PostgreSQL
Parte 2
Repaso a lo pasado

Revisemos la instalación
Clientes alternos para el manejo de PostgreSQL




Utilizar el SHELL
Meta-comandos
\?
Archivos de configuración
Documento
Ejercicio
Practico
Roles en una Base de datos
Que es un Rol
Un rol puede ser considerado como un usuario de base de datos o un grupo de usuarios de base de datos, dependiendo de cómo se configura la función. Los roles son creados por los usuarios (normalmente los administradores) y se utilizan para agrupar privilegios (un derecho para ejecutar un tipo particular de sentencia SQL o un derecho de acceso al objeto de otro usuario) u otros roles.
Roles de la base de datos
PostgreSQL gestiona los permisos de acceso a bases de datos utilizando el concepto de funciones. Se puede crear un rol utilizando el comando SQL: CREATE ROLE.
CREATE ROLE añade un nuevo rol a un clúster de bases de datos PostgreSQL. Debe tener privilegios CREATEROLE o ser un SUPERUSER de base de datos para utilizar este comando.
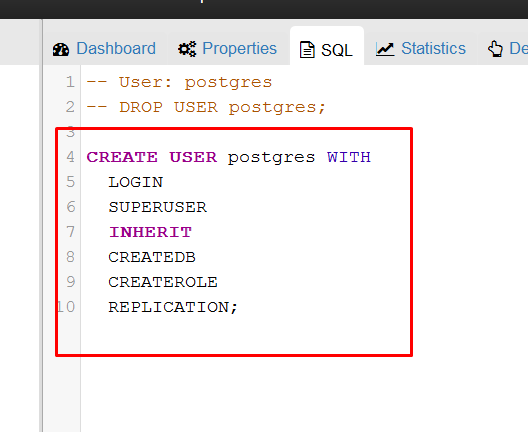
Por defecto nuestro usuario postgres tiene todos esos privilegios. Veamos.
Roles de la base de datos
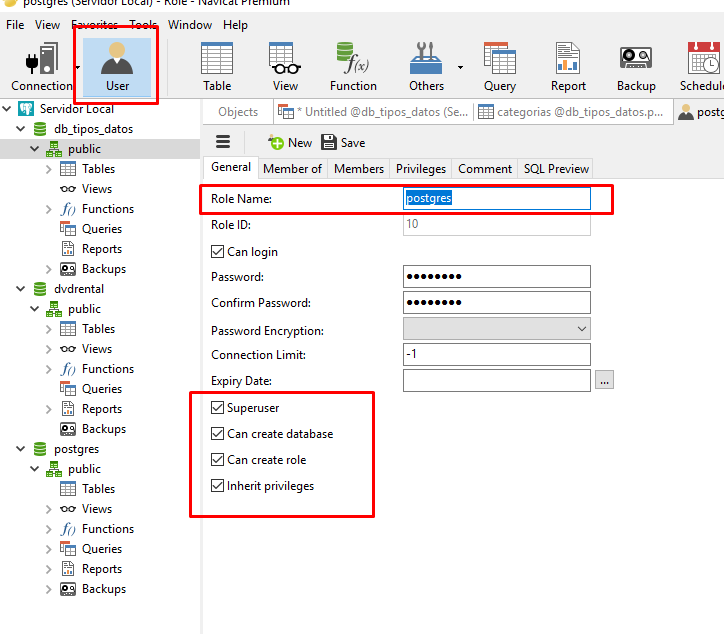
Roles de la base de datos
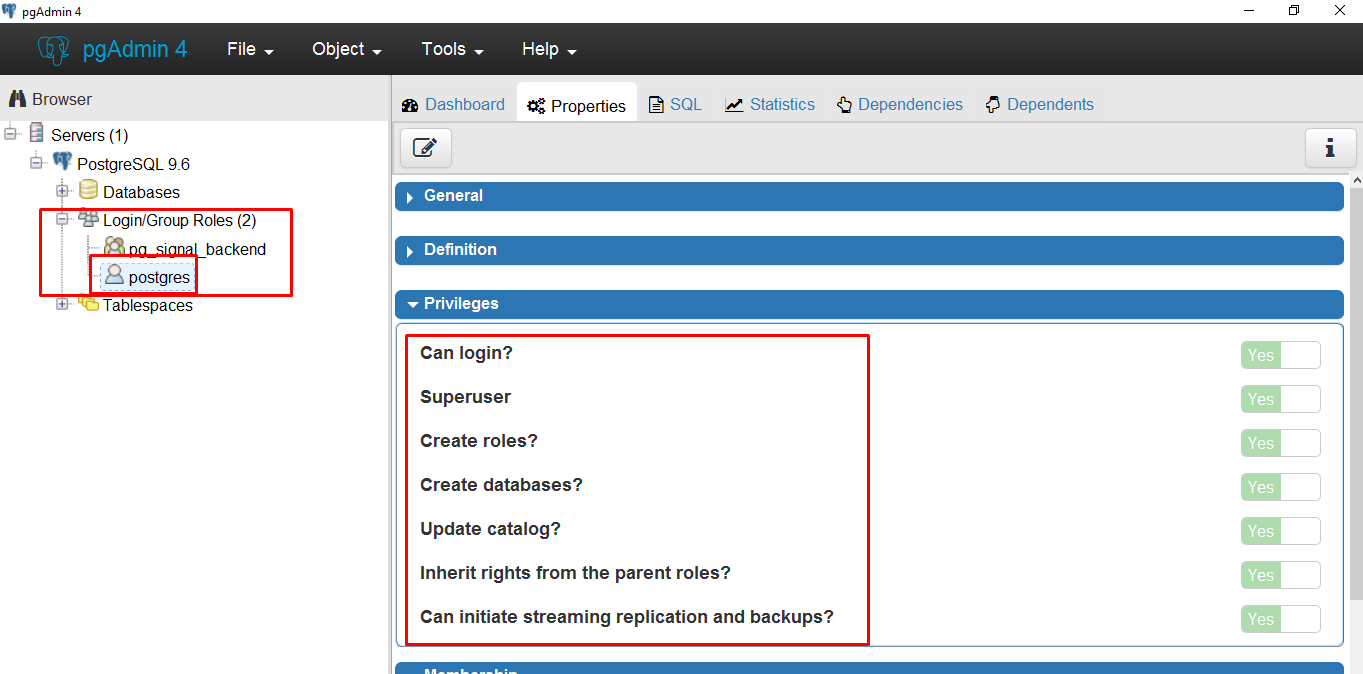
Como esta creado este Rol de base de datos
Sintaxis
CREATE ROLE nombre [ [ WITH ] option [ ... ] ]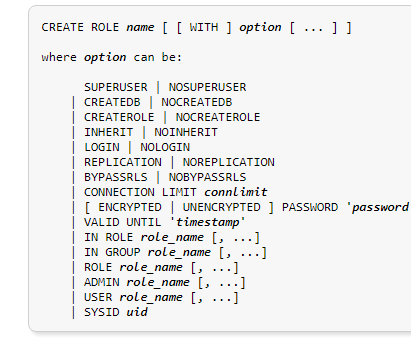
Parámetros
nombre: El nombre del nuevo rol
option:
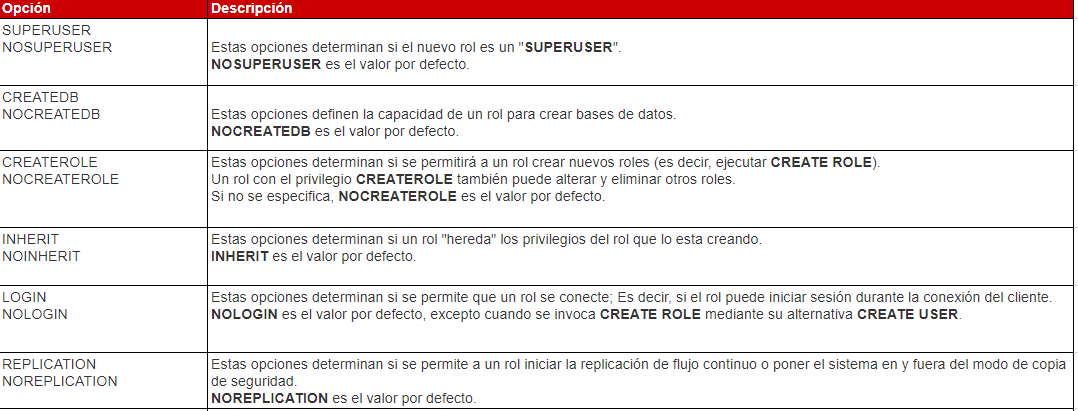
Parámetros
option:

Ejemplos
1. Cree un rol (sin contraseña) que pueda iniciar sesión:
CREATE ROLE yhoan LOGIN;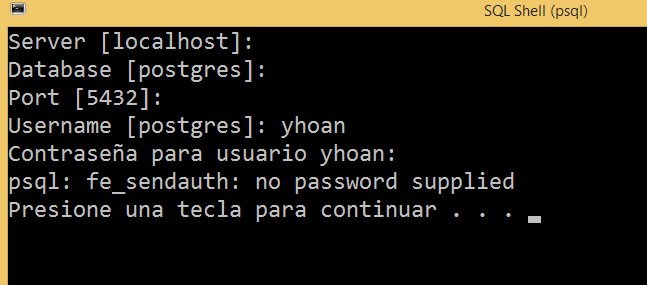
Este ejemplo solo nos permitiría trabajar si en el archivo pg_hba.conf tenemos la siguiente configuración:
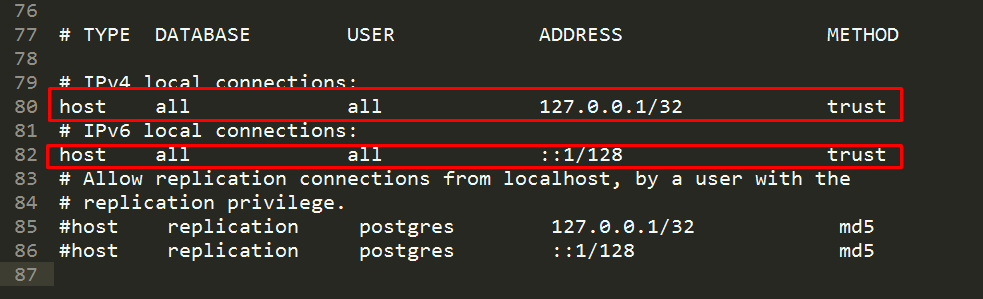
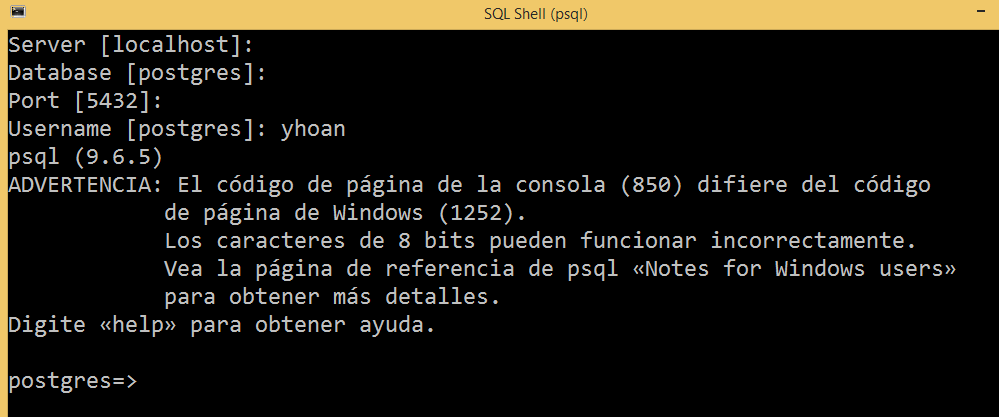
Ejemplos
2. Cree un rol con password:
CREATE USER lucho WITH PASSWORD '123';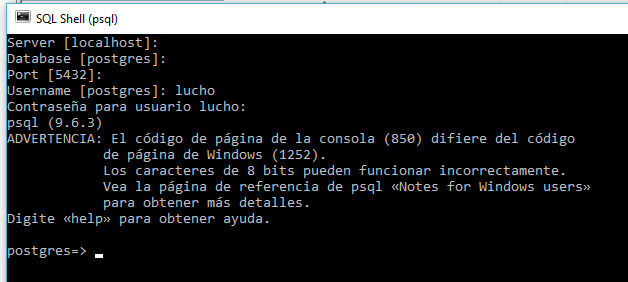
Ejemplos
3. Cree un rol con una contraseña válida hasta el final de 2017. Después de un segundo en 2018, la contraseña ya no es válida.
