Pronominal Coreference Resolution for Proper Nouns using Hobbs Algorithm
Eugene Kostrov
What is coreference resolution?
What is coreference resolution?
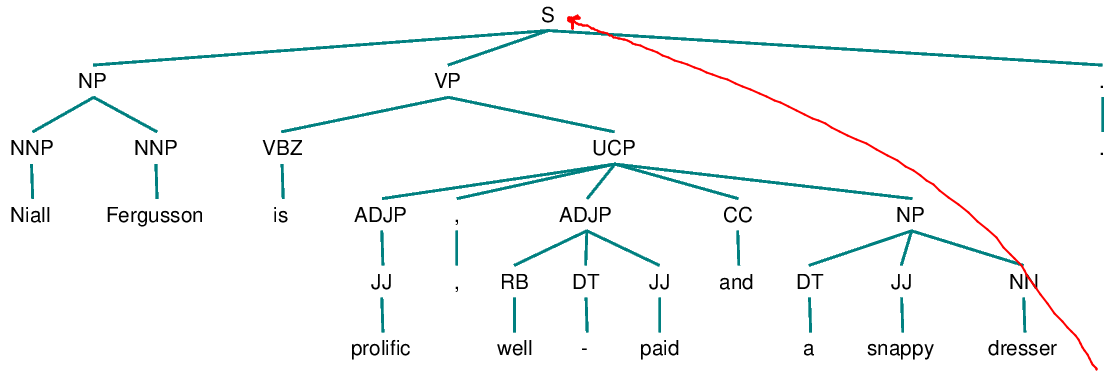
Niall Ferguson is prolific, well-paid and a snappy dresser. Stephen Moss hates him.
What is coreference resolution?
Niall Ferguson is prolific, well-paid and a snappy dresser. Stephen Moss hates him.
- Identify all entities in the text
What is coreference resolution?
- Identify all entities in the text
- Link all mentions to corresponding entities
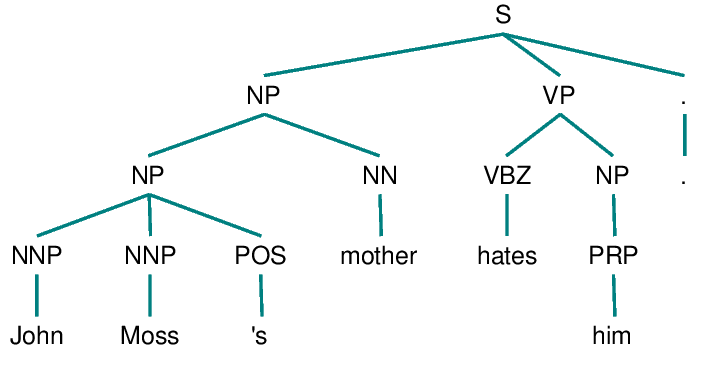
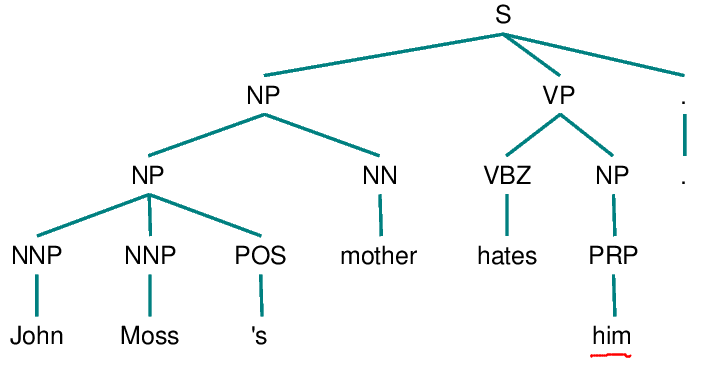
Niall Ferguson is prolific, well-paid and a snappy dresser. Stephen Moss hates him.
Coreferences everywhere
Why do we need it?
- Information extraction
- Full text understanding
- Question answering
- Summarization
- Machine translation
- Dialogue systems
Winograd Schema Challenge
Designed as an improvement to Turing test
Winograd Schema Challenge
Designed as an improvement to Turing test
The trophy would not fit in the brown suitcase because it was too big. What was too big?
Winograd Schema Challenge
Designed as an improvement to Turing test
The trophy would not fit in the brown suitcase because it was too big. What was too big?
The trophy would not fit in the brown suitcase because it was too small. What was too small?
