Scalable online POMDP planning for safe and efficient autonomy
Zachary Sunberg
Europa
Europa
Europa Lander

Two Objectives for Autonomy
EFFICIENCY
SAFETY
Minimize resource use
(especially time)
Minimize the risk of harm to oneself and others


Safety often opposes Efficiency
Types of Uncertainty
Alleatory
Static Epistemic
Dynamic Epistemic



MDP
Uncertain MDP (RL)
POMDP
Uncertainty in Space Exploration



Thrusters (Alleatory)
Gravity (Epistemic)
Rough Terrain (Alleatory and Epistemic)
Policies of Other Vehicles (Epistemic)
Markov Decision Process (MDP)
- \(\mathcal{S}\) - State space
- \(\mathcal{A}\) - Action space
- \(T:\mathcal{S}\times \mathcal{A} \times\mathcal{S} \to \mathbb{R}\) - Transition probability distribution
- \(R:\mathcal{S}\times \mathcal{A} \to \mathbb{R}\) - Reward

Partially Observable Markov Decision Process (POMDP)

- \(\mathcal{S}\) - State space
- \(\mathcal{A}\) - Action space
- \(T:\mathcal{S}\times \mathcal{A} \times\mathcal{S} \to \mathbb{R}\) - Transition probability distribution
- \(R:\mathcal{S}\times \mathcal{A} \to \mathbb{R}\) - Reward
- \(\mathcal{O}\) - Observation space
- \(Z:\mathcal{S} \times \mathcal{A}\times \mathcal{S} \times \mathcal{O} \to \mathbb{R}\) - Observation probability distribution
Pareto Optimization
Safety
Better Performance
Model \(M_2\), Algorithm \(A_2\)
Model \(M_1\), Algorithm \(A_1\)
Efficiency
$$\underset{\pi}{\mathop{\text{maximize}}} \, \sum_{t=1}^T r_t = \sum_{t=1}^T r_t^\text{E} + \lambda r_t^\text{S}$$
Safety
Weight
Efficiency
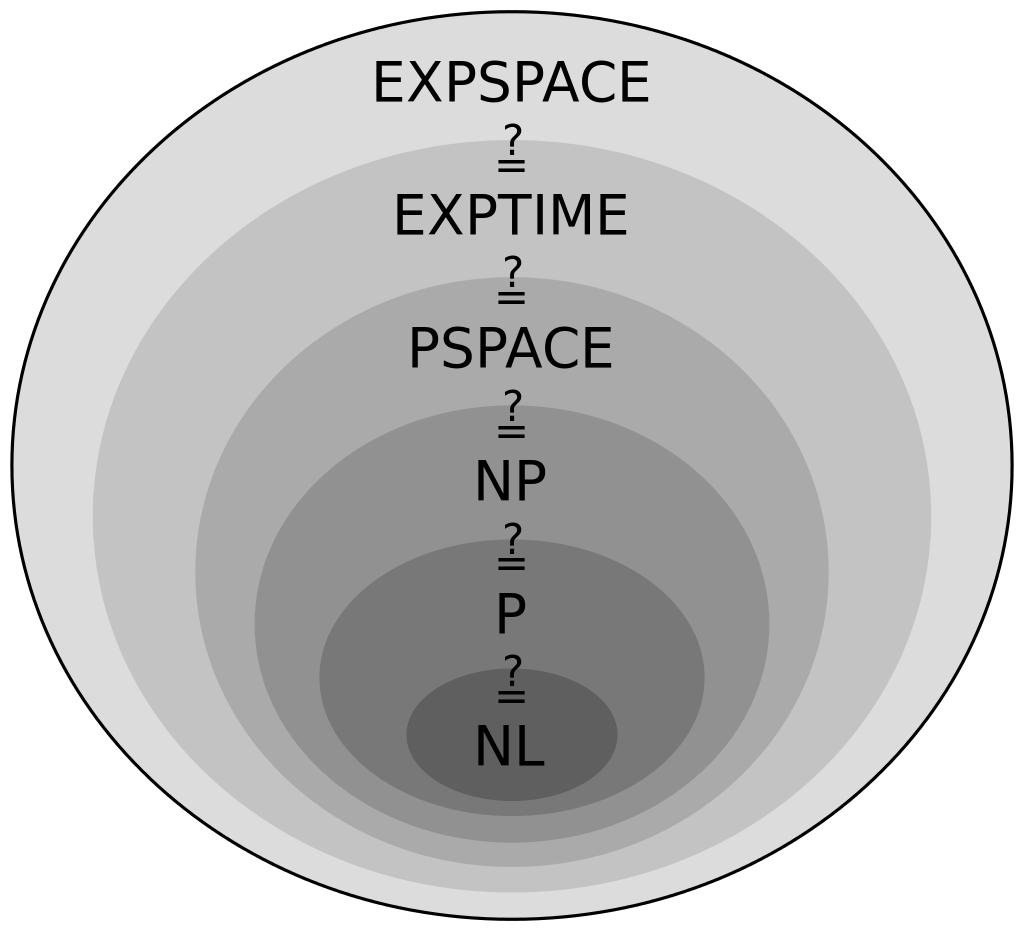
POMDPs are Hard
- Curse of Dimensionality
- Curse of History
- PSPACE-Complete
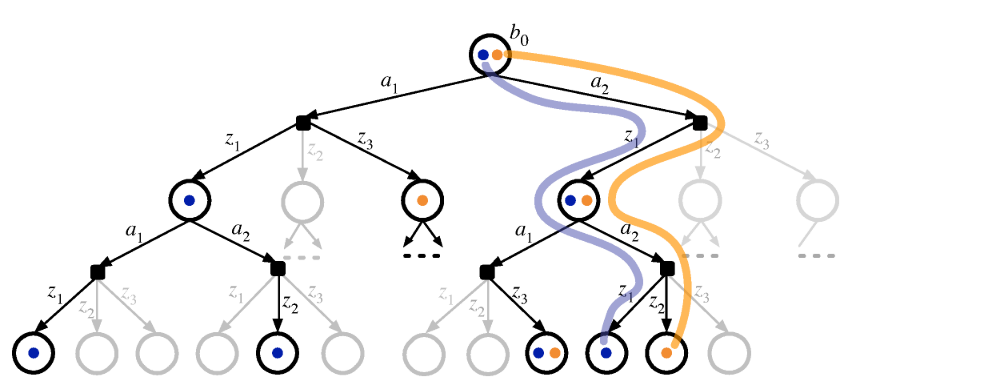
Online Tree Search

