JavaScript正则表达式
正则表达式是使用单个字符串来描述、匹配一系列符合某个句法规则的字符串
什么是正则表达式
-
JavaScript通过内置对象RegExp支持正则表达式
RegExp对象
-
有两种方法实例化RegExp对象
- 构造函数
- 字面量
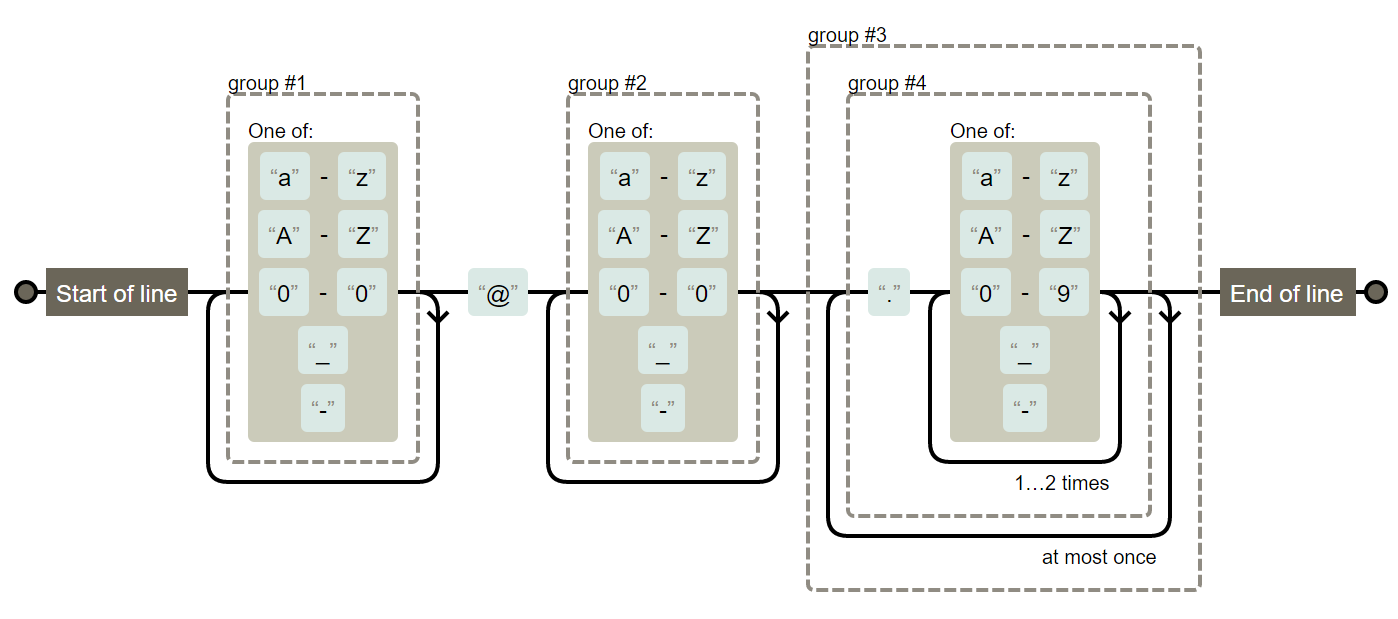
^([a-zA-Z0-0_-])+@([a-zA-Z0-0_-])+((\.[a-zA-Z0-9_-]{2,3}){1,2})$
RegExper
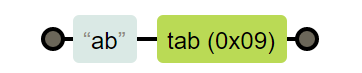
var reg = /\bis\b/g;
字面量
var reg = new RegExp('\\bis\\b', 'g');
构造函数
-
g: global 全文搜索,不添加搜索到第一个匹配停止
修饰符
-
i: ignore case 忽略大小写,默认大小写敏感
-
m: multi-line 多行搜索
-
正则表达式由两种基本类型字符组成:
元字符
- 原义文本字符
- 元字符
-
元字符是在正则表达式中有特殊含义的非字母字符
- * + ?$ ^ . | \ ( ) { } [ ]
非打印字符
| 字符 | 含义 |
|---|---|
| \t | 水平制表符 |
| \v | 垂直制表符 |
| \n | 换行符 |
| \r | 回车符 |
| \0 | 空字符 |
| \f | 换页符 |
| \cX | Ctrl + X |
字符类
-
一般情况下正则表达式一个字符对应字符串一个字符
- 表达式 ab\t 的含义是
字符类
-
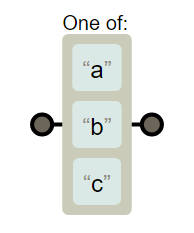
使用元字符[]来构建字符类
- 所谓类是指符合某些特征的对象,不是特指某个字符
- 表达式 [abc] 把字符 a 或 b 或 c 归为一类
字符类取反
-
