Revue 2018 de la Data Science
Sommaire
- OpenAI Five
- NLP's ImageNet Moment?
- Google AutoML
- [Bonus] Some cool stuff
whoami
Data Science Lead @Valoway
Mission actuelle :
Data Science Lead @IMA
OpenAI Five

Dota 2
- Jeu de stratégie en temps réel
- 11 millions de joueurs par mois
- 25 millions de dollars au tournoi mondial annuel 2018
- 5 contre 5 où il faut détruire la base ennemie
- Plus de 100 héros jouables
OpenAI
- Association de recherche à but non lucratif en IA fondée notamment par Elon Musk
- Très orienté "Reinforcement Learning"
Reinforcement Learning
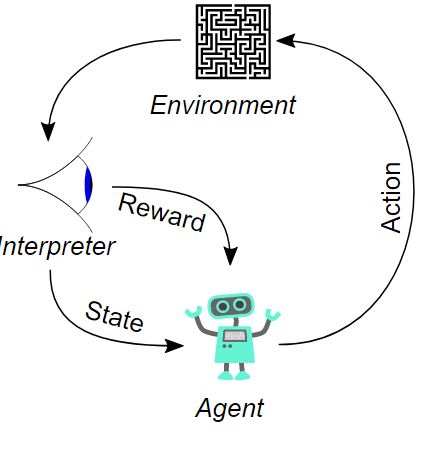
Le scenario typique d'apprentissage par renforcement: un agent effectue une action sur l'environnement, cette action est interprétée en une récompense et une représentation du nouvel état, et cette nouvelle représentation est transmise à l'agent
-- Wikipédia
Le Match
- 5 joueurs semi-pro (top 0.5%)
- Best of 3
Résultat
Victoire écrasante d'OpenAI Five :
OpenAI 3 - 0 Human
Un match en 14 minutes (moyenne est de 45)
Le dernier match, les héros ont été choisis par le public
Qu'est ce qui a changé ?
Fondamentalement : Rien
La "Machine" OpenAI Five
