Mastering DevOps
Scaling from 50k to 500k WAU: How to move fast without breaking things
About Me
Yash Mehrotra
Backend Engineer turned DevOps




Why DevOps
Always had a keen interest in how infrastructure used to work
A knack for automating things
Found joy in improving development workflow
Before we start ...
What is DevOps
The umbrella of DevOps: Infra as code
You own all the infrastructure that the applications run on
Use IaC to manage all the infrastructure
- Terraform/Pulumi to create resources
- Ansible/Puppet to manage changes
- If you use kubernetes, you already know the benefits of a declarative infrastructure
The umbrella of DevOps: Observability
You cannot avoid issues forever, have systems in place which help you find the root cause instantly
Observability is key
- Logs, metrics and traces are the 3 pillars of observability
- Know which metrics to track, start with RED principle
- Rate - the number of requests, per second, you services are serving
- Errors - the number of failed requests per second
- Duration - distributions of the amount of time each request takes
- Use an APM to know your application performance
- Have a time-series database to visualize relevant metrics
- Use tracing to identify which part of your code is slow
- Have a global request ID that helps you keep a track of a request across its lifecycle in your infrastructure
- Logs are your friend, use them wisely, but don't abuse them
The umbrella of DevOps: Observability
The umbrella of DevOps: Alerting
- Are you tracking crashes and errors somewhere ?
- How do you know an error is due to a recent deploy ?
- Do your users tell you that there is a bug ?
Alerting is crucial. Define what you classify as an incident and create alerts for that
Use paging tools for P0 and P1 alerts
Use emails, slack/mattermost/email for all other alerts
A common pitfall of this is setting too many alerts
If you get too many pagers, you might get used to avoiding them. Classifying alerts is key
If there is no actionable for an alert, it should not be bothering you
The umbrella of DevOps: Alerting
The umbrella of DevOps:
Load Testing
Smart engineers write the best code and hope it doesn't fail
Smarter engineers eliminate the possibility of failing
Great tech companies handling immense load in not because they use <insert your favourite stack>
They do not crash because they find the bottlenecks of their system and fix those shortcomings
Load test early, Load test often
Use benchmarking tools to simulate traffic and know how your system performs under load
As a rule of thumb, you should be able to handle 3x of your current traffic at any given time
The umbrella of DevOps:
Load Testing
The umbrella of DevOps: Autoscaling
Kids scale on CPU and Memory
Legends scale on key performance indicators
We have been taught that scaling CPU & Memory is enough
But times have changed. Systems have become much more complex now
Scale on metrics that impact the overall experience
Scenario:
You send an OTP via text message during login.
Everyone uses a service provider, the OTP sending service should scale on the basis of latency, such that all users must receive their OTP in under 30 seconds
If you have a processing queue, scale the number of workers based on processing time
Work with your product and business teams to find these key metrics that scaling of your application will solve
The umbrella of DevOps: Autoscaling
The umbrella of DevOps:
CI/CD
Everybody talks CI/CD ... but, is anyone even doing it ?
CI: Push small and regular changes to your master branch
CD: Deploy those small changes regularly