使用元字符^来构建反向类/负向类
- 反向类匹配不属于某类的字符
- 表达式 [^abc] 把字符 a 或 b 或 c 归为一类
范围类
-
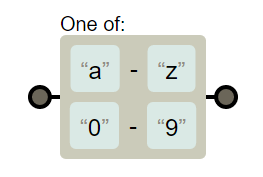
使用元字符-来构建范围类
- 使用 [a-z] 表示从 a 到 z 的任意字符
- 这是一个闭区间
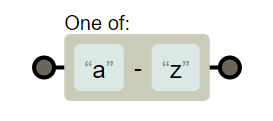
- 多个范围可以连着写 [a-z0-9]
范围类
-
使用元字符-来构建范围类
- 使用 [a-z] 表示从 a 到 z 的任意字符
- 这是一个闭区间
- 多个范围可以连着写 [a-z0-9]
预定义类
| 字符 | 等价类 | 含义 |
|---|---|---|
| . | [^\r\n] | 除了回车换行 |
| \d | [0-9] | 数字 |
| \D | [^0-9] | 非数字 |
| \s | [\t\n\x0B\f\r] | 空白符 |
| \S | [^\t\n\x0B\f\r] | 非空白符 |
| \w | [a-zA-Z_0-9] | 单词字符(字母数字下划线) |
| \W | [^a-zA-Z_0-9] | 非单词字符 |
边界
| 字符 | 含义 |
|---|---|
| ^ | 作为开头 |
| $ | 作为结束 |
| \b | 单词边界 |
| \B | 非单词边界 |
量词
匹配一个连续出现 10次 数字的字符串
\d\d\d\d\d\d\d\d\d\d
量词
| 字符 | 含义 |
|---|---|
| ? | 出现0次或1次 |
| + | 出现1次或多次 |
| * | 出现0次或多次 |
| {n} | 出现n次 |
| {n,m} | 出现n到m次(闭区间) |
| {n,} | 出现至少n次 |
贪婪模式
\d{3-6}
12345678
非贪婪模式
-
尽可能少地匹配
-
在量词后加上 ?