- Une architecture "Etat de l'art"
- Qui scale
1. Architecture
- Utilisation d'un réseau de neurones séparé par héros
- LSTM
- Lors de l'apprentissage, l'algorithme joue contre lui même
- Largement inspiré du papier "Deep Reinforcement Learning" (DeepMind, 2015)
-
Ajout d'une notion de "Team Spirit"
- Score entre 0 et 1 qui détermine à quel point un héros doit se préoccuper de ses récompenses individuelles
2. Scaling
- Système "Rapid" pour paralléliser l'apprentissage
- Utilisation de 128 000 CPU et 256 GPU (~$25000 / jour)
- 180 années de Dota jouées par jour
- Développement d'une approximation pour l'apprentissage
- Permet de faire scaler les méthodes d'apprentissage de l'état de l'art
- Proximal Policy Optimization Algorithms, 2017
So what ?
Ne pas oublier ce qu'il s'est passé pour le jeu de Go
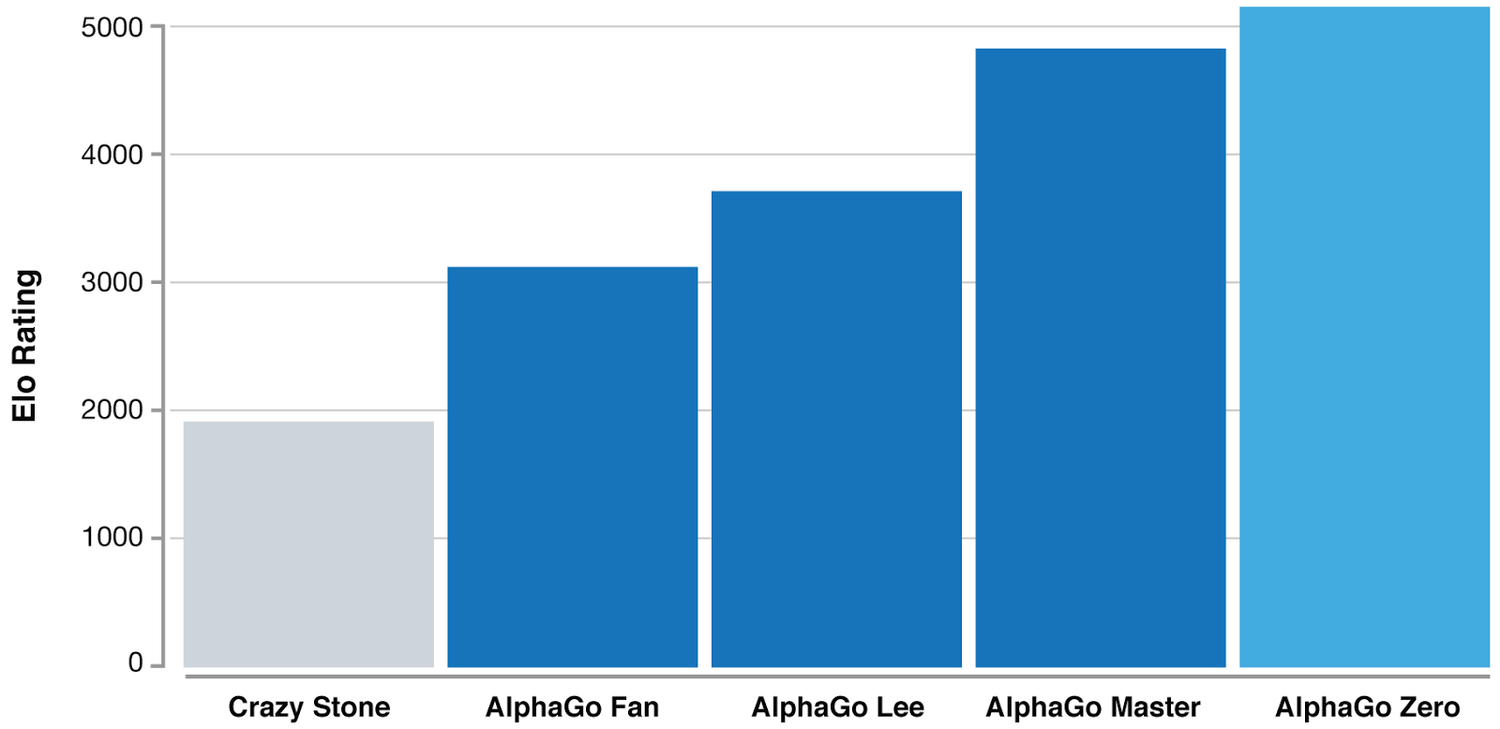
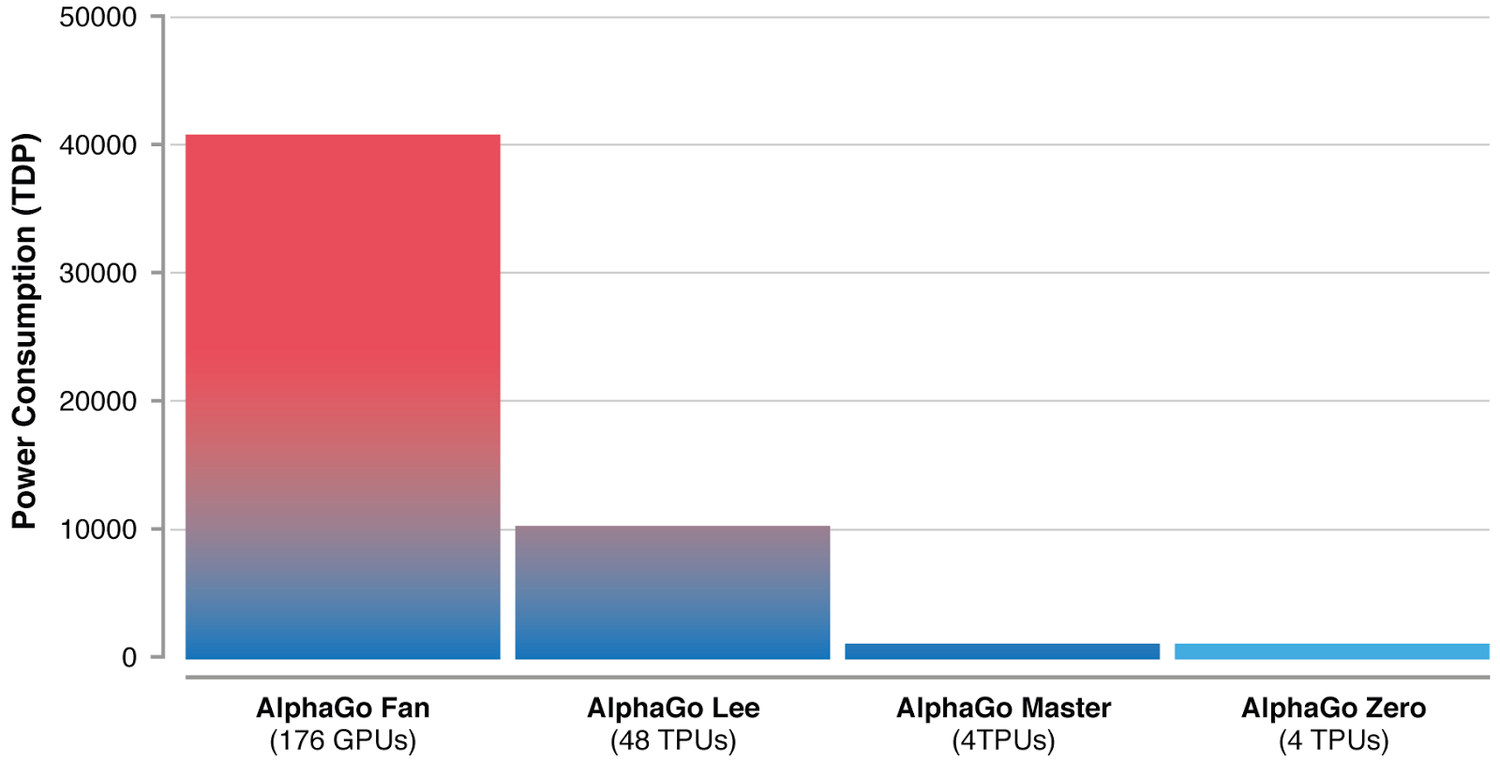
AlphaZero est un algorithme capable d'apprendre sans intervention humaine aussi bien le jeu de Go que les échecs, Atari, ...
So what ?
Est-ce qu'il y aura une version OpenAI Zero ?
L'impact sur le monde de l'eSport ($900 millions de revenue en 2018) ?
NLP's ImageNet Moment ?