Time
Estimate \(Q(s, a)\) based on children
$$Q(s,a) = E\left[\sum_t \gamma^t r_t | s_0 = s, a_0=a\right]$$
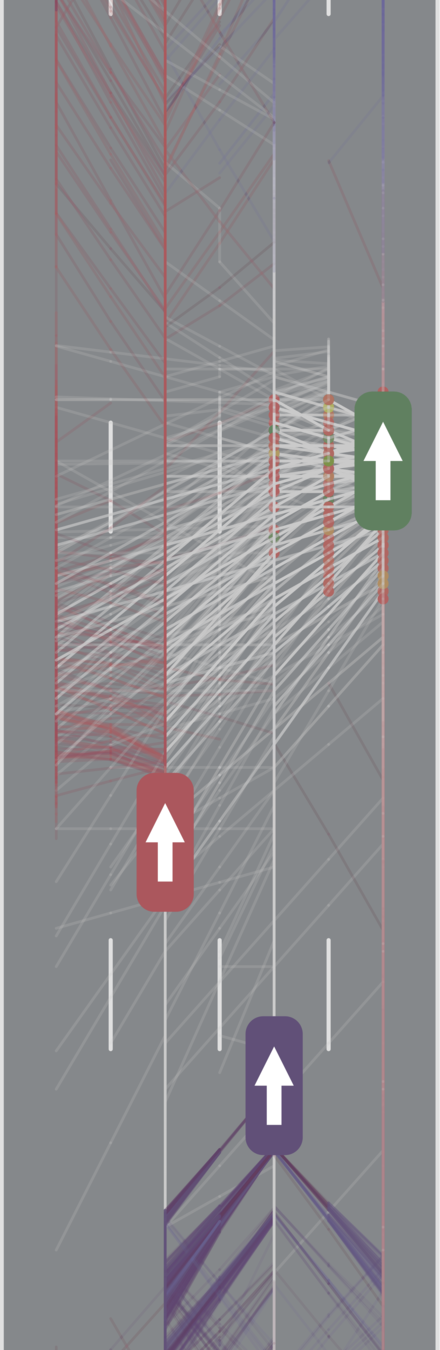
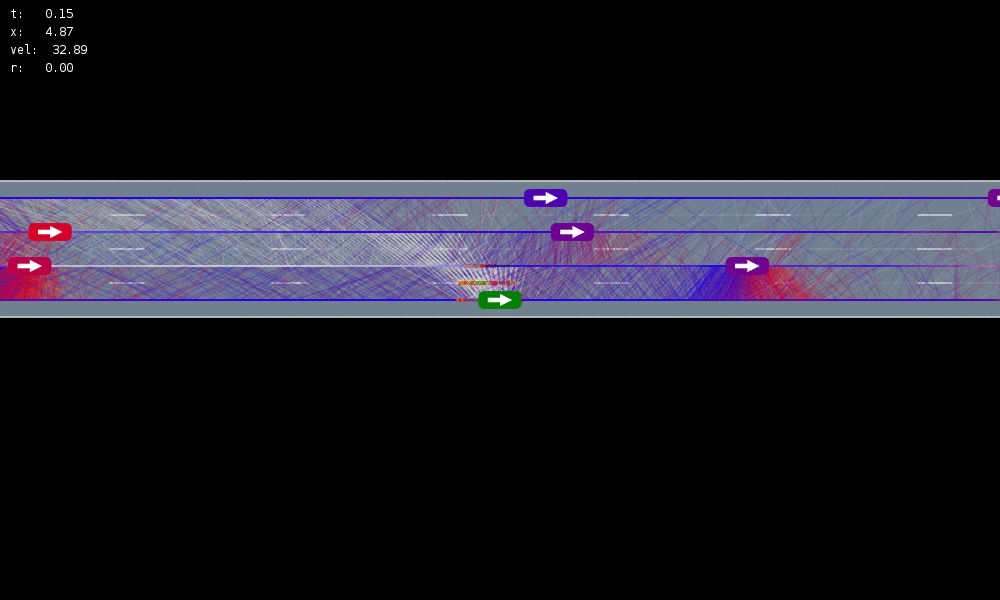
Autonomous Driving
Tweet by Nitin Gupta
29 April 2018
https://twitter.com/nitguptaa/status/990683818825736192