CREATE ROLE jose WITH LOGIN PASSWORD '123' VALID UNTIL '2018-01-01';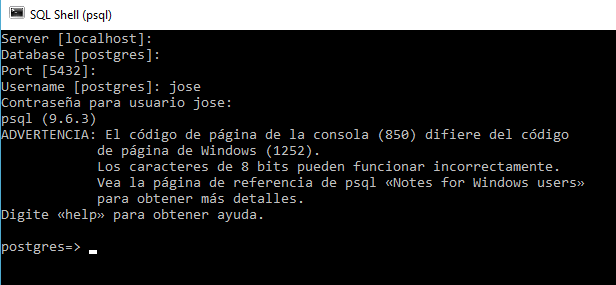
Ejemplos
4. Cree un rol con una contraseña válida hasta las 9:19 de la noche del 17 de Agosto del 2017 .
CREATE ROLE luisa WITH LOGIN PASSWORD '123' VALID UNTIL '2017-08-17 21:19:00';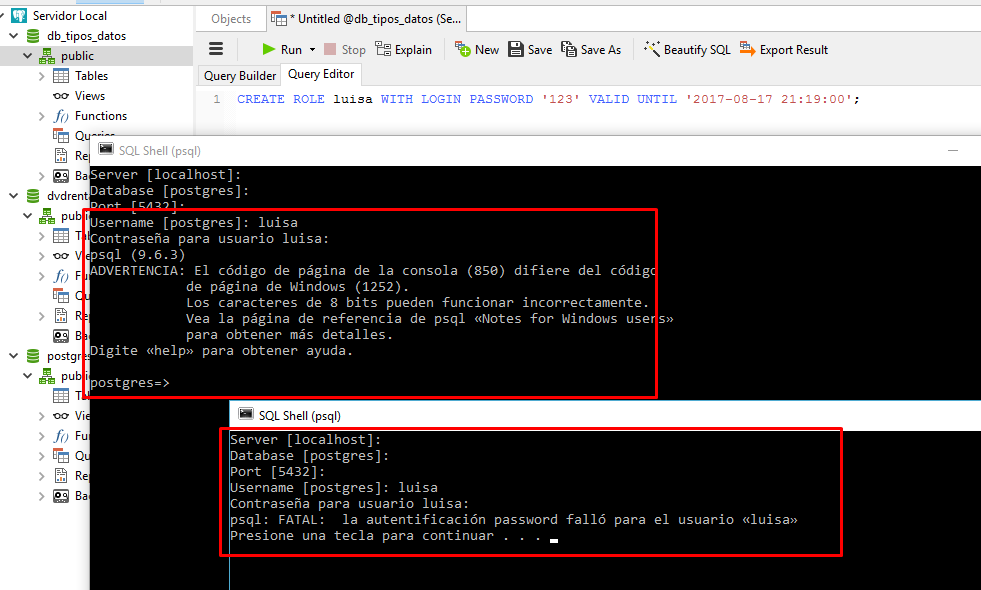
Ejemplos
5. Crear un rol que puede crear bases de datos y administrar roles:
CREATE ROLE admin WITH CREATEDB CREATEROLE LOGIN PASSWORD '123';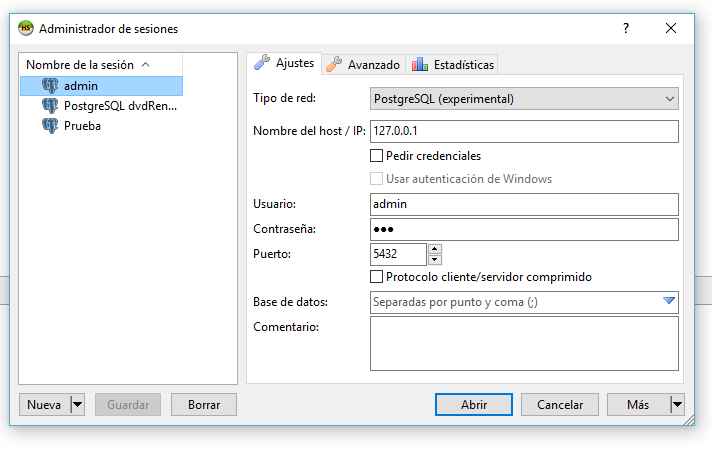
Ejemplos
5. Crear un rol que puede crear bases de datos y administrar roles:
CREATE ROLE admin WITH CREATEDB CREATEROLE LOGIN PASSWORD '123';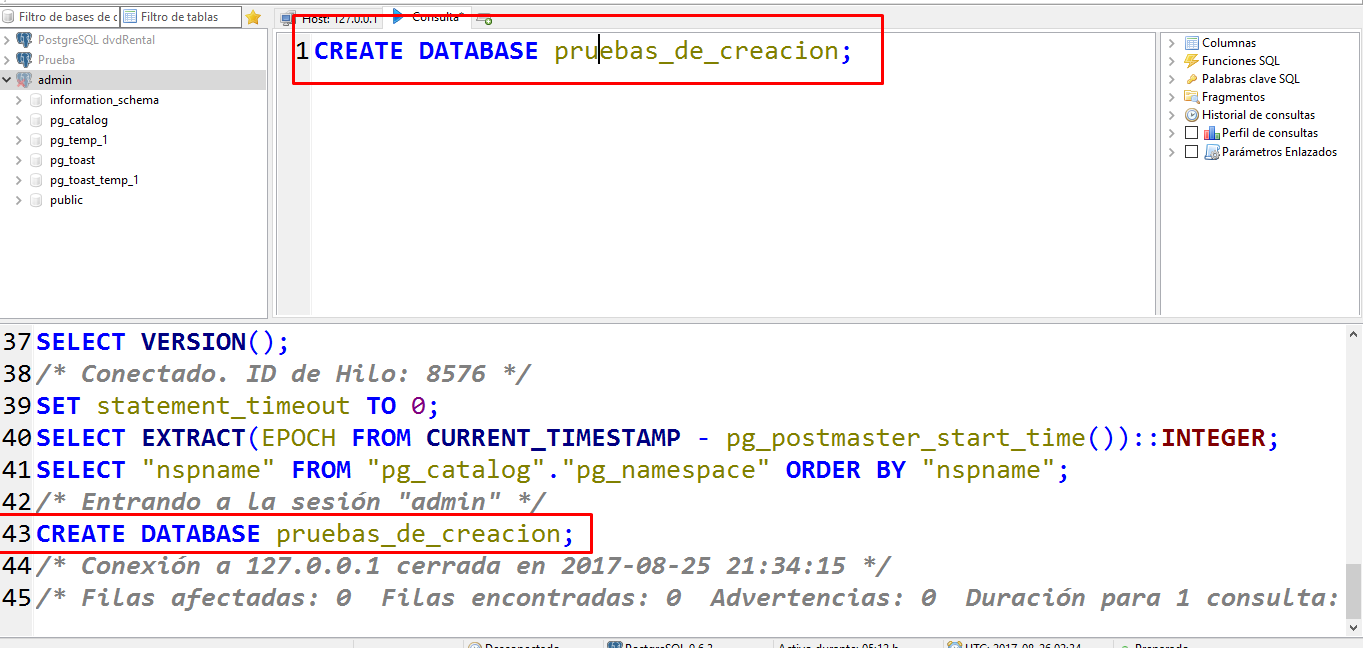
Ejemplos
5. Crear un rol que puede crear bases de datos y administrar roles:
CREATE ROLE admin WITH CREATEDB CREATEROLE LOGIN PASSWORD '123';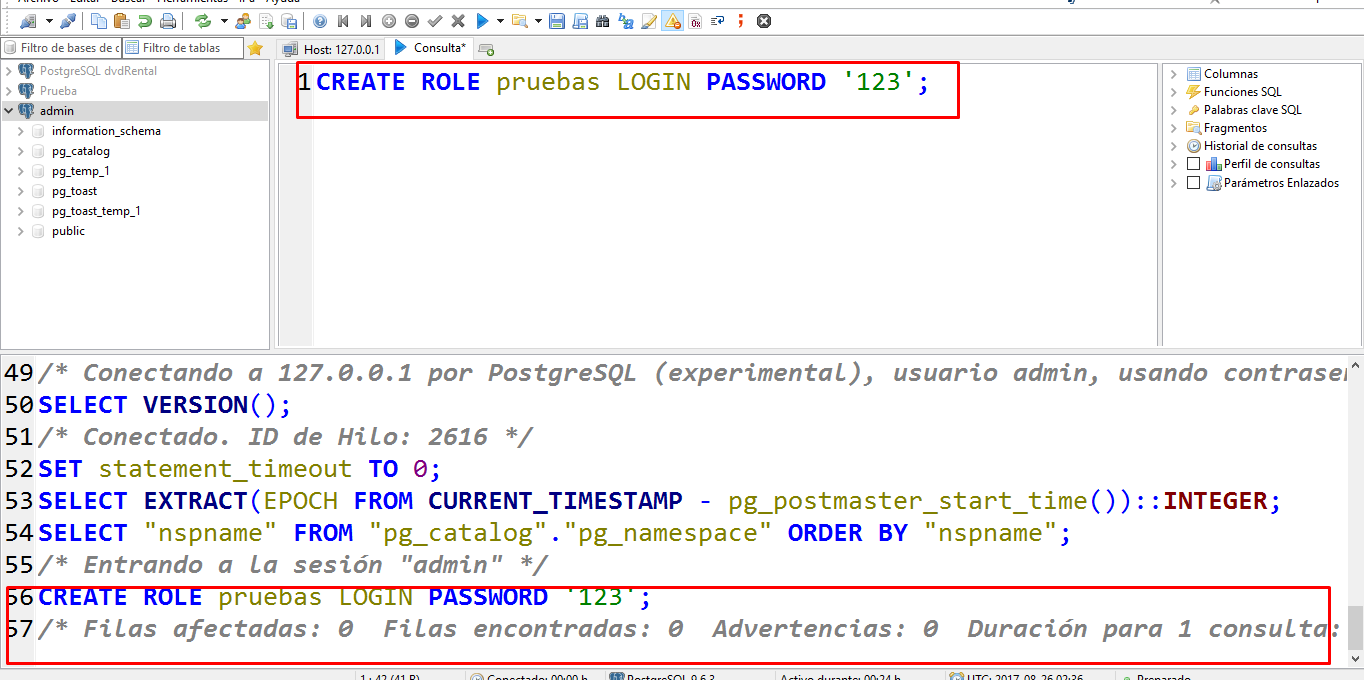
Ejemplos
Probare lo anterior con otro usuario (lucho, 123):
Ejemplos
Probare lo anterior con otro usuario (lucho, 123):
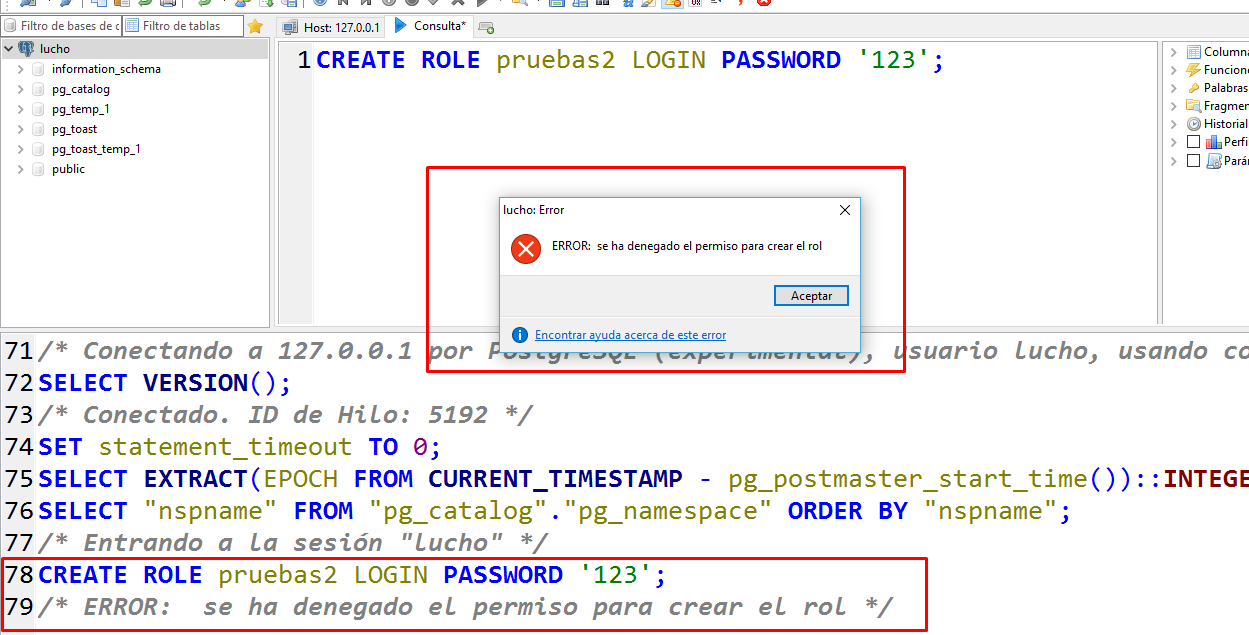
Modificar los roles
Alter Role
El comando ALTER ROLE se utiliza para cambiar los atributos de un rol de PostgreSQL.
