Duality in
Structured and Federated Optimization
Zhenan Fan
Microsoft Research Asia
November 22th, 2022
Outline
1
Duality
in
Optimization
Structured
Optimization
Federated
Learning
2
3
Duality in Optimization
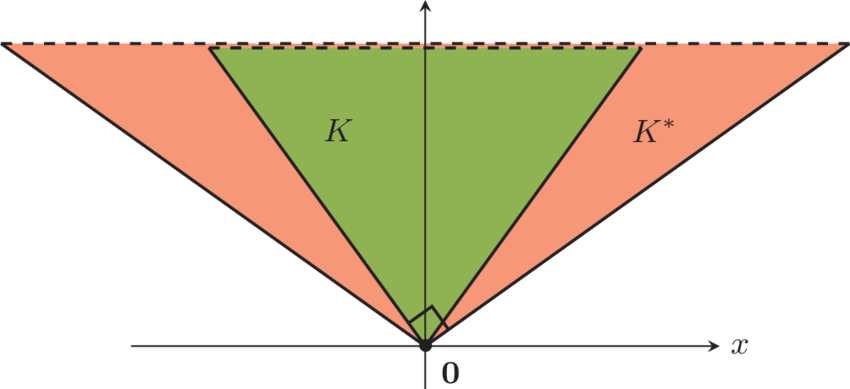
Primal and Dual
Optimization is everywhere
-
machine learning
-
signal processing
-
data mining
Primal problem
Dual problem
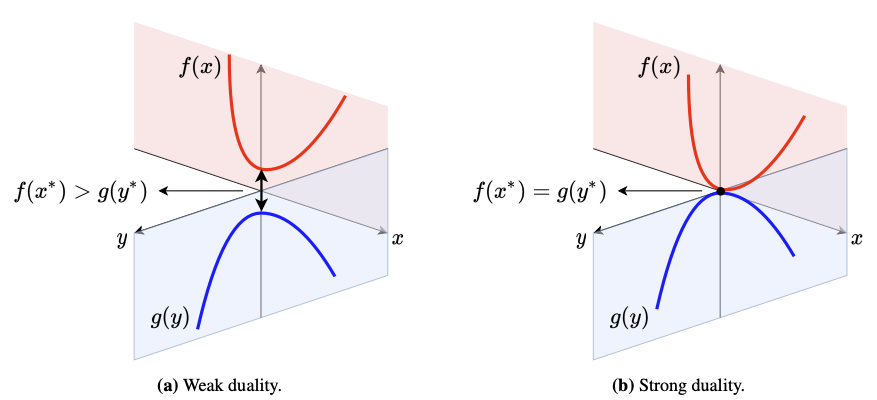
Weak duality
(always hold)
Strong duality
(Under some domain qualification)
Dual Optimization
Possible advantages
-
parallelizable [Boyd et al.'11] -
better convergence rate [Shalev-Shwartz & Zhang.'13] -
smaller dimension [Friedlander & Macêdo'16]
Possible dual formulations
-
Fenchel-Rockafellar dual [Rockafellar'70] -
Lagrangian dual [Boyd & Vandenberghe'04] -
Gauge dual [Friedlander, Macêdo & Pong'04]
(All these different dual formulations can be intepreted using the perturbation framework proposed by [Rockafellar & Wets'98])
Structured Optimization
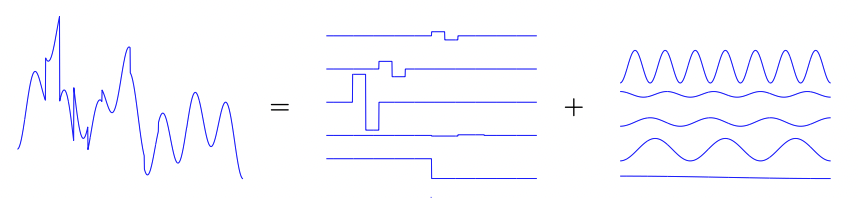
Structured Data-Fitting
Atomic decomposition: mathematical modelling for structure
[Chen, Donoho & Sauders'01; Chandrasekaran et al.'12]
linear map
observation
sparse low-rank smooth
variables
cardinality
weight
atom
atomic set
- sparse n-vectors
-
low-rank matrices
Example: Separating Stars and Galaxy

[Chen, Donoho & Sauders'98; Donoho & Huo'01]
Example: Separating Chessboard and Chess

[Chandrasekaran et al.'09; Candès et al.'09]
Example: Multiscale Low-rank Decomposition

[Ong & Lustig'16]
Roadmap
Convex relaxation with guarantee
Primal-dual relationship and dual-based algorithm
Efficient primal-retrieval strategy
Fan, Z., Jeong, H., Joshi, B., & Friedlander, M. P. Polar Deconvolution of Mixed Signals. IEEE Transactions on Signal Processing (2021).
