GLM in Python
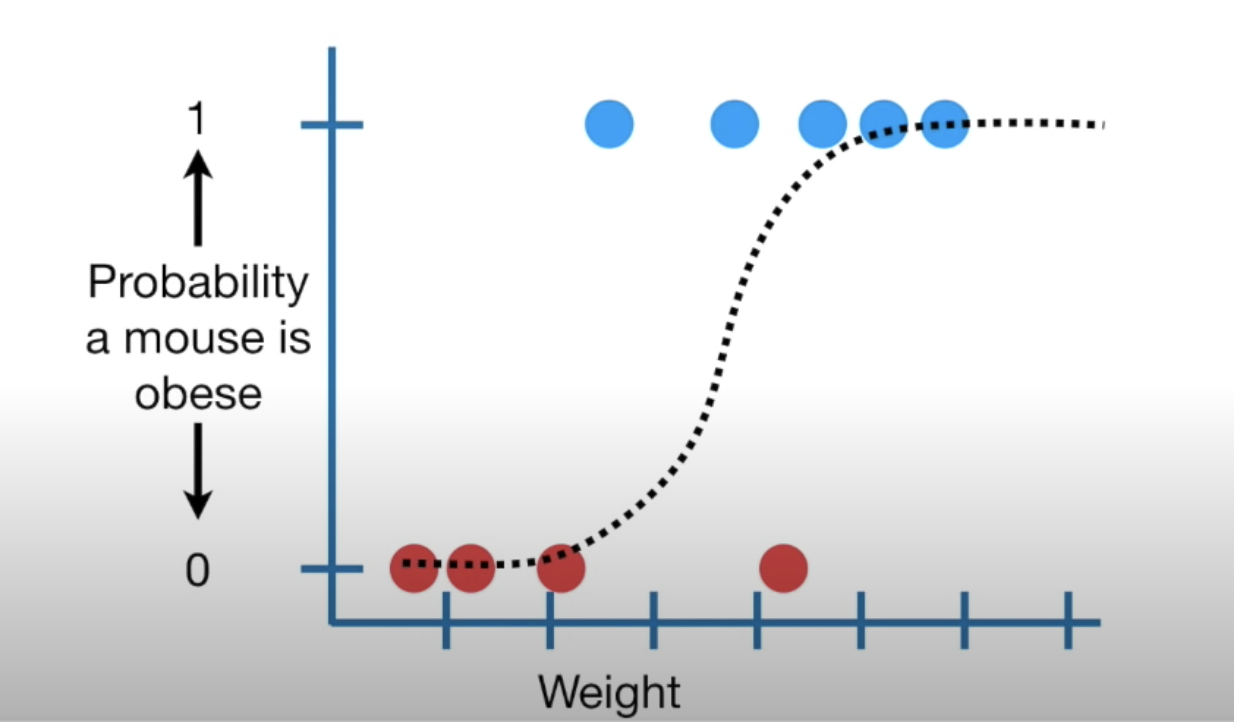
Logistic regression
Predicting 0 or 1
based on continuous variables
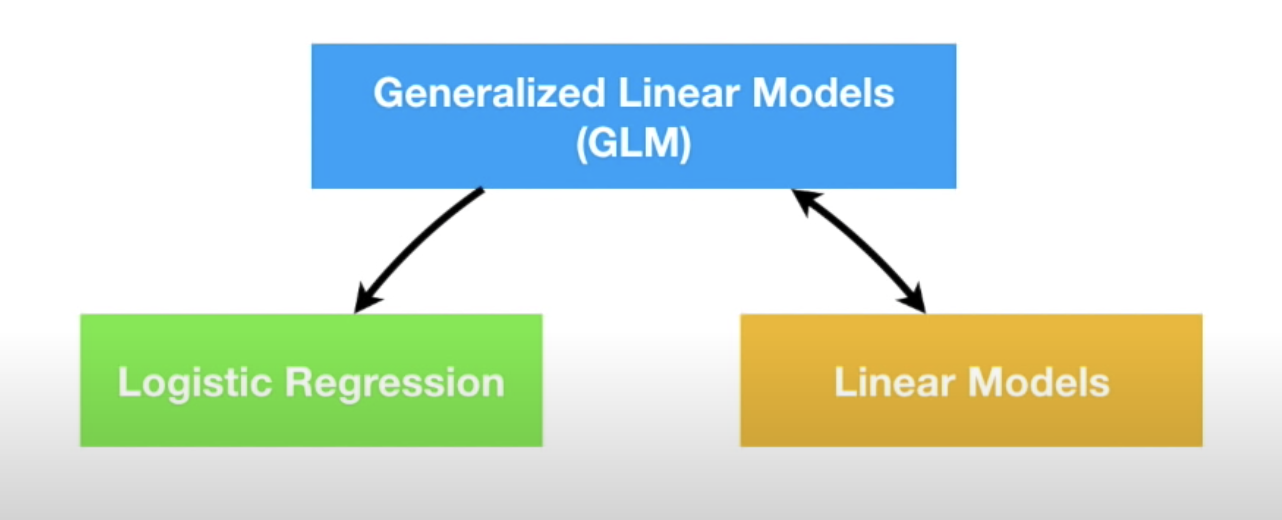
GLM
- Linear models
- Logistic regression
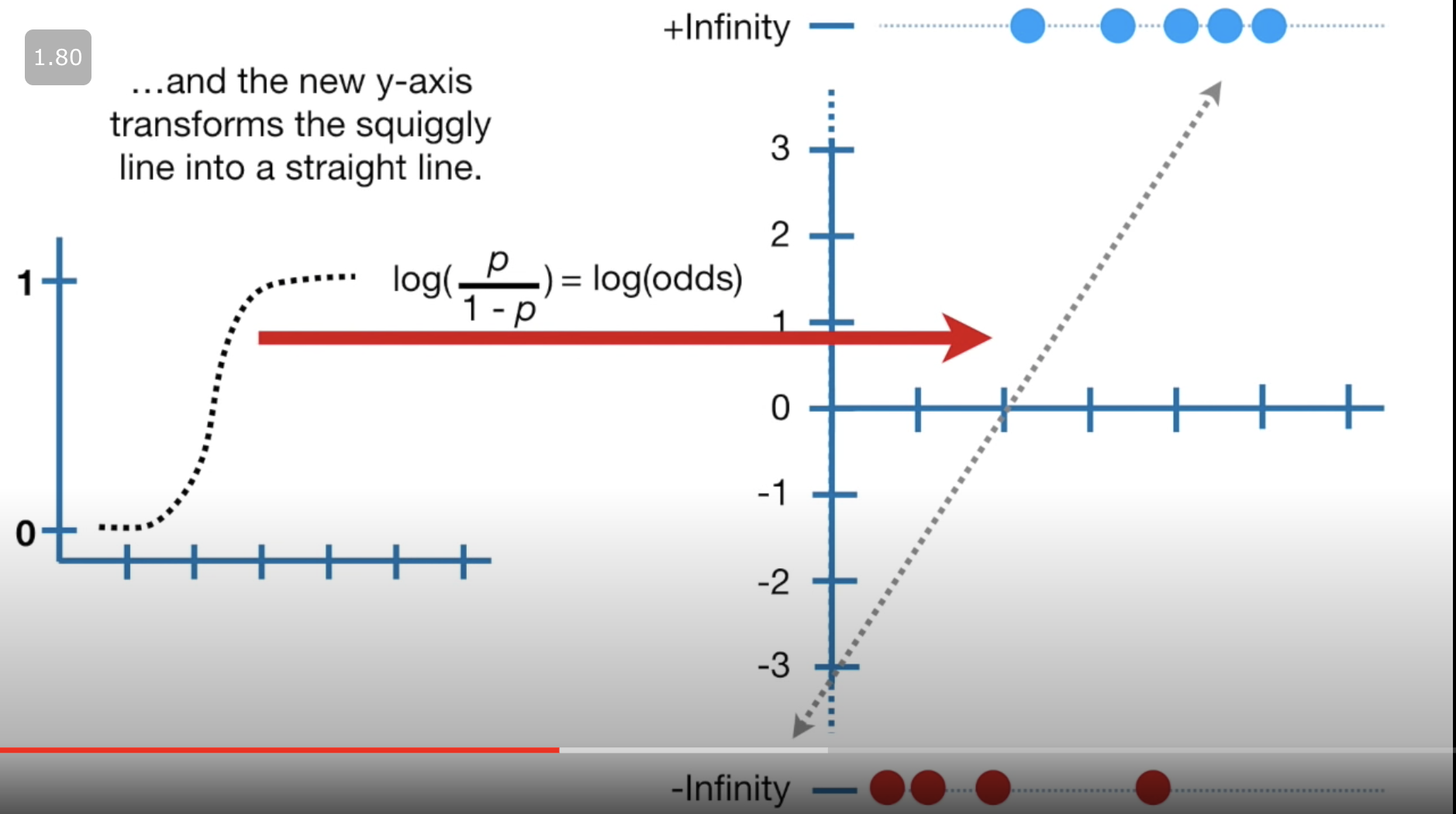
Coefficients
What are the coefficients of logistic regression? log(odds)
Back to the linear models...
Hyperparameter Tuning
Search for optimal alpha and lambda
Grid search
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Morbi nec metus justo. Aliquam erat volutpat.


Maximum iteration
Iteration
One iteration is one pass over the entire data set.
Solvers
Different optimization technique
https://towardsdatascience.com/dont-sweat-the-solver-stuff-aea7cddc3451
Sag, Saga
- sag — Stochastic Average Gradient descent. A variation of gradient descent and incremental aggregated gradient approaches that uses a random sample of previous gradient values. Fast for big datasets.
- saga — Extension of sag that also allows for L1 regularization. Should generally train faster than sag.
