Deep Learning and its applications in NLP
Yugal Sharma
https://yugrocks.github.io/
Linkedin: linkedin.com/in/yugal-sharma-62855713a/
Outline
- What is Deep Learning (Overview)
- Introduction to Natural Language Processing (NLP)
- Basic Components: NLU and NLG
- POS tagging
- Information Extraction
- Language Modeling
- Word Embeddings : Word2Vec
- Some applications of NLP - (And how Deep Learning has invaded NLP)
- Text Classification
- Conversational Interfaces (NLU + NLG)
- Machine Translation
- Text summarization
What is Deep Learning
- It is a subfield of machine learning concerned with algorithms inspired by the structure and function of the brain called artificial neural networks.
- The word "Deep" describes the development of large artificial neural networks.

Why Deep Learning
As we construct larger neural networks and train them with more and more data, their performance continues to increase. This in contrast to other Machine Learning techniques in which the performance reaches a plateau.
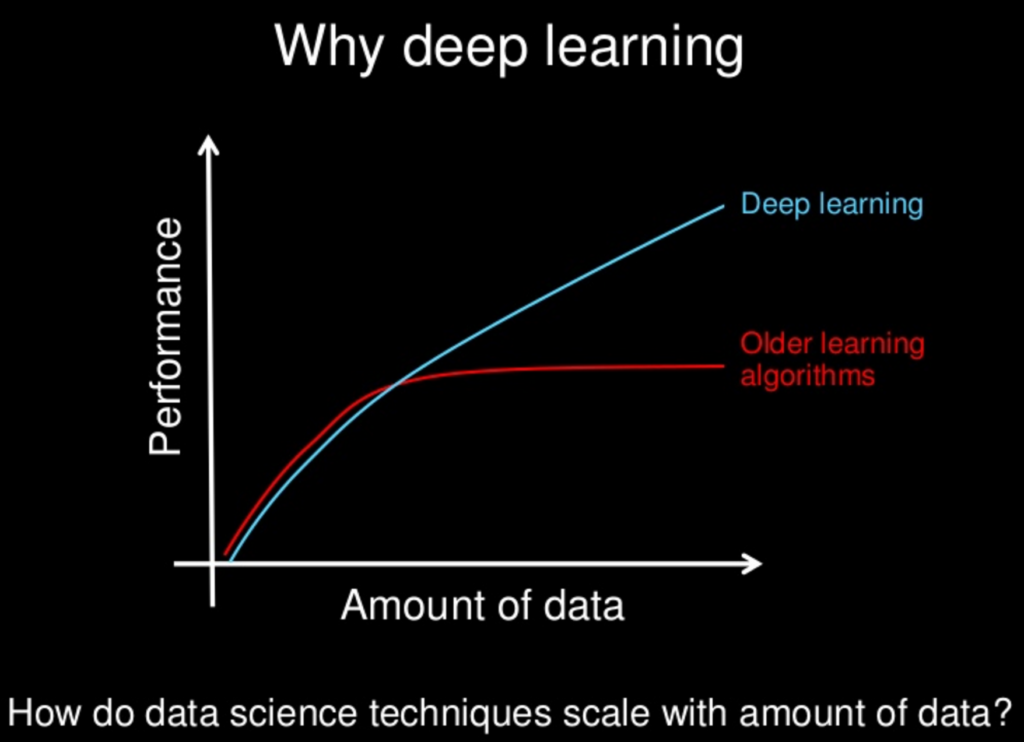
Slide by andrew Ng
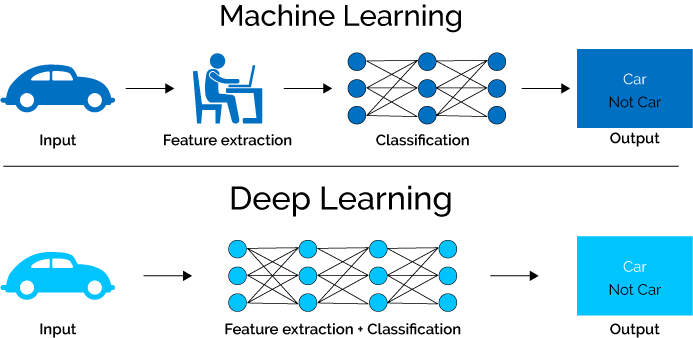
This picture summarizes the main difference between ML and Deep Learning
What is an Artificial Neural Network
- Neural Networks are powerful learning algorithms that are loosely inspired by the brain.
- They are capable of learning complex, hidden representations of the input data.
- Simply put- they take inputs, perform a complex computation and spit out the required prediction about the input data.
- A typical neural network has anything from a few dozen to hundreds, thousands, or even millions of artificial neurons also called units arranged in a series of layers, each of which connects to the layers on either side.
-
Each neuron in a layer:
- Takes the inputs from previous layer.
- Calculates the weighted summation of the input.
- Applies some function (like sigmoid) to the weighted sum.
- Progresses the calculated value to the next layer of neurons
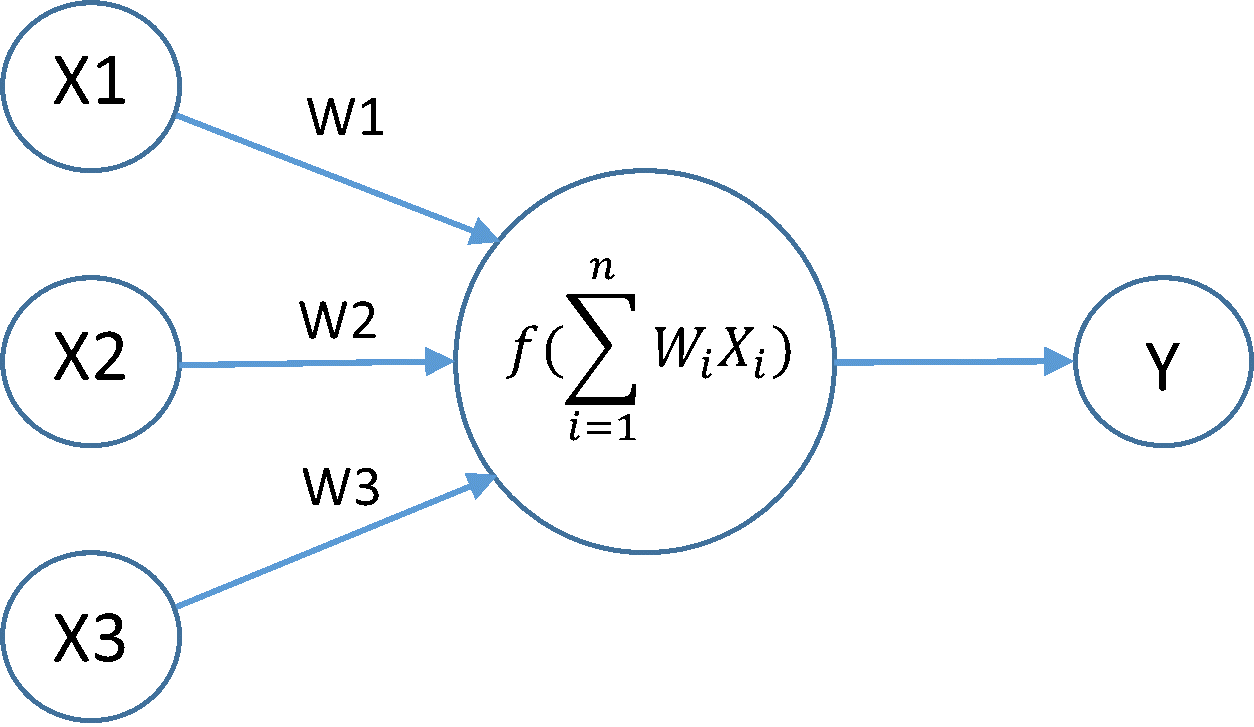
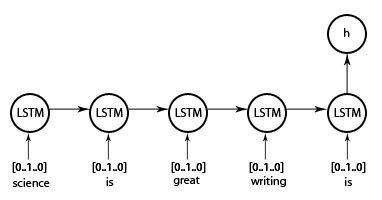
Computation inside a single unit(neuron)
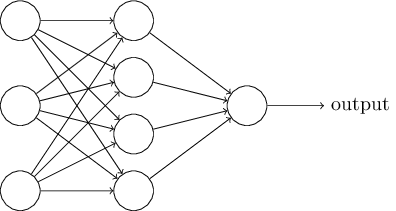
A typical neural network, as an arrangement of units in different layers
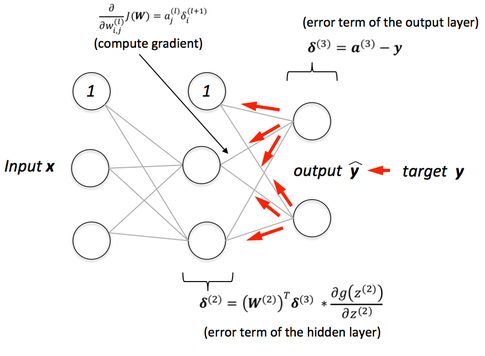
How do Neural Networks learn
This is done using Gradient Descent algorithm with Back-propagation.
Convolutional Neural Network(CNN)
- A CNN consists of an input and an output layer, as well as multiple hidden layers. The hidden layers of a CNN typically consist of convolutional layers, pooling layers, fully connected layers and normalization layers.
- Convolutional layers apply a convolution operation to the input, passing the result to the next layer. The convolution emulates the response of an individual neuron to visual stimuli.
