ResNet & DenseNet
Yu-Hsiu Huang
Quick Facts
- Residual Network (ResNet)
- first proposed by He et al. 2015
- won the ImageNet Large Scale Visual Recognition Challenge in 2015
- Dense Convolutional Network (DenseNet)
- originally from Huang et al. 2017
- Best Paper Award in The Conference on Computer Vision and Pattern Recognition 2017
ResNet
Regular Block
Residual Block
Deeper (more layers), better?
Err...

Andrew Ng
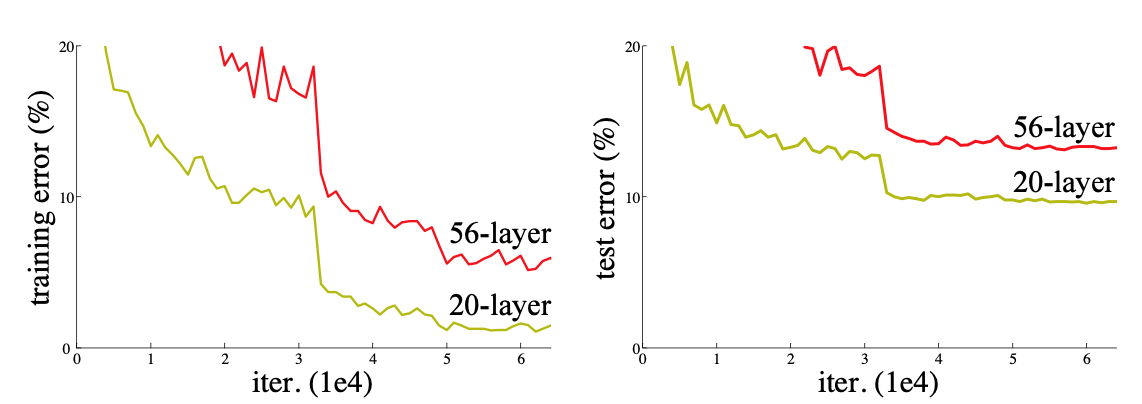
Problem of Plain Networks
He et al. 2015
