Apache Spark
usage in the real world
Yegor Bondar
KEY NOTES
- Real world use cases
- All right.. I want to start working with Apache Spark!
- Conclusions
Use cases
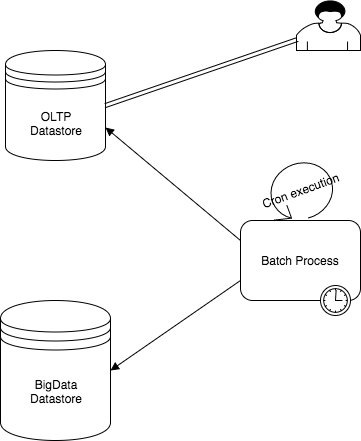
Batch processing
Use cases
Real Time Processing
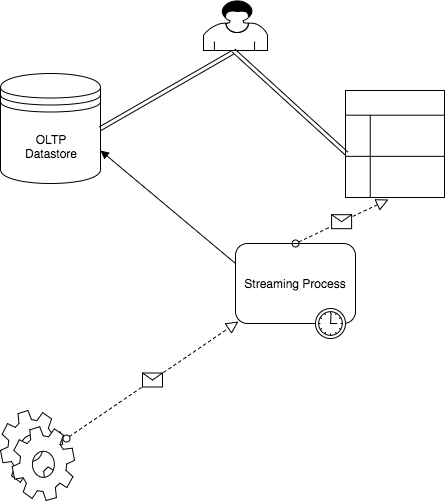
Real world use cases
- Distributed processing of the large file sets
- Process streaming data for different telecom network topologies
- Running calculations on different datasets based on external meta configuration.
Distributed processing
Input
- Set of binary data files stored in HDFS
- Each file represents the geodata + network cell values
- Files have custom format
- Data can be parallelized
Challenges
- Parse custom data format
- Calculate different aggregation values
- Store result as JSON back to HDFS
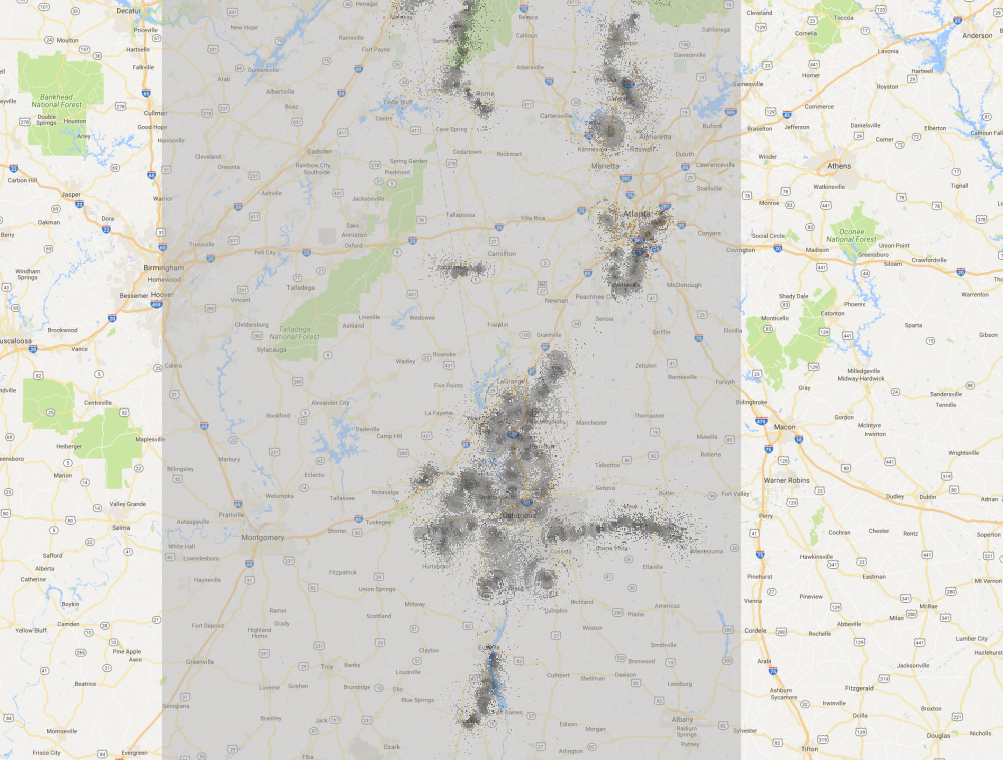
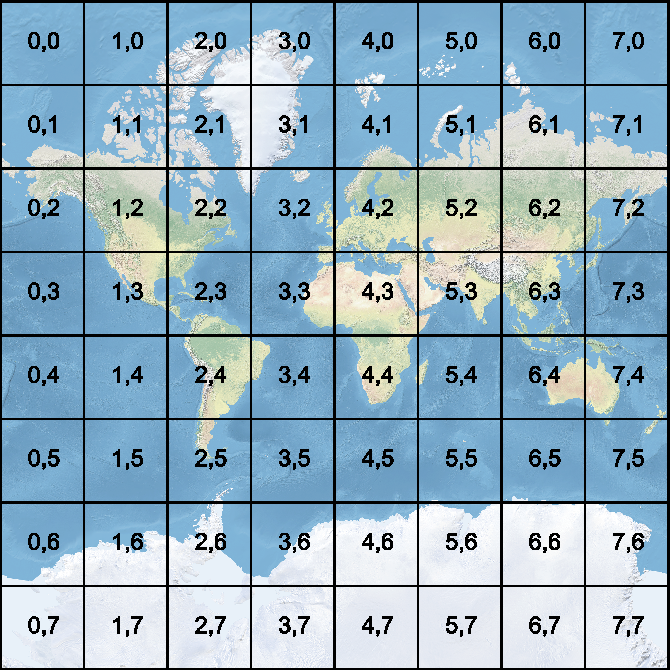
Desired output
JSON objects which represents the average signal value for certain Web Mercator Grid zoom.
{
"9#91#206" : {
"(1468,3300,13)" : -96.65605103479673,
"(1460,3302,13)" : -107.21621616908482,
"(1464,3307,13)" : -97.89720813468034
},
"9#90#206" : {