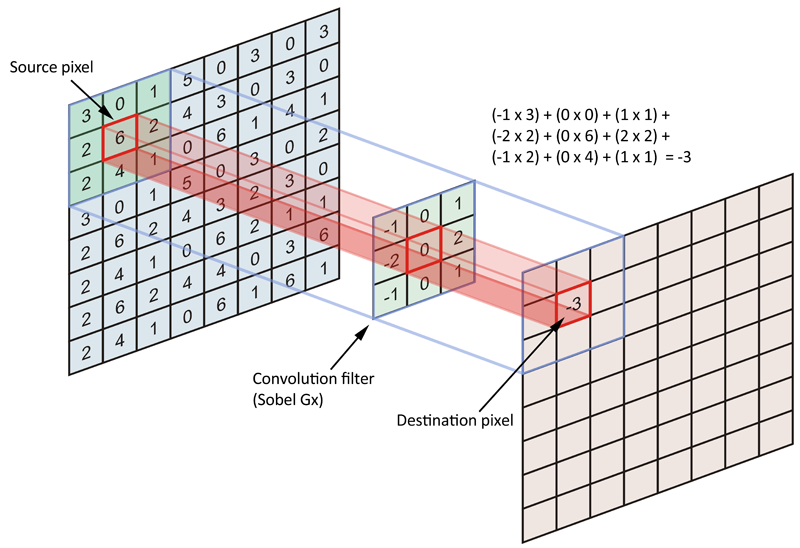
Convolution operation by a single filter
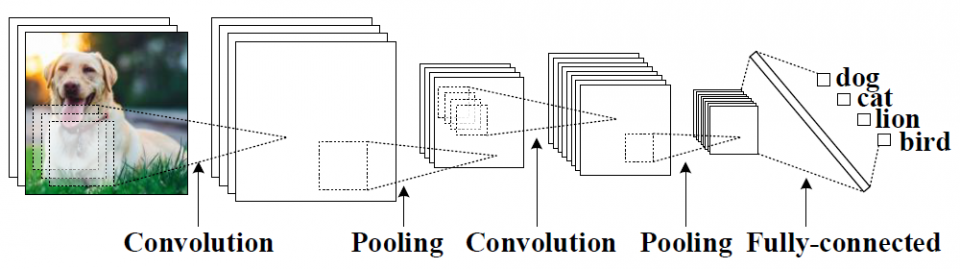
Convutional Neural Networks are widely used in computer vision and NLP
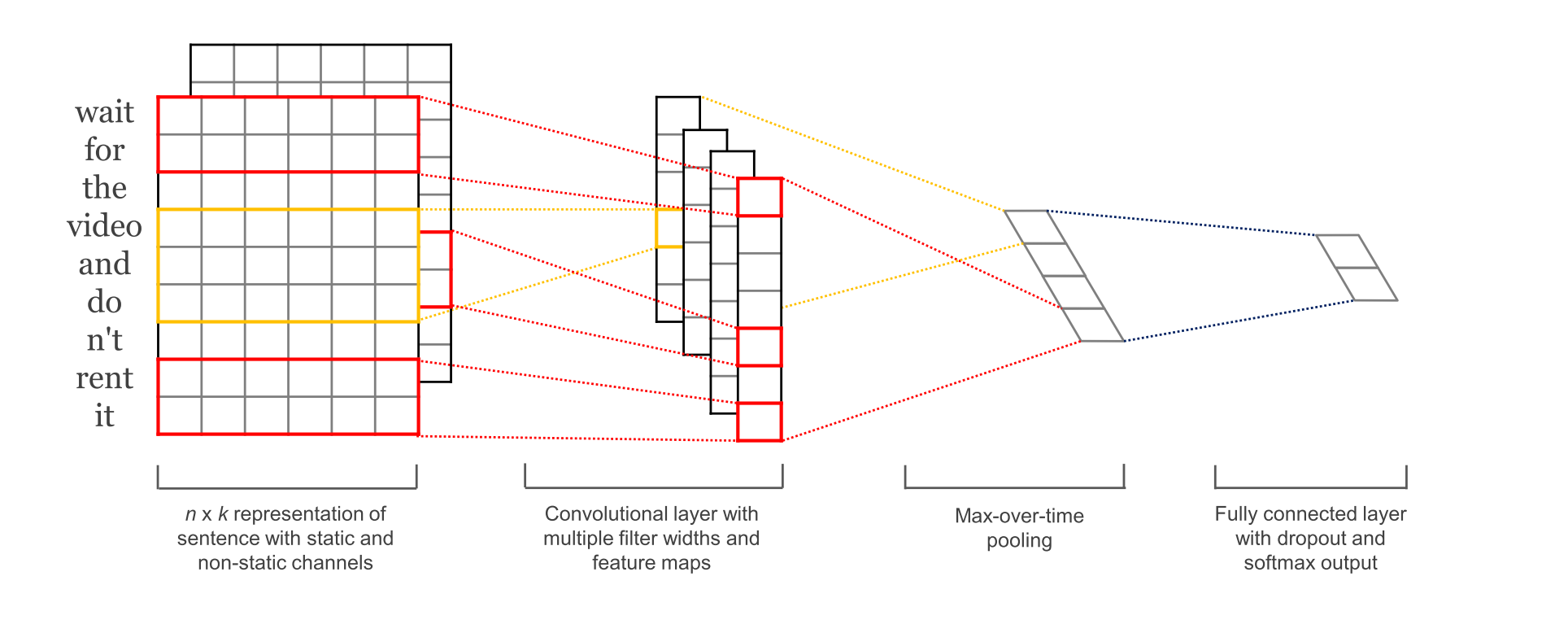
Fig1. Using Conv Nets for image classification
Fig2. Using Conv Nets for text classification
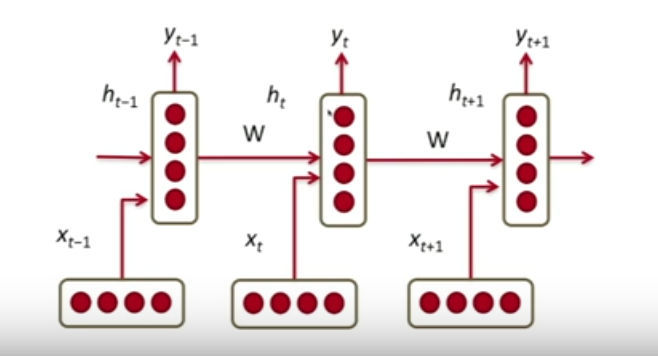
Recurrent Neural Networks
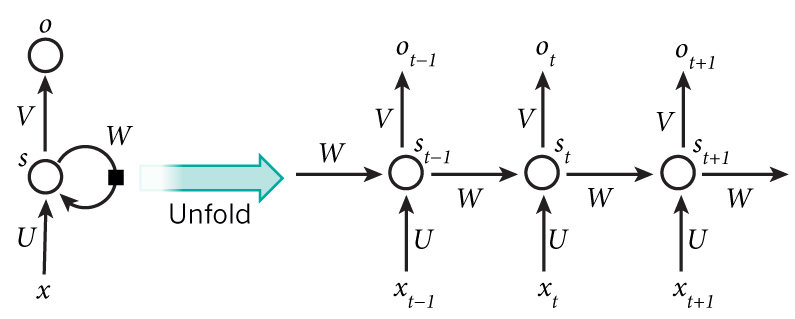
- Along with the present input, the hidden layer activations from the previous time steps are also fed into the neural network.
- This enables it to consider all previously given inputs, along with the current input while making a decision
- This is why they are used extensively in NLP, where sequence classification is required.
Enhancements in the vanilla RNN architecture
- The vanilla RNN suffers from the problem of vanishing gradients while training, which doesn't let it learn long term dependencies on previous inputs.
- There are two modified versions of the simple RNN which suffer much less from this problem, and are capable to remember longer sequences.
- Long Short Term Memory network (LSTM)
- Gated Recurrent Unit (GRU)
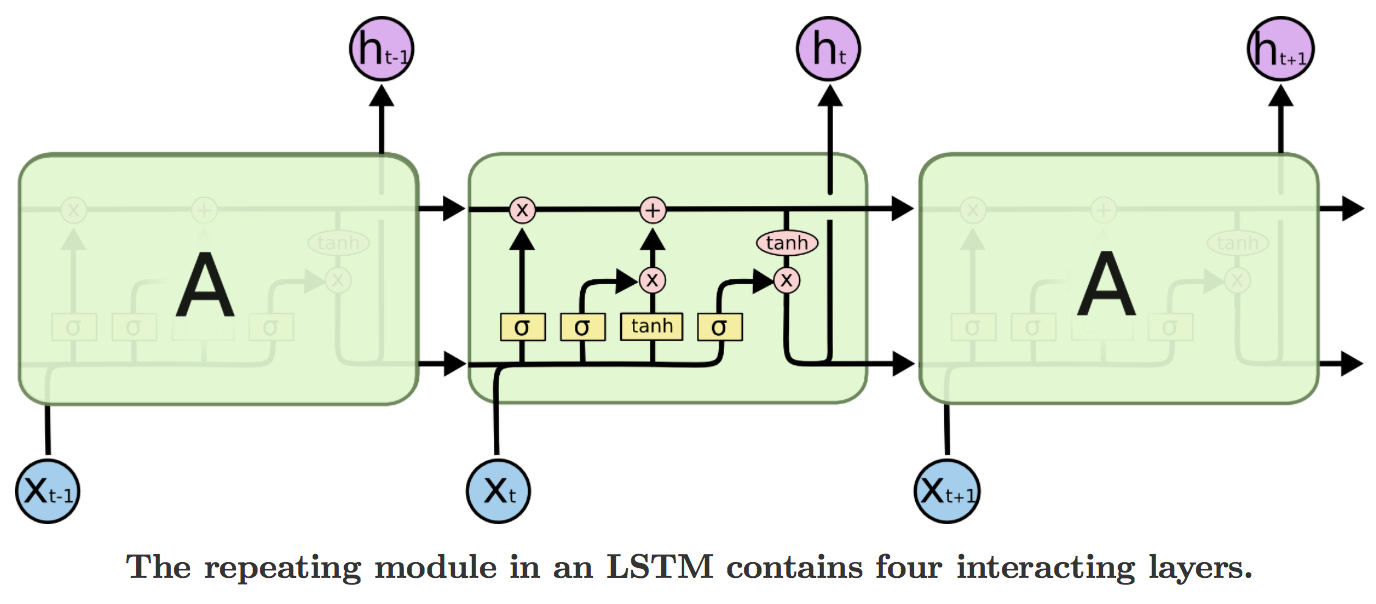
LSTM Architecture
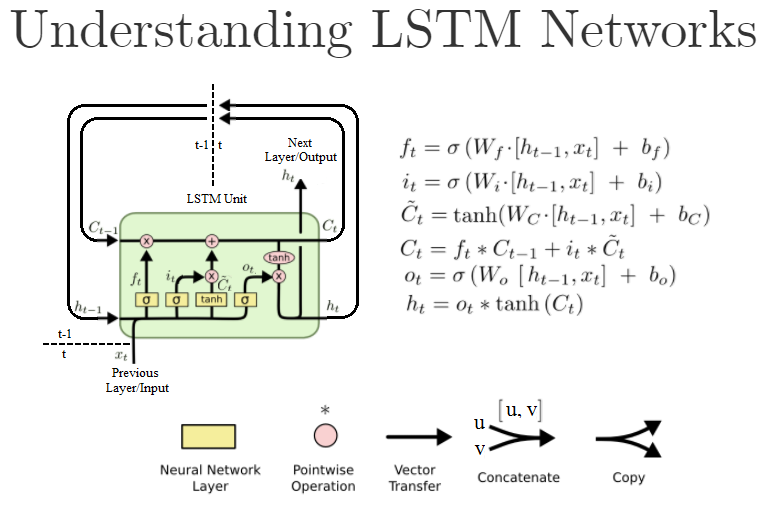
Inside a single LSTM cell
The same cell takes different input at each time step, carries out its computation, produces an output and then uses the newly computed hidden state for next time step

Gated Recurrent Unit (GRU)
GRU can be considered as a variation on the LSTM, as both are designed similarly and, in some cases, produce equally excellent results.
Natural Language Processing
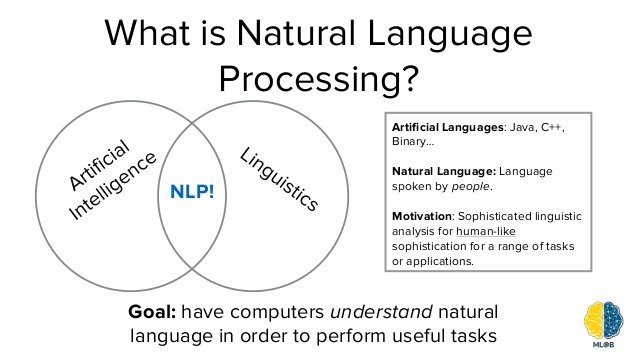
Natural Language Processing is a field that aims to make computers understand and manipulate human language, so we can interact with it more easily.