Fan, Z., Jeong, H., Sun, Y., & Friedlander, M. P. Atomic decomposition via polar alignment: The geometry of structured optimization. Foundations and Trends® in Optimization (2020).
Fan, Z., Fang, H. & Friedlander, M. P. Cardinality-constrained structured data-fitting problems. To appear in Open Journal of Mathematical Optimization (2022).
Convex Relaxation
Gauge function: sparsity-inducing regularizer [Chandrasekaran et al.'12]
Examples
- sparse n-vectors
-
low-rank matrices
Structured convex optimization [FJJF, IEEE-TSP'21]
Minimizing gauge function can promote atomic sparsity!
structure assumption
data-fitting constraint
Recovery Guarantee
Theorem [FJJF, IEEE-TSP'21]
If the ground-truth signals are incoherent and the measurement are gaussian, then with high probability

Primal-dual Correspondence
Primal problem
Dual problem
Theorem [FSJF, FNT-OPT'21]
Let
and
denote optimal primal and dual solutions. Under mild assumptions,
Dual-based Algorithm
(Projection can be computed approximately using Frank-Wolfe.)
Complexity
projection steps
or
Frank-Wolfe steps
A variant of the level-set method developed by [Aravkin et al.'18]
Primal-retrieval Strategy
Can we retrieve primal variables from near-optimal dual variable?
Theorem [FFF, Submitted'22]
Let
denote the duality gap. Under mild assumptions,
Open-source Package https://github.com/MPF-Optimization-Laboratory/AtomicOpt.jl
(equivalent to unconstrained least square when atomic sets are symmetric)
Federated Learning
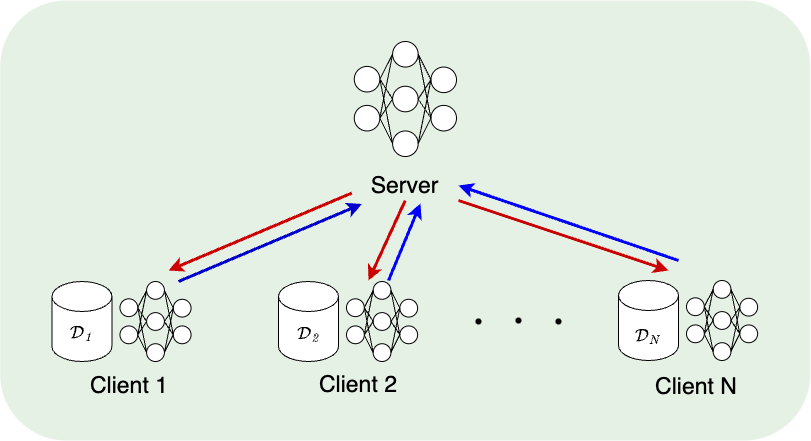
Motivation
Setting
Definition
Federated learning is a collaborative learning framework that can keep data sets private.
