Zhenghan Fang*, Sam Buchanan*, Jeremias Sulam

ICLR 2024
Poster session: Fri 10 May 10:45 a.m.
*Equal contribution.
What's in a Prior?
Learned Proximal Networks for Inverse Problems


Sam Buchanan
TTIC
Jeremias Sulam
JHU
Shoutout to Collaborators
Inverse Problems


- Super-resolution
- Denoising
- Inpainting
- Medical imaging
- Compressed sensing
- ...
Measure
Inversion
Inverse Problems
MAP estimate
Inverse Problems
MAP estimate
\[{\color{darkorange}\mathrm{prox}_{R}} (z) = \argmin_u \tfrac{1}{2} \|u-z\|_2^2 + R(u)\]
Proximal Gradient Descent
ADMM
MAP denoiser
Plug-and-Play: replace \({\color{darkorange} \mathrm{prox}_{R}}\) by off-the-shelf denoisers

Inverse Problems
MAP estimate
Plug-and-Play: replace \({\color{darkorange} \mathrm{prox}_{R}}\) by off-the-shelf denoisers
PnP-PGD
PnP-ADMM
SOTA Neural Network based Denoisers...
Inverse Problems
MAP estimate
PnP-PGD
PnP-ADMM
SOTA Neural Network based Denoisers...
- When is a neural network \(f_\theta\) a proximal operator?
- What's the prior \(R\) in the neural network \(f_\theta\)?
Questions
Learned Proximal Networks
Proposition (Learned Proximal Networks, LPN).
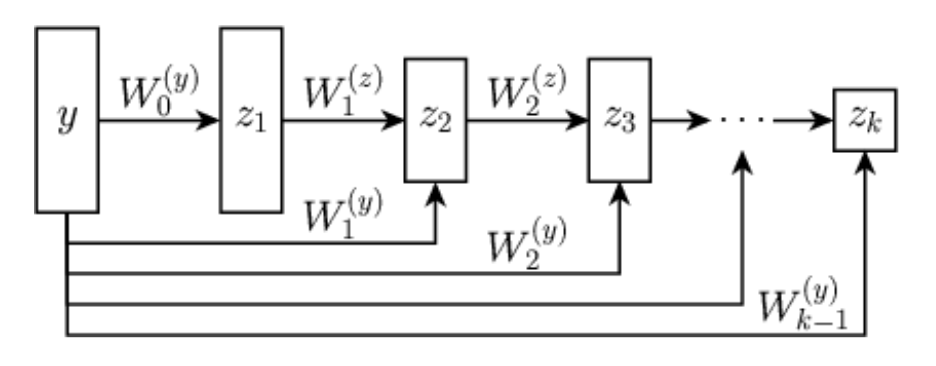
Let \(\psi_\theta: \R^{n} \rightarrow \R\) be defined by \[z_{1} = g( \mathbf H_1 y + b_1), \quad z_{k} = g(\mathbf W_k z_{k-1} + \mathbf H_k y + b_k), \quad \psi_\theta(y) = \mathbf w^T z_{K} + b\]
with \(g\) convex, non-decreasing, and all \(\mathbf W_k\) and \(\mathbf w\) non-negative.
