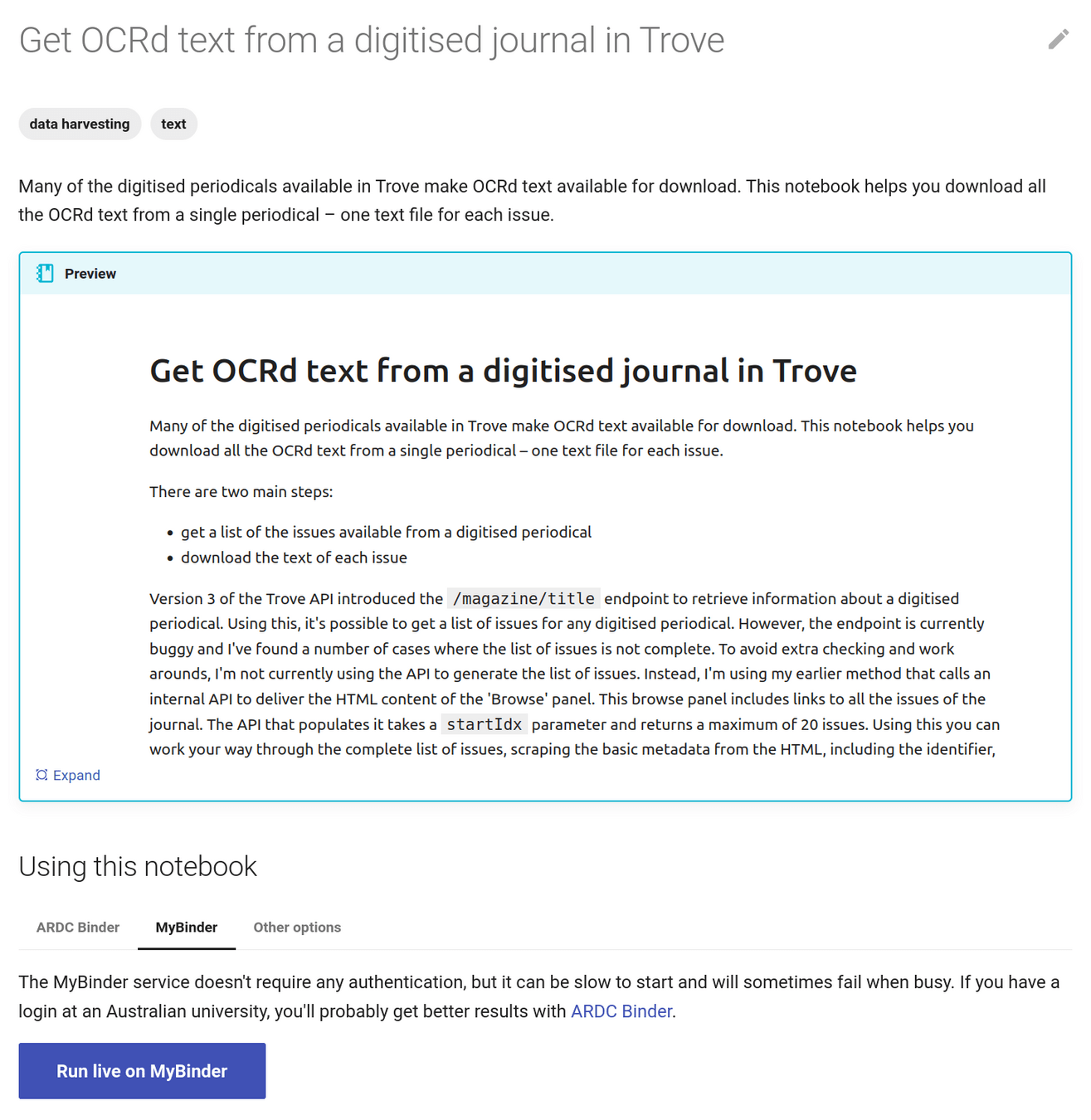
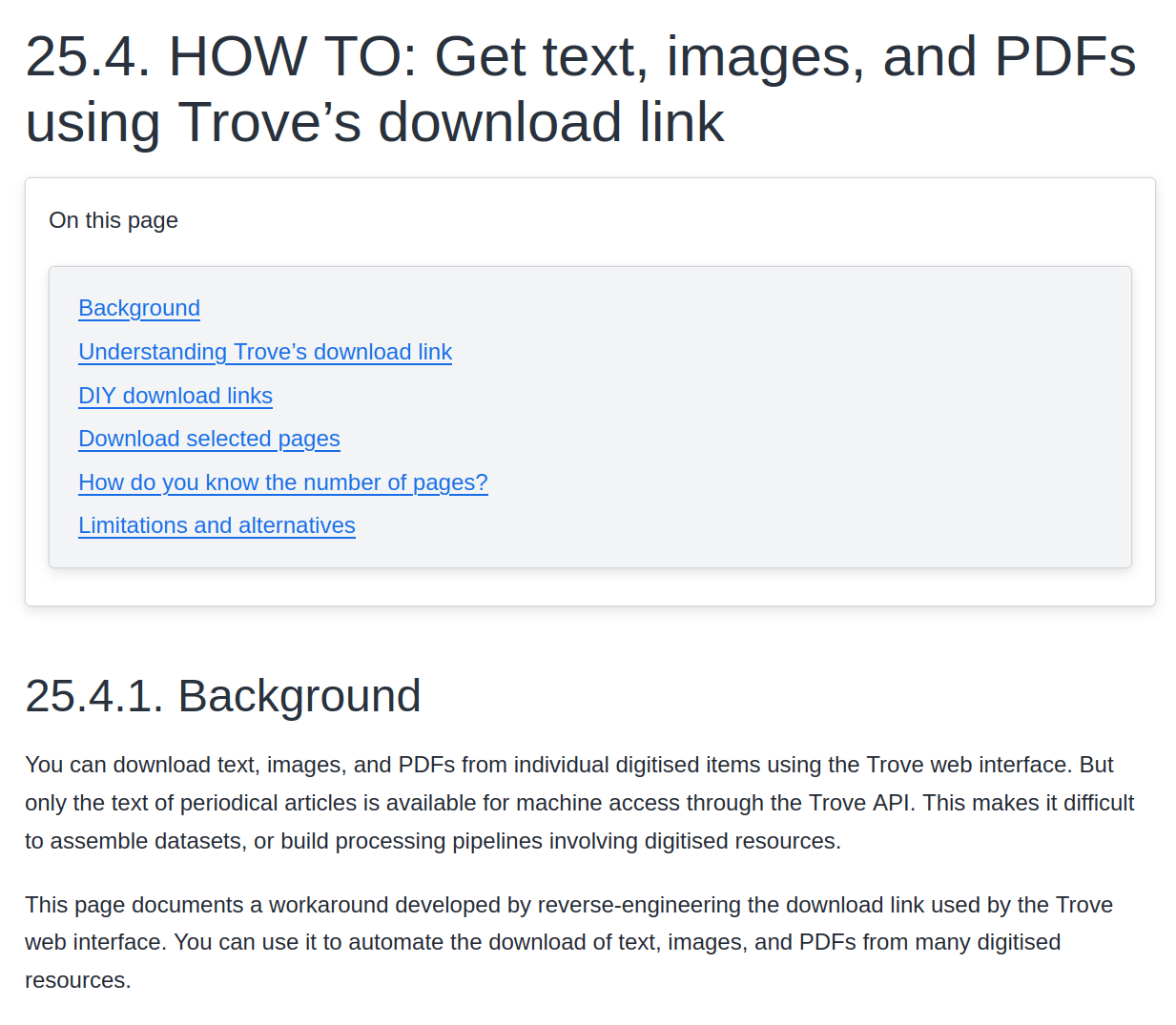
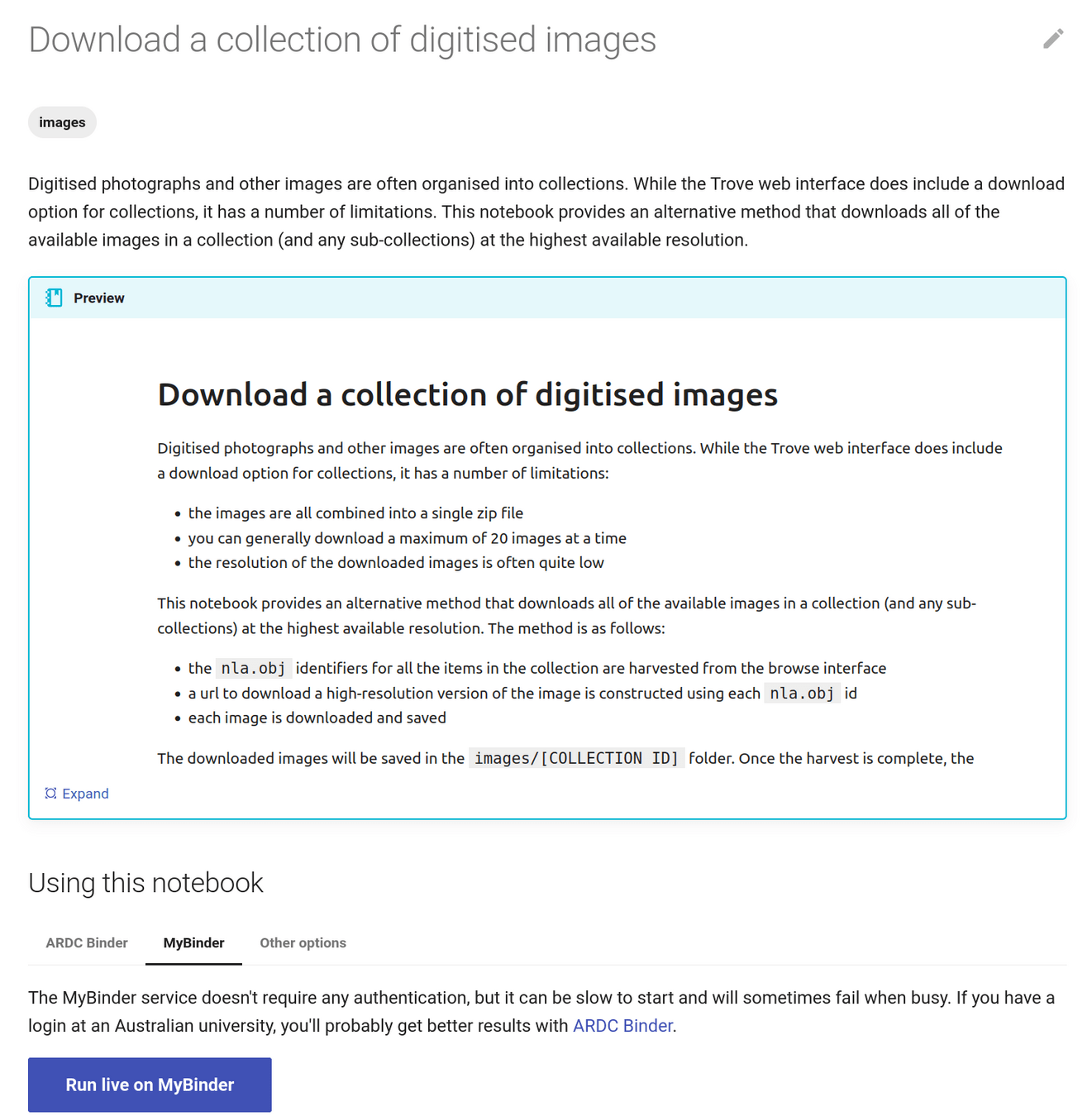
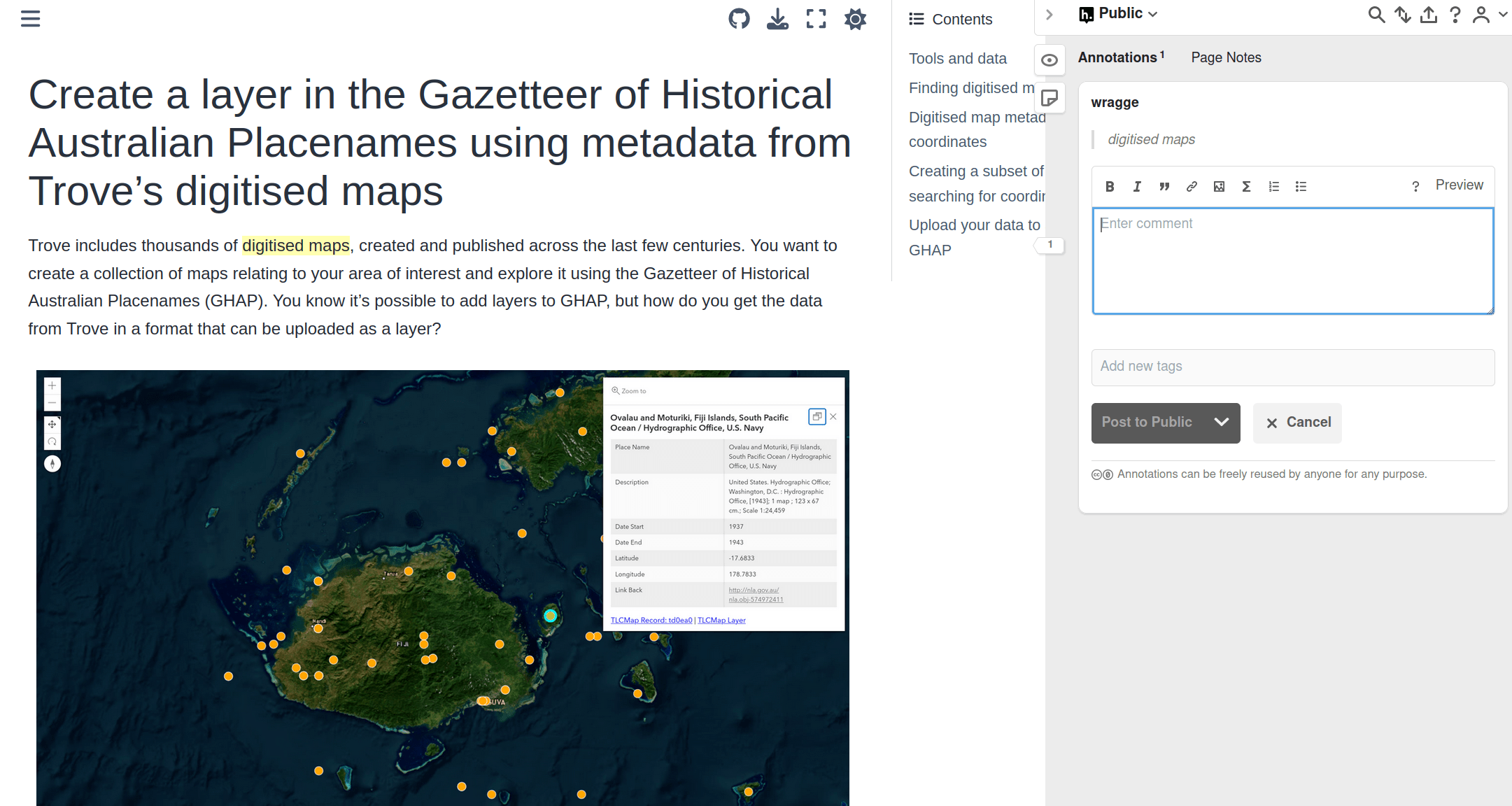
beyond Trove's web interface 🚀