Sintaxis
ALTER ROLE name [ [ WITH ] option [ ... ] ]
las opciones pueden ser:
SUPERUSER | NOSUPERUSER
| CREATEDB | NOCREATEDB
| CREATEROLE | NOCREATEROLE
| CREATEUSER | NOCREATEUSER
| INHERIT | NOINHERIT
| LOGIN | NOLOGIN
| REPLICATION | NOREPLICATION
| CONNECTION LIMIT connlimit
| [ ENCRYPTED | UNENCRYPTED ] PASSWORD 'password'
| VALID UNTIL 'timestamp'
ALTER ROLE name RENAME TO new_name
ALTER ROLE name [ IN DATABASE database_name ] SET configuration_parameter { TO | = } { value | DEFAULT }
ALTER ROLE { name | ALL } [ IN DATABASE database_name ] SET configuration_parameter FROM CURRENT
ALTER ROLE { name | ALL } [ IN DATABASE database_name ] RESET configuration_parameter
ALTER ROLE { name | ALL } [ IN DATABASE database_name ] RESET ALLEjemplos
1. Cambiar la contraseña de un rol:
ALTER ROLE yhoan WITH PASSWORD '123';
Ejemplos
2. Eliminar la contraseña de un rol:
ALTER ROLE yhoan WITH PASSWORD NULL;
Nota:
No olvide que el ejemplo anterior solo funciona si habilito la conexión de los usuarios de forma trust en el archivo pg_hba.conf de lo contrario le aparecería el siguiente error:
Ejemplos
3. Cambie la fecha de vencimiento de una contraseña especificando que la contraseña debe expirar al mediodía del 4 de octubre de 2017 utilizando la zona horaria que está una hora por delante de UTC:
ALTER ROLE yhoan VALID UNTIL 'Oct 4 12:00:00 2017 +1';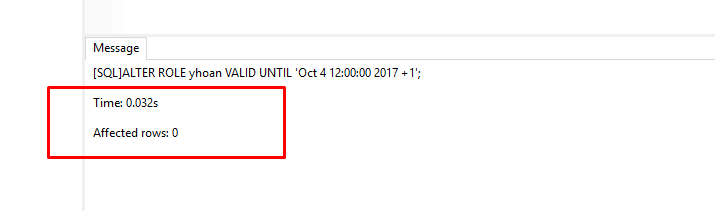
Ejemplos
4. Actualice el rol yhoan para hacer su contraseña válida para siempre:
ALTER ROLE yhoan VALID UNTIL 'infinity';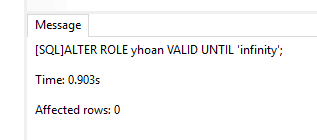
Ejemplos
5. Dar la capacidad a un rol de crear otros roles y nuevas bases de datos:
ALTER ROLE lucho CREATEROLE CREATEDB;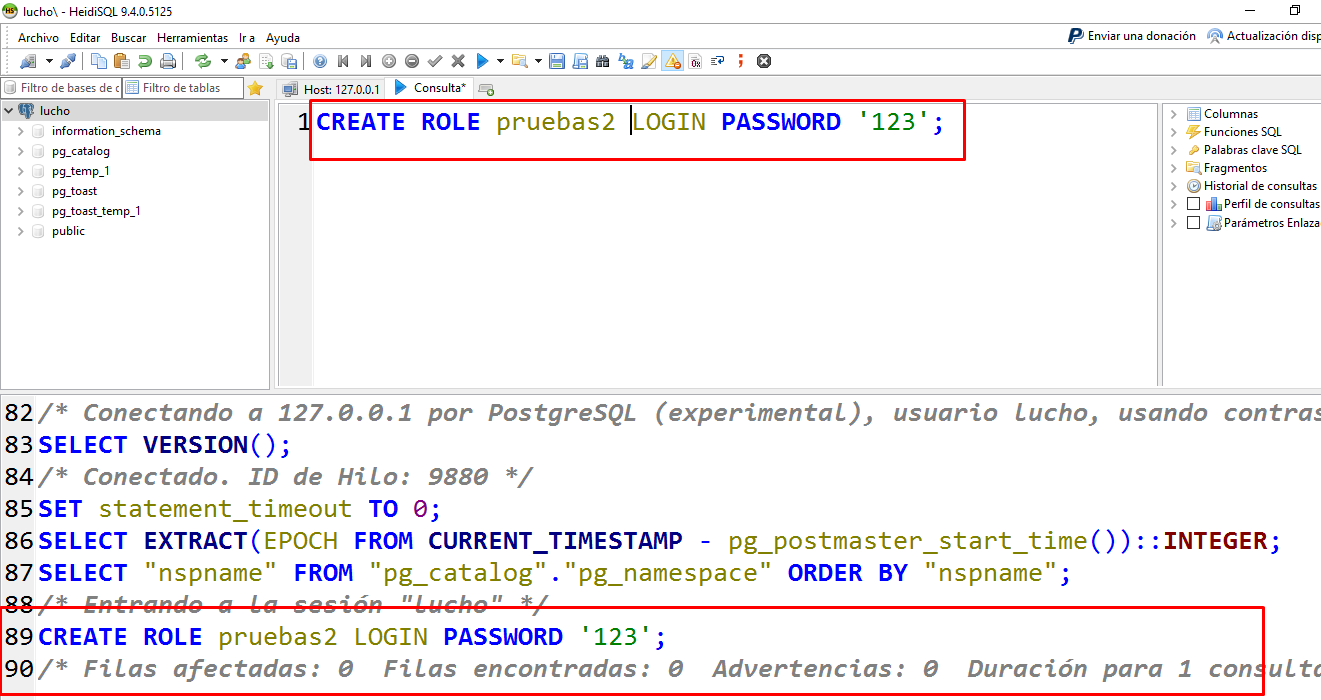
Ejemplos
6. Para rol yhoan cambie la configuración del parámetro client_min_messages de DEFAULT a DEBUG para la base de datos dvdrental. Para saber mas sobre estos parámetros de configuración:https://www.postgresql.org/docs/current/static/runtime-config.html
ALTER ROLE yhoan IN DATABASE dvdrental SET client_min_messages = DEBUG;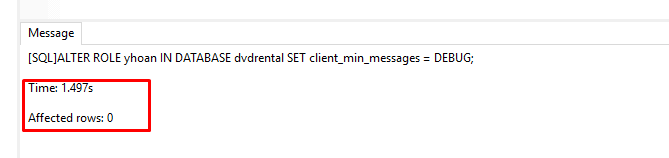
Para que puedas visualizar la información de los diferentes roles en la base de datos, puedes ejecutar la siguiente sentencia:
SELECT * FROM pg_authid;
SELECT * FROM pg_roles;Grupos de roles
Con frecuencia es conveniente agrupar a los usuarios para facilitar la administración de privilegios: de esa manera, los privilegios se pueden conceder o revocar a un grupo como un todo. De esta forma se simplifica la gestión de permisos, pues es más simple lidiar con la granularidad de altas (GRANT) y bajas (REVOKE) de privilegios. Un rol de grupo es un rol común y corriente sin posibilidad de login (si se le otorga login se convierte en un rol de usuario).
Grupos de roles
Con frecuencia es conveniente agrupar a los usuarios para facilitar la administración de privilegios: de esa manera, los privilegios se pueden conceder o revocar a un grupo como un todo. De esta forma se simplifica la gestión de permisos, pues es más simple lidiar con la granularidad de altas (GRANT) y bajas (REVOKE) de privilegios.
Un rol de grupo es un rol común y corriente sin posibilidad de login (si se le otorga login se convierte en un rol de usuario).
Crear un Grupo
CREATE ROLE Analistas;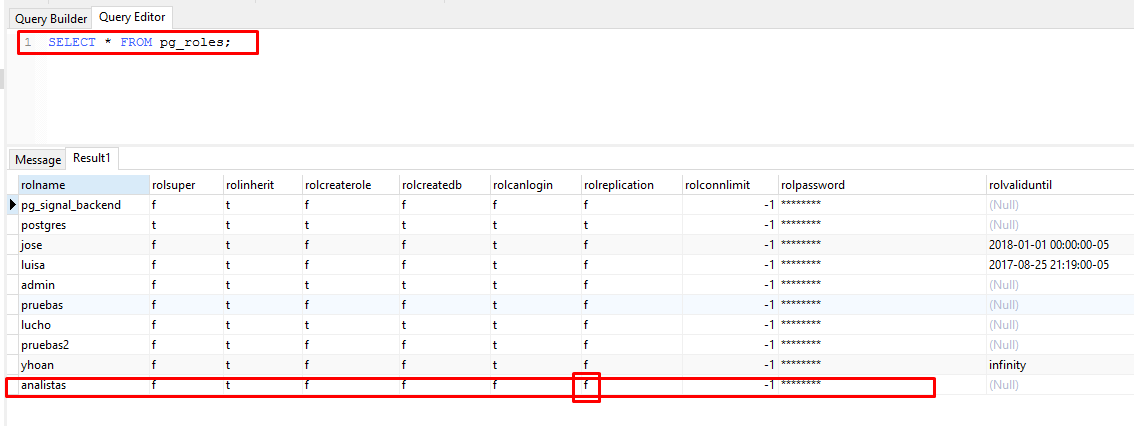
Normalmente, un rol que se utiliza como un grupo no tendría el atributo LOGIN, aunque puede configurarse. Una vez que existe el rol de grupo, puede agregar y quitar miembros utilizando los comandos GRANT y REVOKE
GRANT group_role TO role1, ... ;
REVOKE group_role FROM role1, ... ;Como vemos también se puede agregar al grupo a otros roles de grupo (ya que no hay realmente ninguna distinción entre roles de grupo y roles no pertenecientes al grupo).
La base de datos no le permitirá configurar bucles de grupos circulares.
-- Creando los grupos de usuarios
CREATE ROLE grupo_administradores;
CREATE ROLE grupo_aprendices;
-- Creando los usuarios del grupo administrativo
CREATE ROLE ygaleano WITH LOGIN PASSWORD 'admin' IN ROLE grupo_administradores;
CREATE USER cserna WITH PASSWORD 'admin' IN ROLE grupo_administradores;
-- Creando los usuarios del grupo aprendices
CREATE USER egomez WITH PASSWORD 'aprendiz' IN ROLE grupo_aprendices;
CREATE USER egomez1 WITH PASSWORD 'aprendiz' IN ROLE grupo_aprendices;
CREATE USER jserna WITH PASSWORD 'aprendiz' IN ROLE grupo_aprendices;
CREATE USER yramos WITH PASSWORD 'aprendiz' IN ROLE grupo_aprendices;
CREATE USER esuarez WITH PASSWORD 'aprendiz' IN ROLE grupo_aprendices;Digamos que debemos crear un grupo de administradores y aprendices que tendrán acceso a la base de datos y que luego por medio de privilegios se asignaran los permisos a los objetos de la base de datos.
Veamos el ejemplo.