- Deeper networks have higher training errors.
- He et al. do not explain why this degradation problem happens, but it should relate to optimization.
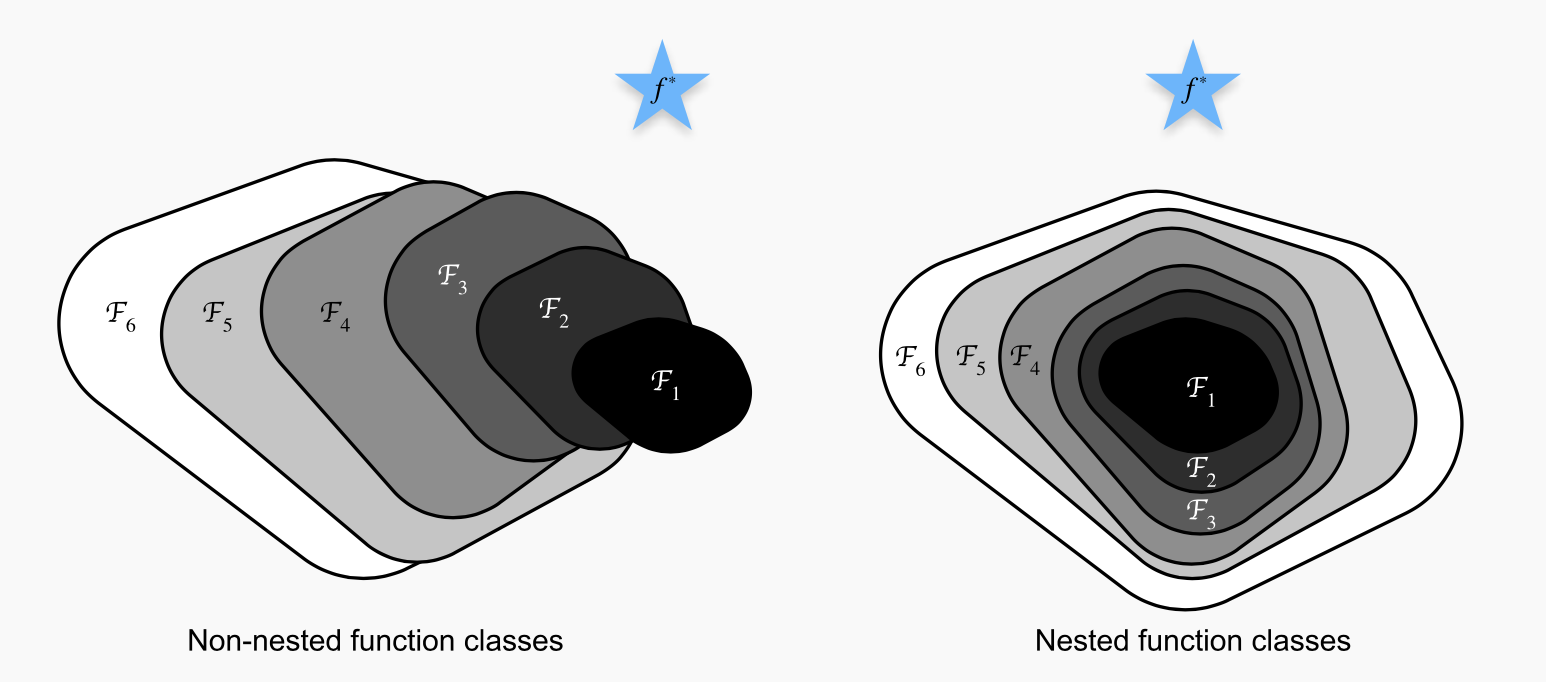
He et al's Idea
D2L
- Ideally, adding more layers to a network should get closer to the true answer
- More-layer networks should at least cover the prediction of the less-layer networks.
non-ideal
ideal
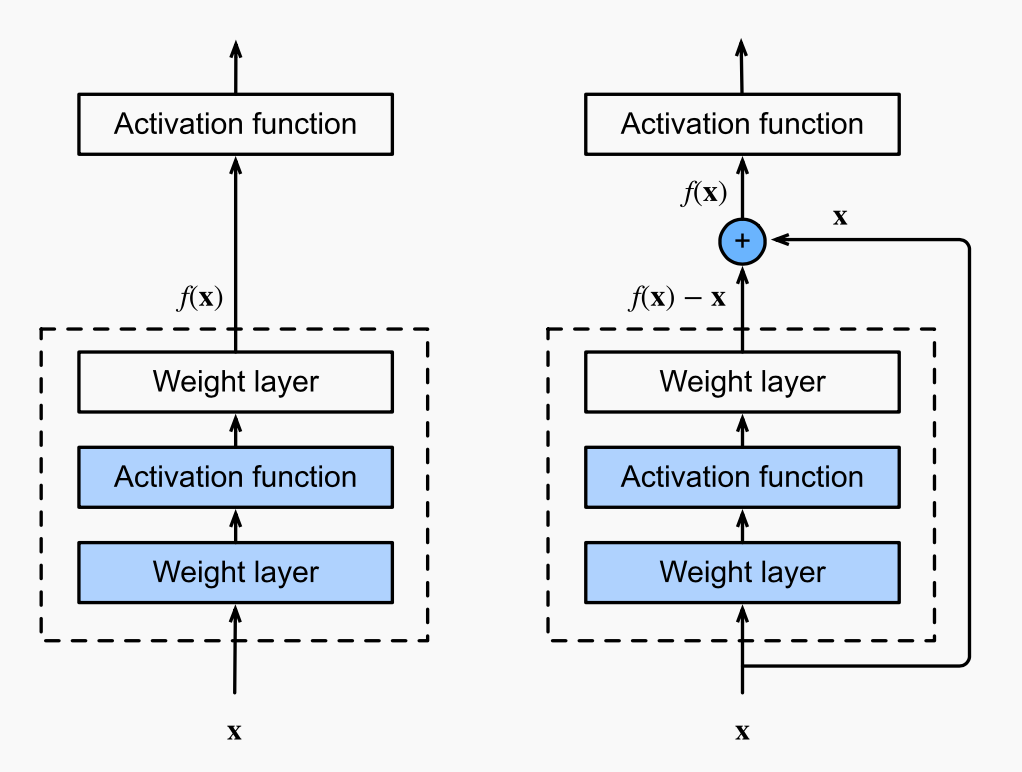
Learn Residual Mapping
Is x fitted well by the previous layer?