Machine Translation


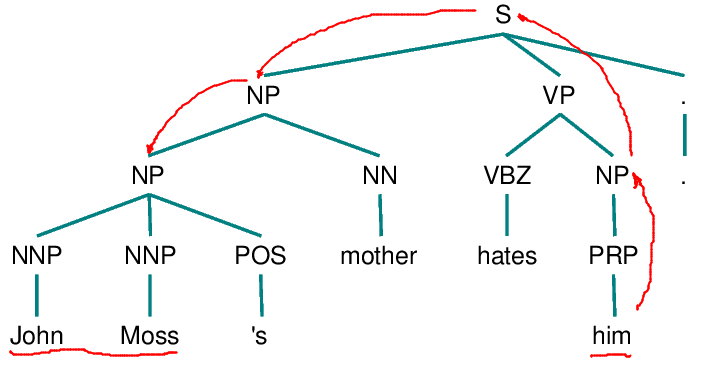
Hobbs algorithm
Hobbs algorithm
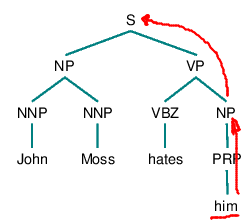
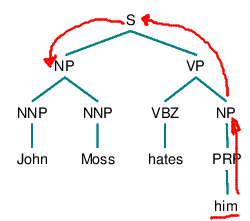
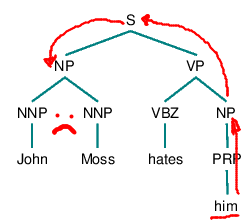
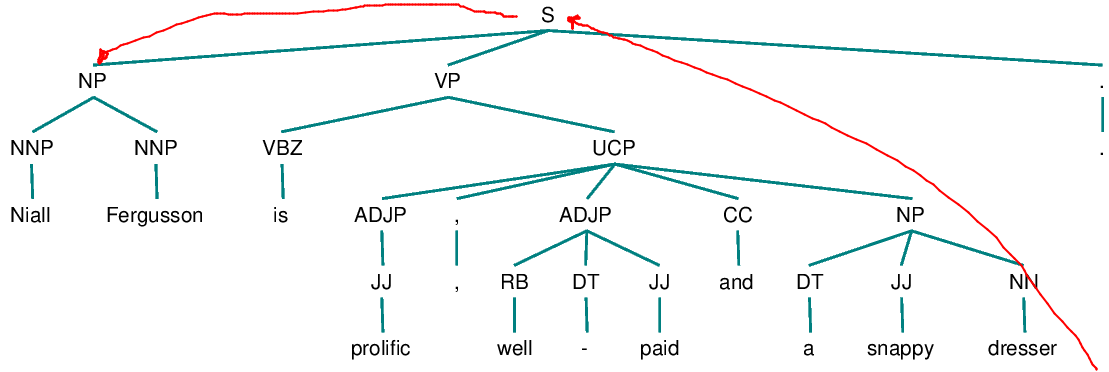
1. Begin at the NP node immediately dominating the pronoun
2. Go up the tree to the first NP or S node encountered. Call this node X and the path used to reach it p.
3. Traverse all branches below node X to the left of path p in a left-to-right, breadth-first fashion. Propose as an antecedent any NP node that is encountered which has an NP or S node between it and X.
4. If node X is the highest S node in the sentence, traverse the surface parse trees of previous sentences in the text in order of recency, the most recent first; each tree is traversed in a left-to-right, breadth-first manner, and when an NP node is encountered, it is proposed as an antecedent. If X is not the highest S node in the sentence, continue to step 5.
...
Hobbs algorithm
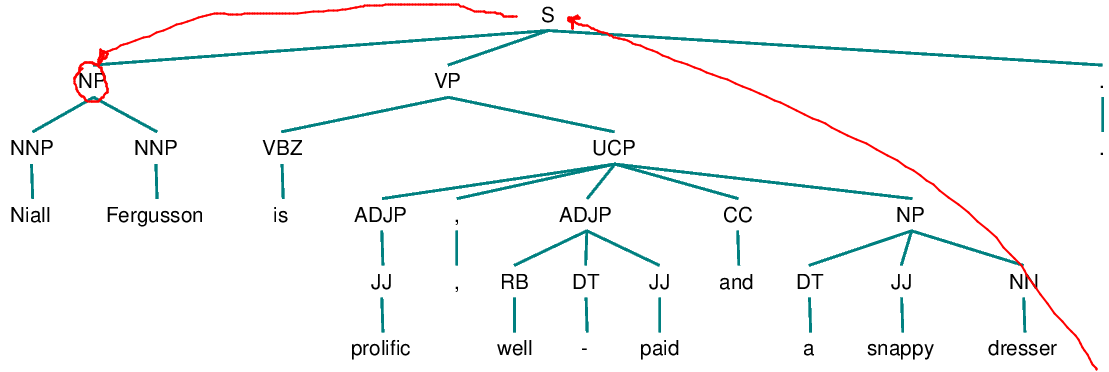
5. From node X, go up the tree to the first NP or S node encountered. Call this new node X, and call the path traversed to reach it p.
