MeGATrack
Efficient hand tracking for Quest 2 VR headset
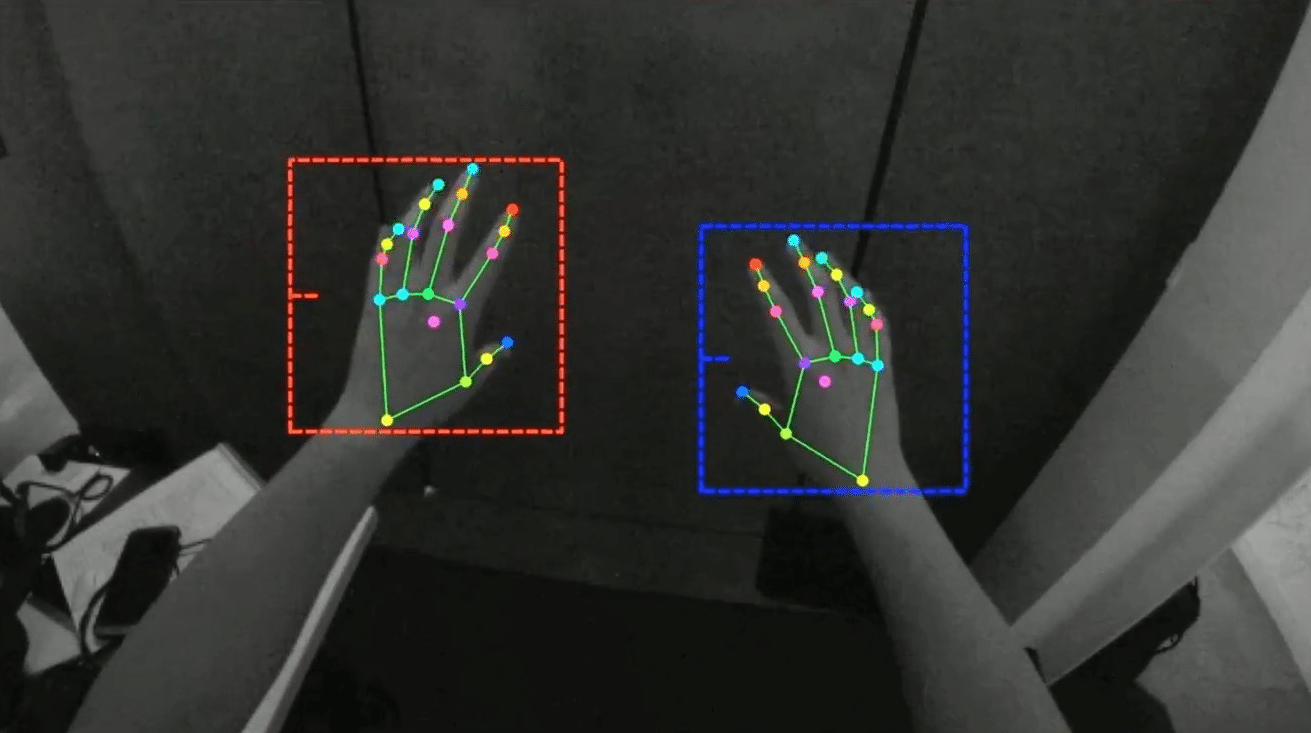
How it looks
Hand Tracking isn't new
Mediapipe

MMPose
OpenCV

ARKit
But Quest 2's cameras are uhhh...