downloading as 'image' delivers an HTML page
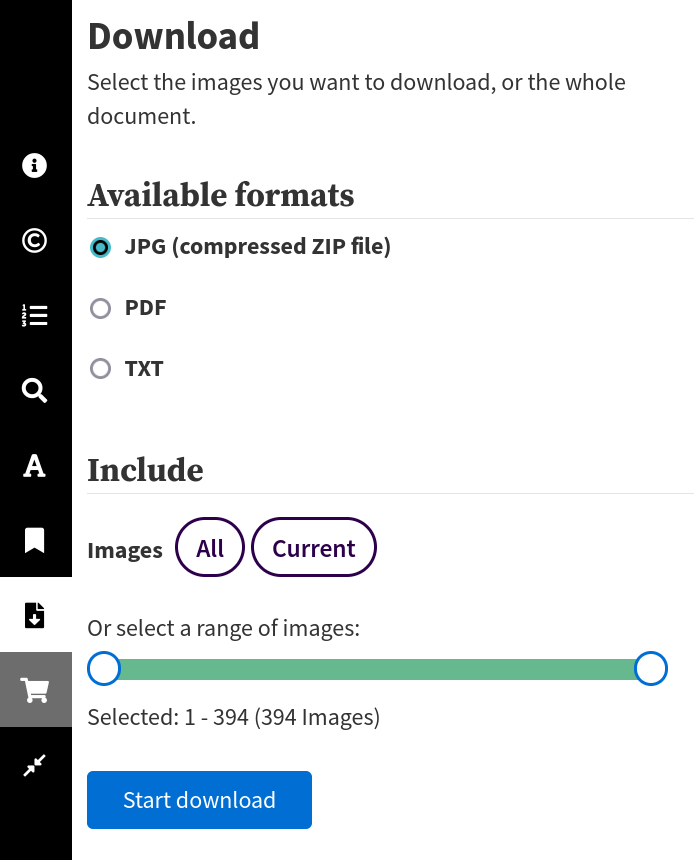
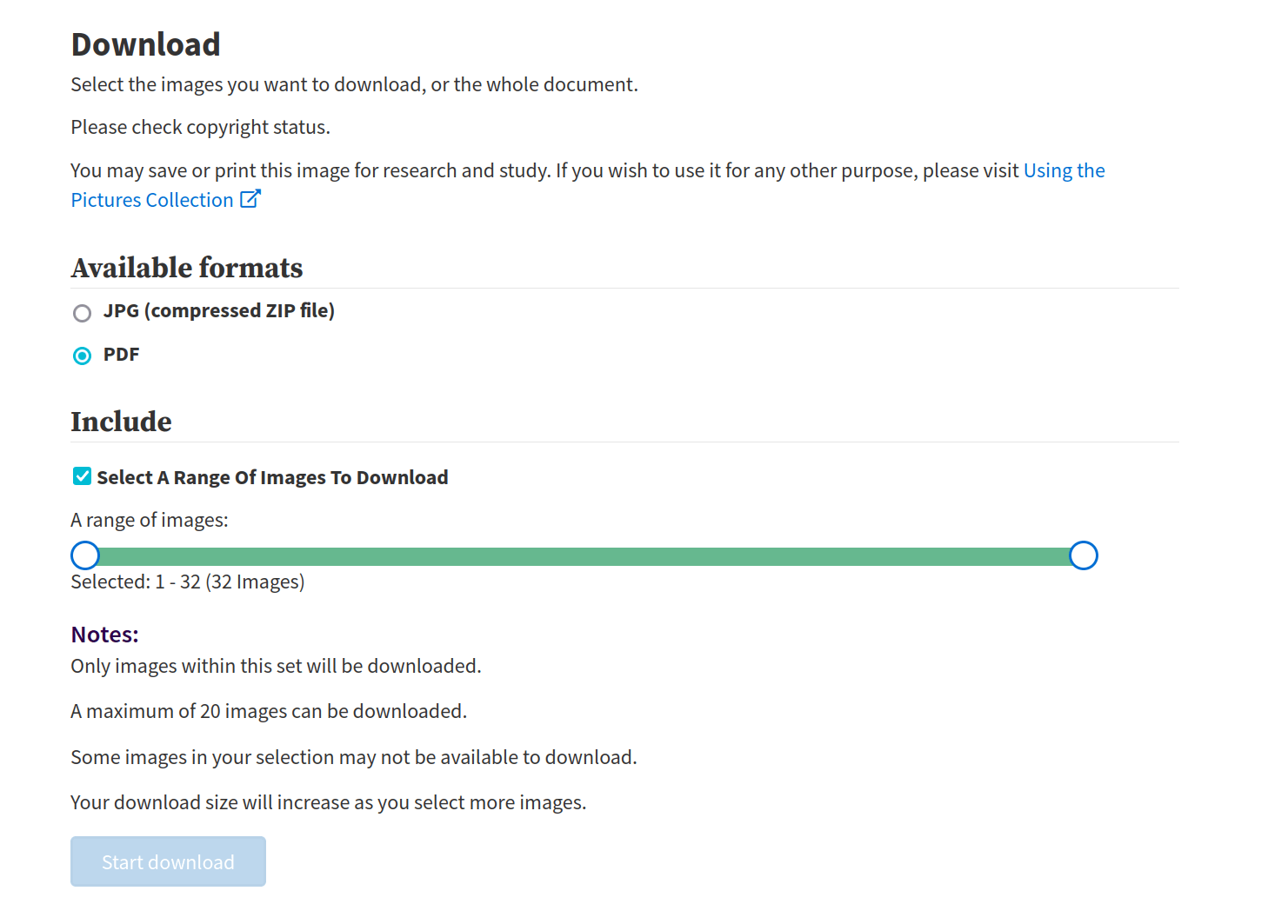
limit of 20
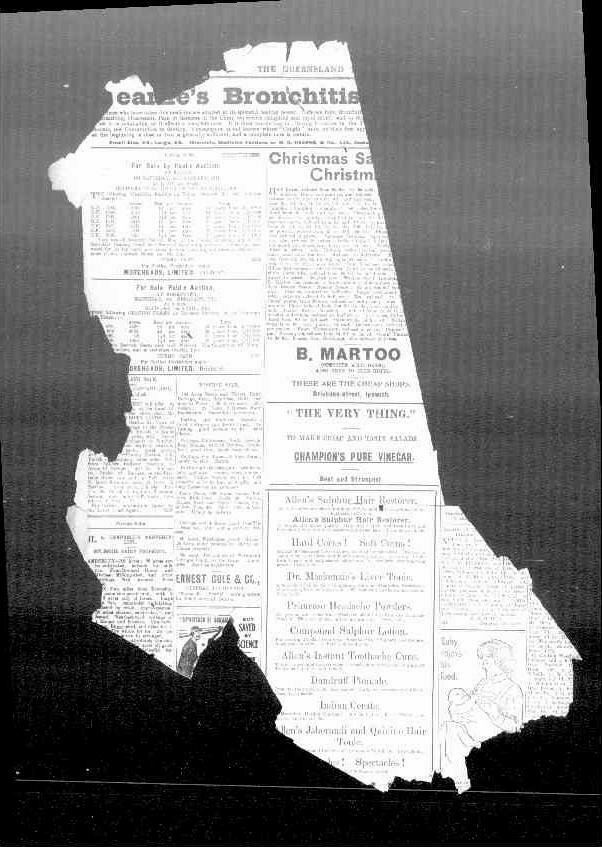
backs missing
(no sub-collections)