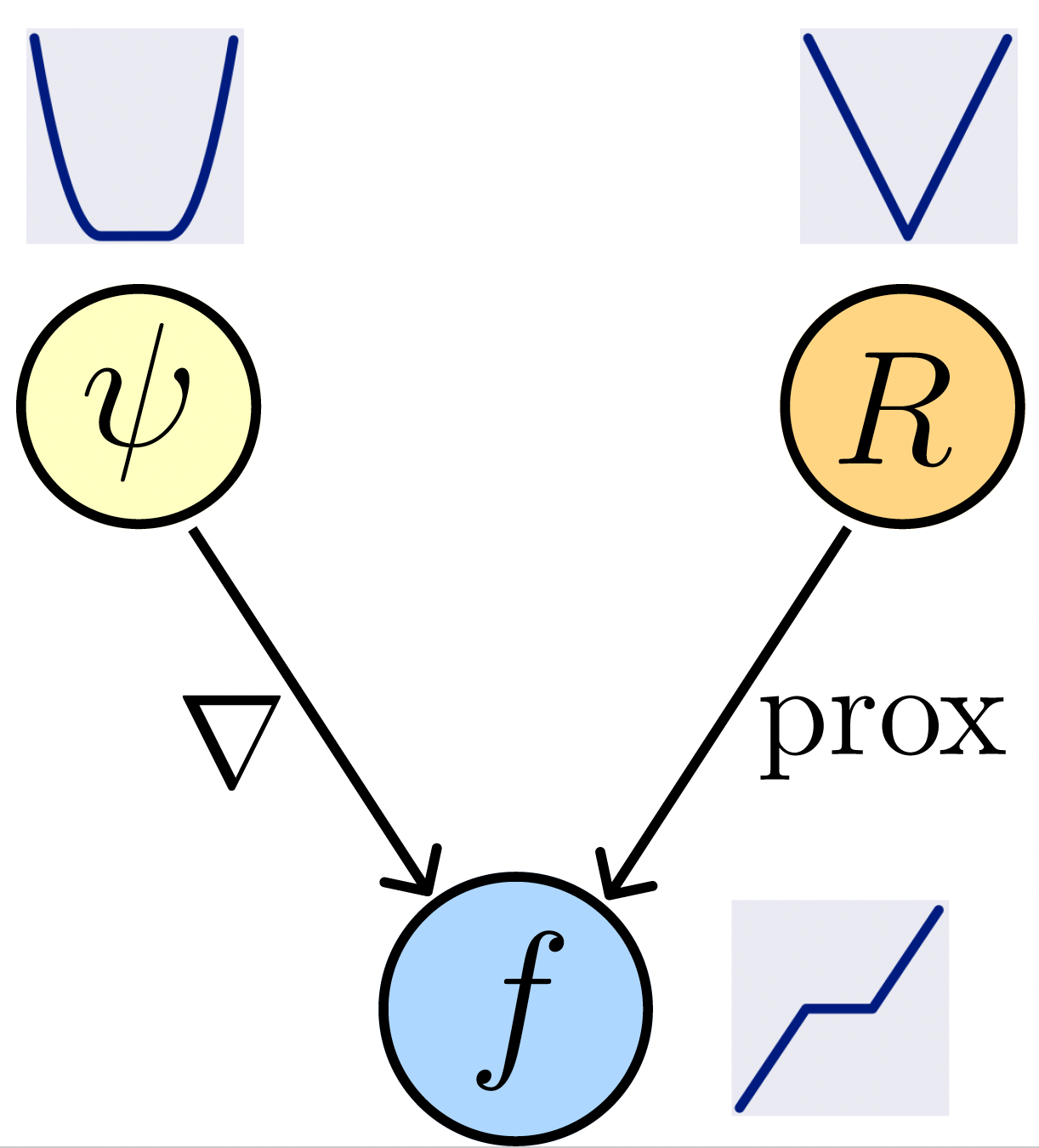
Let \(f_\theta = \nabla \psi_{\theta}\). Then, there exists a function \(R_\theta\) such that \(f_\theta(y) = \mathrm{prox}_{R_\theta}(y)\).


Neural networks that guarantee to parameterize proximal operators
Proximal Matching
\(\ell_2\) loss \(\implies\) E[x|y], MMSE denoiser
\(\ell_1\) loss \(\implies\) Median[x|y]
Can we learn the proximal operator of an unknown prior?
\(f_\theta = \mathrm{prox}_{-\log p_x}\)
\(R_\theta = -\log p_x\)
But we want...