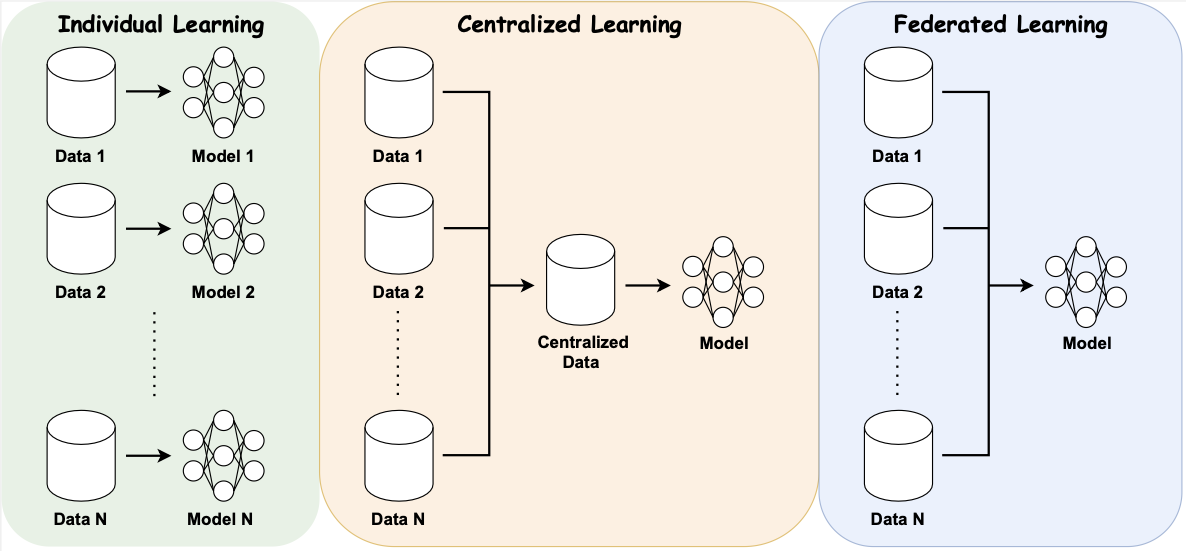
Decentralized data sets, privacy concerns
Horizontal and Vertical Federated Learning
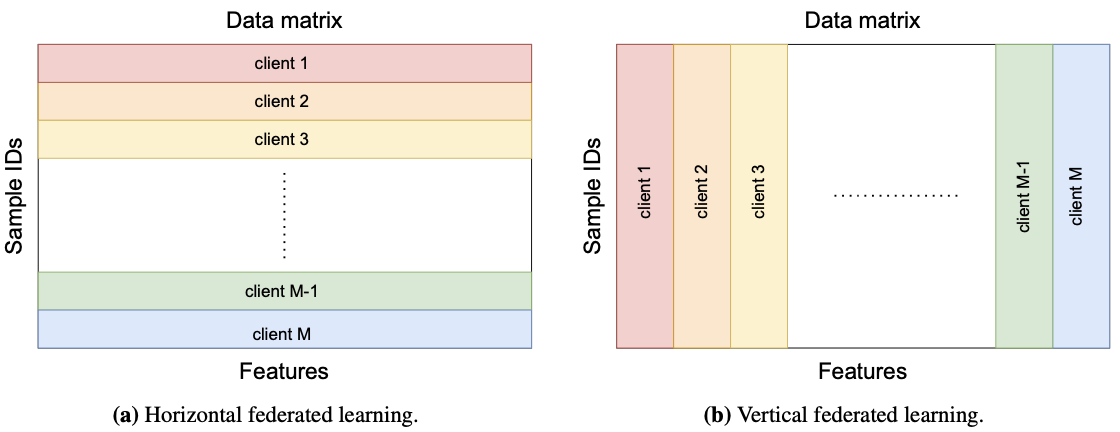
Roadmap
Federated optimization
Fan, Z., Fang, H. & Friedlander, M. P. FedDCD: A Dual Approach for Federated Learning. Submitted (2022).
Knowledge-injected federated learning
Fan, Z., Zhou, Z., Pei, J., Friedlander, M. P., Hu, J., Li, C. & Zhang, Y. Knowledge-Injected Federated Learning. Submitted (2022).