6. If X is an NP node and if the path p to X did not pass through the Nominal node that X immediately dominates, propose X as the antecedent.
7. Traverse all branches below node X to the left of path p in a left-to-right, breadth-first manner. Propose any NP node encountered as the antecedent.
8. If X is an S node, traverse all the branches of node X to the right of path p in a left-to-right, breadth-first manner, but do not go below any NP or S node encountered. Propose any NP node encountered as the antecedent.
9. Go to step 4.
Hobbs algorithm
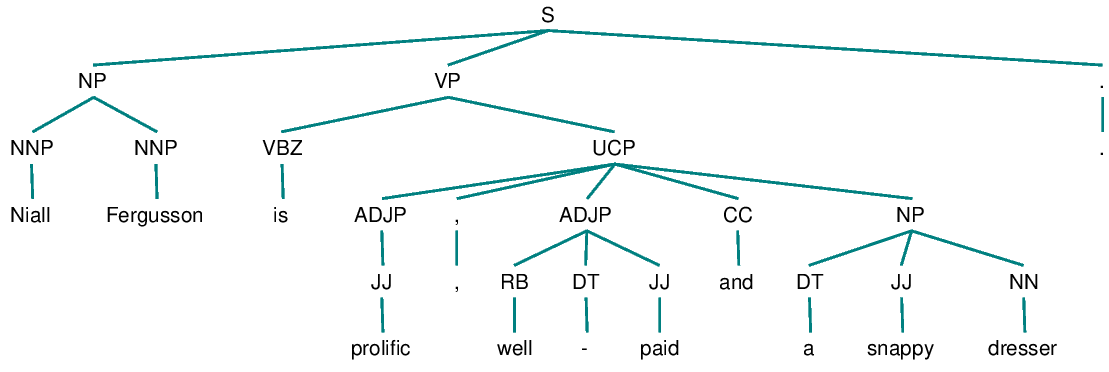
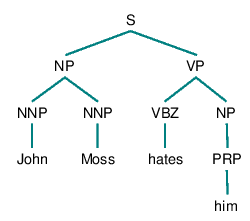
Hobbs algorithm
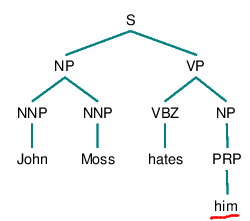
Hobbs algorithm
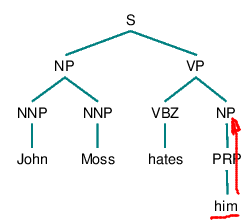
Hobbs algorithm
Hobbs algorithm
Hobbs algorithm
Hobbs algorithm
Hobbs algorithm
Hobbs algorithm
Hobbs algorithm
Hobbs algorithm
Hobbs algorithm
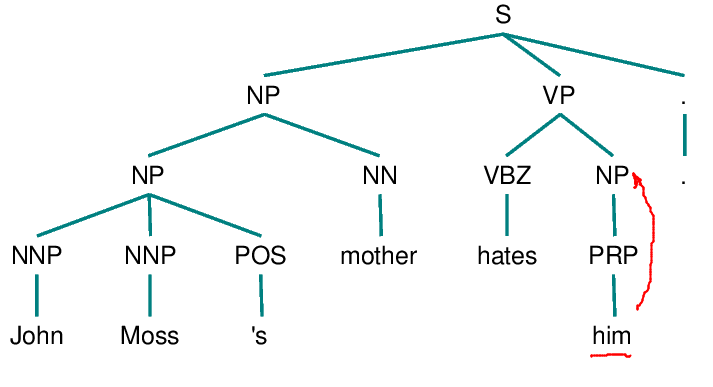
Hobbs algorithm
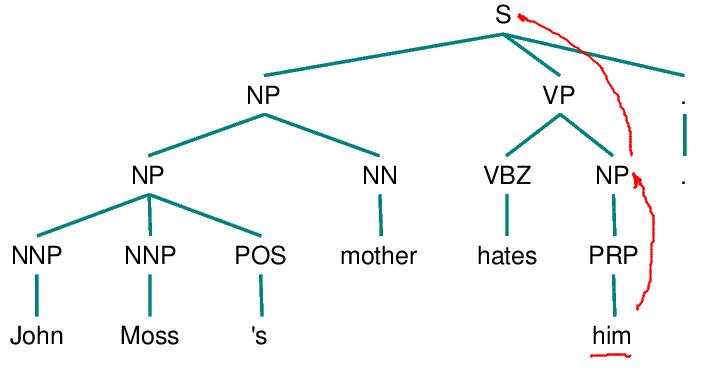
