Name: Xiao Yao (PhD 2Y)
Eduction: 2013-2017 Tianjin U
2019-2022 Shanghai JiaoTong U
2023-Now SUTD
Supervisor: Roy Lee, Li Xiaoli
Current interest: Reasoning、Alignment
Date: 0110
Scaling Samples of Preference Data Construction for DPO
Xiao Yao
Will be submit to ACL 2025
Background
- Human annotation and LLM annotation are expensive
- Ultrafeeback, hh-rlhf
- More and more reward models are available on HF
- Armo RM, Skywork RM
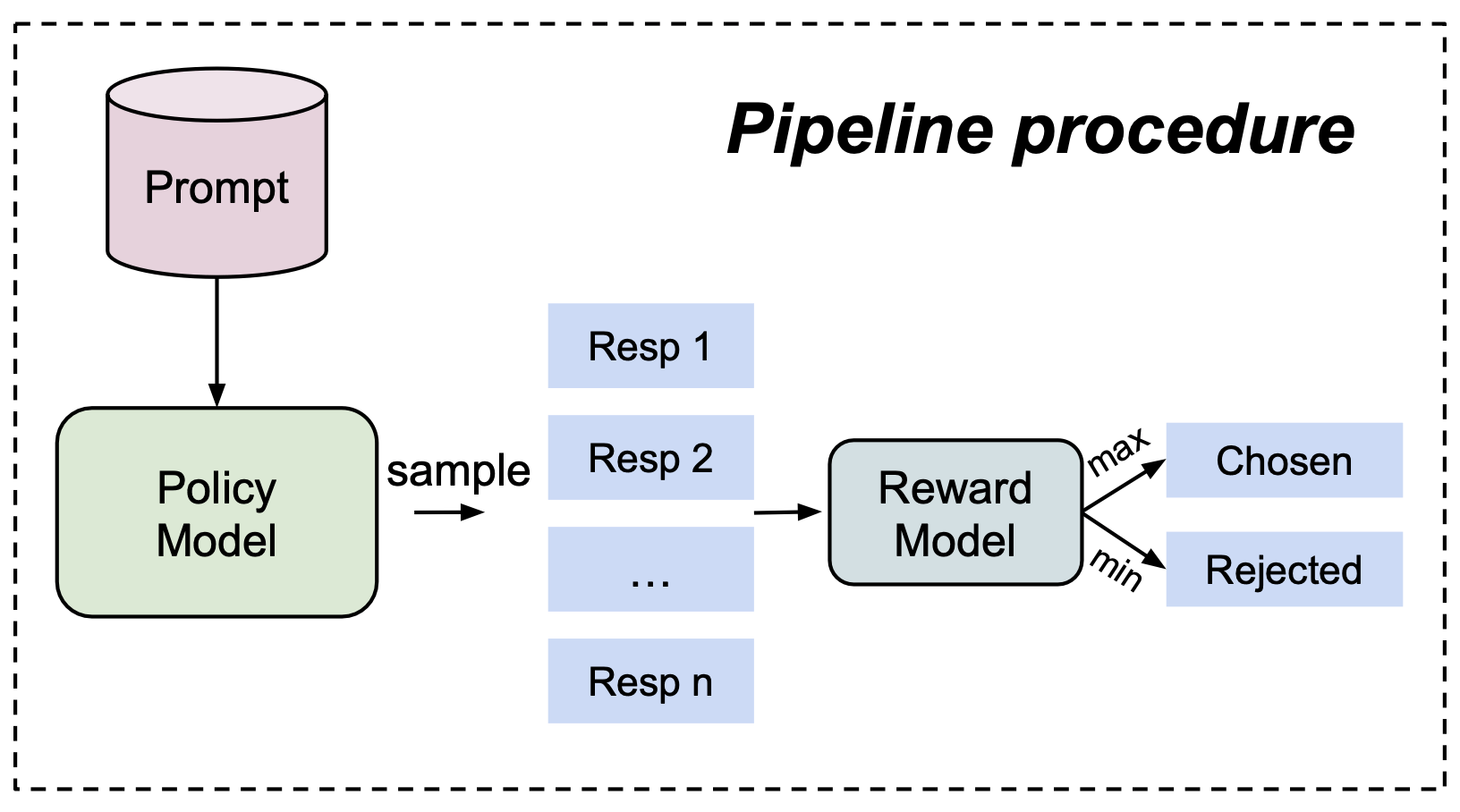
A conventional preference data construction
A Failure Case of Conventional Strategy
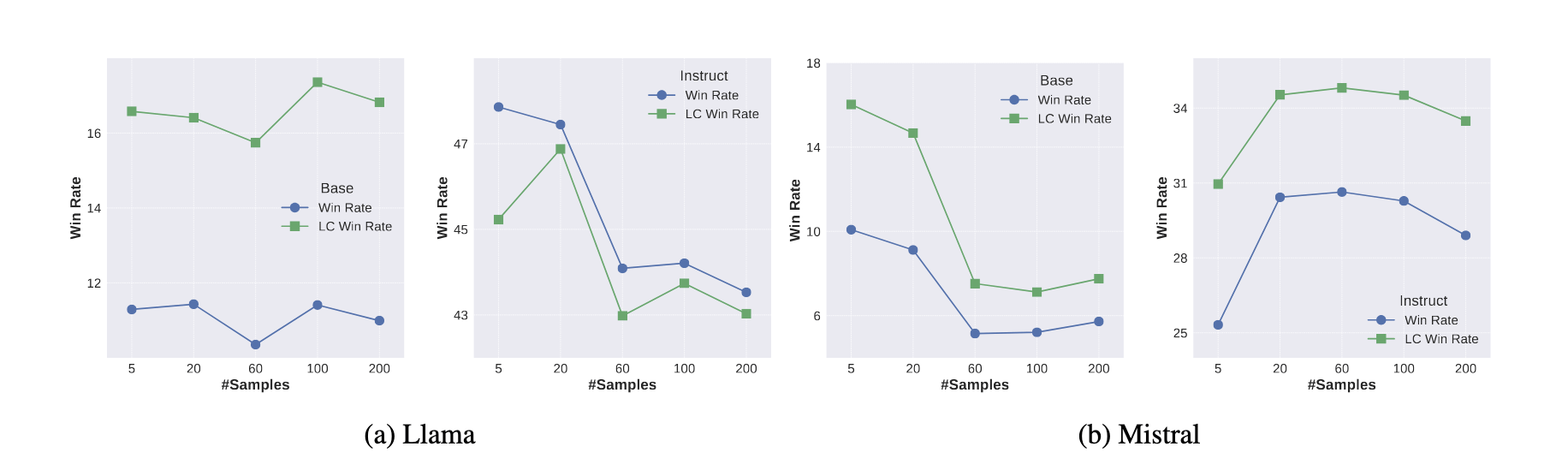
Model: Mistral-7B-v1/instruct,Llama3-8B/instruct
RM: Armo
Prompt: Ultrafeedback
Evaluation: Alpaca Eval2
Question
How should we construct
preference data
for
DPO
given sufficient sample budgets?