Contribution valuation in federated learning
Fan, Z., Fang, H., Zhou, Z., Pei, J., Friedlander, M. P., Liu, C., & Zhang, Y. Improving Fairness for Data Valuation in Horizontal Federated Learning. IEEE International Conference on Data Engineering (ICDE 2022).
Fan, Z., Fang, H., Zhou, Z., Pei, J., Friedlander, M. P., & Zhang, Y. Fair and efficient contribution valuation for vertical federated learning. Submitted (2022).
Federated Optimization
Important features of federated optimization
-
communication efficiency
-
data privacy
-
data heterogeneity
-
computational constraints
model
number of clients
local dataset
loss function
Primal-based Algorithm
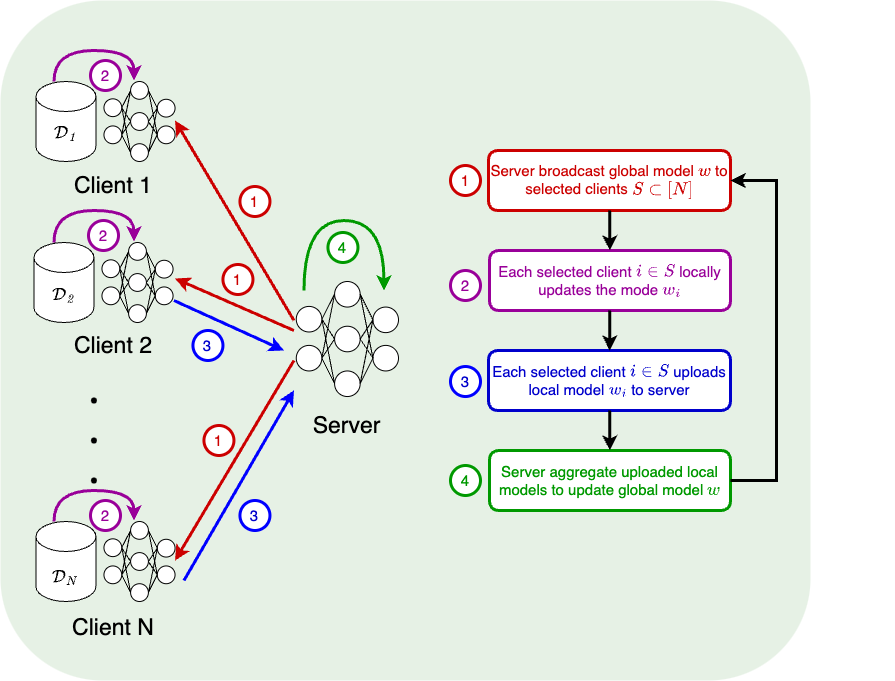
FedAvg [McMahan et al.'17]
SCAFFOLD [Karimireddy et al.'20]
Dual-based Algorithm
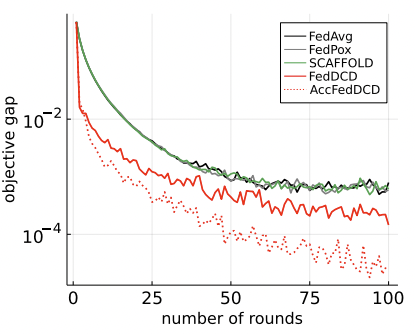
Federated dual coordinate descent (FedDCD) [FFF, Submitted'22]
Each selected client approximately compute dual gradient and upload to server
Server adjusts the gradients (to keep feasibility) and broadcasts to selected clients
Each selected client locally updates the dual model