Examples of some successful NLP systems
The conversational interfaces like Alexa, Siri, Cortana, Google Assistant etc. leverage the power of NLP to interact with their users and fulfil their certain wants

Components of NLP
Natural Language Understanding(NLU)
Mapping the given input in natural language into useful representations
Natural Language Generation (NLG)
Producing meaningful phrazes and sentences in the form of natural language from some internal representation
Why is NLU difficult?
- The human languages are complex
- We use the language creatively. There are a lot of ambiguities.
- Language understanding needs contextual and general knowledge apart from linguistic knowledge.

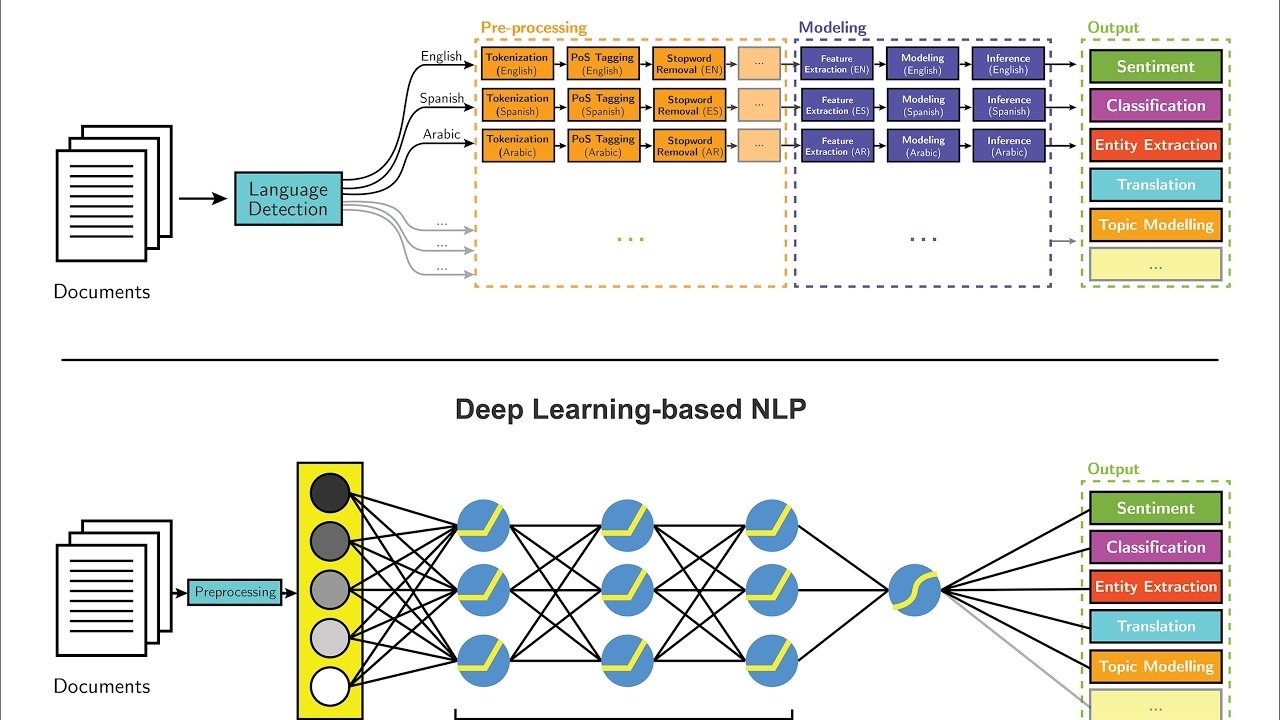
How Deep Learning simplified NLP
We have moved on, from rule based and statistical models which required lot of preprocessing and modeling, to fully end to end and more accurate methods, thanks to Deep Learning.
POS tagging
The process of classifying words into their parts-of-speech and labeling them accordingly is known as Part-of-Speech tagging, POS tagging, or simply tagging.
Text

Some examples of POS tagging
My name is Tony Stark and I am Iron Man
Pronoun (PRP)
Noun (NN)
Verb (VBZ)
Noun (NN)
Noun (NN)
Conjunction (CC)
Pronoun
Verb
Noun
Noun
Mary is reading a book
Noun (NN)
Verb (VBZ)
Verb (VBG)
Noun (NN)
Determiner (DT)
Book a flight for me
Verb (VB)
Determiner (DT)
Noun (NN)
Preposition (PRP)
Pronoun (PRP)
HOW?
- Rule Based Methods
- Transformation based
- Traditional Machine Learning methods
- Using end-to-end Deep Learning
We will explore the last two methods in this talk.
POS Tagging using Machine Learning
- Treat it just like any other Supervised Learning classification problem.
- Take a tagged corpus, extract features, choose a classifier to train and evaluate.
- In practice, the CRF (Conditional Random Fields), Decision tree, naive bayes classifiers have shown good results for this task.
Sources of Information
(Features)
- Knowledge about individual words
- Lexical info
- Spelling (Ex. words ending in 'ing' are likely to be verbs with gerund)
- Capitalization (ex. IBM)
- Knowledge about neighbouring words
- n words before it and n words after.
- pos tags of previous n words

HMM Tagging


The Deep Learning based Approaches
There are a lot of approaches which have been successful. Like-
- Sequence labeling using Bidirectional LSTM
- Ensamble of Bidirectional LSTM and CRF
- Vanilla Neural Network with word embeddings
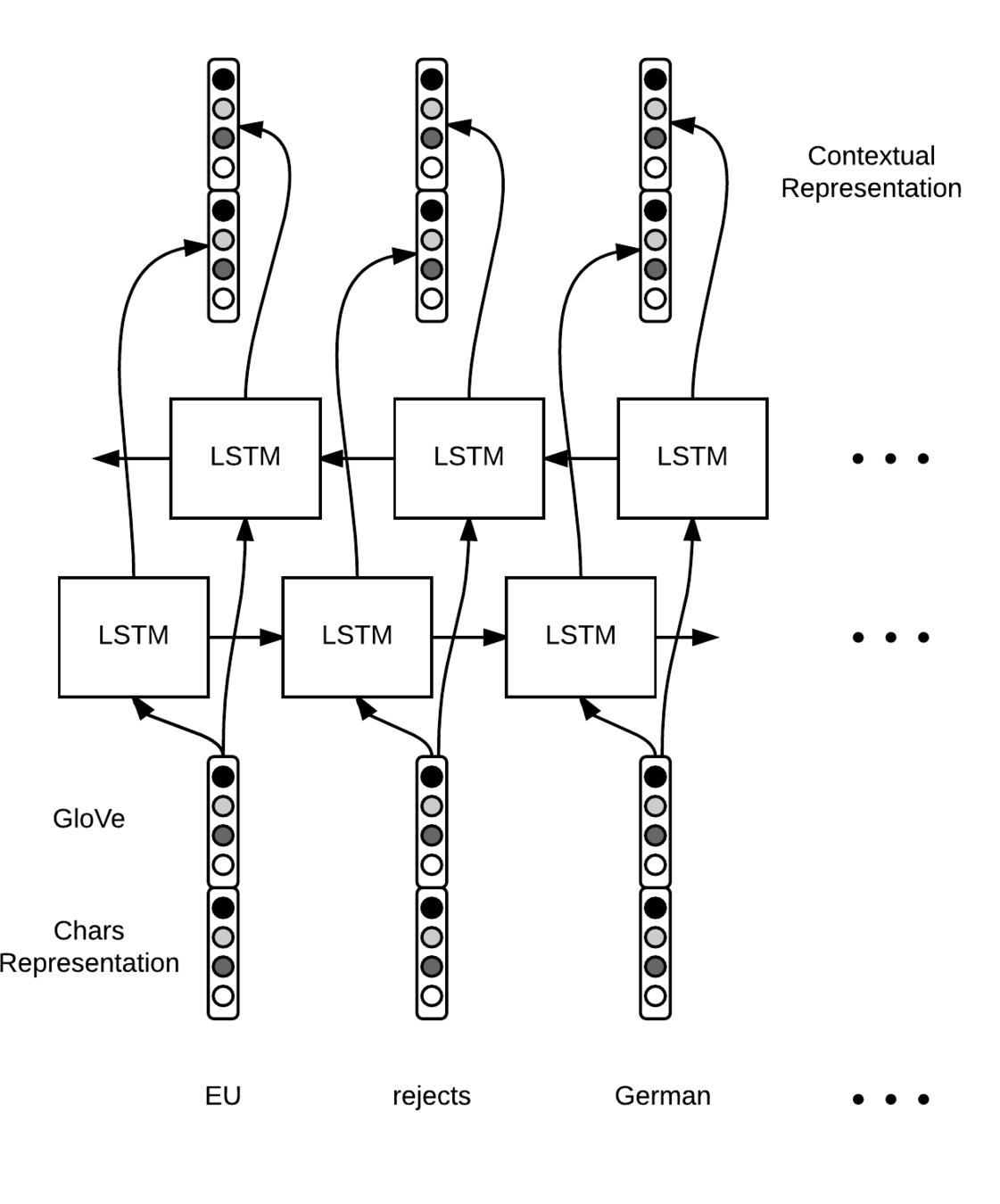
Using Bidirectional LSTM
- While using a Bidirectional LSTM, we do not need to consider explicitly the window of previous and the next n words.
- Bidirectional LSTM is a sequence model, that considers the input series in a two way manner. First it sweeps forward the input and then encodes the same input in the backward direction.
- The input: A series of words converted to their -one-hot-encoding or word embeddings (which we will discuss later about). The length of sentences is fixed to a max value (say 50). The sentences shorter than 50 words are padded to zero vectors.
- Output: At each time step, a k-length vector is output which contains the probabilities of the word belonging to one of the k classes.
LSTM
LSTM
LSTM
LSTM
LSTM
LSTM
Contextual representation
To Fully connected Layer
the
Word representation
(embeddings or one hot)
dog
jumped
Using character level features with the words
In order to make the model consider the spelling based features like:
- Case of the whole word
- Case of the first letter of word
- Suffixes (-ed, -ing) etc.
we can embed character level features as well, by concatenating the character representation vector with the input word vectors
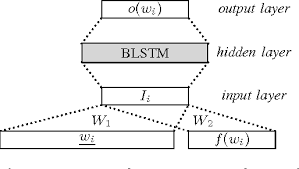
From a paper by Peilu Wang, Yao Qian, Frank K. Soong, Lei He, Hai Zhao,
Part-of-Speech Tagging with Bidirectional Long Short-Term Memory
Recurrent Neural Network
Using character representations along with word representations
How to compute Character level features?
- One option is to use hand-crafted features, like a component with a 0 or 1 if the word starts with a capital for instance.
- Another fancier option is to use some kind of neural network to make this extraction automatically for us. Say a bi-LSTM at the character level.
- Each character ci of a word w=[c1,…,cp] is converted to a vector. We run a bi-LSTM over the sequence of character embeddings and concatenate the final states to obtain a fixed-size vector wchars ∈ Rd2. Intuitively, this vector captures the morphology of the word.