What Does The Reward Look Like
Implementation:
- Model: Llama3-8B-instruct
- Prompt: 1000 prompts from Ultrafeedback
- Samples: 400 samples per prompt
- RM: Armo/Skywork RM
What Does The Reward Look Like
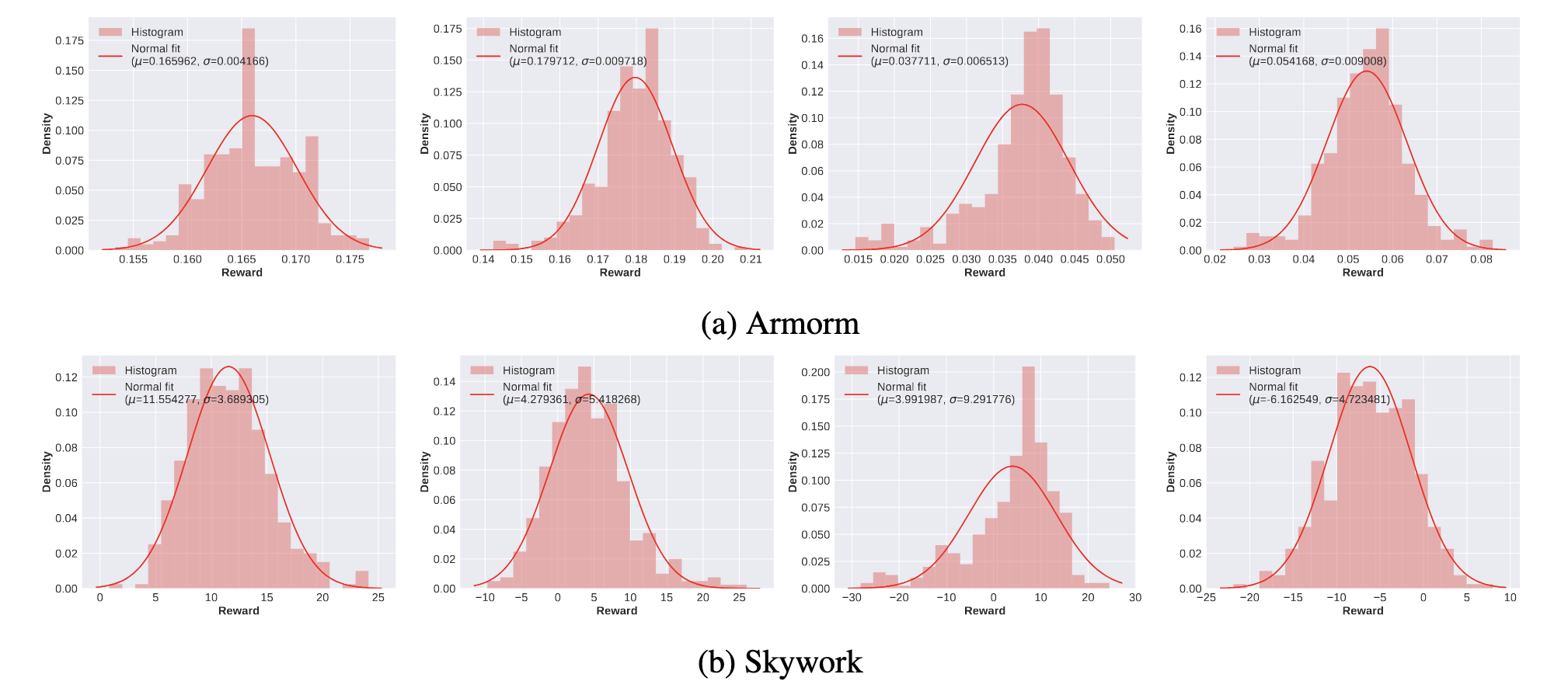
- The reward scores per prompt exhibits a Gaussian distribution
- Response rewards of approximately 20% prompts can perfectly pass the Kolmogorov-Smirnov test
Reward Points
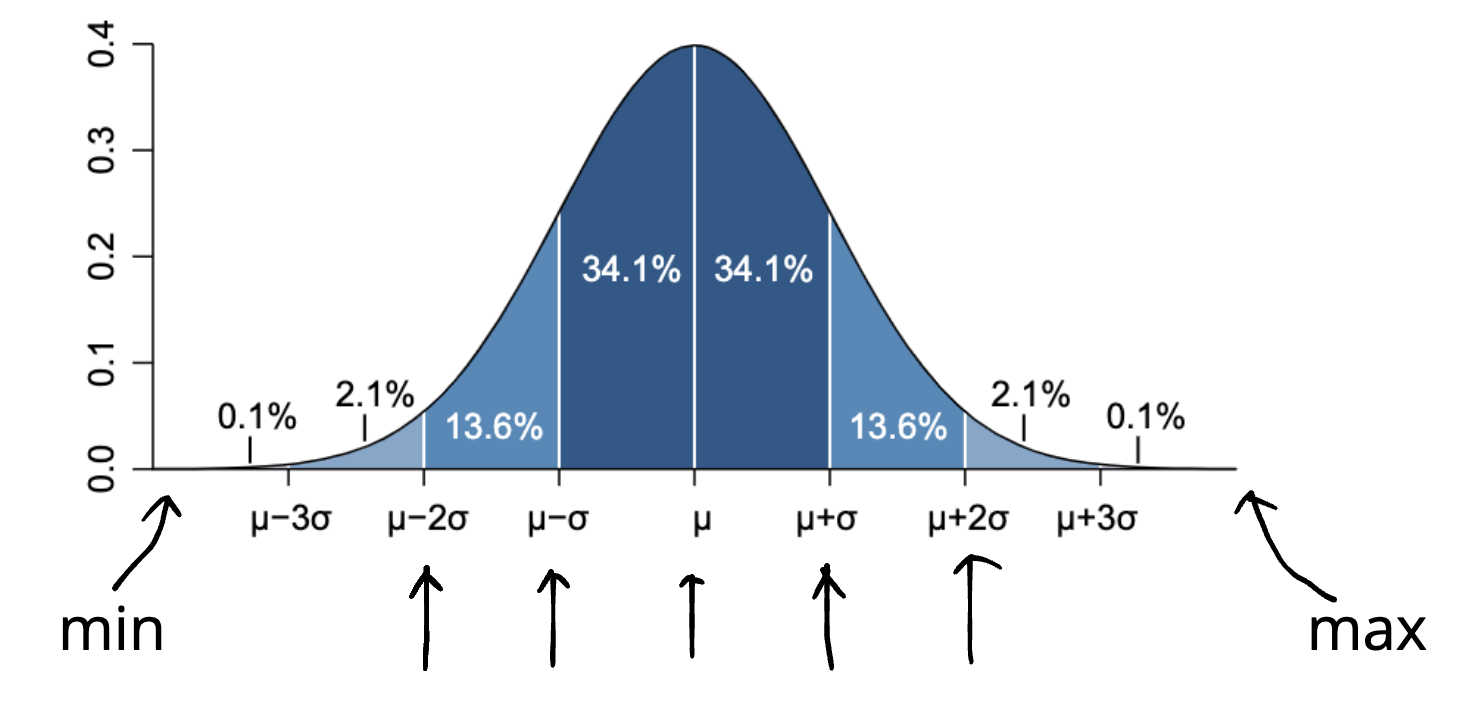
\left\{min, \mu \pm 2\sigma, \mu\pm\sigma, \mu, max\right\}
Position