(A extension of [Necoara et al.'17]: inexact gradient, acceleration)
conjugate function
local dual model
Communication Rounds

Setting
Open-source Package https://github.com/ZhenanFanUBC/FedDCD.jl
Knoledge-Injected Federated Learning
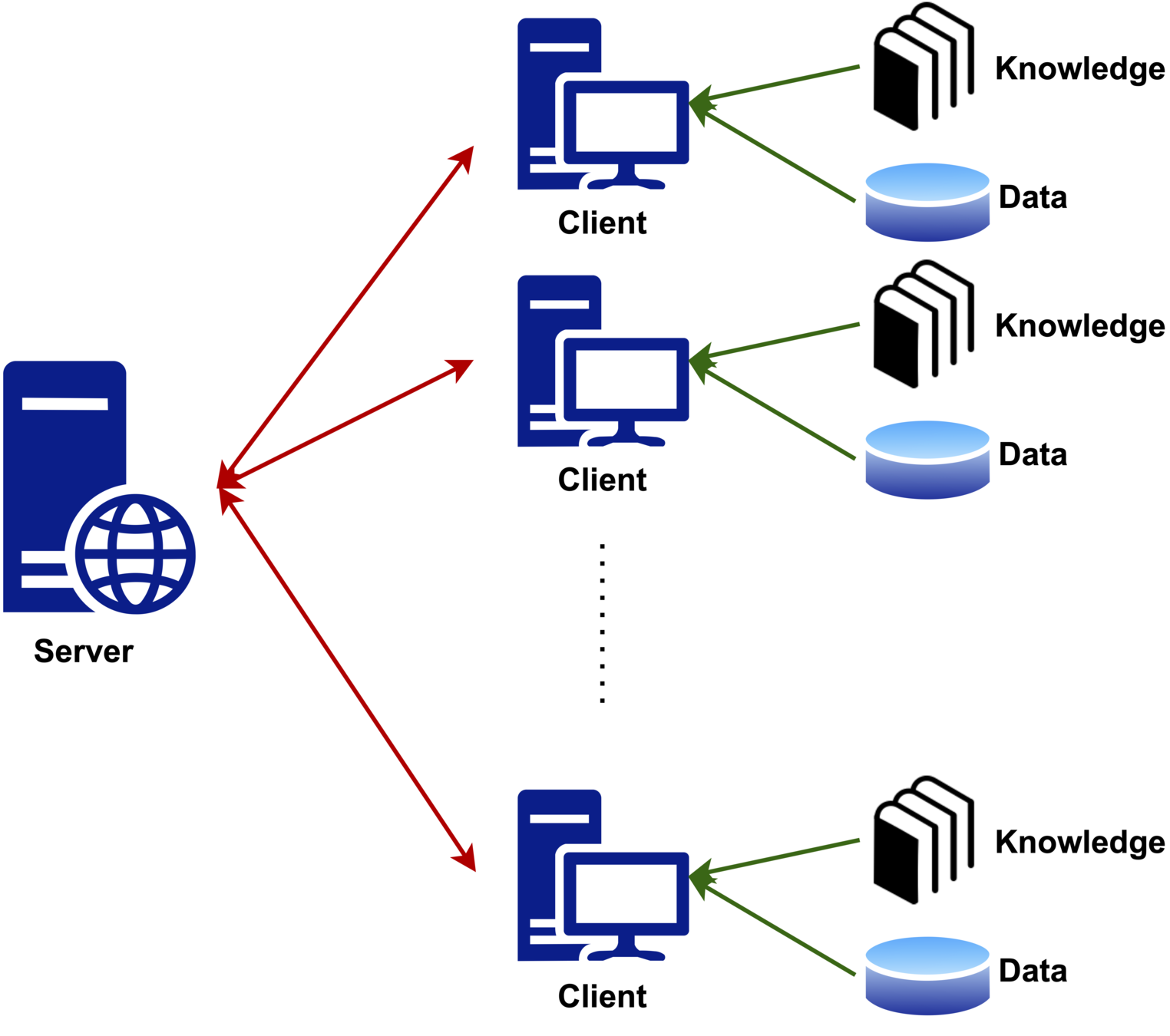
Coal-Mixing in Coking Process
Challenging as no direct formula
Based on experience and knowledge
largely affects cost
Task Description
Goal: improve the expert's prediction model with machine learning
Data scarcity: collecting data is expensive and time consuming
We unite 4 coking industries to collaboratively work on this task
Challeges
local datasets have different distributions
industries have different expert(knowledge) models
privacy of local datasets and knowledge models has to be preserved
Multiclass Classification
training set
data instance
(features of raw coal)
feature space
label
(quality of the final coke)
label space
data distribution
Task
Setting
Knowledge-based Models
Prediction-type Knowledge Model (P-KM)
Range-type Knowledge Model (R-KM)
Eg. Mechanistic prediction models, such as an differential equation that describes the underlying physical process.