-- Creando los grupos de usuarios
CREATE ROLE grupo_instructores;
-- Asignando los usuarios al grupo instructores
GRANT grupo_instructores TO ygaleano, cserna;Si por alguna razón los usuarios ya hubiesen sido creados y por alguna razón se debe crear un grupo, realizamos el siguiente comando:
-- Creando los grupos de auto-evaluación
CREATE ROLE grupo_autoevaluacion ROLE ygaleano, cserna;O pudieses realizar esta sentencia:
Para destruir un rol de grupo, utilice DROP ROLE:
DROP ROLE name;Cualquier rol perteneciente al grupo se revoca automáticamente (pero los roles miembros no se ven afectadas de otro modo).
Privilegios
Para que sirven los privilegios
Cuando se crea un objeto, se le asigna un propietario. Normalmente, un propietario tiene la función de ejecutar determinadas instrucciones. Para la mayoría de tipos de objetos, el estado inicial es que sólo el propietario (o un superusuario) puede hacer algo con el objeto. Para permitir que otros roles lo utilicen, deben concederse privilegios. Un privilegio es un derecho para ejecutar un tipo particular de instrucción SQL o para acceder al objeto de otro usuario.
Ejemplos de privilegios
- Conéctese a la base de datos
- Crear una base de datos o una tabla
- Alterar una tabla
- Seleccionar filas de la tabla de otro usuario
- Ejecutar el procedimiento almacenado de otro usuario
Tipos de privilegios
Hay diferentes tipos de privilegios:
SELECT, INSERT, UPDATE, DELETE, TRUNCATE, REFERENCES, TRIGGER, CREATE, CONNECT, TEMPORARY, EXECUTE y USAGE.
Los privilegios aplicables a un objeto determinado varían dependiendo del tipo del objeto (tabla, función, etc.)
Tipos de privilegios

Tipos de privilegios

Tipos de privilegios

Sentencia GRANT
La sentencia GRANT define los privilegios de acceso.
Esta se utiliza para otorgar privilegios a un objeto de base de datos (tabla, columna, vista, tabla externa, secuencia, base de datos, función, lenguaje de procedimiento, esquema o espacio de tablas) y estos permisos se le asignan a un rol o grupo de roles.
Que estos permisos le sean asignados a un grupo es muy significativo, puesto que este grupo transmite los privilegios otorgados a cada uno de sus miembros.
Sintaxis
Permisos para tablas
GRANT {
{ SELECT | INSERT | UPDATE | DELETE | TRUNCATE | REFERENCES | TRIGGER } [, ...]
|
ALL [ PRIVILEGES ]
}
ON {
[ TABLE ] table_name [, ...]
|
ALL TABLES IN SCHEMA schema_name [, ...]
}
TO { [ GROUP ] role_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]Sintaxis
Permisos para columnas de una tabla
GRANT {
{ SELECT | INSERT | UPDATE | REFERENCES } ( column [, ...] ) [, ...]
|
ALL [ PRIVILEGES ] ( column [, ...] )
}
ON [ TABLE ] table_name [, ...]
TO { [ GROUP ] role_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]Sintaxis
Permisos para las secuencias
GRANT {
{ USAGE | SELECT | UPDATE } [, ...]
|
ALL [ PRIVILEGES ]
}
ON {
SEQUENCE sequence_name [, ...]
|
ALL SEQUENCES IN SCHEMA schema_name [, ...]
}
TO { [ GROUP ] role_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]Sintaxis
Permisos para las bases de datos
GRANT {
{ CREATE | CONNECT | TEMPORARY | TEMP } [, ...]
|
ALL [ PRIVILEGES ]
}
ON DATABASE database_name [, ...]
TO { [ GROUP ] role_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]Sintaxis
Permisos para los dominios creados
GRANT { USAGE | ALL [ PRIVILEGES ] }
ON DOMAIN domain_name [, ...]
TO { [ GROUP ] role_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]Sintaxis
Permisos para las funciones
GRANT {
EXECUTE
|
ALL [ PRIVILEGES ]
}
ON {
FUNCTION function_name ( [ [ argmode ] [ arg_name ] arg_type [, ...] ] ) [, ...]
|
ALL FUNCTIONS IN SCHEMA schema_name [, ...]
}
TO { [ GROUP ] role_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]Sintaxis
Permisos para los esquemas
GRANT {
{ CREATE | USAGE } [, ...]
|
ALL [ PRIVILEGES ]
}
ON SCHEMA schema_name [, ...]
TO { [ GROUP ] role_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]
Sintaxis
Permisos para los espacios de tablas
GRANT { CREATE | ALL [ PRIVILEGES ] }
ON TABLESPACE tablespace_name [, ...]
TO { [ GROUP ] role_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]Sintaxis
Permisos para los tipos de datos
GRANT { USAGE | ALL [ PRIVILEGES ] }
ON TYPE type_name [, ...]
TO { [ GROUP ] role_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]Sintaxis
Permisos para roles
GRANT role_name [, ...] TO role_name [, ...] [ WITH ADMIN OPTION ]Revoke
El comando REVOKE se utiliza para revocar los privilegios concedidos anteriormente de uno o más roles
REVOKE [ GRANT OPTION FOR ]
{
{ SELECT | INSERT | UPDATE | DELETE | TRUNCATE | REFERENCES | TRIGGER } [, ...]
|
ALL [ PRIVILEGES ]
}
ON
{
[ TABLE ] table_name [, ...]
|
ALL TABLES IN SCHEMA schema_name [, ...]
}
FROM { [ GROUP ] role_name | PUBLIC } [, ...]
[ CASCADE | RESTRICT ]Tablespace
Que es un Tablespace
Tablespace en PostgreSQL permiten a los administradores definir los lugares, en el sistema de archivos, donde los archivos de la base de datos se pueden almacenar.
Una vez creado, un Tablespace puede ser llamado por su nombre a la hora de crear objetos de base de datos.
Mediante el uso de Tablespace, un administrador puede controlar la estructura del disco de instalación de PostgreSQL. Esto es útil por lo menos en dos formas.
Que es un Tablespace
En primer lugar, si la partición o volumen en el que el grupo se ha inicializado se queda sin espacio y no puede extenderse, un espacio de Tablespace se pueden crear en una partición diferente y se utiliza hasta que el sistema puede ser reconfigurado.
En segundo lugar, permitir a un administrador el uso de los patrones de uso de objetos de base de datos para optimizar el rendimiento. Por ejemplo, un índice que es muy usado puede ser colocado en un dispositivo de estado sólido.
Al mismo tiempo, una tabla para almacenar datos que rara vez se utiliza o los resultados no son críticos, podrían estar almacenados en un sistema de disco menos costoso o más lento.
Sintaxis
CREATE TABLESPACE tablespace_name
OWNER user_name
LOCATION directory_path;
CREATE TABLESPACE tbl_mis_datos
OWNER postgres
LOCATION 'E:\especializacion\postgres\tablespaces';Tablas, índices, bases de datos completas pueden ser asignadas a los TABLESPACES.
Por ejemplo, el siguiente query crea una tabla en la tablespace tbl_mis_datos.
Como alternativa, utilice el parámetro default_tablespace.
CREATE TABLE prueba (i int) TABLESPACE tbl_mis_datos;
SET default_tablespace = tbl_mis_datos;
CREATE TABLE prueba (i int);
CREATE DATABASE mi_db TABLESPACE tbl_mis_datos;
PostgreSQL tiene una rica y amplia variedad de tipos de datos en los que se puede guardar valores de para los usos comunes, científicos y financieros que el usuario necesite.
Si no se encuentran entre los tipos nativos, algun tipo de dato que necesites, puedes definir alguno con el comando CREATE TYPE.
Veamos algunos de los tipos de datos mas importantes para trabajar con PostgreSQL:
Booleanos
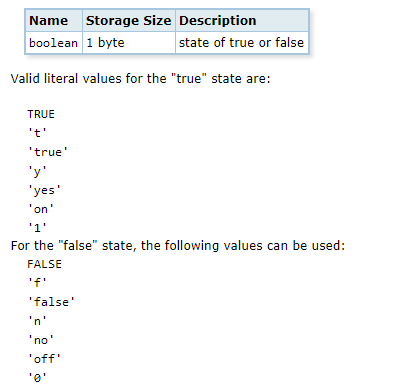
Booleanos
/*Creación de tabla*/
CREATE TABLE tbl_producto(
idProducto INT NOT NULL PRIMARY KEY,
disponible BOOLEAN NOT NULL
);
/*Inserciones*/
INSERT INTO tbl_producto(idProducto, disponible)
VALUES
(100, TRUE),
(200, FALSE),
(300, 't'),
(400, '1'),
(500, 'y'),
(600, 'yes'),
(700, 'no'),
(800, '0');
/*Selects*/
SELECT *
FROM tbl_producto
WHERE disponible = 'yes';
SELECT *
FROM tbl_producto
WHERE disponible;
SELECT *
FROM tbl_producto
WHERE disponible = 'no';
SELECT *
FROM tbl_producto
WHERE NOT disponible;
/*Alterar las tablas*/
ALTER TABLE tbl_producto
ALTER COLUMN disponible SET DEFAULT FALSE;
INSERT INTO tbl_producto(idProducto)
VALUES (900);
SELECT *
FROM tbl_producto
WHERE NOT disponible;
Caracteres
El tipo de dato text puede almacenar una cadena de longitud ilimitada.
Si no especifica el entero n para el tipo de dato varchar, se comporta como el tipo de dato text.
El rendimiento del varchar (sin n) y el text son los mismos. La única ventaja de especificar la longitud para el tipo de datos varchar es que PostgreSQL comprobará y emitirá un error si intenta insertar una cadena más larga en la columna varchar(n).
A diferencia de varchar, el character o char sin el especificador de longitud es el mismo que el character(1) o char(1).
Diferente de otros sistemas de bases de datos, en PostgreSQL, no hay diferencia de rendimiento entre tres tipos de caracteres.
En la mayoría de las situaciones, debe utilizar text o varchar y varchar(n) si desea que PostgreSQL compruebe el límite de longitud.
CREATE TABLE tbl_caracter (
idCaracter serial PRIMARY KEY,
a CHAR (1),
b VARCHAR (10),
c TEXT
);
INSERT INTO tbl_caracter (a, b, c)
VALUES
(
'Si',
'Esto es una prueba para el varchar',
'Esto es un gran texto para probar el tipo de dato text'
);
INSERT INTO tbl_caracter (a, b, c)
VALUES
(
'S',
'Esto es una prueba para el varchar',
'Esto es un gran texto para probar el tipo de dato text'
);
INSERT INTO tbl_caracter (a, b, c)
VALUES
(
'S',
'Varchar(n)',
'Esto es un gran texto para probar el tipo de dato text'
);Numéricos
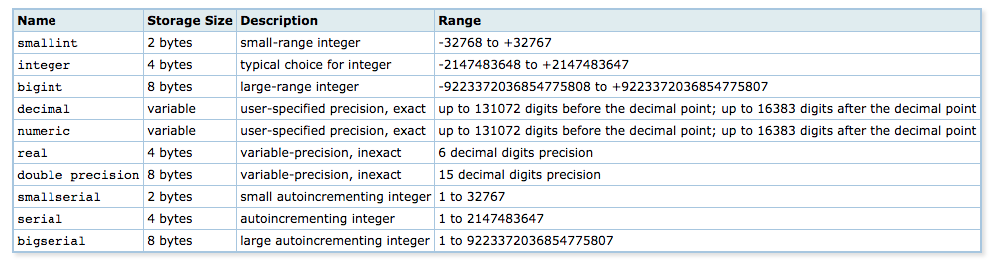
Numéricos
Los campos de tipo serial : se almacenan en un campo de tipo int
Los bigserial : se almacenan en un campo de tipo bigint.
En los decimales el rango depende de los argumentos que le pasemos, también los bytes que ocupa.
Se utiliza el punto como separador de decimales.
Numéricos
Si ingresamos un valor con más decimales que los permitidos, redondea al más cercano; por ejemplo, si definimos "decimal(4,2)" e ingresamos el valor "12.686", guardará "12.69", redondeando hacia arriba; si ingresamos el valor "12.682", guardará "12.67", redondeando hacia abajo.
Si intentamos ingresar un valor fuera de rango, no lo permite.
Numéricos
Si ingresamos una cadena, PostgreSQL intenta convertirla a valor numérico, si dicha cadena consta solamente de dígitos, la conversión se realiza, luego verifica si está dentro del rango, si es así, la ingresa, sino, muestra un mensaje de error y no ejecuta la sentencia. Si la cadena contiene caracteres que PostgreSQL no puede convertir a valor numérico, muestra un mensaje de error y la sentencia no se ejecuta.
