Seminar:
Data Collection
Challenges, Concerns, &
A little bit about Machine Learning
Yu-Chang Ho (Andy)
Oct. 17, 2019
Oct. 22, 2019
UC Davis
First of all, how was it?
Did you try out the challenge?
Any questions?
Let's go through the solutions
I prepared for you guys
Back to
web-scraping
Still remember how does it work?
Web Crawler
Content Parsing
Basic Cleaning
World-wide Web (WWW)
Web-scraper


API or Web-scraping?
| API | Web-scraping |
|---|---|
| Granted to use the data | Not grant to use the data |
| No need to make a parser | Need to design the parser for the webpage source |
| No need to clean the data | Need to make sure the data obtained is correct |
|
Easy to use (as a programmer perspective), but not always provided |
Some companies can prevent the data from being scraped |
| Have rules to follow, so not a security issue for the website | A kind of attack to their service! |
We told about BeautifulSoup4,
how about Selenium?
It's a browser automation software, which is mainly designed for testing.
Because of the feature it has, we are also able to perform web-scraping using it.
The problem, is the performance!
What Should be Aware of When Collecting Data?
- Terms & Conditions provided by the website.
- The ability of the server of the website. (How many requests at the same time?)
- Random wait time.
- The network status/speed
- Your computer could crash!!! (Heavy loading......)

Our Infrastructure
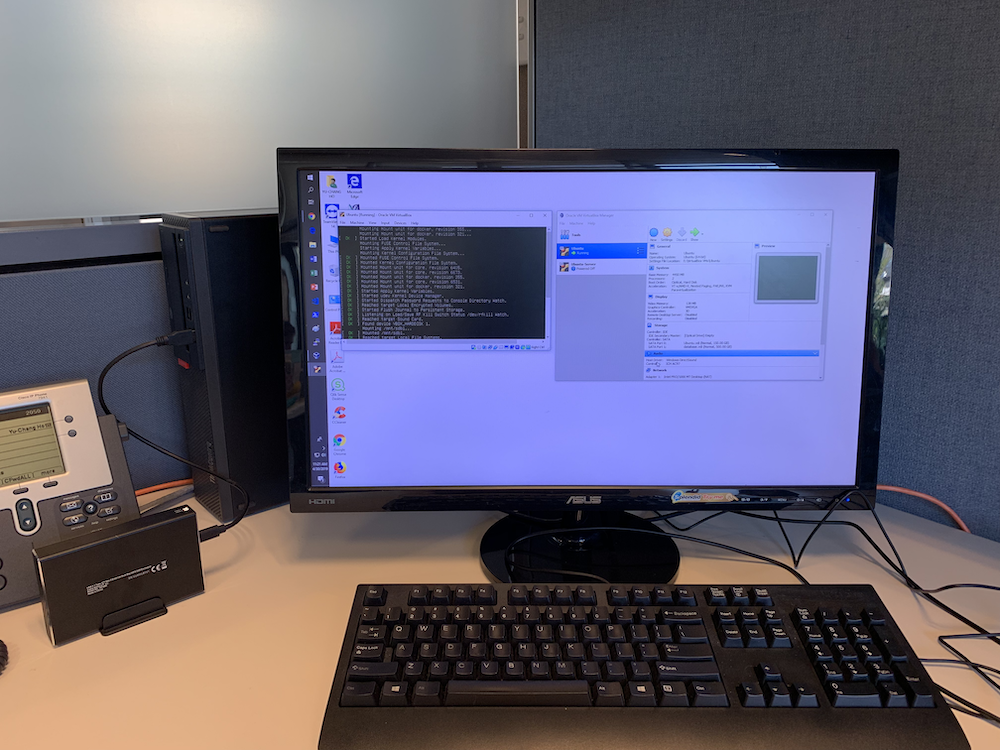
Challenges?
-
Infrastructure😝 - Multi-threaded programming
- Been blocked by the target site for doing the scraping
- Coffee Shop or Public WiFi
- Program errors handling
- Data cleaning
Time-consuming!!!
Recommended Technical Skills for Web-scraping
-
Software Development
- Multi-threaded programming
- Knowledge of Databases (Relational, NoSQL)
- Server Management (Linux, Windows)



Architecture
Database
Multi-threaded Crawler
Multi-threaded Parser
Basic Data Cleaning
Normalization