Quest 2 has 4 spaced-out fish-eye cameras
But Quest 2's cameras are uhhh...
And they have overlaps
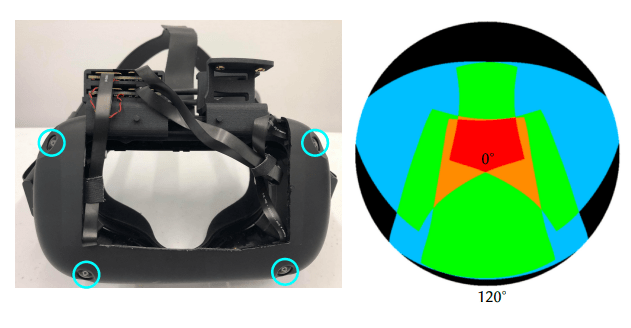
But Quest 2's cameras are uhhh...
All of this typical 2D training data is useless

We need a specialized dataset
Which leads them to creating their own dataset
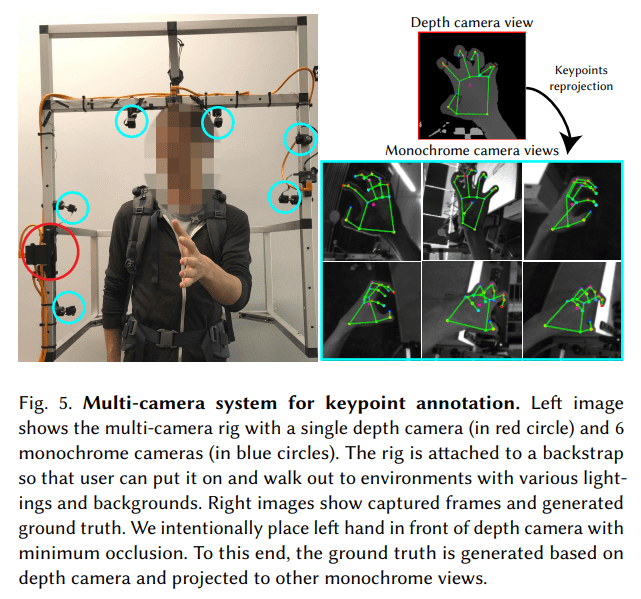
We need a specialized dataset
The RGB-D camera estimates the GT 3D landmarks
The fish-eye cameras project the 3D landmarks to get the fish-eye GT hand landmarks
Fish-eye cameras
RGB-D Camera
We need a specialized dataset
This is for Hand Landmark estimation, when already have a crop
But this is too specialized for Hand Detection

We need a specialized dataset
This is for Hand Landmark estimation, when already have a crop
But this is too specialized for Hand Detection
We need to annotate data for in-the-wild images
We need a specialized dataset



1. Someone annotates the BBox for the first frame
2. It's used to estimate landmarks in first 2 frames
3. Estimate next frame's landmarks using the trajectory
4. Wrap a BBox around the new landmarks
5. Predict using NN with the BBox
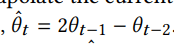
Real-time 🤯
...
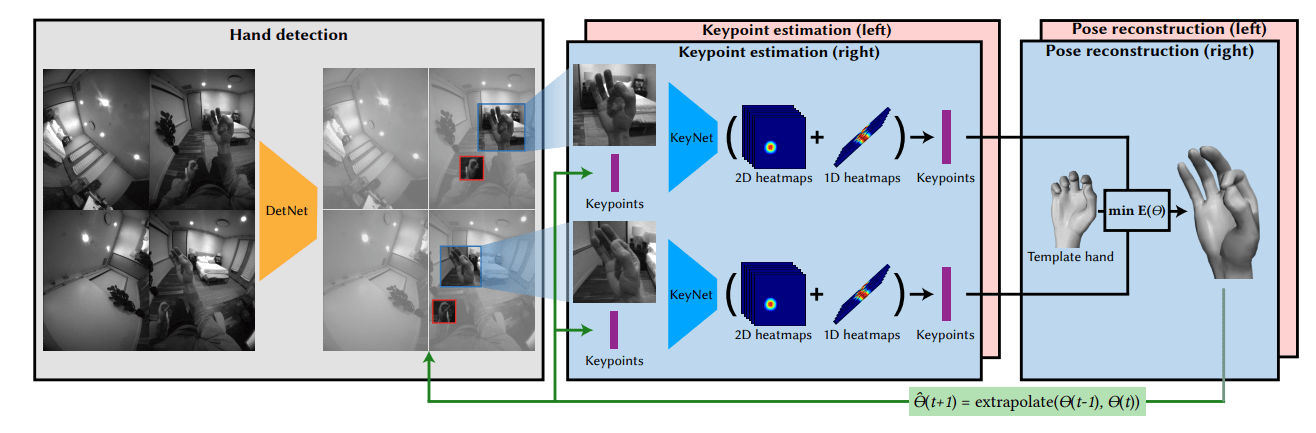
1. Hand detection
2. Keypoint estimation
3. Pose reconstruction
Every frame, very smooth
Real-time 🤯
...
No need to run DetNet on every camera
Run once, get 3D keypoints, project them to all cameras
Real-time 🤯
After the first BBox is detected, same idea as in annotation
No need to run DetNet each frame