Yes
almost zero weighting on f(x)-x
(preserve accuracy)
No
nonzero weighting on f(x)-x
(optimize residual)
output from previous layer
Learn Residual Mapping
When we goes deeper in ResNet, the architecture ensures that the fitting at least covers the prediction from the shallower networks.
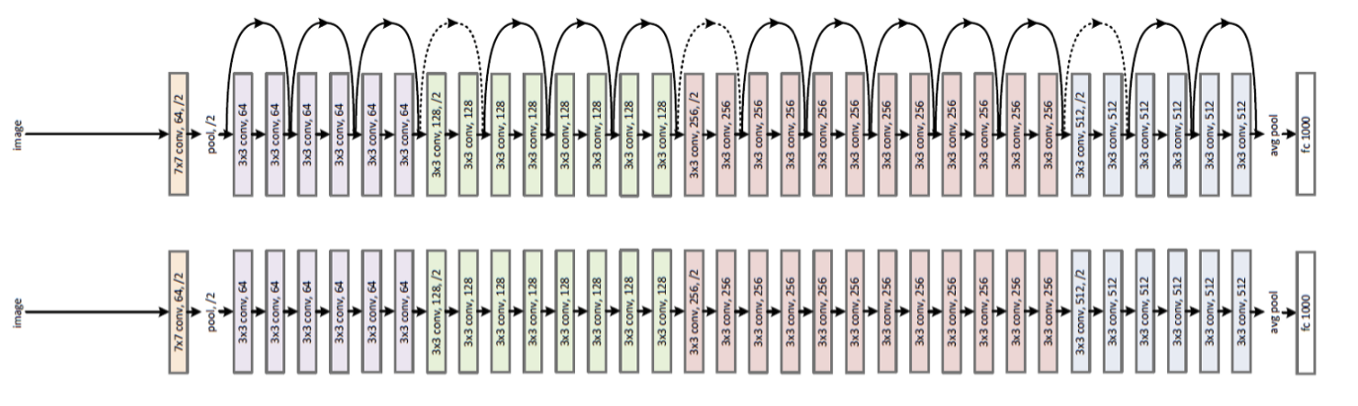
ResNet
Plain
Accuracy Comparison
ResNet
Plain
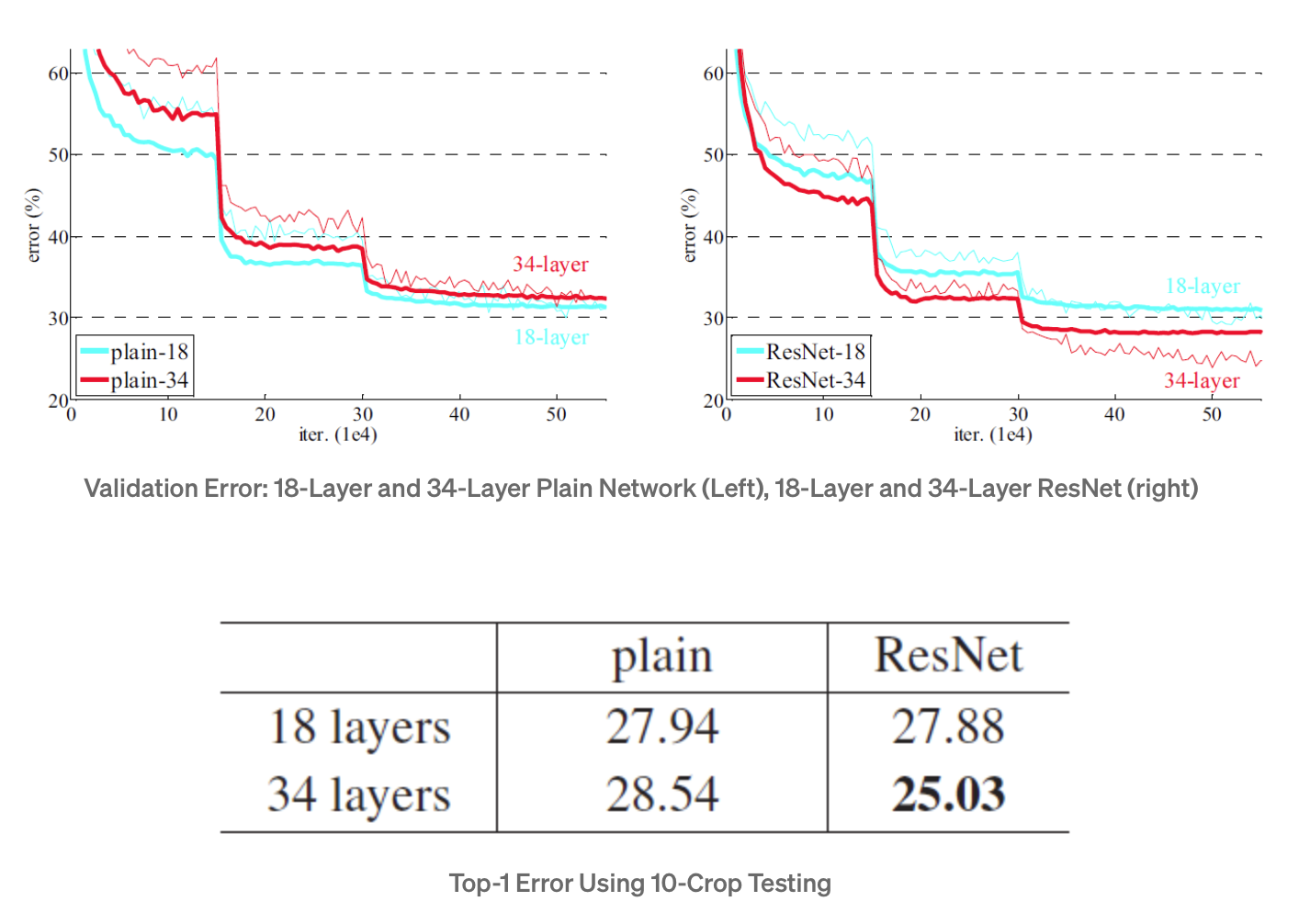
18 layers
34 layers
Usual design: 1x1 Conv layer
To reduce number of channels
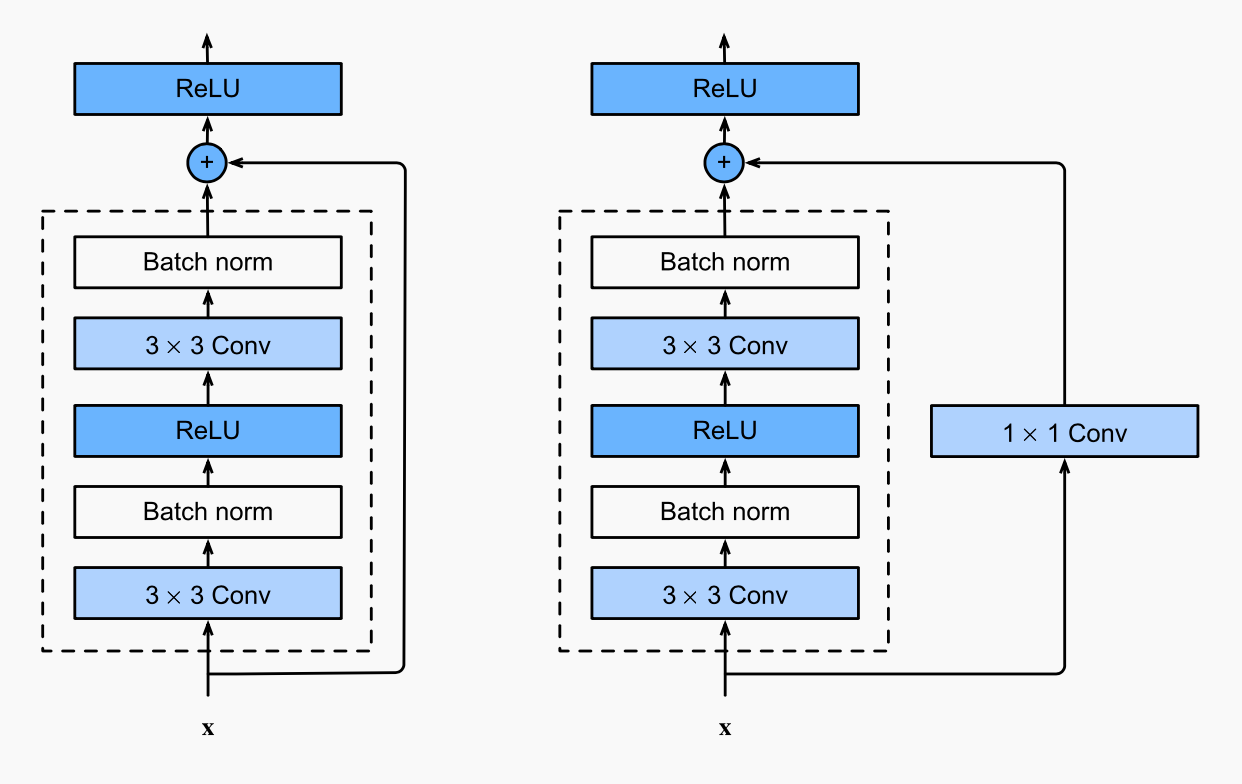
D2L
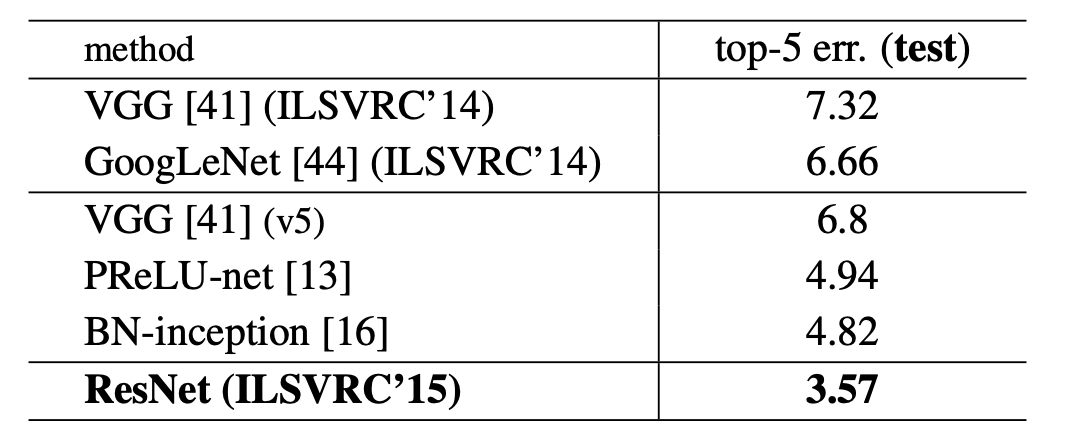
Accuracy Comparison on ImageNet