\(\mathrm{prox}_{-\log p_x} = \) Mode[x|y], MAP denoiser
Conventional losses do not suffice!
Prox Matching Loss
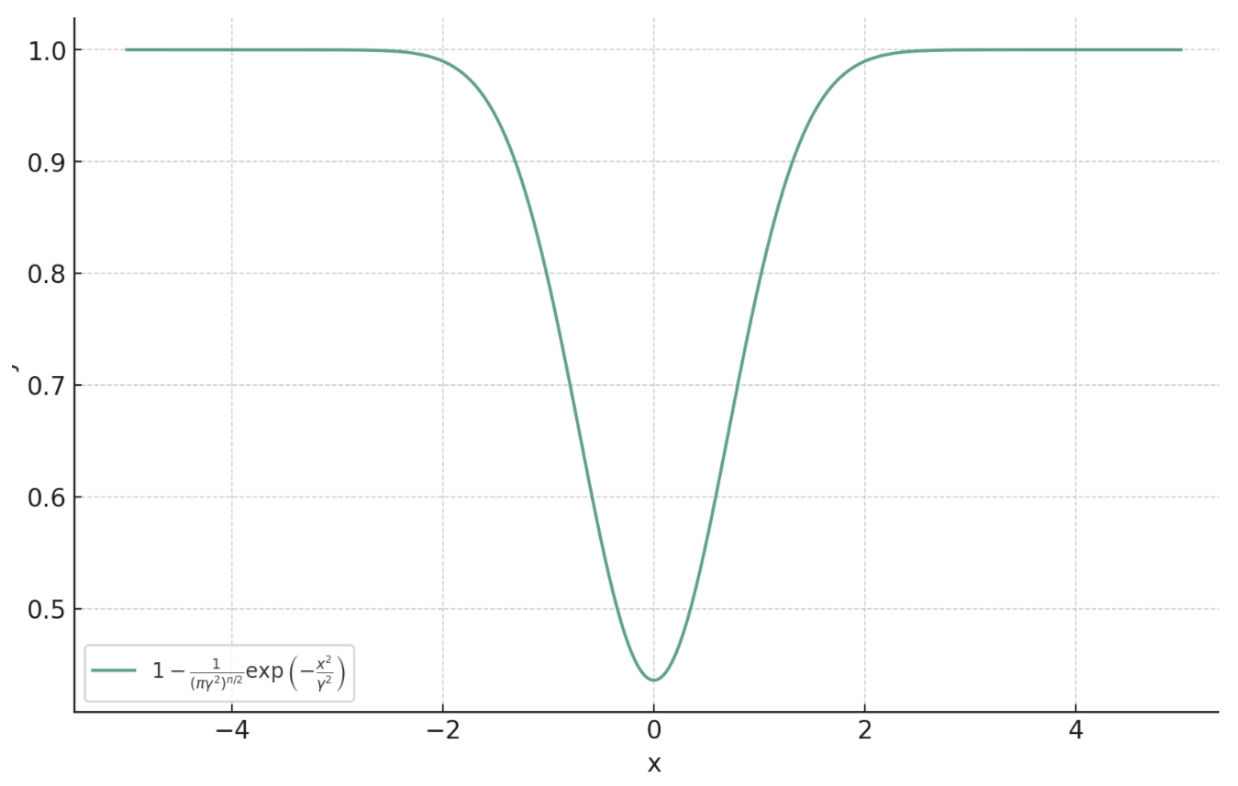
\[\ell_{\text{PM}, \gamma}(x, y) = 1 - \frac{1}{(\pi\gamma^2)^{n/2}}\exp\left(-\frac{\|f_\theta(y) - x\|_2^2}{ \gamma^2}\right)\]
Theorem (Prox Matching, informal).