The umbrella of DevOps: Continuous Integration
If you don't write your tests, you can't have any pudding.
How can you have any pudding if you don't write your tests?
Its the age of automation. No one has the the time to manually verify whether everything.
Unit, functional and integration testing, all have their own importance. Know which one suits you for your use case.
Pro-tip: Always write tests for failure cases
Have a single step deploy process
It can be an ansible playbook
A jenkins job
Or even a git push
Simplify your life so that even Friday evening deploys are blissful
PS: Do not deploy on Friday evenings, have some empathy
The umbrella of DevOps: Continuous Deployment
The umbrella of DevOps: Security
- Security checks should be part of your CI flow
- You can start with basic checks such as
- Static code analysis
- Container scanning
- The smartest move is to hire a dedicated security engineer if you do not have the time or resources to take it up yourself
Common security mistakes
- Unsanitized input
- Authenticating tokens but not checking for authorization
- Installing packages containing malware
The umbrella of DevOps: Security
The umbrella of DevOps: Access Control
- Do not give everyone master access
- Create groups and assign groups permission
- An off-boarding process is a must
- Always have an audit policy in place
- Even if you don't have audit logging, still tell everyone you have audit logging
The umbrella of DevOps: Postmortems
It is okay if you have an outage
But it is bad if you don't learn anything from it
Postmortems are a great way to understand the root-cause of the outage and share your learnings
Common reasons for outages
- Small outages due to code/logical errors
- Large outages due to datasource
- Elasticsearch slowing down due to shard replication
- RDS became bottleneck
- In microservices, outages can lead to cascading issues
- Service A hits Service B which is not responding, Service A threads are busy
- Service C hits service A which is not responding due to Service B's downtime even though Service C -> service A does not require Service A to hit Service B
- Worst outages are usually due to infrastructural components
- Hardest to debug
- You only monitor them when you know in what ways they could break
- Things which can go wrong:
- DNS
- Load balancer configuration
- VPC network choking
Common reasons for outages
Case Study: DevOps practices in B2C vs B2B
B2B and B2C companies operate in very different ways
- Prioritization
- In B2B, SLOs matter much more since they are contractual obligations
- In B2C, going down trends on twitter
- As a DevOps engineer, business goals should be a part of your decisions making process
DevOps workflow in reality: Deployments @ Grofers
- Around 12-14 services
- Started with ansible playbooks at first
- Moved to kubernetes
- Wrote a python utility to manage & apply manifests
- Jenkins was used to execute these tasks
- 110-120 active services
- Platform to manage manifests which were stored in a database
- After making changes on the platform, a jenkins job was executed
- Not scalable since custom solutions require frequent maintenance
- Moved to helm charts later with Gitlab runners
DevOps workflow in reality: Deployments @ MindTickle
- Grafana & NewRelic dashboards
- Sentry for error reporting
- PagerDuty and slack for alerting
- Grafana Loki for logs
DevOps workflow in reality: Observability @ Grofers
- Grafana, Datadog & SumoLogic dashboards
- Sentry for error reporting
- Pagerduty and slack for alerting
- Sumologic for logs
DevOps workflow in reality: Observability @ MindTickle