Intelligent Driver Model (IDM)
\ddot{x}_\text{IDM} = a \left[ 1 - \left( \frac{\dot{x}}{\dot{x}_0} \right)^{\delta} - \left(\frac{g^*(\dot{x}, \Delta \dot{x})}{g}\right)^2 \right]
g^*(\dot{x}, \Delta \dot{x}) = g_0 + T \dot{x} + \frac{\dot{x}\Delta \dot{x}}{2 \sqrt{a b}}

[Treiber, et al., 2000] [Kesting, et al., 2007] [Kesting, et al., 2009]
Internal States
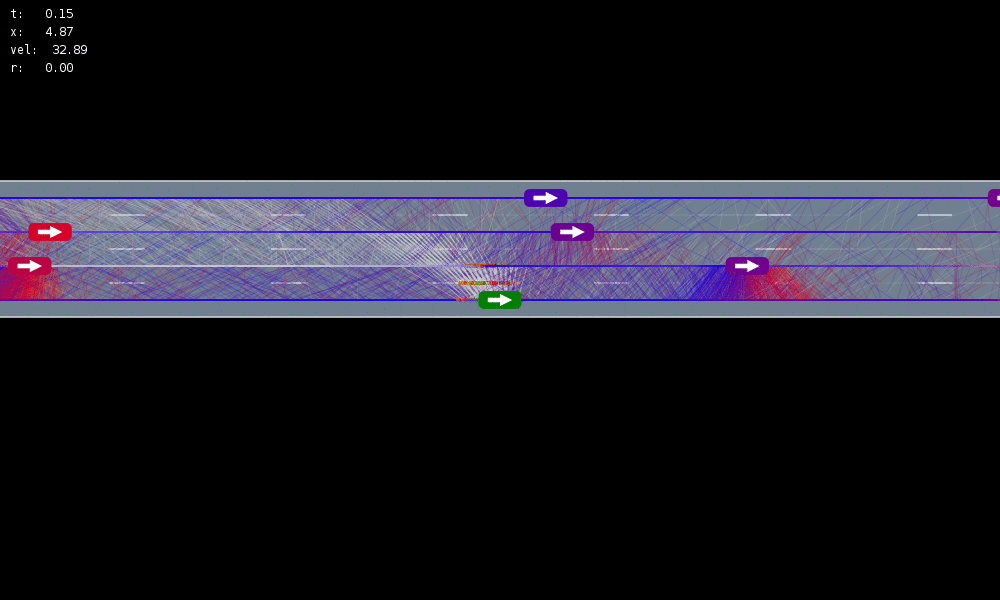






MDP trained on normal drivers



MDP trained on all drivers
Omniscient
POMCPOW (Ours)
Simulation results
[Sunberg & Kochenderfer, ACC 2017, T-ITS Under Review]
Actions
Observations
States
POMDPs with Continuous...
- PO-UCT (POMCP)
- DESPOT
PO-UCT (POMCP)


DESPOT
Actions
Observations
States
POMDPs with Continuous...
- PO-UCT (POMCP)
- DESPOT
\begin{aligned}
& \mathcal{S} = \mathbb{Z} \quad \quad \quad ~~ \mathcal{O} = \mathbb{R} \\
& s' = s+a \quad \quad o \sim \mathcal{N}(s, |s-10|) \\
& \mathcal{A} = \{-10, -1, 0, 1, 10\} \\
& R(s, a) = \begin{cases}
100 & \text{ if } a = 0, s = 0 \\
-100 & \text{ if } a = 0, s \neq 0 \\
-1 & \text{ otherwise}
\end{cases} & \\
\end{aligned}