https://www.nytimes.com/2018/11/18/technology/artificial-intelligence-language.html
NLP
Le NLP (Natural Language Processing) concerne l'interaction entre les langages humains et la machine.
Quelques exemples :
- Question Answering
- Summarization
- Sentiment analysis
- Text classification
- Traduction
- [...]
Le problème : $$$
Expertise forte, spécialisée et longue pour chaque problématique.
ImageNet Moment
Comment le domaine de la vision par ordinateur a résolu ce problème

Concours annuel de reconnaissance visuelle à grande échelle. Environ 15 millions d'image pour 20 000 classes à détecter
ImageNet Moment

Human
Deep Learning
Transfer Learning
Réutilisation des meilleurs modèles entrainés sur ImageNet
ImageNet
ResNet, Inception, ...
Entreprise
Transfer Learning
Les gains
1. Temps
2. Moins besoin d'expertise en Deep Learning ($$$)
3. 'Assurance' d'avoir une bonne performance

ImageNet pour le NLP
Pas un dataset unique mais une multitude
- Compréhension
- Stanford Question Answering Dataset (SQuAD) -- 100 000 exemples
- Traduction
- WMT 2014 -- 40 000 phrases en anglais / français
- Modélisation du langage : prédire le mot suivant
- WikiText-2 -- 1 Milliard de mots
- Glue Benchmark : https://gluebenchmark.com/tasks
- 9 tâches (sentiment, pairing de questions,...)
- [...]
Où en était le NLP
(en représentation des mots)