Es importante elegir el tipo de dato adecuado según el caso, el más preciso. Por ejemplo, si un campo numérico almacenará valores positivos menores a 255, el tipo "int" no es el más adecuado, conviene el tipo "smallint", de esta manera usamos el menor espacio de almacenamiento posible.
Numéricos
CREATE TABLE tbl_numerico (
idNumerico serial PRIMARY KEY,
codigoBarras bigserial,
popular INT NOT NULL,
edad SMALLINT NOT NULL,
cedula BIGINT NOT NULL,
precio DECIMAL(5, 2) NOT NULL,
flotante1 FLOAT NOT NULL, -- Maximo de 8 Bytes, Por defecto es de 2 Bytes
flotante2 REAL NOT NULL, -- Es un Float de 4 Bytes, float4
doubleColumna DOUBLE PRECISION NOT NULL, -- Es un Float de 8 Bytes, float8
resultado NUMERIC(5, 2) NOT NULL
);Fecha y tiempo

Date
CREATE TABLE tbl_post(
idPost serial PRIMARY KEY,
encabezado VARCHAR (255) NOT NULL,
fechaCreacion DATE NOT NULL DEFAULT CURRENT_DATE
);
INSERT INTO tbl_post(encabezado)
VALUES ('Probando las fechas');
SELECT *
FROM tbl_post;
SELECT NOW()::date, NOW()::time, NOW();
SELECT CURRENT_DATE;
SELECT AGE('1993-07-05' :: DATE);
SELECT to_char(date '2017-09-02', 'YYYY/MM/DD');
SELECT to_char('2017-09-02' :: DATE, 'YYYY/MM/DD');
SELECT TO_CHAR(NOW() :: DATE, 'dd/mm/yyyy');
SELECT
EXTRACT (YEAR FROM NOW()) AS YEAR,
EXTRACT (MONTH FROM NOW()) AS MONTH,
EXTRACT (DAY FROM NOW()) AS DAY;
SELECT '2017-09-09' - now() as "¿Falta para el evento?"Time
CREATE TABLE tbl_turnos (
idTurno serial PRIMARY KEY,
nombreTurno VARCHAR NOT NULL,
empieza TIME NOT NULL,
termina TIME NOT NULL
);
INSERT INTO tbl_turnos (nombreTurno , empieza , termina )
VALUES('Mañana', '08:00:00', '12:00:00'),
('Tarde', '13:00:00', '17:00:00'),
('Noche', '18:00:00', '22:00:00');
SELECT CURRENT_TIME;
SELECT CURREN_TIME(5);
SELECT LOCALTIME;
SELECT LOCALTIME(3);Time
CREATE TABLE tbl_ZonaHoraria(
idZona serial NOT NULL PRIMARY KEY,
nombre varchar(50) NOT NULL
);
INSERT INTO tbl_ZonaHoraria(nombre)
VALUES ('Asia/Yekaterinburg'),
('America/Bogota'),
('America/Adak');
SELECT * FROM tbl_ZonaHoraria;
SELECT nombre, CURRENT_TIME AT TIME ZONE (nombre), LOCALTIME AT TIME ZONE (nombre)
FROM tbl_ZonaHoraria;Time
SELECT
LOCALTIME,
EXTRACT (HOUR FROM LOCALTIME) as hora,
EXTRACT (MINUTE FROM LOCALTIME) as minutos,
EXTRACT (SECOND FROM LOCALTIME) as segundos,
EXTRACT (milliseconds FROM LOCALTIME) as Milisegundos;
/*Oparaciones*/
SELECT LOCALTIME + INTERVAL '2 hours';
SELECT time '10:00' - time '02:00';
SELECT time '10:00' * 2;Timestamp y Timestamptz
CREATE TABLE tbl_timestamp (ts TIMESTAMP, tstz TIMESTAMPTZ);
SHOW TIMEZONE;
INSERT INTO tbl_timestamp (ts, tstz)
VALUES
(
'2017-09-02 19:10:25-07',
'2017-09-02 19:10:25-07' -- 'America/Los_Angeles'
);
SELECT *
FROM tbl_timestamp;
SELECT NOW();
SELECT CURRENT_TIMESTAMP;
SELECT TIMEOFDAY();
SELECT timezone('America/Los_Angeles','2017-09-02 00:00');
SELECT timezone('America/Los_Angeles','2017-09-02 00:00'::timestamptz);Interval
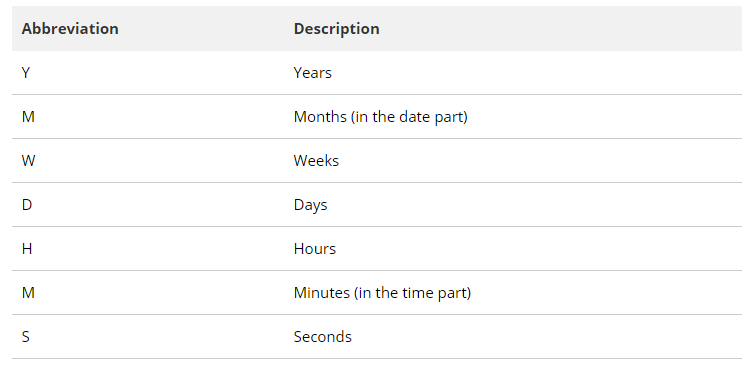
Interval
/*
Sintaxis: cantidad unidad [dirección]
cantidad es cualquier numero (+ o -)
unidad puede ser cualquiera de las siguientes: millennium, century, decade, year, month, week,
day, hour, minute, second, millisecond, microsecond, sus abreviaturas (y, m, d, etc.,) o
sus formas plurales (months, days, etc.).
dirección puede ser: ago
*/
SELECT INTERVAL '2 months ago', INTERVAL '3 hours 20 minutes';
SELECT NOW() - interval '2 DAY' AS "Hace dos días";
SELECT NOW() - interval 'P0000-00-02T00:00:00' AS "Hace dos días";
SELECT NOW() - interval 'P0Y0M2DT0H0M0S' AS "Hace dos días";Interval
SET intervalstyle = 'sql_standard';
SELECT
INTERVAL '6 years 5 months 4 days 3 hours 2 minutes 1 second';
SET intervalstyle = 'postgres';
SELECT
INTERVAL '6 years 5 months 4 days 3 hours 2 minutes 1 second';
SET intervalstyle = 'postgres_verbose';
SELECT
INTERVAL '6 years 5 months 4 days 3 hours 2 minutes 1 second';
SET intervalstyle = 'iso_8601';
SELECT
INTERVAL '6 years 5 months 4 days 3 hours 2 minutes 1 second';
Interval
SELECT
INTERVAL '2h 50m' + INTERVAL '10m'; -- 03:00:00
SELECT
INTERVAL '2h 50m' - INTERVAL '50m'; -- 02:00:00
SELECT
600 * INTERVAL '1 minute'; -- 10:00:00Interval
SELECT
justify_days(INTERVAL '80 days'),
justify_hours(INTERVAL '50 hours'),
justify_interval(interval '13 month')
justify_interval(interval '1 year -1 hour');
SELECT EXTRACT (MINUTE FROM INTERVAL '5 hours 21 minutes');
SELECT TO_CHAR( INTERVAL '17h 20m 05s', 'HH24:MI:SS');Enum Type
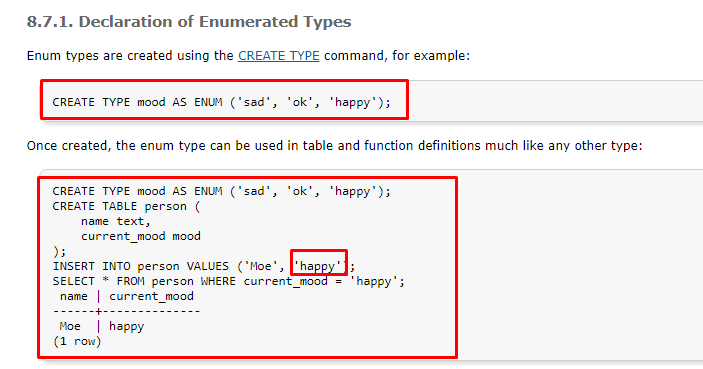
JSON types

JSON types
JSON types
CREATE TABLE tbl_ordenes (
ID serial NOT NULL PRIMARY KEY,
info json NOT NULL
);
INSERT INTO tbl_ordenes(info)
VALUES
(
'{ "cliente": "John Doe", "items": {"producto": "Cerveza","cantidad": 6}}'
),
(
'{ "cliente": "Yhoan Galeano", "items": {"producto": "Pañales","cantidad": 24}}'
),
(
'{ "cliente": "Adalberto Carcamo", "items": {"producto": "Galletas","cantidad": 1}}'
),
(
'{ "cliente": "Christian Serna", "items": {"producto": "Cuadernos","cantidad": 2}}'
);
SELECT info FROM tbl_ordenes;JSON types
PostgreSQL proporciona dos operadores nativos -> y - >> para ayudarle a consultar los datos de JSON.
El operador -> devuelve el campo del objeto JSON por clave.
El operador - >> devuelve el campo de objeto JSON por texto.
JSON types
SELECT
info -> 'cliente' AS cliente,
info -> 'items' AS items,
info ->> 'cliente' AS cliente,
info ->> 'items' AS items
FROM
tbl_ordenes;
SELECT
info -> 'items' ->> 'producto' as producto
FROM
tbl_ordenes
ORDER BY
producto;
SELECT
info -> 'items' ->> 'producto' as producto
FROM
tbl_ordenes
WHERE
info -> 'items' ->> 'producto' LIKE '%ñ%'
ORDER BY
producto;JSON types
SELECT
info -> 'items' ->> 'producto' as producto
FROM
tbl_ordenes
WHERE
CAST(info -> 'items' ->> 'cantidad' AS INTEGER) > 5
ORDER BY
producto;
SELECT json_each (info) FROM tbl_ordenes;
SELECT json_object_keys (info->'items') FROM tbl_ordenes;
SELECT json_typeof (info->'items') FROM tbl_ordenes;
SELECT json_typeof (info->'items'->'cantidad') FROM tbl_ordenes;Geometric Types
SELECT point(6.300953, -75.568887)UUID
UUID de PostgreSQL UUID significa Universal Unique Identifier definido por RFC 4122 y otras normas relacionadas. Un valor UUID es la cantidad de 128 bits generada por un algoritmo que la hace única en el universo conocido usando el mismo algoritmo (Secuencia de 32 - Más información https://www.postgresql.org/docs/9.5/static/uuid-ossp.html).
A continuación se muestran algunos ejemplos de los valores UUID:

UUID
Como puede ver, un UUID es una secuencia de 32 dígitos hexadecimales representados en grupos separados por guiones.
Debido a su característica de singularidad, a menudo se encuentra UUID en los sistemas distribuidos, ya que garantiza una singularidad mejor que el tipo de datos SERIAL que genera sólo valores únicos dentro de una sola base de datos.
Para almacenar valores UUID en la base de datos PostgreSQL, se utiliza el tipo de datos UUID.
UUID
Como puede ver, un UUID es una secuencia de 32 dígitos hexadecimales representados en grupos separados por guiones.
Debido a su característica de singularidad, a menudo se encuentra UUID en los sistemas distribuidos, ya que garantiza una singularidad mejor que el tipo de datos SERIAL que genera sólo valores únicos dentro de una sola base de datos.
Para almacenar valores UUID en la base de datos PostgreSQL, se utiliza el tipo de datos UUID.
UUID
Para habilitar el uso de UUID, PostgreSQL no cuenta con funciones propias para esto. Lo bueno es que permite el uso de funciones de terceros para generarlos.
Para esto debemos ejecutar el siguiente comando:
CREATE EXTENSION IF NOT EXISTS "uuid-ossp";El IF NOT EXIST me permite que el modulo no se vuelva a instalar.
UUID
Si desea generar un valor UUID basándose únicamente en números aleatorios, puede utilizar la función uuid_generate_v4 ().
Por ejemplo:
SELECT uuid_generate_v4();El IF NOT EXIST me permite que el modulo no se vuelva a instalar.