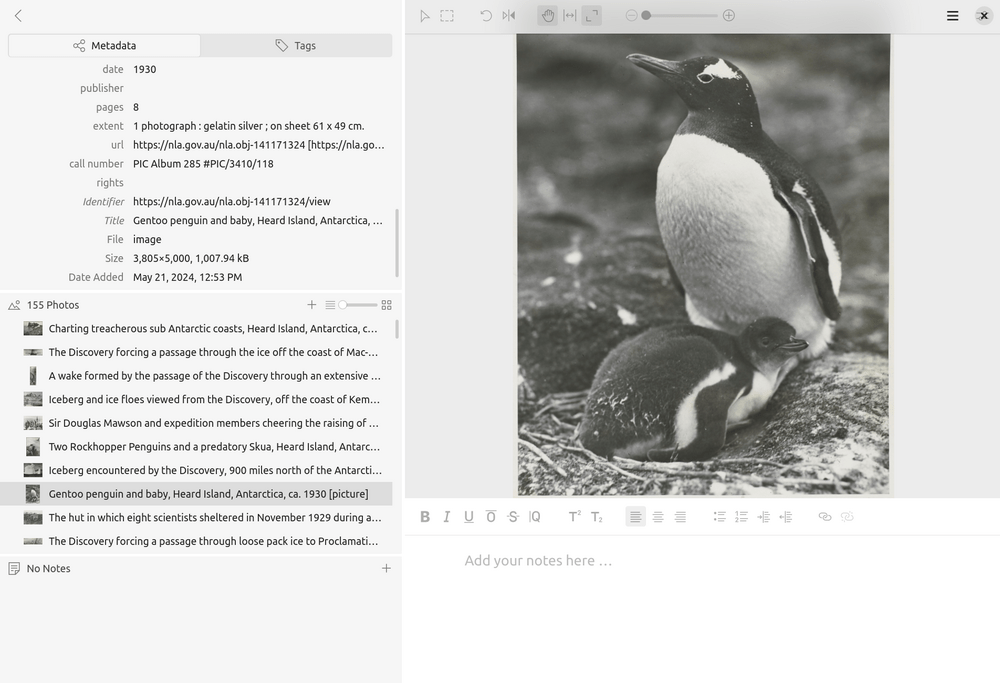
low resolution (1000px x 1588px)
missing metadata
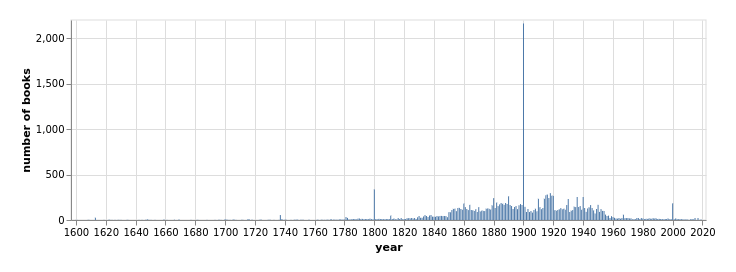
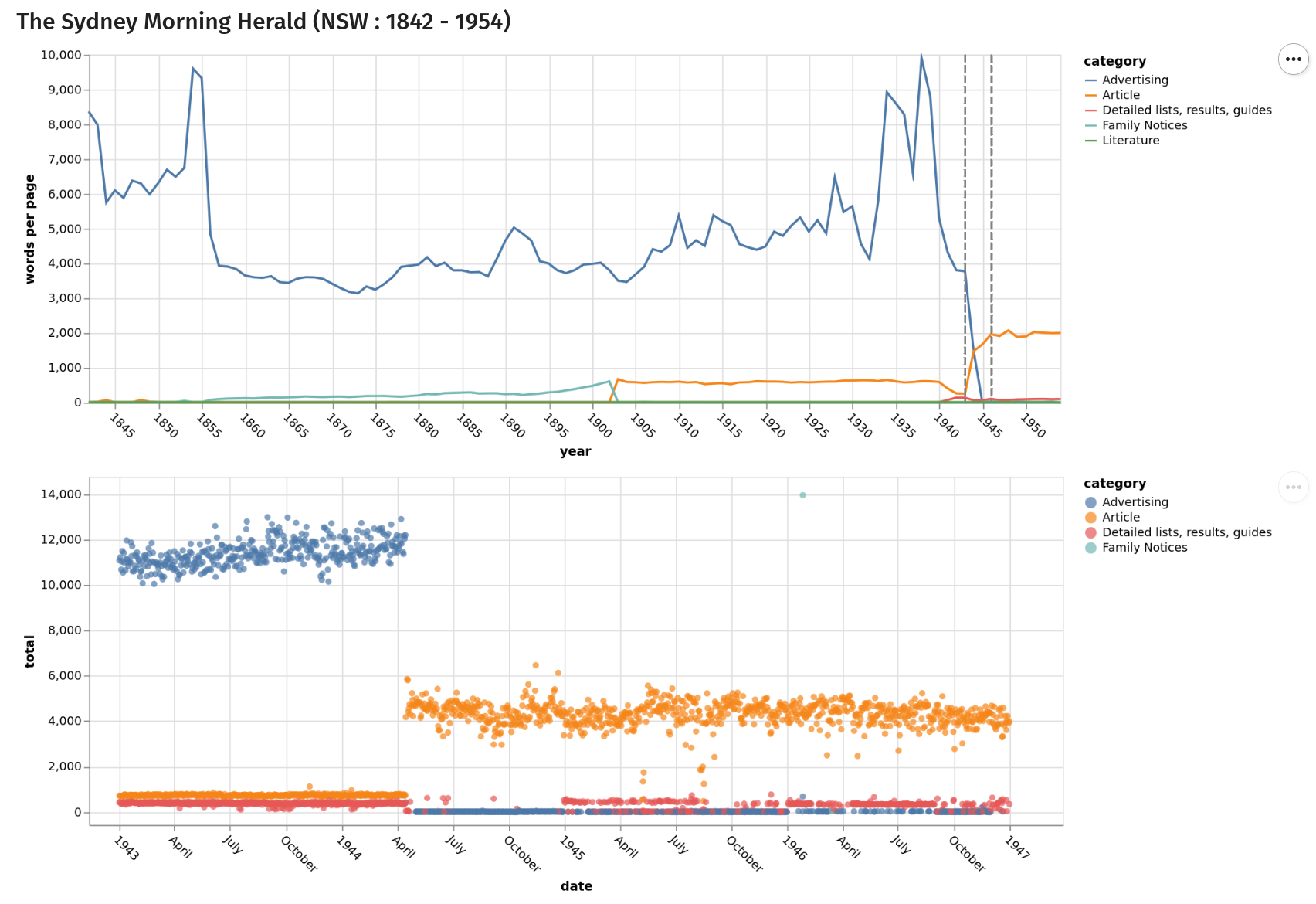
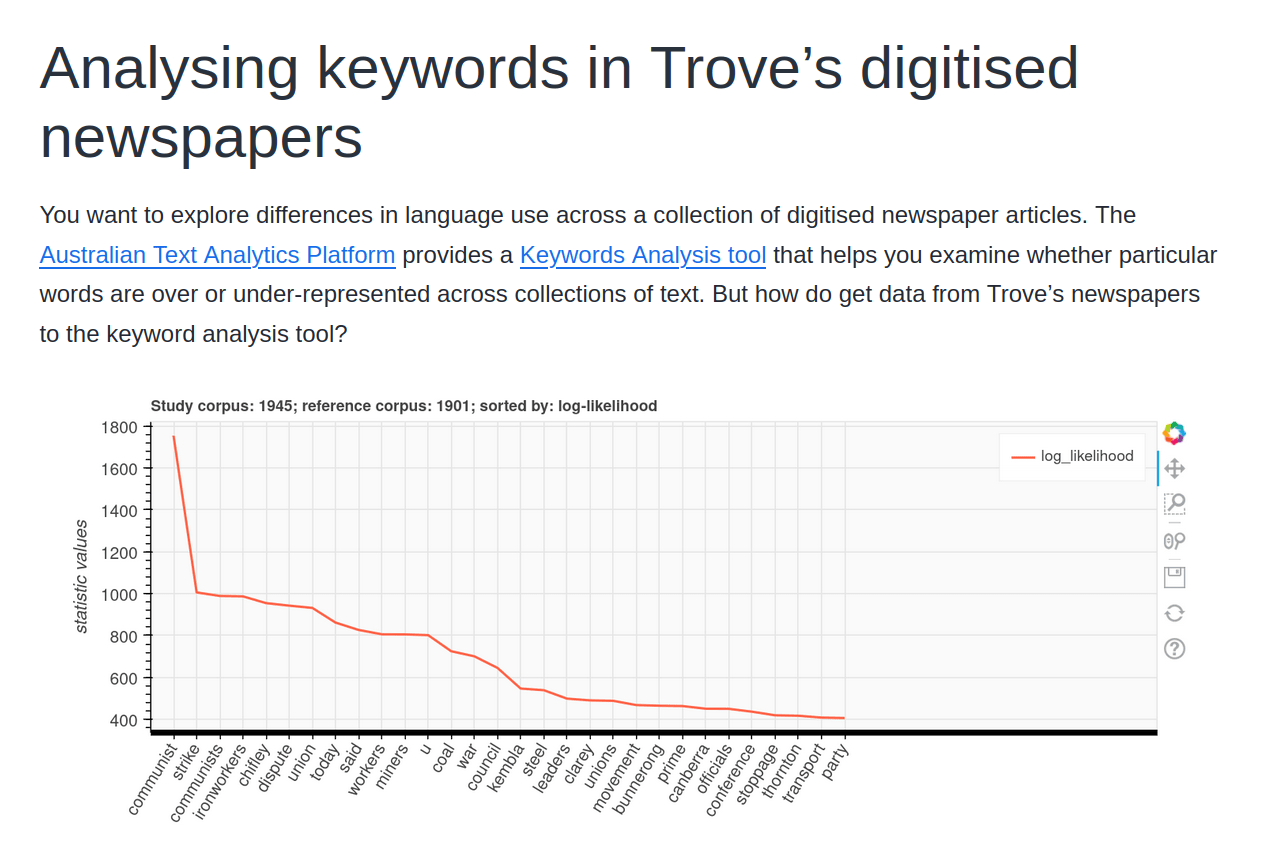