C_7^2\quad(21)
Pairs
- In practice, we select the sample point which has the closest reward score to the value in the set.
- We construct 21 preference pairs per prompt following the principle that the reward of the chosen should be higher than that of rejected.
Alpaca Eval2 Results
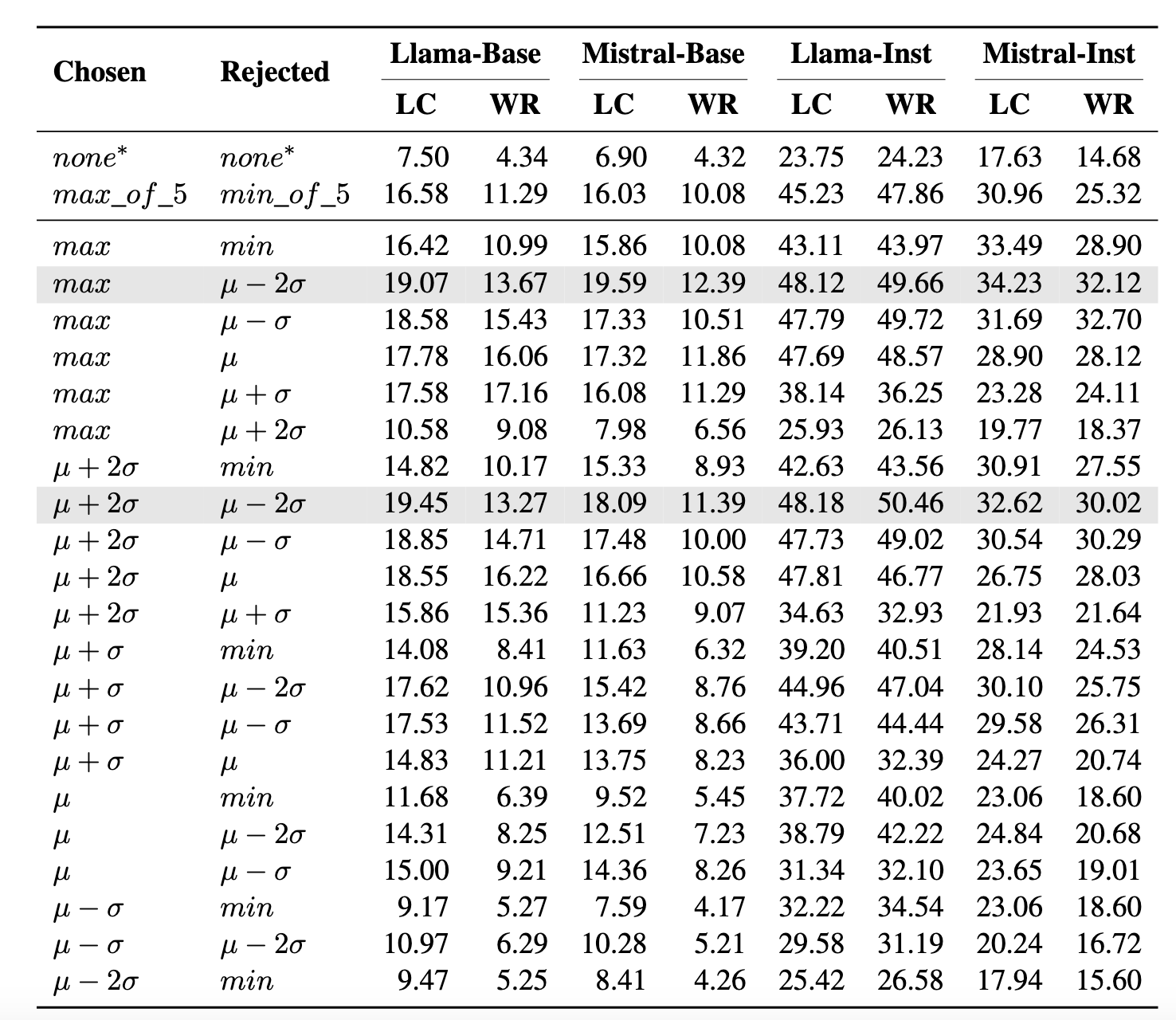
Main Results
- To achieve superior performance, the chosen response should be selected from , while the rejected response should be selected from .