UUID
Para crear una tabla utilizando este tipo de dato, podríamos realizar lo siguiente:
CREATE TABLE contacts (
contact_id uuid DEFAULT uuid_generate_v4 (),
first_name VARCHAR NOT NULL,
last_name VARCHAR NOT NULL,
email VARCHAR NOT NULL,
phone VARCHAR,
PRIMARY KEY (contact_id)
);Los tipos de datos
son un componentes importante a la hora de optimizar recursos
Secuencias en PostgreSQL
¿Para que sirven las secuencias?
Una secuencia (sequence) se emplea para generar valores enteros secuenciales únicos y asignárselos a campos numéricos; se utilizan generalmente para las claves primarias de las tablas garantizando que sus valores no se repitan (normalmente utilizamos la definición de un campo serial, este tiene asociado una secuencia en forma automática)
Una secuencia es una tabla con un campo numérico en el cual se almacena un valor y cada vez que se consulta, se incrementa tal valor para la próxima consulta.
Sintaxis
CREATE SEQUENCE [ IF NOT EXISTS ] name
[ START [ WITH ] start ]
[ INCREMENT [ BY ] increment ]
[ MAXVALUE maxvalue | NO MAXVALUE ]
[ MINVALUE minvalue | NO MINVALUE ]
[ [ NO ] CYCLE ]
[ OWNED BY { table_name.column_name | NONE } ]Propiedades
La cláusula "start with" indica el valor desde el cual comenzará la generación de números secuenciales. Si no se especifica, se inicia con el valor que indique "minvalue".
La cláusula "increment by" especifica el incremento, es decir, la diferencia entre los números de la secuencia; debe ser un valor numérico entero positivo o negativo diferente de 0. Si no se indica, por defecto es 1.
"maxvalue" define el valor máximo para la secuencia. Si se omite, por defecto es 9223372036854775807.
"minvalue" establece el valor mínimo de la secuencia. Si se omite será -9223372036854775808.
Propiedades
La cláusula "cycle" indica que, cuando la secuencia llegue a máximo valor (valor de "maxvalue") se reinicie, comenzando con el mínimo valor ("minvalue") nuevamente, es decir, la secuencia vuelve a utilizar los números.
La opción OWNED BY hace que la secuencia se asocie con una columna de tabla específica, de tal manera que si esa columna (o toda su tabla) se deja caer, la secuencia se eliminará automáticamente también. La tabla especificada debe tener el mismo propietario y estar en el mismo esquema que la secuencia. OWNED BY NONE, el valor predeterminado, especifica que no existe tal asociación.
Propiedades
Si se omite, por defecto la secuencia se crea "nocycle", lo que produce un error si supera el máximo valor. Si no se especifica ninguna cláusula, excepto el nombre de la secuencia, por defecto, comenzará en 1, se incrementará en 1, el mínimo valor será -9223372036854775808, el máximo será 9223372036854775807 y "nocycle".
Ejemplo
CREATE SEQUENCE sec_discotecas
START 1
INCREMENT 1
MAXVALUE 99999
MINVALUE 1;Ejemplo
SELECT nextval('sec_discotecas');
SELECT currval('sec_discotecas');
SELECT setval('sec_discotecas', 7);
drop sequence sec_discotecas;Crear tablas en PostgreSQL
-- SINTAXIS
CREATE DATABASE nombre OWNER = usuario TABLESPACE = el_tablespace
-- SINTAXIS
CREATE TABLE [ IF NOT EXISTS ] nombre_tabla (
columna1 tipo_dato,
columna2 tipo_dato (tamaño),
columna3 tipo_dato NOT NULL,
columna4 tipo_dato
DEFAULT valor_x_defecto,
columna5 SERIAL,
CONSTRAINT nombre_constraint1
CHECK (columnaN > valor and columaN < valor),
CONSTRAINT nombre_constraint2
PRIMARY KEY (columnaN, …, columnaM),
CONSTRAINT nombre_constraint3
UNIQUE (columnaN, …, columnaM),
CONSTRAINT nombre_constraint4
FOREIGN KEY (columnaN, … columnaM)
REFERENCES otra_tabla(columnaN, … columnaM)
ON DELETE acción ON UPDATE accion
);-- SINTAXIS
ALTER DATABASE nombre RENAME TO nuevo_nombre;
ALTER DATABASE nombre OWNER TO nuevo_usuario;
ALTER DATABASE nombre SET TABLESPACE nuevo_tablespace;
ALTER TABLE nombre ADD COLUMN campoN tipo_dato (tamaño);
ALTER TABLE nombre DROP COLUMN campoN;
ALTER TABLE nombre ALTER COLUMN campoN SET NOT NULL;
ALTER TABLE nombre ALTER COLUMN campoN DROP NOT NULL;
ALTER TABLE nombre ADD CONSTRAINT nombre_constraint
FOREIGN KEY (campoN, … campoM)
REFERENCES otra_tabla (campoN, …, campoM) ON DELETE acción ON UPDATE acción;
ALTER TABLE nombre DROP CONSTRAINT nombre_constraint;
ALTER TABLE nombre ALTER COLUMN campoN SET DEFAULT valor_x_defecto;
ALTER TABLE nombre ALTER COLUMN campoN DROP DEFAULT;
ALTER TABLE nombre ALTER COLUMN campoN TYPE nuevo_tipo (tamaño);
ALTER TABLE nombre RENAME COLUMN columnaN TO columnaM;
ALTER TABLE nombre RENAME TO nuevo_nombre;-- Usuarios
DROP USER nombre
-- Bases de Datos
DROP DATABASE nombre
-- Tablas
DROP TABLE nombreINSERT INTO tabla (campo1, campo2, …, campoN)
VALUES (valor1, valor2, …., valorN)
INSERT INTO tabla (campo5, campo3, campo1, campo18, …, campoN)
VALUES (valor5, valor1, valor18, …, valorN)
INSERT INTO tabla
VALUES (valor1, valor2, …, valorN)
INSERT INTO tabla
VALUES (DEFAULT, valorN, valorM, …, valorZ)
INSERT INTO tabla
VALUES (valorA1, valorA2, … valorAN),
(valorB1, valorB2, …, valorBN),
(valorC1, valorC2, … valorCN)
INSERT INTO tabla SELECT consulta_aquiUPDATE tabla SET campo1 = valor1, campo2 = valor2, …, campoN = valorN
WHERE campoM = valorM
Where:
WHERE campoM = valorM (=, >, <, <>)
WHERE campoM BETWEEN valor1 AND valor2
WHERE campoM IN (valor1, valor2, …, valorN)
WHERE campoM IN SELECT consulta
WHERE campoM NOT IN…
DELETE FROM tabla WHERE campoN = valorN
Where:
WHERE campoM = campoM (=, >, <, <>)
WHERE campoM BETWEEN valor1 AND valor2
WHERE campoM IN (valor1, valor2, …, valorN)
WHERE campoM IN SELECT consulta
WHERE campoM NOT IN…Clave Primaria
alter table NOMBRETABLA
add constraint NOMBRECONSTRAINT
primary key (CAMPO,...);Clave Foranea
alter table NOMBRETABLA1
add constraint NOMBRERESTRICCION
foreign key (CAMPOCLAVEFORANEA)
references NOMBRETABLA2 (CAMPOCLAVEPRIMARIA);Ejercicio
Grupo 1
PRIMARY KEY constraint
UNIQUE Constraint
ALTERAR PRIMARY KEY
ALTERAR UNIQUE
Grupo 2
FOREIGN KEY
REFERENCES
[ MATCH FULL | MATCH PARTIAL | MATCH SIMPLE ]
DELETE ON [NO ACTION | RESTRICT | CASCADE | SET NULL | SET DEFAULT]
UPDATE ON [NO ACTION | RESTRICT | CASCADE | SET NULL | SET DEFAULT]
ALTERAR FOREIGN
Grupo 3
CHECK Constraint
NOT NULL constraint
ALTERAR CHECK
ALTERAR NOT NULL
Modelar
Crear roles
Asignar permisos
Vistas
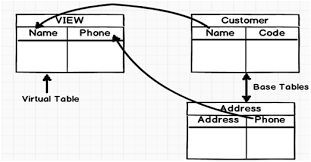
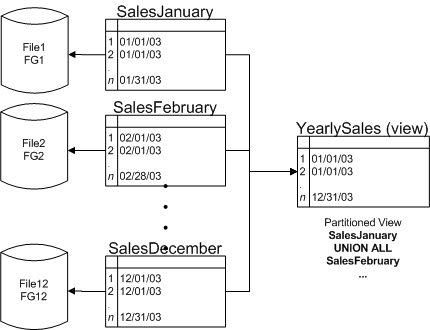
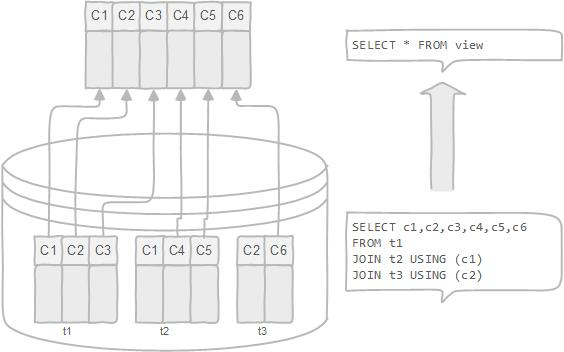
Que es una Vista
CREATE VIEW define una vista de una consulta. La vista no se materializa físicamente. En su lugar, la consulta se ejecuta cada vez que se hace referencia a la vista en un SELECT.
-- Sintaxis:
CREATE [ OR REPLACE ]
VIEW name [ ( column_name [, ...] ) ]
AS queryQue es una Vista
CREATE OR REPLACE VIEW permite que verificar si la vista ya existe con el mismo nombre, de ser así, esta se reemplaza.
Las vistas temporales existen en un esquema especial, por lo que no se puede dar un nombre de esquema al crearla.
El nombre de la vista debe ser distinto del nombre de cualquier otra vista, tabla, secuencia, índice o tabla externa en el mismo esquema.
Ventajas de las vistas
Estas permiten ocultar información: De esta manera estaríamos protegiendo de pronto información importante o que no esta disponible para todos los usuarios.
Permisos sobre tablas: se puede dar al usuario permisos para que solamente pueda acceder a los datos a través de vistas, en lugar de concederle permisos para acceder a ciertos campos, así se protegen las tablas base de cambios en su estructura.
Mejorar el rendimiento: se puede evitar tipear instrucciones repetidamente almacenando en una vista el resultado de una consulta compleja que incluya información de varias tablas.