Eg. Can be derived from the causality of the input-output relationship.
Federated Learning with Knowledge-based Models
M clients and a central server.
conditional data distribution depending on
Each client m has
Task Description
each client m obatins a personalized predictive model
Design a federated learning framework such that
clients can benefit from others' datasets and knowledge
privacy of local datasets and local KMs needs to be protected
Direct Formulation Invokes Infinitely Many Constraints
Simple setting
Challenging optimization problem
Architecture Design
The server provides a general deep learning model
learnable model parameters
Function transformation
where
Personalized model
Properties of Personalized Model
Optimization
Optimization problem
Eg. FedAvg [McMahan et al.'17]
global loss
local loss
Most existing horizontal federated learning algorithms can be applied to solve this optimization problem!
Numerical Results (Case-study)

Test accuracy
Percentage of violation
Open-source Package https: //github.com/ZhenanFanUBC/FedMech.jl
Contribution Valuation in Federated Learning
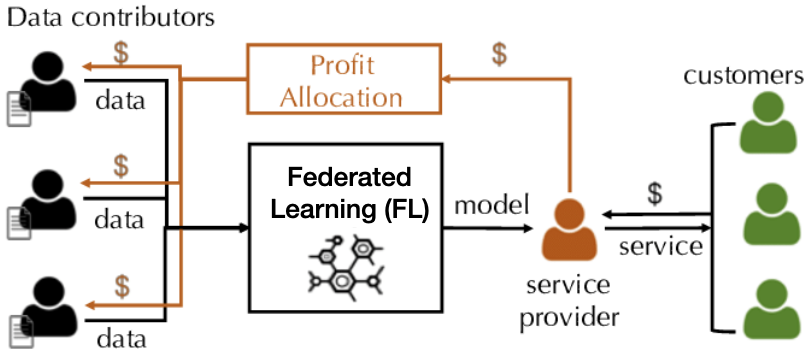
Key requirement
1. Data owners with similar data should receive similar valuation. 2. Data owners with unrelated data should receive low valuation.
Shapley Value
Shapley value is a measure for players' contribution in a game.
Advantage
It satisfies many desired fairness axioms.
Drawback
Computing utilities requires retraining the model.
performance of the model
player i
utility created by players in S
marginal utility gain
Horizontal Federated Learning
model
number of clients
local dataset
loss function
Federated Shapley Value
[Wang et al.'20] propose to compute Shapley value in each communication round, which eliminates the requirement of retraining the model.
Fairness
Symmetry
Zero contribution
Addivity
Utility Function
Test data set (server)
Problem: In round t, the server only has
[Wang et al.'20]
Possible Unfairness
Clients with identical local datasets may receive very different valuations.