Let
\[f^* = \argmin_{f} \lim_{\gamma \searrow 0} \mathbb{E}_{x,y} \left[ \ell_{\text{PM}, \gamma} \left( x, y \right)\right].\]
Then, almost surely (for almost all \(y\)),
\[f^*(y) = \argmax_{c} p_{x \mid y}(c) = \mathrm{prox}_{-\alpha\log p_x}(y).\]
Proximal Matching
\(\ell_2\) loss \(\implies\) E[x|y], MMSE denoiser
\(\ell_1\) loss \(\implies\) Median[x|y]
Can we learn the proximal operator of an unknown prior?
\(f_\theta = \mathrm{prox}_{-\log p_x}\)
\(R_\theta = -\log p_x\)
But we want...
\(\mathrm{prox}_{-\log p_x} = \) Mode[x|y], MAP denoiser
Conventional losses do not suffice!
Prox Matching Loss
\[\ell_{\text{PM}, \gamma}(x, y) = 1 - \frac{1}{(\pi\gamma^2)^{n/2}}\exp\left(-\frac{\|f_\theta(y) - x\|_2^2}{ \gamma^2}\right)\]
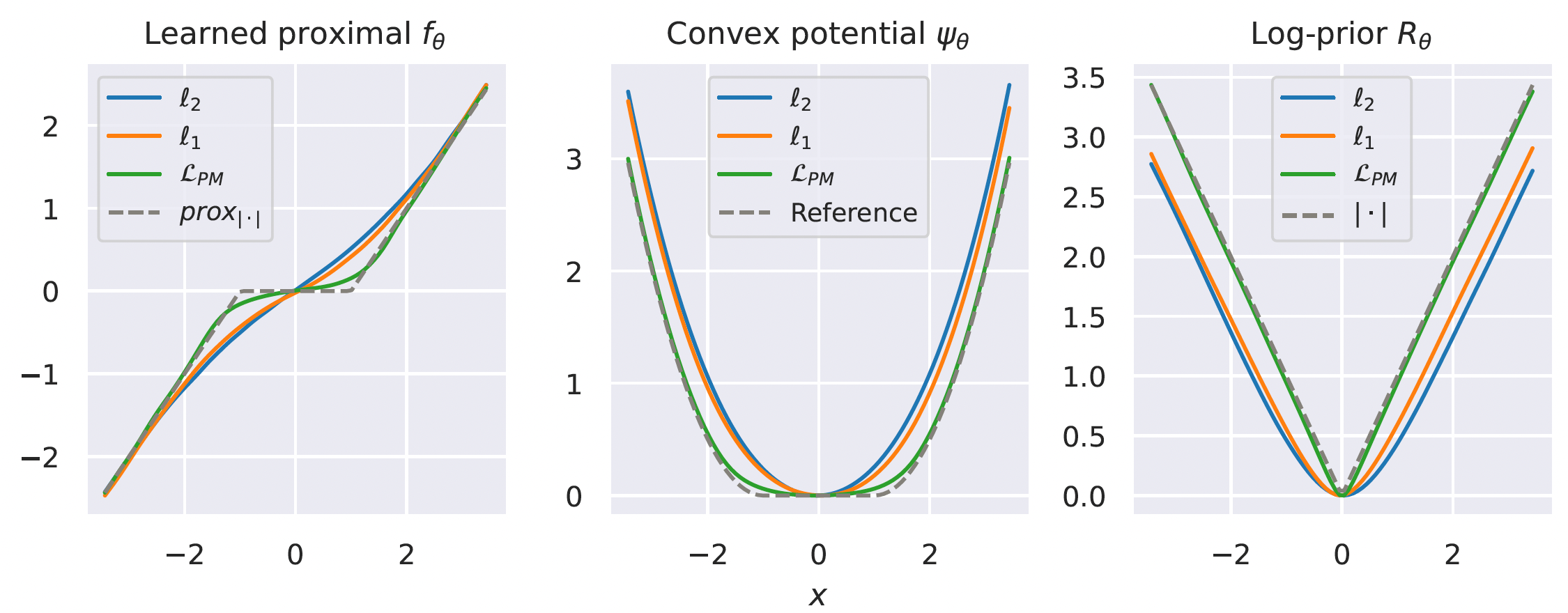
Learning the prox of a Laplacian distribution
Learned Proximal Networks
LPN provides convergence guarantees for PnP algorithms under mild assumptions.