State
Timestep
Accurate Observations
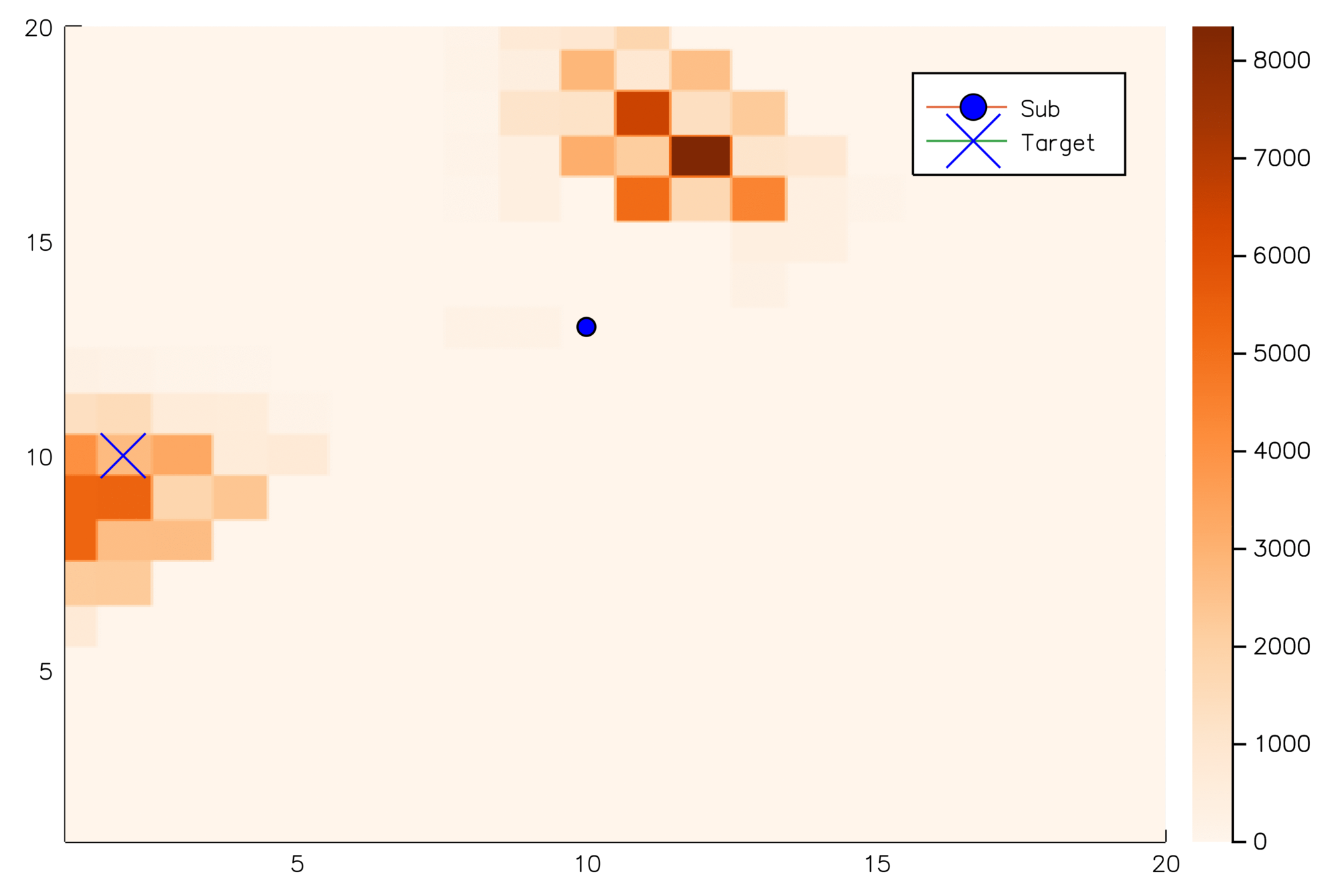
Goal: \(a=0\) at \(s=0\)
Optimal Policy
Localize
\(a=0\)
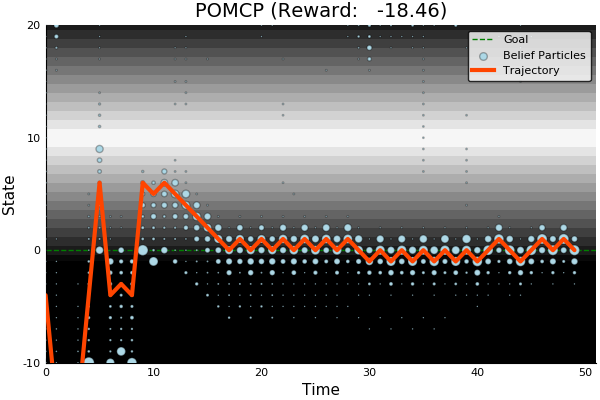
POMDP Example: Light-Dark
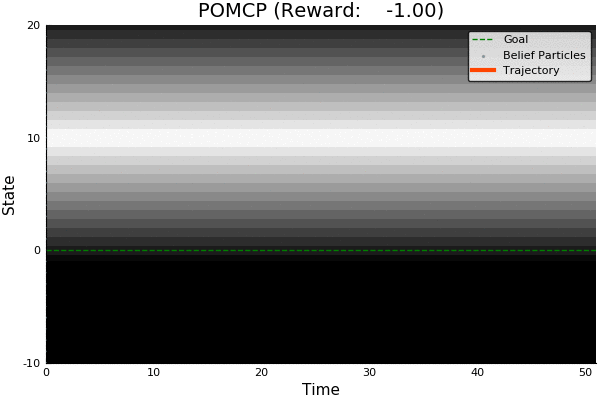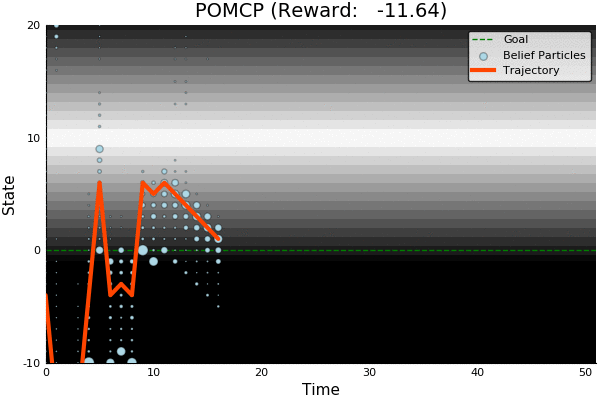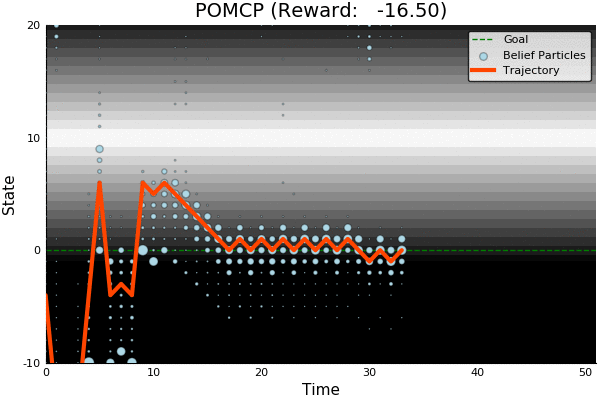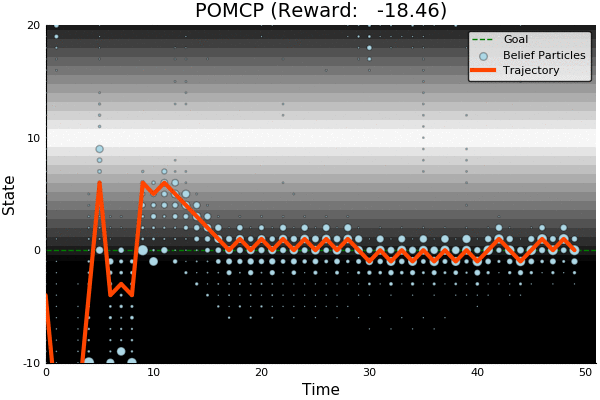