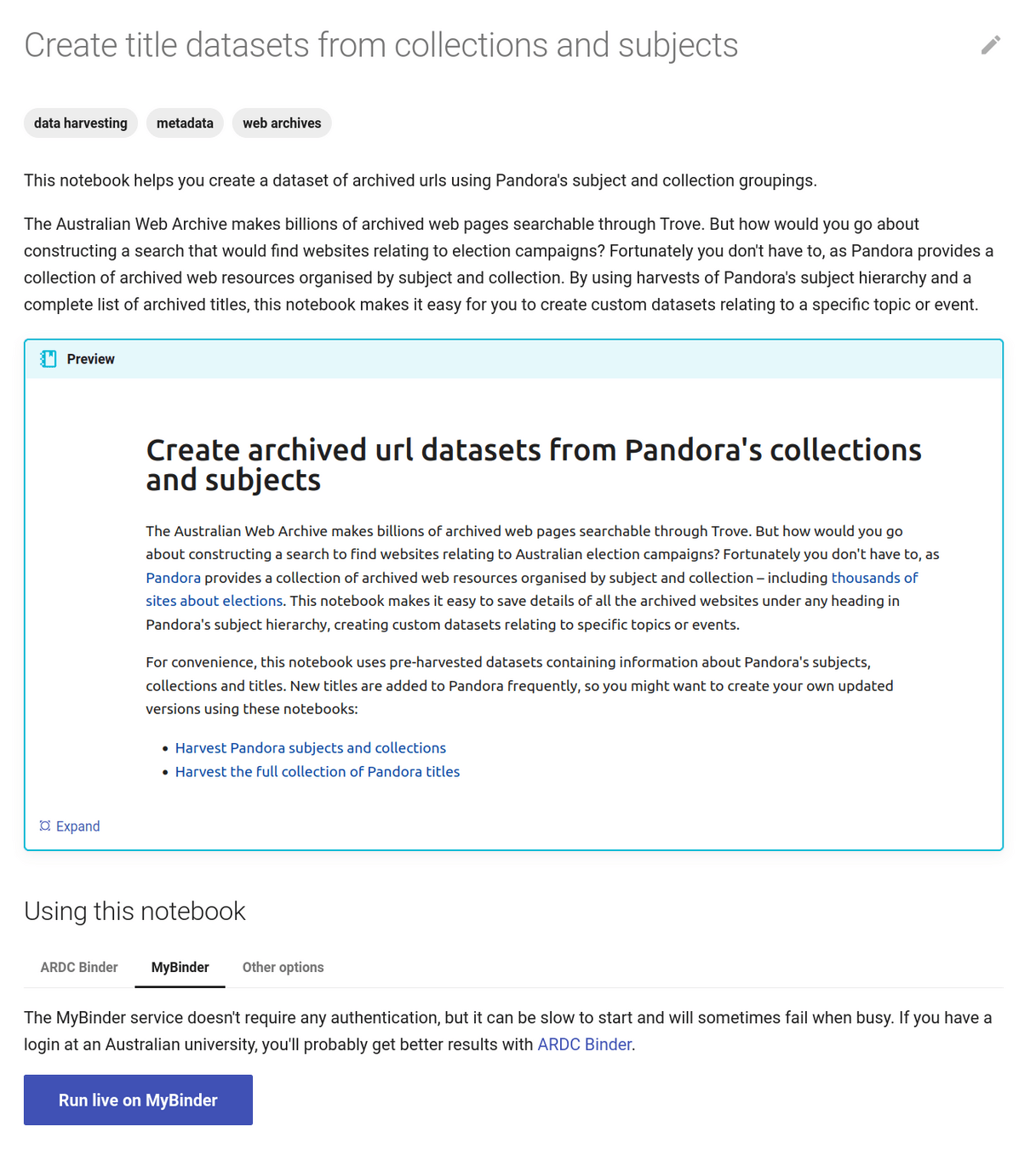
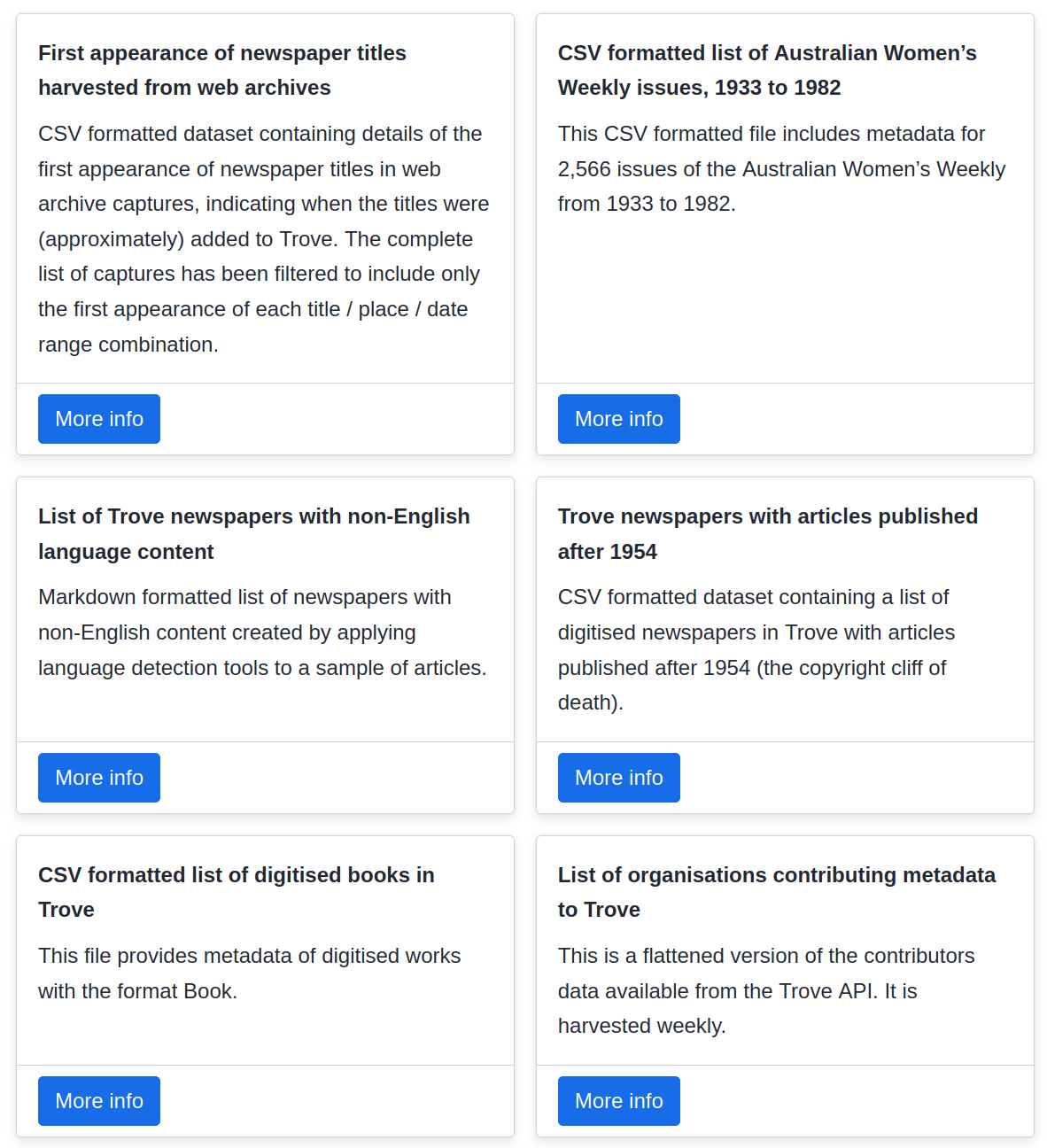
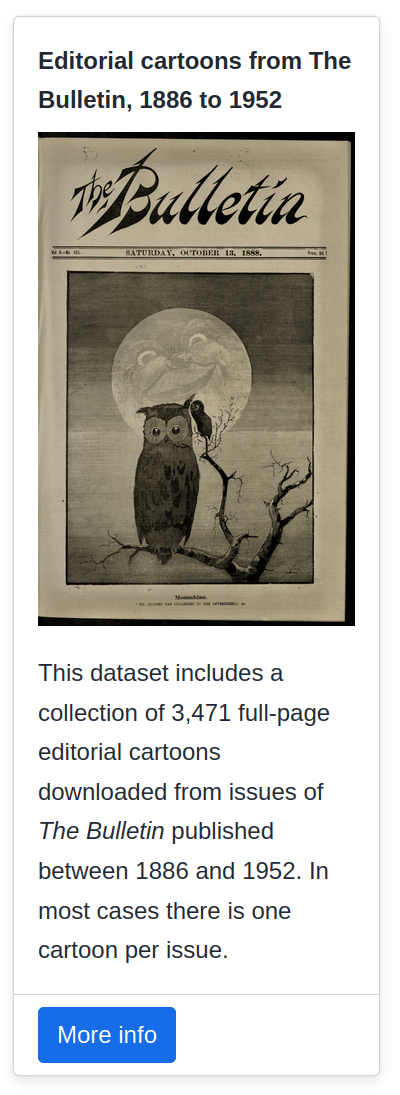
creating datasets
{
"id": "61389505",
"url": "https://api.trove.nla.gov.au/v3/newspaper/61389505",