Theorem (Convergence of PnP-ADMM with LPN, informal)
Consider running LPN with Plug-and-Play and ADMM with a linear forward operator \(A\). Assume the ADMM penalty parameter satisfies \(\rho > \|A^TA\|\). Then, the sequence of iterates converges to a fixed point of the algorithm.
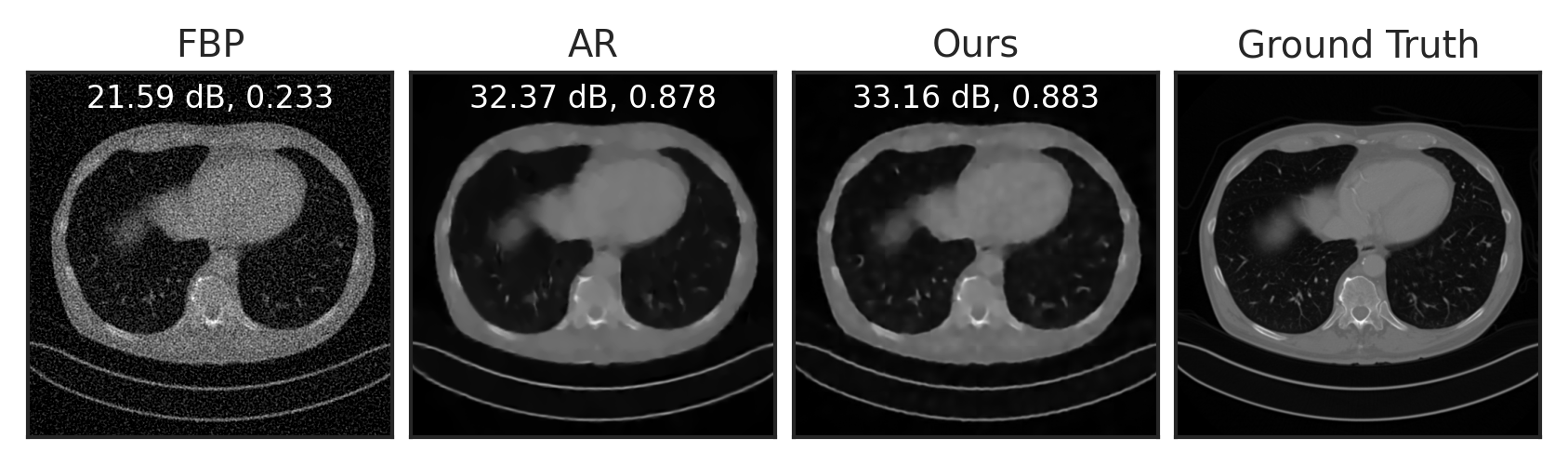
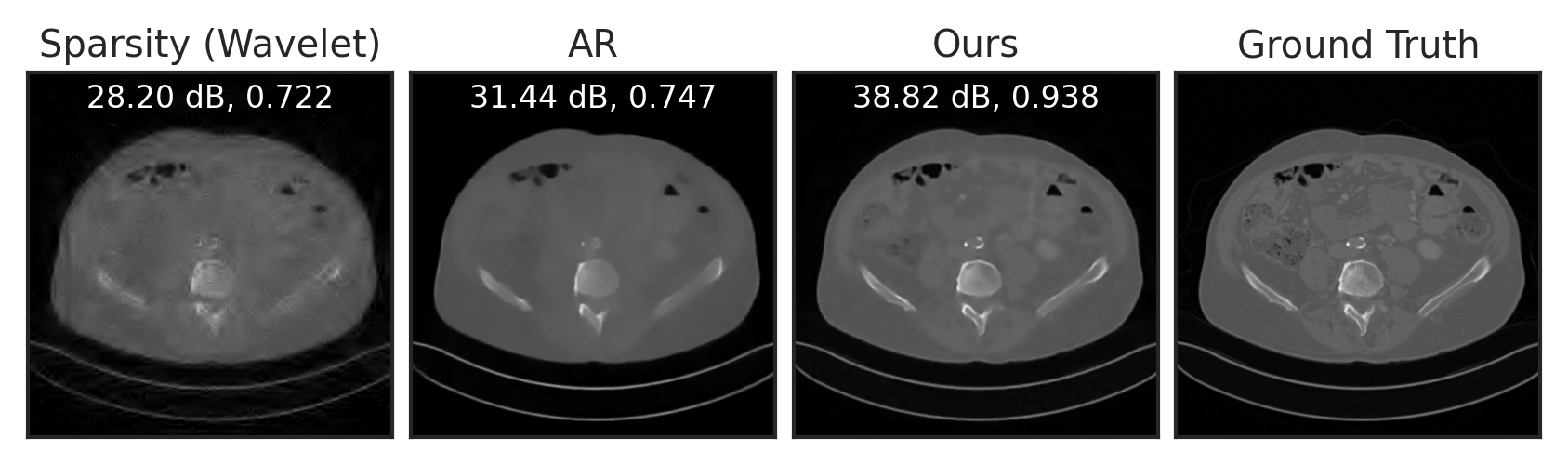
Solve Inverse Problems with LPN
Sparse View Tomographic Reconstruction
Compressed Sensing

Deblurring
Summary
- Learned proximal networks parameterize proximal operators, by construction
- Proximal matching: learn the proximal of an unknown prior
- Interpretable priors for inverse problem
- Convergent PnP with LPN
Poster session: Fri 10 May 10:45 a.m.


Fang, Buchanan, Sulam.
What's in a Prior? Learned Proximal Networks for Inverse Problems.
ICLR 2024
Inverse Problems
MAP estimate
Many optimization algorithms uses the proximal operator of \(R\)...
Proximal Gradient Descent
ADMM
\[\mathrm{prox}_{R} (z) = \argmin_u \tfrac{1}{2} \|u-z\|_2^2 + R(u)\]
Plug-and-Play: Plug-in off-the-shelf denoisers for \(\mathrm{prox}_{R}\)