(The diagramatic representation is in the next slide)
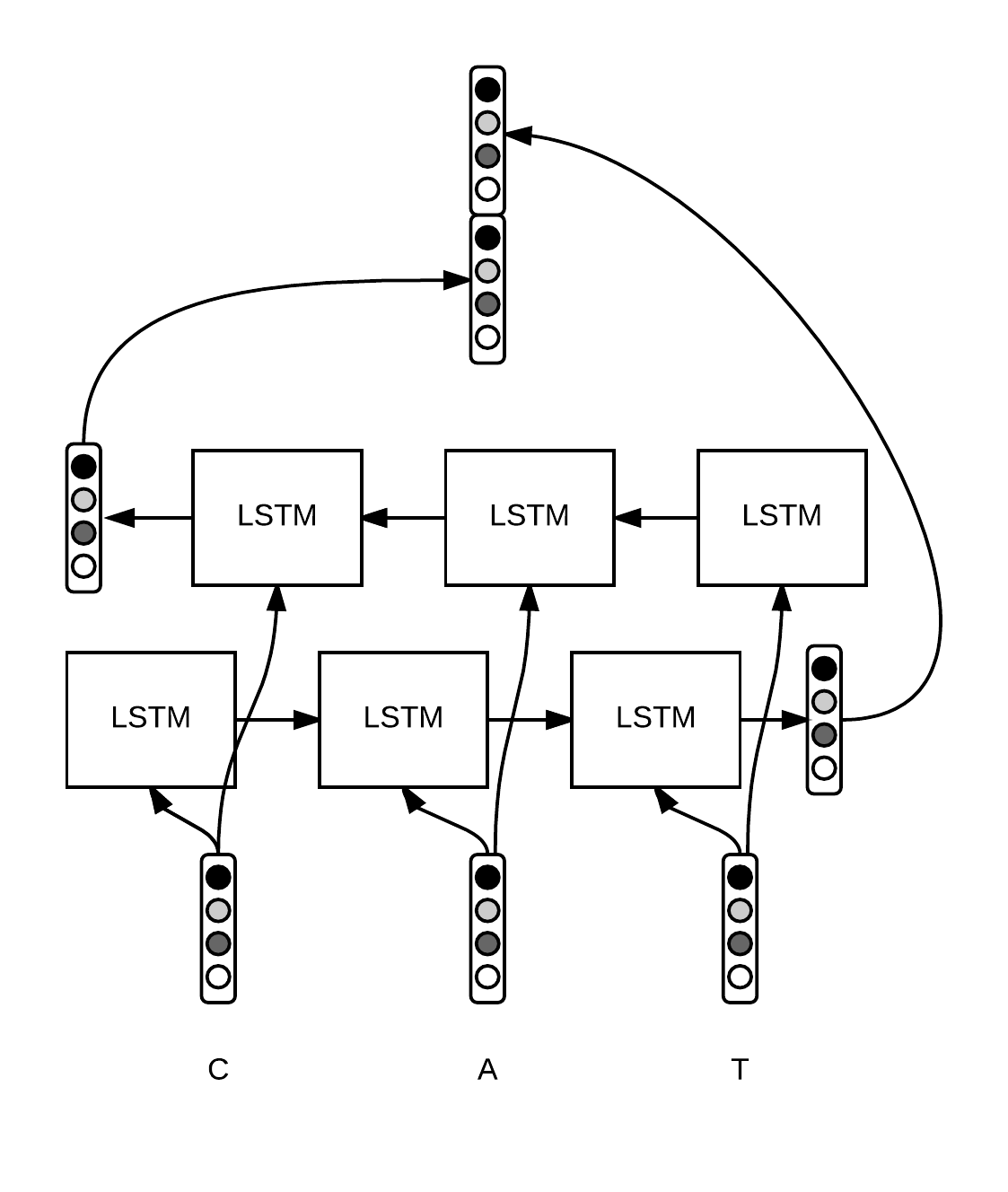
This is how we compute character level features for a word
Using ensamble - Bidirectional LSTM+CRF
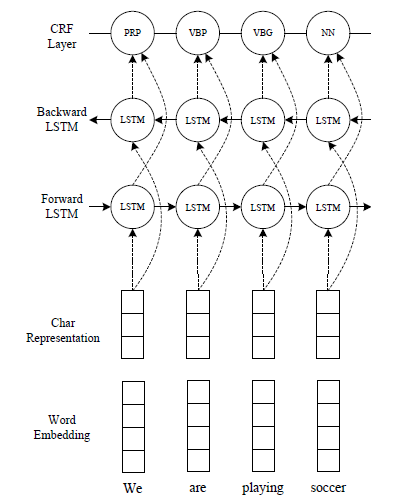
In the output layer, a linear chain CRF can be used instead of a fully connected softmax layer.
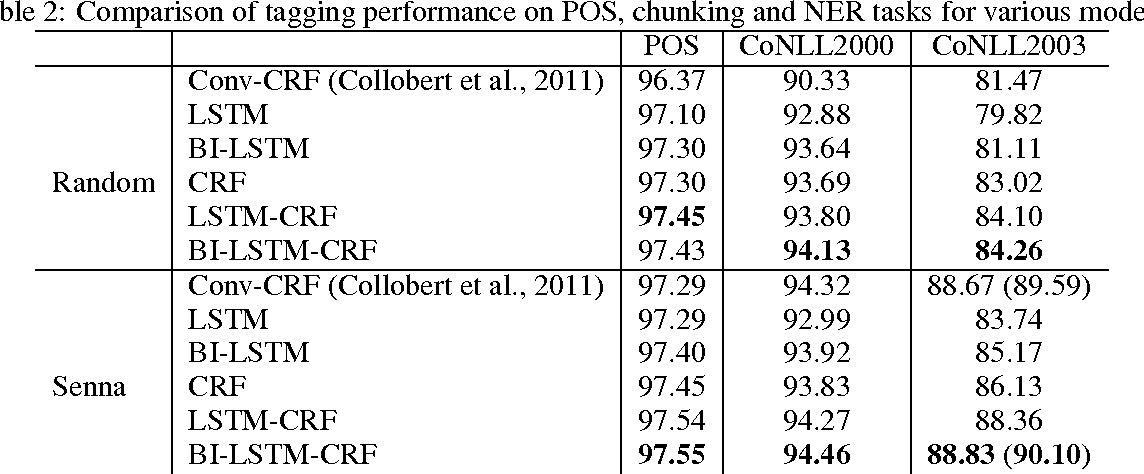
Some results with the deep learning based methods
Huang, Zhiheng et al. “Bidirectional LSTM-CRF Models for Sequence Tagging.” CoRR abs/1508.01991 (2015): n. pag.
Information Extraction
- Information extraction (IE) is the task of automatically extracting structured information from unstructured and/or semi-structured machine-readable documents.
- Information Extraction has many applications, including business intelligence, resume harvesting, media analysis, sentiment detection, patent search, and email scanning.
- Tasks like Named-entity-recognition, relation extraction, co-reference resolution are some examples of information extraction from unstructured text.
Named-Entity Recognition
- The goal of a named entity recognition (NER) system is to identify all textual mentions of the named entities.
- Named entities are definite noun phrases that refer to specific types of individuals, such as organizations,
persons, dates, and so on. - The same technique can be used in medical domain to identify diseases, symptoms, medications, tests etc. from text.
Some examples of NER
Mr Wayne is the owner of the Wayne Enterprises
PERSON
ORGANIZATION
I have a meeting with Mr Bill Gates at California
PERSON
LOCATION
I was born in August 1996
DATE
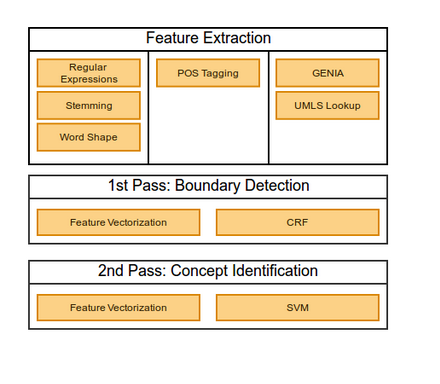
The Clinical Named Entity System (CliNER)
- Clinical Named Entity Recognition system (CliNER) is an open-source natural language processing system for named entity recognition in clinical text of electronic health records. CliNER is designed to follow best practices in clinical concept extraction. (http://text-machine.cs.uml.edu/cliner/index.html)
What it does
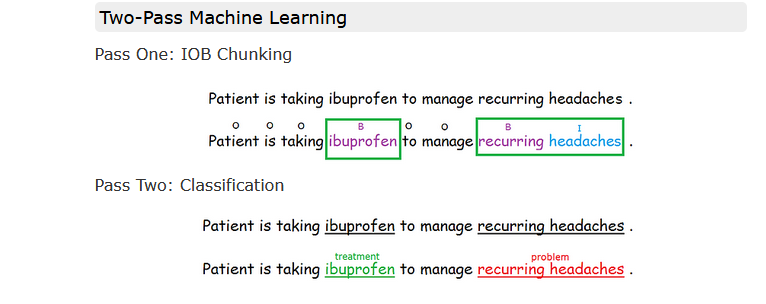
CliNER architecture
IOB format
- The IOB format (short for inside, outside, beginning) is a common tagging format for tagging tokens in a chunking task in computational linguistics, (ex. NER)
- The B- prefix before a tag indicates that the tag is the beginning of a chunk, and an I- prefix before a tag indicates that the tag is inside a chunk.
- The B- tag is used only when a tag is followed by a tag of the same type without O tokens between them.
- An O tag indicates that a token belongs to no chunk.
IOB examples
Mr Wayne is the owner of the Wayne Enterprises
I have a meeting with Mr Bill Gates at California
O
B-PERSON
O
O
O
O
O
B-ORG
I-ORG
O
O
O
O
O
O
B-PER
I-PER
O
B-LOCATION
How to do NER?
- The techniques for carrying out Named Entity recognition is very similar to that of POS tagging, since both are sequence tagging problems. So all the methods which can be used for POS tagging, can also be used for NER.
- Some minor changes can be like:
-
NER involves different tags which are in the IOB format
-
This problem can also be broken down into detection of corresponding IOB tags, followed by classification of the tags into the corresponding categories. (like I-PER, B-LOC)
-
While using the traditional Machine Learning approaches, the POS tags of all the words of the sentences can be first determined and passed as input features for the NER classifier.
-
However, while using Deep Learning for NER, this is not required. (The next slide)
-
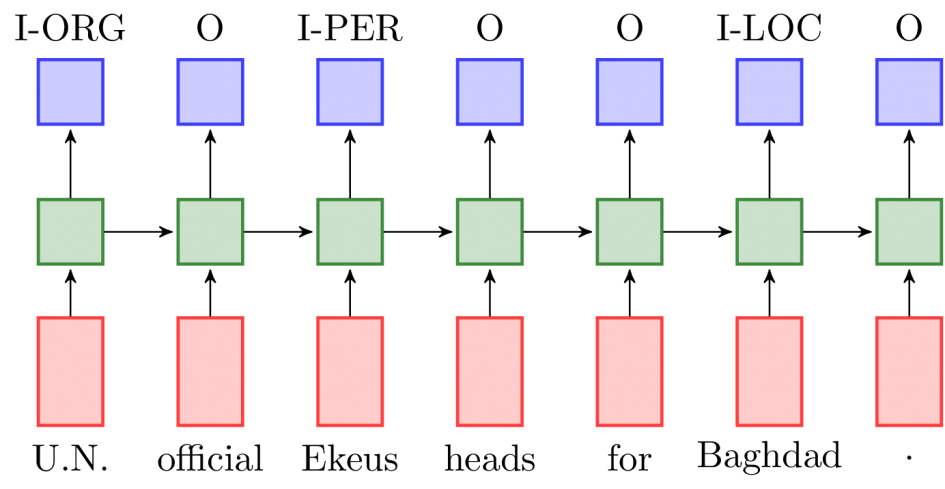
End-to-End NER with LSTM
(IO encoding)
Language Modeling
The goal of Language Modeling is to build a language model that can estimate the distribution of natural language as accurate as possible.