He et al. 2015
ResNet Application in Astronomy


25 refereed papers for ResNet or ResNet-like networks

DenseNet
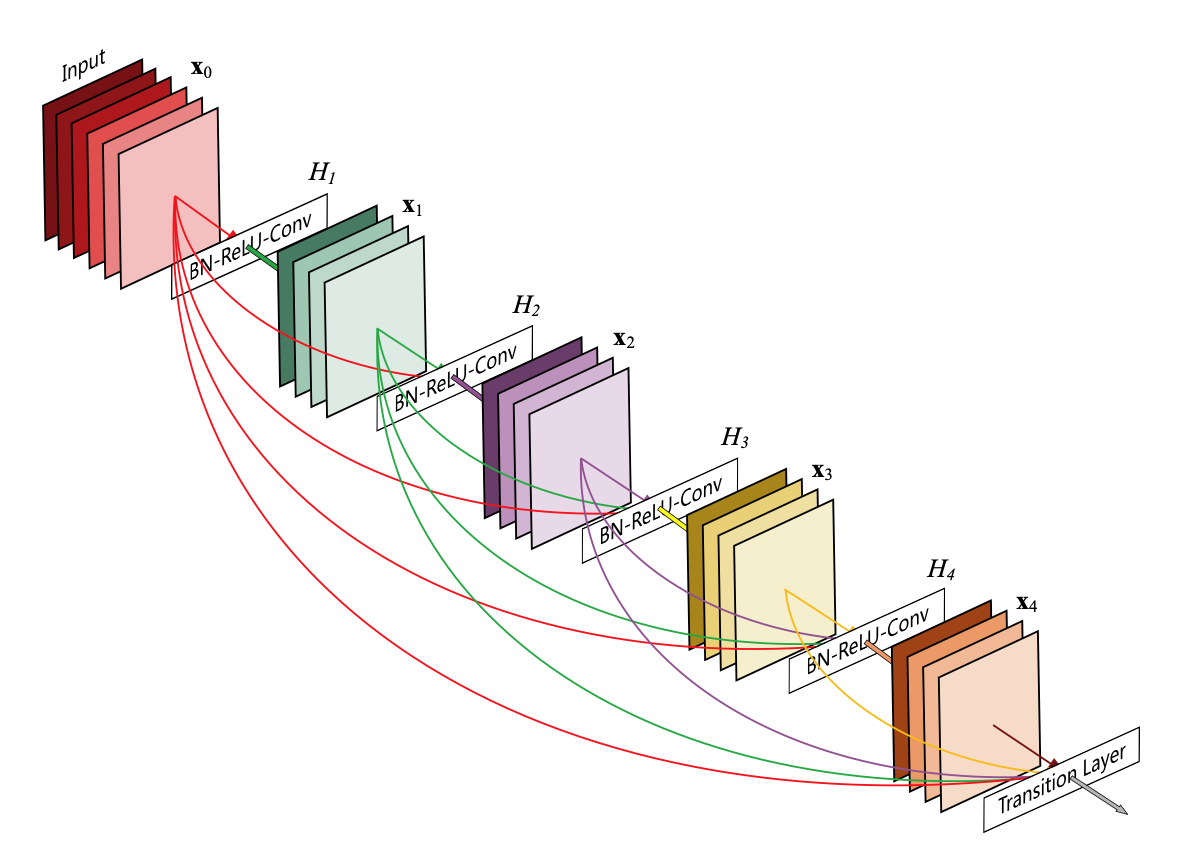
Huang et al. 2017
- Inherit the idea of creating short paths from earlier layers to later layers