Visualization!
Web-scraper
Error Handling & Retry
De-dupe
Aggregation


I Performed a Small Practice regarding Image Recognition
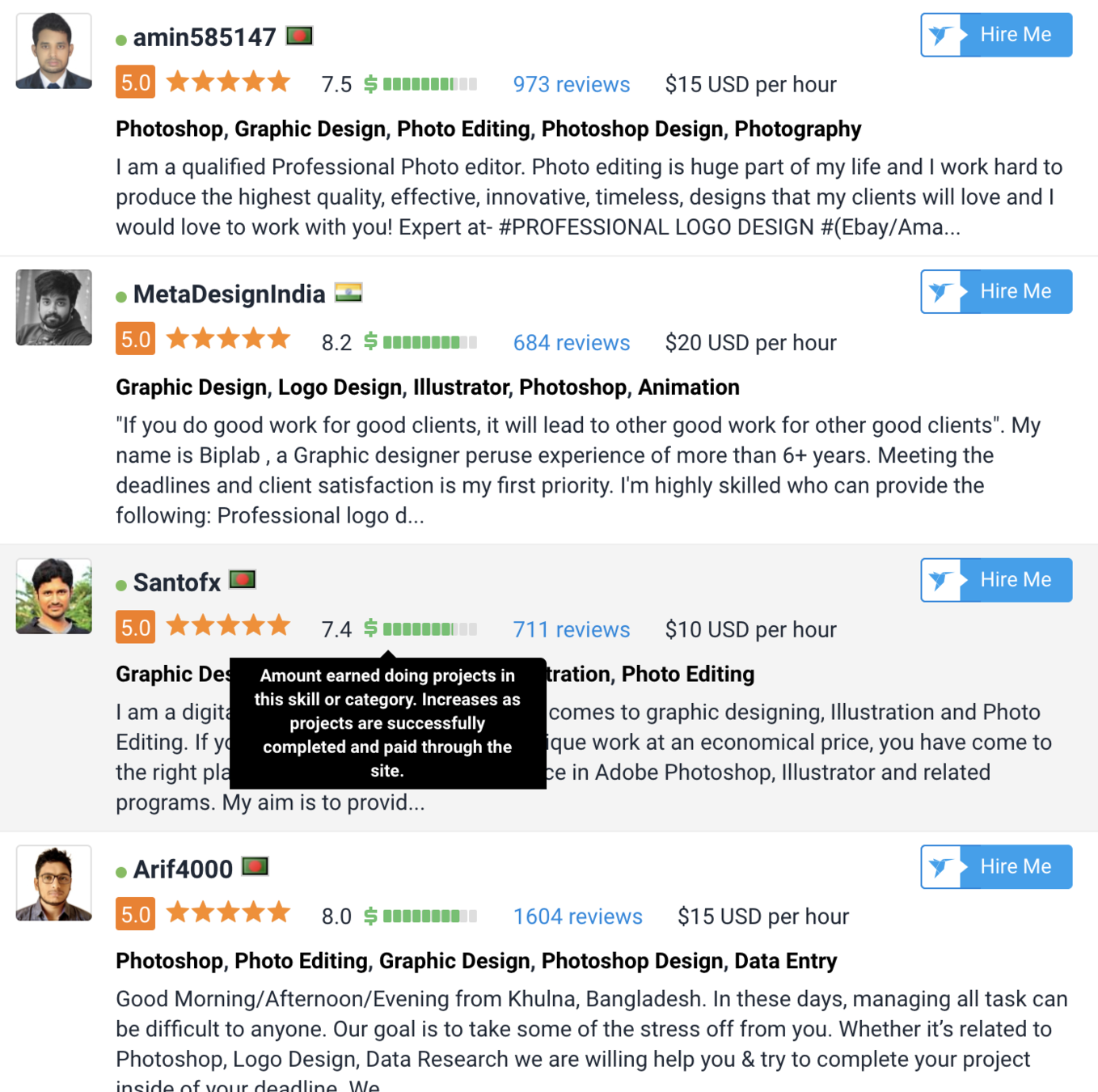
Image Recognition is one of the Applications of Machine Learning
Male
Female
Unkown
Supervised Learning!
Provides categorized dataset beforehand as a "Training Dataset" for model training.
After the model is trained, feed the dataset you would like to retrieve the parsing result based on the trained model.
Tried to increase the accuracy for the identification.
Unsupervised Learning
No "Training Dataset" at all. Given examples and let the machine figured out the "pattern" or "rule" itself.
$ python retrain.py --img_dir=../training_imgs
# Wait until the process complete.Perform model retraining
Perform identification
$ python label_image.py \
--graph=/tmp/output_graph.pb --labels=/tmp/output_labels.txt \
--input_layer=Placeholder \
--output_layer=final_result \
--image ./*.jpg
# Wait until the process complete.
Official Jupyter Notebook Tutorial
Welcome to visit my GitHub repository!
https://github.com/hippoandy/UCDavis_CMN189_F2019_Seminar_Webscraping
My contact e-mail: ycaho@ucdavis.edu