"(1447,3310,13)" : -113.03223673502605,
"(1441,3301,13)" : -108.92957834879557
},
"9#90#207" : {
"(1449,3314,13)" : -112.97138977050781,
"(1444,3314,13)" : -115.83310953776042,
"(1440,3313,13)" : -109.2352180480957
}
}
Data Parallelizm
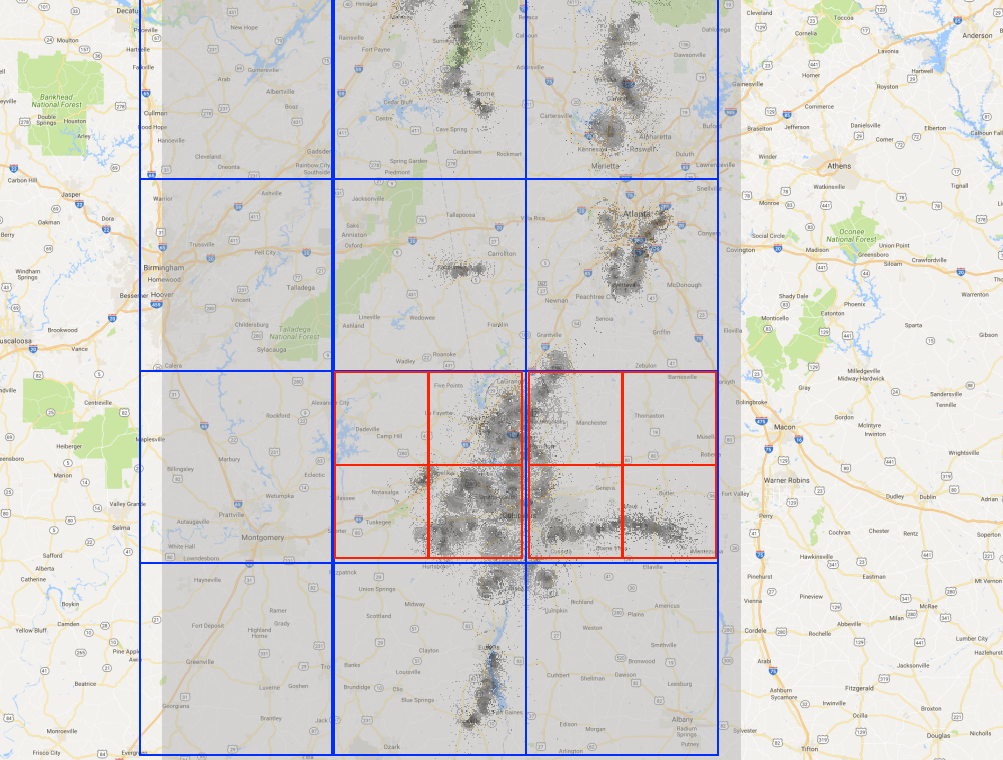
Implementation
def prepareDataset(inputHolder: InputHolder,
processingCandidates: List[Info])(implicit sc: SparkContext): RDD[(Tile, GenSeq[GrdPointState])] = {
sc.binaryFiles(inputHolder.getPath.getOrElse("hdfs://path/to/files"), partitions = 4).filter {
case (grdPath, _) => processingCandidates.exists(inf => grdPath.contains(inf.path))
}.flatMap {
case (path, bytes) =>
log(s"CoverageParser.prepareDataset - Loading dataset for $path")
val grdInMemory = GdalGrdParser.gdal.allocateFile(bytes.toArray())
val infOpt = GdalGrdParser.gdal.info(grdInMemory)
val tileToPoints = ... // collect points from files on each node
tileToPoints
}.reduceByKey(_ ++ _).mapValues(points => AveragedCollector.collect(Seq(points)))
}
def aggregateAndPersistTiles(inputHolder: InputHolder,
dataSet: RDD[(Tile, GenSeq[GrdPointState])])(implicit rootPath: String): Unit = {