Learned Proximal Networks
Proposition (Learned Proximal Networks). Let \(\psi_\theta: \R^{n} \rightarrow \R\) be an input convex neural network.
Let \(f_\theta = \nabla \psi_{\theta}\). Then, there exists a function \(R_\theta\) such that \(f_\theta(y) = \mathrm{prox}_{R_\theta}(y)\).
Neural networks that guarantee to parameterize proximal operators
\(W_i^{(z)}\) nonnegative
Learned Proximal Networks
Can we recover the prior \(R_\theta\) for an LPN \(f_\theta=\mathrm{prox}_{R_\theta}\)?
\(R(x) = \langle x, f^{-1}(x) \rangle - \frac{1}{2} \|x\|_2^2 - \psi(f^{-1}(x))\)
[Gribonval and Nikolova]
\(f_\theta\) can be inverted by solving \(\min_y \psi_{\theta}(y) - \langle x, y\rangle\).
LPN provides convergence guarantees for PnP algorithms under mild assumptions.
Theorem (Convergence of PnP-ADMM with LPN)
Consider running LPN with Plug-and-Play and ADMM with a linear forward operator \(A\). Assume the ADMM penalty parameter satisfies \(\rho > \|A^TA\|\). Then, the sequence of iterates converges to a fixed point of the algorithm.