'1234567890'.match(/\d{3,5}?/g);
['123', '456', '789']
分组
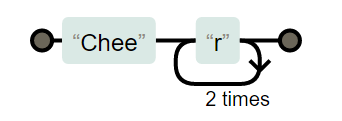
字符串 Cheer 连续出现 3次 的情况
Cheer{3}
分组
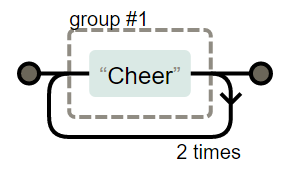
使用 ( ) 可以达到分组的功能,使量词作用于分组
(Cheer){3}
或
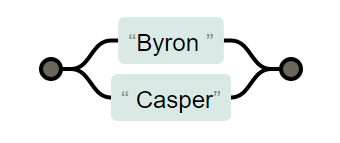
使用 | 可以达到或的效果
Byron | Casper
Byr(on | Ca)sper
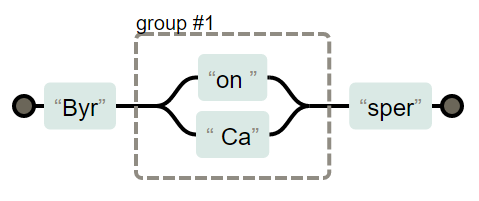
捕获分组
2016-09-24 替换成 09/24/2016
'2016-09-24'.replace(/(\d{4})-(\d{2})-(\d{2})/g, '$2/$3/$1');
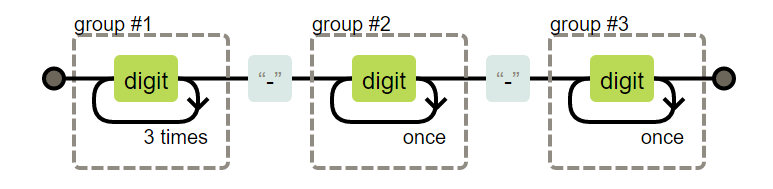
忽略分组
不希望捕获某些分组,在分组内加上 ?:
(?:Byron).(Casper)
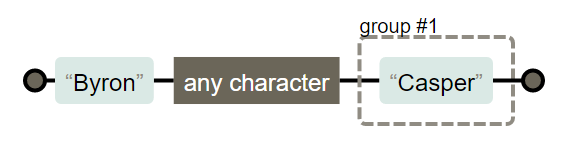
前瞻
-
正则表达式从文本头部开始匹配,文本尾部方向称为“前”
-
前瞻就是在匹配到规则的时候,向前检查是否满足断言
-
后顾方向相反,JavaScript不支持后顾
-
符合和不符合特定断言成为 正向 和 负向 匹配
前瞻
| 名称 | 正则 | 含义 |
|---|---|---|
| 正向前瞻 | exp(?=assert) | 匹配exp并且满足assert |
| 负向前瞻 | exp(?!assert) | 匹配exp并且不满足assert |
‘a234v8’.replace(/\w(?=\d)/g, 'X')
RegExp.prototype.test(str)
-
用于测试参数字符串中是否存在匹配正则表达式的字符串
-
如果存在则返回 true 否则返回 false
RegExp.prototype.exec(str)
-
使用正则表达式模式对字符串进行搜索,并更新RegExp实例的index和lastIndex以反映匹配结果
-
如果没有匹配的文本则返回 null,否则返回结果数组
- 第一个元素是与正则表达式匹配的文本
- 第二个元素是与正则表达式第一个分组(如果有的话)匹配的文本
- 第二个元素是与正则表达式第二个分组(如果有的话)匹配的文本,以此类推
String.prototype.search(str | reg)
-
search方法用于在字符串中检索制定的字符串,或指定正则表达式匹配的字符串
方法返回第一个匹配结果的index,查找不到返回 -1
-
方法会忽略 g 标志,总是从字符串的开始进行检索,并返回第一个匹配结果的index
String.prototype.match(reg)
-
match方法将检索字符串,以找到一个或多个与regExp匹配的文本
-
regExp是否有 g 标志对结果影响很大
match非全局匹配
-
返回数组的第一个元素是第一个匹配的文本,而其余元素存放的是正则分组匹配的文本
-
返回的数组还有 2 个对象属性
- index 匹配文本的起始字符在字符串的位置
- input 调用match方法的字符串
match全局匹配
-
没有找到任何匹配的文本,则返回 null
-
返回的数组中存放所有匹配的文本,没有分组匹配的文本,也没有 index 和 input 属性
-
如果找到了一个或多个匹配文本,则返回一个数组
String.prototype.split(str | reg)
-
使用 split 方法把字符串分割为字符串数组
-
在复杂情况下可以使用正则表达式分割
String.prototype.replace
-
String.prototype.replace(str | reg, replacement)
-
String.prototype.replace(reg, replacer)
- replacer会在每次匹配替换时调用
-
function replacer(match, p1, p2, p3..., index, string)