< 2012

2012 < d < 2018
tf-idf
fast-text > w2v / glove
Où en était le NLP
(en représentation des mots)
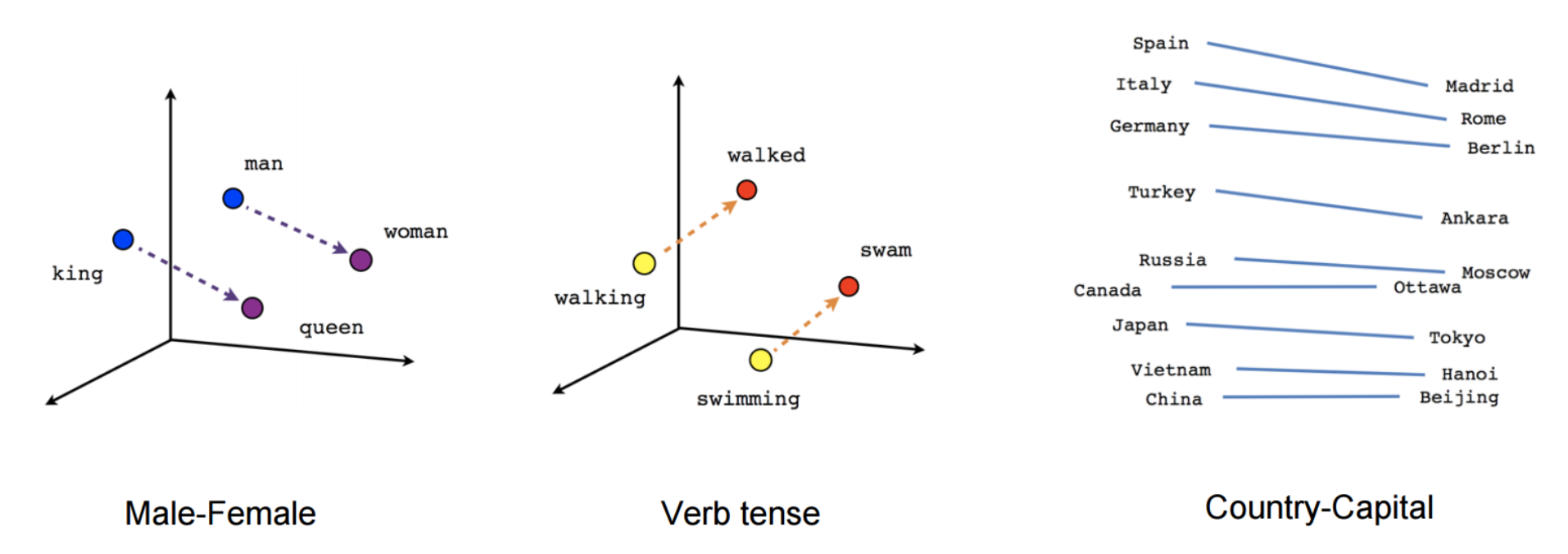
Problème : Le contexte
I like to eat my cereals with an apple.
Apple is a highly profitable company.
Le mot "Apple" est représenté par un seul vecteur dans l'espace.
Envie :
Avoir une représentation du mot "Apple" dans une région de l'espace avec de la nourriture pour la première phrase et une autre représentation dans une région avec des noms d'entreprise pour la deuxième phrase.
Modèles Universels
Millésime 2018
- Janvier 2018 : ULMFIT (FastAI)
- Février 2018 : Elmo (Institut Allen)
- Juin 2018 : Transformer (OpenAI)
- Novembre 2018 : Bert (Google)
Modèles Universels
Performance ?
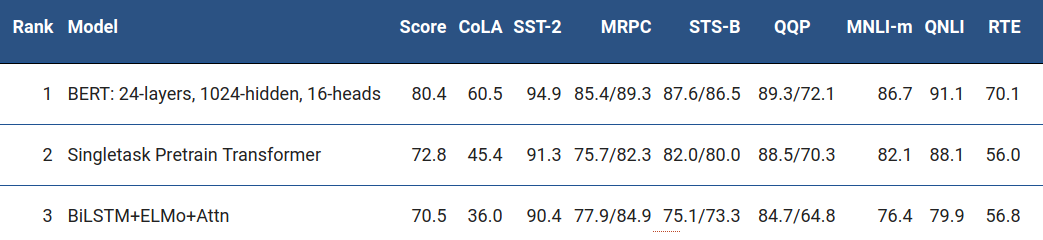
- Apportent tous entre 5 et 25% de gains sur l'état de l'art de différentes tâches et commencent à dépasser l'humain sur plusieurs.
- Leaderboard sur le benchmark Blue :
En conclusion
D'énormes avancées dans le domaine du NLP.
Il faut voir dans la pratique ce qui se passe maintenant.
Bert a une longueur d'avance par la qualité délivrée et l'engouement généré (1000+ étoiles sur Github en un mois).
Les data scientists commencent à l'évaluer sérieusement et à l'utiliser (moi le premier...)
Google AutoML