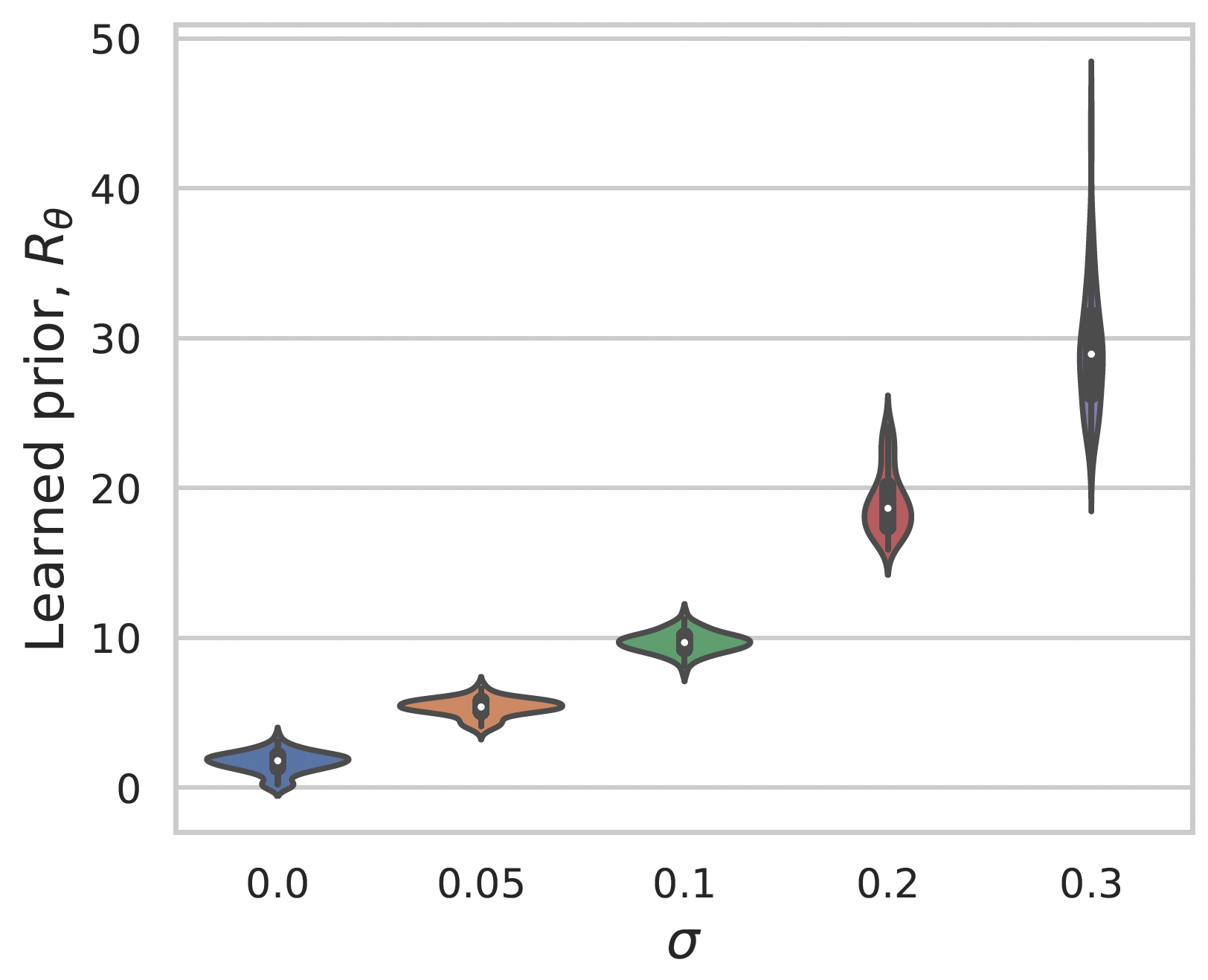
Learning a prior for MNIST images