What is a language model?
A language model computes a probability for a sequence of words:
Language models are used in
- Machine Translation
- Word Ordering:
p(the puppy is cute) > p(cute is the puppy) - Word choice:
p(i am going home) > p(i am going house)
- Word Ordering:
- Speech recognition
- Handwriting recognition
- Parsing etc.
Traditional language models
Compute a probability distribution over n grams (every n sequence of words) from a large corpus.
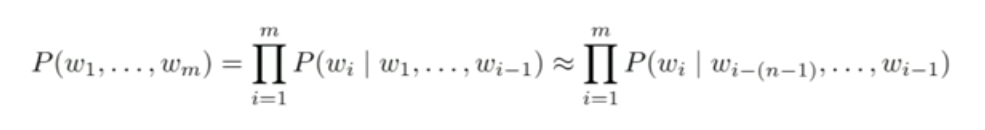
There is an incorrect but necessary Markov assumption involved, that the probability of a word Wi, given previous series of words W1, W2,....,W(i-1) should approximately be equal to the probability of Wi, given only n previous words.
- So, to estimate probabilities, we generally count for unigrams(only the current word), Bigrams(conditioning on previous word) or Trigrams (conditioning on previous two words).
- This is done to reduce the intensive computation involved with higher order word sequences.
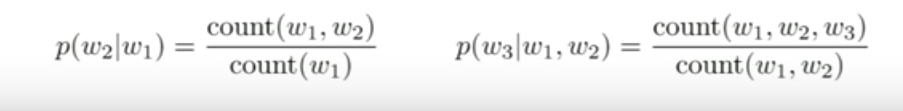
Bigrams
Trigrams
Limitations to the above technique
- Gigantic RAM requirements, which make using more than 3-4 gram infeasible.
- This makes them impossible to be stored on devices with low RAM, like phones.
- There can be as little as zero occurences of a given sequence in the training corpus, which can make probabilities to absolute zero after being multiplied. (Smoothing is done to deal with this)
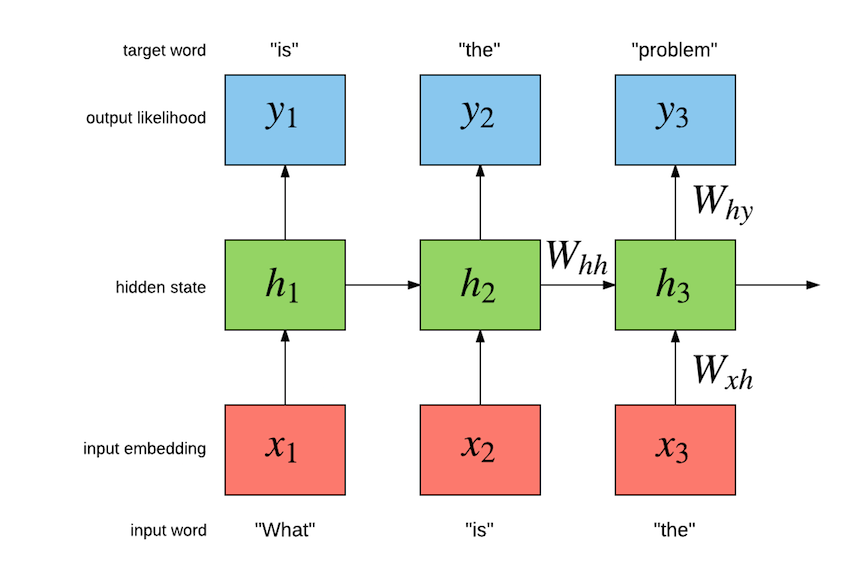
Language Modeling using Recurrent Neural Networks
- LSTMs are good at memorizing long sequences, and so there is no need to compute the n-grams explicitly.
- The RAM requirement only scales with the number of total words.
- Using word embeddings can make the model more accurate.
Given a list of word vectors: x1, x2,......,xT
At a single time step,
LSTM
LSTM
LSTM
Word representation
(embeddings or one hot)
softmax
softmax
softmax
Here,
total.
is the probability distribution over the vocabulary of V words in
The cross entropy loss function is used, but we are predicting words instead of classes.
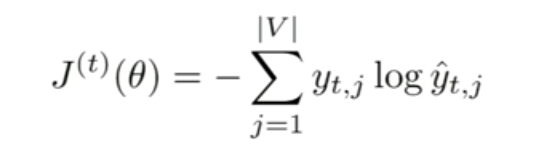
In short...
Word Embeddings
- Word embeddings are a type of word representation that allows words with similar meaning to have a similar representation.
- This has multiple advantages over the traditional one-hot-encoding of words.
Word2Vec
Word2vec is a particularly computationally-efficient predictive model for learning word embeddings from raw text.
It comes in two flavors, the Continuous Bag-of-Words model (CBOW) and the Skip-Gram model.
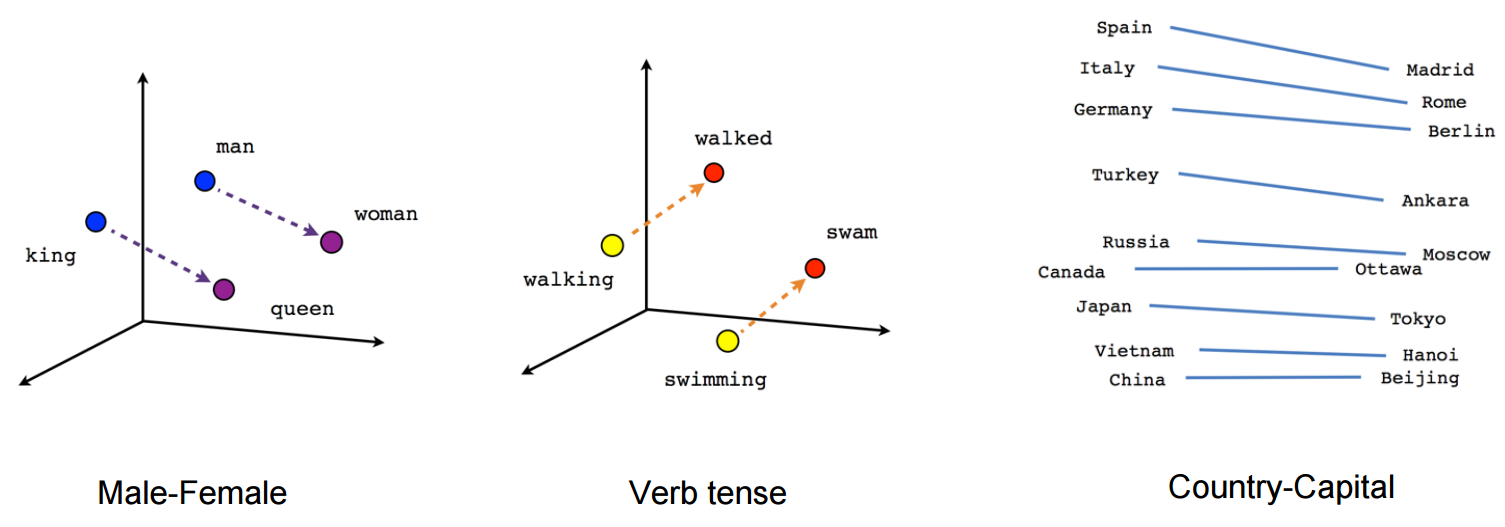
Word2vec can find relations between words. They preserve syntactical as well as symentic information. This explains why these vectors are also useful as features for many canonical NLP prediction tasks, such as part-of-speech tagging or named entity recognition
Visualizing 300Dimensional Word2vec embeddings by reducing their dimensionality to 2Dimensions using t-SNE or PCA
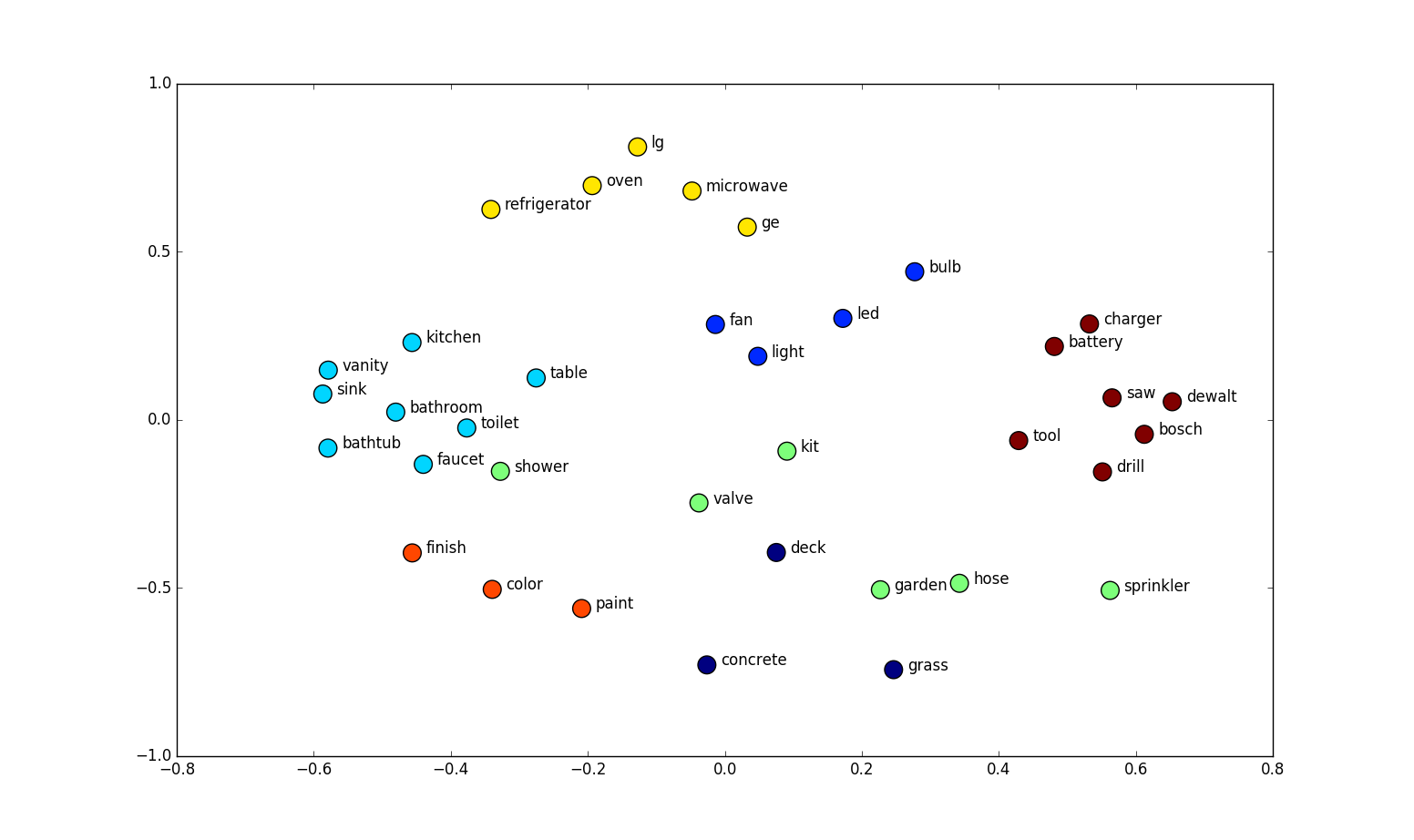
3D visualization with Tensorboard
How does it work?