3D Hand mesh output
The mesh is a rigged parametric model
Levenberg-Marquadt solver optimizes the pose for each frame

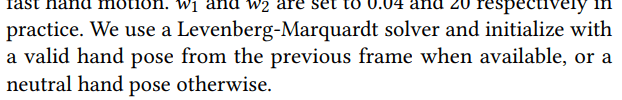
Ambiguous hand scale
When the hand is visible from all cameras, a hand scale parameter is optimized

stereo region
Ambiguous hand scale
This is a heavy operation
So authors do this before hand tracking is even used

Estimating distance
Keypoint estimator only predicts distance relative to the hand center
Actual hand distance is estimated after the model fitting

Hand size is fixed
So we can adjust the distance
Specialized hand tracking
They don't need a general-purpose hand detector
So, by design, they only output detections for left/right hand
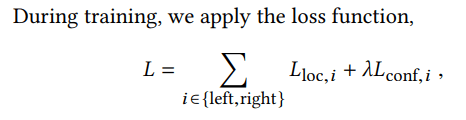
Design decisions for hand tracking smoothness
Keypoints are estimated via regressing heatmaps
Then doing a weighted average of pixel positions
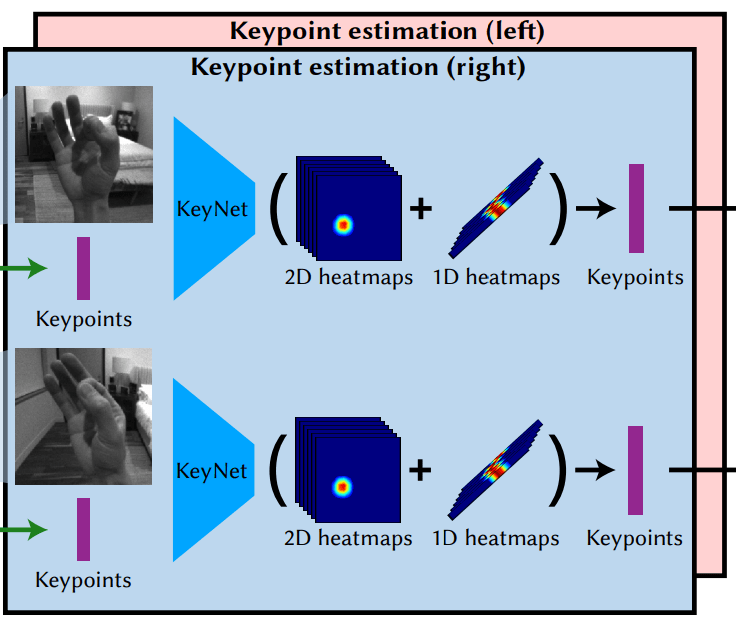
Design decisions for hand tracking smoothness
The next-frame "extrapolation" is used as input to the model

Design decisions for hand tracking smoothness
No need to train for both hands lol
Just train for one, then reflect

Design decisions for hand tracking smoothness
Smoothness isn't enforced in keypoint estimation
Only during mesh fitting
Design decisions for hand tracking smoothness
During training, the extrapolations are sometimes passed inaccurately
Otherwise the network just copies the input

Design decisions for hand tracking smoothness
Lots&lots of augmentations
And keypoint dropouts

Nice.
Nice.
Nice.
Nice.
Nice.
Nice.