- Preference pairs of small margins usually perform poorly. If the reward of the chosen response is slightly higher than that of the rejected response, models trained with them cannot achieve satisfactory performance.
- When the rejected responses are appropriately selected, the performance of trained models can improve as the reward of the chosen responses increases.
\left\{max, \mu+2\sigma\right\}
\left\{\mu-2\sigma\right\}
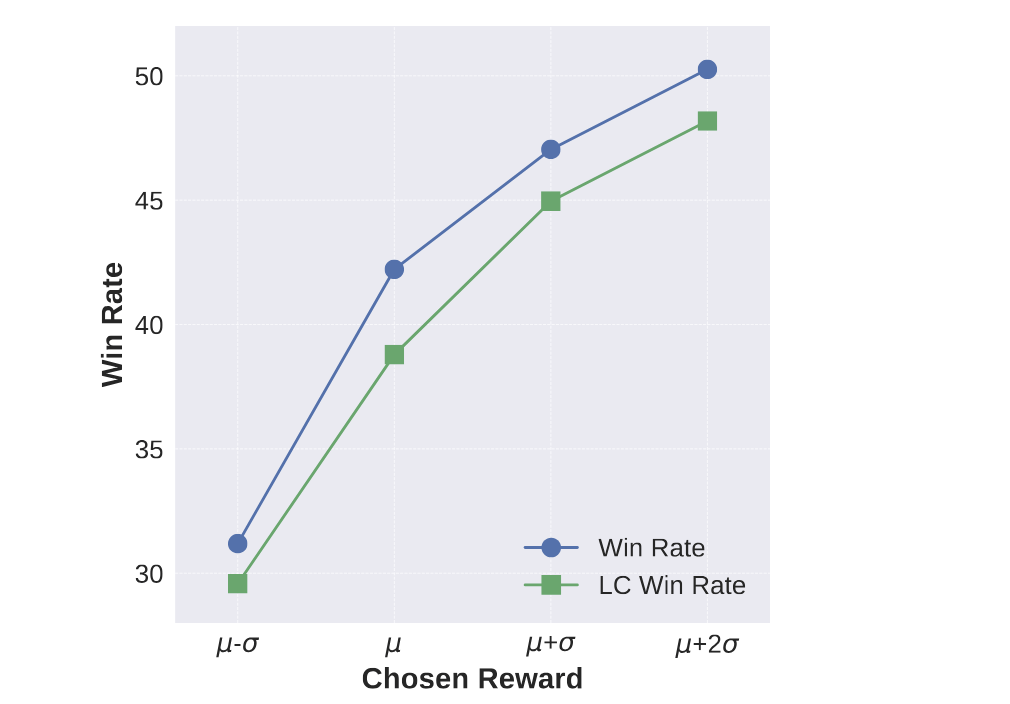
- None of preference pairs will degrade the performance of SFT checkpoint, which indicates the robustness of the DPO training.