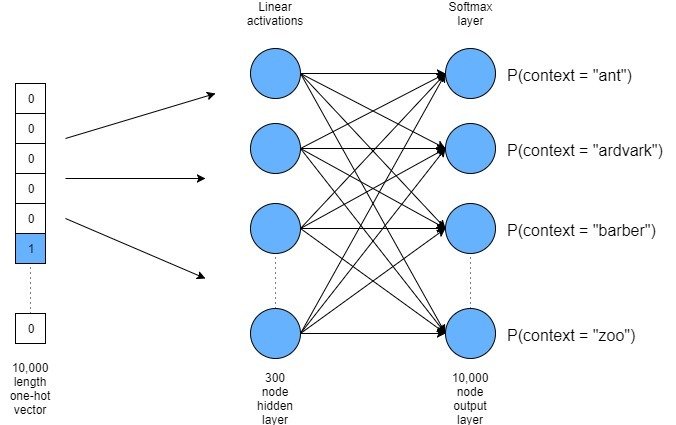
- We create a Neural Network with one hidden layer that aims to predict between a center word w_t and context words, in terms of word vectors.
- After many iterations over a large corpus of unstructured text, when finally the training loss stops decreasing, we stop the training and then the weight matrix of the hidden layer becomes our embeddings.
- We can generate as many dimensional embedding as we want, by adjusting the hidden layer size.
- Usually the more the dimensions, the more information it conveys.
- In the picture on the previous slide, the size of hidden layer is 300, so each word in our word embeddings will be of 300 length.
Text Classification
- Document classification is assigning categories/labels to documents, or a string of text which could be web pages, media articles, customer reviwes etc.
- Has applications like
- Spam filtering
- Sentiment Analysis
- Intent recognition (chatbots)
- Personal twitter filter (will interest me/ won't)
- Language guessing
.....and a lot more.
What is it ?
Topic Extraction, tag assignment by quora- use LSA, or mainstream information extraction techniques.
Intent classification
How is it done ?
- There are a wide variety of methods for text classification, ranging from traditional TF-IDF features and Linear SVMs, to word embeddings and deep learning based classification techniques.
- There are also clustering methods for unsupervised data and finding similarity between documents.
- As we'll see, sometimes it is necessary to take into consideration the sequence of words or characters. That's where RNNs come into play.
The general pipeline for text classification

Text preprocessing
convert to lower case, remove punctuation and Tokenize
despite
a
somewhat
too
tidy
ending
it
s
a
terrific
movie
beautifully
made
despite
somewhat
tidy
ending
terrific
movie
beautifully
made
despit
somewhat
tidy
end
terrif
movi
beautiful
made
despit
somewhat
tidy
end
terrif
movi
beautiful
make
Stopword removal
Stemming
Lemmatization
Converting Preprocessed Text to Features
- The documents can be represented as fixed length vectors. This idea is known as the vector space model.
- Count vectorization
- TF-IDF vectorization
Count Vectorization
Doc1: hello how are you
Doc2: i am good how are you
Doc3: are you coming to college
Vocabulary
hello
coming
to
how
you
are
good
college
i
am
Vector for Doc1
1
0
0
1
1
1
0
0
0
0
Vector for Doc2
0
0
0
1
1
1
1
0
1
1
Vector for Doc3
0
1
1
0
1
1
0
1
0
0
Need for a new metric
- Sometimes certain stopwords can be useful.
- Words do not have the same weightage for each document
Doc1: Tony Stark is a genius.
Doc2: Tony Stark is not a genius.
TF-IDF vecorization
(term frequency–inverse document frequency)
TF: Term Frequency: Measures how frequently a term occurs in a document.
TF(t) = (Number of times term t appears in a document) (Total number of terms in the document).
IDF: Inverse Document Frequency: Measures how important a term is.
IDF(t) = log(Total number of documents / Number of documents with term t in it)
Finally : Tf-Idf (t) = TF(t) * IDF(t)
What after feature extraction?
- Once the feature vector has been made, classic supervised learning algorithms like SVM, Naive Bayes, Logistic regression can be used for classification.
- Generally for short length documents (ex. for intent classfication for short sentences) naive bayes has shown good results because of its ability to generalize better.
Limitations of the traditional approaches
- Don't take sequence into account
- Consider the assumption that words are independent of each other
- Don't generalize to words which were not seen during training
The movie was good; was not bad. (+ve)
vs
The movie was not good; was bad. (-ve)
The cat walks across the table.
or
The dog jumps across the sofa.
Using RNNs for text classification
- Using a many-to-one RNN(LSTM) for text classification.
- AT each time step, a word from the sentence will be passed to LSTM as input in form of either one hot encoding or word embeddings
Using Convolutional Neural Networks with word embeddings
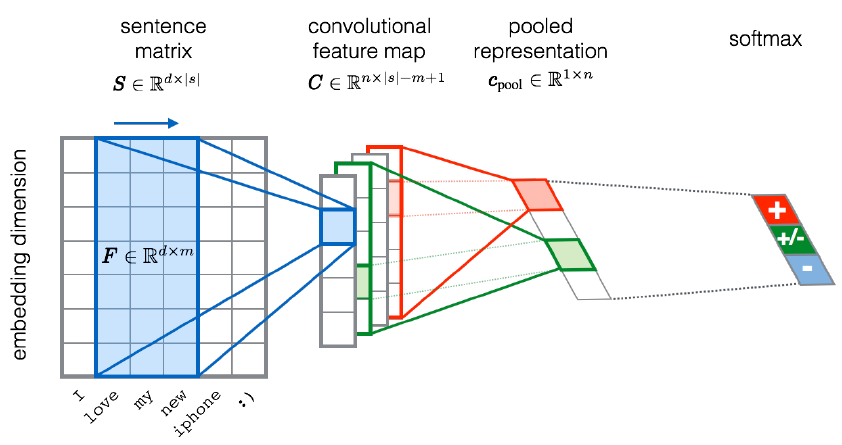
From research paper titled- UNITN: Training Deep Convolutional Neural Network for Twitter Sentiment Classification (Severyn and Moschitti, 2015;Felbo et al., 2017)



Conversational Interfaces (chatbots)

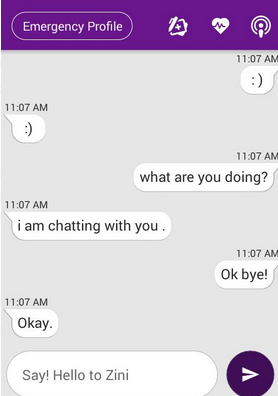
Purpose of a conversational interface
- These are made to serve certain purposes fo example, for booking a hotel, ordering a pizza, entertainment etc.
- Now a days, chatbots are also being used for emotional counselling of people.
How do they work ?
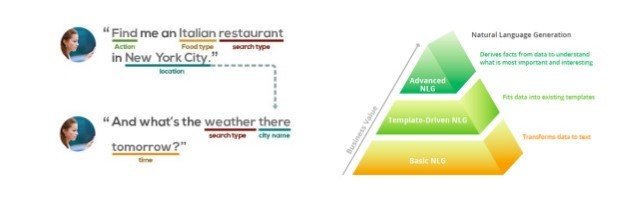
Natural Language Generation:
With and without Deep Learning
Retrieval type chatbots
- Responses are handmade by programmers
- The bot chooses the best possible response, given a query, with the help of some heuristic (such as tf-idf and cosine similarity)
- Can use deep Lerning methods like Dual-encoder similarity.
Generative type Chatbots
- Generates responses from scratch, given a query.
- Rule based systems were made in the old times.
- Now uses the popular Seq2Seq architecture.
"Smart Reply" by Google
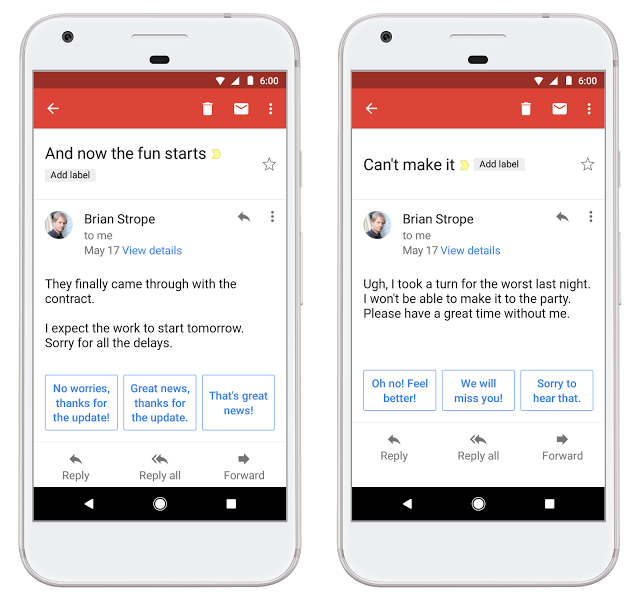
Gives suggestions for appropriate short responses to the received message
How Smart Reply works
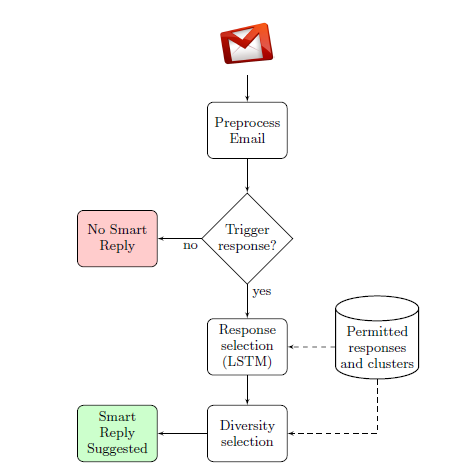
Taken from a research paper by google
The Dual Encoder LSTM
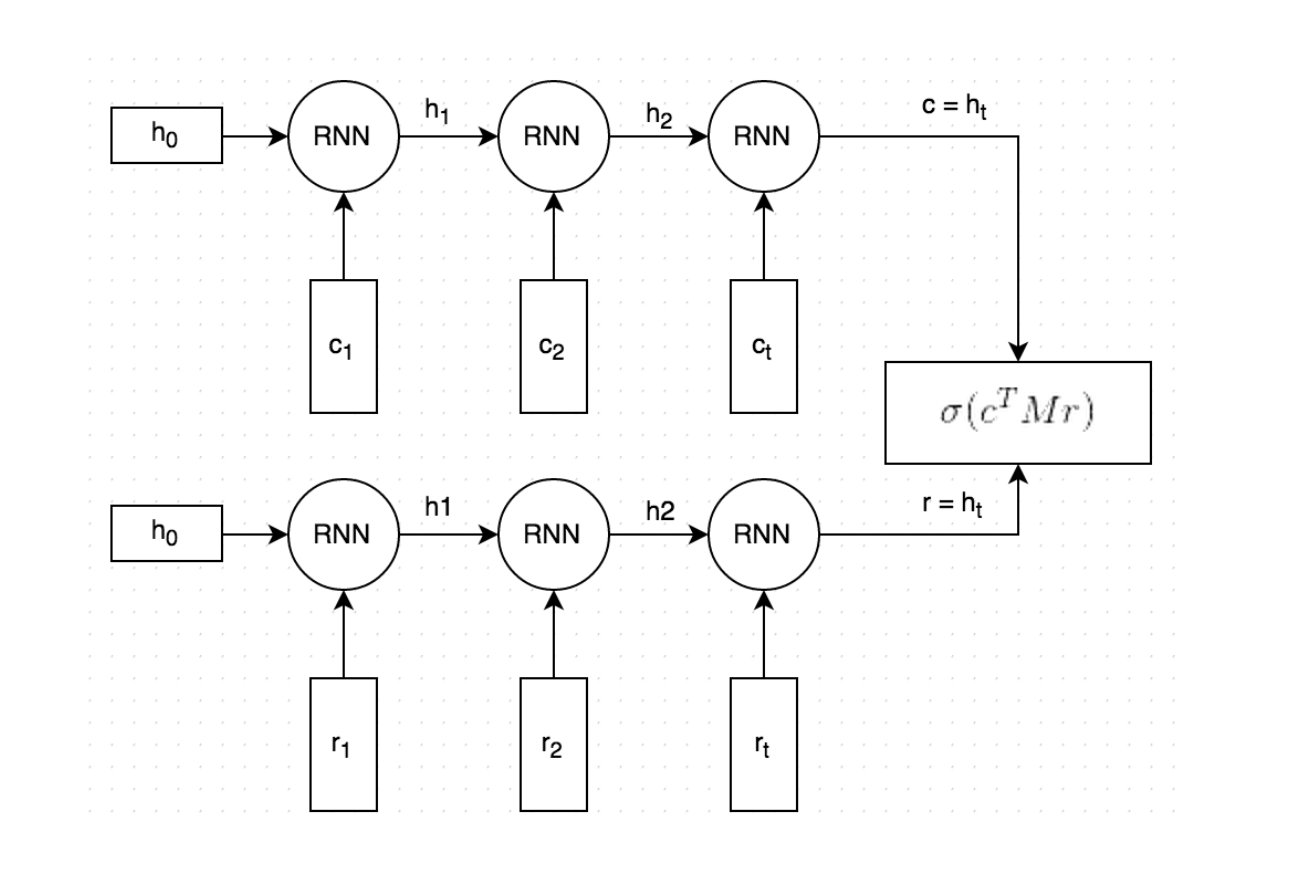
Used to learn a similarity function between a query and a response. The responses are already made.