dataSet.mapPartitions { it =>
it.toSeq.map {
case (_, avgPoints) => ZoomedCollector.collectGrd(level.aggZoom)(avgPoints)
}.iterator
}.map { tileStates =>
ZoomedCollector.collectTiles(level.groupZoom)(tileStates)
}.map {
tileStates =>
tileStates.seq.toMap.asJson.noSpaces
}.saveAsTextFile(s"$rootPath/tiles_result_${System.currentTimeMillis()}")
}Results
| Dataset | Single JVM implementation | Spark Implementation (Local cluster) |
|---|---|---|
| 14 M points | 7 minutes & 2G Heap | 1 minute |
| 25 M points | 12 minutes & 2G Heap | 1.5 minute |
Pros
- Built in parallelism
- Ways to improve performance
Cons
- You should install 3rd party tool on each node to parse binary files
Data Stream Processing
Input
- JSON messages from Apache Kafka topics
- Each message represents the data from network topology element (cell, controller)
- Aggregated JSON object should be persisted to either Kafka topic or HBase
Challenges
- Aggregate different messages to build the final object
- Process Kafka topics in efficient manner
- Ensure reliability
Network Topology
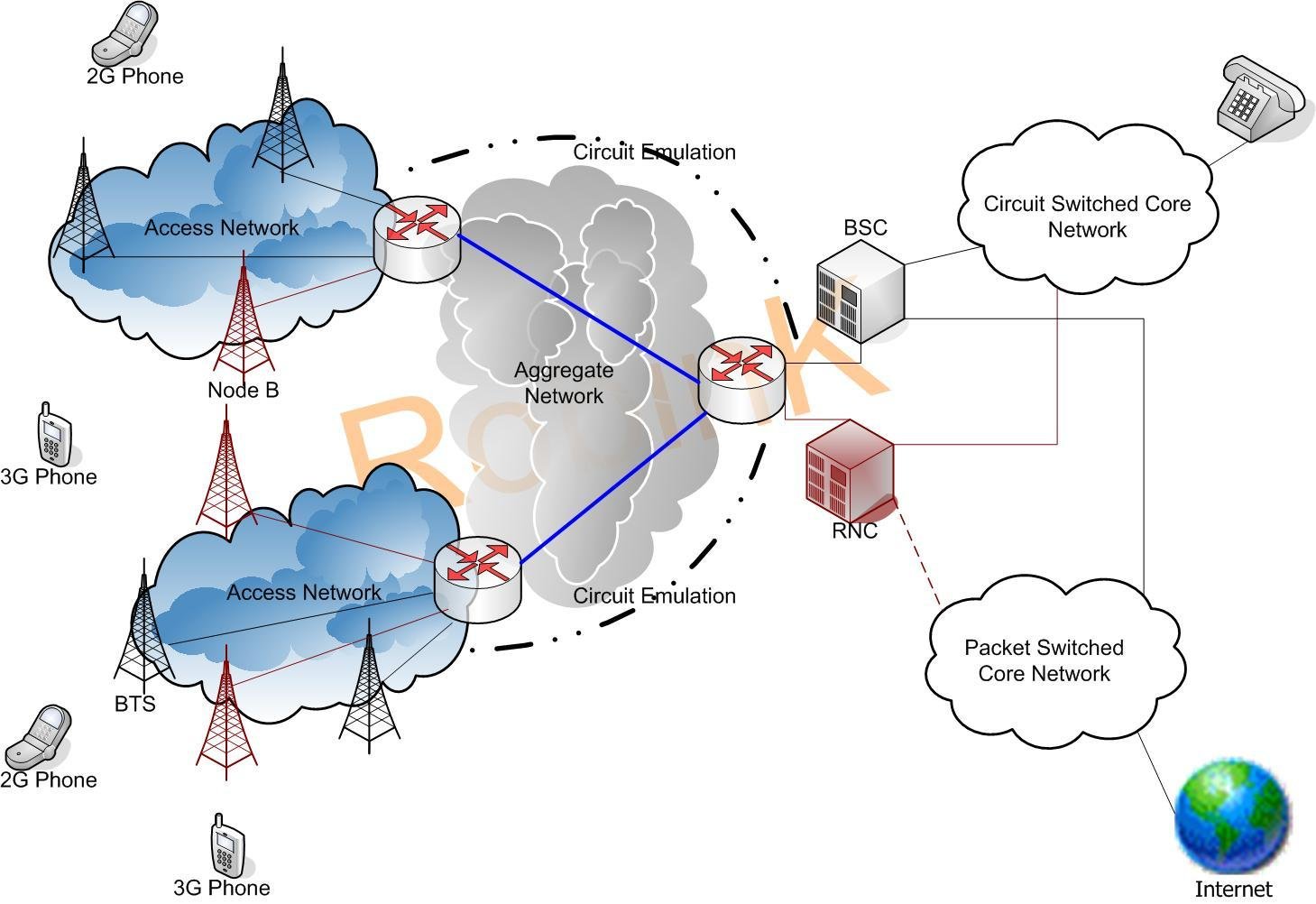
{
"technology" : "2g",
"cell_id" : "10051",