Training Dynamics for Interpretation
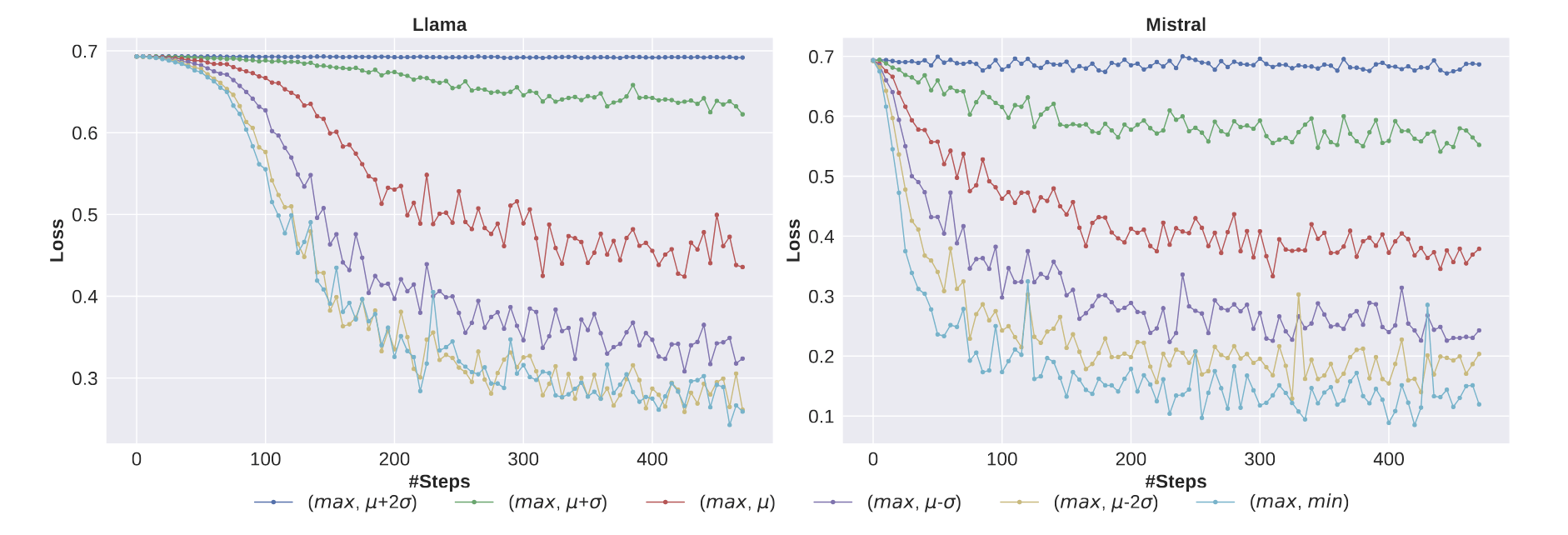
- It can be seen that increasing the reward margin between the chosen and rejected responses may facilitate model training. Training loss can reach a lower bound when the reward margin increases.