Stochastic gradient descent
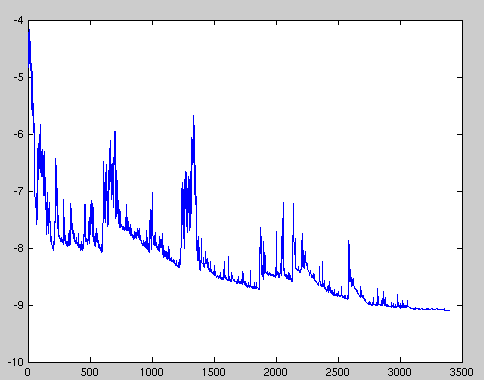
SAG (Stochastic average gradient)

Scoring
F1 (Good for imbalanced class)

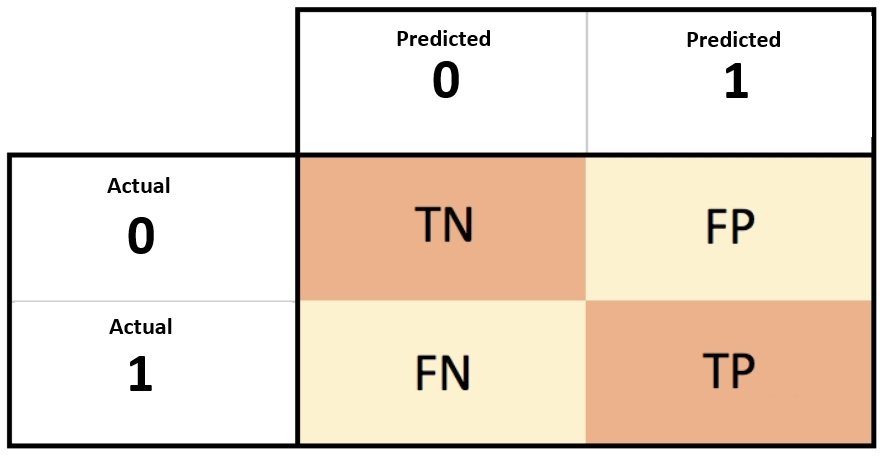
Check threshold
fpr, tpr, thresholds = metrics.roc_curve(y_test, y_pred)Cost - FN
predicted there is no event, but there is actually one
False positive
predicted there is event, but there is none
-> lead to higher cost calculations
Title Text
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Morbi nec metus justo. Aliquam erat volutpat.
Elasticnet -R
- Regularisation strength: In glmnet, higher lambda means more shrinkage. glmnet defaults to 100 lambdas to try
- Standardisation: an glmnet argument standardizes for the data, and the default is TRUE
- CV: k-fold
Python
- Regularisation strength: in the sklearn, C is "the inverse of regularaization strength (lambda). Smaller values specify stronger regularization". scikit LogisticRegressionCV defaults to 10
- Standardisation: no default scaling.
- CV: stratifiedfolds
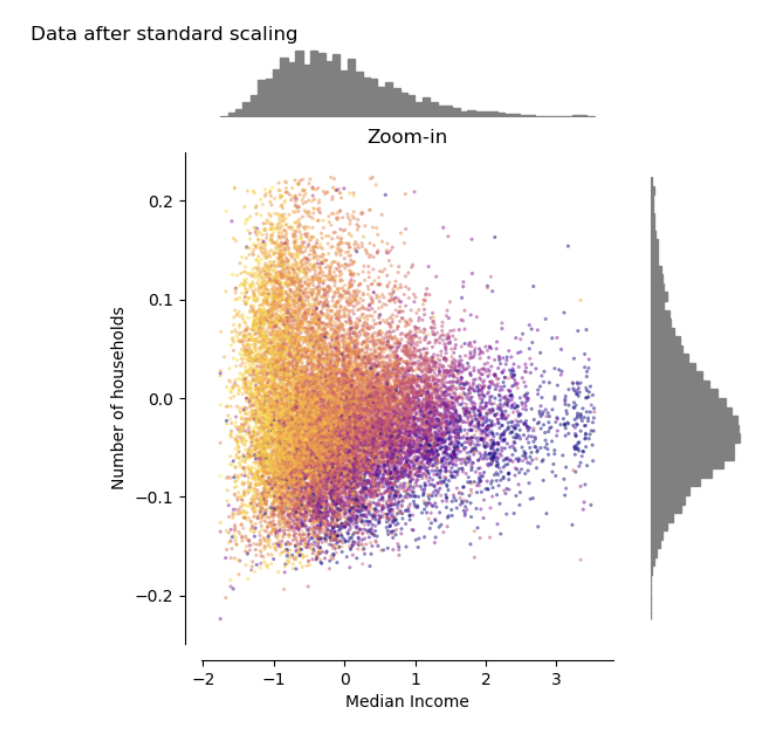
Standardisation
for Iinear regression
Need for linear regression
Standardizing the features makes the convergence faster
Normally not needed for logistic regression
But regularization makes the predictor dependent on the scale of the features.
Standardisation
for logistic regression
Common considersations for classification
- Check class balance
- Experiment with different scaling methods
- Bullet Three
Standard scaler
(Z-score standardisation)
transform the features such that its distribution will have a mean value 0 and standard deviation of 1
Values not within [0, 1]
sensitive to outlier
MinMax Scaler
(Min max normalisation)
rescales the data set such that all feature values are in the range [0, 1]
sensitive to outlier