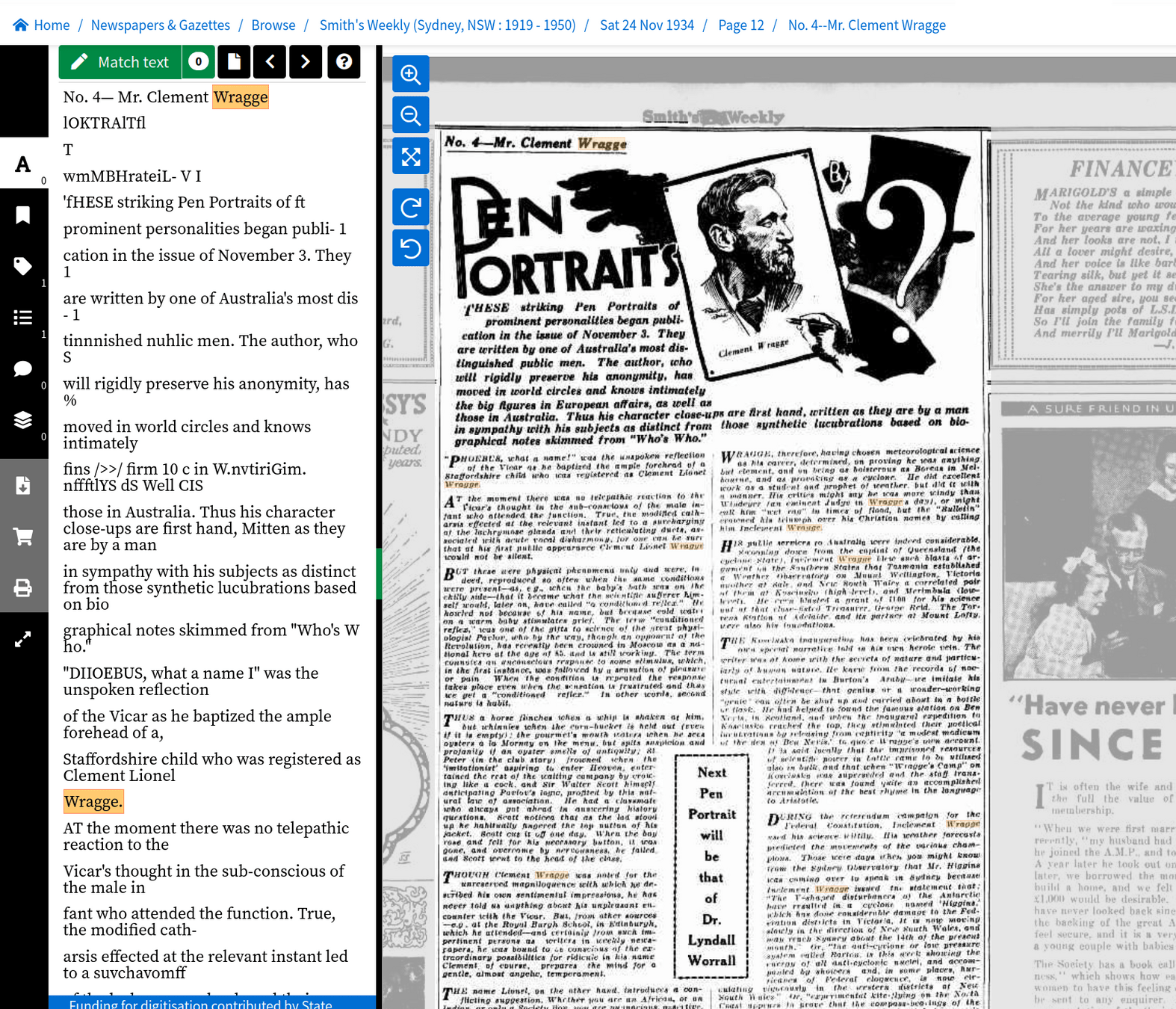
"heading": "MR. WRAGGE'S \"WRAGGE.\"",
"category": "Article",
"title": {
"id": "64",
"title": "Clarence and Richmond Examiner (Grafton, NSW : 1889 - 1915)"