"site_id" : "UK1835",
"cell_name" : "KA1051A",
"latitude" : "49.14",
"longitude" : "35.87777777777778",
"antennaheight" : "49",
"azimuth" : "35",
"antennagain" : "17.5",
"lac" : "56134",
"Site name" : "UK1854"
}{
"SDCCH_NBR" : "23",
"bts_id" : "5",
"site_id" : "18043",
"cell_id" : "10051",
"bsc_id" : "1311",
"technology" : "2G",
"MCC" : "255",
"element-meta" : "BTSID",
"date" : "2016-10-31 03:03",
"bcc" : "2",
"SERVERID" : "259089846018",
"HO_MSMT_PROC_MD" : "0",
"element_type" : "BTS",
"vendor" : "ZTE",
"ncc" : "1",
"cell_name" : "KA1051A"
}Composed Key:
2G#KS#KHA#1311#18043#KA1051A
Composed Value:
Join of Input Jsons
BTS
BSC
Output
Spark Streaming Design
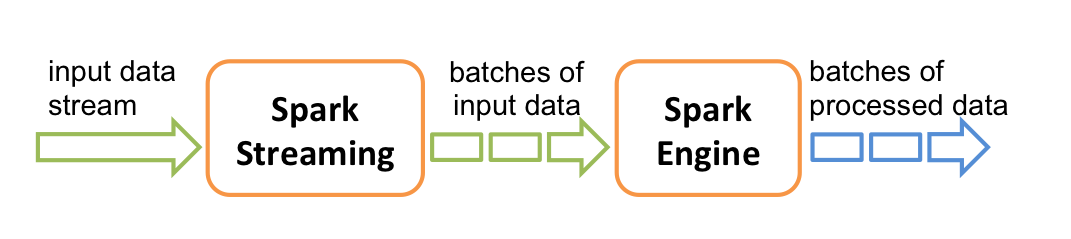

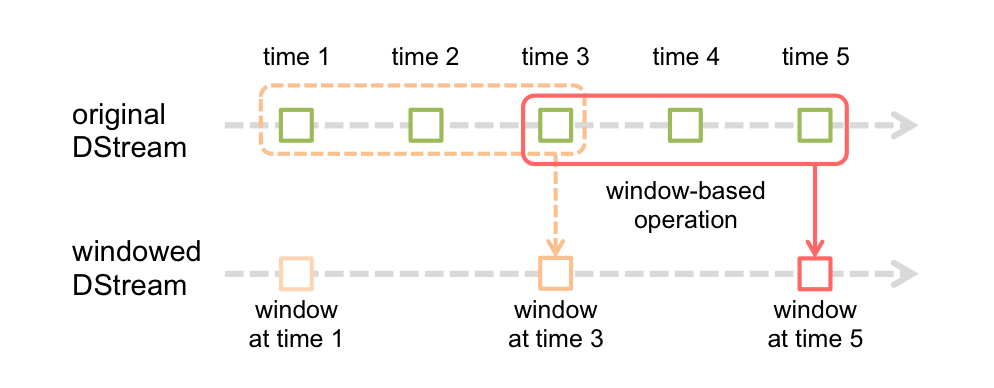
Title Text
type Record = Map[String, String]
def process(config: Map[String, String])(implicit ssc: StreamingContext): Unit = {
val primary = primaryStream(ssc)
val secondary = secondaryStream(ssc)
val cacheElement = getCacheInstance()
transformStream(primary, secondary, ssc).foreachRDD { rdd =>
logger.info(s"TopologyUpdateService.process - New RDD[${rdd.getNumPartitions}] Empty[${rdd.isEmpty}].")