Tablas que impactamos
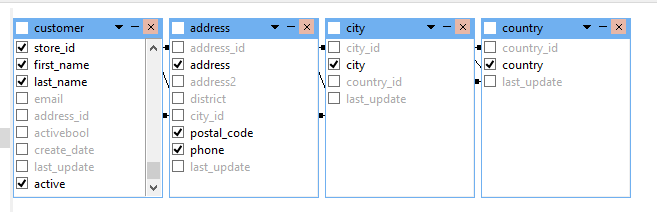
Como queremos mostrarlo
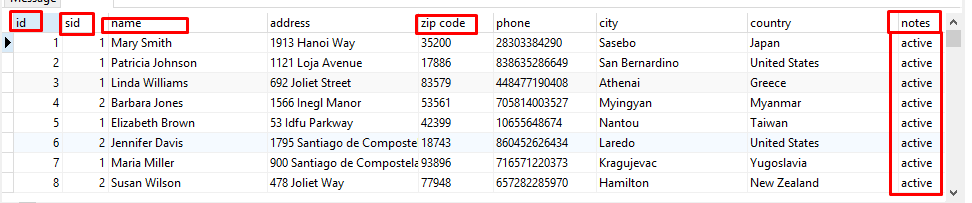
Crear Select
SELECT
cu.customer_id AS id,
cu.store_id AS sid,
(((cu.first_name)::text || ' '::text) || (cu.last_name)::text) AS name,
ad.address,
ad.postal_code AS "zip code",
ad.phone,
ci.city,
co.country,
CASE WHEN cu.activebool
THEN 'active'::text
ELSE ''::text
END AS notes
FROM
customer as cu
INNER JOIN address as ad ON cu.address_id = ad.address_id
INNER JOIN city as ci ON ad.city_id = ci.city_id
INNER JOIN country as co ON ci.country_id = co.country_id
ORDER BY cu.customer_id
Crear vista
CREATE VIEW customer_master AS
SELECT
cu.customer_id AS id,
cu.store_id AS sid,
(((cu.first_name)::text || ' '::text) || (cu.last_name)::text) AS name,
ad.address,
ad.postal_code AS "zip code",
ad.phone,
ci.city,
co.country,
CASE WHEN cu.activebool
THEN 'active'::text
ELSE ''::text
END AS notes
FROM
customer as cu
INNER JOIN address as ad ON cu.address_id = ad.address_id
INNER JOIN city as ci ON ad.city_id = ci.city_id
INNER JOIN country as co ON ci.country_id = co.country_id
ORDER BY cu.customer_id
Llamando a la vista
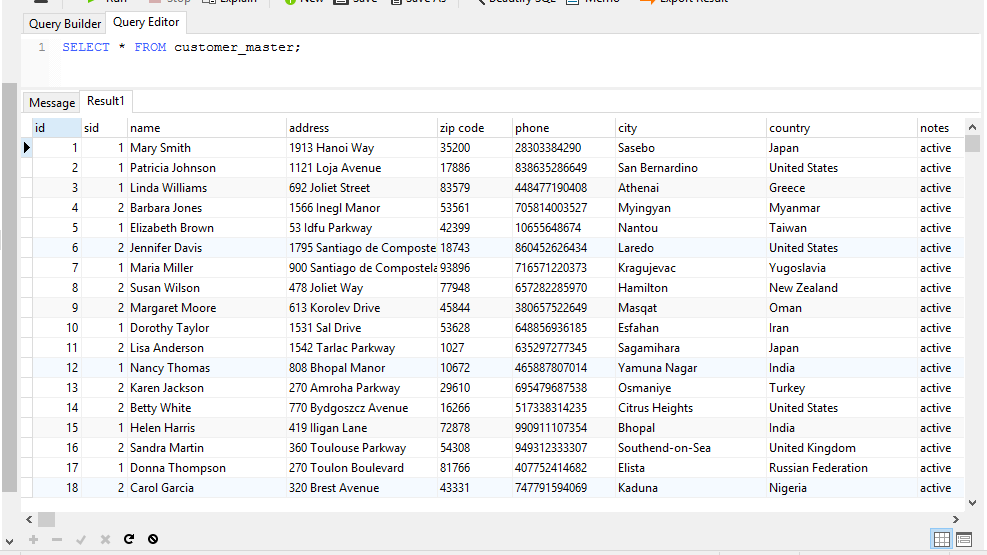
Ejemplo REPLACE
CREATE OR REPLACE VIEW customer_master AS
SELECT
cu.customer_id AS id,
cu.store_id AS sid,
(((cu.first_name)::text || ' '::text) || (cu.last_name)::text) AS name,
ad.address,
ad.postal_code AS "zip code",
ad.phone,
ci.city,
co.country,
CASE WHEN cu.activebool
THEN 'active'::text
ELSE ''::text
END AS notes,
cu.email
FROM
customer as cu
INNER JOIN address as ad ON cu.address_id = ad.address_id
INNER JOIN city as ci ON ad.city_id = ci.city_id
INNER JOIN country as co ON ci.country_id = co.country_id
ORDER BY cu.customer_id
Ejemplo REPLACE
Alterar la vista
ALTER VIEW customer_master RENAME TO customer_info;Alterar la vista
ALTER VIEW customer_master RENAME TO customer_info;Borrar la vista
DROP VIEW IF EXISTS customer_info;Insert, Update y Delete a las vistas
Una vista de PostgreSQL es actualizable cuando cumple con las siguientes condiciones:
La consulta de definición de la vista debe tener exactamente una entrada en la cláusula FROM, que puede ser una tabla u otra vista actualizable.
La consulta de definición no debe contener una de las siguientes cláusulas: GROUP BY, HAVING, LIMIT, OFFSET, DISTINCT, WITH, UNION, INTERSECT y EXCEPT.
La lista de selección no debe contener ninguna función de devolución de conjuntos o cualquier función agregada tal como SUM, COUNT, AVG, MIN, MAX, etc.
Al ejecutar una operación de actualización como INSERT, UPDATE o DELETE, PosgreSQL convertirá esta instrucción en la instrucción correspondiente de la tabla subyacente.
En caso de que tenga una condición WHERE en la consulta de definición de una vista, puede de igual manera actualizar o eliminar las filas que no son visibles a través de la vista.
Los usuarios que realizan operaciones de actualización deben tener el privilegio correspondiente en la vista, pero no necesitan tener privilegios en la tabla subyacente. Sin embargo, los propietarios de vista deben tener privilegios de la tabla subyacente.
Ejemplo
Ciudades de Colombia
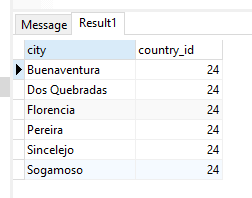
CREATE VIEW colombia_cities AS
SELECT
city,
country_id
FROM
city
WHERE
country_id = 24;
SELECT * FROM colombia_cities;Insertar un registro apuntando a la vista
INSERT INTO colombia_cities (city, country_id)
VALUES('Medellín', 24);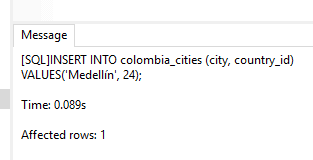
Verificar en la tabla city
SELECT
city,
country_id
FROM
city
WHERE
country_id = 24
ORDER BY last_update DESC;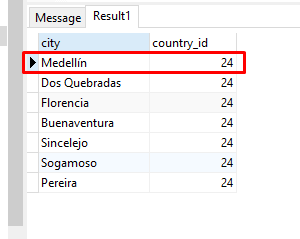
Borrar en la vista
DELETE
FROM
colombia_cities
WHERE
city = 'Medellín';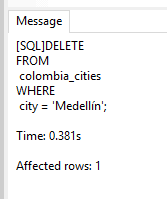
Vistas Materializadas
Triggers
¿Que son?
Un disparador de PostgreSQL es una función que se invoca automáticamente cada vez que se produce un evento, por ejemplo, insertar, actualizar o eliminar.
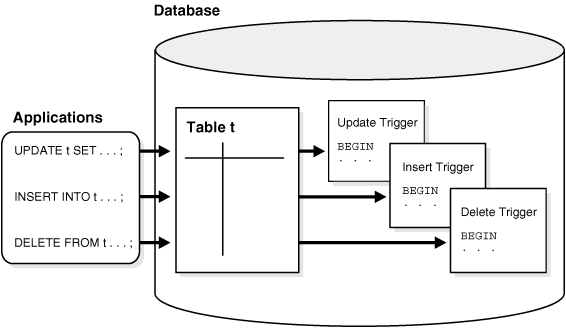
¿Que son?
Un trigger es una función especial definida por el usuario que se une a una tabla. Para crear un nuevo trigger, primero debe definir una función de activación y a continuación, vincularla a una tabla.
La diferencia entre un trigger y una función definida por el usuario es que un disparador se invoca automáticamente cuando se produce un evento.
PostgreSQL proporciona dos tipos principales de triggers: triggers a nivel de fila e instrucción.
¿Que son?
Las diferencias entre los dos son cuántas veces se invoca el trigger y en qué momento. Por ejemplo, si emite una instrucción UPDATE que afecta a 20 filas, el trigger a nivel de fila se invocará 20 veces, mientras que el trigger a nivel de instrucción se invocará 1 vez.
Puede especificar si el trigger se invoca antes o después de un evento. Si el trigger se invoca antes de un evento, puede omitir la operación de la fila actual o incluso cambiar la fila que se está actualizando o insertando. En caso de que el trigger se invoque después del evento, todos los cambios están disponibles para ser usados y verificados (dependiendo de lo que se quiera realizar).
¿Que son?
Los triggers son útiles en caso de que la base de datos sea accedida por varias aplicaciones, y desea mantener la funcionalidad cruzada dentro de la base de datos.
Por ejemplo, si desea mantener el historial de datos sin requerir que la aplicación tenga lógica para comprobar cada evento como INSERT o UDPATE.
Estos también se utilizan para mantener reglas complejas de integridad de datos. Por ejemplo, cuando se agrega una nueva fila a la tabla de clientes, también deben crearse otras filas en tablas de bancos y créditos.
¿Que son?
El principal inconveniente de usar el trigger es que usted debe saber que este existe y entender su lógica con el fin de averiguar los efectos cuando haga cambios a los datos.
Aunque PostgreSQL implementa el estándar SQL, los triggers en PostgreSQL tienen algunas características específicas como:
- PostgreSQL activa el trigger para el evento TRUNCATE.
- PostgreSQL le permite definir el trigger a las instrucciones que afectan las vistas.
- PostgreSQL requiere que defina una función creada por el usuario como la acción del disparador, mientras que el estándar SQL le permite usar cualquier número de comandos SQL.
Para crear un trigger entonces necesitas:
- Crear una función para el trigger con la clausula CREATE FUNCTION
- Vincular esta función de trigger a una tabla utilizando la sentencia CREATE TRIGGER
Para crear un trigger entonces necesitas:
- Crear una función para el trigger con la clausula CREATE FUNCTION
- Vincular esta función de trigger a una tabla utilizando la sentencia CREATE TRIGGER
Crear función de Trigger
CREATE FUNCTION trigger_function()
RETURN trigger AS
logic ...Nota importante
Tenga en cuenta que puede crear funciones de activación utilizando cualquier lenguaje compatible con PostgreSQL. Nosotros usaremos PL/pgSQL.
La función de disparo permite acceder a unas variables importantes a través de una estructura especial llamada TriggerData, que contiene un conjunto de variables locales para trabajar. Por ejemplo, OLD y NEW representan los estados de fila en la tabla antes o después del evento trigger.
PostgreSQL proporciona otras variables locales que comienzan con TG_ como prefijo. Por ejemplo TG_WHEN, TG_TABLE_NAME, etc.
Una vez definida la función de trigger, puede vincularla a acciones específicas en una tabla.
Crear Trigger
CREATE TRIGGER trigger_name {BEFORE | AFTER | INSTEAD OF} {event [OR ...]}
ON table_name
[FOR [EACH] {ROW | STATEMENT}]
EXECUTE PROCEDURE trigger_functionPuede definir el trigger para que se active antes (ANTES) o después del evento (AFTER). El INSTEAD OF se utiliza sólo para INSERT, UPDATE o DELETE en las vistas.
El evento puede ser INSERT, UPDATE, DELETE o TRUNCATE.
PostgreSQL proporciona dos tipos de triggers: a nivel de fila y a nivel de instrucción, que puede especificarse por FOR EACH ROW o FOR EACH STATEMENT.
Crear Trigger
CREATE TRIGGER trigger_name {BEFORE | AFTER | INSTEAD OF} {event [OR ...]}
ON table_name
[FOR [EACH] {ROW | STATEMENT}]
EXECUTE PROCEDURE trigger_functionPuede definir el trigger para que se active antes (ANTES) o después del evento (AFTER). El INSTEAD OF se utiliza sólo para INSERT, UPDATE o DELETE en las vistas.
El evento puede ser INSERT, UPDATE, DELETE o TRUNCATE.
PostgreSQL proporciona dos tipos de triggers: a nivel de fila y a nivel de instrucción, que puede especificarse por FOR EACH ROW o FOR EACH STATEMENT.