POMCP
POMCP-DPW

-18.46
-18.46
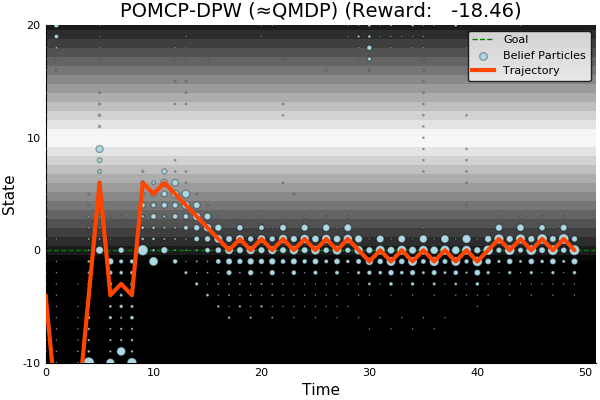
POMCP-DPW converges to QMDP
Proof Outline:
-
Observation space is continuous → observations unique w.p. 1.
-
(1) → One state particle in each belief, so each belief is merely an alias for that state
-
(2) → POMCP-DPW = MCTS-DPW applied to fully observable MDP + root belief state
-
Solving this MDP is equivalent to finding the QMDP solution → POMCP-DPW converges to QMDP



Sunberg, Z. N. and Kochenderfer, M. J. "Online Algorithms for POMDPs with Continuous State, Action, and Observation Spaces", ICAPS (2018)
POMDP Solution
QMDP


\[\underset{\pi: \mathcal{B} \to \mathcal{A}}{\mathop{\text{maximize}}} \, V^\pi(b)\]
\[\underset{a \in \mathcal{A}}{\mathop{\text{maximize}}} \, \underset{s \sim{} b}{E}\Big[Q_{MDP}(s, a)\Big]\]
Same as full observability on the next step
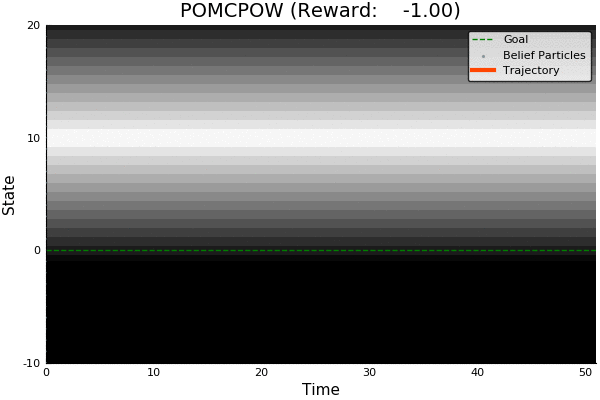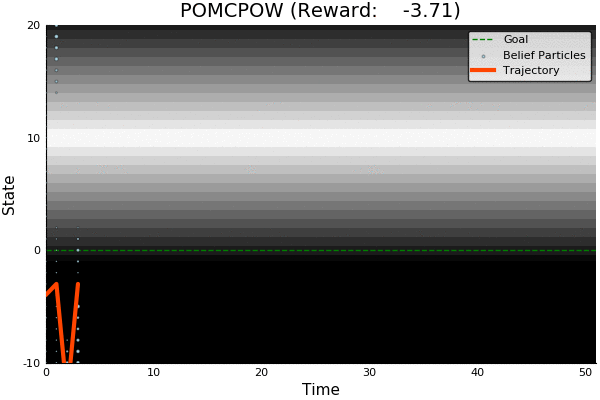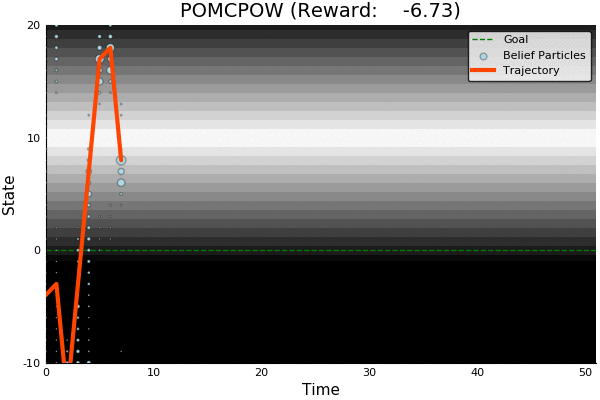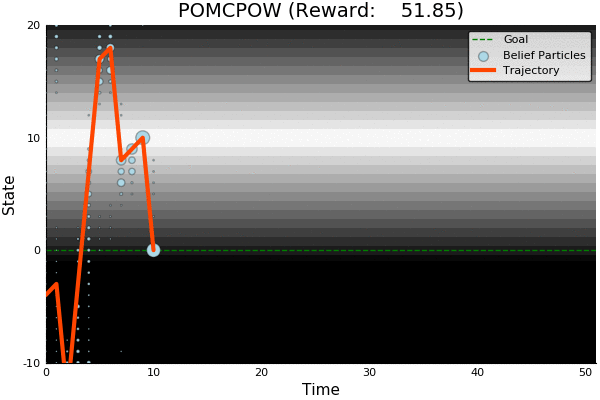