Gaussian noise
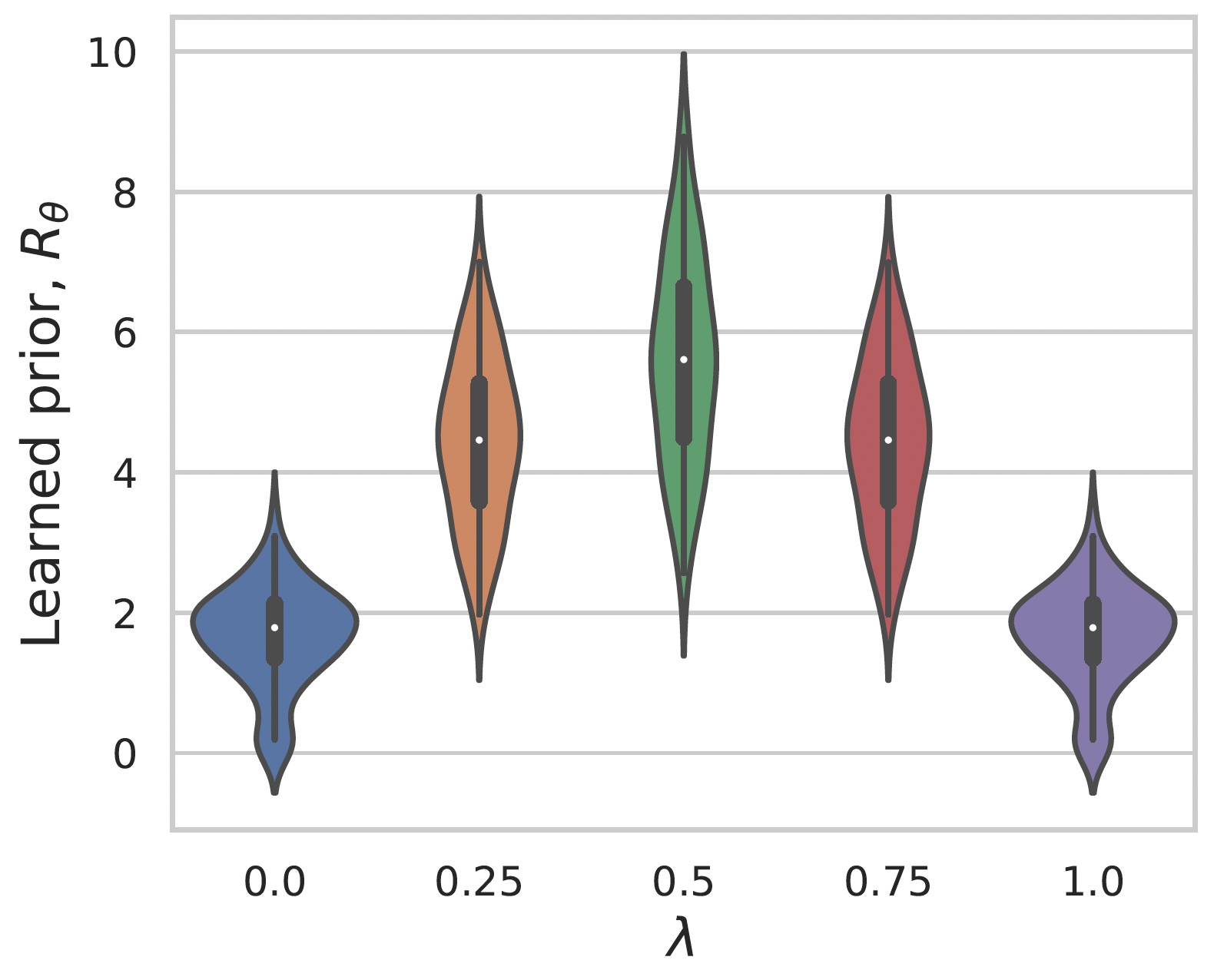
Convex interpolation