val toRetry = for {
(_, (primarySeq, secondaryOpt)) <- rdd if secondaryOpt.isEmpty && primarySeq.forall(_.isSecondaryRequired)
rec <- primarySeq
} yield rec
val toPersist = for {
(_, (primarySeq, secondaryOpt)) <- rdd if secondaryOpt.nonEmpty || !primarySeq.forall(_.isSecondaryRequired)
rec <- primarySeq
} yield rec.enrich(secondaryOpt.asInstanceOf[Option[SecondaryRecord]])
persist(mapToOutput(toPersist))
toRetry.foreachPartition { it =>
it.foreach { el =>
cacheElement.cache("retry", el.data)
}
}
}
}Stream processing code Snippet
Conclusion
- Spark provides built-in Kafka support;
- Spark provides built-in storage for caching messages;
- It is easy to build re-try logic;
- Easy to join different streams.
Meta Calculations
Input
- Abstract dataset
- User should be able to configure the flow how to process the dataset
Challenges
- Apply custom function to transform the data
- Apply different transformations based on the configuration
- The engine should be flexible
Spark SQL
Spark SQL — Batch and Streaming Queries Over Structured Data on Massive Scale
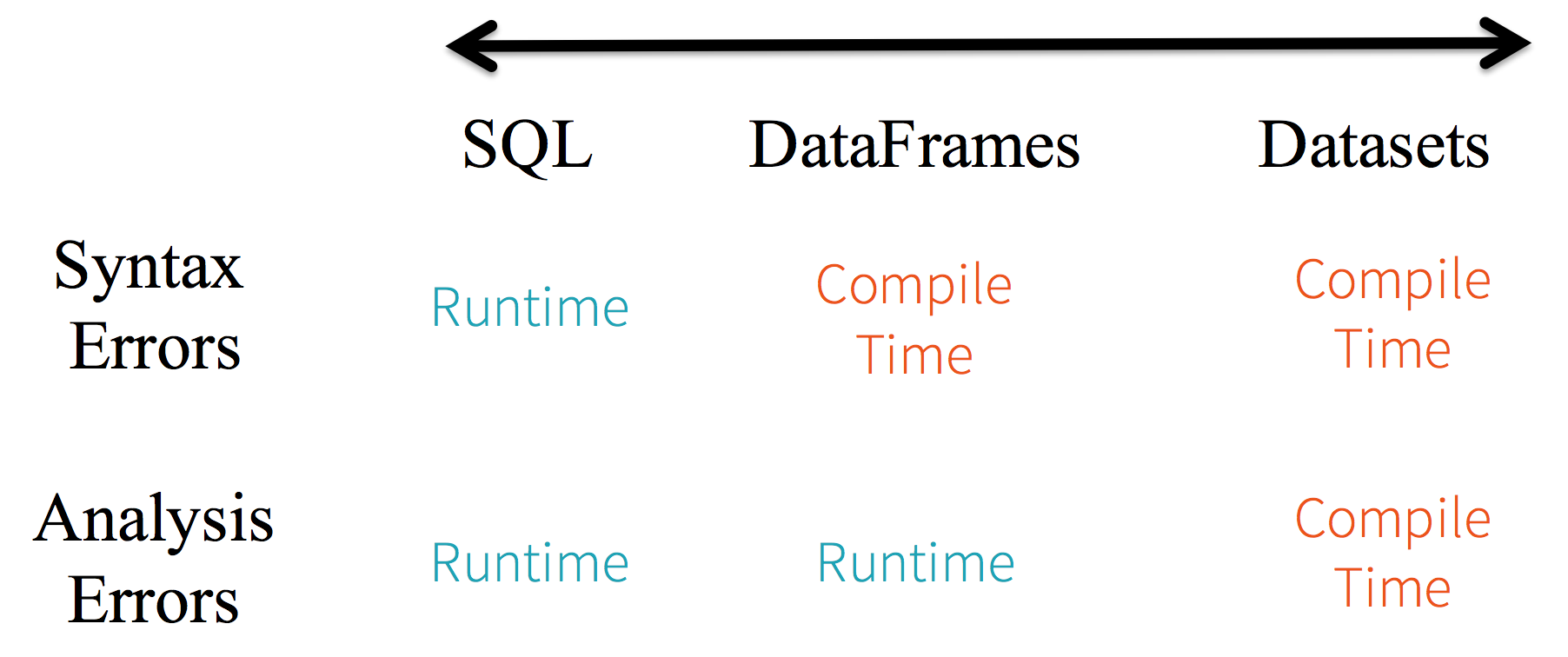
Spark SQL performance

Implementation of SQL Queries
@tailrec
def applyStages(stages: List[KpiTransformationStage],
inputTableAlias: String, stage: Int, df: DataFrame): DataFrame = {
stages match {
case section :: xs =>
val query = addFromClause(section.toSqlQuery, inputTableAlias)