Hobbs algorithm
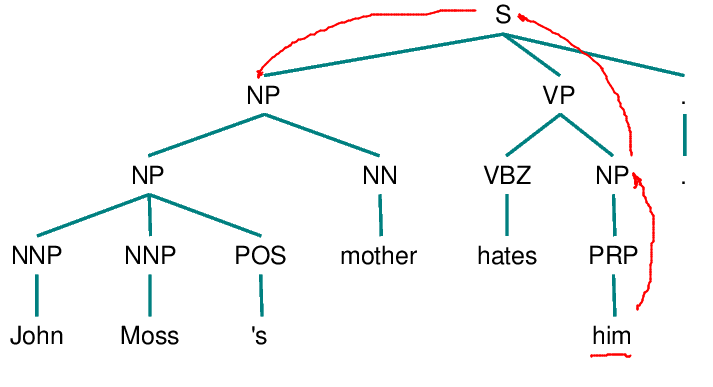
Hobbs algorithm
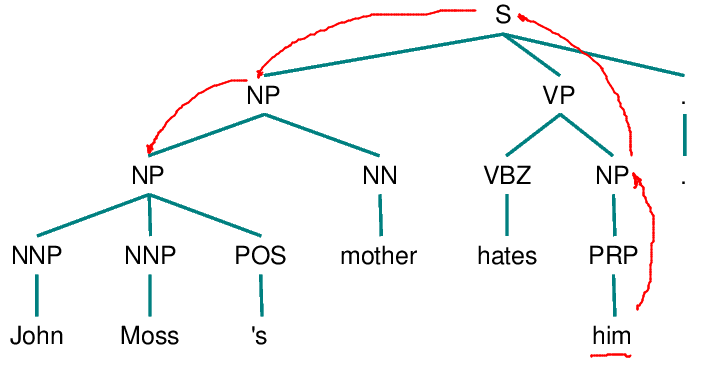
Hobbs algorithm
Dataset
GAP Coreference Dataset - https://github.com/google-research-datasets/gap-coreference
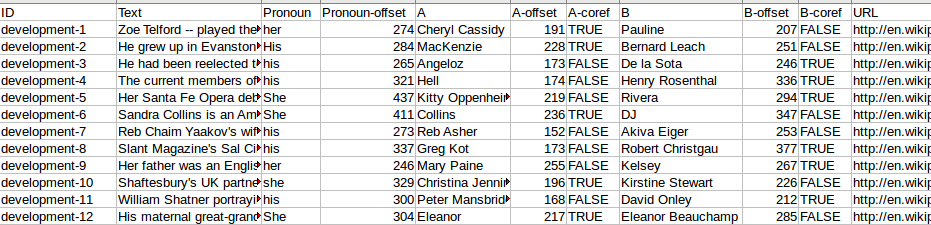
Average tokens in text = ~71.5
Average sentences in text = ~2
Dataset

Results
| Precision | Recall | F1 | |
|---|---|---|---|
| Hobbs | 0.153 | 0.156 | 0.155 |
| Hobbs CNF | 0.087 | 0.088 | 0.087 |
| AllenNLP | 0.340 | 0.386 | 0.356 |
Tools
- Berkeley Neural Parser
- spacy / nltk
Pros / Cons
Pros:
- No need for data
- If it doesn't work - you can track why
- Good for short sentences (dialogs, news)
Cons:
- Works bad where context matters (Winograd)
- It gives neither indication that it failed nor the reason
- Will never be perfect
- ~50 y.o.
Improvements
- Match pronoun gender to antecedent's one
- Introducing animacy
- Make use of special labels like SBARQ, SQ, SINV, etc.
- Use as a feature in more advanced systems