POMCP
POMCP-DPW
POMCPOW
-18.46
-18.46
51.85
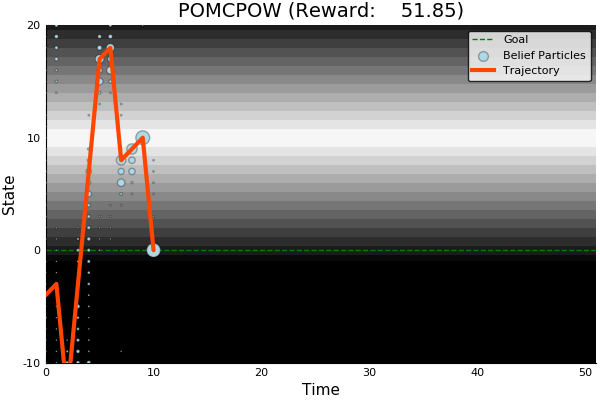

[Sunberg ICAPS 2018, Thesis]

Continuous Observation Analytical Results (POWSS)


Our simplified algorithm is near-optimal
[Lim, Tomlin, & Sunberg, IJCAI 2020]
Actions
Observations
States
POMDPs with Continuous...
- PO-UCT (POMCP)
- DESPOT
- POMCPOW
- DESPOT-α
- LABECOP
DESPOT-α
LABECOP
Actions
Observations
States
POMDPs with Continuous...
- PO-UCT (POMCP)
- DESPOT
- POMCPOW
- DESPOT-α
- LABECOP
- GPS-ABT
- VG-MCTS
- BOMCP
- VOMCPOW
GPS-ABT
(GPS = Generalized Pattern Search)
Value Gradient MCTS