},
"date": "1902-07-15",
"page": "4",
"pageSequence": "4",
"troveUrl": "https://nla.gov.au/nla.news-article61389505"
}🤯
check 'mask image' and try again – what changes?
change the url suffix from /view to /image in your browser's location bar
click enter to view the image
choose 'Save image as...' from the right click menu to download the image
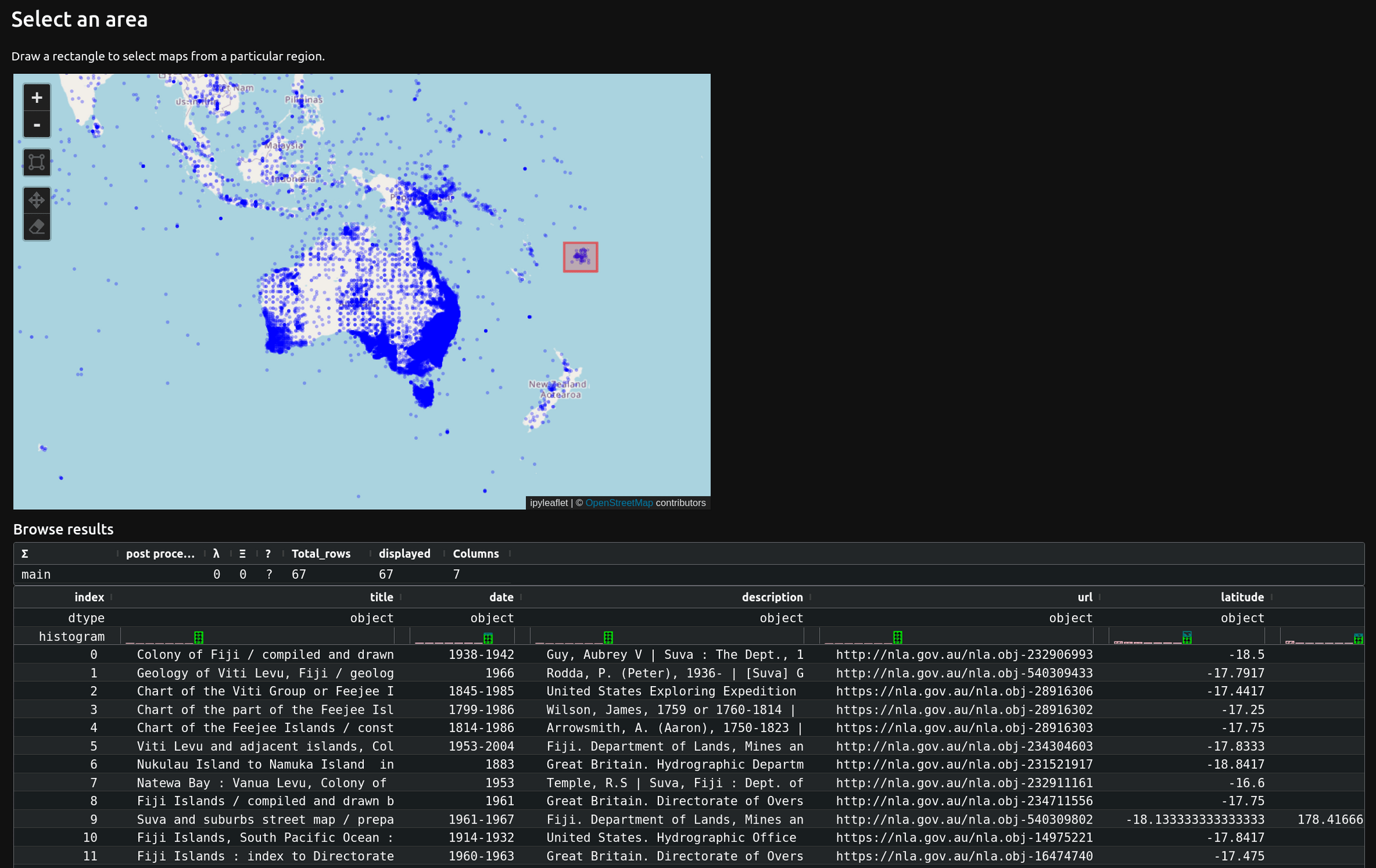
🔭 explore
email: tim@timsherratt.au
web: timsherratt.au
mastodon: @wragge@hcommons.social
updates: https://updates.timsherratt.org/
By Tim Sherratt
Presented at the Australian Historical Association Annual Conference, 1 July 2024