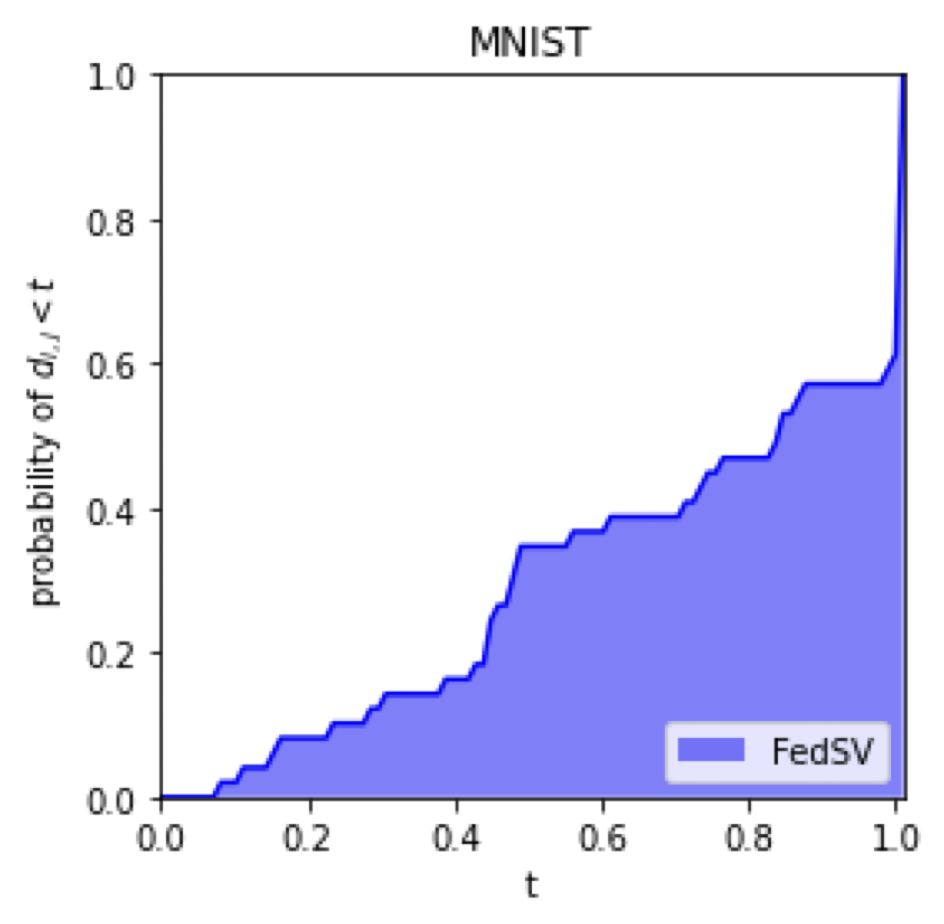
Same local datasets
Relative difference
Empirical probability
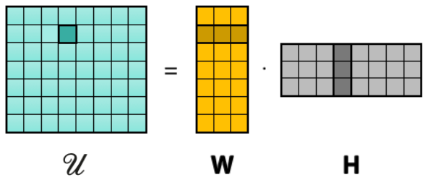
Low Rank Utility Matrix
Utility matrix
This matrix is only partially observed and we can do fair valuation if we can recover the missing values.
Theorem
If the loss function is smooth and strong convex, then
[Fan et al.'22]
[Udell & Townsend'19]
Empirical Results: Singular Value Decomposition
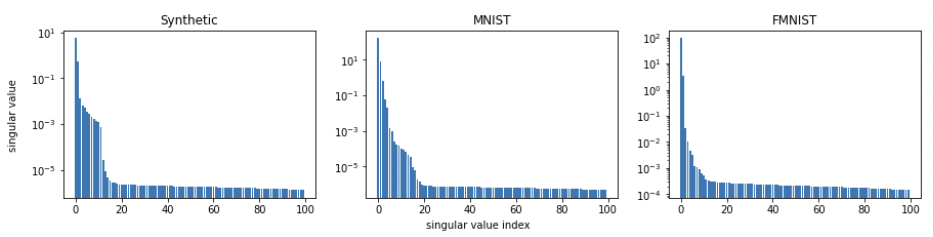
Matrix Completion

Same local datasets
Relative difference
Empirical CDF
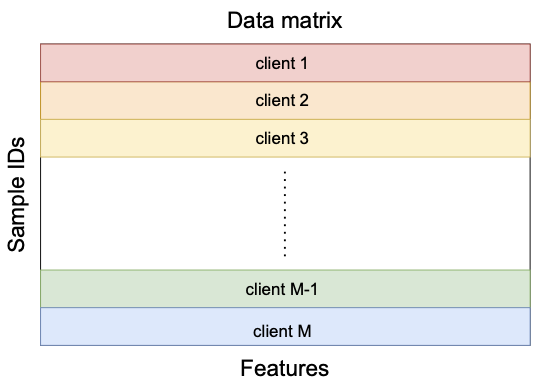
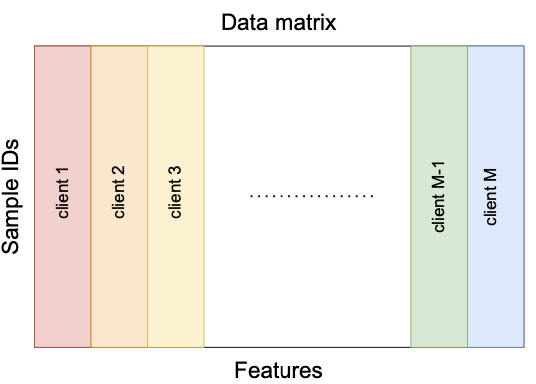
Vertical Federated Learning
local models
local embeddings
Only embeddings will be communicated between server and clients.