- There is a strong correlation between the converged state of the loss and the performance of models. Specifically, models achieving lower loss values tend to demonstrate superior performance, indicating that minimizing the loss effectively enhances model capabilities.
Proposed Preference Dataset Construction Strategy
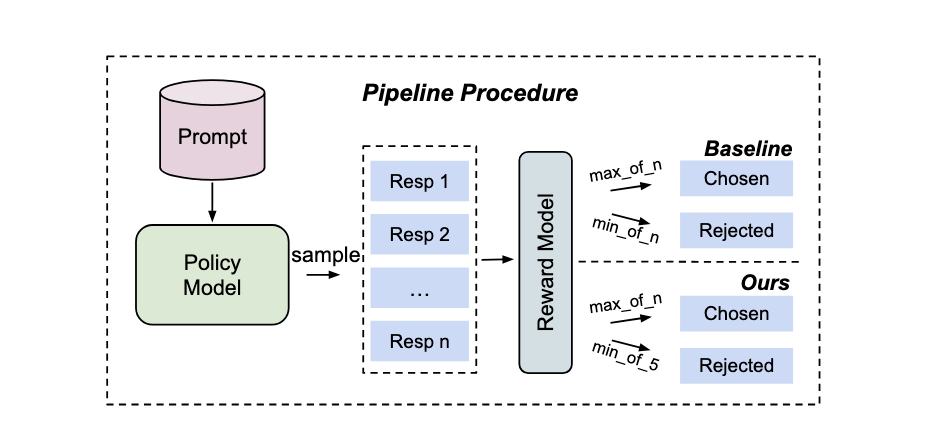
Results
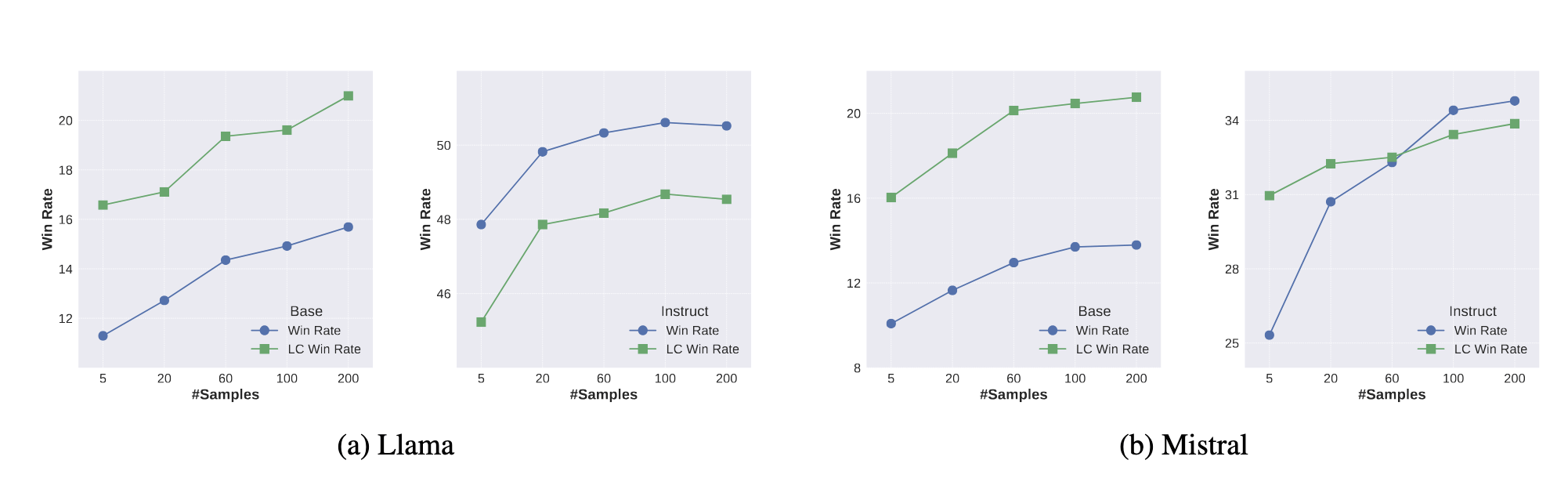
Reward Model: Armo
The performance of trained models is steadily improving if we increase the number of samples from 5 to 200, although with diminishing returns in some cases.