$$a' = a + \eta \nabla_a Q(s, a)$$

BOMCP


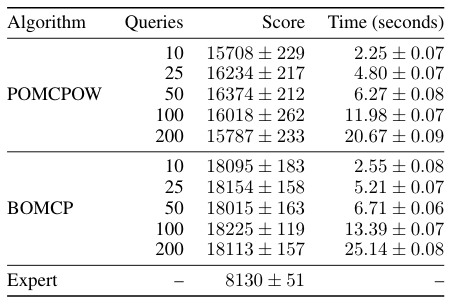
[Mern, Sunberg, et al. AAAI 2021]
Voronoi Progressive Widening
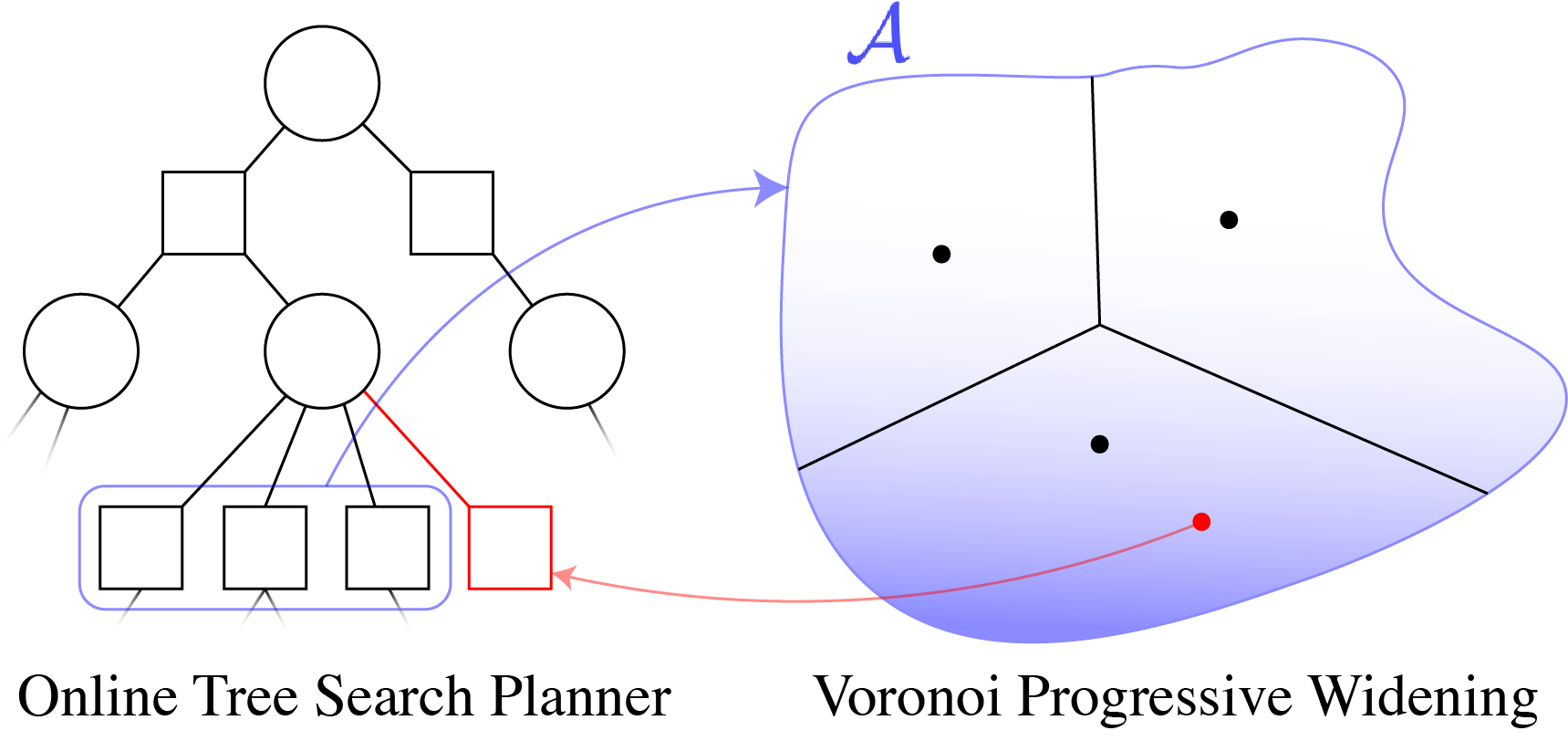
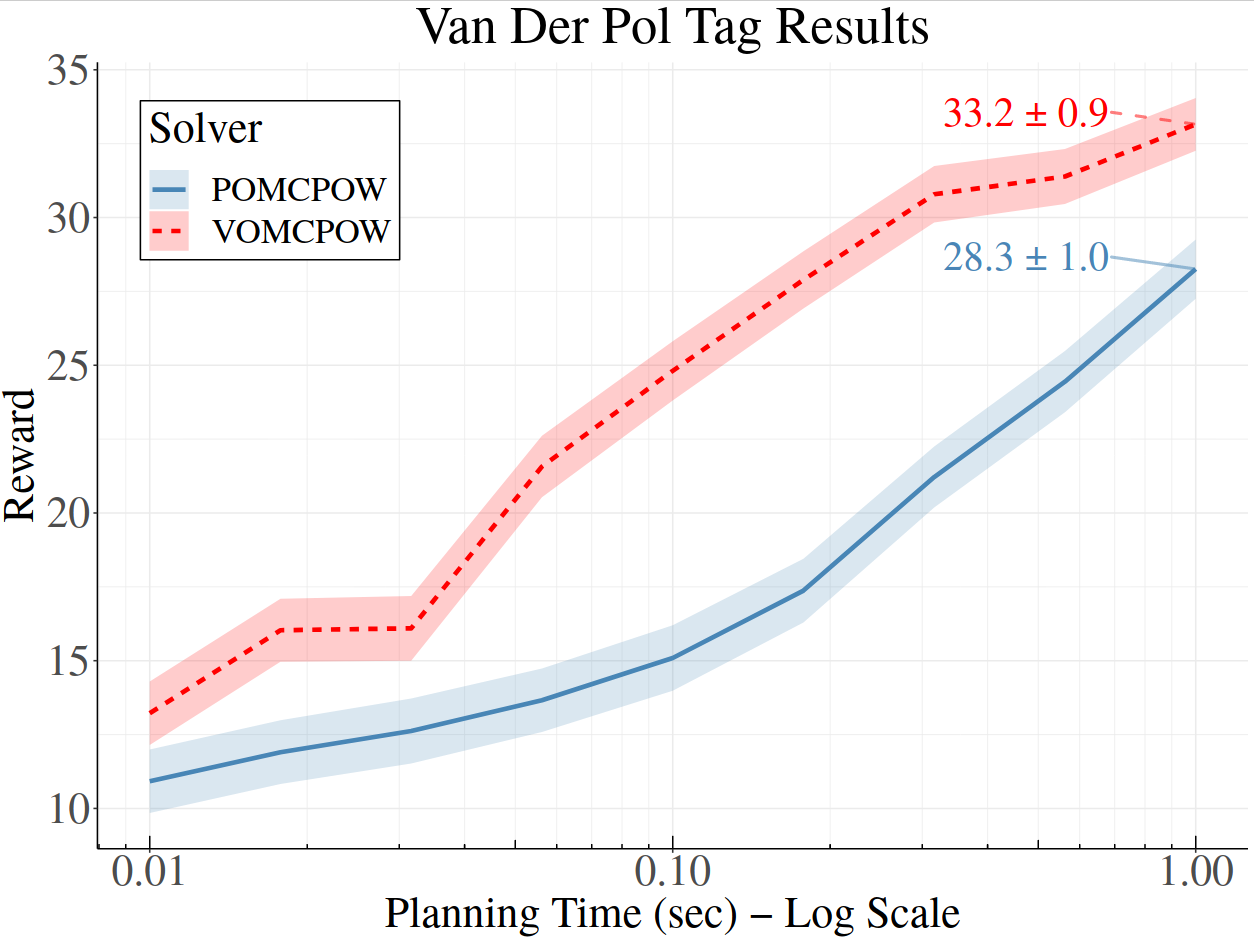

[Lim, Tomlin, & Sunberg ICAPS 2021 (Submitted)]
Future: POMDPs with High-Dimensional Observations