- To ensure maximum information flow between layers, DenseNet connect all layers.
Key feature: Concatenation
- In ResNet, element-wise addition is used when implementing identity mapping.
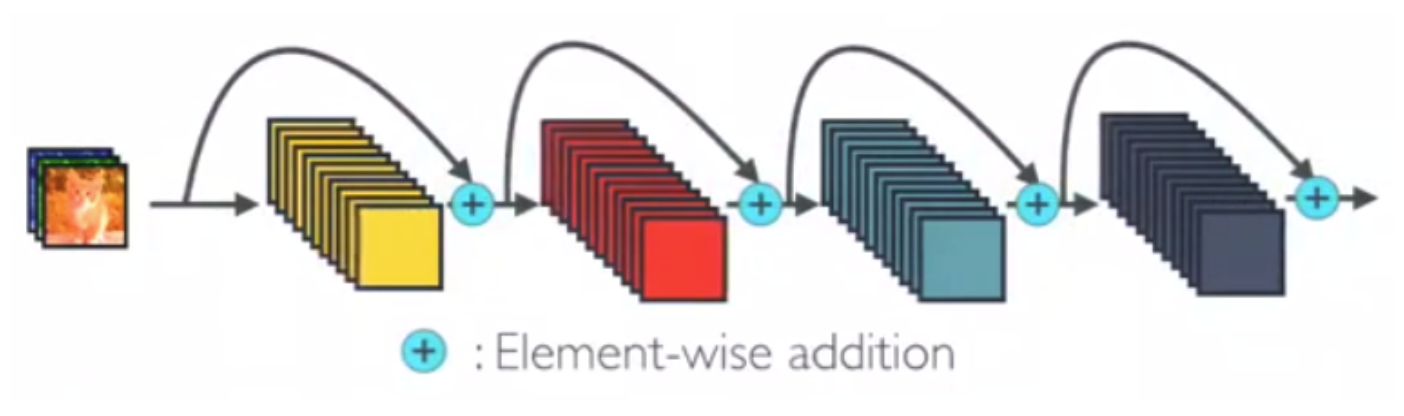
- In DenseNet, concatenation is used. Each layer receives a collective knowledge from all preceding layers.