Ejemplo Crear BD
CREATE DATABASE api OWNER = postgres;
CREATE TABLE tblEmpresa(
idEmpresa serial PRIMARY KEY NOT NULL,
NIT VARCHAR(13) NOT NULL,
razonSocial VARCHAR(50) NOT NULL,
telefono VARCHAR(15) NOT NULL,
nombreResponsable VARCHAR(40) NOT NULL,
usuario VARCHAR(20) NOT NULL,
contrasena VARCHAR(100) NOT NULL,
correo VARCHAR(30) NOT NULL,
estado BOOLEAN DEFAULT TRUE
);
CREATE TABLE tblEmpleado(
idEmpleado serial PRIMARY KEY NOT NULL,
nombre VARCHAR(40) NOT NULL,
apellido VARCHAR(40) NOT NULL,
fechaNacimiento DATE NOT NULL,
genero CHAR NOT NULL,
usuario VARCHAR(20) NOT NULL,
contrasena VARCHAR(100) NOT NULL,
correo VARCHAR(30) NOT NULL,
estado BOOLEAN DEFAULT TRUE,
idEmpresa INTEGER NULL,
CONSTRAINT tblEmpleado_tblEmpresa_idEmpresa
FOREIGN KEY (idEmpresa)
REFERENCES tblempresa (idEmpresa)
);
CREATE TABLE tblEmpleadoAuditoria(
idEmpleadoAuditoria serial PRIMARY KEY NOT NULL,
idEmpleado int4 NOT NULL,
idEmpresa int4 NOT NULL,
cambioEmpresa timestamp NOT NULL
);Ejemplo Función
CREATE OR REPLACE FUNCTION log_cambio_empresa()
RETURNS trigger AS
$BODY$
BEGIN
IF NEW.idEmpresa <> OLD.idEmpresa THEN
INSERT INTO tblEmpleadoAuditoria(idEmpleado,idEmpresa,cambioEmpresa)
VALUES(OLD.idEmpleado,OLD.idEmpresa,now());
END IF;
RETURN NEW;
END;
$BODY$ LANGUAGE plpgsql;Ejemplo Trigger
CREATE TRIGGER tg_cambio_empresa
BEFORE UPDATE
ON tblempleado
FOR EACH ROW
EXECUTE PROCEDURE log_cambio_empresa();Ejemplo Inserts
-- Empresas
INSERT INTO tblempresa (
nit,
razonsocial,
telefono,
nombreresponsable,
usuario,
contrasena,
correo,
estado
)
VALUES
(
'890904478-6',
'Colanta',
'4455555',
'Juan Peralta',
'colanta1',
'$2a$10$MD3RYBuMBhevj2v/K8lhEuIgx9u6OmT6GEvuu/2DrRJXVnyNi21VG',
'juanperalta@colanta.com',
't'
),
(
'890905988-6',
'Zenu',
'5035826',
'Daniela Posada',
'zenu1',
'$2a$10$MD3RYBuMBhevj2v/K8lhEuIgx9u6OmT6GEvuu/2DrRJXVnyNi21VG',
'dposada@zenu.com',
't'
);
-- Empleados
INSERT INTO tblempleado (
nombre,
apellido,
fechanacimiento,
genero,
usuario,
contrasena,
correo,
estado,
idempresa
)
VALUES
(
'Yhoan',
'Galeano',
'1993-07-05',
'M',
'yhoan1',
'$2a$10$MD3RYBuMBhevj2v/K8lhEuIgx9u6OmT6GEvuu/2DrRJXVnyNi21VG',
'yhoan@colanta.com',
TRUE,
1
),
(
'Jose',
'Lujan',
'1993-02-10',
'M',
'jose2',
'$2a$10$MD3RYBuMBhevj2v/K8lhEuIgx9u6OmT6GEvuu/2DrRJXVnyNi21VG',
'joselujan@colanta.com',
TRUE,
1
);Ejemplo Select
SELECT * FROM tblempresa;
SELECT * FROM tblempleado;
SELECT * FROM tblempleadoauditoria;
Ejemplo Update
UPDATE tblempleado
SET idempresa = 2
WHERE idempleado = 2;
SELECT * FROM tblempresa;
SELECT * FROM tblempleado;
SELECT * FROM tblempleadoauditoria;
Funciones y Procedimientos Almacenados
Sintaxis
CREATE FUNCTION function_name(p1 type, p2 type)
RETURNS type AS
BEGIN
-- logic
END;
LANGUAGE language_name;Ejemplo 1
CREATE FUNCTION incrementar(IN i integer, IN val integer)
RETURNS integer AS
$BODY$
BEGIN
RETURN i + val;
END;
$BODY$
LANGUAGE plpgsql;
SELECT incrementar(10,20);Parámetros
IN, OUT, INOUT, VARIADIC
Parámetros IN
La función obtener_suma() acepta dos parámetros: a, b y devuelve un valor numérico.
De forma predeterminada, el tipo de parámetro en PostgreSQL es IN.
Puede pasar los parámetros IN a la función pero no se pueden recuperar como parte del resultado.
CREATE OR REPLACE FUNCTION obtener_suma(
a NUMERIC,
b NUMERIC)
RETURNS NUMERIC AS
$BODY$
BEGIN
RETURN a + b;
END;
$BODY$
LANGUAGE plpgsql;Parámetros OUT
Los parámetros OUT forman parte de la lista de argumentos de y de igual manera se pueden obtener en el resultado de la función.
CREATE OR REPLACE FUNCTION mayor_menor(
a NUMERIC,
b NUMERIC,
c NUMERIC,
OUT mayor NUMERIC,
OUT menor NUMERIC)AS
$BODY$
BEGIN
mayor := GREATEST(a,b,c);
menor := LEAST(a,b,c);
END;
$BODY$
LANGUAGE plpgsql;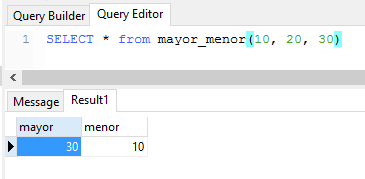
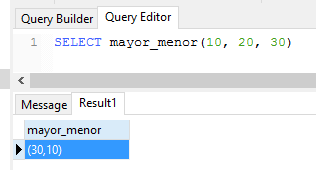
Parámetros INOUT
El parámetro INOUT es la combinación de los parámetros IN y OUT. Significa al llamar la función podemos pasar el valor. Dentro de la función podrá cambiar el argumento y lo devuelve como parte del resultado.
CREATE OR REPLACE FUNCTION elevar_cuadrado(
INOUT a NUMERIC)AS
$BODY$
BEGIN
a := a * a;
END;
$BODY$
LANGUAGE plpgsql;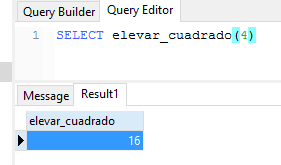
Parámetros VARIADIC
Una función de PostgreSQL puede aceptar un número variable de argumentos. Esto con una condición, que todos los argumentos tengan el mismo tipo de dato. Los argumentos se pasan a la función como una matriz.
CREATE OR REPLACE FUNCTION sum_avg(
VARIADIC lista NUMERIC[],
OUT total NUMERIC,
OUT average NUMERIC) AS
$BODY$
BEGIN
SELECT SUM(lista[i]) INTO total
FROM generate_subscripts(lista, 1) g(i);
SELECT AVG(lista[i]) INTO average
FROM generate_subscripts(lista, 1) g(i);
END;
$BODY$
LANGUAGE plpgsql;
-- Llamar la función
SELECT *
FROM
sum_avg(VARIADIC ARRAY[0,10,20,30,40,50,60])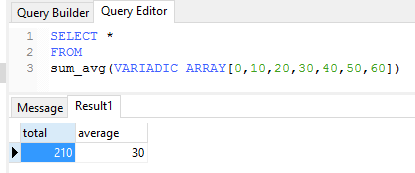
Sobrecarga de Funciones
CREATE OR REPLACE FUNCTION sobrecarga(
a INTEGER,
b INTEGER DEFAULT 5
)
RETURNS INTEGER AS $BODY$
DECLARE
total integer;
BEGIN
total := a * b;
RETURN total;
END;
$BODY$
LANGUAGE plpgsql;
SELECT sobrecarga(4);
SELECT sobrecarga(4, 20);Como vemos en la declaración de la función, podemos declarar los parámetros de entrada y asignarles valores por defecto.
Esto permite que a la hora de realizar el llamado de la función podamos omitir el valor que tiene por defecto.
Los parámetros alternativos siempre van después de los obligatorios.
Retornar Tablas
Return Table(columna tipo, ...) y RETURN QUERY SELECT columna
CREATE OR REPLACE FUNCTION SP_listarEmpleados()
RETURNS TABLE (
idEmpleado INTEGER,
nombreCompleto VARCHAR(80),
fechaNacimiento TIMESTAMP,
genero CHAR,
usuario VARCHAR(20),
correo VARCHAR(30),
estado BOOLEAN,
idEmpresa INTEGER,
razonSocial VARCHAR(50)
)
AS $BODY$
BEGIN
RETURN QUERY SELECT
e.idEmpleado, (e.nombre || ' ' || e.apellido)::VARCHAR(80), e.fechaNacimiento::TIMESTAMP, e.genero,
e.usuario, e.correo, e.estado, e.idEmpresa, emp.razonSocial
FROM
tblempleado AS e
INNER JOIN tblempresa emp
ON(e.idEmpresa = emp.idEmpresa)
ORDER BY e.idEmpleado;
END; $BODY$
LANGUAGE 'plpgsql';Return Table(columna tipo, ...) y RETURN NEXT LOOP
CREATE OR REPLACE FUNCTION SP_listarEmpleados2() RETURNS TABLE (
idEmpleado INTEGER,
nombreCompleto VARCHAR (80),
fechaNacimiento TIMESTAMP,
genero CHAR,
usuario VARCHAR (20),
correo VARCHAR (30),
estado BOOLEAN,
idEmpresa INTEGER,
razonSocial VARCHAR (50)
) AS $BODY$
DECLARE
var_r record;
BEGIN
FOR var_r IN (
SELECT
e.idEmpleado,
(e.nombre || ' ' || e.apellido) :: VARCHAR (80) as nombreCompleto,
e.fechaNacimiento :: TIMESTAMP as fechaNacimiento,
e.genero,
e.usuario,
e.correo,
e.estado,
e.idEmpresa,
emp.razonSocial
FROM
tblempleado AS e
INNER JOIN tblempresa emp ON (e.idEmpresa = emp.idEmpresa)
ORDER BY
e.idEmpleado
) LOOP
idEmpleado := var_r.idEmpleado;
nombreCompleto := var_r.nombreCompleto;
fechaNacimiento := var_r.fechaNacimiento;
genero := var_r.genero;
usuario := var_r.usuario;
correo := UPPER(var_r.correo);
estado := var_r.estado;
idEmpresa := var_r.idEmpresa;
razonSocial := var_r.razonSocial;
RETURN NEXT;
END LOOP ;
END ; $BODY$ LANGUAGE 'plpgsql';Return SETOF [table | view] y RETURN QUERY
CREATE OR REPLACE FUNCTION SP_listarEmpleados3 ()
RETURNS SETOF tblempleado
AS
$BODY$
BEGIN
RETURN QUERY SELECT *
FROM tblempleado
ORDER BY idEmpleado;
END;
$BODY$
LANGUAGE 'plpgsql';
SELECT * FROM SP_listarEmpleados3 ()Más Ejemplos
Enlace a tema.sql
Ejercicio Real Time App
Configurar npm
//En el SENA
npm config set proxy http://proxy2.sena.edu.co:80
npm config set https-proxy http://proxy2.sena.edu.co:80
//En la casa
npm config rm proxy
npm config rm https-proxyAlgunos comandos
npm init
"start": "nodemon index.js",
npm i nodemon --save-dev
npm i express --save
npm i massive --save
npm i pg --save
npm i body-parser --save
npm i bcrypt-nodejs --save
npm i socket.io --saveTrigger Notify
CREATE OR REPLACE FUNCTION notify_trigger() RETURNS trigger AS $$
DECLARE
channel_name varchar DEFAULT ('changes_' || TG_TABLE_NAME);
BEGIN
IF TG_OP = 'INSERT' THEN
PERFORM pg_notify(channel_name, '{"id": "' || NEW.idempleado || '"}');
RETURN NEW;
END IF;
IF TG_OP = 'DELETE' THEN
PERFORM pg_notify(channel_name, '{"id": "' || OLD.idempleado || '"}');
RETURN OLD;
END IF;
IF TG_OP = 'UPDATE' THEN
PERFORM pg_notify(channel_name, '{"id": "' || NEW.idempleado || '"}');
RETURN NEW;
END IF;
END;
$$ LANGUAGE plpgsql;
DROP TRIGGER IF EXISTS tg_cambios_empleado on tblempleado;
CREATE TRIGGER tg_cambios_empleado AFTER INSERT OR UPDATE OR DELETE ON tblempleado
FOR EACH ROW
EXECUTE PROCEDURE notify_trigger();View
CREATE OR REPLACE VIEW vw_listaEmpleados AS
SELECT
e.idEmpleado, (e.nombre || ' ' || e.apellido)::VARCHAR(80), e.fechaNacimiento::TIMESTAMP, e.genero,
e.usuario, e.correo, e.estado, e.idEmpresa, emp.razonSocial
FROM
tblempleado AS e
INNER JOIN tblempresa emp
ON(e.idEmpresa = emp.idEmpresa)
ORDER BY e.idEmpleado;
SELECT * FROM vw_listaEmpleados;