Rendre à César...
Article de Rachel Thomas :
https://www.fast.ai/2018/07/12/auto-ml-1/
Toute cette partie de la présentation est inspirée sur ses excellents articles sur l'AutoML. A lire et à relire.
La Data Science, c'est cher
1. Le concept de "Projet Data" est encore immature
Machine Learning Yearnings, Andrew Ng
2. L'organisation d'une équipe Data est immature
How should you structure your Data Science and Engineering teams?
3. Compétence est trop rare
Mais ça rapporte...
AutoML
Méthodes automatiques pour sélectionner des modèles et/ou optimiser des hyper-paramètres.
Beaucoup de systèmes open-source existent : AutoWeka, Auto-sklearn
Permet de poser une bonne baseline pour connaître le niveau de performance sur un problème donné
Plateformes d'AutoML
Pourquoi regarder du code quand on peut avoir une interface web ?
Tout le monde court dans cette direction ! (avec des plateformes +/- spécialisées)
Quelques leaders :



Plateformes d'AutoML


Pro/Con
- Démocratise le Machine Learning (+++)
- Evite les erreurs
- Itérations et tests rapides
- Garantie d'une certaine performance
- Mise en production rapide
- Traitement efficace de la donnée textuelle et visuelle
- Deep Learning
- Black-Box
- Reproductibilité
- Compréhension théorique
Google AutoML
- Démocratise le Machine Learning (+++)
- Evite les erreurs
- Itérations et tests rapides
- Garantie d'une certaine performance
- Mise en production rapide
- Traitement efficace de la donnée textuelle et visuelle
- Deep Learning
- Black-Box
- Reproductibilité
- Compréhension théorique
Nouveaux produits