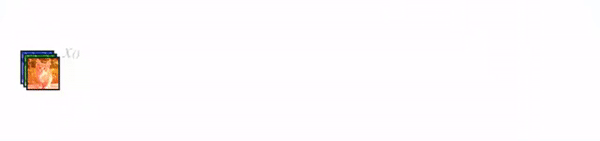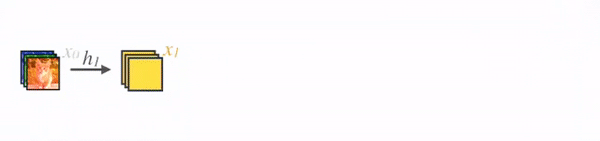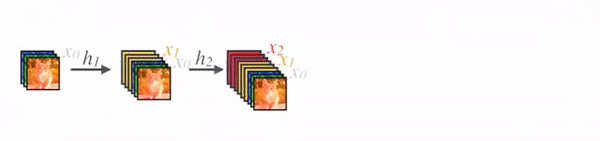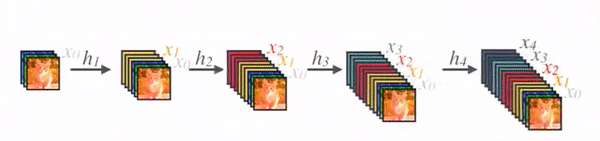
credit: Sik-Ho Tsang
Architecture:
Dense Block + Transition Layer

The concatenation feature will increase the size of feature map, so in reality, a transition lay is added between two dense block to reduce the number of channels.
transition layers
Huang et al. 2017
Advantage of DenseNet
- Increase parameter efficiency: need less parameters
- e.g. At l-th layer, ResNet has C inputs and C outputs; DenseNet has lxk inputs and k outputs. Usually, k<<C.
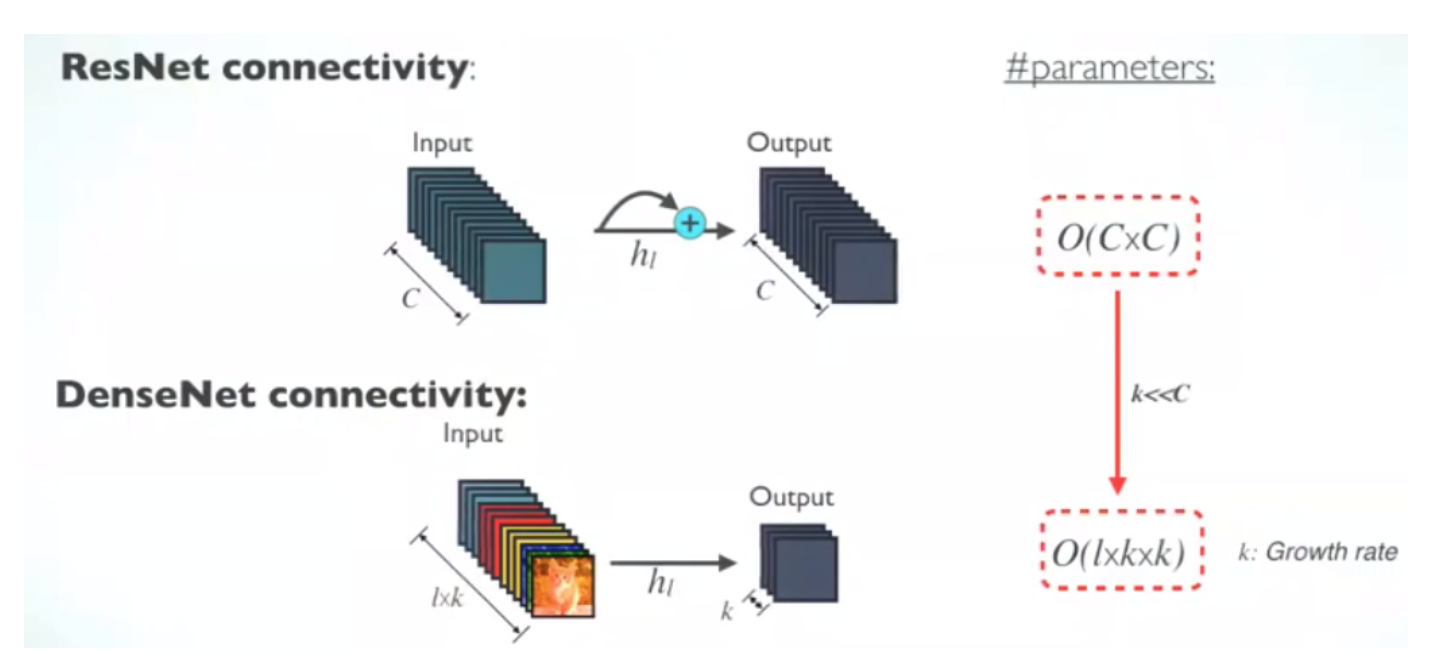
Sik-Ho Tsang, Huang et al 2017
Advantage of DenseNet
- Increase parameter efficiency: need less parameters
- Implicit deep supervision by the short connections
- Deep supervision can improve the accuracy (DSN; Lee et al. 2014)
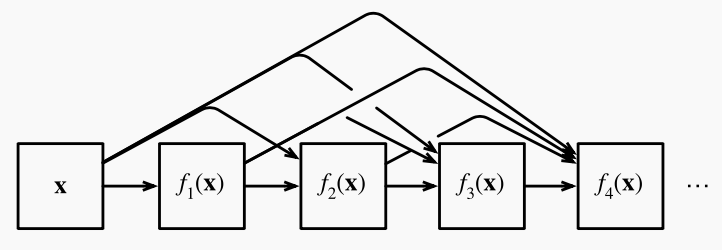