Future: Responding to UAV Emergencies
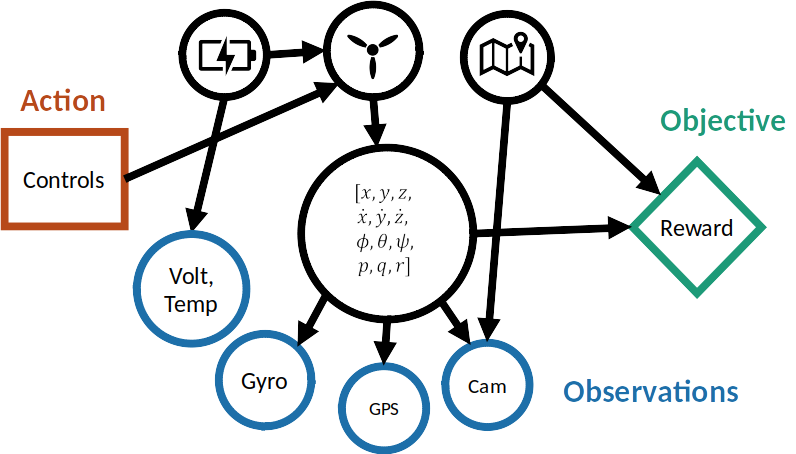
Open Source Software
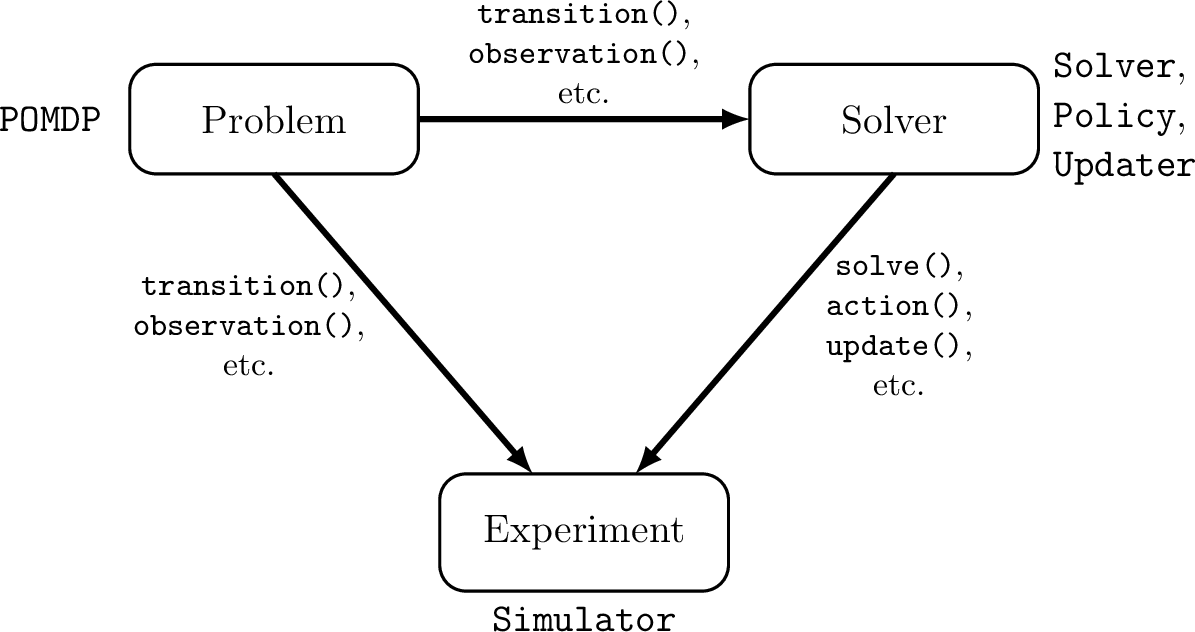
POMDPs.jl - An interface for defining and solving MDPs and POMDPs in Julia
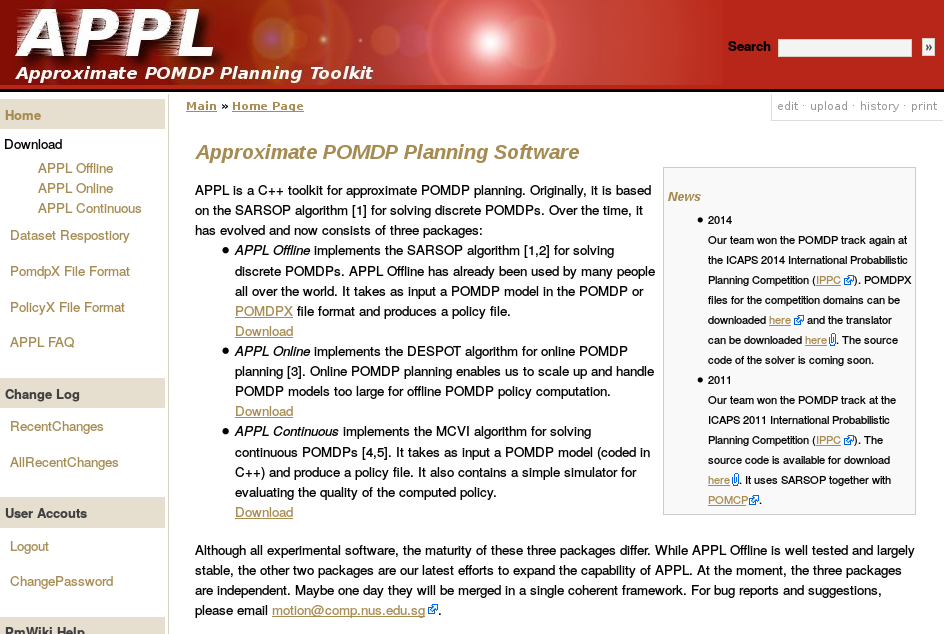
Previous C++ framework: APPL
"At the moment, the three packages are independent. Maybe one day they will be merged in a single coherent framework."

Julia - Speed

Celeste Project
1.54 Petaflops



Thank You!

JPL Online POMDPs
By Zachary Sunberg