Cloud Natural Language

Cloud Natural Language

Cloud Natural Language

Cloud Natural Language

Nouveaux produits
Comment ?
Selon la page d'AutoML, grâce à une combinaison de Transfert Learning et de Neural Architecture Search
Neural Architecture Search
Sous domaine de l'AutoML
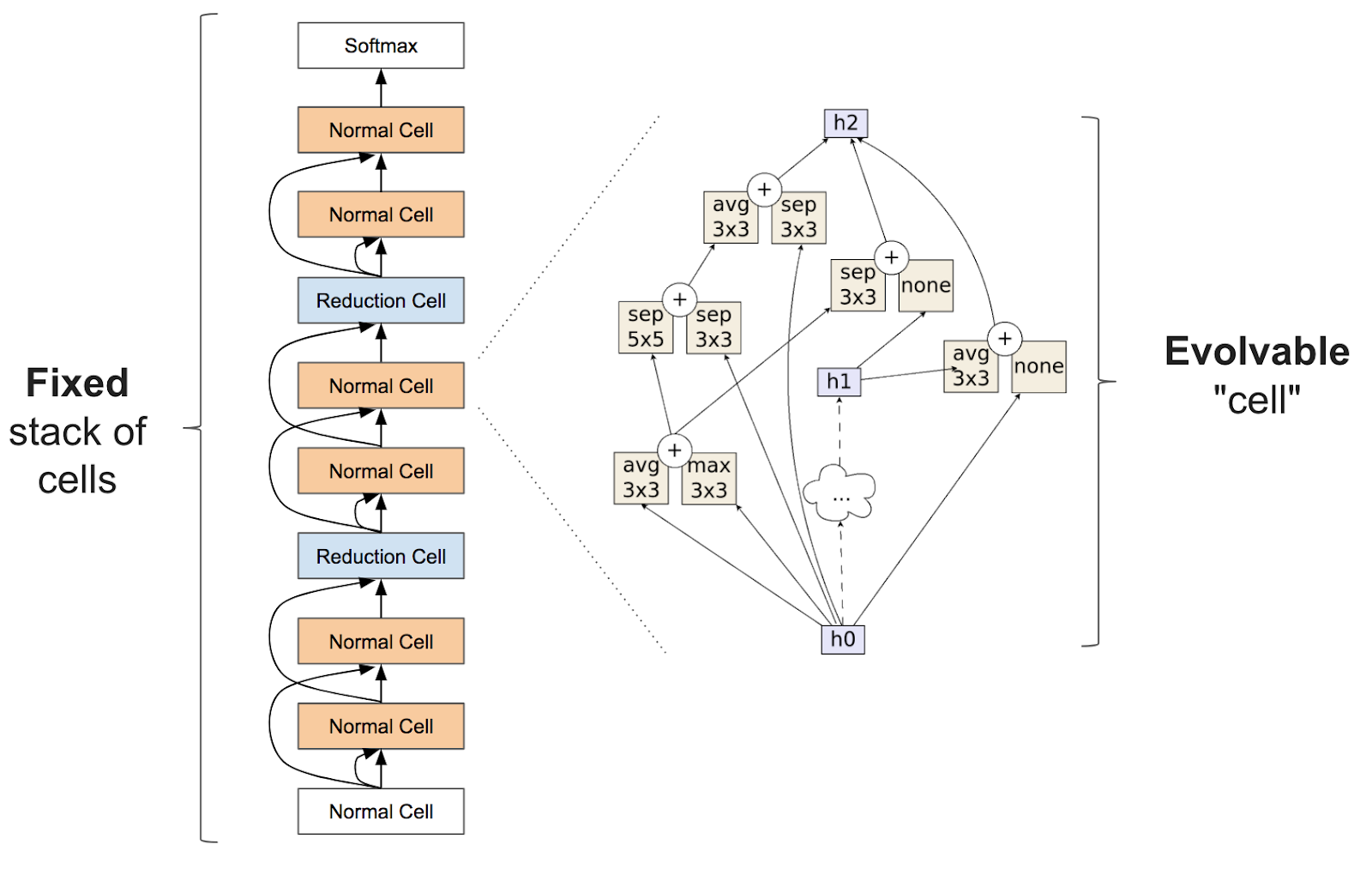
Humain vs NAS
Penn TreeBank -- Predict next word
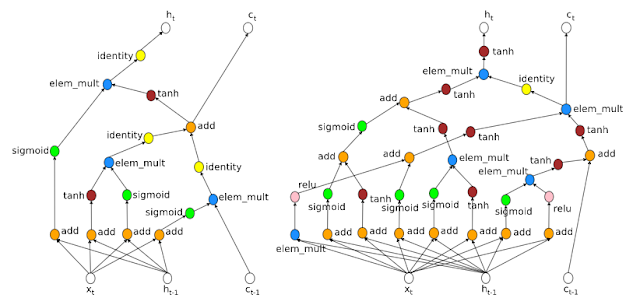
https://ai.googleblog.com/2017/05/using-machine-learning-to-explore.html
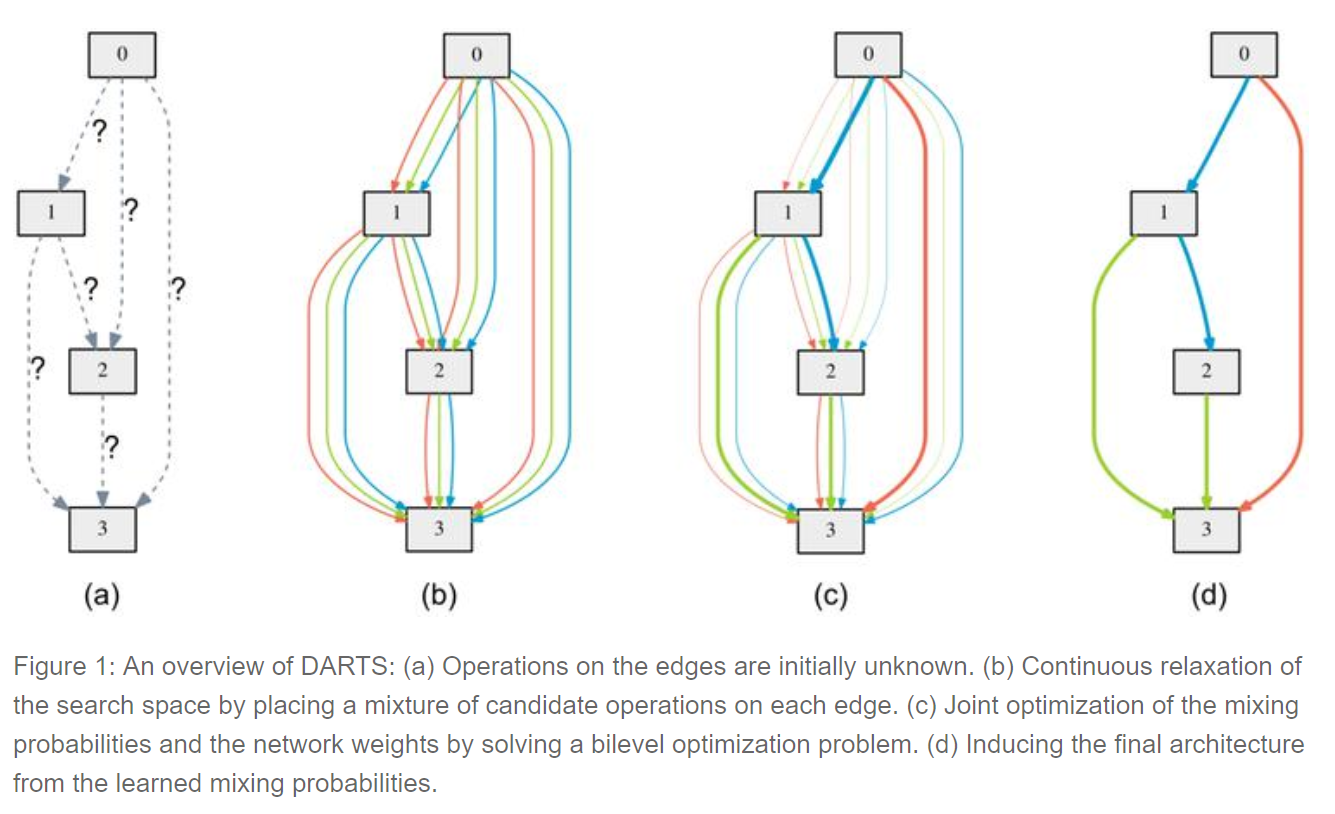
DARTS
Differentiable Architecture Search, Carnegie Mellon University and DeepMind
NAS Classique :
Utilisation d'algorithmes d'apprentissage par renforcement ou évolutionnaires dans un espace discret et non dérivable
=> Très très long
Nouvelle approche par DARTS :
Relaxation continue de l'architecture. Ce qui permet de chercher une solution optimale avec de la descente de gradient
DARTS
Open-Source
Si tu as du temps mais pas d'argent
Plusieurs solutions existent, le plus mature est AutoKeras
=> Implémentations de plusieurs algorithmes NAS
Le futur ?