each individual layer in the dense block received additional supervision

DSN improve accuracy
Lee et al. 2014
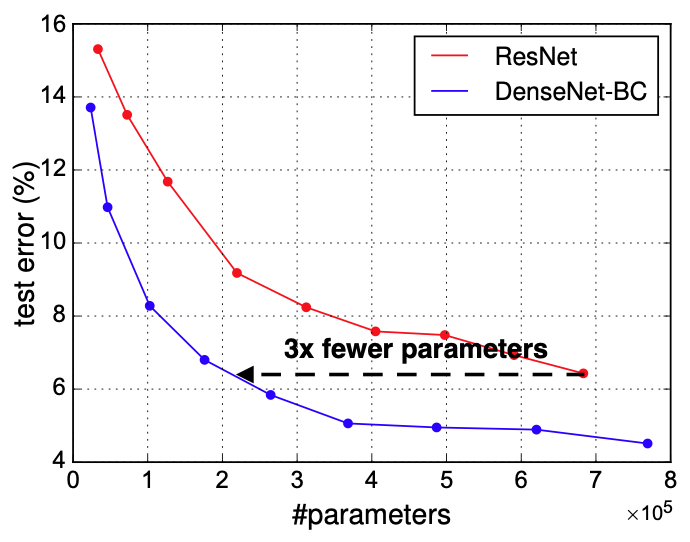
Accuracy Comparison

DenseNet achieve better/similar accuracy than other nets
DenseNet Application in Astronomy
1 refereed paper
Use DenseNet to pre-train model on ImageNet and later reuse this model as galaxy classifier.
Issue of DenseNet:
- high GPU memory
- at least 1000 samples per class
Summary
- ResNet
- A network solves the degradation problem by having residual blocks (identity connections).
- It has large influence on later deep neural
- It is commonly used for image classification nowadays even in astronomy.
- DenseNet
- A network extends the logic of short connections. It addresses the degradation issue as ResNet.
- It achieve higher performance in terms of accuracy by less computation. However, it requires high GPU memory.