FedBCD
[Liu et al.'22]
Server selects a mini-batch
Each client m compute local embeddings
Server computes gradient
Each client m updates local model
Utility Function
Problem: In round t, the server only has
Embedding matrix
Theorem
If the loss function is smooth, then
[Fan et al.'22]
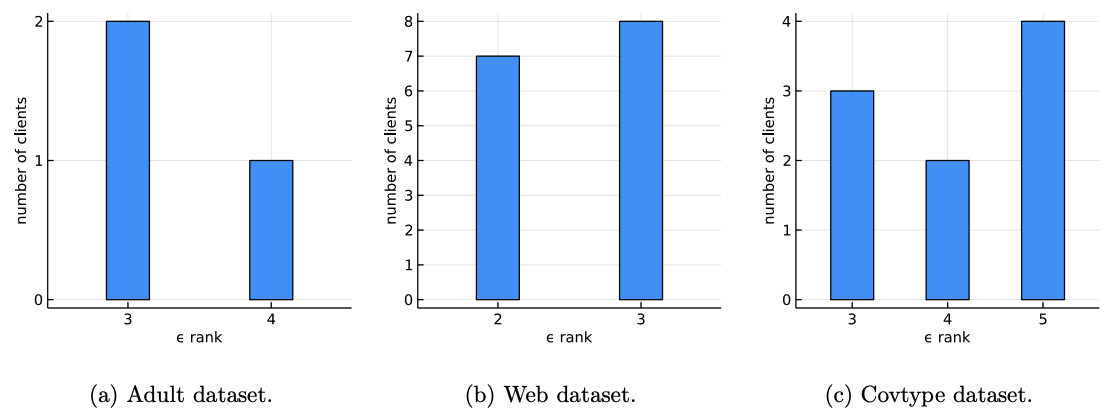
Empirical Results: Approximate Rank
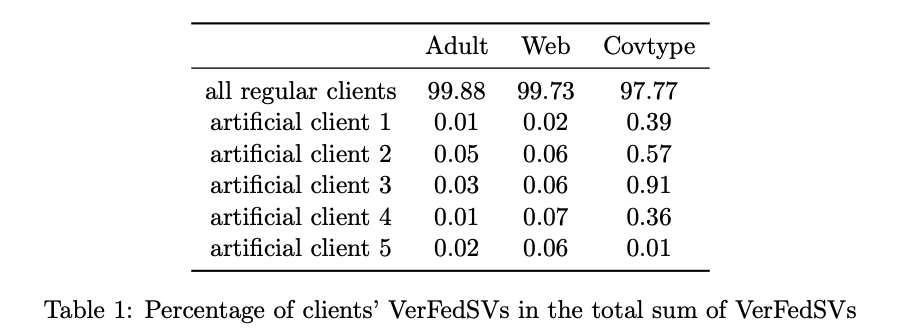
Experiment: Detection of Artificial Clients
These two works are partly done during my internship at Huawei Canada. Our code is publicly available at Huawei AI Gallery.