Beaucoup d'entreprises veulent s'assurer que si vous avez de l'argent mais pas de compétences, vous puissiez quand même résoudre vos problèmes.
Et c'est bien.
Mais attention à la dépendance.
Google AutoML, comme quasiment toutes les solutions sur le marché, ne permettent ni d'exporter les modèles appris ni une bonne reproductibilité des résultats hors de leur écosystème.
Le futur ?
Jeff Dean, Google's head of AI, suggère que 100 fois plus de puissance de calcul pourrait remplacer l'expertise en machine learning (23:50 dans cette keynote).
Ne pas oublier que Google veut nous faire penser que pour mieux utiliser du Deep Learning, il faut plus de puissance de calcul (où ils sont les meilleurs dans ce domaine). Si c'est vrai, on va tous devoir acheter du Google Cloud.
[Bonus]
Some Cool Stuff
Style Transfer
https://reiinakano.github.io/arbitrary-image-stylization-tfjs/

#lookcoolonlinkedin
Real Time Multi Hand Pose Estimation
http://pozus.io/ -- Marche sur mobile !
- Réalité augmentée
- Jeux vidéos
- Sport & Fitness
- Driver Attention
- Baby Monitoring (camera surveillance)
- [...]
Génération de ramen

Conclusion
Ne nous endormons pas, le monde de la Data Science avance très vite.