Working of Dual encoder architecture
- Both the context and the response text are split by words, and each word is embedded into a vector.
-
Both the embedded context and response are fed into the same Recurrent Neural Network word-by-word. The RNN generates a vector representation that, loosely speaking, captures the "meaning" of the context and response (c and r in the picture).
-
We multiply c with a matrix M to "predict" a response r'. If c is a 256-dimensional vector, then M is a 256×256 dimensional matrix, and the result is another 256-dimensional vector, which we can interpret as a generated response. The matrix M is learned during training.
-
We measure the similarity of the predicted response r' and the actual response r by taking the dot product of these two vectors. A large dot product means the vectors are similar and that the response should receive a high score. figure.
The Sequence to Sequence (Seq2seq) model
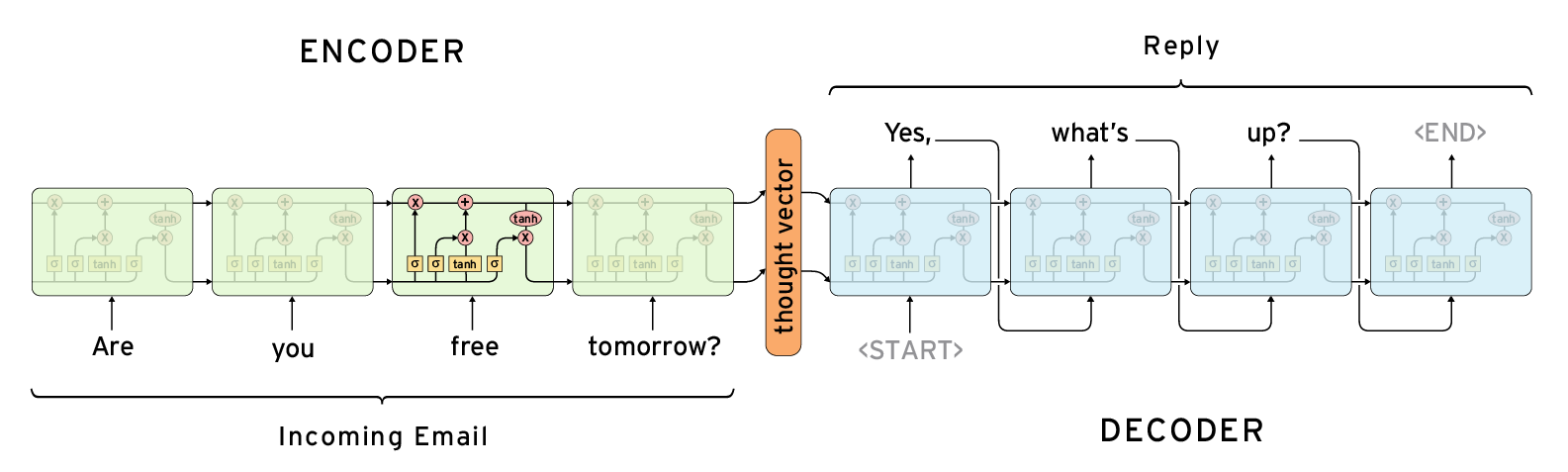
An end to end technique for generating responses from scratch, given a query
How it works
- It consists of two RNNs : An Encoder and a Decoder.
- The encoder takes a sequence(sentence) as input and processes one symbol(word) at each timestep.
- Its objective is to convert a sequence of symbols into a fixed size feature vector (called context) that encodes only the important information in the sequence while losing the unnecessary information.
- From the context, the decoder generates another sequence, one symbol(word) at a time.
Seq2Seq with Attention mechanism
- Attention is a mechanism that forces the model to learn to focus (or to attend) on specific parts of the input sequence when decoding, instead of relying only on the hidden vector of the decoder’s LSTM.
- The decoder does not take the context computed by the encoder. It instead takes the context generated by applying attention mechanism over all the encoder hidden state outputs.
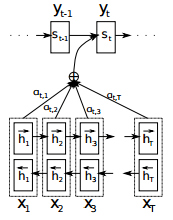
Attention mechanism
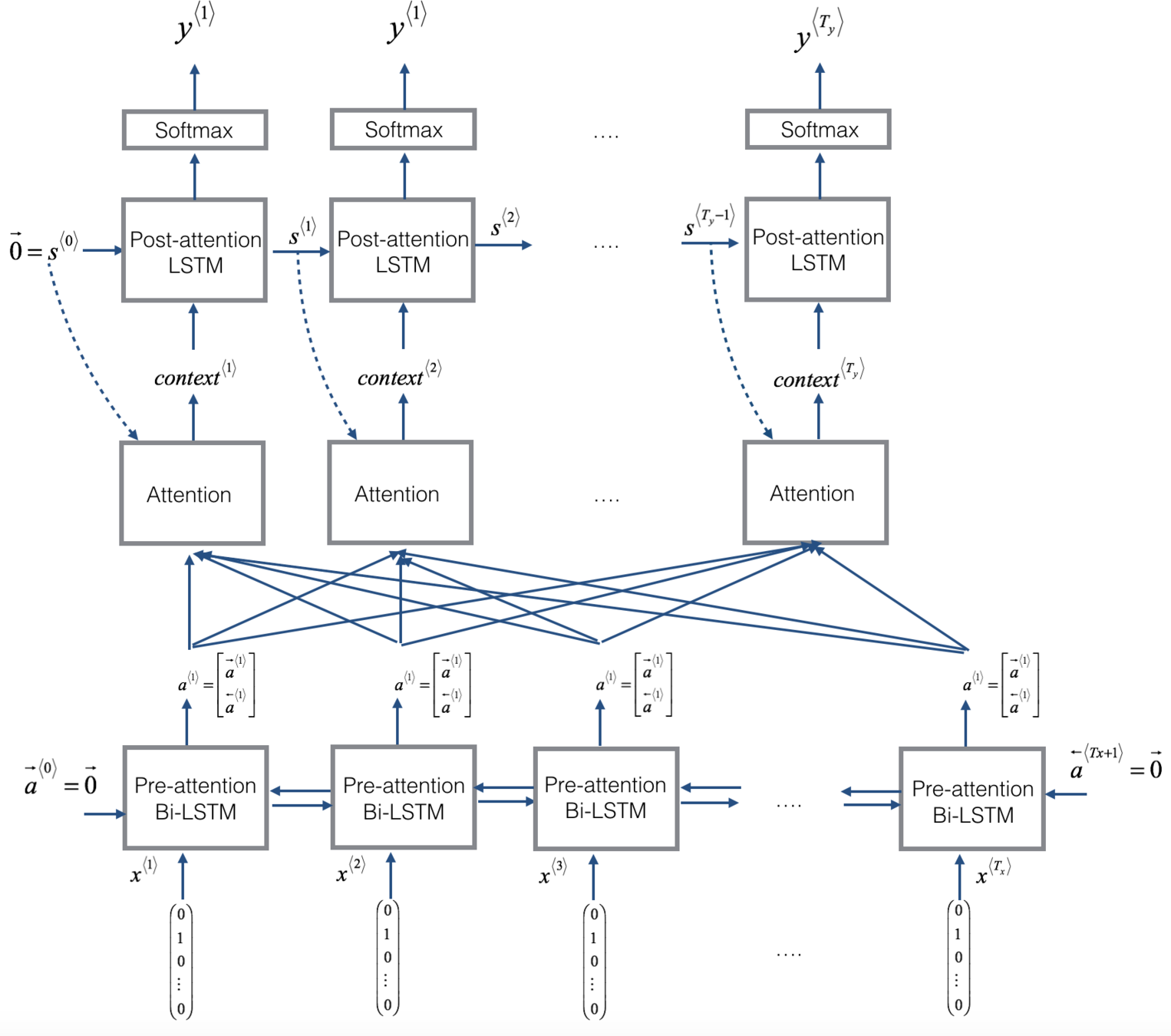
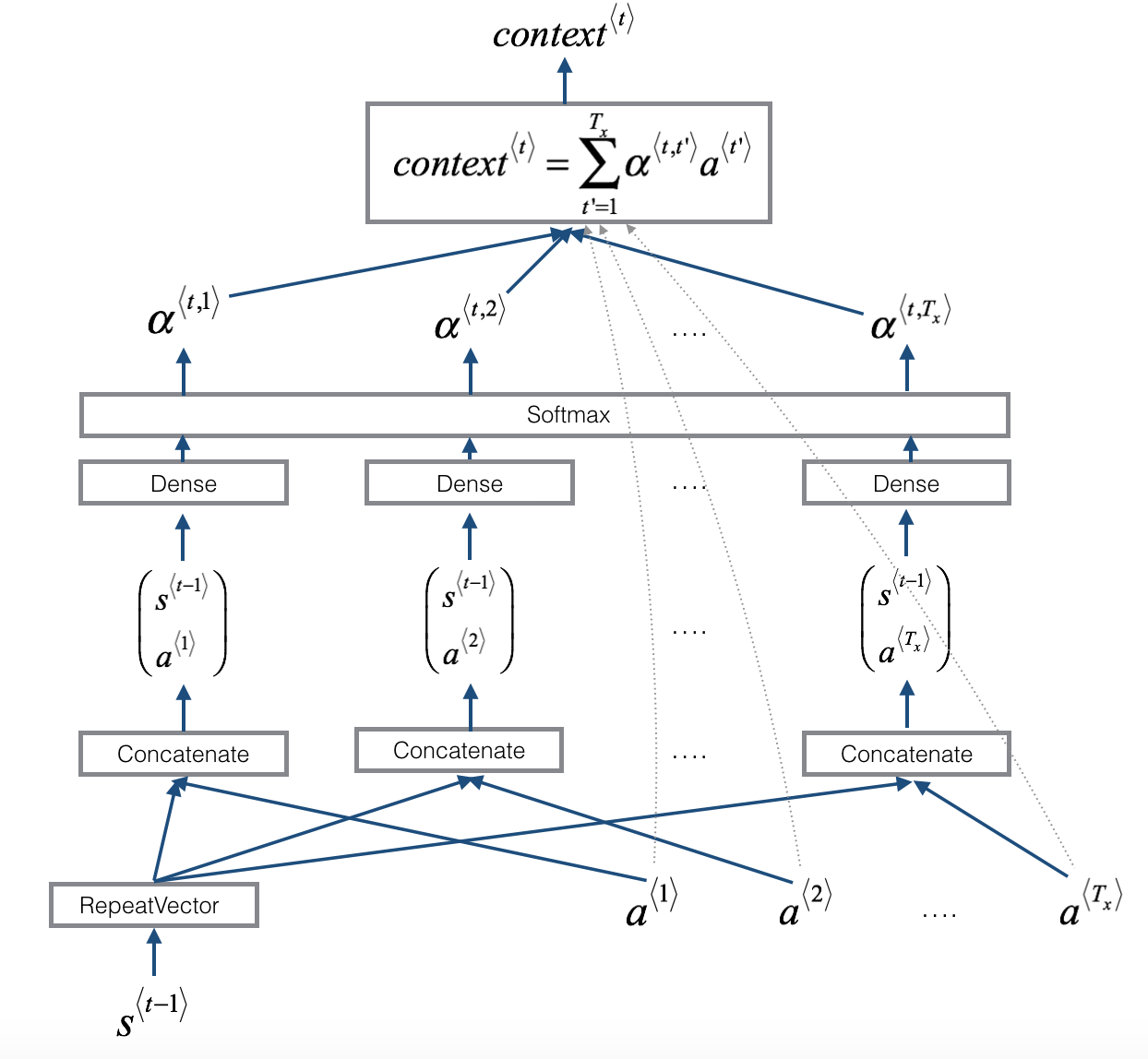
Seq2seq model with attention
How the context is calculated
Drawbacks of using seq2seq for text generation
- This model can take the conversation in any direction, which is not controllable.