Results on Skywork
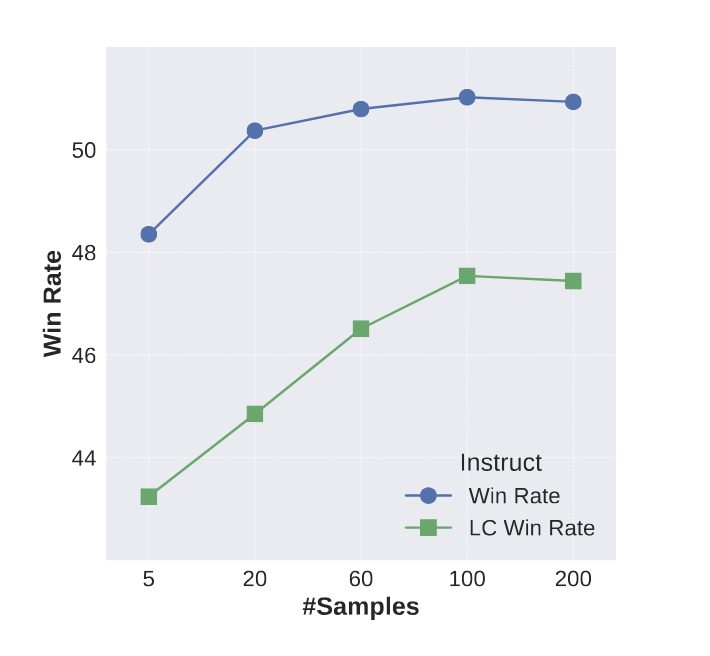
Model: Llama3-8B-instruct
Results on Academic Benchmarks
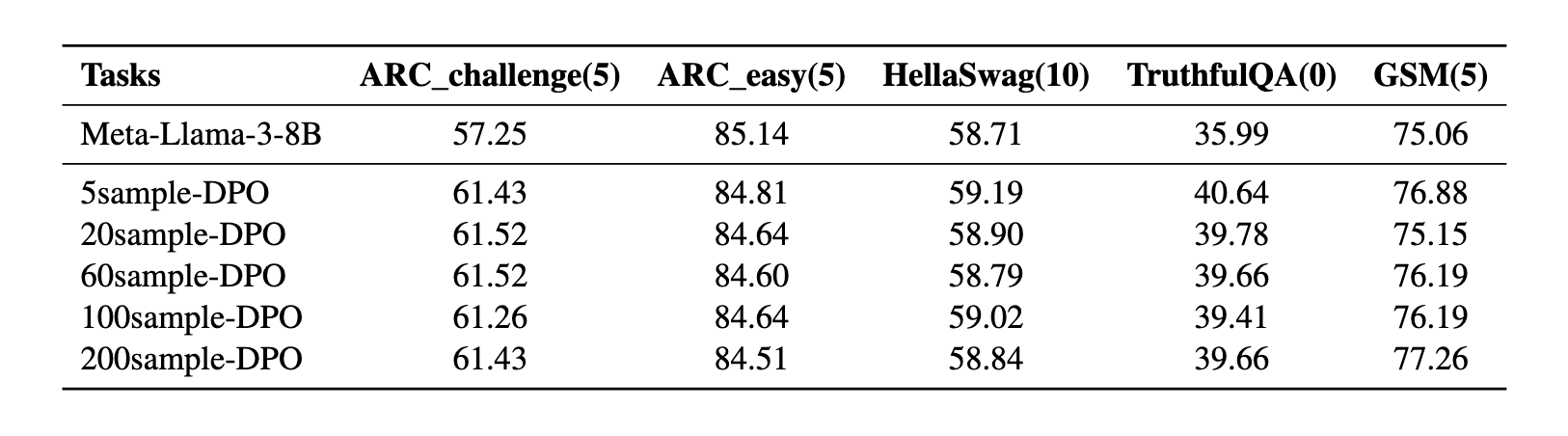
No performance drop