val outputRes = sqlContext.sql(query)
outputRes.registerTempTable(s"Stage${stage}Output")
applyStages(xs, s"Stage${stage}Output", stage + 1, outputRes)
case Nil =>
df
}
}
// ...
registerUdfs(params)(sqlContext)
// ...
dataFrame.registerTempTable("Input"){
"transformations": [
{
"name": "TOPOLOGY_KPI_section",
"stages": [
{
"sql": [
"select rowkey, nr_cells, nr_urban_cells, nr_total_cells,",
"getA(nr_small_cells, nr_total_cells) as aHealth,",
"getB(nr_dense_urban_cells, nr_total_cells) as bHealth"
]
}
]
}
]
}Conlusions
- Immutable nature of DataFrames/DataSets gives a lot of functionality;
- You work in terms of 2D tables: Rows, Columns and Cells;
- DataFrames performance is better than RDD;
- UDF(User Defined Function) is powerful feature for custom transformations.
Starter Kit
Apache Spark can be used locally without any complex setup.
- Add Spark library as a dependency
- Run it in local[*] mode
val conf: SparkConf = new SparkConf()
.setMaster("local[*]")
.setAppName("TestApp")
val sc: SparkContext = new SparkContext(conf)
...
val lines = sc.textFile("src/main/resources/data/data.csv")Starter Kit
Apache Jupiter, Apache Zeppelin
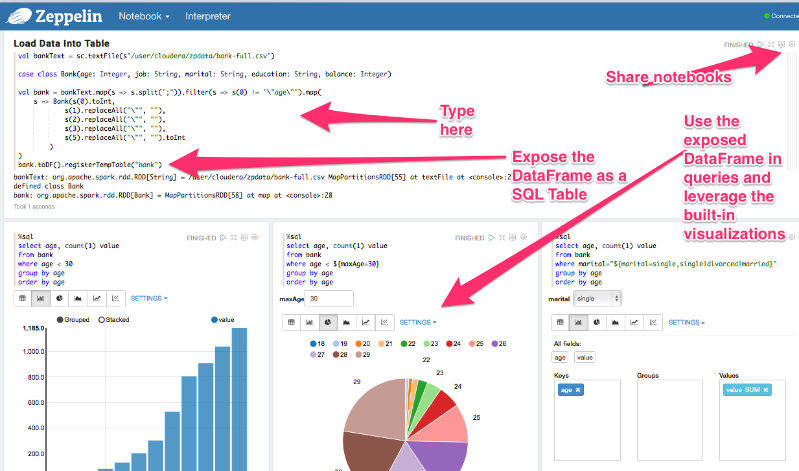
Conclusions
- Big Data not always Big amount of data;
- Apache Spark is the replacement for Apache Hadoop in MapR frameworks;
- Different use cases can be covered using built-in Apache Spark functionality.