Redis queue filled up, cascading failures led to outage
Few time-taking queries chocked the database, leading to cascading failures
DevOps workflow in reality: Downtimes @ Grofers
Frequent DNS problems in the kubernetes cluster
SumoLogic workloads crashed our DNS server
Added Linkerd workloads whose resource consumption throttled our applications
DevOps workflow in reality: Downtimes @ MindTickle
Infrastructure from scratch at Bukukas
The what, the why and how
Infrastructure as Code
- GCP is the primary cloud provider
- Terraform provisions
- Kubernetes cluster
- CloudSQL (Managed PostgreSQL)
- Elasticsearch (via third-party provider)
- CDN (Load balancer + Bucket)
- All networking resources
- VPC
- NAT
- DNS
- VPN
- And much more ...
Infrastructure as Code
Why Terraform ?
Very easy to start with, and a simple philosophy
Writing `terraform apply` will give you your desired state
Terraform's state acts as the source of truth for our infrastructure
Kubernetes
All our applications run on Kubernetes
But why ? Isn't Kubernetes just used by hipsters ?
Kubernetes
It allows us seamless deployment and scaling.
Wrote a new service and want to deploy it ? Just 20 lines of yaml if you have a docker container ready
Need to create an exact replica of your production ? Takes 1 min
Facing a traffic surge and need to double your replicas ? Just a single command
Kubernetes
All external packages are managed via helm
Kustomize is used for generating manifests for our applications
Flux watches the kustomize repo and applies the changes (GitOps !)
Autoscaling based on key metrics using keda
Observability
If only you could perceive metrics as I do
Grafana + Prometheus = <3
DataDog is our APM of choice and logs browser
Observability
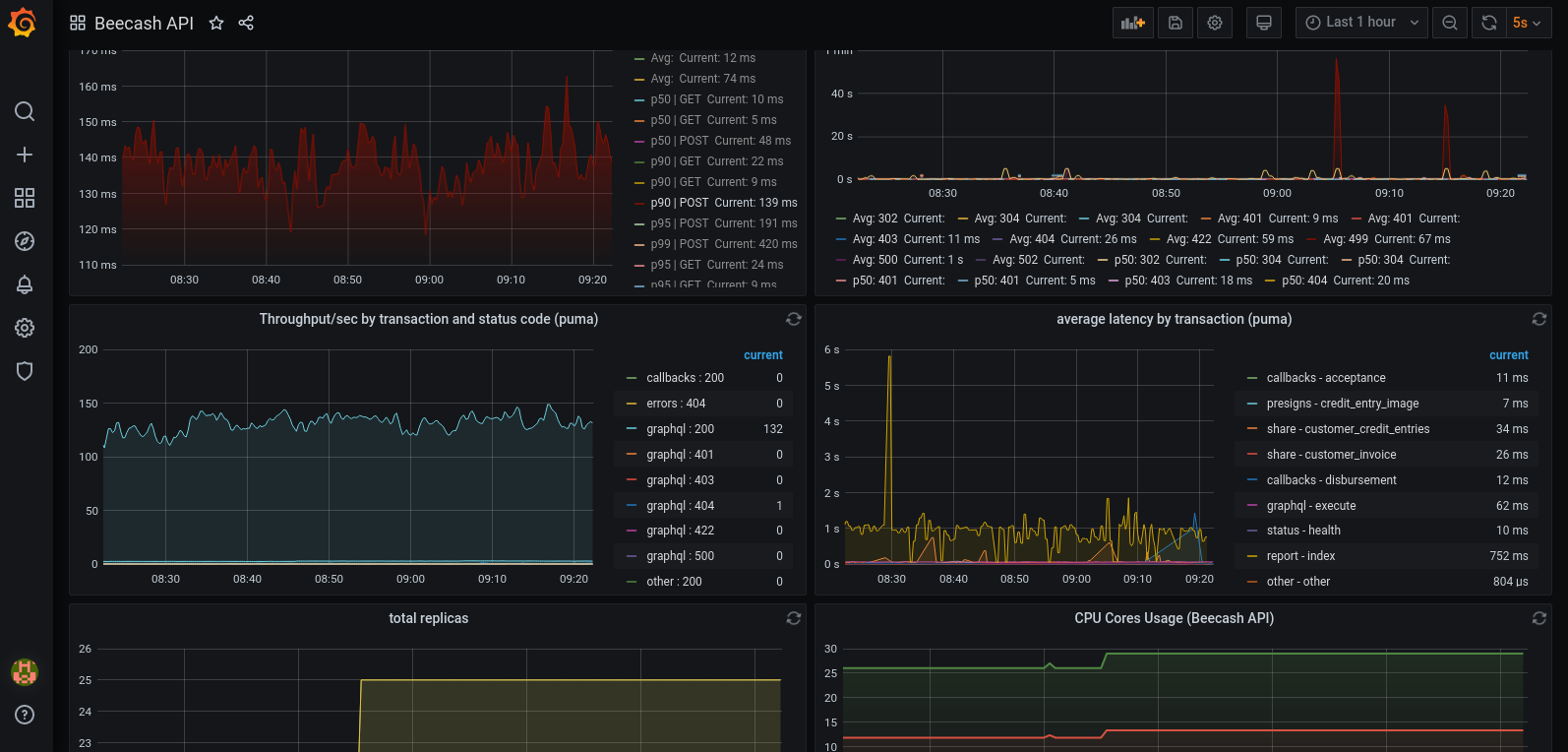
We have grafana dashboards for everything you can imagine:
- App metrics (Latency, Throughput, Error Rate, CPU, Memory, Replicas, queue backlog)
- PostgreSQL
- Elasticsearch
- Redis
- Cert Manager
- DNS & NAT
- Cluster health
- VPN
Observability
Observability
Prometheus is the one which scrapes all the metrics and stores them
We use prometheus exporters for our rails app, pgbouncer, elasticsearch and Kubernetes nodes
Prometheus has become the de-facto standard for observability now
PS: All our dashboards and scrapers are commited into git
Alerting
Raise the alarms, the bugs are coming
We hate it when our customers experience any problem
Our goal is to make sure that in case of any problem, we should be the first one to know
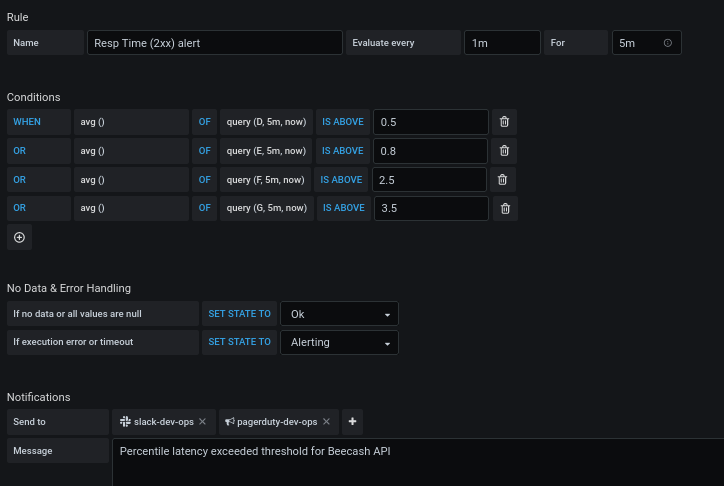
We have defined all our alert thresholds (error rate, high latency, restarts) in Grafana
Alerting
Alerting
- Sentry for in app errors
- Slack for non-essential errors and warnings
- Pager for P0 and P1 errors
- Rule of thumb: if its a pager and your immediate reaction is not to open your machine and try to fix the issue, its not a pager
- Thorough and routine assessment of all the errors, what caused them, and how to fix them
Load Testing
Can a man still be brave if he's afraid?
That is the only time a man can be brave
You should know the limits of your application
All flows of your application should be load tested
Load Testing
We use k6 for our load tests
It uses javascript so we can add our custom logic and has integration with Postman which is where we document all our APIs
Parting thoughts
Take decisions keeping the next 6 months in mind, and factor in how difficult is it to change
Tracking tech-debt is very important
Push back to business when you need to, but make sure your end-goals are aligned
Thank You