- Grammatical mistakes are often there.
- May generate replies which are inconsistent with the previous replies.
Machine Translation
The goal is to convert a given piece of text from one language to another while preserving the syntax and meaning.
Challanges in MT
Lexical ambiguity:
book used as verb: book a flight => reservar (spanish)
book used as noun: read the book => libro (spanish)
Different word orders:
English word order is: subject-verb-object
Japanese word order is: subject-object-verb
Syntactic ambiguity can cause problem:
John hit the dog with a stick. - could have two meanings
Pronoun resolution:
The computer outputs the data; it is fast.
The computer outputs the data; it is stored in ascii.
In the first sentence 'it' refers to the computer; but in second, it refers to the data
Classical approaches to MT
- Rule based: These were called Direct MT systems. They convert it word by word. And then applied some rules to preserve syntactical structure.
- Transfer based approach: Parses the source language sentence, convert the parse tree to the target language parse tree, and finally generate the output sentence from that tree.
- Statistical MT systems: Use parallel corpora. Very complex to build
Statistical MT systems
We have a source language: f , eg. French
And we have a destination language: e, eg. English
We use a probabilistic approach:
p(f|e) is the translational model which is trained on the parallel corpus.
And p(e) is the language model in the language 'e' (here English).
Beam search is used for searching for best sentence out of the possible choices.
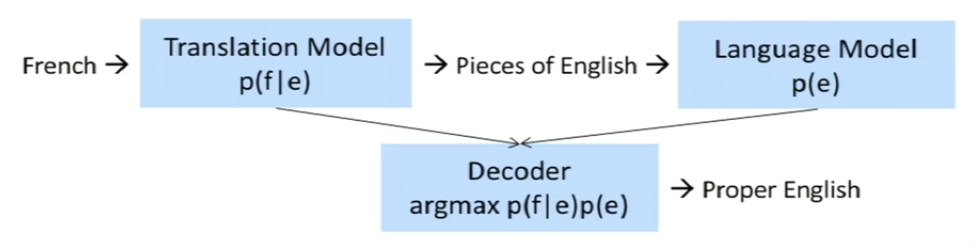
Translation using Seq2Seq model with attention
This approach is similar to the one used to generate a target sentence given a source sentence. The only difference is that here instead of the target sentence being in the same language, it is in the target language.
Visualizing Attention

Text Summarization

Creating a short, accurate, and fluent summary of a longer text document.
Automatic text summarization methods are greatly needed to address the ever-growing amount of text data available online to both better help discover relevant information and to consume relevant information faster.
Using Seq2Seq model for text summarization
- The same approach which was used for machine translation using seq2seq can be used for text summarization.
- As the input we provide the piece of text word by word (as embeddings) and encode it into a fixed length vector.
- Then the decoder decodes this vector to produce the summary (or headline) word by word.
- It is trained in a similar way on a huge dataset of text-summary pairs.
- Attention mechanism can be applied here. In practice, it has shown good results.
Visualizing Attention weights
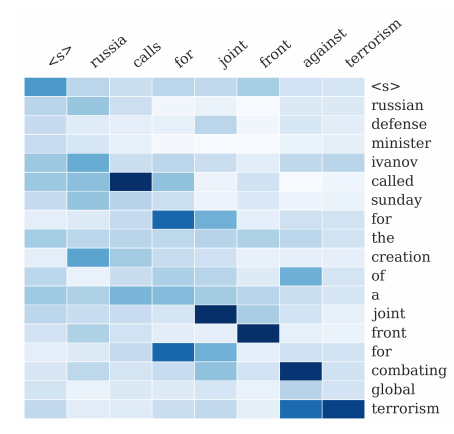
Results with the deep learning approach
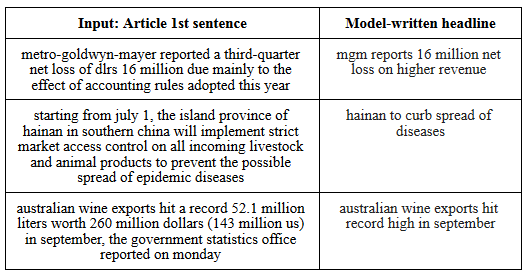
Other widely used approaches for text summarization
Extractive:
- Based on statistical foundation
- Looks at features like Keywords, title ,Word distance, Cue phrazes(for ex. significantly, hardly etc.), sentence position
Abstractive:
- Based on linguistic and mathematical foundation.
- Techniques like Lexical chains, Clustering, Non Negative Matrix factorization
A trainable method by
Kupiec et al. (1995)
For every sentence, it was decided if it is to be included or not.
The features:
- Sentence Length
- Presence of Upper case words (except common acronyms)
- Thematic words
- A set of 26 manually fixed phrazes
- Sentence position in the paragraph
Naive Bayes classifier is used, which assumes statistical independence.
It's an extractive based method.
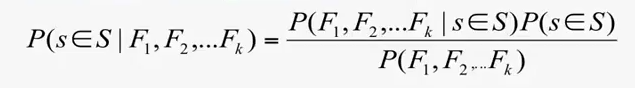
Gong and Liu (2001)
- Using LSA (Latent Semantic Analysis)
- It could be for single and multi document
- No wordNet used
- Each document is represented as a word by sentence matrix (row=word, column=sentence)
- TF*IDF weights in the matrix
- Do SVD(Singular Value Decomposition), and get USV^T
- The rows of V^T are independent topics
- Select sentences that cover these independent topics
Other Common Approaches
- Using LSA(Latent Semantic Analysis
- Using Lexical Chains
Comparison
- The Deep Learning based approach is new and is really easy and less complicated as compared to the statistical and linguistic approaches to this problem.
- But there are some limitations of the Deep Learning approach. That it's essentially supervised and needs a lot of data to train on. Also it can't reliably generate summaries of large paragraphs.
LSTM Layers x 2
softmax
softmax
softmax
Linear
Linear
Linear
Embeddings
LSTM Layers x 2
softmax
Linear
Embeddings
LSTM
classification scores
Zini's AI server (Runs code
for the intelligence)
Programming Language: Python
Zini's android server (Handles user authentication and communication with AI server)
Programming language: ASP. NET
User's android/IOS phone running ZINI app
ZINI Server Communication architecture
ZINI high level architecture and working
User's app
Android Server
AI server (Provides the intelligence)
Intent Recognition
Dialog Manager
Sympotom assessment module
Specialist recommendation module
General Chat module
General Medical Advice & Info (GMAI) module
Additional conversation module
(handles specific chat types for eg. emotional responses)
Database
(PostgreSQL)
Response
Message
Message
| i | n | t | u | i | t | i | v | e |
|---|
mystring =
0 1 2 3 4 5 6 7 8
-9 -8 -7 -6 -5 -4 -3 -2 -1
index
negative index
is a > b?
Yes
No
"a is greater than b"
"a is not greater than b"
a and b are two real numbers
if
a > b
a == b
"a is greater than b"
"a is equal to b"
a < b
"a is less than b"
| A | B | C | D | E | F | G | H | I | J |
|---|
| K | L | M | N | O | P | Q | R | S | T |
|---|
| U | V | W | X | Y | Z |
|---|
= - log ( )
26
1
2
= - log ( )
26
1
probability (p)
2
= - log (p)
2
Self information

i = 1
n
n = No. of possible outcomes
| 0 | |
|---|---|
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | '20m' |
| 8 | |
| 9 |
key : 'carryminati' }
value : '20m' }
Hash function
7
During Insertion
| 0 | |
|---|---|
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | '20m' |
| 8 | |
| 9 |
key : 'carryminati' }
Hash function
7
During Lookup
'20m'
| Message | Response |
|---|---|
| How are you? | I am fine, Thankyou! |
| How to impress girls? | Be rich :P |
Universal Sentence Encoder
Vector1
Vector2
While Training
Vector1
Vector2
Universal Sentence Encoder
"How you doin?"
Vector3
cosine sim.
similarity 1
= 0.9
similarity 2
= 0.3
>
Found most similar question: "How are you?"
During chatting: